
EDKSANet: An Efficient Dual-Kernel Split Attention Neural Network for the Classification of Tibetan Medicinal Materials

Abstract
:1. Introduction
- A total of 300 common Tibetan medicinal materials were photographed, and with the help of data enhancement strategies, a computer vision dataset of Tibetan medicinal materials was successfully constructed. This provides a new opportunity for the further use of visual deep learning to scientifically identify Tibetan medicinal materials and promote the development of the Tibetan medicinal material industry. Furthermore, this block has very flexible and scalable performance and can be directly embedded into network architectures for various computer vision tasks.
- A novel Efficient Dual-Kernel Split Attention (EDKSA) block is proposed to construct dynamic kernel-extracted features using reciprocal filters at different scales, effectively fusing symmetric feature information at multiple scales and generating long-term dependencies in channel interactions and spatially adaptive relationships, thereby increasing the richness and accuracy of feature representation.
- A novel lightweight backbone architecture, EDKSANet, is proposed. It achieves efficient unification of convolution and self-attention under the CNN architectures. EDKSANet can learn richer symmetric feature maps and dynamically calibrate the modeling between symmetric dimensions according to task requirements, thereby improving the learning and generalization capabilities of the model. After a large amount of experimental data verification, EDKSANet not only significantly improved the performance of image classification, target detection, and instance segmentation tasks on the ImageNet and MS COCO datasets but also showed amazing results in the classification tasks of Tibetan medicinal materials.
2. Related Work
2.1. Grouped/Depthwise/Shuffle/Dilated Convolutions
2.2. Dynamic Convolutions
2.3. Multi-Scale Feature Representations and Attention Mechanisms
3. Method
3.1. DKSA Module
3.2. Network Design
4. Experiments
4.1. Implementation Details
4.2. Image Classification on ImageNet
4.3. Object Detection and Instance Segmentation on MS COCO
4.4. Image Classification on Tibetan Medicinal Materials Dataset
