Abstract
Industrial control systems (ICS) are critical networks directly linked to the value of core national and societal assets, yet they are increasingly becoming primary targets for numerous cyberattacks today. The ICS network, a fusion of operational technology (OT) and information technology (IT) networks, possesses a broad attack vector, and attacks targeting ICS often take the form of advanced persistent threats (APTs) exploiting zero-day vulnerabilities. However, most existing ICS security techniques have been adaptations of security technologies for IT networks, and security measures tailored to the characteristics of ICS data are currently insufficient. To mitigate cyber threats to ICS networks, this paper proposes an anomaly detection technique based on dynamic data abstraction. The proposed method abstracts ICS data collected in real time using a dynamic data abstraction technique based on noise reduction. The abstracted data are then used to optimize both the update rate and the detection accuracy of the anomaly detection model through model adaptation and incremental learning processes. The proposed approach updates the model by quickly reflecting data on new attack patterns and their distributions, effectively shortening the dwell time in response to APTs utilizing zero-day vulnerabilities. We demonstrate the attack response performance and detection accuracy of the proposed dynamic data abstraction-based anomaly detection technique through experiments using the SWaT dataset generated from a testbed of an actual ICS process. The experiments show that the proposed model achieves high accuracy with a small number of abstracted data while rapidly learning new attack pattern data in real-time without compromising accuracy. The proposed technique can effectively respond to cyberattacks targeting ICS by quickly learning and reflecting trends in attack patterns that exploit zero-day vulnerabilities.
1. Introduction
Industrial control systems (ICS) play a crucial role in monitoring, managing, and controlling industrial processes. They are an essential component of critical infrastructures across nations, spanning sectors such as electric power generation, water treatment, nuclear power plants, and key manufacturing processes in various corporations [1,2]. Regarding energy and power ICSs, which constitute a considerable segment of large-scale critical infrastructures, the market was valued at USD 165.2 billion in 2022 [3]. It is projected to expand at an average annual growth rate of 5%, culminating in a market size of USD 256.2 billion by 2032. The significance of ICS, along with its growth potential, is anticipated to augment in conjunction with the advancements and trends of Industry 4.0, which includes fields such as advanced manufacturing, automation, and the Industrial Internet of Things (IIoT) [4].
ICSs have increasingly become focal points for cyberattacks, elevating cybersecurity within this domain to a critical issue. ICSs are particularly appealing targets for attackers due to their direct connections with the essential infrastructures and assets of nations, corporations, and societies. These direct connections render ICS assets prime motivations and objectives for assailants pursuing a variety of aims, including economic and political gains [1]. Attacks on ICSs have the potential to inflict immediate and extensive damage across numerous sectors. A prominent example of a cyberattack on an ICS is Stuxnet, discovered in 2010, which targeted a nuclear power plant in Iran with the intent to compromise the country’s critical infrastructure. Stuxnet represents one of the initial cyberattacks on an ICS and was a highly sophisticated APT that exploited zero-day vulnerabilities particular to the target’s SCADA (supervisory control and data acquisition) system, bypassing known vulnerabilities [5]. This meticulously orchestrated attack highlighted the urgent need for fortified cybersecurity measures in ICS environments [6]. Another notable incident is the 2015 cyberattack on the Ukraine power grid, where perpetrators utilized the Black Energy malware to target the Ukrainian power infrastructure. They achieved malicious remote access and control over the ICS clients of the power companies via a VPN (virtual private network), resulting in a blackout that impacted approximately 225,000 customers [7]. The 2021 Colonial Pipeline attack provides a further illustration, in which a ransomware attack on the pipeline’s control network disrupted around 45% of the East Coast’s fuel supply network in the United States. This incident compromised system operations for an estimated five days, affecting roughly 12.5 million barrels of fuel transportation [8]. These incidents collectively underscore the imperative for robust cybersecurity practices within ICS environments, given their critical roles and the severe consequences of potential breaches [9].
ICS security necessitates an analysis that captures the unique characteristics of the ICS network and the data observed therein [10]. However, most existing studies on ICS security technologies apply machine learning- and deep learning-based security techniques, initially designed for IT networks, to ICS data [11]. Despite potentially delivering high accuracy and swift detection performance, this approach needs to pay more attention to the fundamental nature of ICS data, resulting in limitations to security robustness. Firstly, a stark contrast exists in the statistical distribution between data observed in ICS and IT networks [12]. ICS, being a system explicitly crafted for specific industrial processes, exhibits significantly lower data entropy compared to the diverse actions and events in a typical IT environment [13]. Additionally, ICS data are relatively less complex and smaller in size, yet exhibit more biased data classes [14,15]. Since attacks and anomalies targeting ICS are infrequent and small-scale compared to regular operational data, addressing these disparities in data dimension, complexity, and class ratios is imperative [16]. Secondly, cyberattacks on ICS, particularly APT types, unfold over extended periods, necessitating comprehensive time series analysis and continuous tracking of attack pattern trends [17]. Thirdly, the strategy for responding to cyberattacks in ICS environments differs fundamentally from those in IT settings. The primary objective in ICS is to minimize ‘dwell time’, the interval between attack detection and containment [18,19]. Achieving this necessitates the real-time, accurate classification of cyberattacks [20]. However, since ICS-focused cyber-attacks commonly exploit zero-day vulnerabilities [21], prompt and efficient detection of novel attack patterns becomes critical. This necessitates research to identify the optimal trade-off between learning data volume, required model learning resources, and model accuracy during the attack detection and classification model training.
