
Learning-Based Collaborative Computation Offloading in UAV-Assisted Multi-Access Edge Computing


Abstract
:1. Introduction
- •
- We investigate the problem of collaborative computation offloading involving multiple UAVs under the constraints of limited communication range and latency. Our goal is to collectively minimize the average energy consumption while increasing the overall efficiency.
- •
- We transform the optimization problem of cooperative computation offloading into a multi-agent markov decision process (MAMDP). In this framework, each UAV serves as an individual agent, and these agents make decisions by considering local real-time observations and the current policy. These decisions involve selecting the task offloading target and allocation ratio.
- •
- We design an algorithm based on multi-agent deep deterministic policy gradient (MADDPG). With offline training, each UAV can make real-time offloading decisions. We conduct a series of simulation experiments to prove the effectiveness of the algorithm in dynamic environments.
2. Related Work
- •
- First, we address the problem of optimizing cooperative offloading involving multiple UAVs. Considering the constraints of limited computing resource and communication range, our primary goal is to minimize the average energy consumption of these UAVs while ensuring latency constraints are met.
- •
- Second, the predominant approaches in the current landscape heavily rely on game-theory-based methods and optimization-based techniques, which are deterministic optimization methods well-suited for static environments. However, their adaptability diminishes when faced with dynamic environmental changes and the necessity for continuous offloading. To address this dynamism and the continuous nature of offloading decisions, we incorporate deep reinforcement learning methods.
- •
- Third, the majority of existing research predominantly relies on single-agent reinforcement learning algorithms, which makes it challenging to address cooperative issues involving multiple agents. To overcome this limitation, we enhance our approach by adopting the MADDPG framework, which transforms the multi-user cooperative offloading game into a multi-agent model.
