Abstract
In conventional subspace clustering methods, affinity matrix learning and spectral clustering algorithms are widely used for clustering tasks. However, these steps face issues, including high time consumption and spatial complexity, making large-scale subspace clustering (LSC) tasks challenging to execute effectively. To address these issues, we propose a large-scale subspace clustering method based on pure kernel tensor learning (PKTLSC). Specifically, we design a pure kernel tensor learning (PKT) method to acquire as much data feature information as possible while ensuring model robustness. Next, we extract a small sample dataset from the original data and use PKT to learn its affinity matrix while simultaneously training a deep encoder. Finally, we apply the trained deep encoder to the original large-scale dataset to quickly obtain its projection sparse coding representation and perform clustering. Through extensive experiments on large-scale real datasets, we demonstrate that the PKTLSC method outperforms existing LSC methods in clustering performance.
1. Introduction
Clustering is a method that groups data with similar features into the same category, showing the dissimilarity between clusters and the similarity within clusters. It has been widely used in the field of data analysis [1]. However, traditional methods (such as K-means [2]) cannot inefficiently cluster high-dimensional data, because of the complex structures [3]. Since the effective information in high-dimensional data usually resides in low-dimensional structures, many subspace clustering methods have been proposed. These subspace-based clustering methods have proven to be effective in mining feature information from high-dimensional data and are widely applied in handling computer vision tasks [4,5].
Classic subspace clustering methods typically rely on the self-representation (SE) property of the data, i.e., any data point within the same subspace can be represented as a linear combination of other distinct data points [6]. The goal is to find the minimal number of , such that all other points are linear combinations of the . This can be expressed by the following formula:
where is the input data, is a regularization parameter, is the SE coefficient matrix, and is the regularization term. In these methods, the affinity matrix is obtained by applying different norms to the square of and different algorithms in different scenarios. Finally, spectral clustering [7] is used to segment the affinity matrix and obtain the final clustering results [8].
However, with the continuous increase of the data scale, complex negative factors (including noise, data missing, etc.) and nonlinear structures in large-scale data seriously degrade the accuracy and increase the computational complexity of clustering tasks. Consequently, traditional subspace clustering methods (such as SSC [9], LRR [10], and LSR [11]) are not applicable to large-scale data clustering. This is because—when applying these methods to large-scale data—they will inevitably encounter large-scale SE matrices and encode models [12,13,14]. Meanwhile, spectral clustering algorithms also have high computational complexity (, n is the number of samples) [15] and large memory usage. Therefore, it is necessary to explore subspace clustering methods that are applicable to large-scale data.
To overcome this problem, the current mainstream approaches involve extracting a small set of data from the large-scale raw data based on the self-representation property, to perform subspace clustering tasks and then extend them to the raw data [16]. Although this method shows its success in performing LSC tasks, there are still some issues that need to be addressed: (1) performing a simple sparse representation or low-rank representation of the sampled data leads to the limited acquisition of sample feature information, resulting in evident errors when predicting the feature information of the original large-scale data [17,18] in many cases; (2) real data points are usually distributed in several nonlinear subspaces, and the above methods cannot effectively handle the nonlinear structure of the data; (3) only applying simple constraints (e.g., norm, F-norm) to the noise in the sample data will seriously degrade the clustering accuracy.
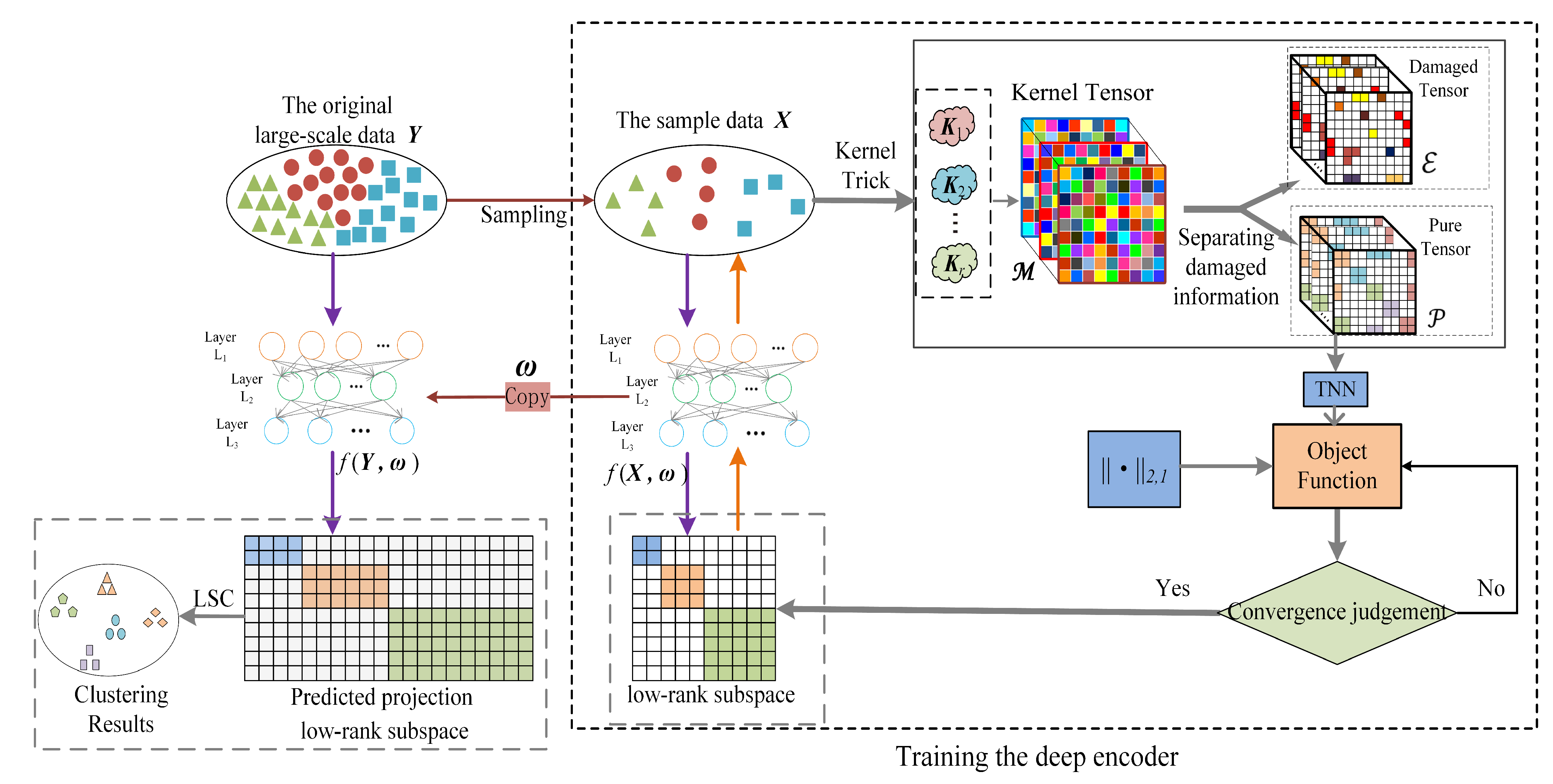
Toward the challenges mentioned above, we designed a novel LSC method: pure kernel tensor learning-based large-scale subspace clustering (abbr. PKTLSC). Mainly three techniques are proposed in PKTLSC. Firstly, PKTLSC extracts a small set of samples from the original dataset, uses kernel tricks to map the sample dataset to a high-dimensional Hilbert space, and stacks the resulting kernel matrices to form a third-order tensor. This leads to the effective handling of nonlinear structures while acquiring more feature information, which is beneficial for reducing errors in predicting the feature information of the original data. Secondly, PKTLSC separates the noise information from the kernel tensor, retains the main information, updates the self-representation matrix of the sample dataset, and applies norm constraints to the self-representation matrix. So, PKTLSC ensures the sparse low-rank properties while avoiding the influence of specific data errors [19]. This denoising method can effectively enhance the robustness of the model and improve clustering performance. Finally, a deep autoencoder is designed for PKTLSC, which is trained with the learned self-representation matrix of the sample dataset. When the training was complete, we applied the autoencoder to the original large-scale dataset to project and obtain its feature representation, thereby achieving the goal of reducing computational complexity. Figure 1 shows the main structure of PKTLSC. The main contributions of this paper can be summarized as follows:
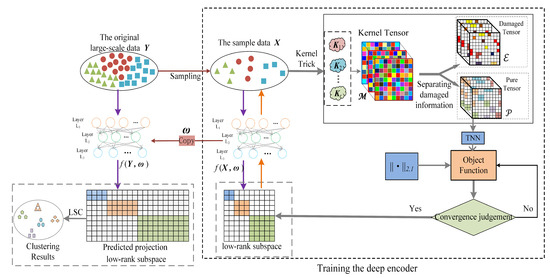
Figure 1.
Schematic diagram of the PKTLSC structure.
- We propose a secondary denoising method to process the sample dataset, providing cleaner training samples for the deep encoder to predict the feature information of the original dataset.
- By ingeniously integrating multi-kernel learning and tensor learning, and applying it to large-scale dataset subspace clustering tasks, we can delve more deeply into sample feature information and effectively handle the nonlinear structures. This approach significantly reduces the prediction error of feature information for large-scale datasets.
- We designed a learnable deep encoder with multiple hidden layers that can effectively manage the nonlinear structures in large-scale datasets and obtain the feature representation of these datasets by projection.
- We integrate ADMM and GD into PKTLSC and design an optimization method. We validate the advantages of PKTLSC to the existing approaches via experiments with datasets consisting of millions of samples.
