Abstract
To solve the problem of complex network models with a large number of redundant parameters, a pruning algorithm combined with an attention mechanism is proposed. Firstly, the basic training is performed once, and the network model is then re-trained with the attention mechanism for the baseline. The obtained model is pruned based on channel correlation, and finally a simplified model is obtained via continuous cyclic iteration while the accuracy rate is kept as close as possible to that of the baseline model. The algorithm was experimentally validated on ResNet based on different datasets, and the results showed that the algorithm provided strong adaptability to different datasets and different network structures. For the CIFAR-100 dataset, ResNet50 was pruned to reduce the amount of model parameters by 80.3% and the amount of computation by 69.4%, while maintaining accuracy. For the ImageNet dataset, the ResNet50 parameter volume was compressed by 2.49 times and the computational volume was compressed by 3.01 times. The ResNet101 parameter volume was reduced by 61.2%, and the computational volume was reduced by 68.5%. Compared with the traditional fixed threshold, the model achieves better results in terms of detection accuracy, compression effect, and inference speed.
1. Introduction
Deep learning has been widely used in many fields, such as image classification, target detection, and semantic segmentation. In order to achieve excellent performance, researchers have proposed VggNet [1], GoogleNet [2], ResNet [3], DenseNet [4], and other backbone architecture networks. More recently, attention mechanism have been introduced to further improve network accuracy. Jiang et al. [5] introduced a convolutional attention mechanism in a residual network to reduce the redundant mapping of remote sensing scene features at a reasonable extra time cost. Zheng et al. [6] added channel and spatial modules based on the self-attention mechanism to the backbone network and the enhanced feature extraction network of pyramid scene parsing, respectively, to extract more important feature detail information from images. However, the large computational resource requirements and high power consumption of deep learning networks limit their potential applications. In order to reduce memory consumption and speed up inference time, researchers have proposed many compression strategies, and these can be divided into weight quantization [7], knowledge distillation [8], low-rank decomposition [9], and network pruning [10]. Pruning as a method to accelerate larger pre-trained models is a common way to compress networks. Wang et al. [11], in their work on network structure, found that pruning the least important filters in the layers with the most structural redundancy enabled them to identify the structural redundancy of the CNN and prune the filters in the selected layers with the most redundancy. Shao et al. [12] proposed a novel filter pruning method that combines convolutional filters and feature map information for convolutional neural network compression, i.e., network pruning using clustered similarity and large eigenvalues. Kim [13] proposed a new technique to shrink the previously used style transfer network to eliminate redundancy in terms of memory consumption and computational cost.
The aforementioned methods have resulted in some progress for neural network model streamlining and other related applications, but the degree of model compression and the degree of accelerated computation are not sufficient and are not necessarily suitable for deployment in mobile terminal devices. Because of this, a cyclic pruning compression algorithm combined with an attention mechanism is proposed.
The remainder of this paper is organized as follows. A basic introduction to the attention mechanism and pruning algorithm is presented in Section 2. A detailed description of the steps and details of the algorithms are then presented in Section 3. Section 4 gives the experimental results and analyzes them. Lastly, the paper is summarized in Section 5.
2. Related Work
2.1. Attention Mechanism
The proposed attention mechanism is a structure based on the human observation pattern. When the human eye observes a picture, it will first quickly scan the whole picture and then focus on certain key regions of the picture so that the brain can focus more on that region and give it particular attention to obtain more effective information, and then integrate this information to draw conclusions. The attention mechanism allows the neural network to analyze and learn the relationships between global and local information to obtain important target regions in the same way the human eye acquires images, and then put more weight on these regions to obtain important image features while ignoring irrelevant image features and using limited resources to select the more critical information for processing the current task, greatly improving the processing efficiency and accuracy. In the field of computer vision, research has been carried out on attention mechanisms such as channel attention mechanisms, spatial attention mechanisms, and hybrid attention mechanisms. Figure 1 is a diagram of the generic structure of an attention mechanism. Different heights in the figure represent different importance. The different colors are used for easy differentiation and have no special meaning.
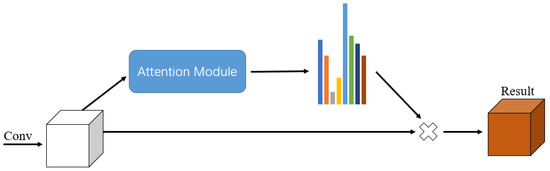
Figure 1.