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sakhteman, A.; Keshavarz, R.; Mohagheghzadeh, A. ATR-IR fingerprinting as a powerful method for identification of traditional medicine samples: A report of 20 herbal patterns. Res. J. Pharmacogn. 2015, 2, 1–8. [Google Scholar]
- Rohman, A.; Windarsih, A.; Hossain, M.A.M.; Johan, M.R.; Ali, M.E.; Fadzilah, N.A. Application of near-and mid-infrared spectroscopy combined with chemometrics for discrimination and authentication of herbal products: A review. J. Appl. Pharm. Sci. 2019, 9, 137–147. [Google Scholar]
- Lecun, Y.; Bottou, L. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Girshick, R. Fast R-CNN. Comput. Sci. 2015, 2015, 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the inherence of convolution for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12321–12330. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. BAM: Bottleneck Attention Module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, H.; Zu, K.; Lu, J.; Zou, Y.; Meng, D. EPSANet: An Efficient Pyramid Squeeze Attention Block on Convolutional Neural Network. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–2 December 2021. [Google Scholar]
- Sagar, A. DMSANet: Dual Multi Scale Attention Network. In Proceedings of the International Conference on Image Analysis and Processing, Lecce, Italy, 23–27 May 2022. [Google Scholar]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Bender, G.; Ngiam, J.; Le, Q.V. CondConv: Conditionally Parameterized Convolutions for Efficient Inference. arXiv 2019, arXiv:1904.04971v3. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11030–11039. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. arXiv 2017, arXiv:1703.06211. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 12. [Google Scholar] [CrossRef]
- Zhang, T.; Qi, G.J.; Xiao, B.; Wang, J. Interleaved group convolutions. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4373–4382. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the ICLR, San Juan, Puerto Rico, 2–4 June 2016. [Google Scholar]
