
ConKgPrompt: Contrastive Sample Method Based on Knowledge-Guided Prompt Learning for Text Classification


Abstract
:1. Introduction
2. Related Works
2.1. Prompt Based Fine-Tuning
2.2. Contrastive Learning
2.3. Knowledge Utilization
3. Preliminaries
3.1. Fine-Tuning Based on PLMs
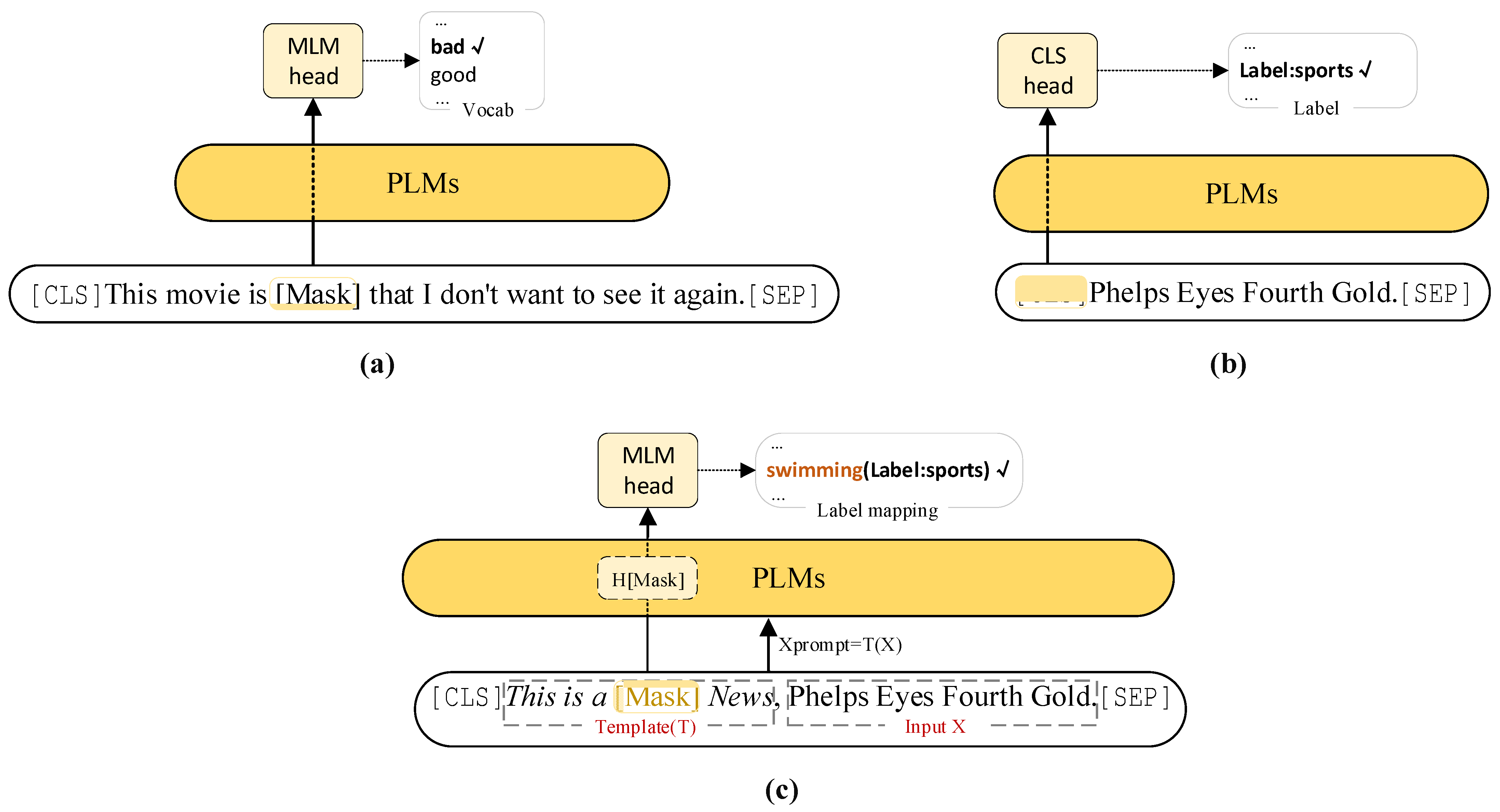
3.2. Prompt-Tuning Based on PLMs
3.3. Supervised Contrastive Learning
4. Related Theory
4.1. Prompt Engineering
4.1.1. Prompt Template Construction
4.1.2. Verbalizer Construction
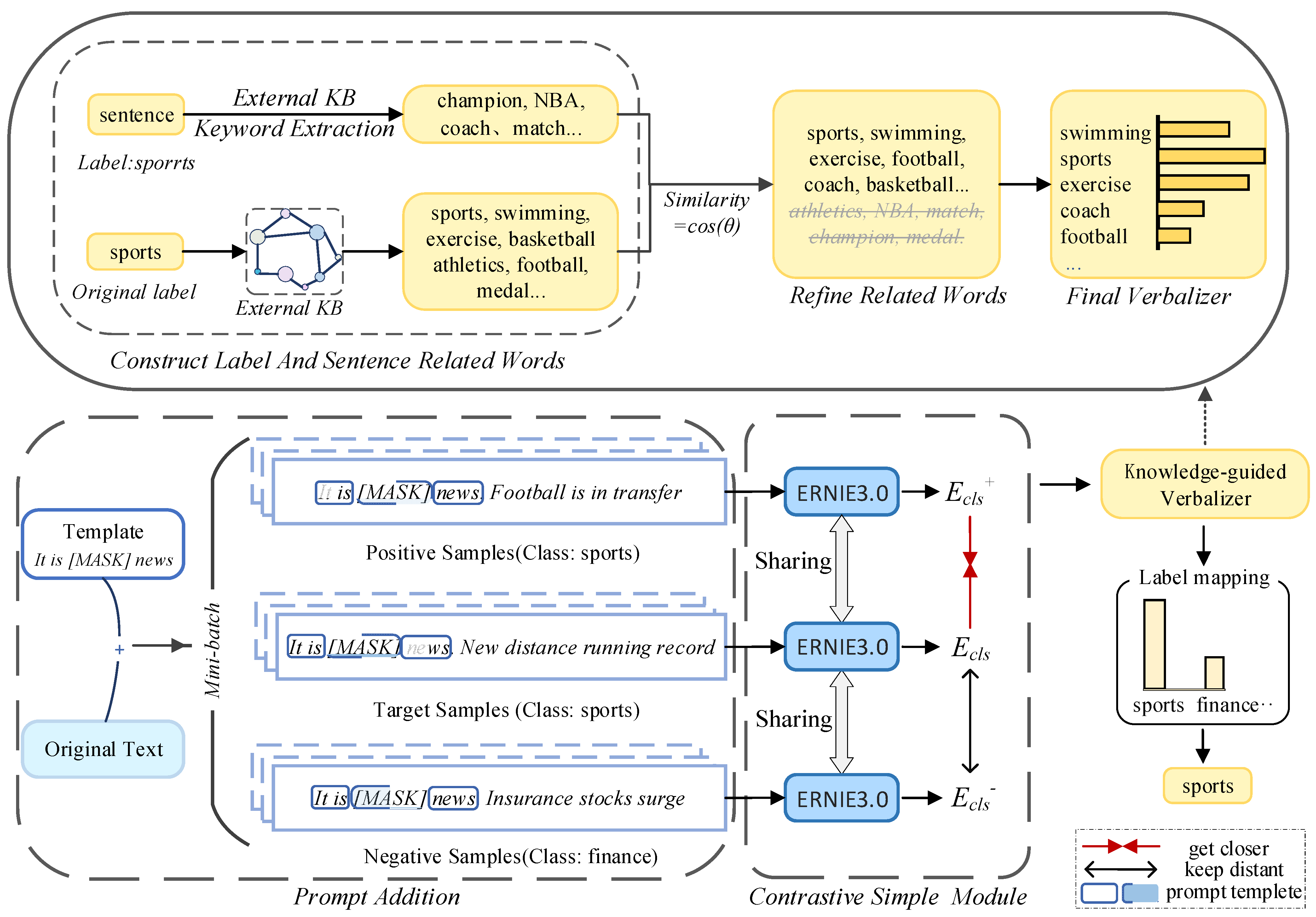
4.2. External Knowledge Acquisition
4.2.1. Label Related Word Set Construction
4.2.2. Text Keyword Extraction
4.2.3. Verbalizer Refinement
4.3. Knowledge Enhanced Pre-Training Model ERNIE 3.0
4.4. Supervised Contrastive Simple Module
5. Experiments
5.1. Dataset and Templates
5.2. Baselines
5.3. Experiment Settings
5.4. Main Results
5.4.1. Full-Data
5.4.2. Few-Shot
5.5. Ablation Study
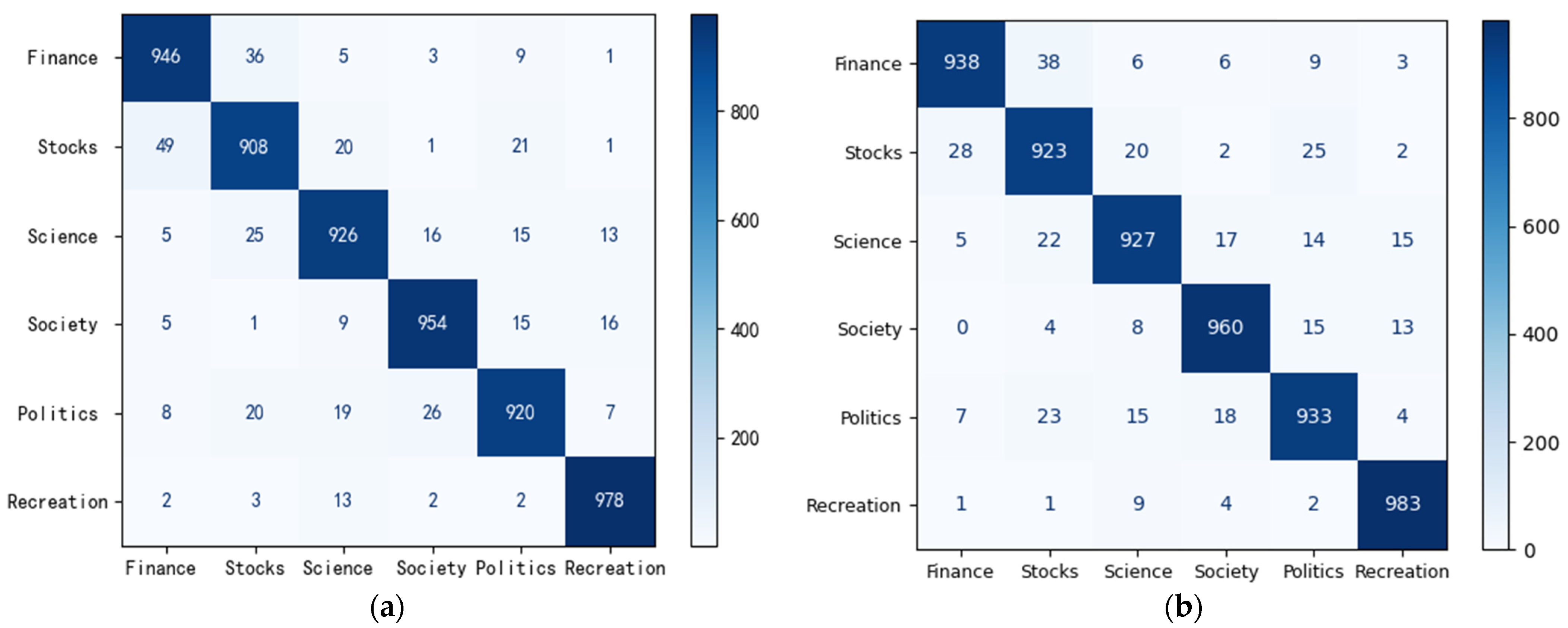
6. Analysis
6.1. Performance Influence between Different Pre-Trained Language Models
6.2. Impact of Knowledge-Guided Prompt Learning
6.3. Impact of Contrastive Sample Module
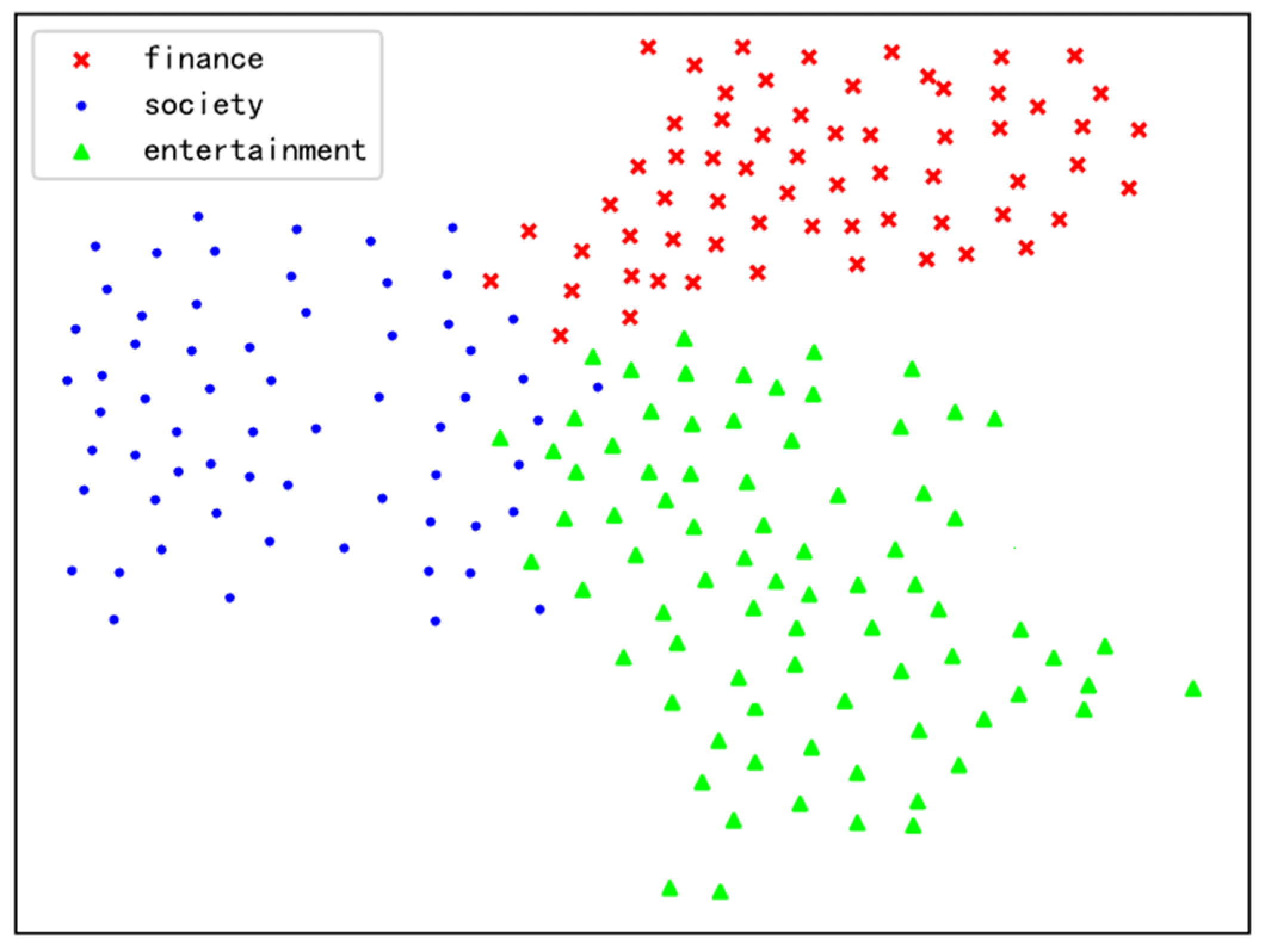
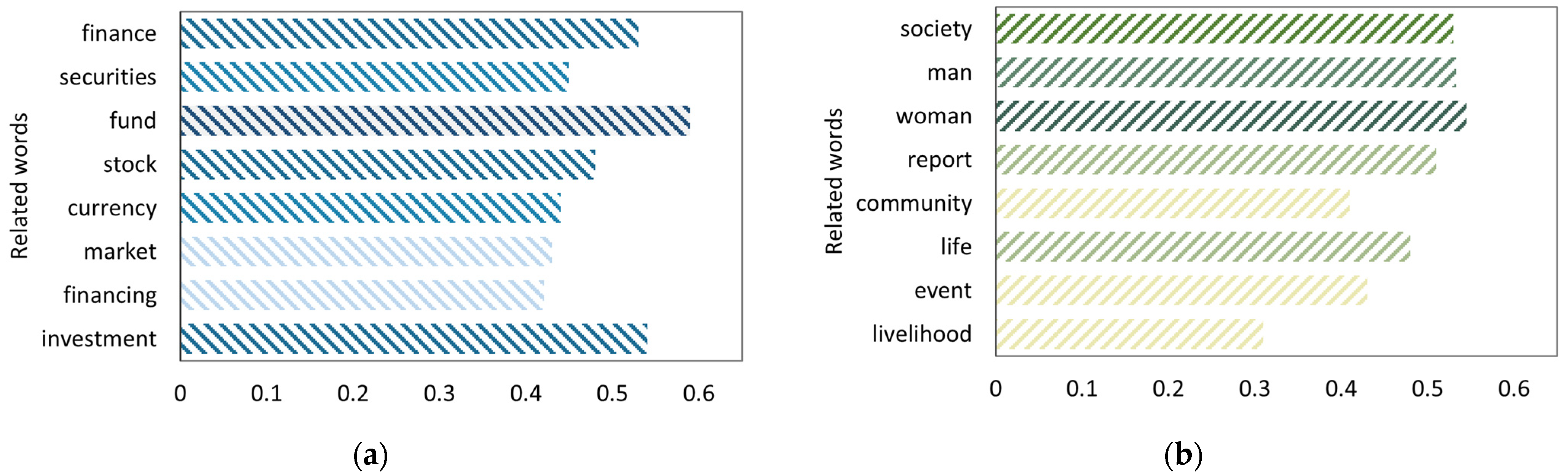
6.4. Visualization of Label Related Word Weights
6.5. Hyperparameter Influence
7. Discussion
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tang, J.W.; Li, R.X.; Wang, K.P.; Gu, X.W.; Xu, Z.Y. A Novel Hybrid Method to Analyze Security Vulnerabilities in Android Applications. Tsinghua Sci. Technol. 2020, 25, 589–603. [Google Scholar] [CrossRef]
- Zhao, B.; Zhao, P.Y.; Fan, P.R. ePUF: A Lightweight Double Identity Verification in IoT. Tsinghua Sci. Technol. 2020, 25, 625–635. [Google Scholar] [CrossRef]