Generalized structure of an attention mechanism.
The improvement of deep neural network (DNN) classification performance is effectively achieved through the utilization of an attention mechanism by enhancing feature map representations with crucial information while suppressing irrelevant interference [14,15,16]. Attention mechanisms have found widespread use in several modern applications, including (but not limited to) neural machine translation [17], image captioning [18], object detection [19], and generative modeling [20]. SENet [21] introduced a lightweight gating mechanism to exploit channel relationships for improved image classification performance. This mechanism dynamically re-weights the channels in feature maps to better capture discriminative features for classification. Compared with traditional convolutional neural networks, SENet’s gating mechanism is more adaptable to datasets and achieves higher classification accuracy. This approach has been widely used in various computer vision tasks, including image classification, object detection, and semantic segmentation. It is an attention mechanism that operates along the channel dimension, but it overlooks the significance of the spatial dimension. The SGE module [22] is designed to improve the semantic expression capability of each feature group while suppressing noise and interference. The described module essentially contains spatial attention, but it unfortunately lacks full integration of this particular attention type. Convolutional block attention modules (CBAMs) [23] and bottleneck attention modules (BAMs) [24] take advantage of both spatial and channel attention in their design, providing empirical evidence that combining these two forms of attention yields better results than can be achieved using only one type. Zhang [25] proposed a sparse layer activation-based greedy strategy.
2.2. Structured Pruning
Pruning methods can generally be classified into two categories, namely unstructured pruning and structured pruning. Unstructured pruning refers to the zeroing of some parameters in the convolutional kernel according to a threshold and thereby obtaining a sparse convolutional kernel. Prior research [26,27,28,29] has focused primarily on weight pruning, which leads to unstructured sparsity in the pruned model. Such methods can obtain theoretically high compression ratios, but such theoretical compression ratios are difficult to achieve in practical compression. Due to irregular memory access [30], runtime acceleration is difficult to achieve unless specialized hardware and libraries are used.
The initial breakthroughs in structured pruning, introduced by [30,31], addressed this issue by removing entire filters or channels and thereby producing a non-sparse compressed model [28,30,32]. It should be noted that there is a correlation between channel pruning and filter pruning, as the removal of a channel from the current layer would result in the corresponding filter being eliminated from the upper layer [31]. The primary focus of this paper is channel pruning, a technique aimed at model compression. It achieves this by eliminating a specific number of channels and their associated filters. The approach proposed in [33] utilizes the -norm as a pruning criterion whereby the filters’ -norm is utilized in the pruning process. In network thinning [34], a batch normalization (BN) layer is incorporated to rescale different channels. The unimportant channels are then identified for pruning based on their relatively small scaling factors. Certain studies recommend pruning channels with minimal impact on feature reconstruction error between the original and pruned models. In [35], a greedy search-based method is proposed to minimize reconstruction error, while [31] preserves representative channels by solving a lasso regression problem related to reconstruction error. Both approaches only consider the local statistics of two adjacent layers, meaning that they prune one layer to minimize reconstruction error in the next layer. To account for error propagation throughout the network, NISP [36] proposes utilizing the global importance score propagated from the second-to-last layer to minimize reconstruction error prior to classification. It should be emphasized that a reliable channel pruning metric must take into account not only the global significance of channels, but also the correlation amongst different channels [21,36].
2.3. Attention-Based Pruning
Attention mechanisms have been introduced in recent years to enhance the performance of model pruning. As an example, [37] proposes utilizing the SENet model to assess channel importance, identifying and removing redundant channels with minimal significance. Nonetheless, the inherent limitations of SENet produce scalar values that incompletely represent channel significance and are inadequate for improving pruning performance. PCAS [38] devised a novel attention model to evaluate channel importance based on attention statistics. The module in PCAS is essentially a channel attention module that comprises two fully connected layers. However, this structure imposes extra complexity and overhead. Furthermore, the prediction of channel attention can be affected by the side effects that arise from dimensionality reduction operations [39,40]. To address these issues, a combination of spatial and channel attention modules is employed. Through an efficient structural design, this approach showcases superior performance during the pruning process.
3. Algorithm
Within this section, we will first provide an overview of the channel correlation pruning based on the channel–spatial attention mechanism (CCPCSA). Subsequently, we will present the structural components of the BAM attention module. Lastly, we will propose a CCPCSA algorithm that accomplishes network model pruning in the context of BAM.