- Jie, H.; Li, S.; Gang, S. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Yang, J.; Wang, W.; Li, X.; Hu, X. Selective Kernel Networks. arXiv 2019, arXiv:1903.06586. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Zhang, Z.; Lin, H.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R. ResNeSt: Split-Attention Networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Vasu, P.K.A.; Gabriel, J.; Zhu, J.; Tuzel, O.; Ranjan, A. FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization. arXiv 2023, arXiv:2303.14189. [Google Scholar]
- Lee, Y.; Kim, J.; Willette, J.; Hwang, S.J. Mpvit: Multi-path vision transformer for dense prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7287–7296. [Google Scholar]
- Li, K.; Wang, Y.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. Uniformer: Unified transformer for efficient spatiotemporal representation learning. arXiv 2022, arXiv:2201.04676. [Google Scholar]
- Li, K.; Wang, Y.; Zhang, J.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. Uniformer: Unifying convolution and self-attention for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12581–12600. [Google Scholar] [CrossRef] [PubMed]
- Rumelhart, D.E. Learning Internal Representations by Error Propagation, Parallel Distributed Processing. In Explorations in the Microstructure of Cognition; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines Vinod Nair. In Proceedings of the International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Output | ResNet-50 | RedNet-50 | EDKSANet-50(1) | EDKSANet-50(2) |
|---|---|---|---|---|
| 112 × 112 | 7 × 7, 64, stride 2 | |||
| 56 × 56 | 3 × 3, MaxPool, stride 2 | |||
| 56 × 56 | ||||
| 28 × 28 | ||||
| 14 × 14 | ||||
| 7 × 7 | ||||
| Platform | Framework | GPU | CPU | Video Mem | RAM | Disk |
|---|---|---|---|---|---|---|
| AI Studio | Paddle Paddle 2.2.2 | 4 × Tesla V100 | 16 Cores | 4 × 32 GB | 128 GB | 100 GB |
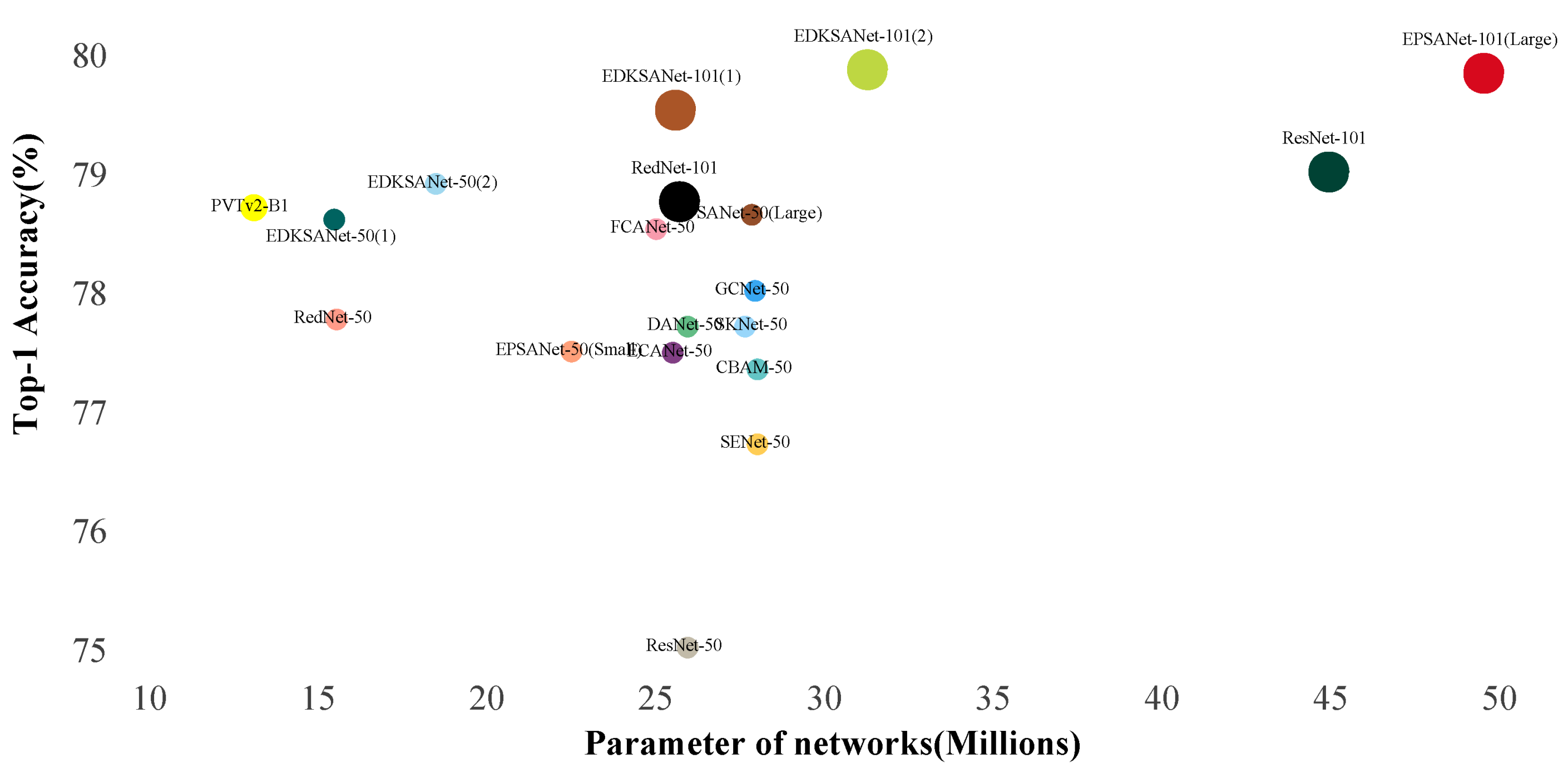
| Network | Arch. | Parameters | FLOPs | Top-1 Acc (%) |
|---|---|---|---|---|
| ResNet [5] | CNN-50 | 25.56 | 4.12 G | 75.20 |
| RedNet [12] | 15.60 | 2.61 G | 77.76 | |
| SENet [29] | 28.07 | 4.13 G | 76.71 | |
| SKNet [33] | 27.70 | 4.25 G | 77.70 | |
| CBAM [14] | 28.07 | 4.14 G | 77.34 | |
| GCNet [36] | 28.11 | 4.13 G | 77.70 | |
| DANet [32] | 25.80 | 4.15 G | 77.70 | |
| FCANet [31] | 25.07 | 4.13 G | 78.52 | |
| ECANet [30] | 25.56 | 4.13 G | 77.48 | |
