
Virtual Network Function Migration Considering Load Balance and SFC Delay in 6G Mobile Edge Computing Networks


Abstract
1. Introduction
- First, in NFV-enabled environments, VNF instances are commonly shared by multiple SFCs for efficient use of network resources. However, most previous studies on VNF migration have ignored this aspect and assumed that each VNF instance is only used by a single SFC. This simplifies the design of VNF migration schemes, as only the impact on one SFC needs to be considered.
- Another issue with dynamic network services is the possibility of multiple physical links or nodes overloading simultaneously. VNF instance migration is often performed concurrently to address this problem. However, there is limited literature on this particular problem.
- Finally, most solutions for VNF migration in SFCRs operate using rule-based algorithms and cannot execute intelligent migrations. This often results in the need for complicated strategy development and reduced efficiency when computing routing paths.
- The VNF migration problem is formulated as a mathematical model. Since VNF instance sharing is considered, one VNF may serve multiple SFCs. It means that migrating one VNF instance may affect all SFCs that use it, making our work different from most current work. While the problem is more complex, it is more in line with the requirements of real cloud datacenter networks.
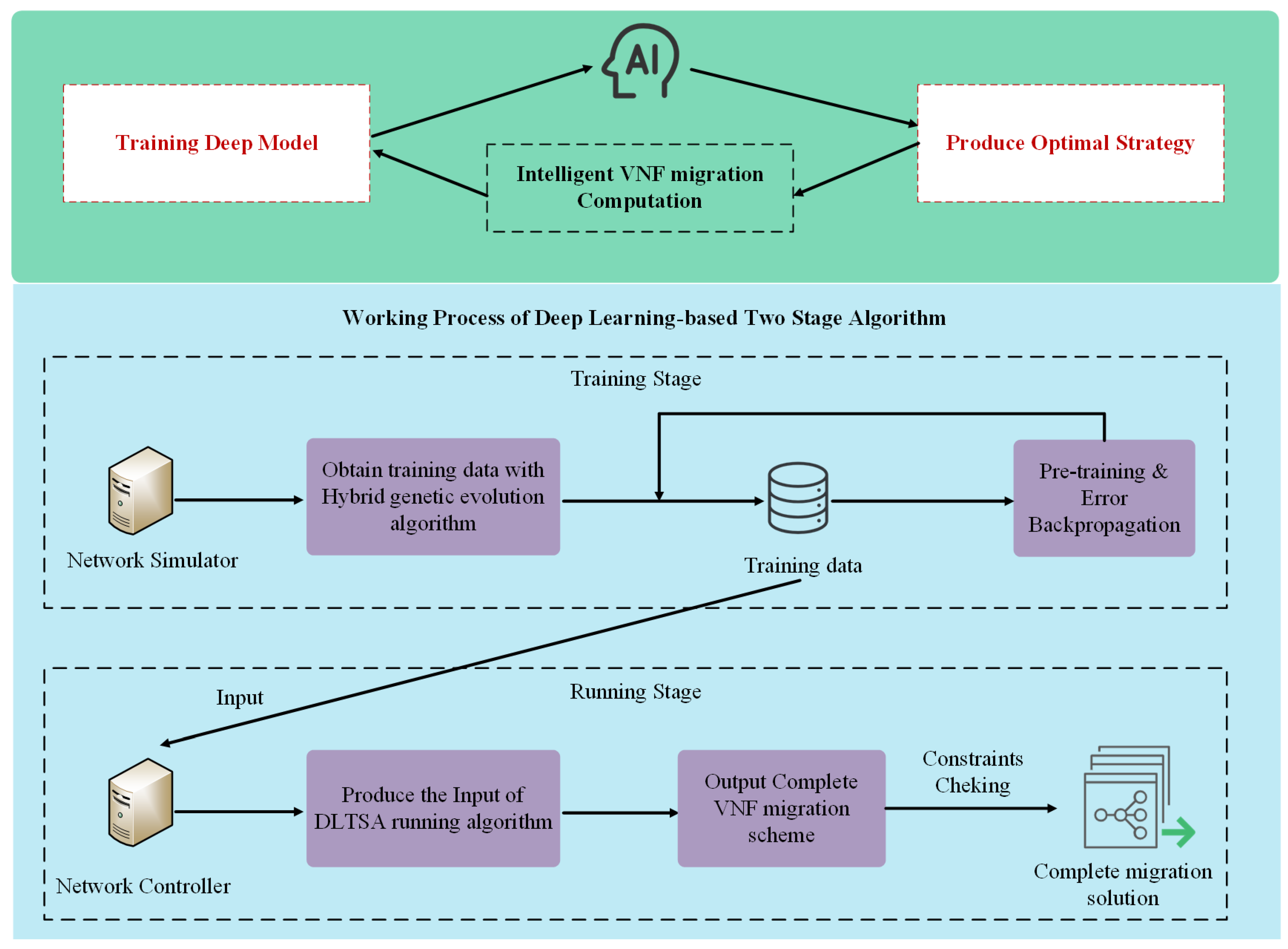
- We propose a Deep-Learning-based Two-Stage Algorithm (DLTSA) to solve the problem. This algorithm comprises two components: a hybrid genetic evolution algorithm and a running algorithm. The former generates training data using available resources and various SFCRs, while the latter handles the migration of VNFs based on the gathered training data.
