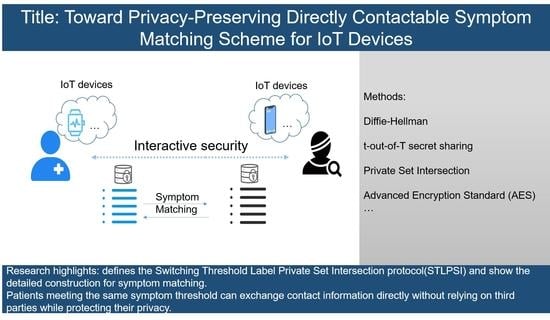
1. Introduction
The increasing prevalence of Internet of Things (IoT) devices has prompted extensive research into mobile medical health [
1,
2,
3]. IoT devices empower patients to monitor their own health status [
4], while medical centers can leverage the devices to analyze and diagnose diseases and then relay the results back to the devices. As a result, IoT devices serve as a vital link between medical centers and patients, facilitating patient-to-patient communication based on symptom similarity, thereby providing mutual encouragement and the opportunity to share treatment experiences. Symptom similarity between different patients is typically determined by the number of identical symptoms in the symptom set. Effective communication between patients who share a certain number of symptoms is pivotal for successful disease treatment.
However, security and privacy issues have become obstacles to matching patients’ symptoms and enabling their communication with each other. The patient’s symptom information is private data, and if it is leaked or used maliciously, it will cause heavy losses to the patient, such as discrimination, property damage, etc. In order to cope with this challenge, Shunrong Jiang et al. [
5] designed two blind signature-based symptom-matching schemes in SDN-based MHSNs, which can achieve coarse-grained symptom matching and fine-grained symptom matching, respectively. Ming Li et al. [
6] proposed a set of privacy-preserving profile-matching schemes for proximity-based mobile social networks. Chengzhe Lai et al. [
7] designed a trust-based privacy-preserving friend-matching scheme in the social Internet of Vehicles. It can prevent the leakage of sensitive information caused by the matching of user attributes, and make the interaction between vehicles faster and more convenient. Hui Xing et al. [
8] proposed a secure and privacy-preserving symptom-matching scheme based on homomorphic encryption, which not only preserves the privacy of personal health information (PHI) but also prevents inflation attacks and other active attacks. However, these schemes either distribute keys through a trusted third party or use cryptographic tools. They not only have a large overhead but, more importantly, there is no direct communication between two patients between these schemes.
Among the existing privacy protection technologies, Private Set Intersection is an emerging privacy protection technology that effectively satisfies the need to return to the intersection, while preserving the privacy of all parties involved. At the same time, the extended PSI protocol (Set Threshold Label Private Set Intersection) also provides solutions for threshold and label requirement scenarios. However, the current STLPSI protocol only satisfies the receiver to receive the sender’s label, and the sender knows nothing about the receiver’s data. For direct-contact symptom matching, both the receiver and sender are required to obtain each other’s tags. We do not seem to have found the relevant technology for this. Therefore, in this context, we need to study new solutions to meet this condition.
In this work, we propose a privacy-preserving direct-contact symptom-matching scheme that guarantees privacy. The core technology of our scheme is the Switching Threshold Label Private Set Intersection (STLPSI) protocol, which is based on the Diffie–Hellman key agreement. Unlike previous threshold-based approaches that only allow the receiver to reconstruct labels, our protocol allows both the receiver and sender to reconstruct labels. By leveraging our protocol for symptom matching, our scheme facilitates direct contact between patients and only when a certain threshold of symptom matching is reached, thereby safeguarding the privacy of patient symptom information. Furthermore, the protocol employs a hash function to reduce communication and enhance the matching efficiency. We also conduct a rigorous analysis of the correctness and security of the protocol. Our contributions are summarized as follows.
In the absence of a trusted third party, we propose the Switching Threshold Label Private Set Intersection (STLPSI) protocol, which is based on the Diffie–Hellman key agreement, and we provide a formal definition of it. Our protocol improves upon previous work by allowing both the receiver and the sender to reconstruct labels. We achieve this by using hashed Diffie–Hellman key agreement and hash functions, which also enhance the overall efficiency of the protocol.
We apply the proposed protocol to the symptom matching of IoT devices to achieve patient symptom matching and contact information exchange. We demonstrate our system using a concrete numerical example.