An overview of our CCPCSA approach is illustrated in Figure 2. The BAM module, which captures channel importance, is integrated into the original network, and the resultant network is then trained. Subsequently, based on the relevance of the channels, the final network model is obtained by performing channel pruning on top of this trained network.
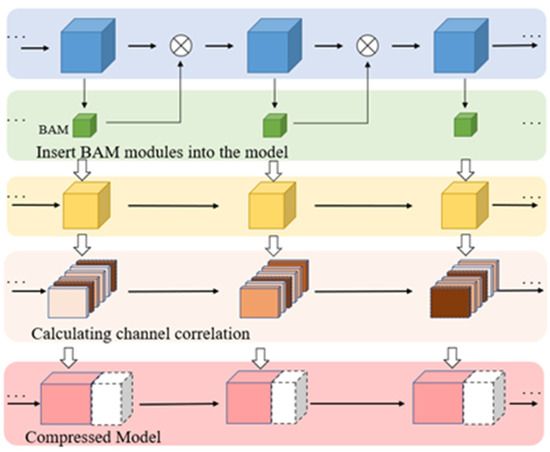
Figure 2.
Overview of CCPCSA method.
3.1. Attention Mechanism
In accordance with the details put forward in reference [24], Figure 3 depicts the complete and comprehensive structural arrangement of our BAM (spatial and channel attention) module. The figure provides insights into the architecture of the module which could prove useful in understanding its functioning and benefits. Indeed, if we solely employ spatial attention, the channel dimension information will be disregarded because it treats features in distinct channels equally. Similarly, if we solely utilize channel attention, the information within the channel will also be overlooked. Hence, we believe that better performance can be achieved by integrating the spatial and channel attention modules into a unified module.

Figure 3.
Schematic diagram of clustering.
For a given input feature map BAM infers a three-dimensional attention map . C represents the number of channels in the feature graph, H is the height of the feature graph, and W is the width of the feature graph. The 3D attention map is multiplied element by element with the input feature map and then added to the original input feature map to obtain the final feature map . The extracted feature map is calculated using Equation (1):
where ⊗ denotes element-by-element multiplication. To calculate the channel attention and the spatial attention in two separate branches, the attention map is calculated using Equation (2):
where is the Sigmoid activation function, and attention is mapped to before the output of both channels.
Each channel of the feature map is aggregated in the channel branch using inter-channel relationships, global average pooling is performed on the feature map , and a channel vector is generated at . This vector encodes global information in each channel. To estimate the cross-channel attention from the channel vector, a multilayer perceptron MLP is used. To save parameter overhead, the hidden activation size is set to , where r is the compression ratio. For the sake of description, instead of using the compressed result directly, we use the compression ratio. After the MLP, a batch normalization (BN) layer is used to scale the spatial branching output. The channel attention is calculated using Equation (3):
where denotes batch regularized, and , , , , and denote input features.
Spatial branching produces spatial attention maps to emphasize or suppress features in different spatial locations. We use inflated convolution to expand the receptive field to make effective use of global information. Inflated convolution helps to construct a more efficient spatial feature map than standard convolution. The features are projected into the reduced dimension , and the feature map is integrated and compressed across channel dimensions using convolution. The same reduction rate used for the channel attention is used (). After normalization, convolution with two expansions is used to efficiently utilize contextual information. Finally, the feature map is reduced again to the spatial attention map using convolution. Batch normalization is performed at the end of the spatial channel using BN. The spatial attention is calculated using Equation (4):
where denotes convolution, BN denotes batch normalization, and the superscript denotes the size of the convolution kernel. Two convolutions are used to narrow the channels and two convolutions are used to aggregate contextual information with larger sensory fields. The main purpose of introducing this attention mechanism into the network is to reweight the different features to eliminate the influence of background, as well as other factors, as much as possible and to focus more on the extraction of effective features.
