
Deep Learning and Kurtosis-Controlled, Entropy-Based Framework for Human Gait Recognition Using Video Sequences

 , , , and
, , , and
Abstract
:
1. Introduction
- A database captured in the real-time outdoor environment using more than 50 subjects. The captured videos include a high rate of noise and background complexity.
- Refinement of the contrast of extracted video frames using the 3D box filtering approach and then fine-tuning of the ResNet101 model. The transfer-learning-based model is trained on real-time captured video frames and extracted features.
- A kurtosis-based heuristic approach is proposed to select the best features and fuse them in one vector using the correlation approach.
- Classification using multiclass one against all-SVM (OaA-SVM) and comparison of the performance of the proposed method on different feature sets.
2. Related Work
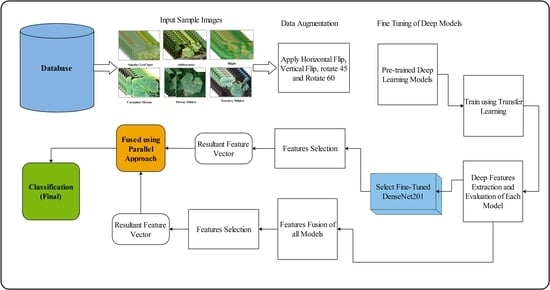
3. Proposed Methodology
3.1. Videos Preprocessing
| Algorithm 1: Data Augmentation Process. |
| Input: Original video frame . Output: Improved video frame . Step 1: Load all video frames . for: Step 2: Calculate filter size.
|
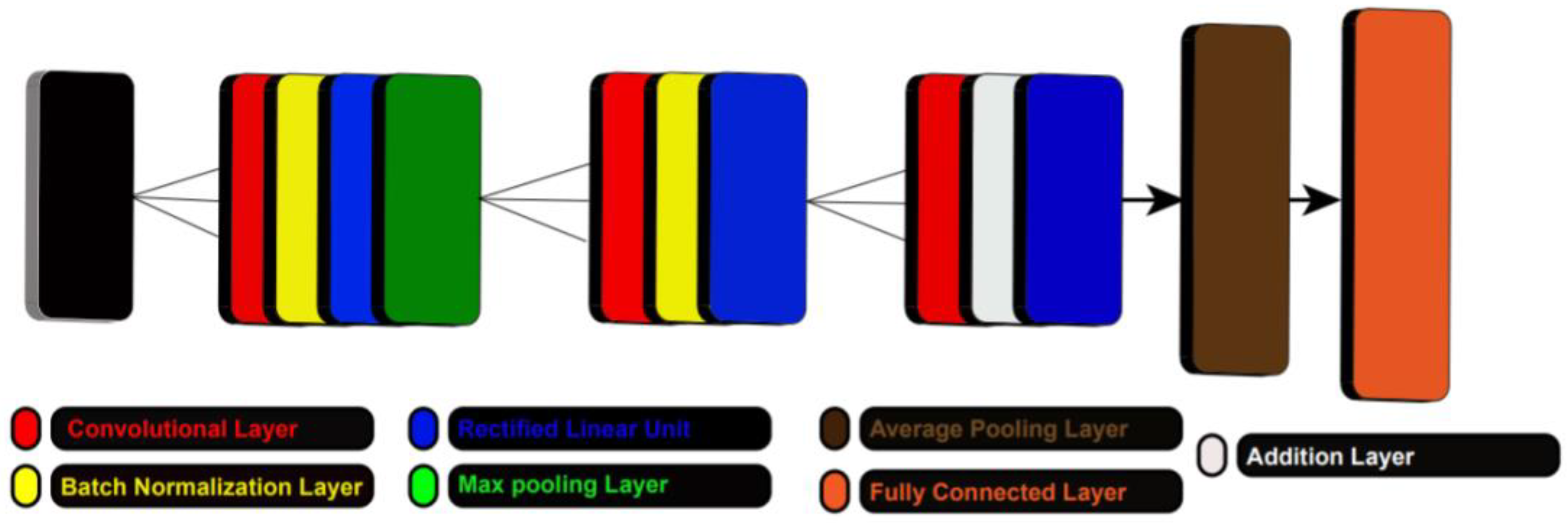
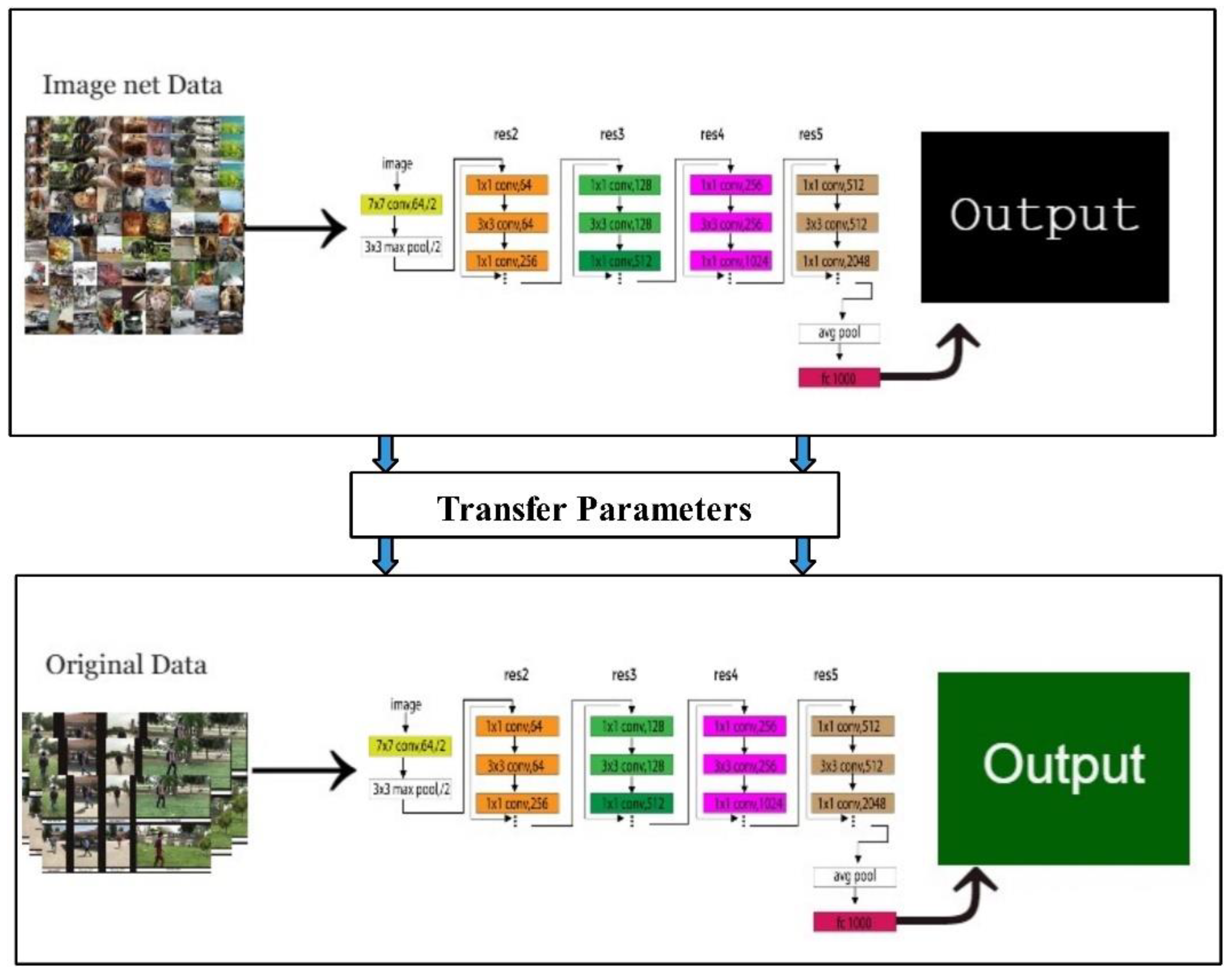
3.2. Convolutional Neural Network
3.3. Deep Features Extraction
3.4. Kurtosis-Controlled, Entropy-Based Feature Selection
| Algorithm 2: Features selection for deep learning model 1. |
| Input: Feature vector of dimension . Output: Selected feature of dimension . Step 1: Features initialization. for // Step 2: Compute kurtosis of each feature pair.