2. Related Work
In this section, we mainly review the existing approaches to large-scale spectral clustering, scalable subspace clustering, and autoencoder-based subspace clustering, and summarize the strategies dealing with the LSC problem.
2.1. Large-Scale Spectral Clustering
Spectral clustering involves calculating the eigenvectors of the affinity matrix generated by the model and then using K-means to cluster these eigenvectors [7]. However, computing the feature vector involves high computational complexity and large memory usage [20]. Therefore, it is very difficult to apply spectral clustering methods to perform subspace clustering tasks on large-scale datasets [21]. In order to extend the spectral clustering method to large-scale datasets, Nystrm [22] uses approximate eigenvectors of the affinity matrix to calculate the required eigenvalues in multiple subsystems at the same time [21], speeding up the computation process and meeting the requirement of large memory usage. Other approaches [1,23,24] sample a small subset of data points from the original dataset as landmarks, construct the affinity matrix from this sampled dataset, use spectral clustering to determine the feature space of the sampled dataset, and finally employ K-means or other methods to categorize the remaining data into their respective subspaces. However, due to the complex structures of the datasets, the constructed affinity matrix cannot effectively divide the subspace, degrading the clustering performance. In contrast, PKTLSC can effectively deal with the complex structure of datasets and improve the accuracy of clustering.
2.2. Scalable Subspace Clustering
Scalable subspace clustering is a commonly used method to handle LSC. It involves sampling a small set of data points and initially performing clustering on this sample dataset to reduce computational complexity.
SSSC [1] firstly samples from a large-scale dataset, then classifies the sample dataset, and finally uses the sparse-representation-based classifier (SRC) [25] to assign the out-of-sample data to the divided subspace. Similarly, the sampling–clustering–classification method [14] also processes large-scale datasets by first clustering the sample dataset and then using a linear classifier. Unfortunately, these two methods still require considerable time to process large-scale datasets and often result in poor clustering accuracy, as the simple classifier cannot effectively identify complex out-of-sample data. You et al. proposed ENSC [26], which reduces computation time by finding the optimal coefficients between sample data and out-of-sample data, processing only the sample dataset. You et al. also proposed ESC [27] using a distance-first search algorithm to find a representative subset to represent all data points. Kang et al. proposed SGL [28] using the idea of anchors to sample data as landmarks and employing K-means to partition all the data points into the subspace determined by the sample dataset. These methods select a small set of sample data to represent all the data points based on the SE property of the data to reduce computational costs. However, they cannot guarantee clustering accuracy due to the complex structure of the out-of-sample data points. Compared to these methods, PKTLSC can quickly calculate the representation matrix of the out-of-sample data and ensure its robustness.
2.3. Autoencoder-Based Subspace Clustering
PKTLSC uses a learned deep encoder to calculate the sparse representation of all data points, thereby reducing computational complexity. An autoencoder is commonly used by the existing methods. However, it still faces some challenges. For example, an autoencoder (AE) [29] or a sparse autoencoder (SAE) [30] just encodes the data directly and cannot deal with the noise in the dataset. Although the denoising autoencoder (DAE) [31] can output robust coded representation, it does not have the ability to directly deal with the noise existing in the dataset. The RPCA encoder (RPCAec) [32] outputs a robust encoded representation by separating the noise from the dataset, but it only encodes for a single subspace in each round of execution. In contrast, PKTLSC ensures the purity of the input dataset and the robustness of the model by means of secondary denoising. So, PKTLSC can output the coded representations of multiple subspaces at the same time.
3. PKTLSC Model
In this section, we first explain the notations used in this paper, then introduce how to train the autoencoder and process the sample dataset. Finally, we analyze the optimization scheme and the computational complexity of PKTLSC in detail.
3.1. Notations
To standardize the use of notations, a tensor is denoted by a calligraphic capital letter, e.g., , and a matrix is denoted by a bold capital letter, e.g., . Table 1 summarizes the meaning of the symbols used in this paper.

Table 1.
Meaning of notations used in the text.
3.2. Design of the Deep Self-Encoder
To efficiently solve the complex computational problem in the LSC process, learned coordinate descent (LCoD) [33] can learn a sparse-coded representation of the original data by training a feed-forward neural network. Based on this idea, we designed a non-iterative deep encoder to learn the low-rank sparse representation of the original data for reducing the high computational complexity. It can be represented by the following mathematical form:
where is the input data, is the representation coefficient, and is the parameter learned by the deep encoder. During the process of training the deep encoder, we use gradient descent (GD) [34] to minimize the loss function , which can be defined as
From Equation (3), we cannot compute the expectation error directly, because we do not know which in is a noise point. Fortunately, we can take advantage of the SE property of the data and use as an SE dictionary, which can solve the problem of generating a trivial solution during the encoding of the predicted computational data. So, we can consider the squared error function and obtain the following form:
for , where is the i-th column of .
To prevent excessive weight during the training process, we introduce the F-norm here to constrain it and rewrite it to obtain our final predictive coding model, as follows:
In this paper, we use a learned deep encoder structure of three layers, as follows:
where g is the activation function, and we choose the ReLU function (i.e., ReLU(x) = max) as the activation function; , , and are the trainable matrices in the first, second, and third layer, respectively; and is the set of parameters to be learned in the deep encoder.
Remark 1.
Existing studies have demonstrated that, for deep encoders with more than three layers of structure, any continuous activation function can achieve a low-rank sparse representation of uniformly approximate data with enough hidden units [35,36].
3.3. PKTLSC Model
Given a large-scale dataset , we suppose that the number of clusters in is known ahead. Based on the idea of scalable subspace clustering, we use the randperm function to randomly select the number of points, and PKTLSC randomly selects m points and forms a small dataset .
We use the multi-kernel learning (MKL) [37,38] technique to efficiently find the internal nonlinear structure in the sample dataset . MKL maps the original data points into a high-dimensional Hilbert space by means of multiple pre-built basis kernel functions to obtain the linear structure. Through this route, the computational complexity of the similarity among data points can be efficiently reduced. Therefore, based on Equation (1), the MKL subspace clustering model can be represented as follows:
where is the basic kernel function, is the kernel Gram matrix obtained by the basis kernel function. In the following, we assume that the order of the kernel Gram matrix is .
Because a single kernel usually cannot accurately capture the complex structure of a high-dimensional large-scale dataset, we use multiple basis kernel functions, e.g., basis kernel functions. We correspondingly obtain kernel Gram matrices and form a kernel pool . We use
to replace Equation (7) as the new MKL subspace clustering model.
To obtain the higher-order correlations between different kernel matrices and to mine more complementary features and common features among multiple kernels, we stack the kernel pool as a third-order tensor , and the block vectorization is defined as .
Some definitions related to the third-order tensor are presented in the following.
Definition 1.
The t-product between two third-order tensors and with matched dimensions is defined as
where is the block circulant matrix of tensor , is the block vectorizing of tensor , and is defined as the inverse operator of .
Definition 2.
The tensor singular value decomposition (t-SVD) with respect to a tensor can be expressed as follows:
where , ,, and is a f-diagonal tensor, and are two orthogonal tensors.
Definition 3.
Due to errors in the sample dataset , the tensor we constructed may be impaired. In order to alleviate the negative impact of the impaired information on to the subsequent clustering task, we attempt to separate the impaired information. Suppose that , where is the purity kernel tensor and is the noise tensor. As usual, we use the tensor nuclear norm (TNN) to impose a constraint on , so that it has the low-rank property. We use the F-norm constraint on the noise tensor in order to effectively avoid the influence of noise. The specific expressions are
Here, we mainly focus on the Gaussian noise in the tensor . We choose the F-norm for the noise constraint, which can further simplify the calculation.
In MKL, to ensure that the optimal SE matrix is learned, we update using the purity kernel tensor . According to Equation (11), we take the sum of all positive slices of , and average it to obtain the optimal consensus kernel matrix , i.e.,
Thus, we can process the sample dataset as
We impose an norm on the regularization term . So, we can ensure that the learned SE matrix has the sparse low-rank property, allowing further handling of the effects of specific data errors during its updating, which will improve the robustness of the model. Thus, Equation (14) can be simplified as
Once is obtained, we input it into the learned predictive coding model, and realize the projection of the sample dataset to its low-rank subspace space. Therefore, the PKTLSC model can be finally expressed as follows:
where , , , and are equilibrium parameters. In order to reduce the difficulty of the parameter selection during model training, we set .
When we complete the processing of , we replicate the trained deep encoder and apply it to the original dataset . The low-rank subspace projection of the original large-scale dataset is obtained from . Finally, PKTLSC uses the LSC algorithm to cluster the original dataset .
3.4. Optimization
In this subsection, we use the alternating directional multiplier method (ADMM) [39] and the gradient descent method (GD) to speed up the calculation and iterative convergence of the PKTLSC model. First, we introduce an auxiliary matrix , which is initialized as . Then, Equation (16) can be rewritten as
Because the computations of and in Equation (16) interfere with each other, which increases the computational complexity of Equation (16). By introducing the auxiliary matrix , we can compute and separately, which will greatly reduce the computational complexity.
The augmented Lagrangian form of Equation (17) is given by
where both and are Lagrangian multipliers, but is a matrix, and is a tensor; is the penalty parameter. Next, we iteratively update all variables.
- (1)
- Updating
Omitting the terms not related to in Equation (18), it becomes
Using the GD algorithm to minimize , we can update as
where is the learning rate during the training of the deep encoder, which is set to = 0.0001 in this paper, and is the gradient in the minimization process.