- Pagolu, V.S.; Reddy, K.N.; Panda, G.; Majhi, B. Sentiment analysis of Twitter data for predicting stock market movements. In Proceedings of the 2016 International Conference on Signal Processing, Communication, Power and Embedded System (SCOPES), Paralakhemundi, India, 3–5 October 2016; pp. 1345–1350. [Google Scholar]
- Debnath, K.; Kar, N. Email spam detection using deep learning approach. In Proceedings of the 2022 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COM-IT-CON), Faridabad, India, 26–27 May 2022; pp. 37–41. [Google Scholar]
- Guo, Y.; Lamaazi, H.; Mizouni, R. Smart edge-based fake news detection using pre-trained BERT model. In Proceedings of the 2022 18th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Thessaloniki, Greece, 10–12 October 2022; pp. 437–442. [Google Scholar]
- Kim, Y.J. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X.J. Recurrent neural network for text classification with multi-task learning. arXiv 2016, arXiv:1605.05101. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K.J. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, (Long and Short Papers). pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V.J. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. In Proceedings of the 34th Conference on Neural Information Processing Systems, Online, 6–12 December 2020; pp. 1877–1901. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Chen, X.; Zhang, H.; Tian, X.; Zhu, D.; Tian, H.; Wu, H.J. Ernie: Enhanced representation through knowledge integration. arXiv 2019, arXiv:1904.09223. [Google Scholar]
- Su, Y.S.; Han, X.; Lin, Y.K.; Zhang, Z.Y.; Liu, Z.Y.; Li, P.; Zhou, J.; Sun, M.S. CSS-LM: A Contrastive Framework for Semi-Supervised Fine-Tuning of Pre-Trained Language Models. IEEE ACM Trans. Audio Speech Lang. Process. 2021, 29, 2930–2941. [Google Scholar] [CrossRef]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J.J. GPT understands, too. arXiv 2021, arXiv:2103.10385. [Google Scholar] [CrossRef]