3.2. Pruning Algorithm Based on Channel Correlation
Filter pruning is primarily a data-driven technique. When the importance of a filter is solely determined by the feature mappings it produces, it can render the importance scale unstable and vulnerable to minor perturbations in the input data. Conversely, when importance is evaluated based on the information present in multiple feature maps, it has the potential to minimize interference from input data variations, leading to more dependable and robust importance rankings, provided that it is implemented accurately. Cross-channel strategies have an inherent advantage in terms of facilitating improved modeling and the capture of correlations between different channels. This is due to the fact that such strategies enable more precise modeling, and thereby enable the more accurate identification of inter-channel correlations. In the context of compressing models, correlations identified through cross-channel strategies are viewed as redundancies at the architectural level and serve as the target of filter pruning techniques. This approach aims to eliminate unnecessary filters while ensuring that the model remains effective and accurate. Therefore, by adopting a channel-to-channel strategy, it becomes possible to implement more aggressive pruning techniques while still achieving high levels of accuracy. Building on this insight, we propose to investigate the significance of filters from an inter-channel perspective [41]. Our primary concept is to leverage channel correlations as a means of determining the importance of each feature map (and its corresponding filter). A particular feature map exhibits substantial linear interdependence with feature maps from different channels, and this implies that the content it carries is already extensively encoded in those other feature maps. Thus, despite removing the correlated filter, valuable information and knowledge regarding the representation of highly correlated feature maps can still be preserved and effectively reconstructed by other filters through approximation during the fine-tuning process. This suggests that filters producing highly correlated feature maps may have greater “interchangeability” and lower importance. Consequently, it is reasonable to remove filters associated with high correlation feature map channels while maintaining model capacity.
To extract the linear dependence information of each feature map within the 3D tensor feature atlas generated from a single layer, a methodology based on linear algebra is proposed. This approach addresses the challenge of analyzing the large and complex datasets often encountered in deep learning applications. Specifically, assuming that the output feature atlas of the layer is , we first transform the matrix into , where the row vector is vectorized . The h and w are the dimensions of the feature map. In this case, the linear correlation of each vectorized feature map can be measured by existing matrix analysis tools as a row in the matrixed whole set of feature maps . The most straightforward solution is to use the rank to determine the correlation of , since the rank mathematically represents the maximum number of linearly independent rows/columns in the matrix. For example, one can remove a row from a matrix and calculate its rank change, and then determine the impact and importance of the removed row—the smaller the rank change, the higher the relevance of the matrix of the removed row.
However, within the background of filter pruning, we believe that the change in the nuclear norm of the whole set of feature maps is a better indicator for quantifying the relevance of each feature map. This is because the nuclear norm, i.e., the -norm of the matrix singular values, can reveal more about the effect of deleting rows on the matrix, whereas the rank, i.e., the -norm of the singular values, cannot reflect these changes.
For layer of the output feature map , the channel correlation () of one of the channels of the feature map is defined and calculated using Equation (5):
where is the matrixed , is the nuclear norm, is the Hadamard product, and is the row mask matrix whose entries in the row are zero and whose other entries are one.
Equation (5) defines the channel correlation measurement for a single feature map. However, practical filter pruning targets the removal of multiple filters, requiring the computation of correlations across combinations of feature maps. For filter pruning, this entails evaluating the change in the nuclear norm of in the original rows following the removal of the m rows . One solution is to calculate the variation in , the number of kernel parameters, for all possible m row removal options and select the option with the smallest variation. However, this approach may be computationally expensive and challenging to manage for large values.
To effectively address this computational challenge, our proposal entails leveraging the inter-feature map correlation as an approximation for the correlation exhibited by its amalgamation. This strategy seeks to mitigate the computation burden associated with analyzing the combined set of features. To identify the smallest linearly independent rows in the matrix , we adopt an iterative approach that involves removing a single row () from and calculating the resulting change in the nuclear norm between the reduced matrix () and the original row matrix (). This process is repeated until independent rows have been determined. Among the set of computed changes in , we select the smallest change and subsequently remove the rows () from that contributed most significantly to this change. The chosen set of vectorized feature maps () were deemed to possess higher correlations with other feature maps. Consequently, the corresponding filters () were identified as being less important and subjected to pruning. Overall, the utilization of individual correlation-based measures can often yield a highly accurate approximation of the combined correlation arising from multiple feature maps.
This approximation method requires less computational complexity while still achieving excellent filter pruning performance.
For layer of the output feature map , the channel correlation of the combined feature map , where is in the first channel, is defined and approximated using in Equation (6):
where is a multi-row mask matrix in which the row is zero and all the other rows are one.
Given that our proposed filter pruning method based on channel correlation property is a data-driven approach, it should be carefully ensured and checked for its reliability using different input data distributions. To accomplish this, we conducted an empirical assessment of the channel correlation across multiple input images, and consistently observed a high degree of stability in the average channel correlation for each feature map within each batch of samples that we processed. Consequently, we computed the average channel correlation for small batches of image samples and employed this value to estimate the channel correlation of all input data.