- We conduct a detailed analysis of DLTSA and evaluate DLTSA in cloud datacenter networks of different sizes. The performance evaluation results show that our proposed solution can effectively guarantee the network load balance after VNF migration. Additionally, it can provide a lower SFC average delay after migration than the benchmark.
2. Related Works
3. System Model
3.1. Network Model
3.2. SFC Requests
3.3. VNF Forward Graph
4. Problem Formulation
5. Proposed Algorithm
5.1. Genetic Evolution on VNF Migration
5.1.1. Initialization
5.1.2. Fitness Calculation
5.1.3. Individual Selection
5.1.4. Crossover and Mutation
| Algorithm 1 Hybrid genetic evolution algorithm. |
| Input: Physical network , VNF-FG , Set of SFCRs R, . Output: .
|
| Algorithm 2 Best fit decreasing algorithm. |
| Input: Physical network , VNF-FG , Set of VNF instances to be migrated. Output: Initial population .
|
5.2. Pre-Stage in Hybrid Genetic Evolution Algorithm
5.3. Running Algorithm of DLTSA
| Algorithm 3 Running algorithm of DLTSA. |
| Input: Training data , Physical network , VNF-FG , Set of SFCRs R. Output: Complete migration solution .
|
6. Performance Evaluation
6.1. Simulation Setup
6.2. Contrastive Benchmarks
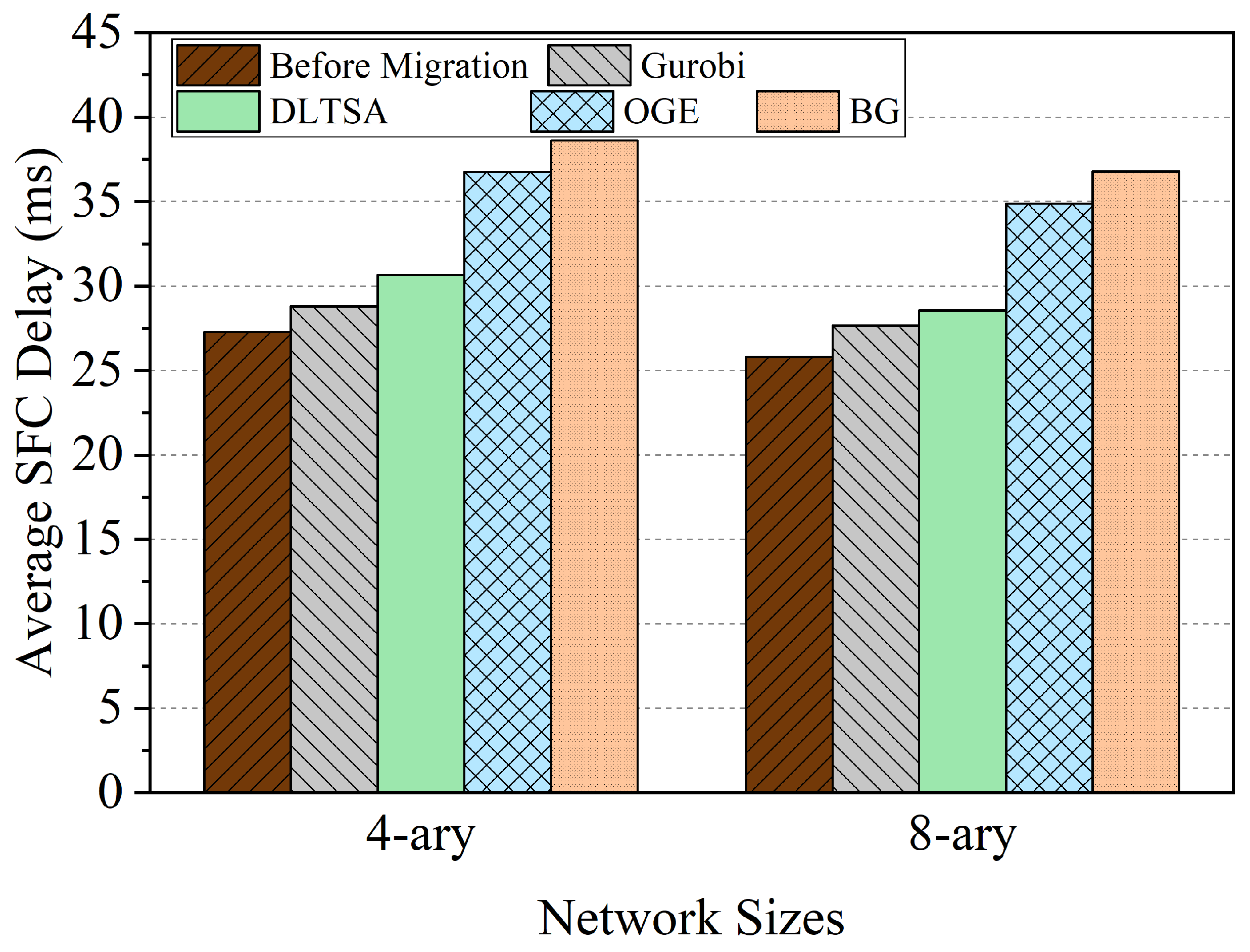
- To solve small-scale problems, we use Gurobi [32], a mathematical programming solver with precise algorithms like branch and bound. Gurobi can solve complex mathematical models efficiently by traversing the solution space. However, for larger networks, Gurobi’s execution time increases dramatically, and it may crash before completing the task. Therefore, we only use Gurobi as a small and medium-scale network baseline.