Step 4: Perform fitness function.
end for |
| Algorithm 3: Features selection for deep learning model 2. |
| Input: Feature vector of dimension. Output: Selected feature of dimension. Step 1: Features initialization. for // Step 2: Compute kurtosis of each feature pair.
Step 4: Perform fitness function.
end for |
3.5. Recognition
4. Results
4.1. Datasets
4.2. Experimental Setup
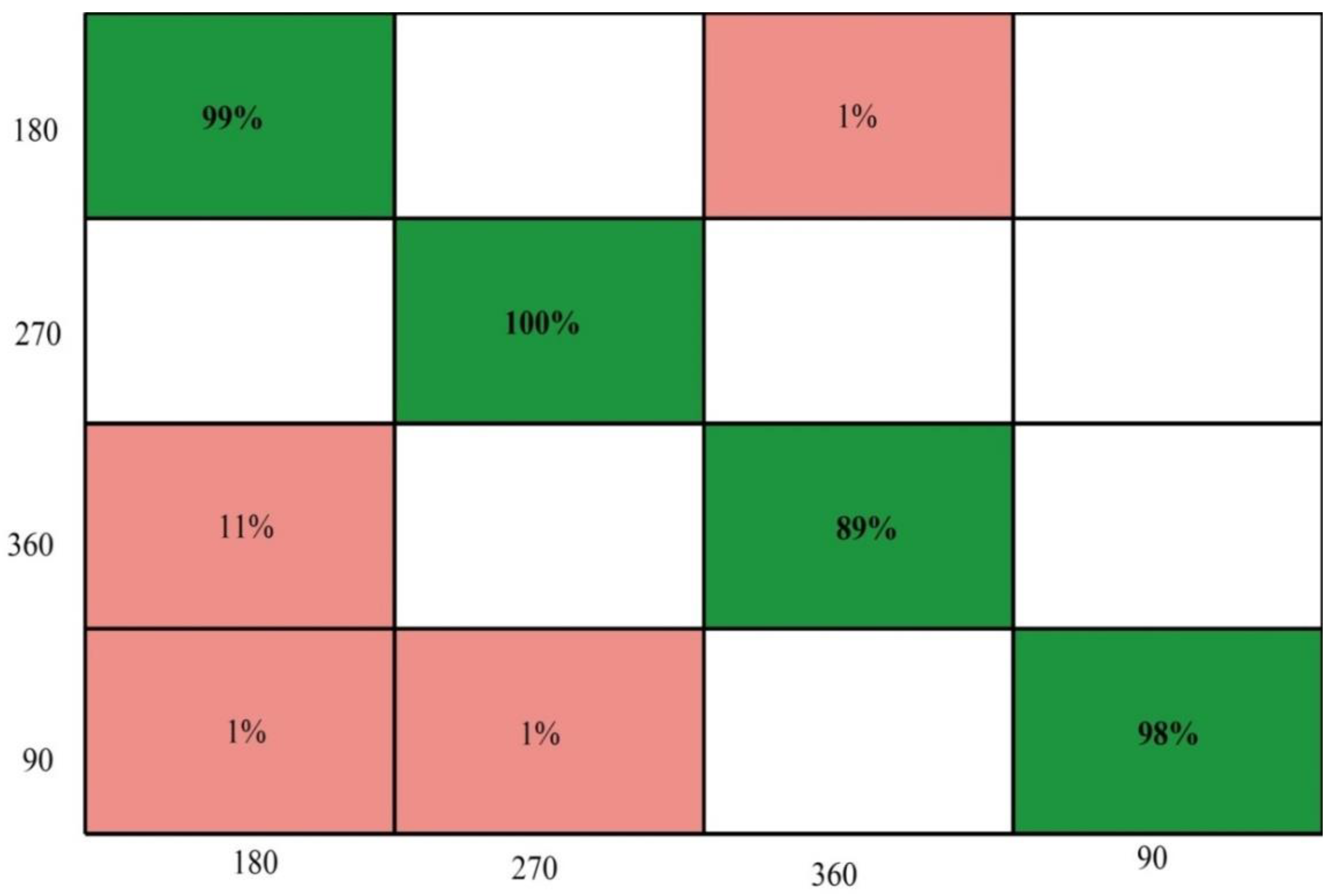
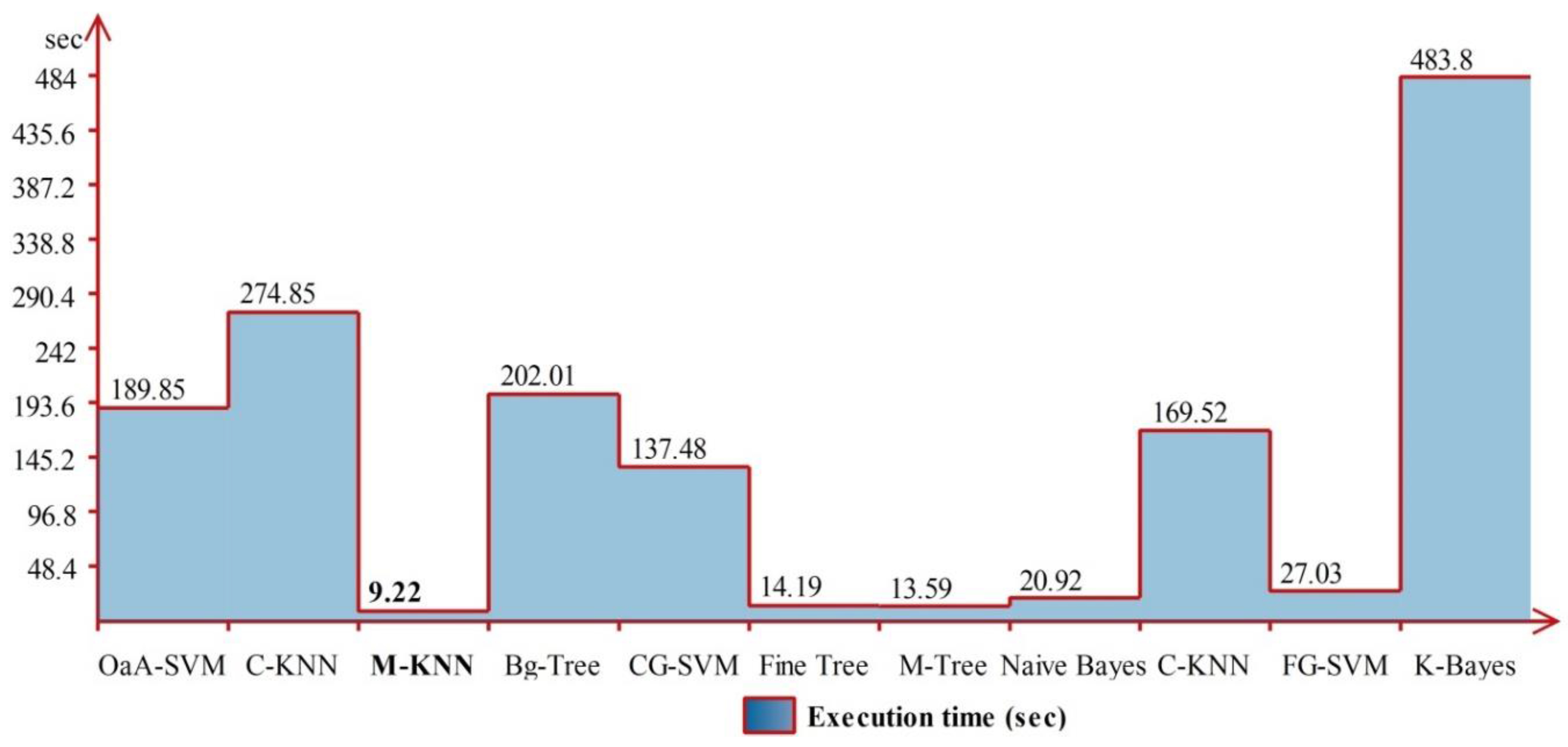
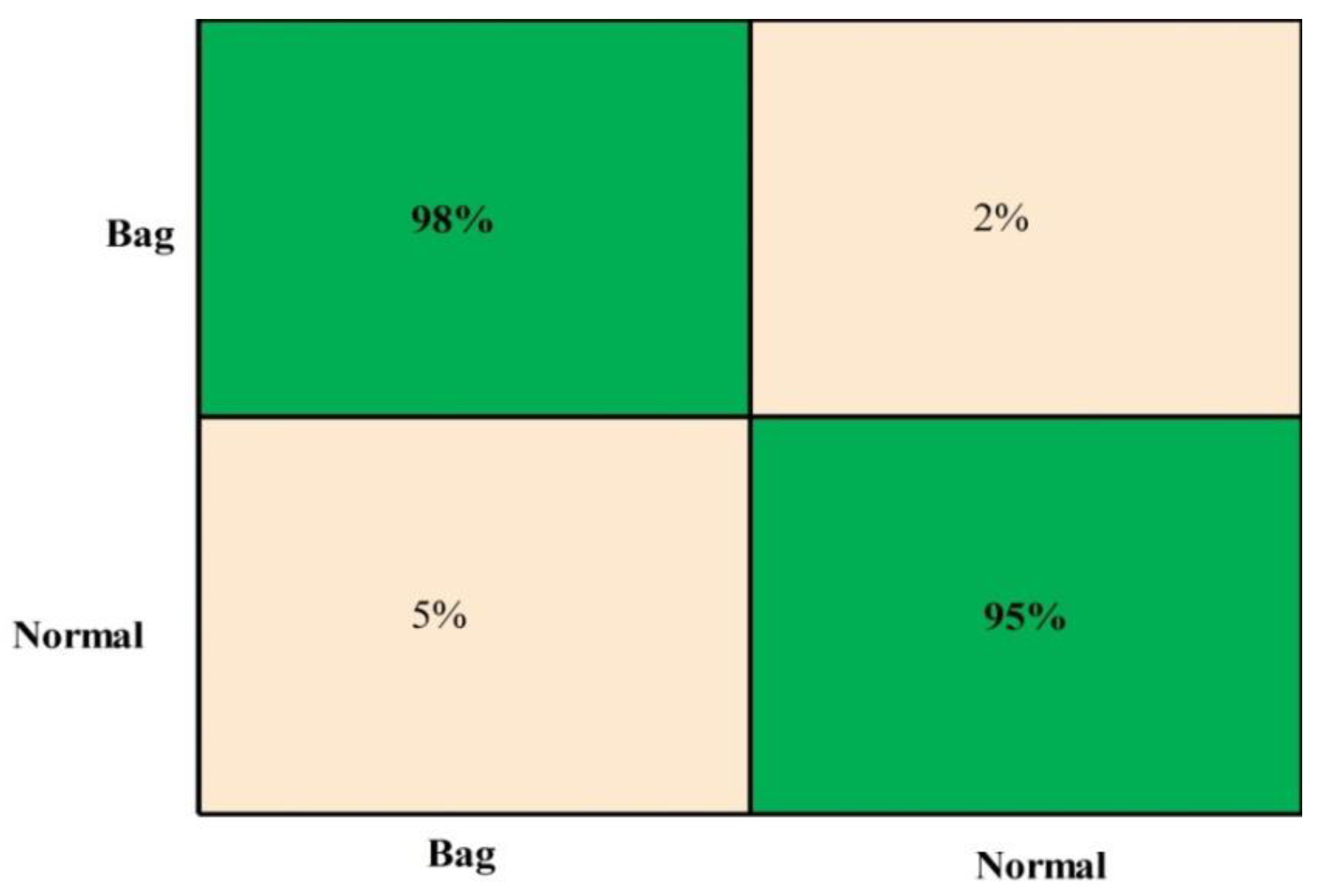
4.3. Real-Time Dataset Results
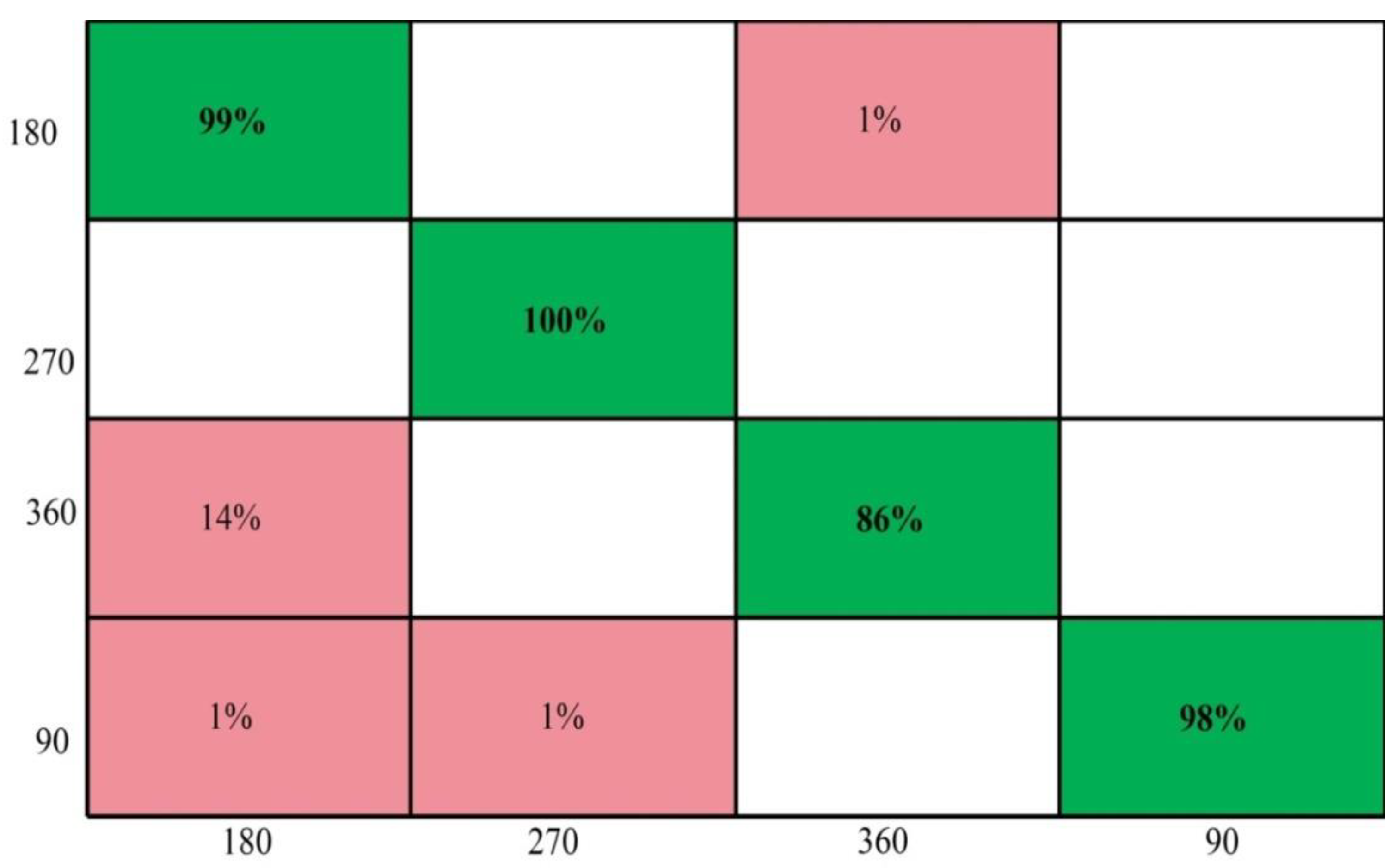
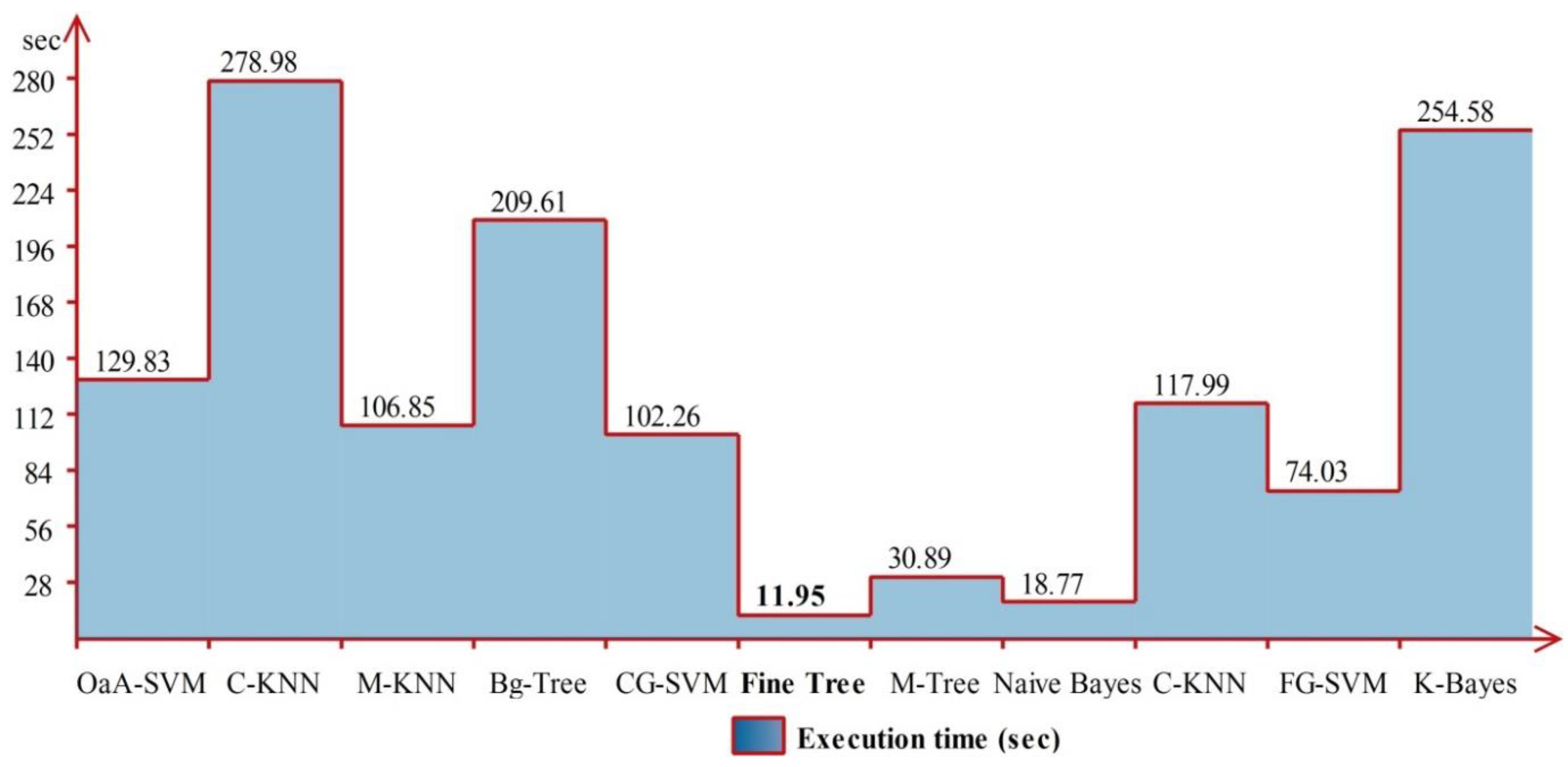
4.4. CASIA B Dataset Results at a 90° Angle
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Saleem, F.; Khan, M.A.; Alhaisoni, M.; Tariq, U.; Armghan, A.; Alenezi, F.; Choi, J.-I.; Kadry, S. Human Gait Recognition: A Single Stream Optimal Deep Learning Features Fusion. Sensors 2021, 21, 7584. [Google Scholar] [CrossRef] [PubMed]
- Bendjillali, R.I.; Beladgham, M.; Merit, K.; Taleb-Ahmed, A. Improved Facial Expression Recognition Based on DWT Feature for Deep CNN. Electronics 2019, 8, 324. [Google Scholar] [CrossRef] [Green Version]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, Present, and Future of Face Recognition: A Review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Olanrewaju, L.; Oyebiyi, O.; Misra, S.; Maskeliunas, R.; Damasevicius, R. Secure ear biometrics using circular kernel principal component analysis, Chebyshev transform hashing and Bose–Chaudhuri–Hocquenghem error-correcting codes. Signal Image Video Process. 2020, 14, 847–855. [Google Scholar] [CrossRef]
- Rodrigues, J.D.C.; Filho, P.P.R.; Damasevicius, R.; de Albuquerque, V.H.C. EEG-based biometric systems. In Neurotechnology: Methods, Advances and Applications; The Institution of Engineering and Technology: London, UK, 2020; pp. 97–153. Available online: https://www.researchgate.net/publication/340455635_Neurotechnology_Methods_advances_and_applications (accessed on 17 January 2022).
- Arshad, H.; Khan, M.A.; Sharif, M.I.; Yasmin, M.; Tavares, J.M.R.S.; Zhang, Y.-D.; Satapathy, S.C. A multilevel paradigm for deep convolutional neural network features selection with an application to human gait recognition. Expert Syst. 2020, 20, 1–21. [Google Scholar] [CrossRef]
- Sokolova, A.; Konushin, A. Pose-based deep gait recognition. IET Biom. 2018, 8, 134–143. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Li, Y.; Xiong, F.; Zhang, W. Gait Recognition Using Optical Motion Capture: A Decision Fusion Based Method. Sensors 2021, 21, 3496. [Google Scholar] [CrossRef]