- (2)
- Updating
Omitting the terms not related to in Equation (18), we can update as
Let , and according to Equation (14), we can obtain
Equation (22) is a typical TNN solving problem. We can first perform the fast Fourier transform (FFT) on and to obtain and , and then perform the SVD operation on the third dimensions of and . This allows us to better utilize the information in each frontal slice of and to obtain the higher-order correlations between different kernel matrices. The specific procedure for solving Equation (22) is shown in Algorithm 1. In Algorithm 1, if , ; otherwise, . , is a matrix, where elements of its diagonal are , respectively, and other elements not in the diagonal are zero.
| Algorithm 1 Updating |
|
- (3)
- Updating
is determined by the tensor . So, we can simply update as
- (4)
- Updating
Omitting the terms not related to in Equation (18), it becomes
Let , we can update as
- (5)
- Updating
Omitting the terms not related to in Equation (18), it becomes
Let ; we can update as
However, the nonlinear depth encoder leads to difficulties in convergence during the iterative solution of . To achieve the fast local convergence of , we remove from Equation (17). So, we update as
Moreover, from our experiments presented in the next section, we find that PKTLSC still achieves high accuracy, even if is omitted.
- (6)
- Updating
Omitting the terms not related to in Equation (18), we can update as
Let , we can solve Equation (29) by means of the following Lemma 1.
Lemma 1.
Given a matrix , suppose the solution of
is , then the i-th column of is
For the proof of Lemma 1, refer to [10] for details.
- (7)
- Updating , and
The optimization process of PKTLSC involves repeatedly updating the parameters until the convergence condition is satisfied. Algorithm 2 summarizes the whole iterative process. In Algorithm 2, Equation (33) is a convergence condition, which varies for different cases. An example of Equation (33) is shown in Section 4.7. After completing the training of the deep encoder, it is copied to the large-scale dataset to calculate the low-rank subspace projection of the large-scale dataset. Algorithm 3 shows the processing of the large-scale dataset.
| Algorithm 2 PKTLSC algorithm via ADMM and GD |
| Algorithm 3 Processing large-scale data with PKTLSC |
|
3.5. Computational Complexity Analysis
The computational complexity of Algorithm 2 mainly arises from Step 2. The computational complexities of updating , and are , and respectively, where m is the size of the sample dataset , is the number of iterations used for training the deep encoder, and (usually) , denotes the number of iterations used for applying the deep encoder to the original large dataset . Updating involves matrix inversion with a computational complexity of . So, the overall complexity of the training process is . Algorithm 3 shows the process for large-scale data. Its computational complexity is linear with , where is the number of units in the i-th layer, l is the number of layers, and n is the number of samples in the large-scale dataset . From the analysis above, our method, PKTLSC, is efficient at reducing computational complexity and saving the memory usage for dealing with LSC tasks.
4. Experimental Analysis
In this section, we use six real datasets of different sizes to validate the clustering performance of the PKTLSC model and compare it with the state-of-the-art LSC method. All experiments were conducted on a computer equipped with an Intel i7-3.6GHz CPU and 128GB of RAM, using Matlab2020b.
4.1. Dataset Settings
The six real datasets used include two small datasets, two medium datasets, and two large datasets. The two small datasets are COIL20 [40], a 32 × 32 grayscale image of 20 different classes of objects, totaling 1440 samples, and MNISTSC2000, a variant of the MNIST dataset [41], where we select a total of 2000 samples from different classes and downscale them to 500 by principal component analysis. The two medium datasets are PenDights [42], a UCI dataset [43] containing 10 features and 10 classes with 10,992 samples, and MNIST [41], which is a 28 × 28 grayscale image of handwritten digits from 0–9, with 60,000 training samples and 10,000 test samples. The two large datasets are UCI datasets [43]. One is CovType [42], which contains 54 features and 7 classes of 581,012 samples. The other is PokerHand [44], which contains 10 features and 10 classes of 1,000,000 samples. The details of all datasets are summarized in Table 2. Figure 2 shows some sample datasets.
Table 2.
Details of the datasets used in the experiments.
Figure 2.
Sample images of some datasets used in the experiment. (a) COIL20; (b) MNIST.
4.2. Comparison Methods and Evaluation Metrics
To extensively evaluate the performance of the PKTLSC model, we compare PKTLSC with 13 state-of-the-art LSC methods, including K-means [2], SEC [20], Nystrm [22], LSC-R [23], LSC-K [23], SSSC [1], SLRR [1], SLSR [1], PLrSC [34], RPCM[17], RPCM[17], RPCM [17], and RPCM [17]. The specifics of these methods were described in detail in the introduction section. To guarantee the fairness of the comparison experiments, we strictly follow the parameter settings in the original texts to optimize these methods in order to achieve their optimal results.
We choose two commonly used metrics, the clustering accuracy (ACC) and the normalized mutual information (NMI), to evaluate the clustering performance. For ACC and NMI, larger values indicate better clustering performance. Refer to [39] for the detailed definitions of ACC and NMI.
4.3. Parameter Settings and Analysis
In PKTLSC, several parameter settings are involved, including kernel parameters, learning depth encoder parameters, sampling numbers, and balancing parameters. They are explained in detail as follows.
4.3.1. The Setting of Kernel Parameters
In order to better handle the nonlinear structure of the data, we set up a total of twelve basis kernel functions, including (1) seven Gaussian kernel functions with the same formula . All have the same setting of , with the maximum distance between x and y in the dataset, but with different ; (2) four polynomial kernel functions with the same formula , but different settings of and ; and (3) one linear kernel function .
4.3.2. The Settings of Hidden Units and Layers
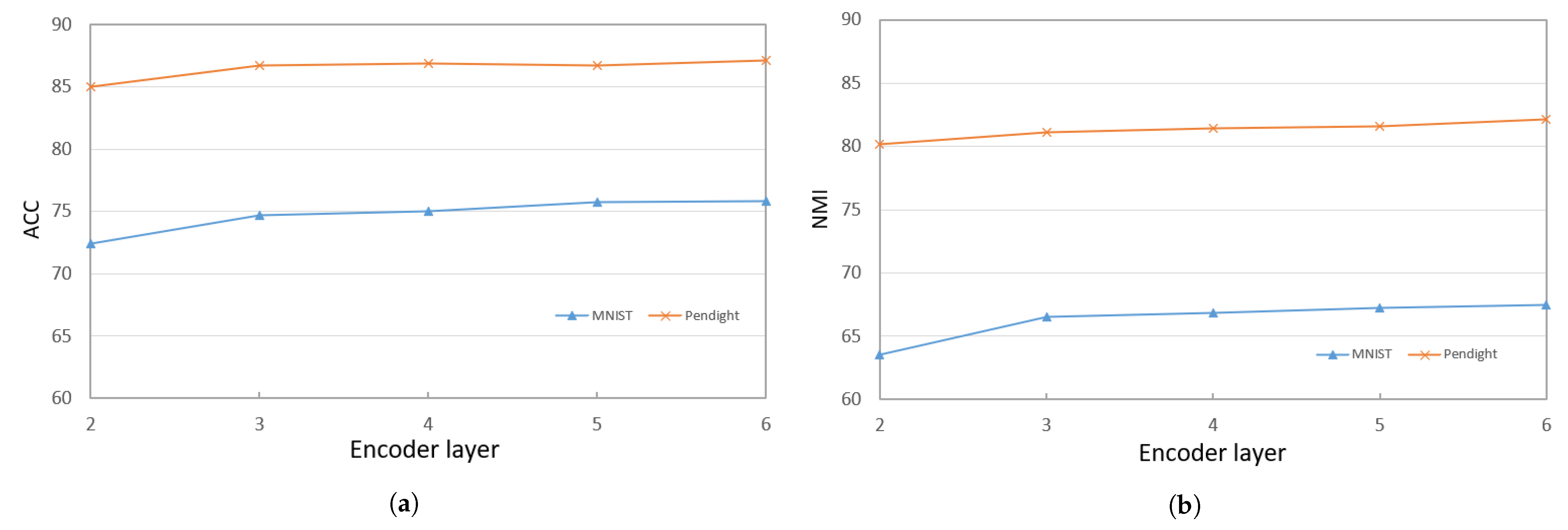
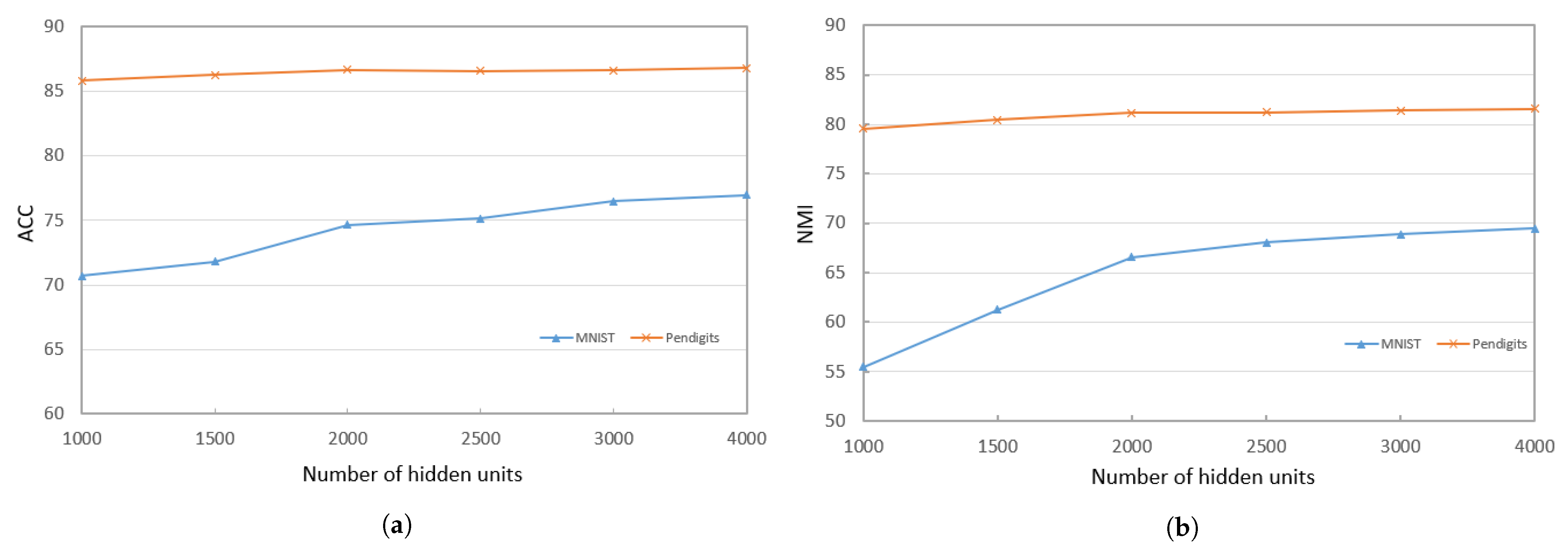
When training the deep encoder, we find that the performance of PKTLSC is greatly related to the number of hidden units and the number of structural layers. Figure 3a,b show the ACCs and NMIs, respectively, with a fixed number of hidden units (2000) but varying the number of structural layers. Figure 4a,b show results with a fixed number of structural layers (3), but different numbers of hidden units, conducted on the PenDigits and MNIST datasets. This experiment achieved similar effects to other datasets, but due to space limitations, they are not presented in this paper.