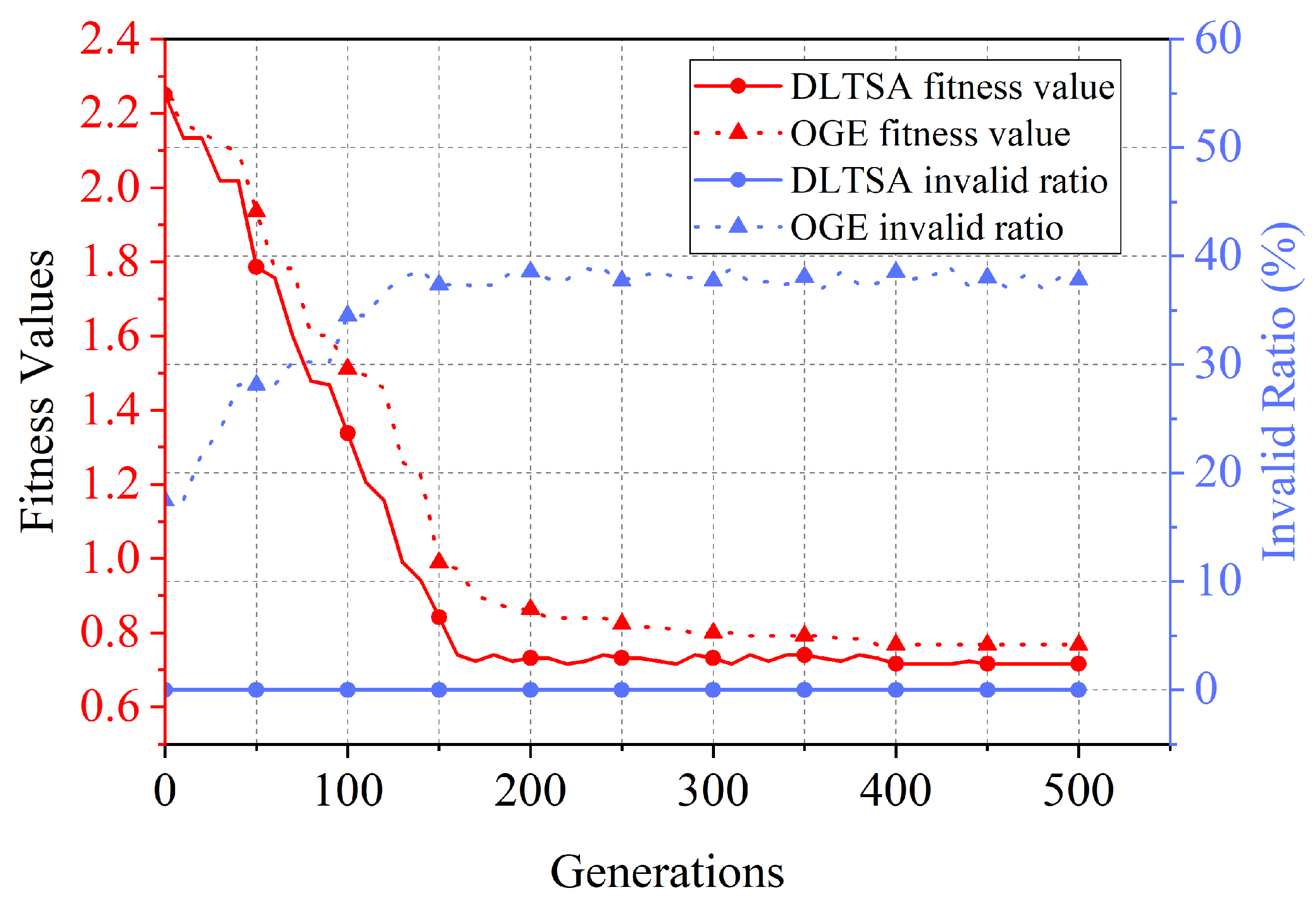
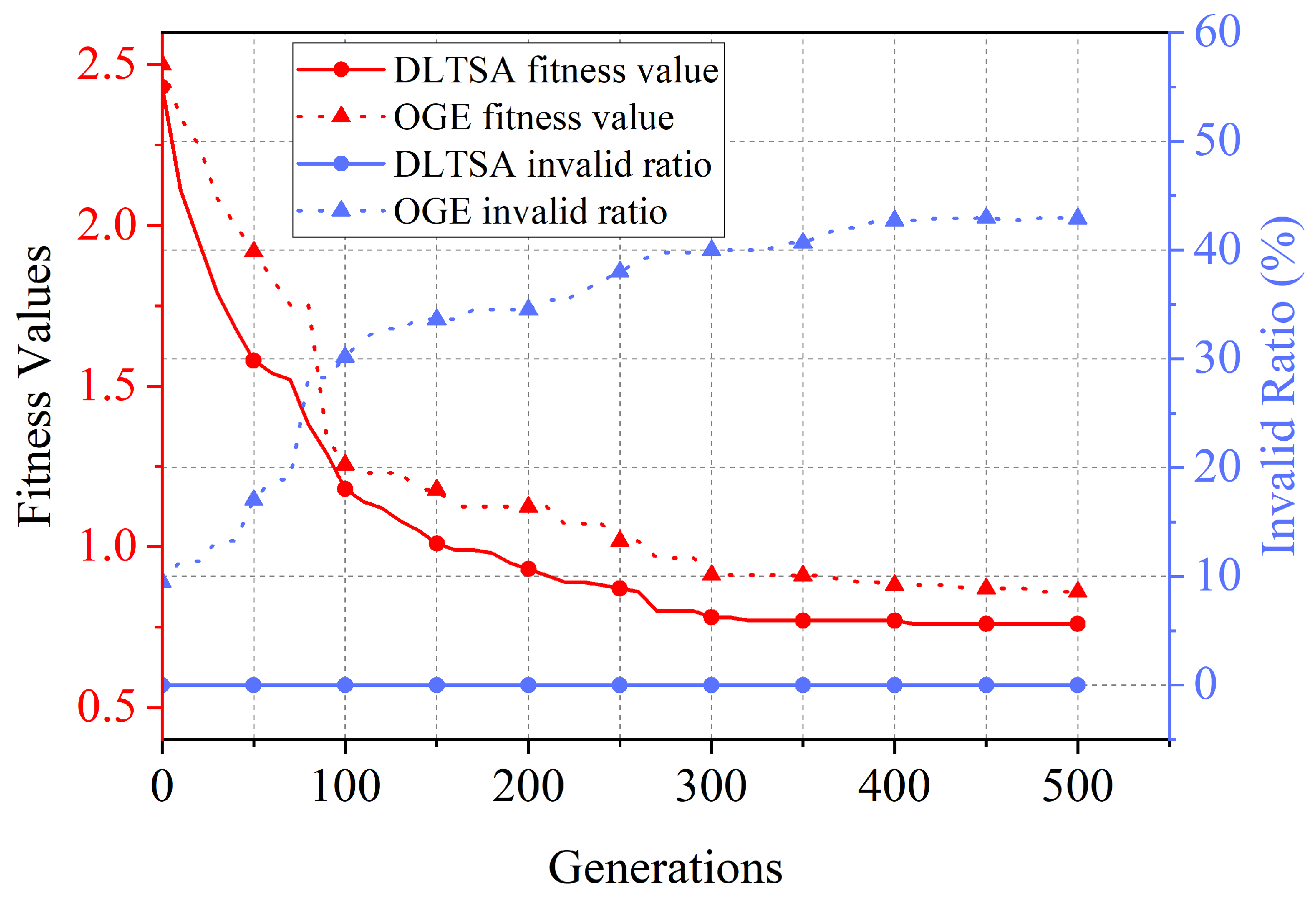
- To compare the convergence of the DLTSA in the evolution process, we introduce the unimproved Original Genetic Evolution algorithm (OGE) as the baseline. It is important to note that the OGE algorithm generates initial individuals randomly and does not use the best-fit decreasing heuristic for optimization.
- The Backtracking-based Greedy algorithm (BG) [33] determines migration decisions based on the memory size of the migration service. It employs two variables, allocation ratio, and backtracking rate, to manage the backtracking process and minimize the allocation of nodes with limited resources.
6.3. Simulation Results
6.3.1. Fitness Value
6.3.2. Network Load Balance
6.3.3. Average SFC Delay
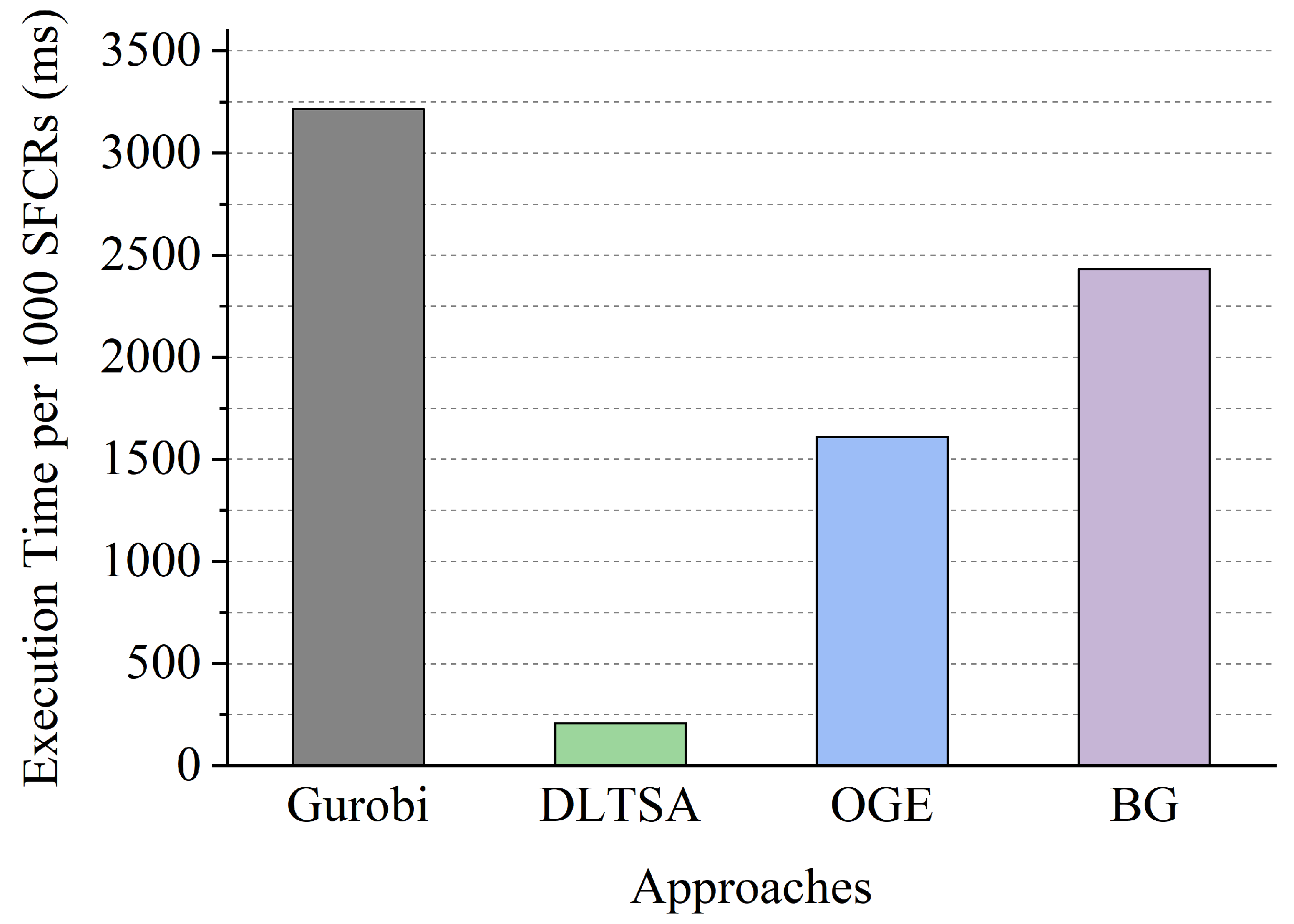
6.3.4. Execution Time
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Laghrissi, A.; Taleb, T. A Survey on the Placement of Virtual Resources and Virtual Network Functions. IEEE Commun. Surv. Tutor. 2019, 21, 1409–1434. [Google Scholar] [CrossRef]
- Pei, J.; Hong, P.; Xue, K.; Li, D. Resource Aware Routing for Service Function Chains in SDN and NFV-Enabled Network. IEEE Trans. Serv. Comput. 2021, 14, 985–997. [Google Scholar] [CrossRef]