- Gao, T.; Fisch, A.; Chen, D.J. Making pre-trained language models better few-shot learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; pp. 3816–3830. [Google Scholar]
- Schick, T.; Schütze, H.J. It’s not just size that matters: Small language models are also few-shot learners. arXiv 2020, arXiv:2009.07118. [Google Scholar]
- Hu, S.; Ding, N.; Wang, H.; Liu, Z.; Wang, J.; Li, J.; Wu, W.; Sun, M.J. Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification. In Proceedings of the 60th Annual Meeting of the Association for Computational linguistics, Dublin, Ireland, 22–27 May 2022; pp. 2225–2240. [Google Scholar]
- Sun, Y.; Wang, S.; Feng, S.; Ding, S.; Pang, C.; Shang, J.; Liu, J.; Chen, X.; Zhao, Y.; Lu, Y.J. Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation. arXiv 2021, arXiv:2107.02137. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. In Proceedings of the 34th Conference on Neural Information Processing Systems, Online, 6–12 December 2020; pp. 18661–18673. [Google Scholar]
- Dan, Y.; Zhou, J.; Chen, Q.; Bai, Q.; He, L. Enhancing class understanding via prompt-tuning for zero-shot text classification. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 4303–4307. [Google Scholar]
- Zhang, W.; Song, X.; Feng, Z.; Xu, T.; Wu, X.J. LabelPrompt: Effective Prompt-based Learning for Relation Classification. arXiv 2023, arXiv:2302.08068. [Google Scholar]
- You, Y.; Jiang, Z.; Zhang, K.; Jiang, J.; Wang, X.; Zhang, Z.; Wang, S.; Feng, H. TI-Prompt: Towards a Prompt Tuning Method for Few-shot Threat Intelligence Twitter Classification. In Proceedings of the 2022 IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC), Los Alamitos, CA, USA, 27 June–1 July 2022; pp. 272–279. [Google Scholar]
- Zhang, H.; Liang, B.; Yang, M.; Wang, H.; Xu, R.F. Prompt-Based Prototypical Framework for Continual Relation Extraction. IEEE ACM Trans. Audio Speech Lang. Process. 2022, 30, 2801–2813. [Google Scholar] [CrossRef]