- Kim, H.; Kim, H.-J.; Park, J.; Ryu, J.-K.; Kim, S.-C. Recognition of Fine-Grained Walking Patterns Using a Smartwatch with Deep Attentive Neural Networks. Sensors 2021, 21, 6393. [Google Scholar] [CrossRef]
- Hwang, T.-H.; Effenberg, A.O. Head Trajectory Diagrams for Gait Symmetry Analysis Using a Single Head-Worn IMU. Sensors 2021, 21, 6621. [Google Scholar] [CrossRef]
- Khan, M.H.; Li, F.; Farid, M.S.; Grzegorzek, M. Gait recognition using motion trajectory analysis. In Proceedings of the International Conference on Computer Recognition Systems, Polanica Zdroj, Poland, 22–24 May 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 73–82. [Google Scholar]
- Manssor, S.A.; Sun, S.; Elhassan, M.A. Real-Time Human Recognition at Night via Integrated Face and Gait Recognition Technologies. Sensors 2021, 21, 4323. [Google Scholar] [CrossRef]
- Liao, R.; Yu, S.; An, W.; Huang, Y. A model-based gait recognition method with body pose and human prior knowledge. Pattern Recognit. 2019, 98, 107069. [Google Scholar] [CrossRef]
- Sharif, M.; Attique, M.; Tahir, M.Z.; Yasmim, M.; Saba, T.; Tanik, U.J. A Machine Learning Method with Threshold Based Parallel Feature Fusion and Feature Selection for Automated Gait Recognition. J. Organ. End User Comput. 2020, 32, 67–92. [Google Scholar] [CrossRef]
- Priya, S.J.; Rani, A.J.; Subathra, M.S.P.; Mohammed, M.A.; Damaševičius, R.; Ubendran, N. Local Pattern Transformation Based Feature Extraction for Recognition of Parkinson’s Disease Based on Gait Signals. Diagnostics 2021, 11, 1395. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.; Khan, M.A.; Alhaisoni, M.; Tariq, U.; Yong, H.-S.; Armghan, A.; Alenezi, F. Human Action Recognition: A Paradigm of Best Deep Learning Features Selection and Serial Based Extended Fusion. Sensors 2021, 21, 7941. [Google Scholar] [CrossRef]
- Khan, M.A.; Zhang, Y.-D.; Khan, S.A.; Attique, M.; Rehman, A.; Seo, S. A resource conscious human action recognition framework using 26-layered deep convolutional neural network. Multimed. Tools Appl. 2021, 80, 35827–35849. [Google Scholar] [CrossRef]
- Khan, M.A.; Javed, K.; Khan, S.A.; Saba, T.; Habib, U.; Khan, J.A.; Abbasi, A.A. Human action recognition using fusion of multiview and deep features: An application to video surveillance. Multimed. Tools Appl. 2020, 1–27. [Google Scholar] [CrossRef]