- Hantouti, H.; Benamar, N.; Taleb, T.; Laghrissi, A. Traffic Steering for Service Function Chaining. IEEE Commun. Surv. Tutor. 2019, 21, 487–507. [Google Scholar] [CrossRef]
- Pepper, R. Cisco Visual Networking Index (VNI) Global Mobile Data Traffic Forecast Update; Technical Report; Cisco: Singapore, 2013. [Google Scholar]
- Sun, P.; Guo, Z.; Liu, S.; Lan, J.; Wang, J.; Hu, Y. SmartFCT: Improving power-efficiency for data center networks with deep reinforcement learning. Comput. Netw. 2020, 179, 107255. [Google Scholar] [CrossRef]
- Nobach, L.; Rimac, I.; Hilt, V.; Hausheer, D. SliM: Enabling efficient, seamless NFV state migration. In Proceedings of the 24th IEEE International Conference on Network Protocols, ICNP, Singapore, 8–11 November 2016; IEEE Computer Society. pp. 1–2. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Mao, B.; Fadlullah, Z.M.; Tang, F.; Kato, N.; Akashi, O.; Inoue, T.; Mizutani, K. Routing or Computing? The Paradigm Shift Towards Intelligent Computer Network Packet Transmission Based on Deep Learning. IEEE Trans. Comput. 2017, 66, 1946–1960. [Google Scholar] [CrossRef]
- Pei, J.; Hong, P.; Pan, M.; Liu, J.; Zhou, J. Optimal VNF Placement via Deep Reinforcement Learning in SDN/NFV-Enabled Networks. IEEE J. Sel. Areas Commun. 2020, 38, 263–278. [Google Scholar] [CrossRef]
- Kuo, T.; Liou, B.; Lin, K.C.; Tsai, M. Deploying Chains of Virtual Network Functions: On the Relation Between Link and Server Usage. IEEE/ACM Trans. Netw. 2018, 26, 1562–1576. [Google Scholar] [CrossRef]