We provide a correctness and security analysis, showing that our scheme is correct and protects privacy. Additionally, we compare our work theoretically and experimentally with previous work, and the results show that our protocol is feasible.
3. Preliminaries
3.1. Notations
In this paper, we denote the sender’s data set, which has a size of n, as . Here, represents the sender’s symptoms, and represents the sender’s personal contact information. is the secret share of the label . denotes the construction of . Similarly, we represent the receiver’s data set as , where m is the size, indicates the receiver’s symptoms, and indicates the receiver’s personal contact information. is the secret share of the label , and is the construction result of . Note that the size of the two parties’ sets in our protocol may differ. At the same time, the threshold t is smaller than the minimum value of m and n.
In the protocol, denotes the intersection set of X and Y. The number of elements contained is denoted as . denotes the negotiated key. We use to denote the number of hash functions. The size of the elliptic curve group elements is 256. Other special symbols will be introduced when using them.
3.2. Threshold Label Private Set Intersection Functionality
In
Figure 1, we formally describe the threshold label private set intersection functionality. The threshold label private set intersection protocol is a special type of PSI. In this scenario, each element in the Sender’s set has associated data (a label), and the receiver hopes to learn the labels of the elements in the intersection if he/she satisfies the intersection threshold, while the sender obtains no information.
3.3. Shamir’s Secret Sharing
Secret sharing [
25] is an important cryptographic tool. It can be used to build secure multi-party computing, which is used in many multi-party secure computing protocols, such as threshold PSI, secure multi-party computation, and so on. In this work, we use Shamir’s secret sharing. We explain the scheme at a high level. Given integers n, t (n≤t) and the finite field
F, Shamir’s secret-sharing scheme contains two steps.
Sharing step:
Choose a random polynomial of degree t that satisfies f(0) = s and distinct points .
Compute . The set S = . Note that is the secret shared value.
Reconstruction step:
Input set of size .
Use Lagrangian interpolation to compute the polynomial , which satisfies , where and output .
The privacy requirement of Shamir’s secret sharing is that any subset of size smaller than the threshold cannot know any information about s, i.e., its probability distribution is independent of s. In our protocol, the sender and receiver each generate t-out-of-T secret shares for the label ().
3.4. Diffie–Hellman Key Agreement
The classic Diffie–Hellman key agreement protocol is a one-round KA protocol, which means that two messages can be sent simultaneously. Given a cyclic group of order q, the agreement follows:
Sender chooses a random message a, computes , and sends to receiver;
Receiver chooses a random message b, computes , and sends to sender;
Sender computer ;
Receiver computer .
In this work, we use “hashed” Diffie–Hellman key exchange and use elliptic curves for the underlying cyclic group, which means that the negotiated keys are processed by the same hash function. The hashed Diffie–Hellman key exchange algorithm uses the public and private keys to encrypt and decrypt when exchanging public keys—that is,
and
. After receiving the public key, the sender and receiver calculate the negotiation key
. The security of the protocol is based on the oracle Diffie–Hellman (ODH) assumption. In brief, the oracle Diffie–Hellman (ODH) assumption is that
,
,
is indistinguishable from random in the presence of an oracle for
, as long as the distinguisher does not know the value of
. The detailed proof is given in [
26].
3.5. Cuckoo Hashing
Cuckoo hashing is a hash table data structure that provides constant time
average case lookup, insertion, and deletion operations, which was introduced by Pagh and Rodler in [
27]. It uses two hash functions and two separate arrays, called tables, to store the key-value pairs. The cuckoo hashing works as follows.
Let H be a hash table of size m, and let and be two independent hash functions that map keys to the integers 0 to . The hash table H consists of two arrays, and , each of size m.
The insertion algorithm works as follows: when a key–value pair is inserted into the hash table, first the hash functions and are used to calculate two possible index positions and , respectively, in the two arrays. If either or is empty, the pair is stored at the corresponding position. Otherwise, one of the pairs currently stored at or must be moved to its other position in the other table. This displacement process continues recursively until an empty position is found or a cycle is detected. In the latter case, the table is rehashed with new hash functions.
The lookup operation works similarly. Given a key k, the two hash functions and are used to calculate the two possible index positions and in the two arrays. If either or contains the key k, the corresponding value can be returned.