- Shin, T.; Razeghi, Y.; Logan IV, R.L.; Wallace, E.; Singh, S.J. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–18 November 2020; pp. 4222–4235. [Google Scholar]
- Schick, T.; Schütze, H.J. Exploiting cloze questions for few shot text classification and natural language inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; pp. 255–269. [Google Scholar]
- Jiang, T.; Jiao, J.; Huang, S.; Zhang, Z.; Wang, D.; Zhuang, F.; Wei, F.; Huang, H.; Deng, D.; Zhang, Q.J. Promptbert: Improving bert sentence embeddings with prompts. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 8826–8837. [Google Scholar]
- Gao, T.; Yao, X.; Chen, D.J. Simcse: Simple contrastive learning of sentence embeddings. arXiv 2021, arXiv:2104.08821. [Google Scholar]
- Guo, J.; Zhao, B.; Liu, H.; Liu, Y.; Zhong, Q.J.T.S. Technology Supervised contrastive learning with term weighting for improving Chinese text classification. Tsinghua Sci. Technol. 2022, 28, 59–68. [Google Scholar] [CrossRef]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-bert: Enabling language representation with knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 2901–2908. [Google Scholar]
- Liu, J.; Zhang, Z.; Guo, Z.; Jin, L.; Li, X.; Wei, K.; Sun, X.J.K.-B.S. KEPT: Knowledge Enhanced Prompt Tuning for event causality identification. Knowl. Based Syst. 2023, 259, 110064. [Google Scholar] [CrossRef]
- Song, C.; Cai, F.; Wang, M.; Zheng, J.; Shao, T.J.K.-B.S. TaxonPrompt: Taxonomy-aware curriculum prompt learning for few-shot event classification. Knowl. Based Syst. 2023, 264, 110290. [Google Scholar] [CrossRef]
- Qi, F.; Zhang, L.; Yang, Y.; Liu, Z.; Sun, M. Wantwords: An open-source online reverse dictionary system. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 175–181. [Google Scholar]