- Zebari, D.A.; Ibrahim, D.A.; Zeebaree, D.Q.; Haron, H.; Salih, M.S.; Damaševičius, R.; Mohammed, M.A. Systematic Review of Computing Approaches for Breast Cancer Detection Based Computer Aided Diagnosis Using Mammogram Images. Appl. Artif. Intell. 2021, 1–47. [Google Scholar] [CrossRef]
- Kassem, M.; Hosny, K.; Damaševičius, R.; Eltoukhy, M. Machine Learning and Deep Learning Methods for Skin Lesion Classification and Diagnosis: A Systematic Review. Diagnostics 2021, 11, 1390. [Google Scholar] [CrossRef]
- Kumar, V.; Singh, D.; Kaur, M.; Damaševičius, R. Overview of current state of research on the application of artificial intelligence techniques for COVID-19. PeerJ Comput. Sci. 2021, 7, e564. [Google Scholar] [CrossRef]
- Mehmood, A.; Khan, M.A.; Sharif, M.; Khan, S.A.; Shaheen, M.; Saba, T.; Riaz, N.; Ashraf, I. Prosperous Human Gait Recognition: An end-to-end system based on pre-trained CNN features selection. Multimed. Tools Appl. 2020, 11, 1–21. [Google Scholar] [CrossRef]
- Anusha, R.; Jaidhar, C.D. Clothing invariant human gait recognition using modified local optimal oriented pattern binary descriptor. Multimed. Tools Appl. 2020, 79, 2873–2896. [Google Scholar] [CrossRef]
- Khan, M.A.; Akram, T.; Sharif, M.; Muhammad, N.; Javed, M.Y.; Naqvi, S.R. Improved strategy for human action recognition; experiencing a cascaded design. IET Image Process. 2020, 14, 818–829. [Google Scholar] [CrossRef]
- Kadry, S.; Rajinikanth, V.; Taniar, D.; Damaševičius, R.; Valencia, X.P.B. Automated segmentation of leukocyte from hematological images—A study using various CNN schemes. J. Supercomput. 2021, 1–21. [Google Scholar] [CrossRef]
- Tanveer, M.; Rashid, A.H.; Ganaie, M.; Reza, M.; Razzak, I.; Hua, K.-L. Classification of Alzheimer’s disease using ensemble of deep neural networks trained through transfer learning. IEEE J. Biomed. Health Inform. 2021. [Google Scholar] [CrossRef]
- Khan, M.Z.; Saba, T.; Razzak, I.; Rehman, A.; Bahaj, S.A. Hot-Spot Zone Detection to Tackle Covid19 Spread by Fusing the Traditional Machine Learning and Deep Learning Approaches of Computer Vision. IEEE Access 2021, 9, 100040–100049. [Google Scholar] [CrossRef]
- Rehman, A.; Naz, S.; Razzak, M.I.; Hameed, I.A. Automatic Visual Features for Writer Identification: A Deep Learning Approach. IEEE Access 2019, 7, 17149–17157. [Google Scholar] [CrossRef]
- Alyasseri, Z.A.A.; Al-Betar, M.A.; Abu Doush, I.; Awadallah, M.A.; Abasi, A.K.; Makhadmeh, S.N.; Alomari, O.A.; Abdulkareem, K.H.; Adam, A.; Damasevicius, R.; et al. Review on COVID-19 diagnosis models based on machine learning and deep learning approaches. Expert Syst. 2021, e12759. [Google Scholar] [CrossRef]