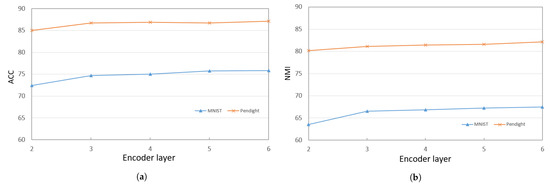
Figure 3.
ACCs and NMIs of PKTLSC with different numbers of structural layers and a fixed number of hidden units (2000) on the PenDights and MNIST datasets. (a) ACCs; (b) NMIs.
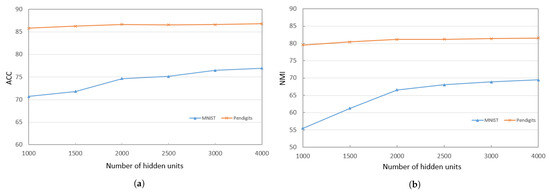
Figure 4.
ACCs and NMIs of PKTLSC with different numbers of hidden units and a fixed number of structural layers (3) on the PenDights and MNIST datasets. (a) ACCs; (b) NMIs.
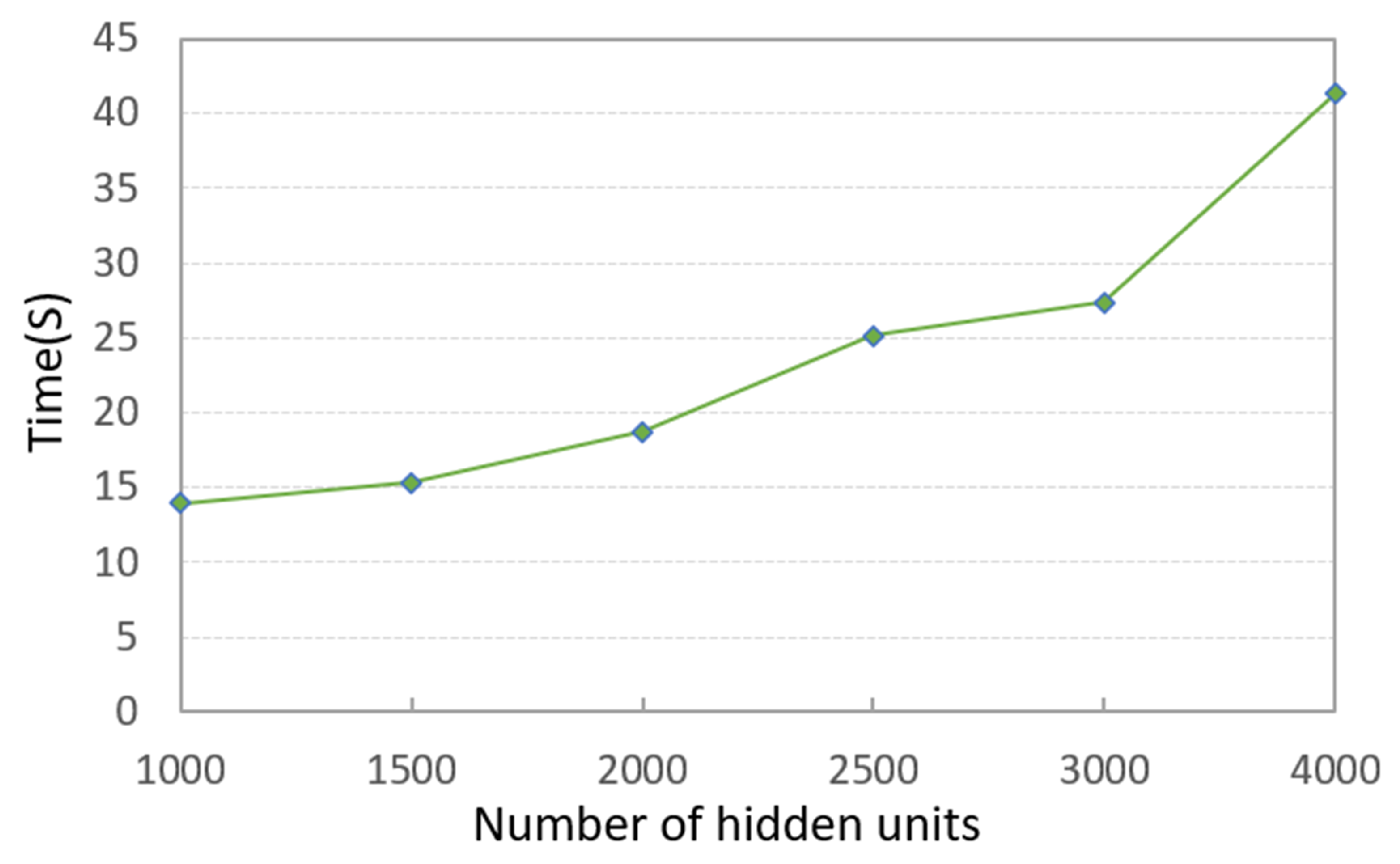
It can be seen that the PKTLSC model achieves ideal ACCs and NMIs when the number of structural layers is ≥3 and the number of hidden units is ≥2000. As the number of hidden units increases, both ACCs and NMIs become larger, but this leads to longer execution times. Figure 5 shows the execution time in relation to the number of hidden units. In order to better balance the clustering performance and the execution time, we set the number of structural layers to 3 and the number of hidden units to 2000 in the following experiments:
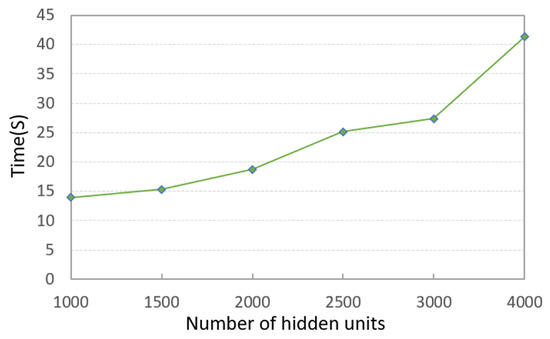
Figure 5.
Execution times along with the number of hidden units and a fixed number of structural layers (3) on the MNIST dataset (in seconds).