In this paper, our primary objective is to enhance the responsiveness to cyberattacks within the ICS domain. We introduce an anomaly detection methodology founded on dynamic data abstraction, capable of real-time threat mitigation. The proposed approach addresses APT attacks aimed at ICS by utilizing gathered ICS data to assemble a high-quality dataset conducive to real-time learning, thereby facilitating the continuous improvement of anomaly and attack detection models. To achieve this, our methodology comprises a framework with two central components: Dynamic Data Abstraction and Incremental Learning. In the dynamic data abstraction stage, we employ data abstraction on ICS data to bolster the real-time attack detection efficacy of anomaly detection within the ICS environment. The data abstraction process involves sampling high-level sub-datasets capable of aptly representing extensive data volumes [22]. This results in a manageable dataset size, optimized for the rapid and effective training of anomaly detection models. Our paper introduces a dynamic data abstraction technique, aiming to generate and perpetually update a dataset tailored for efficient model learning from ICS data collected in real time. This technique is proficient in discerning novel attack patterns from the observed data, dynamically modulating the data range subjected to abstraction. This methodology ensures the training of a model proficient in countering APT attacks and newly emerging attack patterns that exploit zero-day vulnerabilities. The incremental learning phase of the methodology complements the dynamic data abstraction by incessantly refreshing the learning dataset and the attack detection model in real time. This synergy enhances the anomaly detection model’s efficiency, pinpointing an optimal balance between the attack detection model’s accuracy and the learning efficiency, all while maintaining real-time attack responsiveness.
The main contributions of the methodology proposed in this paper are delineated as follows:
- We introduce a dynamic data abstraction technique capable of swiftly and effectively capturing the unique characteristics of ICS data. This technique demonstrates flexibility in environments characterized by uniquely distributed and statistically significant data collection, serving as a foundational technology for anomaly detection and time-series data analysis techniques.
- We present a incremental learning method, ensuring the continual real-time updating of the anomaly detection model. This approach is versatile, applicable across various settings, and considers the trade-off between system resources and data complexity during the operation of attack detection and classification models.
The structure of the remaining sections of this paper is organized as follows. Section 2 reviews existing literature reviews on detecting abnormal behavior and data abstraction within the realm of ICS data. Section 3 provides a detailed exposition of the methodology proposed in this paper, elucidating its various components and underlying principles. Section 4 presents the results of experiments conducted to validate the performance and efficiency of the proposed methodology. Finally, Section 5 offers a conclusion, summarizing the principal findings and contributions of this work.
2. Related Work
This section reviews existing literature on anomaly and attack detection in ICSs.
ICSs jeopardize connected physical, economic, and human assets by manipulating industrial processes [23]. The challenge in countering cyberattacks on ICSs stems from an expanded attack vector due to integrating industrial processes with IT technology [24]. Consequently, ICS security measures must address threats directed at the ICS and IT domains. This necessitates two primary security approaches: extending IT security technologies to the ICS context and concentrating on the unique attributes of ICS data through data abstraction.
2.1. Anomaly Detection Techniques for ICS
Ike et al. [25] developed a model capturing the relationships and information flows between the physical processes and control elements of ICS to identify targeted cyber-attacks. They introduced the process dependency and impact graph (PDIG), which encapsulates the processes and control information integral to ICS. Utilizing the status of each component within the ICS and their corresponding impact coefficients, the PDIG calculates the influence of control actions on the current state of the system. The study presented a quantitative approach to ascertain the system’s normal state and behavior, employing coefficients that define the interactions between modeled physical processes. This approach proves particularly effective against attacks orchestrated by adversaries with an in-depth understanding of the ICS, as it enables the detection of malicious activities disguised as normal operations.
Hao et al. [24] proposed a hybrid approach, integrating a statistical model and a machine learning model for real-time anomaly detection in ICS. The methodology employed the SARIMA model for local, short-term detection alongside the LSTM (long short-term memory) model for long-term analysis. This dual-model strategy, combining a computationally light model with a high-accuracy algorithmic model, aligns well with the real-time demands of ICS environments, often targets of APT attacks. However, the simultaneous utilization of online and offline models makes this approach sensitive to the complexity of the input data, necessitating a flexible adjustment of the data complexity collected in the ICS environment to fit the model.
M.R. et al. [26] conducted a study on a simulated ICS testbed, modeling sub-processes and their interactions using deep learning. They achieved real-time detection of abnormal behavioral changes by learning the functional dependencies among the modeled sub-processes through rule-based machine learning. This approach effectively merges ICS process design with a data-centric methodology, enabling early and accurate detection of attacks on ICSs. Nonetheless, its reliance on ICS design-specific rules poses limitations to its applicability across various ICS environments.
2.2. Data Abstraction on ICS Data
Gomez et al. [27] introduced a methodology to produce a reliable anomaly detection dataset tailored for ICSs. Their study devised a four-stage attack simulation and dataset creation process, encompassing attack selection, deployment, traffic capture, and feature computation. This approach aims to authentically replicate the specific characteristics of the ICS environment and the associated attack-related data. The method effectively emulates the operation of each sub-process within an ICS network, incorporating a PLC (programmable logic controller) and SCADA, using the ICS communication protocol.
Yang et al. [15] presented a technique to generate a high-dimensional dataset from ICS network flow, addressing the issues related to low data dimensionality, entropy, and high bias associated with ICS datasets. Their methodology involves deriving data from network flow, assessing data quality, and extracting latent features of ICS network flow through a bidirectional RNN model, incorporating an attention mechanism. This standardized approach harmonizes the dataset format across various devices and protocols within the ICS network, resulting in a high-dimensional latent feature dataset well-suited for machine learning and deep learning applications. However, generating high-dimensional and complex datasets to enhance the precision of machine learning and deep learning techniques inevitably leads to substantial resource consumption.
Abstraction of ICS data can also utilize the physical and electrical signal information of actual industrial devices. The information abstracted from the noise signals of devices can be effectively used to check the state of the devices or to predict and estimate their lifetime. Zhang et al. [28] used an adaptive noise estimation technique to assess the state of devices and predict their lifetime. This methodology effectively estimates noise and predicts the device state using a combination of the expectation maximization-unscented particle filter and the Wilcoxon rank sum test. Additionally, Zhang et al. [29] employ the Levenberg–Marquardt neural network for noise estimation and device state assessment, as well as lifetime/power efficiency optimization. This approach uses a backpropagation neural network to abstract device noise data, proposing a power-routing technique that can enhance the overall system efficiency. This approach has the advantage of automatically abstracting data from the noise of industrial devices for anomaly detection purposes.