- Castro, F.M.; Marín-Jiménez, M.J.; Guil, N.; De La Blanca, N.P. Multimodal feature fusion for CNN-based gait recognition: An empirical comparison. Neural Comput. Appl. 2020, 32, 14173–14193. [Google Scholar] [CrossRef] [Green Version]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Bari, A.S.M.H.; Gavrilova, M.L. Artificial Neural Network Based Gait Recognition Using Kinect Sensor. IEEE Access 2019, 7, 162708–162722. [Google Scholar] [CrossRef]
- Zheng, S.; Zhang, J.; Huang, K.; He, R.; Tan, T. Robust view transformation model for gait recognition. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 2073–2076. [Google Scholar]
- Wang, X.; Yan, W.Q. Human Gait Recognition Based on Frame-by-Frame Gait Energy Images and Convolutional Long Short-Term Memory. Int. J. Neural Syst. 2019, 30, 1950027. [Google Scholar] [CrossRef] [PubMed]
- Anusha, R.; Jaidhar, C.D. Human gait recognition based on histogram of oriented gradients and Haralick texture descriptor. Multimed. Tools Appl. 2020, 79, 8213–8234. [Google Scholar] [CrossRef]
- Zhao, A.; Li, J.; Ahmed, M. SpiderNet: A spiderweb graph neural network for multi-view gait recognition. Knowl. Based Syst. 2020, 206, 106273. [Google Scholar] [CrossRef]
- Arshad, H.; Khan, M.A.; Sharif, M.; Yasmin, M.; Javed, M.Y. Multi-level features fusion and selection for human gait recognition: An optimized framework of Bayesian model and binomial distribution. Int. J. Mach. Learn. Cybern. 2019, 10, 3601–3618. [Google Scholar] [CrossRef]
- Ferroukhi, M.; Ouahabi, A.; Attari, M.; Habchi, Y.; Taleb-Ahmed, A. Medical Video Coding Based on 2nd-Generation Wavelets: Performance Evaluation. Electronics 2019, 8, 88. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Torrey, L.; Shavlik, J. Transfer learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Naheed, N.; Shaheen, M.; Khan, S.A.; Alawairdhi, M.; Khan, M.A. Importance of Features Selection, Attributes Selection, Challenges and Future Directions for Medical Imaging Data: A Review. Comput. Model. Eng. Sci. 2020, 125, 315–344. [Google Scholar] [CrossRef]
- Liu, Y.; Zheng, Y.F. One-against-all multi-class SVM classification using reliability measures. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; pp. 849–854. [Google Scholar]