5. Our Proposed Protocol
In this section, we propose a detailed protocol called Switching Threshold Label Private Set Intersection (STLPSI) for privacy-preserving directly contactable symptom matching. First, we formally define the general syntax and correctness of our protocol. Next, we present the protocol design in
Figure 3. To help readers to better understand our innovation, we also provide specific examples from the symptom-matching system.
5.1. Formal Definition of STLPSI
Definition 1. Switching Threshold Label Private Set Intersection (STLPSI). The protocol definition has several parameters:
ζ is the input space of the two parties;
ψ is the label space of the two parties;
t is a threshold value, which ;
Finite field F.
In addition, four algorithms are included in the definition: , , , OR ⊥.
Given two sets and , generates secret sharing and for and . Then, the F algorithm inputs the set M and N, which is the encrypted set by the key generated by the algorithm, and outputs the sets R and S. Finally, R and S are input into the algorithm, and the output is OR ⊥. The details of the four algorithms are as follows.
. Given a secret value and an integer n, generate a sharing set , where each is a share of s.
. Generate a secret key using the input parameters a and b.
. Input two sets and , and the function outputs two sets, () and () through interaction between two parties.
or ⊥. The algorithm inputs a set R and returns s if , or ⊥ if .
Correctness and privacy. For correctness, we require that for any s and , it holds that with probability 1 if the size of R is greater than t. For privacy, we require that any information of X and Y cannot be revealed if the size of R is lower than t. Otherwise, elements other than the same elements in the X and Y sets cannot be disclosed even if the threshold is met.
5.2. STLPSI Protocol Design
Protocol overview: At a high level, after giving the threshold t, our protocol is executed by a sender and a receiver. First, the sender and receiver share their own labels secretly, where the sender generates and the receiver generates . In order to preserve the corresponding relationship between the sender and the receiver and , and , we use cuckoo hashing to generate the hash tables and for the corresponding relationship. Then, they agree on a key using the Diffie–Hellman algorithm and encrypt their hashed elements as and . Next, the two parties exchange labels through interaction. More specifically, the sender computes the set . Among them, . Finally, the sender sends the hash table and set S to the receiver. The receiver calculates the set , where . Then, the receiver sends the set R and to the sender. It is obvious that the label-sharing values and will be observed if . Furthermore, the sender and receiver will obtain label sharing and rebuild the label if the two sets have elements that are the same. Otherwise, the protocol is terminated and both parties will obtain nothing.
To better illustrate our protocol, our protocol uses the four algorithms defined above and is divided into three stages: (1) the preprocessing stage, (2) the interactive stage, and (3) the result recovery stage. During this process, the private data of the two parties will not be disclosed. In addition, we assume that the two parties have negotiated hash functions, security parameters, and other information before the protocol starts. The detailed description of our Switching Threshold Label Private Set Intersection is shown in
Figure 3.
5.3. Symptom-Matching System
In this section, we apply the Switching Threshold Label Private Set Intersection (STLPSI) protocol to the symptom-matching system. Similar to the protocol, our system consists of three stages: the preprocessing stage, the interaction stage, and the result recovery stage. We demonstrate the operation of each stage of the system using specific numerical values.
5.3.1. The Preprocessing Stage
The preprocessing phase is an offline phase, and two patients who want to exchange contact information will prepare for the next phase by performing this phase. We assume that the two patients are the receiver and the sender, and symptom information and contact information are mapped to the integer field of 256. We use the example of the symptom-matching system, where the set represents the sender and the set represents the receiver. The last element in the set represents the contact information of the two patients. We set the threshold to 4, which means that only when the number of identical elements in both sets X and Y is greater than or equal to 4, the sender and receiver can reconstruct contact information.
At this stage, the sender and receiver first randomly select polynomial interpolation functions based on a threshold of 4. To demonstrate the system, we assume that the sender randomly selects the polynomial and the receiver selects the polynomial . We evaluate eight points as the secret shared values of the label using the two polynomials, obtaining the sets and . Then, we map the items of and into b bins. To be more specific, item will be added into , regardless of whether these bins are empty. Correspondingly, is also added into .
5.3.2. The Interactive Stage
During the interaction phase, the sender and receiver first obtain a shared secret key through the DH key negotiation protocol. Here, we assume that the negotiated key is and XOR is used as the encryption method. During this process, the sender and receiver first encrypt sets X and Y into sets and , respectively. Then, for each element and in and , the sender and receiver, respectively, compute and . This yields sets and . Finally, the sender sends the set S and to the receiver, and correspondingly the receiver sends the set R and to the sender.