3. Dynamic Data Abstraction-Based Anomaly Detection for Industrial Control Systems
This section explains the overall architecture of the proposed ICS anomaly detection framework and its detailed mechanisms. The proposed framework consists of two main mechanisms: dynamic ICS data abstraction and incremental learning. The following Figure 1 illustrates the overall architecture of the proposed framework.
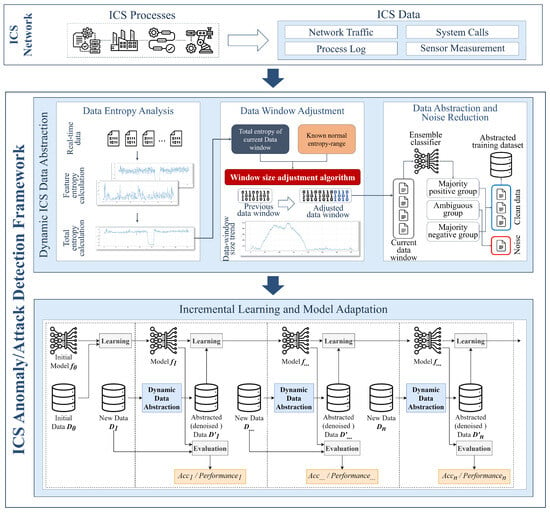
Figure 1.
Overall architecture of proposed ICS anomaly and attack detection framework.
3.1. Dynamic Data Abstraction
The proposed method in this paper aims to quickly learn and classify evolving data patterns in real time, rapidly reflecting these in the AI model’s decision boundaries within the classification model. To achieve this, the method performs anomaly detection in semi-real time while frequently updating the model to learn new data patterns continuously. However, frequent model updates through continuous learning consume substantial time and resources, complicating semi-real time learning. To address this trade-off, this method utilizes dynamic data abstraction, which creates smaller sub-datasets suitable for training. The proposed method frequently trains the anomaly detection model with these smaller datasets, enabling efficient model training and rapid learning of new data patterns simultaneously. Additionally, to satisfy the optimal balance between training time and performance of the anomaly detection model due to data abstraction, we propose the technique of dynamic data abstraction.
Cyberattacks on ICS, comprising industrial processes and protocols, are carried out by modifying information on the sensors and actuators. Such information falsification occurs at limited observation points, but due to the organic interaction of each industrial process, identifying whether the information has been falsified requires high-level analysis of a relatively large amount of data [30]. In particular, many cyberattacks on ICS are new pattern attacks using zero-day vulnerabilities, and the sensor data observed from these attack patterns are highly different in distribution and pattern. For example, the duration of a cyberattack aimed at turning off a specific industrial process of ICS and causing abnormal behavior significantly differs depending on which process out of the entire process is targeted. Therefore, to respond to ICS threats that include various patterns, the ability to respond to attack patterns with an extensive range of changes is required.
The process of dynamically determining the level of data abstraction provides the ability to respond to various attacks robustly. Dynamic data abstraction continuously updates a dataset that trains an anomaly detection model in real time to effectively detect evidence of data modification and abnormal behavior in ICS data. This method is suitable for quickly learning new pattern data through continuous and periodic dataset updates. Simultaneously, when a pattern with an abnormal distribution is identified, it is important to quickly find a way to learn this unusual distribution from data effectively. For these two core goals, the proposed dynamic data abstraction technique uses the following three detailed techniques: data entropy analysis, data window adjustment, and data abstraction using noise reduction.
3.1.1. Data Entropy Analysis
The proposed technique uses dynamic data abstraction to effectively counter a wide variety of cyber attack patterns. In dynamic data abstraction, ’dynamic’ implies the use of varying data abstraction strategies depending on the form and pattern of the input data. Therefore, the proposed method selects a dynamic strategy by performing preprocessing on the observed data. Data abstraction is a process of selecting data suitable for learning, and the quantity and quality of data used in this process directly influence the performance of abstraction. To maximize the expected performance of data abstraction, the proposed method determines the intensity of data abstraction through the preprocessing process. The primary objective of this preprocessing is to quickly assess the general form and distribution of the currently input new data. This assessment, based on statistical information about known normal states, determines the form and distribution of newly input data, and this judgment is used as the intensity of data abstraction that follows. The proposed technique employs data entropy for analyzing ICSs, which function based on specific industrial processes and protocols. This approach leverages the distinct patterns of normal behavior, derived from known normal data. Using sectional data entropy, calculated from this normal data and their average entropy, the technique assesses new data distribution patterns in recent observations. Entropy, indicative of data randomness, is calculated for each data point x within a data feature X, as outlined in Equation (1).
Suppose that w is the data window size for the observed data during a time interval t from the ICS system. The following Equation (2) calculates the average entropy of all observed data in window w when the newly observed data for time t consist of n features, and each data feature is i.
Due to the known normal behavior, the average data entropy observed in a normal state of ICS can be simply calculated. This known average entropy is used as a threshold to detect patterns of data distribution and attack. In this process, the number n of features in the observed data affects the threshold value. When an attacker attacks an ICS, the attacker performs a single-point or multi-point attack. As the number of points at which an attacker manipulates information increases, the likelihood of causing critical anomaly increases, and this attack pattern shows a significant difference from normal entropy. Whereas, if an attacker performs an attack against a single point, this will require a long-term attack, but it seems relatively close to normal entropy compared to an attack against multiple points. These attacks appear in minor differences compared to normal entropy that are continuously observed over a long period. Therefore, the entropy of observed data is a means of effectively identifying the presence of new, unlearned patterns of data distribution and attacks. The final threshold value can be set experimentally depending on the characteristics and complexity of the data used.