- Li, Z.; Lu, Z.; Deng, S.; Gao, X. A Self-Adaptive Virtual Network Embedding Algorithm Based on Software-Defined Networks. IEEE Trans. Netw. Serv. Manag. 2019, 16, 362–373. [Google Scholar] [CrossRef]
- Eramo, V.; Miucci, E.; Ammar, M.H.; Lavacca, F.G. An Approach for Service Function Chain Routing and Virtual Function Network Instance Migration in Network Function Virtualization Architectures. IEEE/ACM Trans. Netw. 2017, 25, 2008–2025. [Google Scholar] [CrossRef]
- Cziva, R.; Anagnostopoulos, C.; Pezaros, D.P. Dynamic, Latency-Optimal vNF Placement at the Network Edge. In Proceedings of the 2018 IEEE Conference on Computer Communications, INFOCOM, Honolulu, HI, USA, 16–19 April 2018; pp. 693–701. [Google Scholar]
- Tseng, F.; Wang, X.; Chou, L.; Chao, H.; Leung, V.C.M. Dynamic Resource Prediction and Allocation for Cloud Data Center Using the Multiobjective Genetic Algorithm. IEEE Syst. J. 2018, 12, 1688–1699. [Google Scholar] [CrossRef]
- Pei, J.; Hong, P.; Xue, K.; Li, D.; Wei, D.S.L.; Wu, F. Two-Phase Virtual Network Function Selection and Chaining Algorithm Based on Deep Learning in SDN/NFV-Enabled Networks. IEEE J. Sel. Areas Commun. 2020, 38, 1102–1117. [Google Scholar] [CrossRef]
- Huang, W.; Li, S.; Wang, S.; Li, H. An Improved Adaptive Service Function Chain Mapping Method Based on Deep Reinforcement Learning. Electronics 2023, 12, 1307. [Google Scholar] [CrossRef]
- Agarwal, S.; Malandrino, F.; Chiasserini, C.F.; De, S. Joint VNF Placement and CPU Allocation in 5G. In Proceedings of the 2018 IEEE Conference on Computer Communications, INFOCOM, Honolulu, HI, USA, 16–19 April 2018; pp. 1943–1951. [Google Scholar]