3. Models and Problem Definition
3.1. The UAV-Assisted MEC Environment
3.2. Offloading Schemes of UAVs
3.3. Energy Consumption Models
3.3.1. Computational Energy Consumption
3.3.2. Communication Energy Consumption
3.3.3. Average Energy Consumption
3.4. Average Response Latency
3.5. Problem Definition
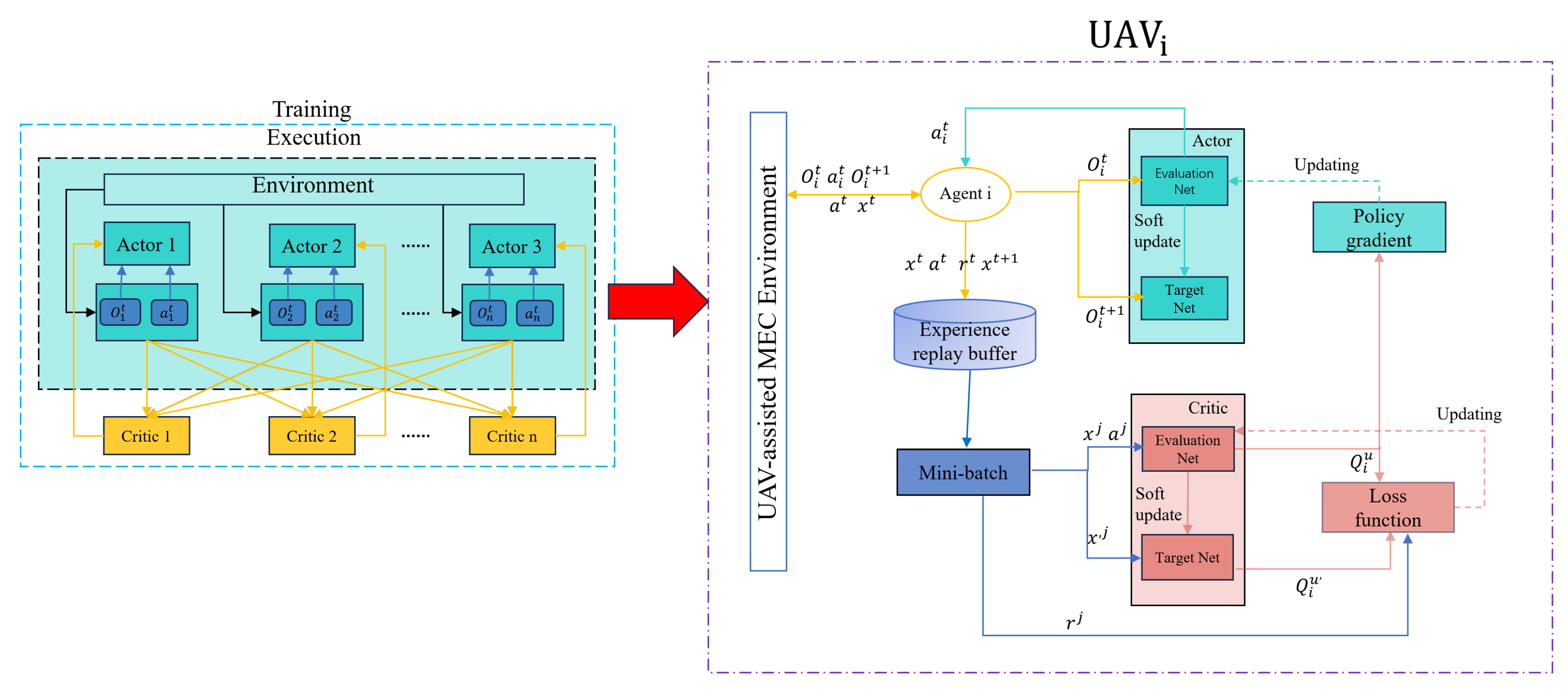
4. Our Solutions
4.1. Problem Transformation
4.2. Preliminaries of the MADDPG
| Algorithm 1 MADDPG-Based Task Offloading Optimization in UAV-assisted MEC Environment |
Input: , Output:
|
5. Performance Evaluation
5.1. Simulation Settings
5.2. Parameter Analysis
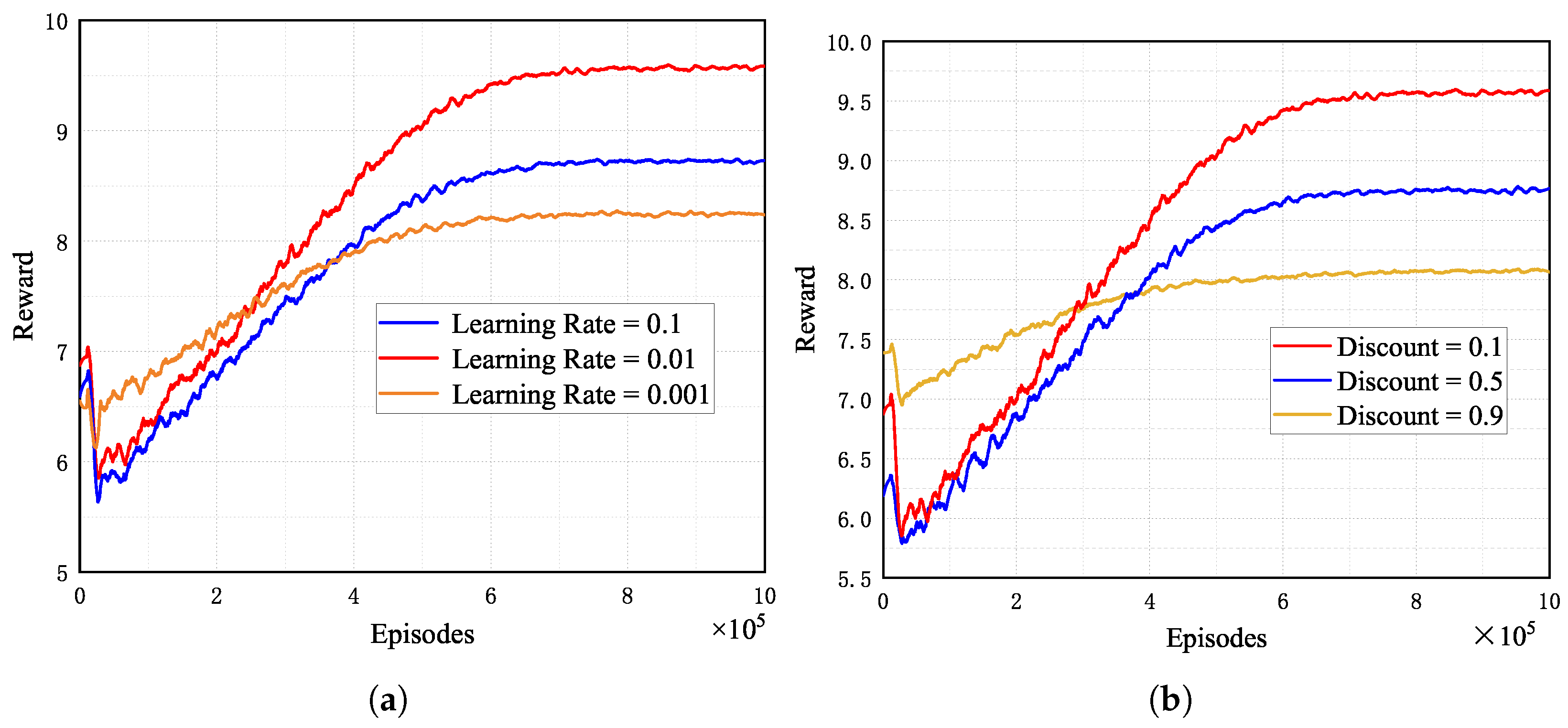
5.2.1. Impact of Learning Rate on Convergence
5.2.2. Impact of Discount Factor on Convergence
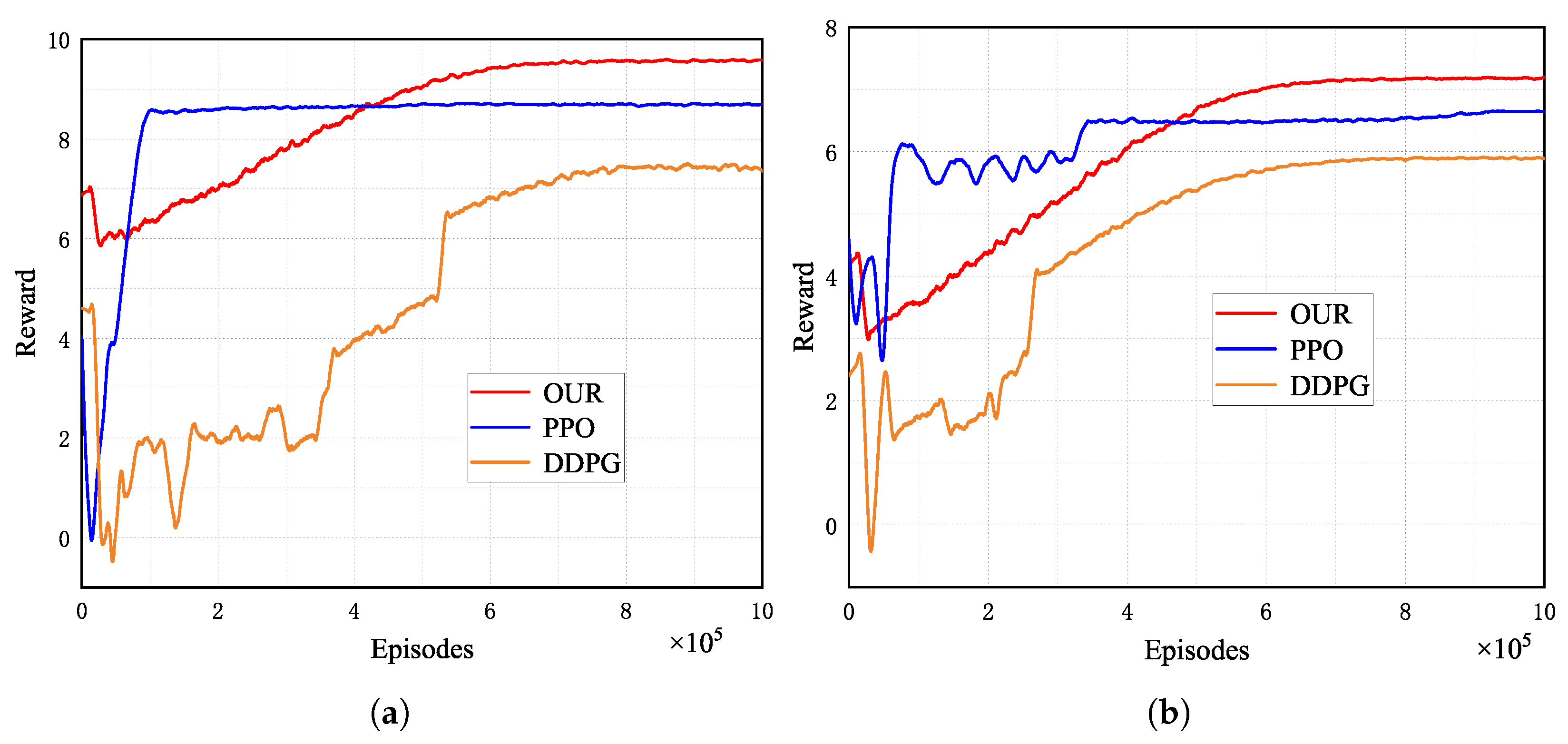
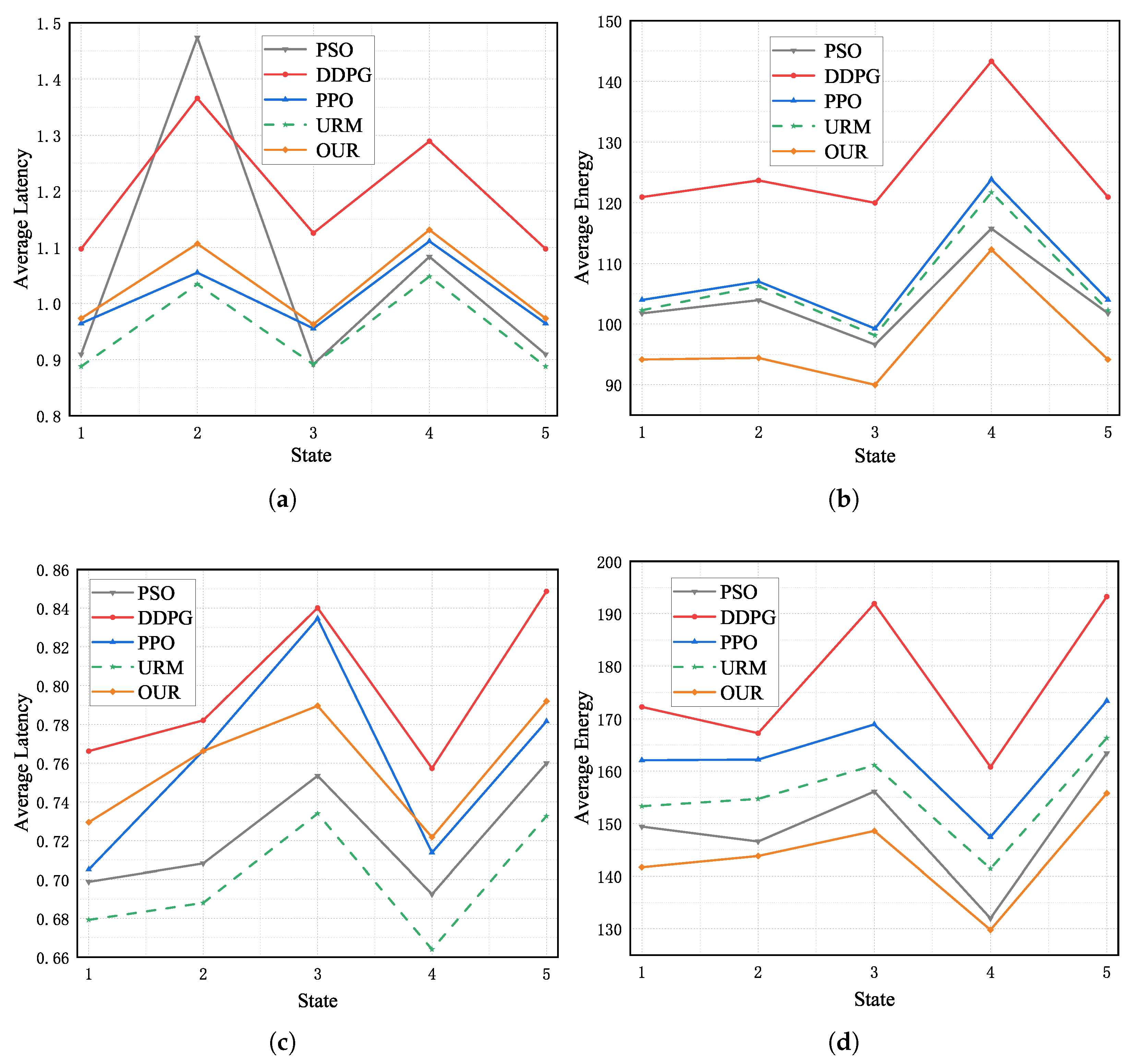
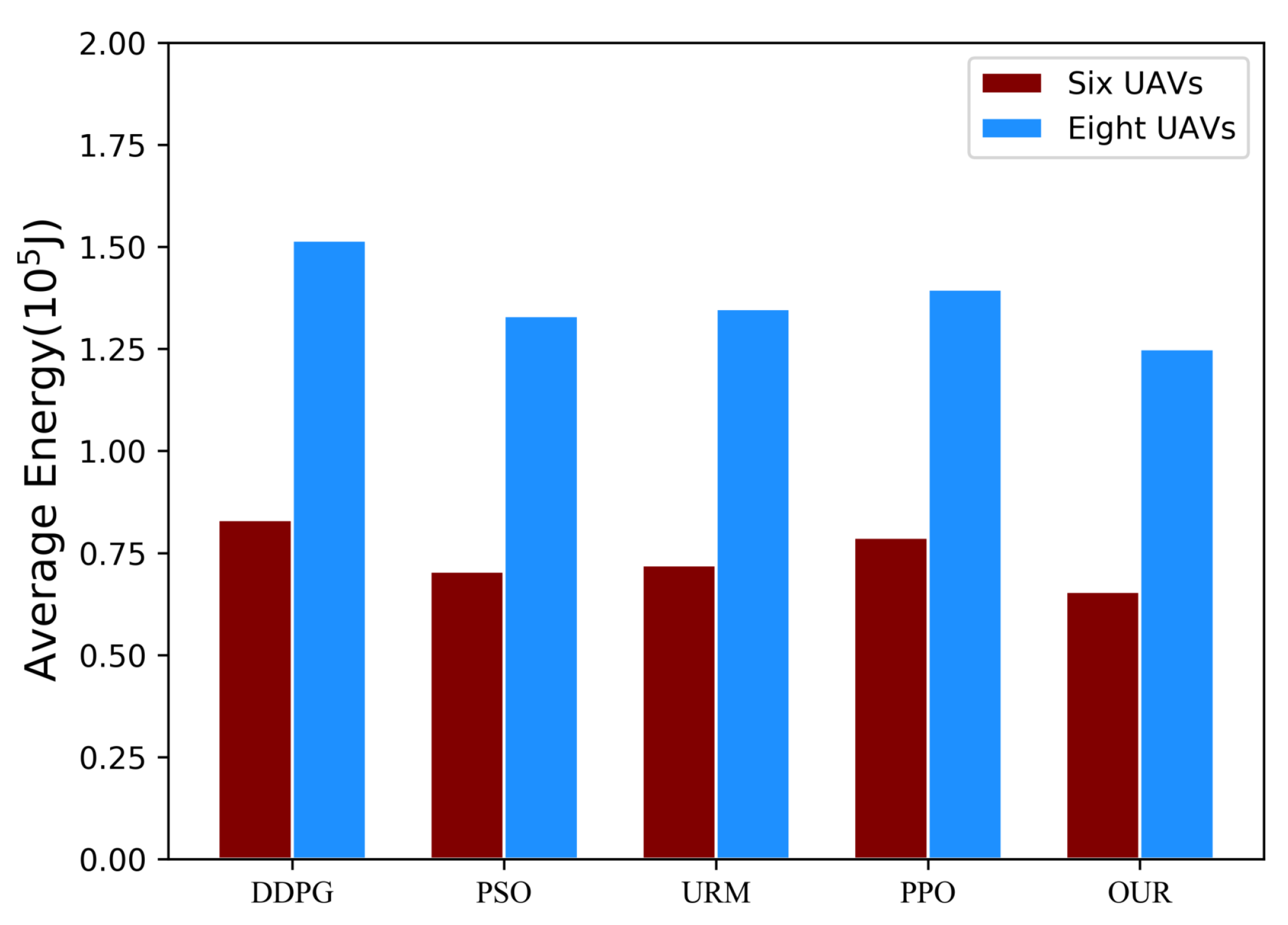
5.3. Comparison Experiments
- •
- •
- URM scheme: In the URM scheme, each UAV first determines the number of UAVs within its communication range (denoted as m). It then distributes the tasks equally between itself and the other UAVs within its communication range. Thus, the size of the task that shares with other UAVs in its communication range is .
- •
- Proximal policy optimization (PPO) scheme: Each UAV has an independent PPO [46] model and each UAV makes independent offloading decisions.
- •
- DDPG scheme: Each UAV operates autonomously with its independent DDPG model, devoid of a centralized critic network and local information sharing. Each UAV autonomously makes offloading decisions. We employ the neural network structure consistent with the MADDPG algorithm for both the actor and critic networks of the DDPG.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Symbol | Definition |
| n | Number of UAVs |
| Communication circumstances of | |
| Data size of tasks received by from IOTDs at time slot t | |