3.3. Overall Flow of the Algorithm
The attention mechanism can explicitly describe the importance of relationships between channels in the same layer and continuously adjust the parameters of the fully connected layer during back propagation [23,42]. By inserting the attention module, the network can show a tendency to gradually enhance or suppress some channels. Then, based on channel similarity, channels with high similarity are continuously filtered out while maintaining high accuracy, and these deleted channels are removed for restorative training. The Figure 4 shows the pruning flow chart.
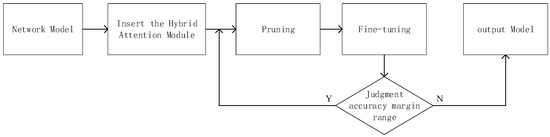
Figure 4.
Flow chart of the pruning process guided by the hybrid attention mechanism.
The Algorithm 1 flow is shown below.
| Algorithm 1. CCPCSA Algorithm | |
| Input: | |
| M: | The initial network model |
| D: | The training dataset |
| L: | The number of the layers in M |
| m: | The number of channel groups removed per epoch |
| Output: | |
| M′: | The pruned network model |
| Steps: | |
| 1: | Obtain ACC by training the model M |
| 2: | Obtain a model named M’ by training model M within BAM modules |
| 3: | For each batch |
| 4: | Train M’ with d |
| 5: | For each layer |
| 6: | For each channel |
| 7: | Calculate the |
| 8: | Sort all the and prune the smaller rows of channels |
| 9: | Fine-tune M’ and obtain the Acc’ |
| 10: | If Acc-Acc’ < 0.5%, then go back to Step 3 |
| 11: | Return M’ |
4. Experiment
To validate the efficacy of our model pruning algorithm, we conducted experiments on the ResNet model utilizing the PyTorch framework. The experimental setup was based on a Windows 10 system equipped with an Intel(R) Core(TM) i5-10300H CPU @ 2.50 GHz and a NVIDIA GeForce GTX 1650 graphics card, and it was run in a virtual environment using PyCharm 2020.1.2 (Professional Edition) with PyTorch version 1.8.0, TorchVision version 0.9.0, and CUDA version 10.2.89.
We conducted image classification experiments to evaluate the feasibility of the method. In the ResNet network, the attention module was placed on the convolutional output of the ResBlock. Experiments were performed on CIFAR-100 and ImageNet datasets and compared with other representative pruning schemes.
FLOPs stands for floating point operations. The mathematical unit of FLOPs(M) is million and the mathematical unit of GFLOPs is billion. The “↑” represents an increase or raise relative to the original model, while the “↓” represents a decrease or lower. OTO* indicates the best performing result in the cited paper, which is identified by *. Based on these results, it can be concluded that CCPCSA shows excellent performance with very little loss of inference accuracy. Based on the results presented in Table 1 and Table 2, it can be concluded that the CCPCSA method outperformed the other advanced pruning methods comprehensively on both datasets, indicating its effectiveness. The CCPCSA method is capable of achieving high accuracy, particularly when the pruning ratio is low. This finding demonstrates the effectiveness of the proposed channel pruning approach in enhancing model accuracy while reducing model complexity. The results obtained by compressing the model as much as possible are shown in Table 1 and Table 2. The results show that a larger network pruning ratio leads to a partial loss of accuracy. On both the CIFAR-100 and ImageNet datasets, the accuracy of the CCPCSA algorithm was almost the same as the original accuracy, and the compression effect results were much better than those of other methods. In particular, the proposed CCPCSA pruning algorithm can significantly speed up the inference computation because of the reduced parameters and computational effort. All these observations clearly show that pruning channels under the guidance of the attention module is beneficial.

Table 1.
Comparison of different pruning algorithms for ResNet50 on CIFAR-100.
Table 2.
Comparison of different pruning algorithms for different ResNet backbones on ImageNet.
5. Conclusions
The proposed method, called CCPCSA, is a new channel pruning approach that utilizes a channel–spatial attention mechanism to compress network models for use in edge computing. The core idea of CCPCSA is to use the attention statistics provided by a new attention module called BAM and prune the network based on channel correlation information to achieve model efficiency and compression. The BAM module combines spatial attention and channel attention as a whole, which not only enhances the representation capability of the network model, but also reveals the impact of the presence of channels on the inference performance. The pruning operation is then completed by removing channels with high similarity based on inter-channel correlation. The comprehensive experiments we conducted on two benchmark datasets validated the superior effectiveness of the CCPCSA approach compared with other state-of-the-art solutions. In future work, we plan to combine this approach with other model compression strategies (e.g., quantization) and other edge intelligence techniques (e.g., edge cloud collaboration) to further reduce model size and inference costs.