- Pham, C.; Tran, N.H.; Ren, S.; Saad, W.; Hong, C.S. Traffic-Aware and Energy-Efficient vNF Placement for Service Chaining: Joint Sampling and Matching Approach. IEEE Trans. Serv. Comput. 2020, 13, 172–185. [Google Scholar] [CrossRef]
- Liu, Y.; Ran, J.; Hu, H.; Tang, B. Energy-Efficient Virtual Network Function Reconfiguration Strategy Based on Short-Term Resources Requirement Prediction. Electronics 2021, 10, 2287. [Google Scholar] [CrossRef]
- Eramo, V.; Ammar, M.H.; Lavacca, F.G. Migration Energy Aware Reconfigurations of Virtual Network Function Instances in NFV Architectures. IEEE Access 2017, 5, 4927–4938. [Google Scholar] [CrossRef]
- Song, S.; Lee, C.; Cho, H.; Lim, G.; Chung, J.M. Clustered Virtualized Network Functions Resource Allocation based on Context-Aware Grouping in 5G Edge Networks. IEEE Trans. Mob. Comput. 2020, 19, 1072–1083. [Google Scholar] [CrossRef]
- Tam, P.; Math, S.; Kim, S. Priority-Aware Resource Management for Adaptive Service Function Chaining in Real-Time Intelligent IoT Services. Electronics 2022, 11, 2976. [Google Scholar] [CrossRef]
- Tam, P.; Math, S.; Kim, S. Optimized Multi-Service Tasks Offloading for Federated Learning in Edge Virtualization. IEEE Trans. Netw. Sci. Eng. 2022, 9, 4363–4378. [Google Scholar] [CrossRef]