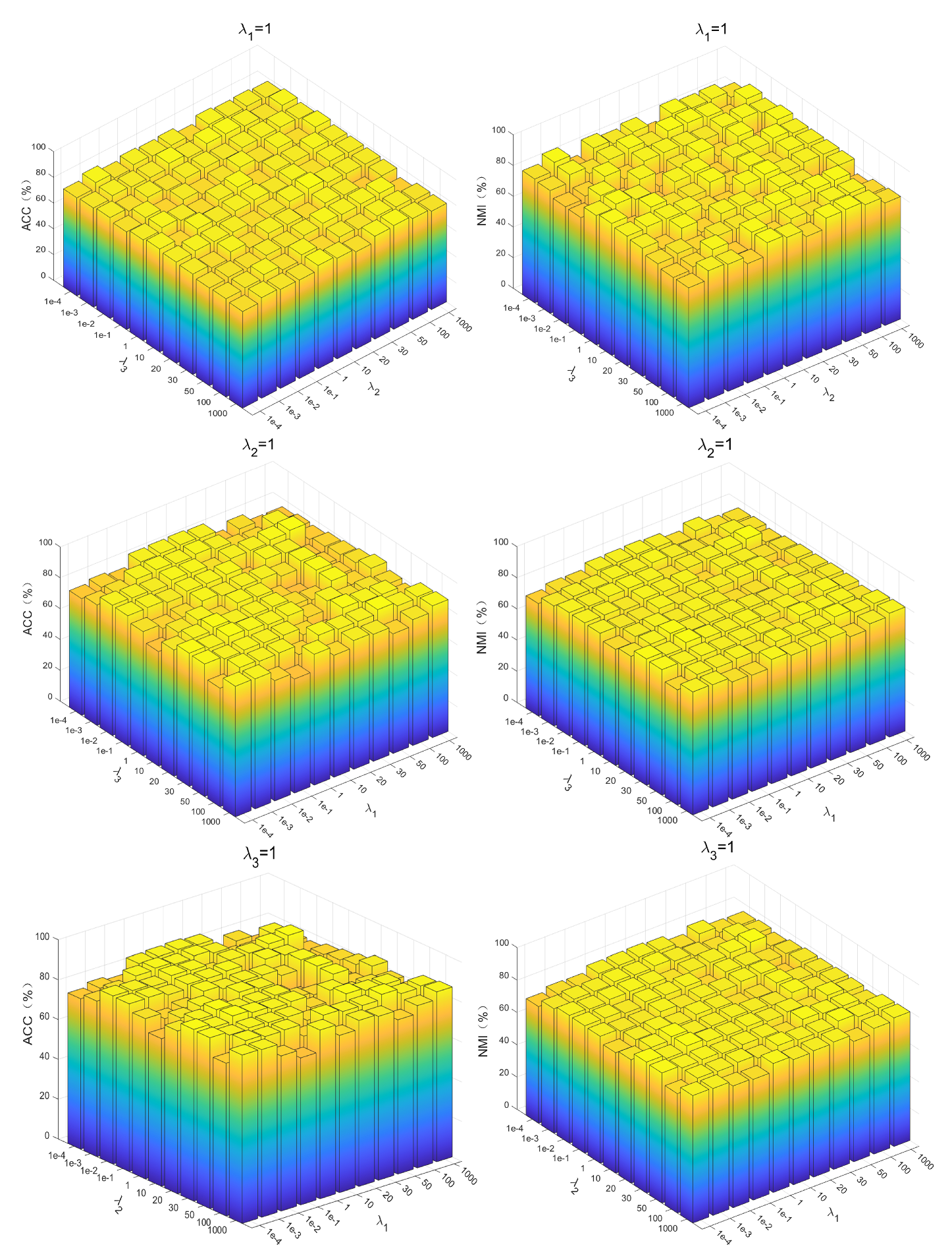
4.3.3. Setting of Balance Parameters
The PKTLSC model contains four equilibrium parameters: , , , and . Among them, , , and are the parameters to equilibrate , , and , respectively, and is the parameter used to equilibrate . To find the optimal parameters, we first simply set to 1 [34], and then use the grid search method for the optimal , , , and set them to . Using PenDights as an example, the parameters’ sensitivity of the PKTLSC model on this dataset is shown in Figure 6. It can be found that the PKTLSC model is applicable to a wide range of values.
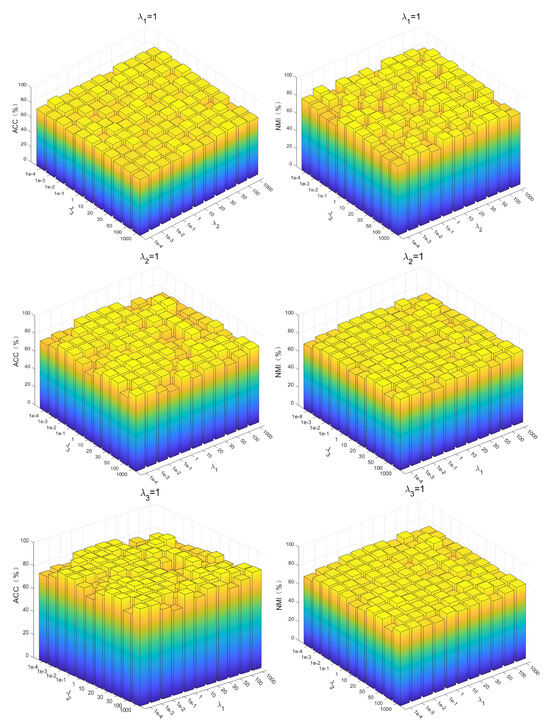
Figure 6.
Parameter sensitivity of the PKTLSC model on the PenDights dataset.
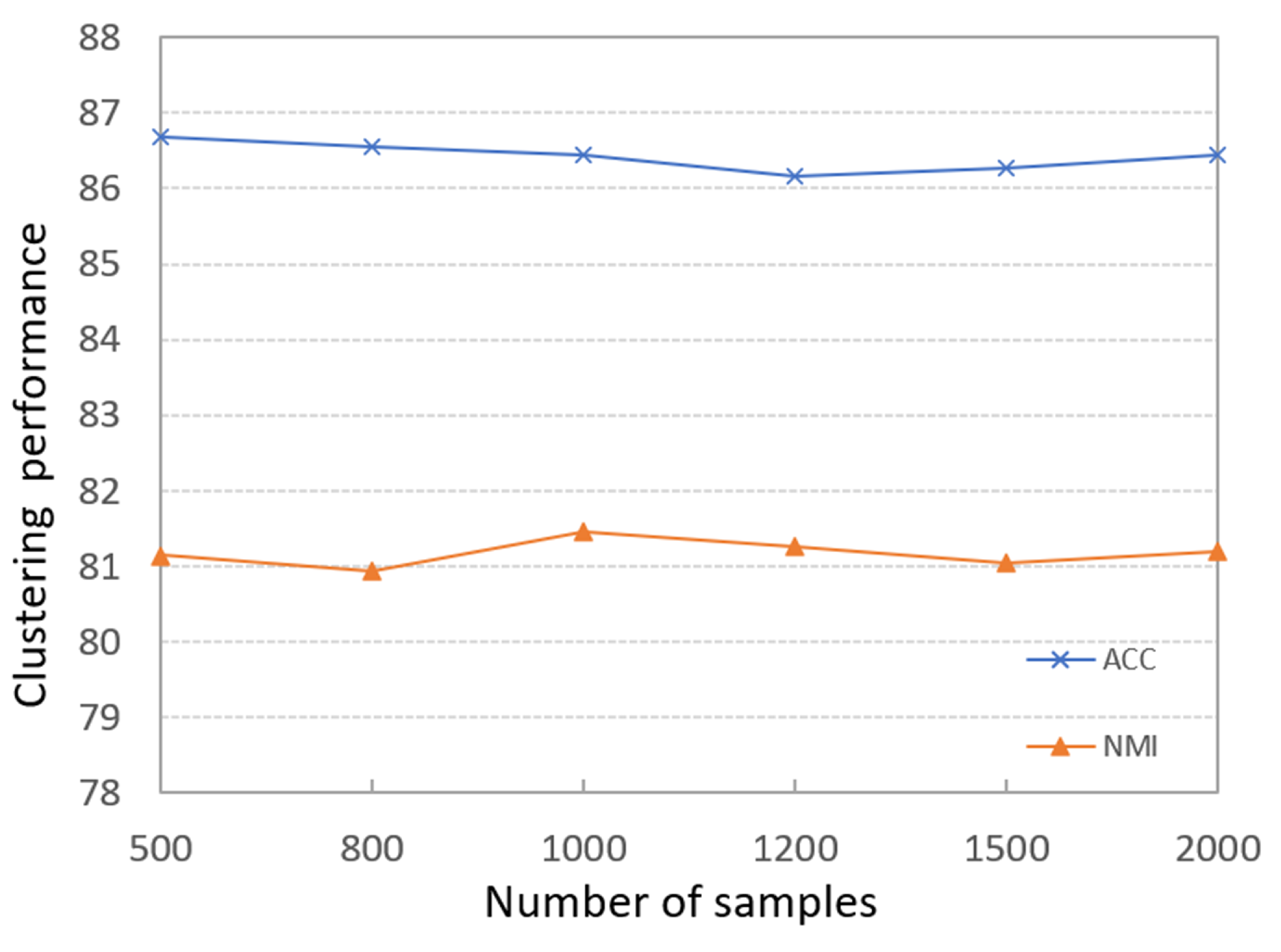
4.3.4. Effects of the Number of Samples
To evaluate the impacts of different sizes of sample datasets on the final clustering results, we run PKTLSC on the PenDights dataset with different sample numbers; the results are shown in Figure 7. It can be seen that the PKTLSC model has stable ACCs and NMIs that are not sensitive to the number of samples. So we can use small datasets to train the deep encoder and greatly shorten the training time. This experiment has also achieved similar effects on other datasets, but due to space constraints, it will not be presented here. This experiment has also achieved similar effects on other datasets, but due to space limitations, they are not presented in this paper.
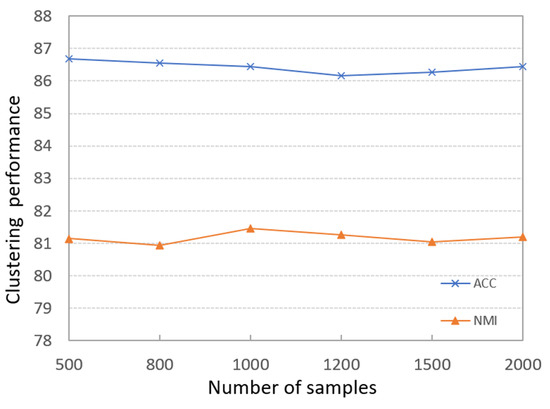
Figure 7.
Effects of different scale sample data on clustering results on the PenDights dataset.