5.3.3. The Result Recovery Stage
The result recovery stage is also for offline operation. In this phase, after the receiver receives the set
R from the sender, the receiver calculates the set
based on its own encrypted data. Each element in the set is expressed as
. Similarly, after the sender receives the set
R from the receiver, the sender calculates the set
. Each element in the set is expressed as
. In the demonstration system, both the
m and
n sets contain eight elements. Finally, the receiver and the sender select the
t value from their respective sets and look up the corresponding point value in the hash table for reconstruction according to Equations (
1) and (
2). We use points (16,252), (45,178), (14,23), and (41,32) to reconstruct the polynomial on the field of 256 as a presentation.
with
satisfying Equation (
2).
Substituting the given points, we obtain Equation (
3),
Simplifying, we obtain
. The label information is the value of
. Using this method, the sender and receiver can obtain the contact information of one another.
6. Correctness
In this section, we analyze the correctness of the Switching Threshold Label Private Set Intersection (STLPSI) protocol. We justify each step of the Switching Threshold Label Private Set Intersection (STLPSI) protocol as described in
Figure 3.
In the preprocessing stage, the sender and receiver use polynomial interpolation to ensure that their respective polynomials and pass through the designated points and , respectively, in step 1 and 2. Since both and have degree , they can interpolate up to t points uniquely.
In step 3, the sender and receiver then hash their sets
X and
Y using the collision-resistant hash function
H, respectively. It guarantees that each element of the
X and
Y is mapped to a unique hash value. If two elements in different sets have the same hash value, they are assumed to be the same element. In step 4, the sender and receiver generate hash tables, and the correctness is based on the failure probability. According to the empirical analysis in [
28], we can adjust the values of
and
to reduce the stash size to 0 while achieving a hashing failure probability of
, which can be negligible.
In the interactive stage, the sender and receiver use the hashed Diffie–Hellman key exchange to generate a shared agreement key in step 1 to 4. To prove the correctness of the hashed Diffie–Hellman key exchange protocol, we need to show that the two parties can derive the same shared secret key from the public values exchanged during the protocol. In steps 1 and 2 of the interactive stage, the sender and receiver calculate and , respectively, and send them to each other. In step 3, the sender computes the shared secret key as . In step 4, the receiver computes the shared secret key as . Now, we should prove that the sender and receiver can derive the same shared secret key. From step 2, we have . From step 1, we have . Because and , we can see that . This shows that the sender and receiver can derive the same shared secret key from the Diffie–Hellman key exchange during the protocol.
At the result recovery stage, the sender computes for each sent by the receiver, and the receiver computes for each sent by the sender. We divide the correctness of this phase into two cases.
Case one:
—that is, the elements in the intersection of sets
X and
Y. Then, according to the construction of
Figure 3, we have
. In the interaction phase, the sender obtains the value
. Then, the sender computes
. Due to
, the value of
is equal to
. According to this, if there are
k (
k greater than
t) elements in the intersection set, then the sender will obtain
k secret shared values of
, i.e.,
. Note that we here only represent any
k of the
n secret shared values. The receiver is the same as the sender, and the receiver will obtain
k secret shared values of
. In the reconstruction phase, we share labels using the Shamir secret sharing method. Therefore, when recovering labels, the sender and receiver will construct a Lagrangian interpolation function to reconstruct the labels. The correctness is proven below, which follows the proof of Shamir [
25]. To prove the correctness of Shamir’s secret reconstruction, we need to show that the polynomials
and
can be reconstructed from any
shares, and the secret can be recovered by evaluating the reconstructed polynomial at
.
First, let us consider the interpolation problem. Given
k points (
), (
), …, (
), where the
are distinct, we want to find a polynomial
of degree
such that
for
. It can be found using Lagrange interpolation, whose equation is Equation (
5). Using this equation, we can reconstruct the polynomial from any k shares, since each share corresponds to a distinct point (
). The correctness of the polynomial interpolation can be ensured by Lagrange’s interpolation theorem, which states that given a set of
t points
, where
if
, there exists a unique polynomial
P of degree at most
such that
for all
. The proof process is as follows.