- Shin, M.; Chong, S.; Rhee, I. Dual-resource TCP/AQM for processing-constrained networks. IEEE/ACM Trans. Netw. 2008, 16, 435–449. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, S.; Zhou, A.; Xu, J.; Yuan, J.; Hsu, C. User allocation-aware edge cloud placement in mobile edge computing. Softw. Pract. Exp. 2020, 50, 489–502. [Google Scholar] [CrossRef]
- Mitchell, M. An introduction to Genetic Algorithms; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Srinivas, M.; Patnaik, L.M. Adaptive probabilities of crossover and mutation in genetic algorithms. IEEE Trans. Syst. Man Cybern. 1994, 24, 656–667. [Google Scholar] [CrossRef]
- Liu, X.; Cheng, B.; Wang, S. Availability-Aware and Energy-Efficient Virtual Cluster Allocation Based on Multi-Objective Optimization in Cloud Datacenters. IEEE Trans. Netw. Serv. Manag. 2020, 17, 972–985. [Google Scholar] [CrossRef]
- Al-Fares, M.; Loukissas, A.; Vahdat, A. A scalable, commodity data center network architecture. Acm Sigcomm Comput. Commun. Rev. 2008, 38, 63–74. [Google Scholar] [CrossRef]
- Pei, J.; Hong, P.; Xue, K.; Li, D. Efficiently Embedding Service Function Chains with Dynamic Virtual Network Function Placement in Geo-Distributed Cloud System. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 2179–2192. [Google Scholar] [CrossRef]
- Xu, Z.; Liang, W.; Galis, A.; Ma, Y.; Xia, Q.; Xu, W. Throughput optimization for admitting NFV-enabled requests in cloud networks. Comput. Netw. 2018, 143, 15–29. [Google Scholar] [CrossRef]
- Gurobi Optimizer Reference Manual Version 8.1.1. Available online: https://www.gurobi.com/documentation/quickstart.html (accessed on 25 March 2023).