3.1.2. Data Window Adjustment
The dynamic window is the core mechanism of the proposed framework and uses the entropy of newly observed data to determine the intensity of data abstraction. Data abstraction effectively compresses large amounts of ICS data to create a small learning dataset that can well reproduce the original dataset. The key point in this process is that the strength of data abstraction refers to how much data will be used to perform abstraction. As shown in the overall process in Figure 1, the training data used in the previous step and the newly observed data window are used as inputs for dynamic data abstraction. The framework proposed in this paper keeps the size of the dataset used for model learning constant for semi-real-time incremental learning. Therefore, regardless of the data size given as input to data abstraction, the size of the resulting learning dataset is constant. In other words, as the data window grows, the strength of data abstraction increases proportionally.
The reason for dynamically adjusting the window size is to maintain a dataset at a level that can be learned in semi-real time while also learning as many attack patterns as possible and attack patterns and their various durations. If the window size is not established variably during the data abstraction process, an attack with an extremely long duration may contaminate the entire abstracted dataset. For instance, if an attack pattern persists beyond the duration of the window size, it can undermine the integrity of the entire classification model. This attack pattern makes the dataset abstract from the distribution and pattern of the attack data rather than the distribution of the normal data. Typically, in the case of APT attacks targeting ICS, there are cases where they are carried out over a very long period, so the abstraction process must be able to take this into account. On the other hand, if the window size is too large, fragmentary attacks of short duration can be completely ignored during the learning process. The window size used in the data abstraction is deciding what length of attack pattern to learn and focusing on it.
The normal entropy confirmed in a known normal state and the threshold derived from it are used for dynamic window adjustment through the following Equation (3). The s value means the threshold of entropy, and and mean the upper and lower limits of the window size, respectively. The r value refers to the unit of window size that changes when the window size is adjusted.
3.1.3. Data Abstraction Using Noise Reduction
The proposed framework performs dynamic data abstraction through the entropy analysis and window adjustment described earlier. Through prior research [31], we have verified that using noise reduction enables the effective training of an anomaly detection model. The framework suggested in this paper proposes a methodology that can train an anomaly detection model more effectively through dynamic data abstraction based on noise reduction.
Data abstraction utilizing noise reduction creates a subset of data that can effectively replicate the diverse distributions of the dataset by employing a voting ensemble model. For newly observed data, the preliminary classification results from the ensemble model select data that represent the original dataset well, filtering out the rest as noise. If the internal models of the ensemble model reach a near consensus in the classification process, it indicates that the data can well replicate the original dataset. Conversely, if there is disagreement in the classification results for specific data, it implies that the data do not fall within the clearly defined category of normal known distributions. Therefore, such data can be considered noise. Once these noise data are removed, the dataset composed of data clearly classified by the ensemble model sharpens the decision boundaries of the model. Furthermore, the improved quality of training data due to the selection of non-noisy datasets means that even with fewer data points, effective decision boundaries can be formed to distinguish the patterns. This indicates that data abstraction has been effectively performed. The paper employs the following two elements to carry out dynamic data abstraction using noise reduction:
Ensemble Model: The ensemble model used for noise reduction consists of models that are complementary to each other to encompass the various distributions. As the number of internal models used in this ensemble increases, the likelihood that the data abstraction phase can replicate the distributions and characteristics of various datasets also increases. However, using a large number of internal models increases the computational demands of the data abstraction phase. In this paper, the number of internal models was determined empirically through experimentation to reproduce as many distributions as possible.
Noise Reduction: ICS data show distinct differences in distribution according to the defined industrial processes. Therefore, the classification results for ICS data can vary depending on the composition of the internal models that make up the ensemble model. Our research reflects these characteristics of ICS data while minimizing noise data resulting from attacks by performing noise reduction based on the weighted sum of the classification results of the ensemble model. We set a specific threshold and determine the noise status of ICS data based on whether the classification results of the ensemble model meet this threshold. This approach has the advantage of flexibly reflecting the distribution characteristics of ICS data according to the process. In addition, we adjust the intensity of noise reduction by modifying the composition of the internal models of the ensemble model and the threshold value. The intensity of noise reduction indicates how many data points from newly observed data can be used to train the next version of the model, which in turn signifies the final strength of data abstraction. The proposed methodology tunes the level at which newly observed attack patterns are learned rapidly and sensitively through the trade-off between internal models and thresholds and the sensitivity to overfitting.
The following Algorithm 1 details the process of dynamic data abstraction that incorporates all three mechanisms from Section 3.1.
The following Algorithm 1 takes as input the existing training dataset T, the newly observed data O, the window size w at time t, the entropy threshold , the noise threshold , and the window adjustment coefficient r for dynamic data abstraction. This algorithm produces the abstracted training dataset and the adjusted window size for the next time point, .
3.2. Incremental Learning Phase
This subsection describes a methodology for continuously updating anomaly detection models for each sliding window using small-scale training datasets derived through dynamic data abstraction. The incremental learning involves recursively retraining the classifier model using an abstracted training dataset. During this process, it is crucial to assess how quickly the model can learn new patterns while retaining the old ones for a significant duration. To satisfy a semi-real-time learning speed, the proposed methodology fixes the size of the training dataset by controlling the intensity with which new data are abstracted. Given the limited size of training data, there is an inevitable phenomenon of forgetting past patterns as the model and dataset are continuously updated.
| Algorithm 1 Dynamic Data Abstraction |
|
To mitigate this limitation, the proposed methodology utilizes the abstracted dataset generated at each iteration. Although there is a significant variance in the time taken to train each classifier model, under fixed computational resources, the size of the training data is expected to be inversely proportional to the model’s learning speed. Many machine learning models exhibit linear time complexity; however, some algorithms have quadratic time complexity. Therefore, dividing a large dataset into several sub-datasets for training has disadvantages in abstracting high-dimensional relationships among massive data but offers advantages from the perspective of learning speed and resource consumption. Our research compensates for the downside of this divided learning approach—interpreting the relationships—through dynamic data abstraction. Our methodology continuously removes noise data from the observed data and performs abstraction by selecting only those that significantly contribute to forming the model’s decision boundary. Thus, data with little influence on model training are eliminated during the data abstraction process, allowing us to replicate the effects of large datasets with smaller ones.