Let (
,
), (
,
), …, (
,
) be
n distinct data points. We want to find a polynomial
of degree at most
that passes through all these points. We start by defining the Lagrange basis polynomials as Equation (
4).
Note that each
is a polynomial of degree
and has the property that
for
and
. Using these basis polynomials, we can construct the interpolating polynomial as Equation (
5).
where
is the value of the function at the point
. To show that
passes through all the given data points, we substitute each
into
and show that
for all
i. For any
, we have an equation as a description, i.e., Equation (
6),
Therefore, for all , which means that passes through all the given data points. Since is a polynomial of degree at most and it passes through n distinct points, it must be unique. Based on this, we can claim that and are unique polynomials that satisfy the given conditions in our construction.
Secondly, let us consider the secret recovery problem. Given the reconstructed polynomial , we want to recover the secret s, which is the constant term of the polynomial. We can do this by evaluating the polynomial at since . Therefore, Shamir’s secret reconstruction is correct.
Case two: . In this case, and are not in the intersection of X and Y. Since we encrypt the elements with an AES symmetric key, we obtain . For different and , the value of and is pseudorandom. In the following stages, values calculated from this are random and meaningless. This suffices to confirm our protocol’s correctness.
7. Security Proof
In this section, we prove the security of the STLPSI protocol under the semi-honest model [
29]. The definition is as follows.
Definition 2. For a two-party protocol Π to compute , and , respectively, calculate the functions , . α and β are the inputs of and , . We denote the view generated by during the execution of the protocol as . The output is denoted as . We say that Π is secure against semi-honest adversaries if there exist probabilistic polynomial time (PPT) simulators and such as Equations (7) and (8):where denotes computational indistinguishability. In other words, it means that a real-world protocol is secure if for the ideal-world function F, which is possessed by a simulator , the output of F should be indistinguishable from the output of the real protocol. Therefore, we construct ideal-world simulators and to emulate the views and of the sender and receiver in the real execution.
Theorem 1. The protocol of Switching Threshold Label Private Set Intersection (STLPSI) shown in Figure 3 is secure (in the semi-honest model) if the hashed Diffie–Hellman key agreement (DHKA) protocol and Shamir’s secret sharing scheme are secure. Proof. To enhance the clarity, we assume that the simulator possesses fixed and public parameters utilized in our protocol for illustrative purposes. Subsequently, we introduce the view that necessitates simulation and then proceed to delineate the views of the simulators and , respectively. □
Simulating the sender. To construct
, we first describe the real view that needs to be simulated. Recall that, in the preprocessing stage, the sender receives nothing from the receiver; thus,
is not necessary to simulate the view. In the interactive stage, the sender obtains
,
, and
R from the receiver, which should be simulated. The result recovery phase is offline, and the sender computes the label or random result locally. We note the final result as
v. Therefore, the real view of the sender can be denoted as Equation (
9).
For , it works as follows:
obtains the sender’s input X and output v from an adversary A.
generates random value and then computes the value of for the simulation of the received by the receiver.
randomly generates to simulate the received set R from the receiver, where each element .
generates hash label for the simulation of the received by the receiver.
. According to the above analysis, the view of
is denoted by Equation (
10).
Now, we prove that the simulator’s view and the rear view are indistinguishable. Based on the security of hashed Diffie–Hellman key agreement (DHKA) proposed by Abdalla, Bellare, and Rogaway [
26], we know that
,
are indistinguishable from a random value. The value
w is computed by
’s chosen random value
. It is indistinguishable from
. For each element of set
R,
, Shamir’s secret sharing scheme guarantees the indistinguishability of each individual share from a random item in the shared domain
F.
is secret for
. At the same time, we use AES as the encryption algorithm. Thus, it is obvious that
is random for
and is indistinguishable from
. From this, we can claim that the simulator’s view and the real view are indistinguishable, as shown by Equation (
11).
Simulating the receiver. In the same way as for the sender, we first provide the real view, and then we construct the view of the receiver.
When the entire protocol is running, there are only two rounds of interaction—that is, the receiver receives the sender’s
,
S, and
. We note the result of the receiver computed locally as
e. Therefore, the receiver’s view can be represented as Equation (
12).