- Xia, J.; Pang, D.; Cai, Z.; Xu, M.; Hu, G. Reasonably Migrating Virtual Machine in NFV-Featured Networks. In Proceedings of the IEEE International Conference on Computer and Information Technology, CIT, Nadi, Fiji, 8–10 December 2016; pp. 361–366. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | [10] | [11] | [12] | [13] | [14] | [9,15] | [16] | Our Approach | |
|---|---|---|---|---|---|---|---|---|---|
| Scopes | |||||||||
| VNF sharing consideration | ✓ | × | × | × | × | ✓ | × | ✓ | |
| Concurrent migration of multiple VNFs | × | × | ✓ | ✓ | × | × | × | ✓ | |
| Applying Deep learning | × | × | × | × | × | ✓ | ✓ | ✓ | |
| Network load maintenance | ✓ | ✓ | ✓ | × | ✓ | × | × | ✓ | |
| SFCR delay guarantee | × | ✓ | × | ✓ | × | ✓ | × | ✓ | |
| Node resource consideration | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Link resource consideration | ✓ | ✓ | ✓ | × | × | ✓ | ✓ | ✓ | |
| Symbols and Variables | Description |
|---|---|
| Physical network | |
| N | Set of physical nodes, is a physical node. |
| L | Set of physical links, is a physical link. |
| , | Capacity of CPU and memory in node . |
| Bandwidth capacity on link . | |
| Propagation delay on link . | |
| SFCR related | |
| R | Set of SFCRs, is an SFCR. |
| Set of VNFRs in SFCR , . | |
| Set of logical links in SFCR , . | |
| Traffic arrival rate in SFCR . | |
| , | CPU and memory requirement of VNF . |
| The maximum tolerated delay of SFCR . | |
| VNF-FG related | |
| Set of VNF instance nodes, . | |
| Set of virtual links, . | |
| Processing rate allocated by VNF instance to SFCR | |
| Unknown variables | |
| Whether VNFR is mapped on VNF . | |
| Whether logical link is mapped on virtual link . | |
| Whether VNF is host on node . | |
| Whether virtual link is host on link . |
| Parameters | Value | Parameters | Value |
|---|---|---|---|
| [10, 30] cores | [32, 64] GB | ||
| [500, 1000] Mbps | [2, 5] ms | ||
| [10, 50] ms | [1000, 4000] packets/s | ||
| SFC length | [3, 5] | 0.4, 0.75 | |
| 0.091, 0.063 | Max generations | 500 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, Y.; Tang, X.; Zhang, Z.; Zhang, X.; Yang, W. Virtual Network Function Migration Considering Load Balance and SFC Delay in 6G Mobile Edge Computing Networks. Electronics 2023, 12, 2753. https://doi.org/10.3390/electronics12122753
Yue Y, Tang X, Zhang Z, Zhang X, Yang W. Virtual Network Function Migration Considering Load Balance and SFC Delay in 6G Mobile Edge Computing Networks. Electronics. 2023; 12(12):2753. https://doi.org/10.3390/electronics12122753
Chicago/Turabian StyleYue, Yi, Xiongyan Tang, Zhiyan Zhang, Xuebei Zhang, and Wencong Yang. 2023. "Virtual Network Function Migration Considering Load Balance and SFC Delay in 6G Mobile Edge Computing Networks" Electronics 12, no. 12: 2753. https://doi.org/10.3390/electronics12122753
APA StyleYue, Y., Tang, X., Zhang, Z., Zhang, X., & Yang, W. (2023). Virtual Network Function Migration Considering Load Balance and SFC Delay in 6G Mobile Edge Computing Networks. Electronics, 12(12), 2753. https://doi.org/10.3390/electronics12122753