
Deep Learning Reader for Visually Impaired

 ,
,  ,
,  and
and 
Abstract
1. Introduction
2. Related Work
- Electronic Travel Aids (ETAs)ETAa are devices that translate environment information that are typically identified via human vision, using non-vision sensory. It includes sensing inputs such as a camera, Radio Frequency Identification (RFID), Bluetooth, or Near-Field Communication (NFC), to receive environment inputs, and a feedback modalities to deliver information to the user in a non-vision form such as such as audio, tactile, or vibrations.
- Electronic Orientation Aids (EOAs)EOAs devices provide a navigation path and identify obstacles to people with visual impairment. The objectives of EOAs devices is to improve safety and mobility in unrecognized environment by detecting obstacles and delivering information by means of audio or vibrations [25].
- Position Locator Devices (PLDs)PLDs provide a precise positioning of devices that utilizes Global Positioning System (GPS) and Geographic Information System (GIS). Such technologies have limitation that it ought to be used outdoors and need to be coupled with other sensors to identify obstacles throughout navigation
2.1. AT Based on Deep Learning Techniques
2.2. AT Based on Raspberry Pi
2.3. AT Based on Internet of Things (IoT)
2.4. Image Captioning Techniques
3. Preliminaries
3.1. Multilayer Perceptron (MLP)
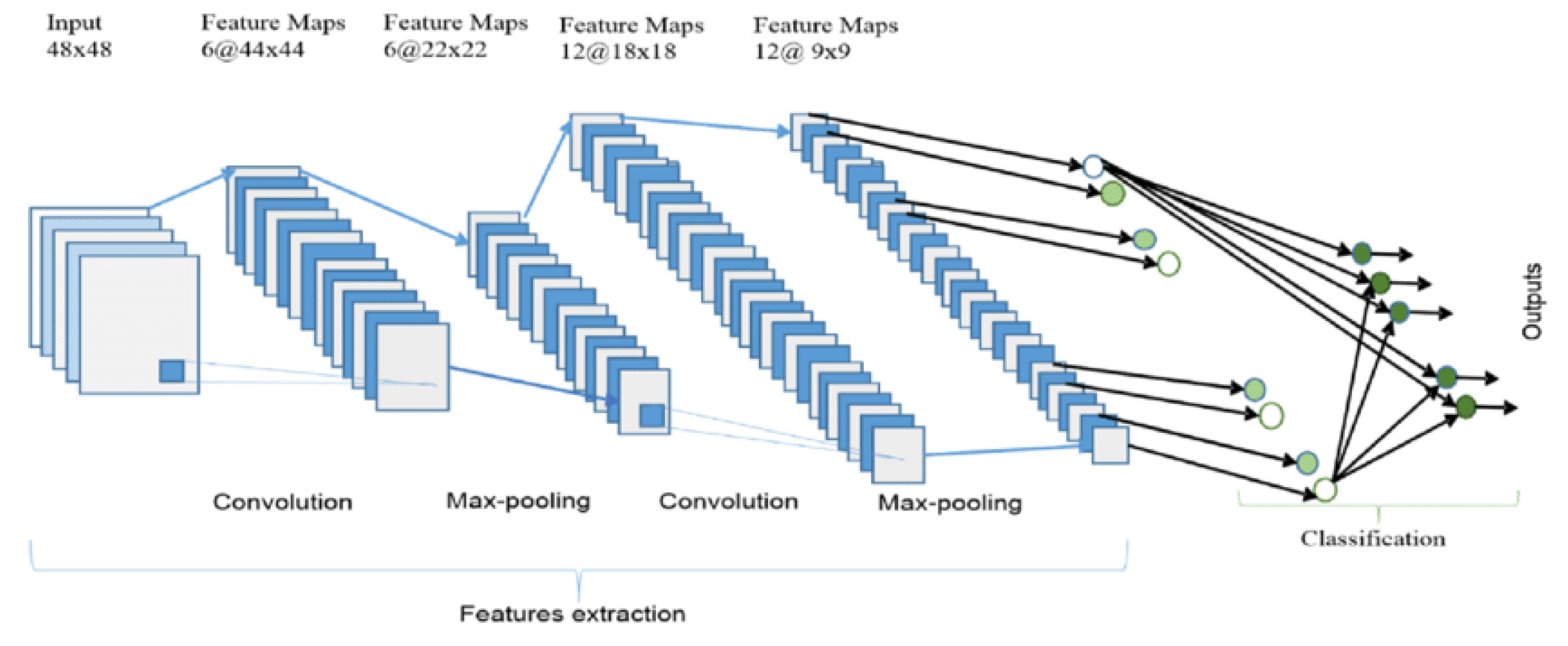
3.2. Convolutional Neural Networks (CNNs)