For , it works as follows:
obtains the receiver’s inputs Y and outputs e from an adversary A.
generates random value and then computes the value of for the simulation of the received by the sender.
randomly generates to simulate the received set S from the sender.
randomly generates to simulate the received set S from the sender.
. According to the above analysis, the view of
is denoted by Equation (
13).
What we should prove is that the receiver’s real views and
’s views are indistinguishable. First,
is random for
based on the security of hashed Diffie–Hellman key agreement (DHKA). The value of
u is indistinguishable from
. Secondly, for each element
of set
S,
is indistinguishable from the value of domain
F. Then,
is also random. Therefore, the value of
is random. A semi-honest receiver cannot distinguish between the values of
and
. Based on the above, we can obtain that the
’s view is indistinguishable from the receiver’s view, as shown by Equation (
14).
According to the above analysis, we can claim that the Switching Threshold Label Private Set Intersection (STLPSI) is secure under the semi-honest adversaries model.
8. Complexity Analysis of STLPSI
In this section, we first show the complexity of our scheme, including the communication complexity and computational complexity. Then, we compare the symptom-matching scheme with [
5] and Zhu [
30] as shown in
Table 1. Additionally, we compare the number of communication rounds with [
5] and Zhu [
30] as shown in
Table 2.
In order to compare under the same standard, we continue the method in [
5], which takes the bits transmitted by the receiver and the sender as the communication overhead. The number of instances of modular multiplication and modular exponentiation is taken as the computation overhead. We compare them in two rows in
Table 1 since Jiang et al. [
5] proposed coarse-grained and fine-grained symptom-matching schemes. We denote
,
, and
as 160-bit, 1024-bit, and 256-bit modular multiplication. Moreover, we denote
,
,
as 160-bit, 1024-bit, and 256-bit modular exponentiation.
represents an encryption operation.
represents the hash function, such as SHA-256.
is the length of the bloom filter used in Zhu’s system, see [
30] and [
5]. Note that we neglect the overhead of the Diffie–Hellman key generation operation.
Communication complexity. In our scheme, there are two interactions in the protocol. The sender must send KA information and calculate the set S to the receiver. The receiver responds to a KA message and sets R and hash table to the sender. Therefore, the total communication overhead consists of three parts. (1) Two rounds of KA messages from the sender and receiver. Each size has 256 bits. (2) The set S, which is from the sender and contains n elements, and set R contains m elements from the receiver. Each element is 256 bits. (3) The size of the hash table. For the sender, according to the parameters of our hash table, the size of our table is . The size of the receiver’s hash table is . In summary, the total communication cost of the sender is bits. The total communication cost of the receiver is bits.
Computation complexity. Given a threshold t, in the preprocessing stage, the sender and receiver generate random polynomials and of order , respectively. The process of generating a random polynomial involves modular multiplications. Then, the sender and the receiver select n and m points on the polynomial and calculate the corresponding and . This process involves times modular exponentiation and times modular multiplication for the receiver and times modular exponentiation and times modular multiplication for the sender. In the result recovery stage, the sender and the receiver select t points from m and n numbers, respectively, to reconstruct the result by using the Lagrange interpolation method. The reconstruction in turn secretly involves t modular exponentiations and t modular multiplications. Therefore, the complexity of the sender and receiver at this stage is and , respectively. Both the preprocessing phase and the result recovery phase are completed offline, so we can obtain the complexity of the offline phase of the sender and receiver as and .
Comparison. As shown in
Table 1, the computational complexity of our protocol in the offline stage is not dominant compared to Jiang’s system; see [
5] and [
30]. In their work, the sender does not need any computation in the offline phase, while our protocol needs to have the same computation as the receiver. This is because our protocol can permit both the sender and the receiver to recover the result, compared to their work, which can only allow the receiver to obtain the result. Therefore, it is reasonable to have computations on the sender’s side during the offline phase. In addition, we can see from the table that the communication and computation in our online stage are lower than in their work. This is even more advantageous in IoT devices.
As shown in
Table 2, we compare the number of communication rounds between our protocol and other protocols. It is obvious that our work and theirs both require two rounds of communication, with no significant difference. Therefore, the number of communication rounds in our protocol is reasonable. However, according to the result of
Table 3 the comparison of communication bits in
Table 4, our protocol has certain advantages compared to other protocols. Therefore, although our protocol is not optimized in terms of communication rounds, the communication cost of our protocol is lower than in other works.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}