Furthermore, the proposed framework evaluates how much information about past attack patterns has been lost through an incremental learning process. Our research produces small datasets at each iteration, and the version-managed abstracted dataset includes information on the changing trends of attack patterns. Therefore, past attack patterns that had been forgotten are quickly reintegrated into the classifier model’s learning process through dataset aggregation. The proposed methodology maintains the detection capability for various attack patterns by evaluating the effectiveness of each previous dataset based on the accuracy demonstrated by the last trained model over all existing abstracted datasets and by reincorporating datasets that show low accuracy back into the data abstraction process.
4. Experiments
In this section, we describe the experiments conducted to demonstrate the attack detection performance of the proposed dynamic data abstraction technique, their results, and a description of the data used in the experiments.
4.1. Datasets and Experiment Environment
For attack detection in ICSs based on dynamic data abstraction, we used the SWaT dataset. The SWaT dataset [14] is a research-oriented dataset generated through a physical testbed that models actual industrial processes aimed at supporting ICS security research. These data effectively model the processes of a water treatment plant, capturing data from a physical environment that realistically implements procedures such as water storage, chemical dosing, ultrafiltration, and dechlorination. The collected data are multivariate time series data with real-time measurements from various attack scenarios. This dataset, being well labeled and high-resolution, is a suitable resource for evaluating the performance of the anomaly detection technique based on the dynamic data abstraction proposed in this paper. The experiments in this paper were carried out on a server equipped with an E5-2697 v4 (2.30 GHz) CPU, 512 GB of memory, and a Tesla P100 GPU, utilizing libraries in Python version 3.11.4 and CUDA version 11.7.
4.2. Data Entropy Analysis
Before evaluating the performance of the dynamic data abstraction and anomaly detection techniques, we conducted a data entropy analysis, which is crucial for determining the window size, a key aspect of the data analysis process in the proposed method. Figure 2 shows the time series distribution of attack labels in the SWaT dataset, the measured entropy values in each data period, and a horizontal line representing the average entropy of the entire dataset. The individual entropy distributions for each normal and attack period depicted in Figure 2 are presented in Figure 3 and Figure 4, respectively.
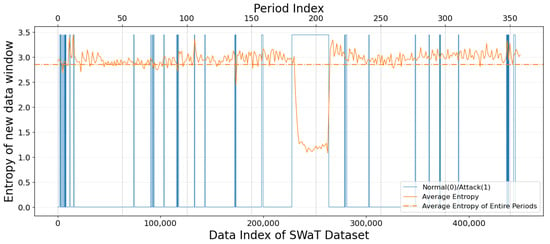
Figure 2.
Distribution of normal (0) and attack (1) across the entire dataset, along with the entropy for each data segment and the average entropy for the entire dataset.

Figure 3.
Entropy of each data period and the average of the entire entropy for normal data.
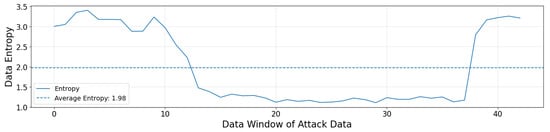
Figure 4.
Entropy of each data period and the average of the entire entropy for attack data.
Figure 5 depicts histograms for the normal and attack data periods observed in Figure 3 and Figure 4. Figure 5 clearly illustrates a noticeable difference in the average data entropy observed by the actual normal and attack behaviors of the ICS testbed. We have confirmed this difference through experimentation, and based on the entropy of each data segment observable in the training data, we have set the initial window size for dynamic data abstraction, as well as the threshold values for adjustment of dynamic window size. The size of the initial window was set to 1252, which is the average of the attack durations, excluding outliers, to reflect the attack periods sufficiently. The entropy threshold range for the dynamic window was set between 2.09 and 4.13, which is the range for the normal data distribution, based on the average entropy of normal data, 3.11. Through the range, we tuned the mechanism to filter out approximately 95% of the attack data patterns.
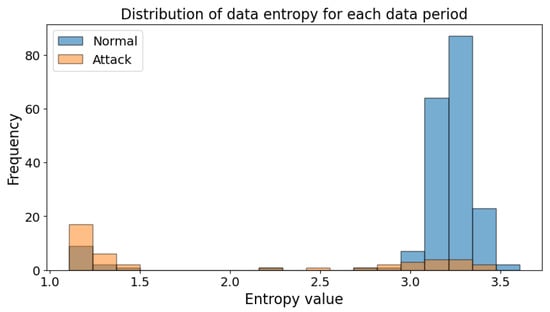
Figure 5.
Histogram of entropy for each normal and attack data period.
4.3. Anomaly Detection Performance of Proposed Method
In this section, we describe the experiments conducted to demonstrate the performance of the proposed dynamic abstraction-based anomaly detection and their results. Our experiments were carried out using the SWaT dataset and involved a performance comparison between the proposed method and a baseline method.
Figure 6, Figure 7, Figure 8 and Figure 9 present the comparative results of accuracy and model training time between the proposed method and the baseline method using the SWaT dataset. The proposed method utilized only 5% of the total training dataset size for training data in Figure 6 and Figure 8, and 10% in Figure 7 and Figure 9. Figure 6 and Figure 7 show the accuracy for the cases using 5% and 10% of the training data, respectively, while Figure 8 and Figure 9 show the model training time for the same. The yellow areas highlighted in Figure 6, Figure 7, Figure 8 and Figure 9 represent the data windows during which attack data were present in the actual dataset.