- Arai, K.; Andrie, R. Gait recognition method based on wavelet transformation and its evaluation with chinese academy of sciences (casia) gait database as a human gait recognition dataset. In Proceedings of the 2012 Ninth International Conference on Information Technology-New Generations, Las Vegas, NV, USA, 16–18 April 2012; pp. 656–661. [Google Scholar]
- Arora, P.; Hanmandlu, M.; Srivastava, S. Gait based authentication using gait information image features. Pattern Recognit. Lett. 2015, 68, 336–342. [Google Scholar] [CrossRef]
- Castro, F.M.; Marín-Jiménez, M.J.; Mata, N.G.; Muñoz-Salinas, R. Fisher motion descriptor for multiview gait recognition. Int. J. Pattern Recognit. Artif. Intell. 2017, 31, 1756002. [Google Scholar] [CrossRef] [Green Version]
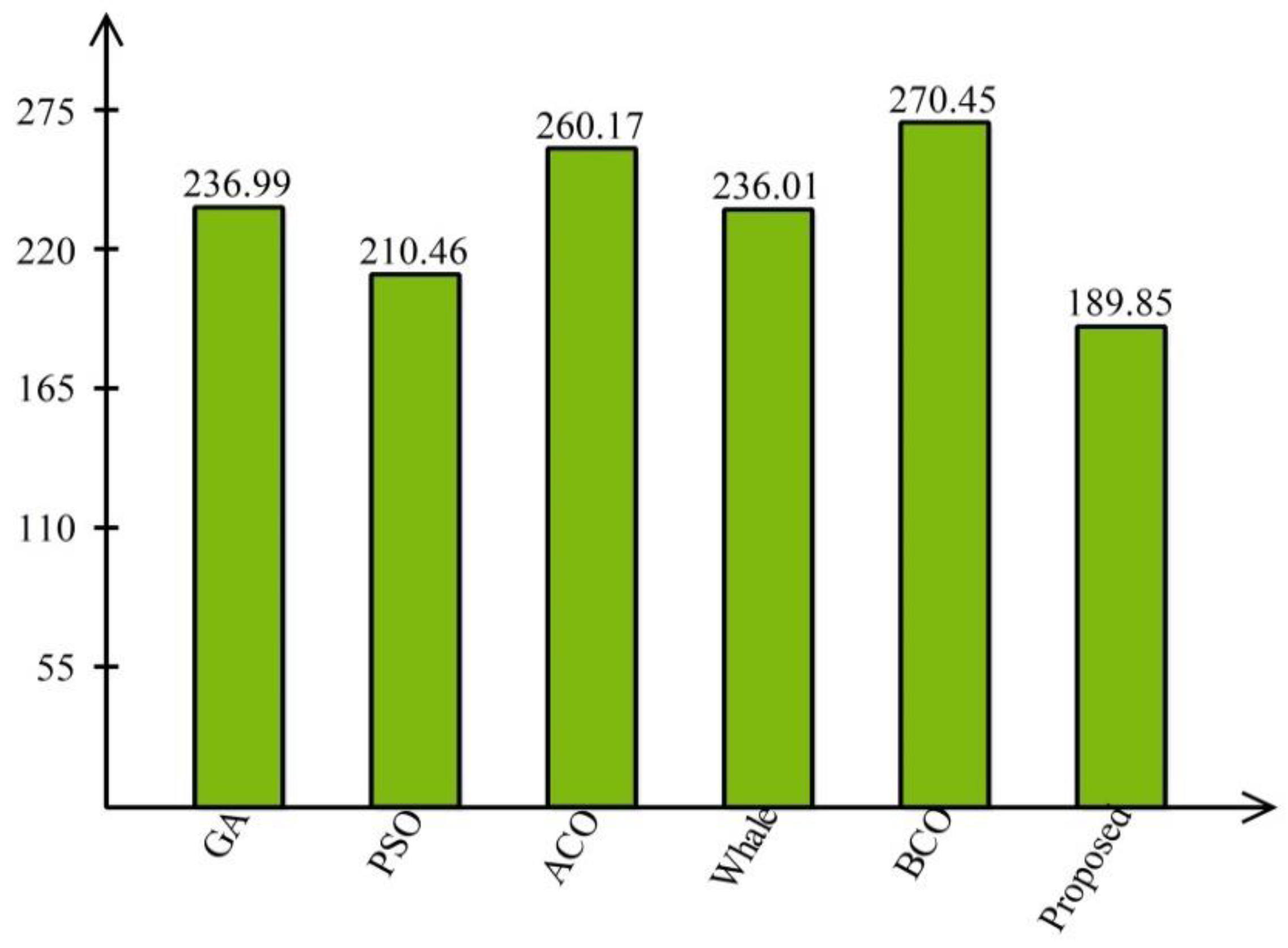
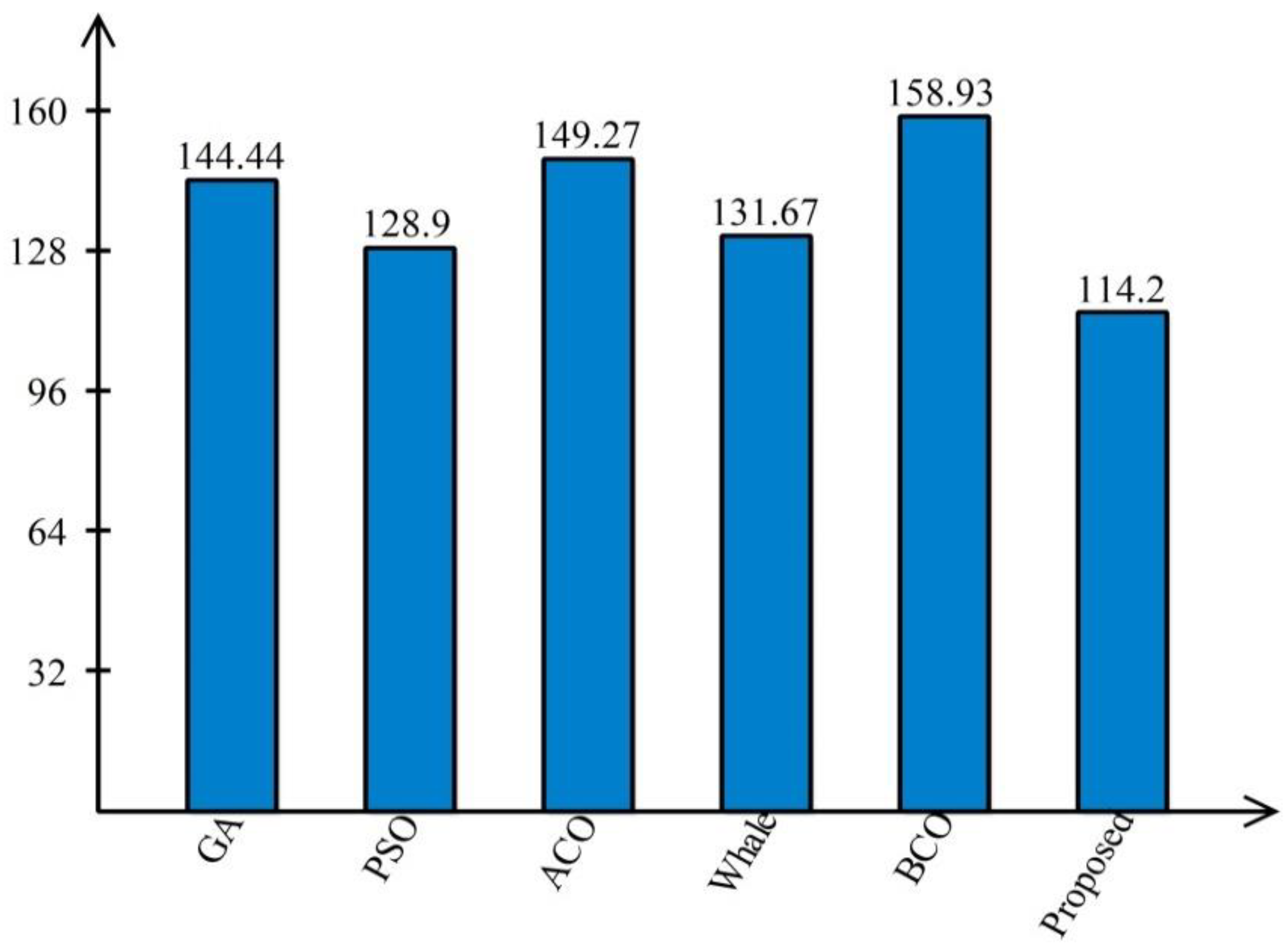
- Agrawal, P.; Abutarboush, H.F.; Ganesh, T.; Mohamed, A.W. Metaheuristic Algorithms on Feature Selection: A Survey of One Decade of Research (2009–2019). IEEE Access 2021, 9, 26766–26791. [Google Scholar] [CrossRef]
- Amari, S.-I. Backpropagation and stochastic gradient descent method. Neurocomputing 1993, 5, 185–196. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifiers | Performance Measures | ||||||
|---|---|---|---|---|---|---|---|
| Recall (%) | Precision (%) | FI Score (%) | AUC | FPR | Accuracy (%) | Time (s) | |
| OaA-SVM | 95.75 | 96.25 | 95.98 | 1.00 | 0.0125 | 96.0 | 204.050 |
| Cubic KNN | 94.25 | 94.75 | 94.48 | 1.00 | 0.0175 | 94.5 | 366.480 |
| Medium KNN | 95.00 | 95.50 | 95.24 | 1.00 | 0.0175 | 94.9 | 175.870 |
| Bagged Trees | 93.50 | 93.75 | 93.62 | 0.99 | 0.0200 | 93.5 | 345.750 |
| CG-SVM | 90.25 | 90.50 | 90.36 | 0.99 | 0.0325 | 90.1 | 189.300 |
| Fine Tree | 86.75 | 86.50 | 86.62 | 0.92 | 0.0425 | 86.7 | 19.565 |
| Medium Tree | 85.50 | 85.75 | 85.62 | 0.92 | 0.0475 | 85.4 | 39.907 |
| Naïve Bayes | 84.50 | 87.25 | 85.84 | 0.90 | 0.0500 | 84.3 | 34.035 |
| Coarse KNN | 61.50 | 72.50 | 66.54 | 0.92 | 0.1275 | 61.5 | 189.760 |
| FG-SVM | 61.00 | 84.75 | 70.92 | 0.91 | 0.1300 | 60.9 | 132.050 |
| Kernel Bayes | 48.75 | 63.50 | 50.54 | 0.73 | 0.1725 | 48.5 | 582.710 |
| Classifiers | Performance Measures | ||||||
|---|---|---|---|---|---|---|---|
| Recall (%) | Precision (%) | FI Score (%) | AUC | FPR | Accuracy (%) | Time (s) | |
| OaA-SVM | 96.5 | 97.0 | 96.7 | 1.00 | 0.01 | 96.6 | 189.850 |
| Cubic KNN | 95.0 | 95.2 | 95.1 | 1.00 | 0.01 | 95.1 | 274.850 |
| Medium KNN | 95.0 | 95.2 | 95.1 | 1.00 | 0.01 | 95.1 | 9.219 |
| Bagged Trees | 94.7 | 95.0 | 94.8 | 0.99 | 0.01 | 94.9 | 202.010 |