| EPSANet [15] (Small) | 22.56 | 3.62 G | 77.49 | |
| EPSANet [15] (Large) | 27.90 | 4.72 G | 78.64 | |
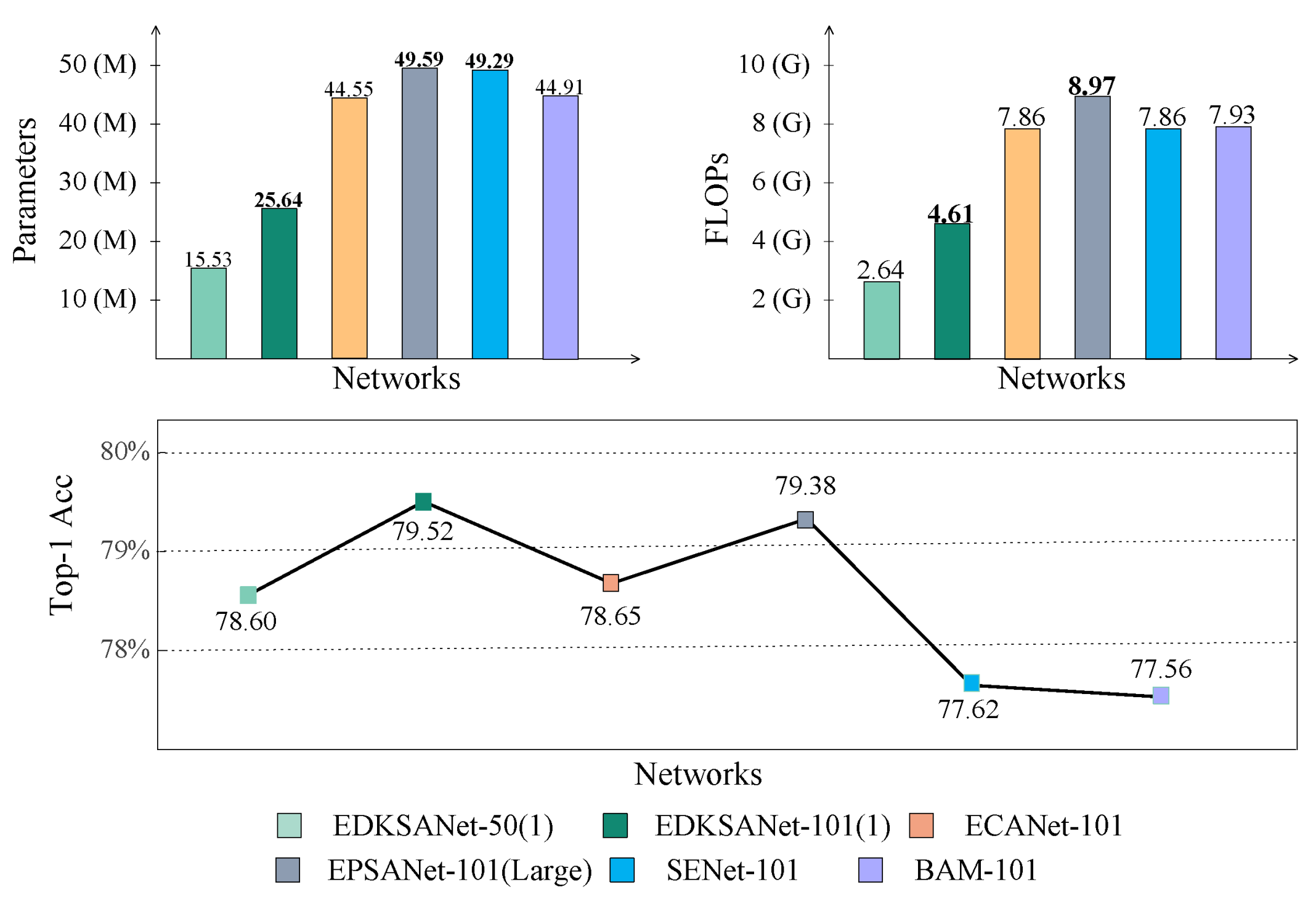
| EDKSANet(1) | 15.53 | 2.64 G | 78.60 | |
| EDKSANet(2) | 18.54 | 3.12 G | 78.90 | |
| ResNet [5] | CNN-101 | 44.65 | 7.83 G | 76.83 |
| RedNet [12] | 25.76 | 4.58 G | 78.75 | |
| SENet [29] | 49.29 | 7.86 G | 77.62 | |
| SKNet [33] | 49.20 | 8.03 G | 78.70 | |
| BAM [13] | 44.91 | 7.93 G | 77.56 | |
| CBAM [14] | 49.33 | 7.88 G | 78.49 | |
| DANet [32] | 45.40 | 8.05 G | 78.70 | |
| ECANet [30] | 44.55 | 7.86 G | 78.65 | |
| EPSANet [15] (Small) | 39.00 | 6.82 G | 78.43 | |
| EPSANet [15] (Large) | 49.59 | 8.97 G | 79.38 | |
| EDKSANet(1) | 25.64 | 4.61 G | 79.52 | |
| EDKSANet(2) | 31.33 | 5.57 G | 79.86 | |
| PVTv2-B1 [38] | CNN + Trans | 13.15 | 2.10 G | 78.70 |
| UniFormer-B [42] | 50.30 | 8.34 G | 82.50 |
| Backbone | Detectors | Parameters(M) | GFLOPs(B) | AP | |||||
|---|---|---|---|---|---|---|---|---|---|
| ResNet-50 [5] | Faster-RCNN | 41.53 | 207.07 | 36.4 | 58.2 | 39.5 | 21.8 | 40.0 | 46.2 |
| RedNet-50 [12] | 29.50 | 135.50 | 39.3 | 61.2 | 42.3 | 22.9 | 42.9 | 52.8 | |
| SENet-50 [29] | 44.02 | 207.18 | 37.6 | 60.2 | 41.0 | 23.1 | 41.8 | 48.4 | |
| ECANet-50 [30] | 41.53 | 207.18 | 38.1 | 60.5 | 40.8 | 23.4 | 42.0 | 48.0 | |
| FCANet-50 [31] | 44.02 | 215.63 | 39.0 | 61.1 | 42.3 | 23.7 | 42.8 | 49.6 | |
| EPSANet50 [15] (Small) | 38.56 | 197.07 | 39.2 | 60.3 | 42.3 | 22.8 | 42.4 | 51.1 | |
| EPSANet50 [15] (Large) | 43.85 | 219.64 | 40.6 | 62.1 | 44.6 | 23.6 | 44.5 | 54.0 | |
| EDKSANet-50(1) | 31.50 | 135.68 | 40.4 | 62.1 | 43.5 | 23.7 | 43.8 | 53.3 | |
| EDKSANEt-50(2) | 34.51 | 159.81 | 40.8 | 62.8 | 44.8 | 24.6 | 44.6 | 54.4 | |
| PVTv2-B1 [38] | 29.12 | 134.84 | 40.5 | 62.3 | 43.5 | 23.8 | 43.9 | 53.7 | |
| UniFormer-B [42] | 66.27 | 306.88 | 43.1 | 64.8 | 49.2 | 26.6 | 46.8 | 57.0 | |
| ResNet-50 [5] | Mask-RCNN | 44.18 | 275.58 | 37.2 | 58.9 | 40.3 | 22.2 | 40.7 | 48.0 |
| RedNet-50 [12] | 34.22 | 181.30 | 40.2 | 61.2 | 43.5 | 22.6 | 43.5 | 53.0 | |
| SENet-50 [29] | 46.67 | 275.69 | 38.6 | 60.8 | 42.0 | 23.6 | 42.5 | 49.9 | |
| GCNet-50 [36] | 46.90 | 279.60 | 39.4 | 61.6 | 42.4 | - | - | - | |