Author Contributions
Methodology, M.Z. and J.T.; funding acquisition, M.Z. and J.T.; supervision, M.Z. and J.T.; project administration, M.Z. and J.T.; writing—original draft preparation, T.L.; writing—review and editing, M.Z. and J.T.; validation, T.L.; formal analysis, S.-L.P.; investigation, S.-L.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the New Generation Information Technology Innovation Project 2021; Intelligent loading system based on artificial intelligence, grant number 2021ITA05050.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data in this study are publicly available. The data were obtained from the Internet, but access is required due to privacy or ethical concerns. Access can be obtained by contacting the authors.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Comput. Sci. 2014. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. IEEE Comput. Soc. 2014. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Laurens, V.; Weinberger, K. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Jiang, Z.F.; He, T.; Shi, Y.L.; Long, X.; Yang, S. Remote sensing image classification based on convolutional block attention module and deep residual network. Laser J. 2022, 43, 76–81. [Google Scholar] [CrossRef]
- Zheng, Q.M.; Xu, L.K.; Wang, F.H.; Lin, C. Pyramid scene parsing network based on improved self-attention mechanism. Comput. Eng. 2022, 1–9. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. In Proceedings of the ICLR, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. Comput. Sci. 2015, 14, 38–39. [Google Scholar]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Speeding up Convolutional Neural Networks with Low Rank Expansions. arXiv 2014, arXiv:1405.3866. [Google Scholar]
- Setiono, R.; Liu, H. Neural-network feature selector. IEEE Trans. Neural Netw. 1997, 8, 654–662. [Google Scholar] [CrossRef]
- Wang, Z.; Li, C.; Wang, X. Convolutional neural network pruning with structural redundancy reduction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14913–14922. [Google Scholar]
- Shao, M.; Dai, J.; Wang, R.; Kuang, J.; Zuo, W. CSHE: Network pruning by using cluster similarity and matrix eigenvalues. Int. J. Mach. Learn. Cybern. 2022, 13, 371–382. [Google Scholar] [CrossRef]
- Kim, M.; Choi, H.-C. Compact Image-Style Transfer: Channel Pruning on the Single Training of a Network. Sensors 2022, 22, 8427. [Google Scholar] [CrossRef]
- Xue, Z.; Yu, X.; Liu, B.; Tan, X.; Wei, X. HResNetAM: Hierarchical Residual Network with Attention Mechanism for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3566–3580. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, L.; Phonevilay, V.; Gu, K.; Xia, R.; Xie, J.; Zhang, Q.; Yang, K. Image super-resolution reconstruction based on feature map attention mechanism. Appl. Intell. 2021, 51, 4367–4380. [Google Scholar] [CrossRef]
- Cai, W.; Zhai, B.; Liu, Y.; Liu, R.; Ning, X. Quadratic Polynomial Guided Fuzzy C-means and Dual Attention Mechanism for Medical Image Segmentation. Displays 2021, 70, 102106. [Google Scholar] [CrossRef]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Liu, M.; Li, L.; Hu, H.; Guan, W.; Tian, J. Image caption generation with dual attention mechanism. Inf. Process. Manag. 2020, 57, 102178. [Google Scholar] [CrossRef]
- Li, W.; Liu, K.; Zhang, L.; Cheng, F. Object detection based on an adaptive attention mechanism. Sci. Rep. 2020, 10, 11307. [Google Scholar] [CrossRef]
- Dollar, O.; Joshi, N.; Beck DA, C.; Pfaendtner, J. Attention-based generative models for de novo molecular design. Chem. Sci. 2021, 12, 8362–8372. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Li, X.; Hu, X.; Yang, J. Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks. arXiv 2019, arXiv:1905.09646. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.-Y.; Kweon, I. Bam: Bottleneck attention module. arXiv 2018, arXiv:180706514. [Google Scholar]
- Zhang, X.; Colbert, I.; Das, S. Learning Low-Precision Structured Subnetworks Using Joint Layerwise Channel Pruning and Uniform Quantization. Appl. Sci. 2022, 12, 7829. [Google Scholar] [CrossRef]