| The percentage of tasks that handles locally at time slot t | |
| The percentage of tasks that offload to at time slot t | |
| Number of CPU cycles needed to execute 1-bit data on | |
| CPU cycles required by to perform local tasks at time slot t | |
| CPU cycles required by to perform tasks from other UAVs at time slot t | |
| Total CPU cycles required by to perform all tasks at time slot t | |
| Computational power consumption of | |
| k | Constant factor related to the CPU chip architecture |
| Execution speed of | |
| Overall time required to perform all tasks on during time slot t | |
| Energy consumption required to perform all tasks on during time slot t | |
| Data transmission rate between and | |
| Channel bandwidth from to | |
| Transmission power from to | |
| Channel gain from to | |
| Noise power spectral density from to | |
| Transmission time required of to offload tasks to during time slot t | |
| Energy consumption due to task offloading from to during time slot t | |
| Communication energy consumption of during time slot t | |
| Total energy consumption of the during time slot t | |
| Data size of the tasks on all UAVs at time slot t | |
| Data size of all tasks to be executed by at time slot t | |
| Average energy consumption at time slot t | |
| Response latency of the task assigned to itself by in time slot t | |
| Response latency of tasks that offloads to for execution in time slot t | |
| Average response latency of tasks offloaded by for execution in time slot t | |
| Average response latency of tasks received by from IOTDs in time slot t | |
| Average response latency of all tasks during time slot t | |
| Latency constraint |
References
- Zhao, M.; Li, W.; Bao, L.; Luo, J.; He, Z.; Liu, D. Fairness-Aware Task Scheduling and Resource Allocation in UAV-Enabled Mobile Edge Computing Networks. IEEE Trans. Green Commun. Netw. 2021, 5, 2174–2187. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile Edge Computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Dao, N.N.; Pham, Q.V.; Tu, N.H.; Thanh, T.T.; Bao, V.N.Q.; Lakew, D.S.; Cho, S. Survey on Aerial Radio Access Networks: Toward a Comprehensive 6G Access Infrastructure. IEEE Commun. Surv. Tutor. 2021, 23, 1193–1225. [Google Scholar] [CrossRef]