4.4. Comparison with Other Models
In this subsection, we compare the clustering performance of the PKTLSC model with other models on the six datasets, where results for small datasets, medium datasets, and large datasets are shown in Table 3, Table 4 and Table 5, respectively. In addition, we add seven traditional subspace clustering methods on small-scale datasets (i.e., K-means [2], SSC [9], LRR [10], LKGr [45], JMKSC [46], LLMKL [47], and LRMKSC [39]) for comparison. Since these traditional methods are not applicable to medium and large datasets, we only use them on small datasets. We present the average and standard deviations of ACCs and NMIs in ten runs, where the optimal values of different algorithms are presented in bold font.
Table 3.
Clustering results and execution times (in seconds) for small datasets.
Table 4.
Clustering results and execution times (in seconds) for medium datasets.
Table 5.
Clustering results and execution times (in seconds) for large datasets.
Overall. From Table 3, Table 4 and Table 5, we find that the PKTLSC method achieves the best results compared to the other methods in the six datasets. In particular, the average ACC and NMI values of PKTLSC improve by up to 8.25% and 4.97% compared to the suboptimal values on the MNIST dataset. In addition, the running time of the PKTLSC method is shorter than all other methods on the four medium and large datasets. It is also shorter than all other methods except for K-means on the two small datasets,
Small datasets. From Table 3, we find that PKTLSC achieves significant improvement compared with the traditional methods. For example, compared with the best one achieved by the traditional methods, PKTLSC increases the average ACC and NMI by 19.48% and 19.22%, respectively, on the COIL20 dataset, and 16.39% and 9.15%, respectively, on the MNISTSC2000 dataset. This is because PKTLSC uses a secondary denoising method, which can effectively highlight the structural feature of the dataset and minimize the impact of noise on the clustering task. This is also demonstrated in the following robustness and visualization experiments. Except for K-means, the other traditional subspace clustering methods are based on spectral clustering, which leads to high computational complexity. However, PKTLSC learns the feature information of the original dataset from a trained deep encoder with a small sample dataset, greatly reducing the computational complexity. For example, the running times of LRR on the COIL20 and MNISTSC2000 datasets are about 400 times longer than PKTLSC’s. For the same reason, all LSC methods require considerably less time than traditional methods on both datasets.
Medium datasets. From Table 4, we find that PKTLSC also achieves the best ACCs and NMIs compared to other state-of-the-art LSC-based methods. For example, on the PenDigits dataset, PKTLSC increases the average ACC and NMI values by 0.9% and 0.39% compared with the other best ones, even reaching 8.25% and 4.97% on the MNIST dataset. Among the compared methods, RPCM, RPCM, RPCM, RPCM, and PKTLSC all use deep encoders to predict the feature information of the original large dataset and they perform better than other LSC-based methods. This indicates the effectiveness of using deep self-encoders for the prediction of large dataset feature information. Moreover, during the process of selecting a small sample dataset to train the deep encoder, we use MKL to deal with the nonlinear structure of datasets, and we use to tensor to capture the higher-order correlations among datasets. So, PKTLSC allows the trained deep encoder to obtain the data feature information as comprehensively as possible, guaranteeing the reliability of its clustering performance.
Large datasets. Table 5 shows the experiments on large datasets, even reaching 1,000,000 units in the PokerHand dataset. Different from the four datasets in Table 3 and Table 4, these two datasets are more challenging. From Table 5, we find that all methods perform very poor on NMI for both datasets, which is caused by the highly imbalanced clustering. Therefore, we only compare ACC. PKTLSC, on average, improves ACC by 0.57% compared to the suboptimal one on the CovType dataset, and it reaches 1.06% on the PokerHand dataset. The running time of PKTLSC is also the shortest among all the compared methods and takes substantially less time to perform the clustering task. This indicates that PKTLSC can be applied to LSC tasks with high clustering efficiency.
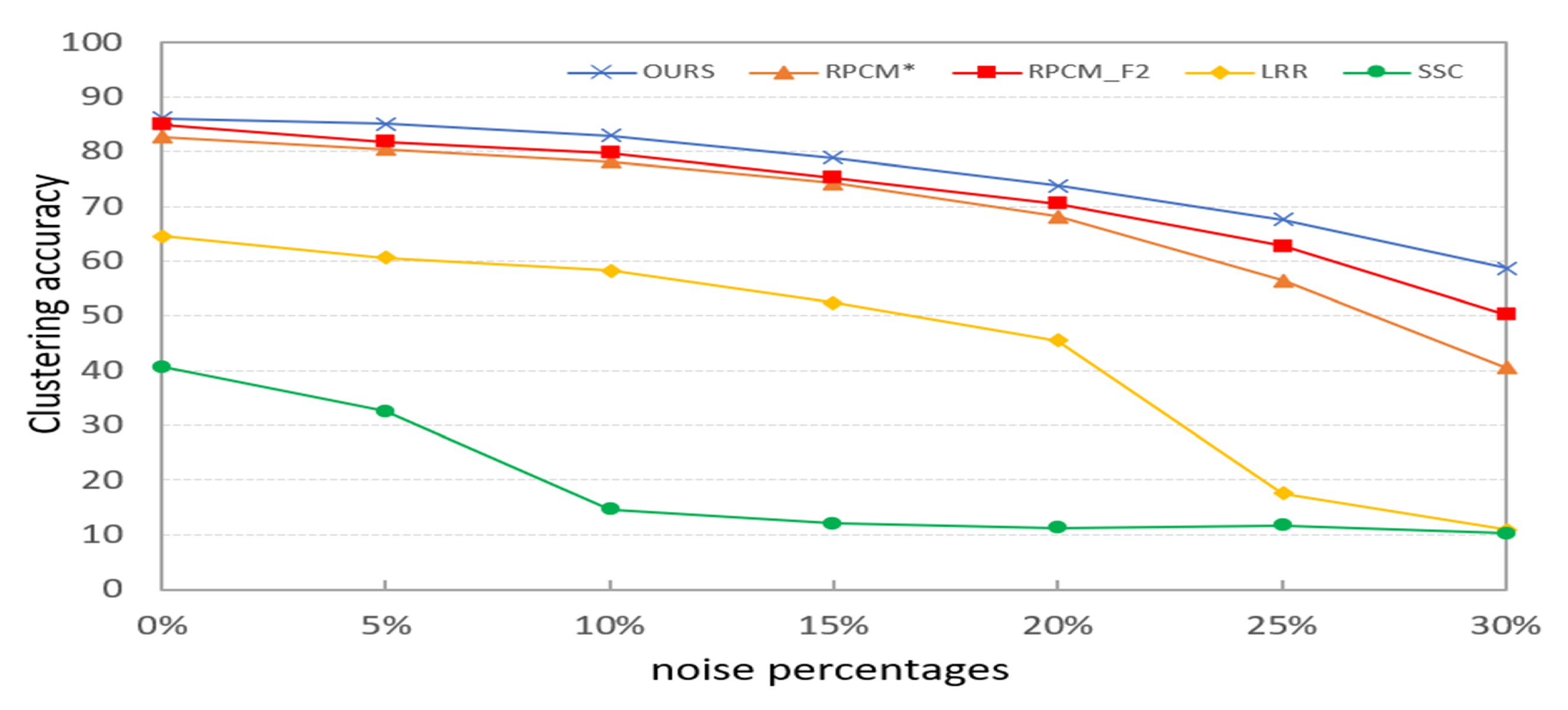
4.5. Robustness Analysis
In this section, we verify the robustness of PKTLSC. We select the robust LSC methods (RPCM and RPCM) and conventional methods (SSC and LRR) as the compared methods. As shown in Figure 8, we add a certain percentage (5%, 10%, 15%, 20%, 25%, and 30%) of random noises to the COIL20 dataset. Then, we perform clustering tasks on them separately and use ACC to evaluate the clustering performance of the methods with different proportions of noises. According to Figure 9, we find that the clustering performance of all methods decreases as the proportion of noise increases. But PKTLSC achieves the best clustering results in all cases. It shows that our proposed quadratic denoising method in PKTLSC can efficiently enhance the clustering robustness. This experiment also achieved similar effects on other datasets, but due to space limitations, they are not presented in this paper.

Figure 8.
Visualization of the COIL20 data with different noise ratios.
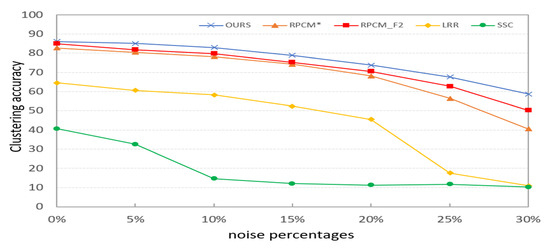
Figure 9.
Effects of different proportions of noises on the clustering performance on the COIL20 dataset.