Figure 6.
Performance (accuracy) of dynamic abstraction using 5% of total data.
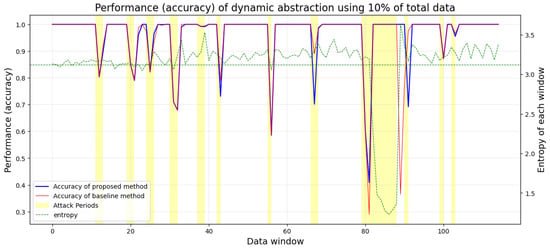
Figure 7.
Performance (accuracy) of dynamic abstraction using 10% of total data.
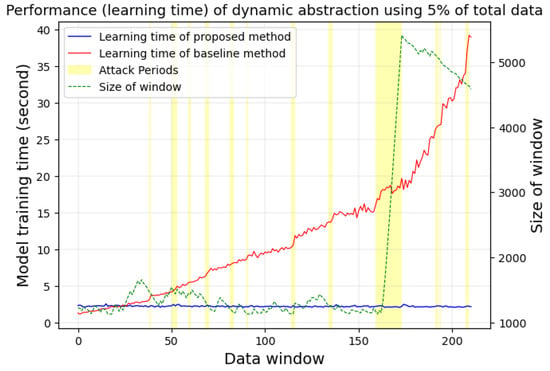
Figure 8.
Performance (learning time) of dynamic abstraction using 5% of total data.

Figure 9.
Performance (learning time) of dynamic abstraction using 10% of total data.
Additionally, the green dotted line graphs in Figure 6 and Figure 8 represent the normalized average entropy values of the newly observed data windows, and the green horizontal dotted lines indicate the average entropy over the entire section. In Figure 7 and Figure 9, the green dotted lines correspond to the size of the window used for dynamic data abstraction at that point in time.
4.3.1. Baseline Method
The baseline method utilizes all observed data up to the current moment for model training. Aiming to achieve the highest possible anomaly detection accuracy, it leverages all available data, investing significant training time to develop an optimal model. The designed experiment integrates newly input data into the model training process for model updating due to the continuous input of data at specific intervals. This approach differs from the one proposed in our paper as the baseline method uses a large volume of training data to simultaneously learn various data patterns. While this strategy is expected to satisfy detection performance across different patterns, it could result in ambiguous decision boundaries for classification. Additionally, the vast amount of training data may pose additional challenges in quickly learning and classifying new changing patterns. This baseline method, operating in a typical AI pipeline, is compared with the proposed methodology in terms of data volume and dwell time for learning and classifying new data patterns.
4.3.2. Performance of Anomaly Detection Using Dynamic Data Abstraction
In Figure 6 and Figure 7, the accuracy of the proposed method, indicated by the blue line, is generally similar to that of the baseline method, shown by the red line. This means that the proposed method demonstrates comparable anomaly detection performance to the baseline method despite using a much smaller scale of training data for learning. Across all sections in Figure 6, the average accuracy of the proposed method was 0.9545, while the average accuracy of the baseline method was 0.9601. In all sections of Figure 7, the average accuracy of the proposed method was 0.9651, and the average accuracy of the baseline method was 0.9613. Table 1 displays the average performance of anomaly detection using dynamic data abstraction and the average training time of the detection model, as illustrated in Figure 6, Figure 7, Figure 8 and Figure 9. In Table 1, ‘average accuracy (attack periods)’ refers to the mean accuracy during the actual anomaly (attack) periods marked in yellow across the entire dataset.

Looking at the sections of Figure 6’s window 160-173 and Figure 7’s window 80-88, where the attack of the new pattern persisted, it can be seen that the proposed method learns the new pattern data more quickly than the baseline method. Observing the data entropy for each window period, marked by green dotted lines, it is evident that the entropy of these attack sections differs significantly from other attack periods, confirming that these attacks are of a new pattern. The starting point of these attack sections is where the patterned attacks begin, and at this point, the accuracy of the proposed method is higher than that of the baseline method, which has learned more data. Additionally, immediately after the long-term attack ends, the proposed method is seen to improve accuracy more rapidly than the baseline method. This suggests that when the pattern of observed data changes, the proposed dynamic data abstraction approach enables the model to learn much faster and more effectively than simply using more data.
Figure 8 and Figure 9 represent the time taken for model learning and updating during each new data window period for the proposed method. The proposed method incurs additional computation by calculating the entropy of newly observed data and adjusting the window size accordingly. As a result, training with a dataset of the same size consumes more computation and time than the baseline model. However, as the observed data gradually accumulate, the computational efficiency shows a significant difference. The proposed method performed semi-real-time online learning while continuously updating a small-scale training dataset. In this process, since the proposed method maintained a constant size for the training dataset, it was able to learn new attack patterns quickly, even as new data accumulated, maintaining semi-real-time learning. This demonstrates a significant efficiency from the perspective of model training time compared to the baseline method, which used a large amount of data to learn new patterns. Furthermore, even in sections where long-term attacks occurred, the proposed method maintained training efficiency while radically increasing the window size to effectively learn the patterns of long-term attacks. This implies that the proposed approach can quickly learn various distribution attack patterns without changes in efficiency.
5. Discussion
The results of the experiments conducted in this paper demonstrate the efficacy of the proposed dynamic data abstraction technique for real-time response to a diverse range of attack patterns and types targeting ICSs. With average accuracies of 0.9545 and 0.9601, as shown in Figure 6 and Figure 7, the method proves effective in real-time countermeasures against various attacks on ICSs. Additionally, the proposed approach exhibits similar accuracy to anomaly detection models trained with large datasets while consuming significantly less computation and training time, as indicated in Figure 8 and Figure 9. These findings can be particularly useful in responding to novel types of APT attacks exploiting zero-day vulnerabilities and can be effectively applied in environments with limited resources or extensive attack vectors, such as those characteristic of ICS networks. Furthermore, our experimental results reveal that the proposed method not only learns long-term attack patterns effectively but also demonstrates resilience to data poisoning attacks caused by a large volume of noise data. The proposed model affirms its ability to maintain detection accuracy without increasing resource consumption, proving the feasibility of real-time anomaly detection across various settings.