- Lakew, D.S.; Sa’ad, U.; Dao, N.-N.; Na, W.; Cho, S. Routing in Flying Ad Hoc Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 1071–1120. [Google Scholar] [CrossRef]
- Zhou, F.; Hu, R.Q.; Li, Z.; Wang, Y. Mobile Edge Computing in Unmanned Aerial Vehicle Networks. IEEE Wirel. Commun. 2020, 27, 140–146. [Google Scholar] [CrossRef]
- Qiu, J.; Grace, D.; Ding, G.; Zakaria, M.D.; Wu, Q. Air-Ground Heterogeneous Networks for 5G and Beyond via Integrating High and Low Altitude Platforms. IEEE Wirel. Commun. 2019, 26, 140–148. [Google Scholar] [CrossRef]
- Kurt, G.K.; Khoshkholgh, M.G.; Alfattani, S.; Ibrahim, A.; Darwish, T.S.; Alam, M.S.; Yanikomeroglu, H.; Yongacoglu, A. A Vision and Framework for the High Altitude Platform Station (HAPS) Networks of the Future. IEEE Commun. Surv. Tutor. 2021, 23, 729–779. [Google Scholar] [CrossRef]
- Motlagh, N.H.; Bagaa, M.; Taleb, T. Energy and Delay Aware Task Assignment Mechanism for UAV-Based IoT Platform. IEEE Internet Things J. 2019, 6, 6523–6536. [Google Scholar] [CrossRef]
- Jeong, S.; Simeone, O.; Kang, J. Mobile Edge Computing via a UAV-Mounted Cloudlet: Optimization of Bit Allocation and Path Planning. IEEE Trans. Veh. Technol. 2018, 67, 2049–2063. [Google Scholar] [CrossRef]
- Zhang, T.; Xu, Y.; Loo, J.; Yang, D.; Xiao, L. Joint Computation and Communication Design for UAV-Assisted Mobile Edge Computing in IoT. IEEE Trans. Ind. Inform. 2020, 16, 5505–5516. [Google Scholar] [CrossRef]
- Diao, X.; Guan, X.; Cai, Y. Joint Offloading and Trajectory Optimization for Complex Status Updates in UAV-Assisted Internet of Things. IEEE Internet Things J. 2022, 9, 23881–23896. [Google Scholar] [CrossRef]
- Lv, W.; Yang, P.; Zheng, T.; Yi, B.; Ding, Y.; Wang, Q.; Deng, M. Energy Consumption and QoS-Aware Co-Offloading for Vehicular Edge Computing. IEEE Internet Things J. 2023, 10, 5214–5225. [Google Scholar] [CrossRef]