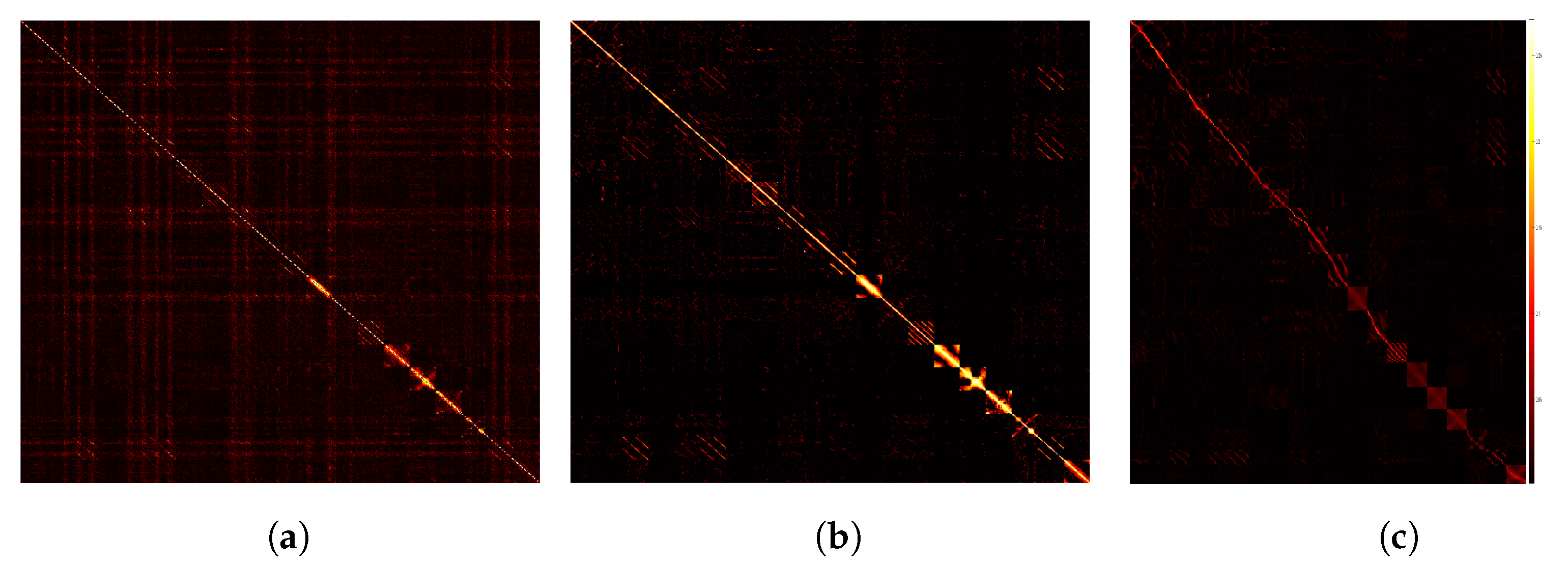
4.6. Visualization
In this section, we use the small-scale dataset, COIL20, to show the prediction results of the feature information by the trained deep encoder. We compare the affinity matrix generated by PKTLSC with SSC and LRR, as shown in Figure 10. From Figure 10, we find that PKTLSC can efficiently process the structure of the original dataset. The inter-cluster structure in the low-rank representation matrix of the original data generated by PKTLSC is more clearly visible than the other two, which provides the basis for accurate identification in subsequent clustering tasks. This also ensures that PKTLSC is applicable to large datasets. In addition, the low-rank representation matrix data generated by PKTLSC is purer than those generated by SSC and LRR, further demonstrating the robustness of PKTLSC.
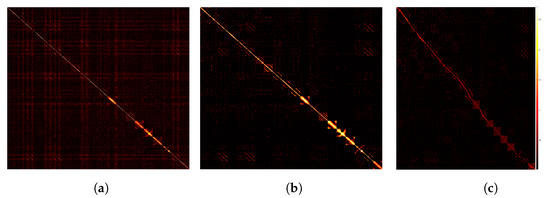
Figure 10.
Comparison of visualizations on the COIL20 dataset. (a) SSC; (b) LRR; (c) PKTLSC.
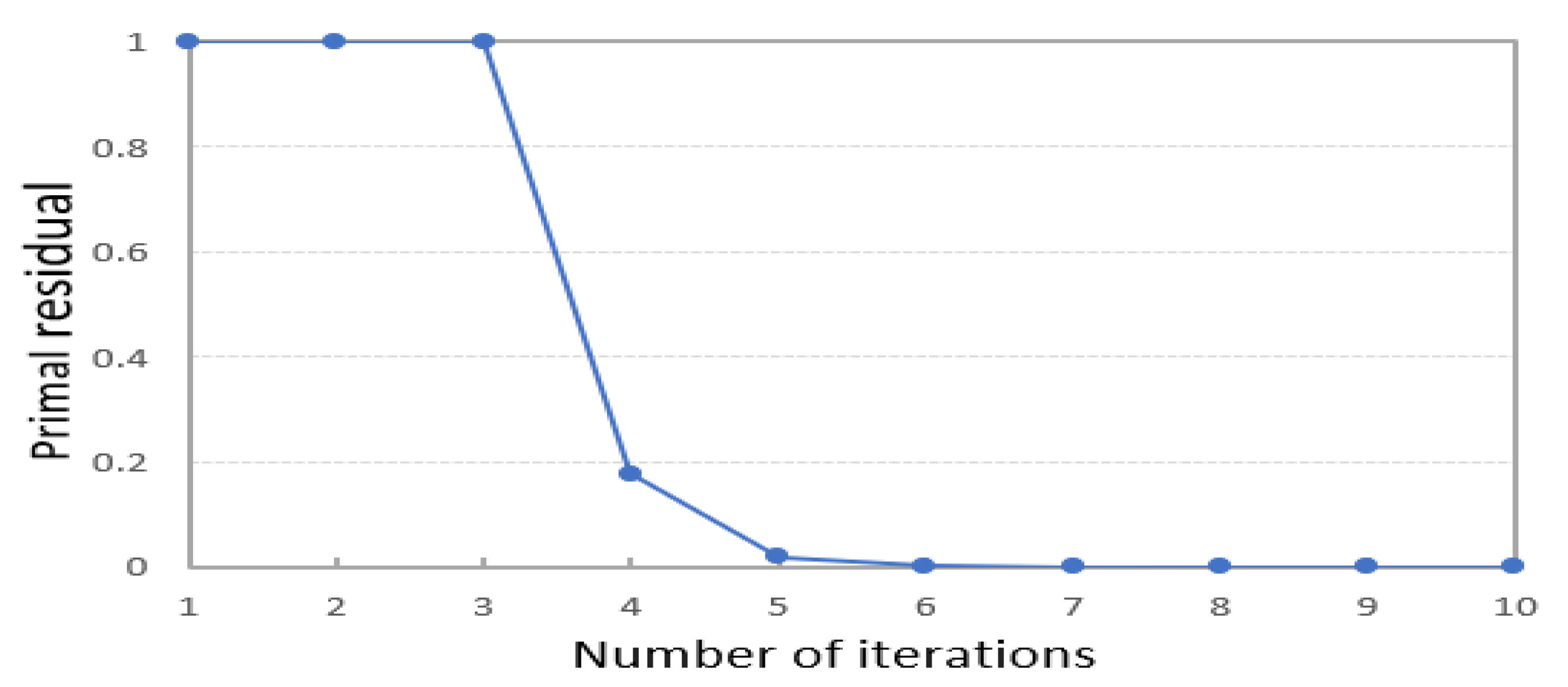
4.7. Convergence Analysis
According to Equation (2), solving the SE matrix of the sample dataset is related to the training of the deep encoder. In PKTLSC, to guarantee fast convergence in training the deep encoder, we simply constrain the solved residual values of the sample dataset’s SE matrix . Therefore, we set the following convergence condition:
When the residual is less than 1e − 4, the model meets the convergence condition and the iteration stops. The setting of this parameter belongs to the setting of experience value. Figure 11 shows the residuals of the MNIST dataset in each iteration of the solving process of PKTLSC. We find that PKTLSC converges and smooths out within a relatively small number of iterations. This experiment also achieved similar effects on other datasets, but due to space limitations, they are not presented in this paper.
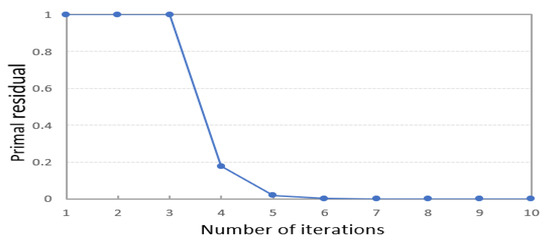
Figure 11.
Convergence curve variation of the PKTLSC method on the MNIST dataset.
It is normal that residuals do not decrease during the first three iterations. The reason is that we use the gradient descent method in the optimization process, which may lead to escaping local optimal solutions in the iterative search space to find a better solution, which may result in instances where the residual does not decrease.
5. Conclusions
In this paper, we propose an efficient LSC method—PKTLSC. PKTLS uses a small sample dataset to train the deep encoder, and then applies it to the original large dataset, which can quickly obtain a projection sparse-coded representation of the large dataset. Extensive experiments on large datasets show that PKTLSC achieves higher accuracy and a higher convergence rate compared to existing LSC methods. In addition, we propose purity kernel tensor learning and secondary denoising methods, which help PKTLSC capture more valid information and further improve the robustness of the model. Moreover, we executed extensive experiments to analyze the parameters of the learned deep encoder, verifying its feasibility in performing subspace clustering tasks. Future work will focus on optimizing the processing of the sample dataset to obtain more useful information for training the deep encoder.
Author Contributions
Y.Z.: conceptualization, software, writing—original draft. S.Z.: experiment, examination, methodology, supervision. X.Z.: examination, experiment. Y.X.: supervision. L.P.: survey literature, editing. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China (grant no. 62102331), the Natural Science Foundation of Sichuan Province (grant no. 2022NSFSC0839), and the Doctoral Program Fund of the University of Science and Technology of Southwest China (grant no. 22zx7110).