- Xu, B.; Xu, Y.; Liang, J.; Xie, C.; Liang, B.; Cui, W.; Xiao, Y. CN-DBpedia: A never-ending Chinese knowledge extraction system. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Online, 27–30 June 2017; pp. 428–438. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R.J. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Xu, L.; Lu, X.; Yuan, C.; Zhang, X.; Xu, H.; Yuan, H.; Wei, G.; Pan, X.; Tian, X.; Qin, L.J. Fewclue: A Chinese few-shot learning evaluation benchmark. arXiv 2021, arXiv:2107.07498. [Google Scholar]
- Chen, Q.; Zhang, R.; Zheng, Y.; Mao, Y.J. Dual contrastive learning: Text classification via label-aware data augmentation. arXiv 2022, arXiv:2201.08702. [Google Scholar]
- Hambardzumyan, K.; Khachatrian, H.; May, J.J. Warp: Word-level adversarial reprogramming. In Proceedings of the Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; pp. 4921–4933. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Task Type | Classes | Average Length | Training | Test |
|---|---|---|---|---|---|
| THUCNews | Topic classification | 6 | 54 | 48,000 | 6000 |
| Tnews | Topic classification | 15 | 65 | 1185 | 2010 |
| Healthcare | Question classification | 5 | 46 | 10,800 | 1906 |
| Onshop | Sentiment classification | 2 | 78 | 50,220 | 6275 |
| Datasets | Template |
|---|---|
| THUCNews | A [MASK] news: <Input> It is a [MASK] news: <Input> <Input> This topic is about [MASK] [News: [MASK]] <Input> |
| Tnews | A [MASK] news: <Input> It is a [MASK] news: <Input> <Input> This topic is about [MASK] [News: [MASK]] <Input> |
| Healthcare | A [MASK] question: <Input> It is a [MASK] question: <Input> <Input> This topic is about [MASK] [Category: [MASK]] <Input> |
| Onshop | It was [MASK]: <Input> This was [MASK]: <Input> Just [MASK]: <Input> <Input> All in all, it was [MASK] <Input> In summary, it was [MASK] |
| Methods | THUCNews | Healthcare | Onshop | |
|---|---|---|---|---|