- Chen, J.; Wu, H.; Li, R.; Jiao, P. Green Parallel Online Offloading for DSCI-Type Tasks in IoT-Edge Systems. IEEE Trans. Ind. Inform. 2022, 18, 7955–7966. [Google Scholar] [CrossRef]
- Hu, X.; Masouros, C.; Wong, K.-K. Reconfigurable Intelligent Surface Aided Mobile Edge Computing: From Optimization-Based to Location-Only Learning-Based Solutions. IEEE Trans. Commun. 2021, 69, 3709–3725. [Google Scholar] [CrossRef]
- Guo, M.; Wang, W.; Huang, X.; Chen, Y.; Zhang, L.; Chen, L. Lyapunov-Based Partial Computation Offloading for Multiple Mobile Devices Enabled by Harvested Energy in MEC. IEEE Internet Things J. 2022, 9, 9025–9035. [Google Scholar] [CrossRef]
- Luo, Q.; Li, C.; Luan, T.H.; Shi, W. Minimizing the Delay and Cost of Computation Offloading for Vehicular Edge Computing. IEEE Trans. Serv. Comput. 2022, 15, 2897–2909. [Google Scholar] [CrossRef]
- Abbas, N.; Fawaz, W.; Sharafeddine, S.; Mourad, A.; Abou-Rjeily, C. SVM-Based Task Admission Control and Computation Offloading Using Lyapunov Optimization in Heterogeneous MEC Network. IEEE Trans. Netw. Serv. Manag. 2022, 19, 3121–3135. [Google Scholar] [CrossRef]
- Sheng, M.; Dai, Y.; Liu, J.; Cheng, N.; Shen, X.; Yang, Q. Delay-Aware Computation Offloading in NOMA MEC Under Differentiated Uploading Delay. IEEE Trans. Wirel. Commun. 2020, 19, 2813–2826. [Google Scholar] [CrossRef]
- Moura, J.; Hutchison, D. Game Theory for Multi-Access Edge Computing: Survey, Use Cases, and Future Trends. IEEE Commun. Surv. Tutor. 2019, 21, 260–288. [Google Scholar] [CrossRef]
- Zhou, J.; Tian, D.; Sheng, Z.; Duan, X.; Shen, X. Distributed Task Offloading Optimization with Queueing Dynamics in Multiagent Mobile-Edge Computing Networks. IEEE Internet Things J. 2021, 8, 12311–12328. [Google Scholar] [CrossRef]
- Pham, X.-Q.; Huynh-The, T.; Huh, E.-N.; Kim, D.-S. Partial Computation Offloading in Parked Vehicle-Assisted Multi-Access Edge Computing: A Game-Theoretic Approach. IEEE Trans. Veh. Technol. 2022, 71, 10220–10225. [Google Scholar] [CrossRef]