| CG-SVM | 90.5 | 91.0 | 90.7 | 0.99 | 0.03 | 90.5 | 137.480 |
| Fine Tree | 87.7 | 81.0 | 84.2 | 0.93 | 0.04 | 87.6 | 14.190 |
| Medium Tree | 86.7 | 87.0 | 86.8 | 0.93 | 0.04 | 86.8 | 13.590 |
| Naïve Bayes | 83.7 | 86.7 | 85.2 | 0.89 | 0.05 | 83.7 | 20.920 |
| Coarse KNN | 63.0 | 74.0 | 68.0 | 0.92 | 0.12 | 63.0 | 169.521 |
| FG-SVM | 61.0 | 84.7 | 70.9 | 0.91 | 0.13 | 61.3 | 27.030 |
| Kernel Bayes | 48.7 | 60.2 | 53.8 | 0.75 | 0.17 | 48.6 | 483.800 |
| Classifiers | Performance Measures | ||||||
|---|---|---|---|---|---|---|---|
| Recall (%) | Precision (%) | FI Score (%) | AUC | FPR | Accuracy (%) | Time (s) | |
| OaA-SVM | 96.5 | 96.5 | 96.5 | 1.00 | 0.03 | 96.4 | 129.830 |
| Cubic KNN | 95.0 | 96.0 | 95.7 | 1.00 | 0.04 | 95.6 | 278.980 |
| Medium KNN | 96.0 | 96.0 | 96.0 | 1.00 | 0.04 | 96.1 | 106.850 |
| Bagged Trees | 90.5 | 90.5 | 90.5 | 0.97 | 0.09 | 90.3 | 209.610 |
| CG-SVM | 82.0 | 82.5 | 82.2 | 0.91 | 0.18 | 82.2 | 102.260 |
| Fine Tree | 80.0 | 80.0 | 80.0 | 0.81 | 0.20 | 79.8 | 11.954 |
| Medium Tree | 76.0 | 76.5 | 76.2 | 0.80 | 0.24 | 76.3 | 30.888 |
| Naïve Bayes | 68.0 | 69.0 | 68.4 | 0.78 | 0.32 | 67.8 | 18.767 |
| Coarse KNN | 79.0 | 79.5 | 79.2 | 0.88 | 0.21 | 79.3 | 117.990 |
| FG-SVM | 79.5 | 85.5 | 82.3 | 0.98 | 0.41 | 79.6 | 74.026 |
| Kernel Bayes | 73.0 | 74.5 | 73.7 | 0.84 | 0.27 | 73.0 | 254.580 |
| Classifier | Features | Measures | ||||
|---|---|---|---|---|---|---|
| GAP | FC | Proposed | Recall (%) | Accuracy (%) | Time (s) | |
| OaA-SVM | ✓ | 90.10 | 90.22 | 242.4426 | ||
| ✓ | 88.52 | 88.64 | 176.4450 | |||
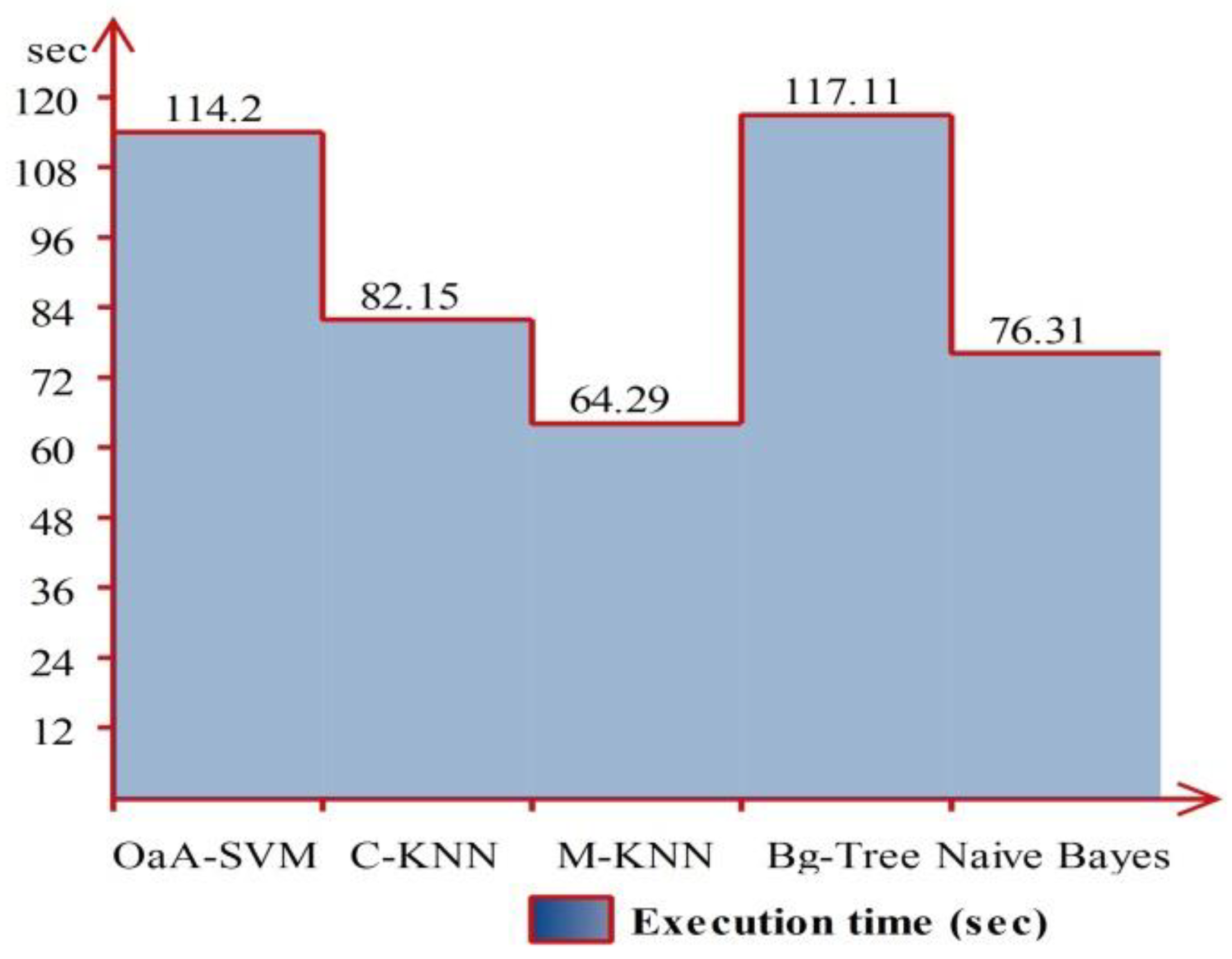
| ✓ | 95.10 | 95.26 | 114.2004 | |||
| Cubic KNN | ✓ | 84.42 | 84.54 | 165.5994 | ||
| ✓ | 83.60 | 83.98 | 111.2011 | |||
| ✓ | 93.60 | 93.60 | 82.1460 | |||
| Medium KNN | ✓ | 83.40 | 83.48 | 151.0014 | ||
| ✓ | 84.80 | 84.76 | 104.1446 | |||
| ✓ | 93.40 | 93.46 | 64.2914 | |||
| Baggage Tree | ✓ | 85.10 | 85.16 | 256.1130 | ||
| ✓ | 84.14 | 84.33 | 201.0148 | |||
| ✓ | 87.50 | 87.45 | 117.1106 | |||
| Naïve Bayes | ✓ | 71.10 | 71.04 | 171.2540 | ||
| ✓ | 74.94 | 74.82 | 104.3360 | |||
| ✓ | 79.30 | 79.30 | 76.3114 | |||
| Gait Name | Gait Name | ||
|---|---|---|---|
| Normal Walk | W-Coat | W-Bag | |
| Normal Walk | 94% | 4% | 2% |
| W-Coat | 3% | 95% | 2% |
| W-Bag | 1% | 2% | 97% |
| Dataset | Accuracy (%) on Feature Sets | |||||
|---|---|---|---|---|---|---|
| 300 Features | 400 Features | 500 Features | 600 Features | 700 Features | All Features | |