Data Availability Statement
Data is contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Peng, X.; Tang, H.; Zhang, L.; Yi, Z.; Xiao, S. A unified framework for representation-based subspace clustering of out-of-sample and large-scale data. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 2499–2512. [Google Scholar] [CrossRef] [PubMed]
- MacQueen, J. Classification and analysis of multivariate observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, San Diego, CA, USA, 21 June–18 July 1967; pp. 281–297. [Google Scholar]
- Li, Q.; Xie, Z.; Wang, L. Robust Subspace Clustering with Block Diagonal Representation for Noisy Image Datasets. Electronics 2023, 12, 1249. [Google Scholar] [CrossRef]
- Fan, L.; Lu, G.; Liu, T.; Wang, Y. Block Diagonal Least Squares Regression for Subspace Clustering. Electronics 2022, 11, 2375. [Google Scholar] [CrossRef]
- Yin, L.; Lv, L.; Wang, D.; Qu, Y.; Chen, H.; Deng, W. Spectral Clustering Approach with K-Nearest Neighbor and Weighted Mahalanobis Distance for Data Mining. Electronics 2023, 12, 3284. [Google Scholar] [CrossRef]
- Liu, M.; Liu, C.; Fu, X.; Wang, J.; Li, J.; Qi, Q.; Liao, J. Deep Clustering by Graph Attention Contrastive Learning. Electronics 2023, 12, 2489. [Google Scholar] [CrossRef]
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Adv. Neural Inf. Process. Syst. 2001, 14, 849–856. [Google Scholar]
- Hou, C.; Nie, F.; Yi, D.; Tao, D. Discriminative embedded clustering: A framework for grouping high-dimensional data. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 1287–1299. [Google Scholar] [PubMed]
- Elhamifar, E.; Vidal, R. Sparse subspace clustering: Algorithm, theory, and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2765–2781. [Google Scholar] [CrossRef]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 171–184. [Google Scholar] [CrossRef]
- Lu, C.Y.; Min, H.; Zhao, Z.Q.; Zhu, L.; Huang, D.S.; Yan, S. Robust and efficient subspace segmentation via least squares regression. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 347–360. [Google Scholar]
- Fan, J. Large-Scale Subspace Clustering via k-Factorization. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 342–352. [Google Scholar]
- Pourkamali-Anaraki, F. Large-scale sparse subspace clustering using landmarks. In Proceedings of the 2019 IEEE 29th International Workshop on Machine Learning for Signal Processing (MLSP), Pittsburgh, PA, USA, 13–16 October 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Wang, S.; Tu, B.; Xu, C.; Zhang, Z. Exact subspace clustering in linear time. In Proceedings of the AAAI Conference on Artificial Intelligence, Quebec, QB, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Zhang, X.; Tan, Z.; Sun, H.; Wang, Z.; Qin, M. Orthogonal Low-rank Projection Learning for Robust Image Feature Extraction. IEEE Trans. Multimed. 2021, 24, 3882–3895. [Google Scholar] [CrossRef]
- Wang, H.; Kawahara, Y.; Weng, C.; Yuan, J. Representative selection with structured sparsity. Pattern Recognit. 2017, 63, 268–278. [Google Scholar] [CrossRef]
- Li, J.; Liu, H.; Tao, Z.; Zhao, H.; Fu, Y. Learnable subspace clustering. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 1119–1133. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Tao, Z.; Wu, Y.; Zhong, B.; Fu, Y. Large-scale subspace clustering by independent distributed and parallel coding. IEEE Trans. Cybern. 2021, 52, 9090–9100. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Zhang, Y.; Lin, Z.; Lu, H. Subspace clustering by mixture of gaussian regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–11 June 2015; pp. 2094–2102. [Google Scholar]
- Nie, F.; Zeng, Z.; Tsang, I.W.; Xu, D.; Zhang, C. Spectral embedded clustering: A framework for in-sample and out-of-sample spectral clustering. IEEE Trans. Neural Netw. 2011, 22, 1796–1808. [Google Scholar] [PubMed]
- Chen, W.Y.; Song, Y.; Bai, H.; Lin, C.J.; Chang, E.Y. Parallel spectral clustering in distributed systems. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 568–586. [Google Scholar] [CrossRef] [PubMed]
- Fowlkes, C.; Belongie, S.; Chung, F.; Malik, J. Spectral grouping using the Nystrom method. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 214–225. [Google Scholar] [CrossRef]
- Cai, D.; Chen, X. Large scale spectral clustering via landmark-based sparse representation. IEEE Trans. Cybern. 2014, 45, 1669–1680. [Google Scholar]
- Yan, D.; Huang, L.; Jordan, M.I. Fast approximate spectral clustering. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Virtual Event, 6–10 July 2009; pp. 907–916. [Google Scholar]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 210–227. [Google Scholar] [CrossRef]
- You, C.; Li, C.G.; Robinson, D.P.; Vidal, R. Oracle based active set algorithm for scalable elastic net subspace clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3928–3937. [Google Scholar]
- You, C.; Li, C.; Robinson, D.P.; Vidal, R. Scalable exemplar-based subspace clustering on class-imbalanced data. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 67–83. [Google Scholar]
- Kang, Z.; Lin, Z.; Zhu, X.; Xu, W. Structured graph learning for scalable subspace clustering: From single view to multiview. IEEE Trans. Cybern. 2021, 52, 8976–8986. [Google Scholar] [CrossRef]
- Bourlard, H.; Kamp, Y. Auto-association by multilayer perceptrons and singular value decomposition. Biol. Cybern. 1988, 59, 291–294. [Google Scholar] [CrossRef]
- Ranzato, M.; Poultney, C.; Chopra, S.; Cun, Y. Efficient learning of sparse representations with an energy-based model. Adv. Neural Inf. Process. Syst. 2006, 19, 819006. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Sprechmann, P.; Bronstein, A.M.; Sapiro, G. Learning efficient sparse and low rank models. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1821–1833. [Google Scholar] [CrossRef] [PubMed]
- Gregor, K.; LeCun, Y. Learning fast approximations of sparse coding. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 399–406. [Google Scholar]
- Li, J.; Liu, H. Projective low-rank subspace clustering via learning deep encoder. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Ripley, B.D. Pattern Recognition and Neural Networks; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Haykin, S. Neural Networks and Learning Machines, 3/E; Pearson Education: Chennai, India, 2009. [Google Scholar]
- Liu, X.; Zhou, S.; Wang, Y.; Li, M.; Dou, Y.; Zhu, E.; Yin, J. Optimal neighborhood kernel clustering with multiple kernels. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Gönen, M.; Alpaydın, E. Multiple kernel learning algorithms. J. Mach. Learn. Res. 2011, 12, 2211–2268. [Google Scholar]
- Zhang, X.; Xue, X.; Sun, H.; Liu, Z.; Guo, L.; Guo, X. Robust multiple kernel subspace clustering with block diagonal representation and low-rank consensus kernel. Knowl. Based Syst. 2021, 227, 107243. [Google Scholar] [CrossRef]
- Nene, S.A.; Nayar, S.K.; Murase, H. Columbia Object Image Library (Coil-20); Columbia University: New York, NY, USA, 1996. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Alimoglu, F.; Alpaydin, E. Combining multiple representations and classifiers for pen-based handwritten digit recognition. In Proceedings of the Fourth International Conference on Document Analysis and Recognition, Ulm, Germany, 18–20 August 1997; IEEE: New York, NY, USA, 1997; Volume 2, pp. 637–640. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml (accessed on 1 December 2023).
- Blackard, J.A.; Dean, D.J. Comparative accuracies of artificial neural networks and discriminant analysis in predicting forest cover types from cartographic variables. Comput. Electron. Agric. 1999, 24, 131–151. [Google Scholar] [CrossRef]
- Kang, Z.; Wen, L.; Chen, W.; Xu, Z. Low-rank kernel learning for graph-based clustering. Knowl. Based Syst. 2019, 163, 510–517. [Google Scholar] [CrossRef]
- Yang, C.; Ren, Z.; Sun, Q.; Wu, M.; Yin, M.; Sun, Y. Joint correntropy metric weighting and block diagonal regularizer for robust multiple kernel subspace clustering. Inf. Sci. 2019, 500, 48–66. [Google Scholar] [CrossRef]
- Ren, Z.; Li, H.; Yang, C.; Sun, Q. Multiple kernel subspace clustering with local structural graph and low-rank consensus kernel learning. Knowl. Based Syst. 2020, 188, 105040. [Google Scholar] [CrossRef]
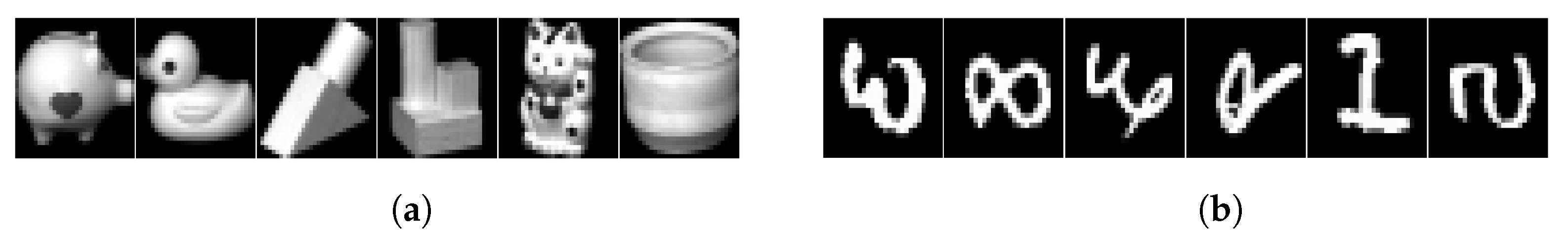

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).