- Xiao, Z.; Dai, X.; Jiang, H.; Wang, D.; Chen, H.; Yang, L.; Zeng, F. Vehicular Task Offloading via Heat-Aware MEC Cooperation Using Game-Theoretic Method. IEEE Internet Things J. 2020, 7, 2038–2052. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, J.; Wu, Y.; Huang, J.; Shen, X.S. QoE-Aware Decentralized Task Offloading and Resource Allocation for End-Edge-Cloud Systems: A Game-Theoretical Approach. IEEE Trans. Mob. Comput. 2022. [Google Scholar] [CrossRef]
- Teng, H.; Li, Z.; Cao, K.; Long, S.; Guo, S.; Liu, A. Game Theoretical Task Offloading for Profit Maximization in Mobile Edge Computing. IEEE Trans. Mob. Comput. 2023, 22, 5313–5329. [Google Scholar] [CrossRef]
- Fang, T.; Wu, D.; Chen, J.; Liu, D. Cooperative Task Offloading and Content Delivery for Heterogeneous Demands: A Matching Game-Theoretic Approach. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 1092–1103. [Google Scholar] [CrossRef]
- You, F.; Ni, W.; Li, J.; Jamalipour, A. New Three-Tier Game-Theoretic Approach for Computation Offloading in Multi-Access Edge Computing. IEEE Trans. Veh. Technol. 2022, 71, 9817–9829. [Google Scholar] [CrossRef]
- Zhang, K.; Gui, X.; Ren, D.; Li, D. Energy–Latency Tradeoff for Computation Offloading in UAV-Assisted Multiaccess Edge Computing System. IEEE Internet Things J. 2021, 8, 6709–6719. [Google Scholar] [CrossRef]
- Hussain, F.; Hassan, S.A.; Hussain, R.; Hossain, E. Machine Learning for Resource Management in Cellular and IoT Networks: Potentials, Current Solutions, and Open Challenges. IEEE Commun. Surv. Tutor. 2020, 22, 1251–1275. [Google Scholar] [CrossRef]
- Wang, J.; Hu, J.; Min, G.; Zomaya, A.Y.; Georgalas, N. Fast Adaptive Task Offloading in Edge Computing Based on Meta Reinforcement Learning. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 242–253. [Google Scholar] [CrossRef]
- Liu, Y.; Yu, H.; Xie, S.; Zhang, Y. Deep Reinforcement Learning for Offloading and Resource Allocation in Vehicle Edge Computing and Networks. IEEE Trans. Veh. Technol. 2019, 68, 11158–11168. [Google Scholar] [CrossRef]