6. Conclusions
Our research has presented a robust anomaly detection framework that leverages dynamic data abstraction to address contemporary challenges in ICS security. The experimental results affirm that our proposed method can achieve high accuracy with a fraction of the training data required by traditional approaches. Notably, it can effectively identify and learn from new attack patterns while preserving efficiency, offering a strategic advantage in real-world applications where rapid detection and minimal computational overhead are critical. The core approach of the methodology proposed in this paper fundamentally improves the efficiency of the model by filtering out data that hinder the model’s performance as learning elements from real-time observed data. However, during our experiments, we identified two main limitations. The first limitation is that, in cases where extreme label distributions are observed in real-time input data, appropriate post-processing is required. Using training data with extreme label distributions in the continuous retraining and updating process of anomaly detection can lead to model bias, making it difficult to accurately assess the model’s performance at that point. Therefore, research into appropriate post-processing methods that can mitigate the extreme imbalance of labels during the data abstraction process in real time is necessary. The second limitation is that the proposed method abstracts the input data into a smaller dataset to perform this data filtering quickly and effectively. However, this approach may exhibit lower accuracy for certain types of new patterns, indicating that the proposed methodology has difficulties in learning some complex new data patterns. To mitigate this limitation, it may be necessary to increase the size of the abstracted dataset when required. This necessitates research that dynamically considers various criteria, such as data pattern types, learning accuracy, and training time, and finds the optimal point in their trade-off process. In our subsequent research, we aim to expand upon the methodology proposed in this paper and study data abstraction techniques that simultaneously consider various metrics.
Author Contributions
Conceptualization, J.C.; methodology, J.C. and S.G.; software, S.G.; validation, J.C. and S.G.; formal analysis, J.C. and S.G.; investigation, J.C. and S.G.; resources, J.C. and S.G.; data curation, S.G.; writing—original draft preparation, S.G.; writing—review and editing, J.C. and S.G.; visualization, S.G.; supervision, J.C.; project administration, J.C.; funding acquisition, J.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Ministry of Trade, Industry & Energy (MOTIE, Republic of Korea) under grant number 20018637 (Development of Industrial Technology for Electronic Components: Research on constructing a data tree for the federated learning of distributed industrial data).
Data Availability Statement
The data presented in this study are openly available in [SWaT dataset (https://itrust.sutd.edu.sg/itrust-labs_datasets/dataset_info/)] at [https://doi.org/10.1007/978-3-319-71368-7_8], ref. [14] (accessed on 1 June 2023).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| APT | Advanced Persistent Threats |
| ICS | Industrial Control System |
| IIoT | Industrial Internet of Things |
| IT | Information Technology |
| LSTM | Long Short-Term Memory |
| OT | Operational Technology |
| PDIG | Process Dependency and Impact Graph |
| PLC | Programmable Logic Controller |
| SCADA | Supervisory Control and Data Acquisition |
| VPN | Virtual Private Network |
References
- Stouffer, K.; Lightman, S.; Pillitteri, V.; Abrams, M.; Hahn, A. Guide to Industrial Control Systems (ICS) Security. NIST Special Publication, 2011; Volume 800, p. 16. [Google Scholar]
- Myers, D.; Suriadi, S.; Radke, K.; Foo, E. Anomaly detection for industrial control systems using process mining. Comput. Secur. 2018, 78, 103–125. [Google Scholar] [CrossRef]
- Chitranshi Jaiswal. Industrial Control Systems Energy Power Market. 2022. Available online: https://www.marketresearchfuture.com/amp/reports/industrial-control-systems-energy-power-market-1706 (accessed on 1 December 2023).
- Ghobakhloo, M. Industry 4.0, digitization, and opportunities for sustainability. J. Clean. Prod. 2020, 252, 119869. [Google Scholar] [CrossRef]
- Stefanidis, K.; Voyiatzis, A.G. An HMM-based anomaly detection approach for SCADA systems. In Information Security Theory and Practice: 10th IFIP WG 11.2 International Conference, WISTP 2016, Heraklion, Crete, Greece, 26–27 September 2016, Proceedings 10; Springer International Publishing: Heraklion, Crete, Greece, 2016; pp. 85–99. [Google Scholar]
- Langner, R. Stuxnet: Dissecting a cyberwarfare weapon. IEEE Secur. Priv. 2011, 9, 49–51. [Google Scholar] [CrossRef]
- Alert, D. Cyber-Attack against Ukrainian Critical Infrastructure; Tech. Rep. ICS Alert (IR-ALERT-H-16-056-01); Cybersecurity Infrastructure Security Agency: Washington, DC, USA, 2016. [Google Scholar]
- Hobbs, A. The Colonial Pipeline Hack: Exposing Vulnerabilities in US Cybersecurity; SAGE Publications; SAGE Business Cases Originals: Thousand Oaks, CA, USA, 2021. [Google Scholar]