- Zhang, T.; Ye, S.; Zhang, K.; Tang, J.; Wen, W.; Fardad, M.; Wang, Y. A systematic dnn weight pruning framework using alternating direction method of multipliers. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 184–199. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both Weights and Connections for Efficient Neural Networks. In Proceedings of the NIPS 2015, Montreal, QC, Canada, 7–10 December 2015. [Google Scholar]
- Luo, J.H.; Wu, J. An Entropy-based Pruning Method for CNN Compression. arXiv 2017, arXiv:1706.05791. [Google Scholar]
- Xiang, K.; Peng, L.; Yang, H.; Li, M.; Cao, Z.; Jiang, S.; Qu, G. A novel weight pruning strategy for light weight neural net-works with application to the diagnosis of skin disease. Appl. Soft Comput. 2021, 111, 107707. [Google Scholar] [CrossRef]
- Wen, W.; Wu, C.; Wang, Y.; Chen, Y.; Li, H. Learning Structured Sparsity in Deep Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- He, Y.; Zhang, X.; Sun, J. Channel Pruning for Accelerating Very Deep Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Min, C.; Wang, A.; Chen, Y.; Xu, W.; Chen, X. 2PFPCE: Two-Phase Filter Pruning Based on Conditional Entropy. arXiv 2018, arXiv:1809.02220. [Google Scholar]
- Yang, C.; Yang, Z.; Khattak, A.M.; Yang, L.; Zhang, W.; Gao, W.; Wang, M. Structured pruning of convolutional neural networks via l1 regularization. IEEE Access 2019, 7, 106385–106394. [Google Scholar] [CrossRef]
- Zhuang, L.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, G. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Luo, J.H.; Wu, J.; Lin, W. ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yu, R.; Li, A.; Chen, C.-F.; Lai, J.-H.; Morariu, V.; Han, X.; Gao, M.; Lin, Y.; Davis, L. Nisp: Pruning networks using neuron importance score propagation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Song, F.; Wang, Y.; Guo, Y.; Zhu, C. A channel-level pruning strategy for convolutional layers in cnns. In Proceedings of the 2018 International Conference on Network Infrastructure and Digital Content (IC-NIDC), Guiyang, China, 22–24 August 2018. [Google Scholar]
- Yamamoto, K.; Maeno, K. PCAS: Pruning Channels with Attention Statistics for Deep Network Compression. arXiv 2018, arXiv:1806.05382. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global second-order pooling convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Sui, Y.; Yin, M.; Xie, Y.; Phan, H.; Aliari Zonouz, S.; Yuan, B. Chip: Channel independence-based pruning for compact neural networks. Adv. Neural Inf. Process. Syst. 2021, 34, 24604–24616. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. Comput. Sci. 2015, 2048–2057. [Google Scholar] [CrossRef]
- Wang, J.; Jiang, T.; Cui, Z.; Cao, Z. Filter pruning with a feature map entropy importance criterion for convolution neural networks compressing. Neurocomputing 2021, 461, 41–54. [Google Scholar] [CrossRef]
- Hu, Y.; Sun, S.; Li, J.; Wang, X.; Gu, Q. A novel channel pruning method for deep neural network compression. arXiv 2018, arXiv:1805.11394. [Google Scholar]
- Shao, W.; Yu, H.; Zhang, Z.; Xu, H.; Li, Z.; Luo, P. BWCP: Probabilistic Learning-to-Prune Channels for ConvNets via Batch Whitening. arXiv 2021, arXiv:2105.06423. [Google Scholar]
- Wang, Z.; Li, F.; Shi, G.; Xie, X.; Wang, F. Network pruning using sparse learning and genetic algorithm—ScienceDirect. Neurocomputing 2020, 404, 247–256. [Google Scholar] [CrossRef]
- Aflalo, Y.; Noy, A.; Lin, M.; Friedman, I.; Zelnik, L. Knapsack Pruning with Inner Distillation. arXiv 2020, arXiv:2002.08258. [Google Scholar]
- Chen, T.; Ji, B.; Ding, T.; Fang, B.; Wang, G.; Zhu, Z.; Liang, L.; Shi, Y.; Yi, S.; Tu, X. Only Train Once: A One-Shot Neural Network Training and Pruning Framework. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021. [Google Scholar]
- Molchanov, P.; Mallya, A.; Tyree, S.; Frosio, I.; Kautz, J. Importance Estimation for Neural Network Pruning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).