- Zhou, H.; Jiang, K.; Liu, X.; Li, X.; Leung, V.C.M. Deep Reinforcement Learning for Energy-Efficient Computation Offloading in Mobile-Edge Computing. IEEE Internet Things J. 2022, 9, 1517–1530. [Google Scholar] [CrossRef]
- Tang, M.; Wong, V.W.S. Deep Reinforcement Learning for Task Offloading in Mobile Edge Computing Systems. IEEE Trans. Mob. Comput. 2022, 21, 1985–1997. [Google Scholar] [CrossRef]
- Dai, Y.; Zhang, K.; Maharjan, S.; Zhang, Y. Deep Reinforcement Learning for Stochastic Computation Offloading in Digital Twin Networks. IEEE Trans. Ind. Inform. 2021, 17, 4968–4977. [Google Scholar] [CrossRef]
- Gao, H.; Huang, W.; Liu, T.; Yin, Y.; Li, Y. PPO2: Location Privacy-Oriented Task Offloading to Edge Computing Using Reinforcement Learning for Intelligent Autonomous Transport Systems. IEEE Trans. Intell. Transp. Syst. 2023, 24, 7599–7612. [Google Scholar] [CrossRef]
- Wang, J.; Hu, J.; Min, G.; Zhan, W.; Ni, Q.; Georgalas, N. Computation Offloading in Multi-Access Edge Computing Using a Deep Sequential Model Based on Reinforcement Learning. IEEE Commun. Mag. 2019, 57, 64–69. [Google Scholar] [CrossRef]
- Lu, H.; He, X.; Du, M.; Ruan, X.; Sun, Y.; Wang, K. Edge QoE: Computation Offloading with Deep Reinforcement Learning for Internet of Things. IEEE Internet Things J. 2020, 7, 9255–9265. [Google Scholar] [CrossRef]
- Motlagh, N.H.; Bagaa, M.; Taleb, T. UAV Selection for a UAV-Based Integrative IoT Platform. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Galkin, B.; Kibilda, J.; DaSilva, L.A. UAVs as Mobile Infrastructure: Addressing Battery Lifetime. IEEE Commun. Mag. 2019, 57, 132–137. [Google Scholar] [CrossRef]
- Mekikis, P.-V.; Antonopoulos, A. Breaking the Boundaries of Aerial Networks with Charging Stations. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Mao, Y.; Zhang, J.; Song, S.H.; Letaief, K.B. Stochastic Joint Radio and Computational Resource Management for Multi-User Mobile-Edge Computing Systems. IEEE Trans. Wirel. Commun. 2017, 16, 5994–6009. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Nasir, Y.S.; Guo, D. Multi-Agent Deep Reinforcement Learning for Dynamic Power Allocation in Wireless Networks. IEEE J. Sel. Areas Commun. 2019, 37, 2239–2250. [Google Scholar] [CrossRef]