| ERNIE 3.0-Xbase | Fine-tuning | 93.22 ± 0.34 (93.4) | 92.69 ± 0.55 (93.0) | 94.46 ± 0.65 (95.1) |
| DualCL | 93.41 ± 0.23 (93.5) | 92.92 ± 0.36 (93.2) | 94.62 ± 0.78 (95.3) | |
| PET | 93.27 ± 0.41 (93.6) | 92.63 ± 0.31 (93.1) | 94.68 ± 0.83 (95.4) | |
| P-tuning | 93.53 ± 0.24 (93.8) | 92.47 ± 0.41 (92.8) | 94.87 ± 0.71 (95.5) | |
| Soft | 93.32 ± 0.35 (93.6) | 92.68 ± 0.51 (93.3) | 94.92 ± 0.60 (95.5) | |
| Ours w/o SCL | 93.83 ± 0.30 (94.1) | 93.10 ± 0.68 (94.3) | 94.95 ± 0.61 (95.6) | |
| Ours | 94.04 ± 0.16 (94.5) | 93.84 ± 0.64 (94.8) | 95.67 ± 0.54 (96.2) | |
| k-Shot | Methods | THUCNews | Tnews | Healthcare | Onshop |
|---|---|---|---|---|---|
| 1-shot | PET | 51.75 ± 10.20 (60.5) | 39.40 ± 3.73 (43.1) | 53.73 ± 6.61 (60.8) | 52.11 ± 10.32 (59.9) |
| P-tuning | 47.78 ± 5.34 (52.9) | 38.96 ± 5.16 (44.9) | 61.76 ± 5.57 (70.1) | 48.71 ± 5.56 (54.9) | |
| Soft | 48.91 ± 1.97 (50.5) | 40.88 ± 6.17 (46.2) | 61.26 ± 9.59 (71.9) | 48.14 ± 4.98 (55.2) | |
| KPT | 57.43 ± 3.03 (62.3) | 45.11 ± 4.81 (45.8) | 60.59 ± 7.20 (67.2) | 58.23 ± 3.54 (62.1) | |
| Ours w/o SCL | 58.58 ± 3.73 (61.1) | 45.97 ± 1.72 (48.1) | 63.61 ± 8.81 (73.8) | 59.31 ± 7.11 (66.8) | |
| Ours | 61.19 ± 3.79 (67.5) | 46.80 ± 1.87 (49.1) | 64.01 ± 9.41 (75.8) | 62.31 ± 8.42 (71.1) | |
| 5-shot | PET | 74.96 ± 2.88 (79.1) | 49.95 ± 2.71 (52.4) | 72.44 ± 2.19 (73.8) | 73.87 ± 2.75 (78.1) |
| P-tuning | 71.02 ± 3.25 (74.9) | 49.87 ± 2.20 (52.1) | 79.92 ± 2.96 (83.3) | 74.45 ± 3.53 (79.2) | |
| Soft | 77.95 ± 2.25 (79.6) | 52.72 ± 0.63 (53.5) | 79.11 ± 4.98 (82.7) | 73.54 ± 2.94 (78.6) | |
| KPT | 77.45 ± 2.37 (80.1) | 52.54 ± 1.77 (53.9) | 81.39 ± 3.19 (83.9) | 75.86 ± 2.43 (79.4) | |
| Ours w/o SCL | 79.67 ± 2.29 (81.7) | 53.10 ± 1.21 (54.1) | 81.95 ± 2.08 (84.3) | 78.13 ± 2.78 (81.4) | |
| Ours | 81.45 ± 1.75 (83.5) | 53.62 ± 1.06 (54.7) | 82.15 ± 2.83 (84.9) | 81.94 ± 2.36 (84.3) | |