- Khan, I.A.; Pi, D.; Khan, Z.U.; Hussain, Y.; Nawaz, A. HML-IDS: A hybrid-multilevel anomaly prediction approach for intrusion detection in SCADA systems. IEEE Access 2019, 7, 89507–89521. [Google Scholar] [CrossRef]
- Bernieri, G.; Conti, M.; Turrin, F. Evaluation of machine learning algorithms for anomaly detection in industrial networks. In Proceedings of the 2019 IEEE International Symposium on Measurements & Networking (M&N), Catania, Italy, 8–10 July 2019; IEEE: Manhattan, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Ahmed, C.M.; Gauthama Raman, M.R.; Mathur, A.P. Challenges in machine learning based approaches for real-time anomaly detection in industrial control systems. In Proceedings of the 6th ACM on Cyber-Physical System Security Workshop, Taipei, Taiwan, 6 October 2020; pp. 23–29. [Google Scholar]
- Yadav, G.; Paul, K. Architecture and security of SCADA systems: A review. Int. J. Crit. Infrastruct. Prot. 2021, 34, 100433. [Google Scholar] [CrossRef]
- Akpinar, K.O.; Ozcelik, I. Analysis of machine learning methods in EtherCAT-based anomaly detection. IEEE Access 2019, 7, 184365–184374. [Google Scholar] [CrossRef]
- Goh, J.; Adepu, S.; Junejo, K.N.; Mathur, A. A dataset to support research in the design of secure water treatment systems. In Critical Information Infrastructures Security: 11th International Conference, CRITIS 2016, Paris, France, 10–12 October 2016; Revised Selected Papers 11; Springer International Publishing: New York, NY, USA, 2017; pp. 88–99. [Google Scholar]
- Yang, T.; Hu, Y.; Li, Y.; Hu, W.; Pan, Q. A standardized ics network data processing flow with generative model in anomaly detection. IEEE Access 2019, 8, 4255–4264. [Google Scholar] [CrossRef]
- Sapkota, S.; Mehdy, A.N.; Reese, S.; Mehrpouyan, H. Falcon: Framework for anomaly detection in industrial control systems. Electronics 2020, 9, 1192. [Google Scholar] [CrossRef]
- Javed, S.H.; Ahmad, M.B.; Asif, M.; Almotiri, S.H.; Masood, K.; Ghamdi, M.A.A. An intelligent system to detect advanced persistent threats in industrial internet of things (I-IoT). Electronics 2022, 11, 742. [Google Scholar] [CrossRef]
- Filkins, B.; Wylie, D.; Dely, A.J. Sans 2019 State of OT/ICS Cybersecurity Survey; SANS™ Institute: Rockville, MD, USA, 2019. [Google Scholar]
- Mokhtari, S.; Abbaspour, A.; Yen, K.K.; Sargolzaei, A. A machine learning approach for anomaly detection in industrial control systems based on measurement data. Electronics 2021, 10, 407. [Google Scholar] [CrossRef]
- Kulkarni, A.; Pino, Y.; French, M.; Mohsenin, T. Real-time anomaly detection framework for many-core router through machine-learning techniques. ACM J. Emerg. Technol. Comput. Syst. (JETC) 2016, 13, 1–22. [Google Scholar] [CrossRef]
- Asghar, M.R.; Hu, Q.; Zeadally, S. Cybersecurity in industrial control systems: Issues, technologies, and challenges. Comput. Netw. 2019, 165, 106946. [Google Scholar] [CrossRef]
- Cho, J.; Choi, K.; Shon, T.; Moon, J. A network data abstraction method for data set verification. In Secure and Trust Computing, Data Management and Applications: 8th FIRA International Conference, STA 2011, Loutraki, Greece, 28–30 June 2011; Proceedings 8; Springer: New York, NY, USA, 2011. [Google Scholar]
- Bhamare, D.; Zolanvari, M.; Erbad, A.; Jain, R.; Khan, K.; Meskin, N. Cybersecurity for industrial control systems: A survey. Comput. Secur. 2020, 89, 101677. [Google Scholar] [CrossRef]
- Hao, W.; Yang, T.; Yang, Q. Hybrid statistical-machine learning for real-time anomaly detection in industrial cyber-physical systems. IEEE Trans. Autom. Sci. Eng. 2023, 20, 32–46. [Google Scholar] [CrossRef]
- Ike, M.; Phan, K.; Sadoski, K.; Valme, R.; Lee, W. SCAPHY: Detecting Modern ICS Attacks by Correlating Behaviors in SCADA and PHYsical. In Proceedings of the 2023 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21–25 May 2023; IEEE: Manhattan, NY, USA, 2023; pp. 20–37. [Google Scholar]
- Gauthama Raman, M.R.; Mathur, A.P. AICrit: A unified framework for real-time anomaly detection in water treatment plants. J. Inf. Secur. Appl. 2022, 64, 103046. [Google Scholar]
- Gómez, Á.L.P.; Maimó, L.F.; Celdrán, A.H.; Clemente, F.J.G.; Sarmiento, C.C.; Masa, C.J.D.C.; Nistal, R.M. On the generation of anomaly detection datasets in industrial control systems. IEEE Access 2019, 7, 177460–177473. [Google Scholar] [CrossRef]
- Zhang, J.; Jiang, Y.; Li, X.; Luo, H.; Yin, S.; Kaynak, O. Remaining useful life prediction of lithium-ion battery with adaptive noise estimation and capacity regeneration detection. IEEE/ASME Trans. Mechatron. 2022, 28, 632–643. [Google Scholar] [CrossRef]
- Zhang, J.; Tian, J.; Alcaide, A.M.; Leon, J.I.; Vazquez, S.; Franquelo, L.G.; Luo, H.; Yin, S. Lifetime Extension Approach Based on Levenberg-Marquardt Neural Network and Power Routing of DC-DC Converters. IEEE Trans. Power Electron. 2023, 38, 10280–10291. [Google Scholar] [CrossRef]
- Turrin, F.; Erba, A.; Tippenhauer, N.O.; Conti, M. A statistical analysis framework for ICS process datasets. In Proceedings of the 2020 Joint Workshop on CPS& IoT Security and Privacy, Virtual Event, 9 November 2020; pp. 25–30. [Google Scholar]
- Cho, J.; Gong, S.; Choi, K. A Study on High-Speed Outlier Detection Method of Network Abnormal Behavior Data Using Heterogeneous Multiple Classifiers. Appl. Sci. 2022, 12, 1011. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).