- Narendra, K.S.; Wang, Y.; Mukhopadhay, S. Fast Reinforcement Learning using multiple models. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 7183–7188. [Google Scholar] [CrossRef]
- Arulkumaran, N.K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 4909–4926. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Definition | Setting |
|---|---|---|
| Episode | 1,000,000 | |
| D | Replay buffer size | 1,000,000 |
| Coefficient for reward function | 1000 | |
| Coefficient for reward function | 10 | |
| Gaussian noise variance | 0.05∼0.5 | |
| Steps | 1 | |
| Discount factor | 0.1 | |
| Critic network learning rate | 0.01 | |
| Actor network learning rate | 0.01 | |
| Softupdate factor | 0.01 | |
| Number of iterations | 200 | |
| Number of particles | 100 | |
| Acceleration coefficients | 1.5 | |
| Acceleration coefficients | 1.5 | |
| Inertia weight | 0.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Liu, J.; Guo, Y.; Dong, Y.; He, Z. Learning-Based Collaborative Computation Offloading in UAV-Assisted Multi-Access Edge Computing. Electronics 2023, 12, 4371. https://doi.org/10.3390/electronics12204371
Xu Z, Liu J, Guo Y, Dong Y, He Z. Learning-Based Collaborative Computation Offloading in UAV-Assisted Multi-Access Edge Computing. Electronics. 2023; 12(20):4371. https://doi.org/10.3390/electronics12204371
Chicago/Turabian StyleXu, Zikun, Junhui Liu, Ying Guo, Yunyun Dong, and Zhenli He. 2023. "Learning-Based Collaborative Computation Offloading in UAV-Assisted Multi-Access Edge Computing" Electronics 12, no. 20: 4371. https://doi.org/10.3390/electronics12204371
APA StyleXu, Z., Liu, J., Guo, Y., Dong, Y., & He, Z. (2023). Learning-Based Collaborative Computation Offloading in UAV-Assisted Multi-Access Edge Computing. Electronics, 12(20), 4371. https://doi.org/10.3390/electronics12204371