| ECANet-50 [30] | 44.18 | 275.69 | 39.0 | 61.3 | 42.1 | 24.2 | 42.8 | 49.9 | |
| FCANet-50 [31] | 46.66 | 261.93 | 40.3 | 62.0 | 44.1 | 25.2 | 43.9 | 52.0 | |
| EPSANet50 [15] (Small) | 41.20 | 248.53 | 40.0 | 60.9 | 43.3 | 22.3 | 43.2 | 52.8 | |
| EPSANet50 [15] (Large) | 46.50 | 271.10 | 41.1 | 62.3 | 45.3 | 23.6 | 45.1 | 54.6 | |
| EDKSANet-50(1) | 34.15 | 184.08 | 40.9 | 61.8 | 44.4 | 23.5 | 44.4 | 53.7 | |
| EDKSANEt-50(2) | 37.16 | 217.56 | 41.5 | 62.8 | 45.5 | 24.2 | 45.6 | 54.9 | |
| PVTv2-B1 [38] | 32.33 | 189.02 | 41.2 | 62.4 | 45.3 | 23.8 | 49.8 | 53.8 | |
| UniFormer-B [41] | 68.48 | 400.92 | 44.0 | 65.1 | 47.2 | 26.2 | 47.8 | 56.8 |
| Network | Arch. | Parameters | FLOPs | Top-1 Acc (%) |
|---|---|---|---|---|
| ResNet | CNN | 24.18 | 4.12 G | 90.84 |
| RedNet | 14.16 | 2.61 G | 92.30 | |
| EDKSANet(1) | 14.09 | 2.64 G | 95.57 | |
| EDKSANet(2) | 17.11 | 3.12 G | 96.85 | |
| PVTv2-B1 | CNN + Trans | 13.15 | 2.10 G | 96.10 |
| Kernel | Kernel Sizen | Group Size | Top-1 Acc (%) |
|---|---|---|---|
| 3 | 1 | 75.2 | |
| 3 | C/16 | 76.9 | |
| (, ) | (3, 3) | (1, C/16) | 77.9 |
| (, ) | (3, 7) | (C/32, 16) | 78.6 |
| (, ) | (3, 7) | (32, C/16) | 78.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, J.; Wangdui, B.; Jiang, J.; Yang, J.; Zhou, Y. EDKSANet: An Efficient Dual-Kernel Split Attention Neural Network for the Classification of Tibetan Medicinal Materials. Electronics 2023, 12, 4330. https://doi.org/10.3390/electronics12204330
Qi J, Wangdui B, Jiang J, Yang J, Zhou Y. EDKSANet: An Efficient Dual-Kernel Split Attention Neural Network for the Classification of Tibetan Medicinal Materials. Electronics. 2023; 12(20):4330. https://doi.org/10.3390/electronics12204330
Chicago/Turabian StyleQi, Jindong, Bianba Wangdui, Jun Jiang, Jie Yang, and Yanxia Zhou. 2023. "EDKSANet: An Efficient Dual-Kernel Split Attention Neural Network for the Classification of Tibetan Medicinal Materials" Electronics 12, no. 20: 4330. https://doi.org/10.3390/electronics12204330
APA StyleQi, J., Wangdui, B., Jiang, J., Yang, J., & Zhou, Y. (2023). EDKSANet: An Efficient Dual-Kernel Split Attention Neural Network for the Classification of Tibetan Medicinal Materials. Electronics, 12(20), 4330. https://doi.org/10.3390/electronics12204330