| 10-shot | PET | 79.82 ± 2.34 (82.8) | 52.92 ± 1.71 (55.3) | 81.32 ± 1.61 (83.4) | 79.11 ± 2.97 (82.2) |
| P-tuning | 80.96 ± 2.14 (83.2) | 52.76 ± 1.83 (55.1) | 83.17 ± 1.59 (84.8) | 80.42 ± 2.67 (83.8) | |
| Soft | 82.82 ± 1.31 (83.9) | 53.19 ± 1.40 (55.2) | 83.01 ± 2.14 (84.1) | 80.11 ± 2.32 (82.6) | |
| KPT | 81.91 ± 2.27 (83.6) | 53.74 ± 1.74 (55.4) | 82.39 ± 1.60 (84.6) | 81.98 ± 2.24 (84.1) | |
| Ours w/o SCL | 82.65 ± 1.55 (83.5) | 54.29 ± 1.07 (55.8) | 83.51 ± 1.31 (84.9) | 82.87 ± 1.57 (84.5) | |
| Ours | 84.61 ± 0.29 (84.9) | 54.43 ± 1.22 (55.9) | 83.98 ± 1.01 (85.2) | 84.18 ± 1.81 (85.1) | |
| 20-shot | PET | 84.84 ± 1.41 (85.9) | 54.60 ± 1.15 (55.3) | 84.61 ± 0.92 (85.3) | 84.34 ± 1.52 (85.9) |
| P-tuning | 85.16 ± 1.65 (86.4) | 53.81 ± 1.39 (55.7) | 86.08 ± 0.79 (86.9) | 85.36 ± 1.15 (86.5) | |
| Soft | 84.59 ± 0.61 (85.3) | 54.64 ± 0.73 (55.4) | 85.62 ± 0.62 (86.3) | 84.79 ± 1.35 (86.1) | |
| KPT | 85.03 ± 0.97 (85.8) | 55.34 ± 0.67 (55.8) | 86.13 ± 0.58 (86.8) | 86.36 ± 0.65 (86.9) | |
| Ours w/o SCL | 86.53 ± 0.21 (86.8) | 55.85 ± 0.38 (55.9) | 86.54 ± 0.62 (87.4) | 86.97 ± 0.95 (87.8) | |
| Ours | 87.42 ± 0.24 (87.7) | 56.12 ± 0.57 (56.4) | 87.25 ± 0.72 (88.4) | 87.32 ± 0.82 (88.2) |
| k-Shot | Methods | THUCNews | Tnews | Healthcare | Onshop |
|---|---|---|---|---|---|
| 10-shot | ConKgPrompt | 84.61 ± 0.29 (84.9) | 54.43 ± 1.22 (55.9) | 83.98 ± 1.01 (85.2) | 84.18 ± 1.81 (85.1) |
| w/o SCL | 82.65 ± 1.55 (83.5) | 54.29 ± 1.07 (55.8) | 83.51 ± 1.31 (84.9) | 82.87 ± 1.57 (84.5) | |
| w/o EKA | 82.42 ± 1.23 (83.6) | 54.14 ± 1.34 (55.4) | 82.89 ± 1.54 (84.8) | 82.57 ± 1.04 (83.7) | |
| w/0 BOTH | 81.36 ± 1.84 (83.1) | 53.46 ± 1.61 (55.1) | 82.57 ± 1.61 (84.1) | 81.89 ± 1.68 (83.6) | |
| 20-shot | ConKgPrompt | 87.42 ± 0.24 (87.7) | 56.12 ± 0.57 (56.4) | 87.25 ± 0.72 (88.4) | 87.32 ± 0.82 (88.2) |