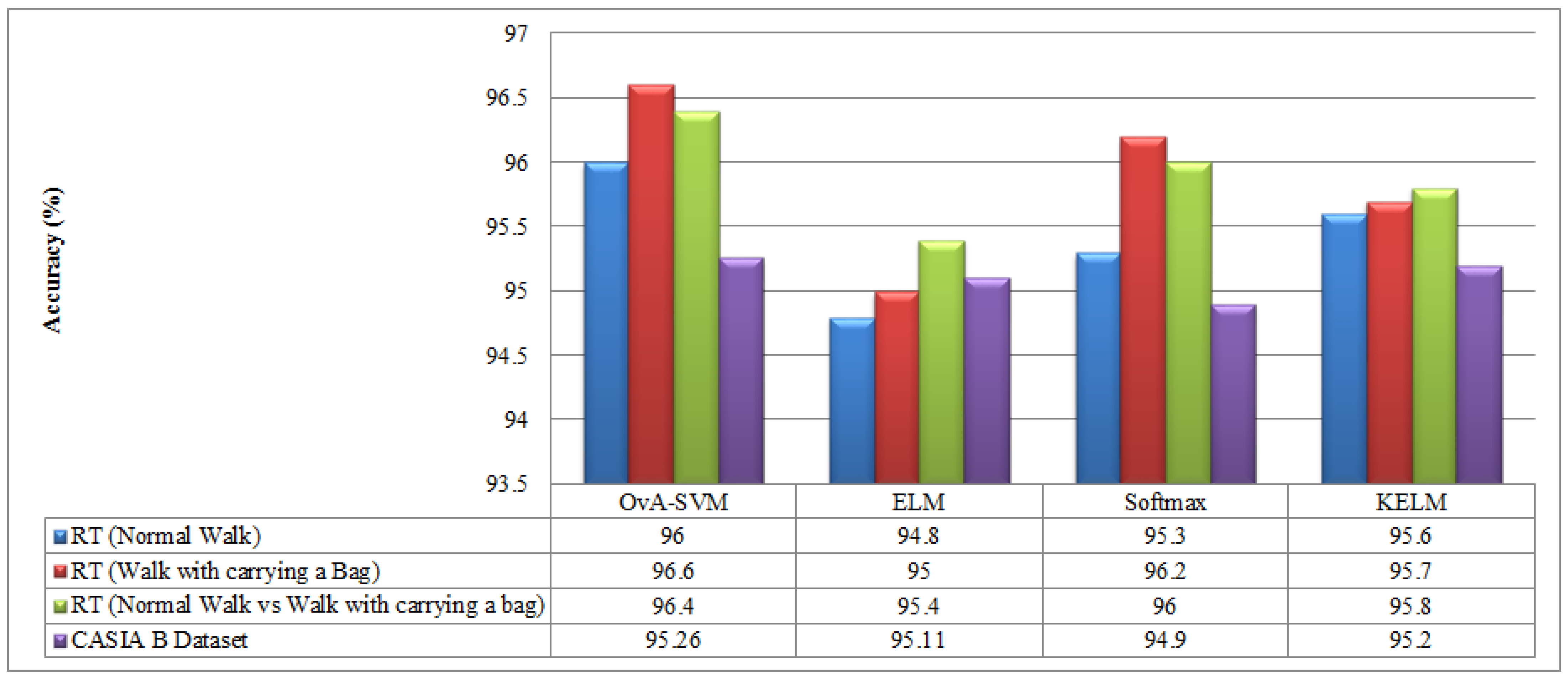
| Real-time (normal walking) | 93.70 | 94.24 | 95.35 | 96.00 | 95.70 | 93.04 |
| Real-time (walking while carrying a bag) | 94.10 | 94.90 | 95.80 | 96.60 | 96.32 | 92.10 |
| Real-time (normal walking vs. walking while carrying a bag) | 92.90 | 93.72 | 95.30 | 96.40 | 96.14 | 93.50 |
| CASIA B Dataset | 92.96 | 93.40 | 93.85 | 95.26 | 95.10 | 92.64 |
| Reference | Year | Dataset | Accuracy (%) |
|---|---|---|---|
| [45] | 2015 | CASIA B | 86.30 |
| [46] | 2017 | CASIA B | 90.60 |
| [37] | 2019 | CASIA B | 87.7 |
| [6] | 2020 | CASIA B | 93.40 |
| Proposed | CASIA B | 95.26 | |
| Proposed | Real-time | 96.60 | |
| Epochs | Accuracy (%) | Error (%) | Time (min) |
|---|---|---|---|
| 20 | 83.5 | 16.5 | 221.6784 |
| 40 | 87.9 | 12.1 | 375.7994 |
| 60 | 90.2 | 9.8 | 588.7834 |
| 80 | 92.6 | 5.4 | 792.5673 |
| 100 | 93.9 | 5.1 | 875.1247 |
| 150 | 96.8 | 1.2 | 988.0045 |
| 200 | 98.1 | 0.4 | 1105.5683 |
| Epochs | Accuracy (%) | Error (%) | Time (min) |
|---|---|---|---|
| 20 | 81.4 | 18.6 | 174.8957 |
| 40 | 84.6 | 15.4 | 292.0645 |
| 60 | 88.0 | 12 | 411.4756 |
| 80 | 90.2 | 9.8 | 581.8322 |
| 100 | 91.6 | 8.4 | 695.4570 |
| 150 | 94.3 | 5.7 | 808.5334 |
| 200 | 97.5 | 2.5 | 981.6873 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharif, M.I.; Khan, M.A.; Alqahtani, A.; Nazir, M.; Alsubai, S.; Binbusayyis, A.; Damaševičius, R. Deep Learning and Kurtosis-Controlled, Entropy-Based Framework for Human Gait Recognition Using Video Sequences. Electronics 2022, 11, 334. https://doi.org/10.3390/electronics11030334
Sharif MI, Khan MA, Alqahtani A, Nazir M, Alsubai S, Binbusayyis A, Damaševičius R. Deep Learning and Kurtosis-Controlled, Entropy-Based Framework for Human Gait Recognition Using Video Sequences. Electronics. 2022; 11(3):334. https://doi.org/10.3390/electronics11030334
Chicago/Turabian StyleSharif, Muhammad Imran, Muhammad Attique Khan, Abdullah Alqahtani, Muhammad Nazir, Shtwai Alsubai, Adel Binbusayyis, and Robertas Damaševičius. 2022. "Deep Learning and Kurtosis-Controlled, Entropy-Based Framework for Human Gait Recognition Using Video Sequences" Electronics 11, no. 3: 334. https://doi.org/10.3390/electronics11030334
APA StyleSharif, M. I., Khan, M. A., Alqahtani, A., Nazir, M., Alsubai, S., Binbusayyis, A., & Damaševičius, R. (2022). Deep Learning and Kurtosis-Controlled, Entropy-Based Framework for Human Gait Recognition Using Video Sequences. Electronics, 11(3), 334. https://doi.org/10.3390/electronics11030334