| w/o SCL | 86.53 ± 0.21 (86.8) | 55.85 ± 0.38 (55.9) | 86.54 ± 0.62 (87.4) | 86.97 ± 0.95 (87.8) | |
| w/0 EKA | 86.01 ± 0.34 (86.2) | 55.94 ± 0.52 (56.2) | 86.32 ± 0.77 (87.2) | 86.51 ± 1.35 (87.8) | |
| w/0 BOTH | 85.83 ± 0.81 (86.7) | 55.63 ± 0.58 (55.9) | 86.37 ± 0.61 (86.9) | 85.98 ± 1.52 (87.4) |
| PLM | THUCNews | Healthcare | Onshop | Avg | |
|---|---|---|---|---|---|
| BERT | base | 92.78 ± 0.16 (92.9) | 92.49 ± 0.23 (92.5) | 94.78 ± 0.24 (95.1) | 93.35 |
| RoBERTa | base | 93.19 ± 0.24 (93.3) | 92.41 ± 0.21 (92.6) | 94.87 ± 0.31 (95.2) | 93.49 |
| ERNIE 3.0 | base | 93.41 ± 0.19 (93.5) | 92.77 ± 0.27 (93.0) | 95.51 ± 0.78 (96.3) | 93.90 |
| Xbase | 94.04 ± 0.16 (94.5) | 93.84 ± 0.64 (94.8) | 95.67 ± 0.54 (96.2) | 94.52 | |
| Actual Positive | Actual Negative | |
|---|---|---|
| Predict Positive | True Positive (TP) | False Positive (FP) |
| Predict Negative | False Negative (FN) | True Negative (TN) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Zeng, C.; Li, B.; He, P. ConKgPrompt: Contrastive Sample Method Based on Knowledge-Guided Prompt Learning for Text Classification. Electronics 2023, 12, 3656. https://doi.org/10.3390/electronics12173656
Wang Q, Zeng C, Li B, He P. ConKgPrompt: Contrastive Sample Method Based on Knowledge-Guided Prompt Learning for Text Classification. Electronics. 2023; 12(17):3656. https://doi.org/10.3390/electronics12173656
Chicago/Turabian StyleWang, Qian, Cheng Zeng, Bing Li, and Peng He. 2023. "ConKgPrompt: Contrastive Sample Method Based on Knowledge-Guided Prompt Learning for Text Classification" Electronics 12, no. 17: 3656. https://doi.org/10.3390/electronics12173656
APA StyleWang, Q., Zeng, C., Li, B., & He, P. (2023). ConKgPrompt: Contrastive Sample Method Based on Knowledge-Guided Prompt Learning for Text Classification. Electronics, 12(17), 3656. https://doi.org/10.3390/electronics12173656