3.3. CNN-AlexNet
3.4. CNN-VGG16
3.5. CNN-GoogLeNet
3.6. CNN-ResNet
3.7. CNN-SqueezeNet
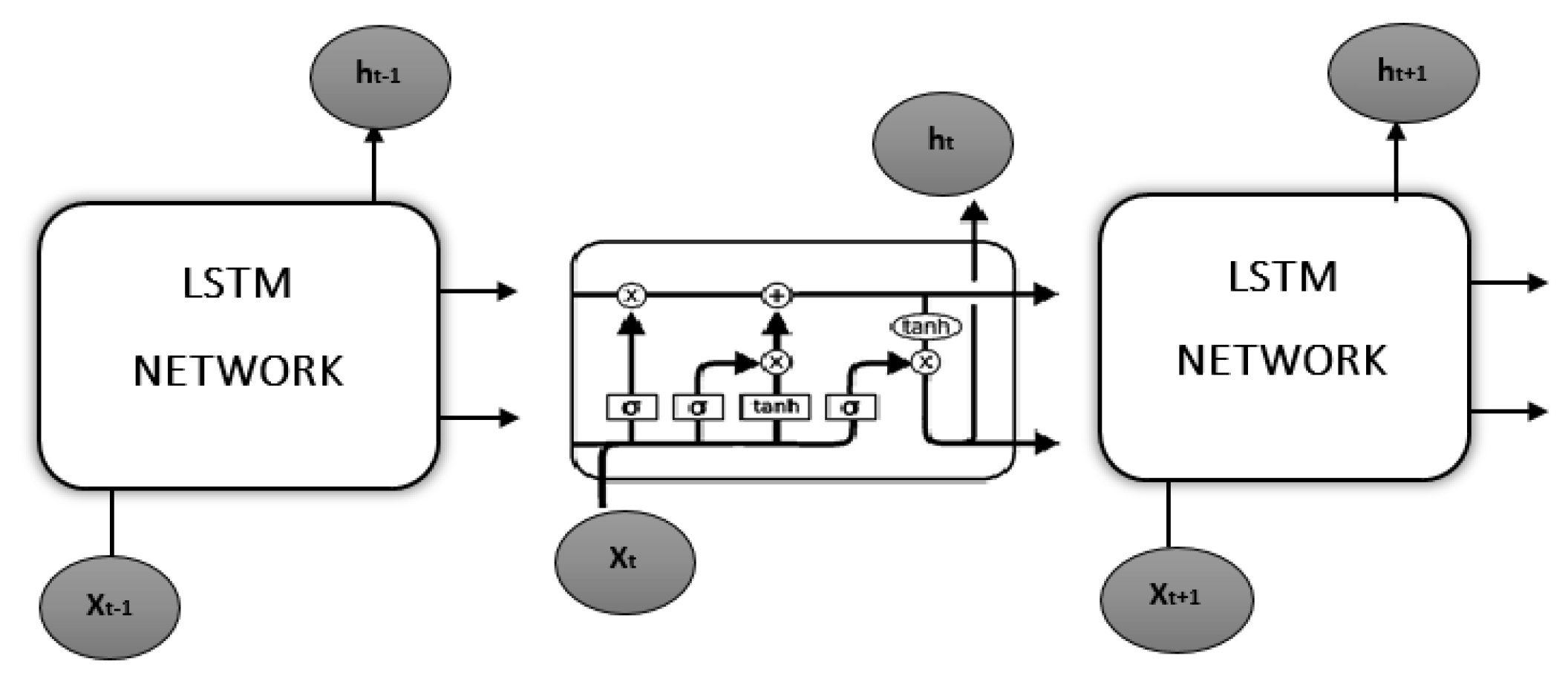
3.8. Long Short Term Memory (LSTM)
4. The Proposed CNN-LSTM Design
5. Results and Discussion
5.1. Dataset Collection
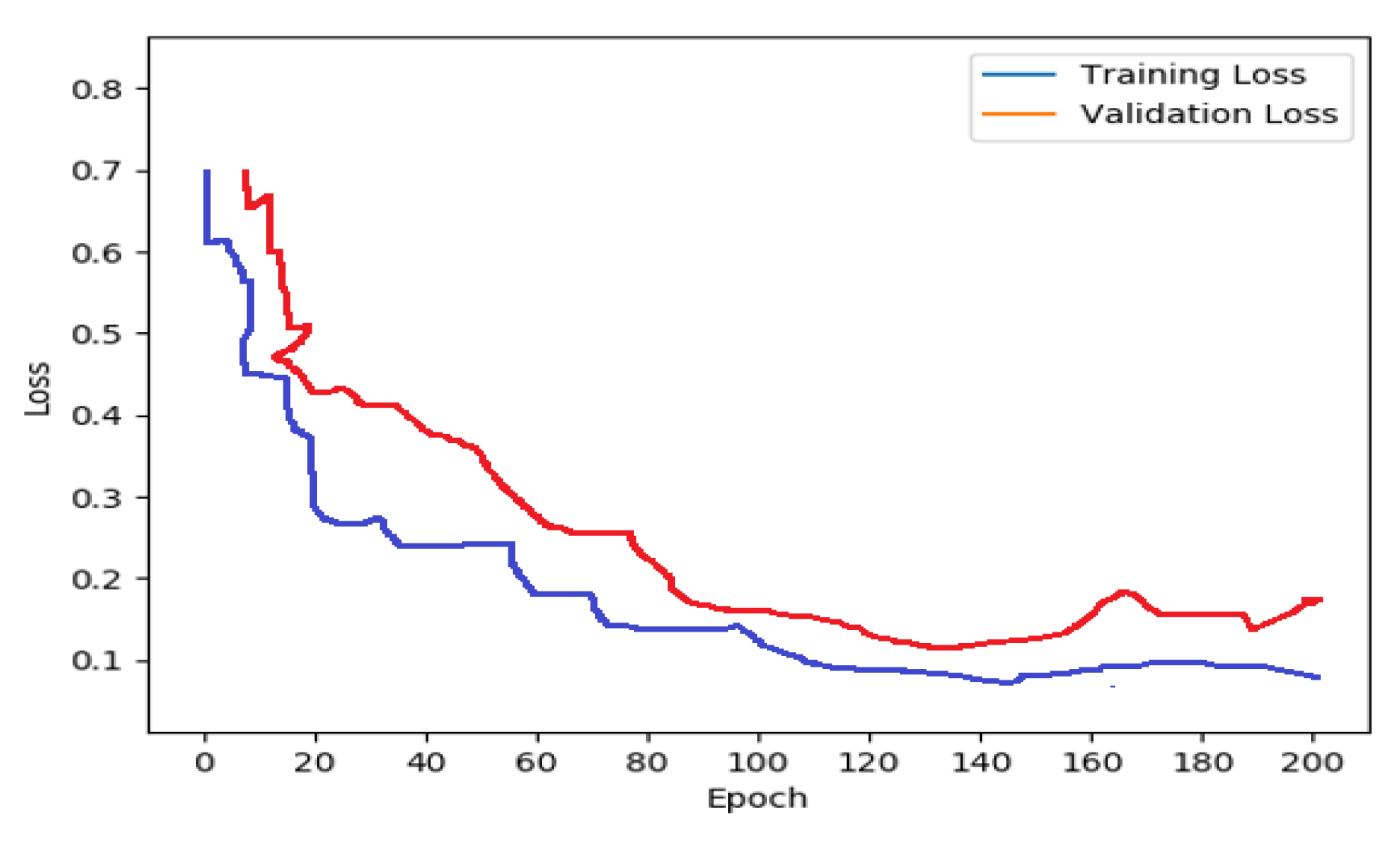
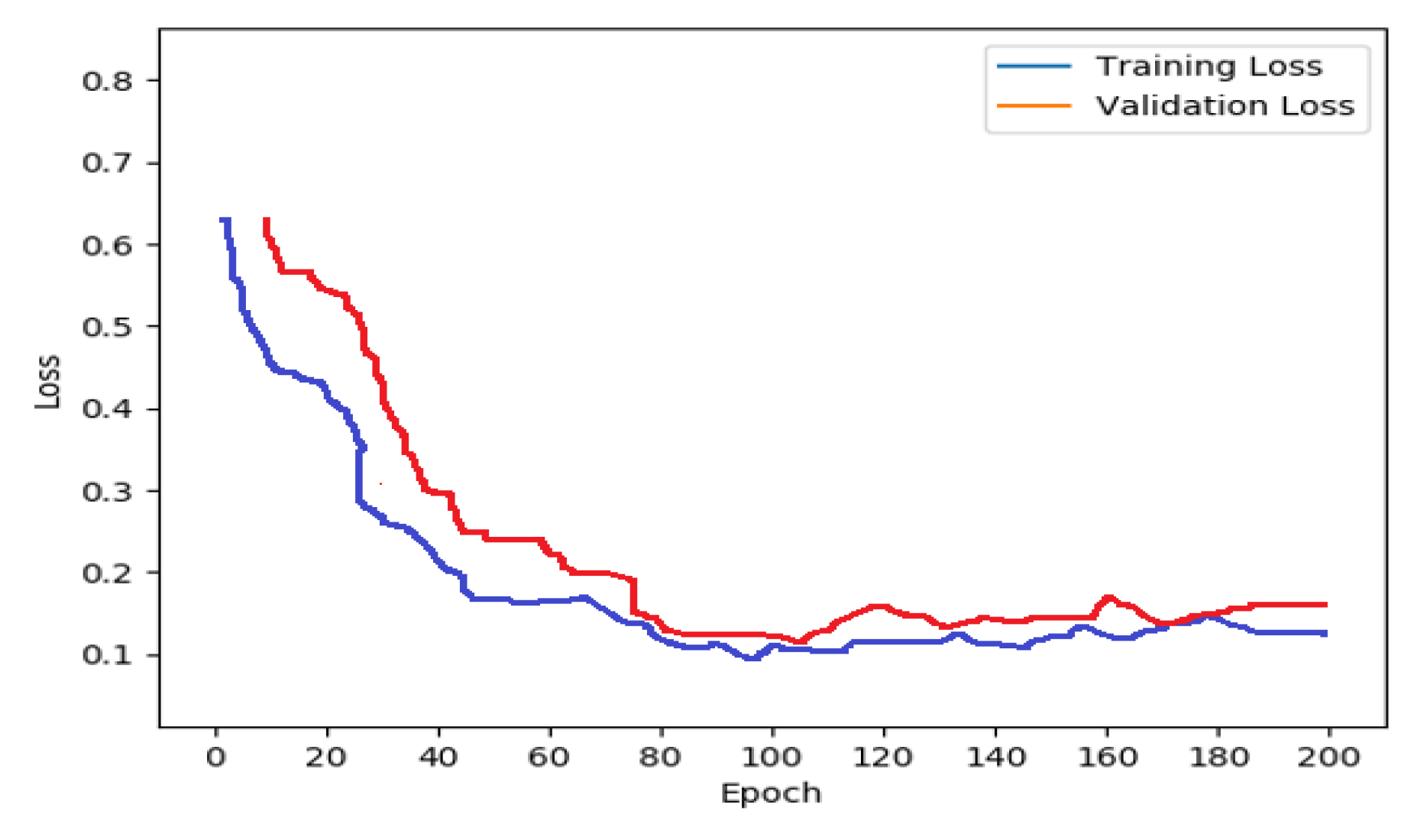
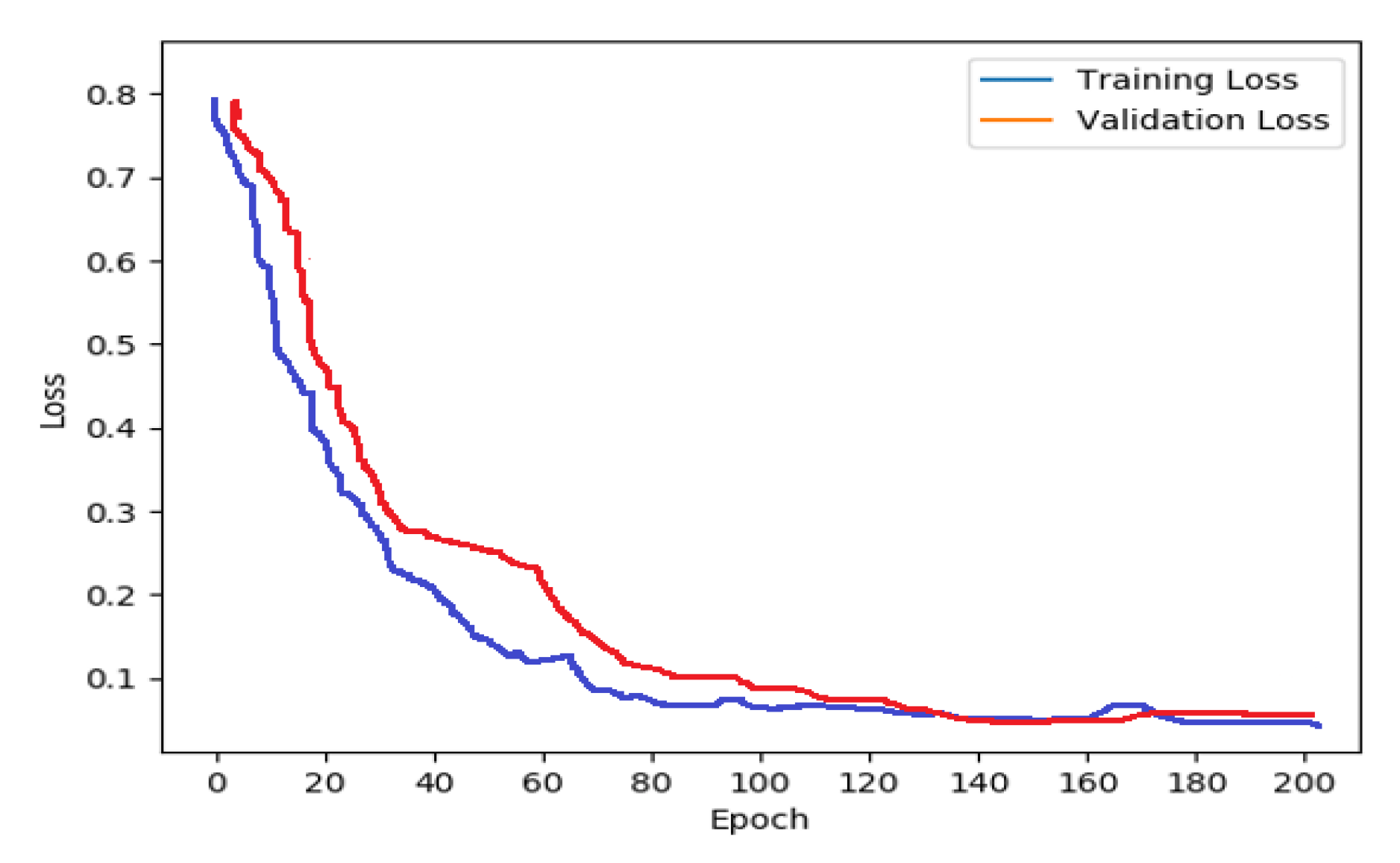
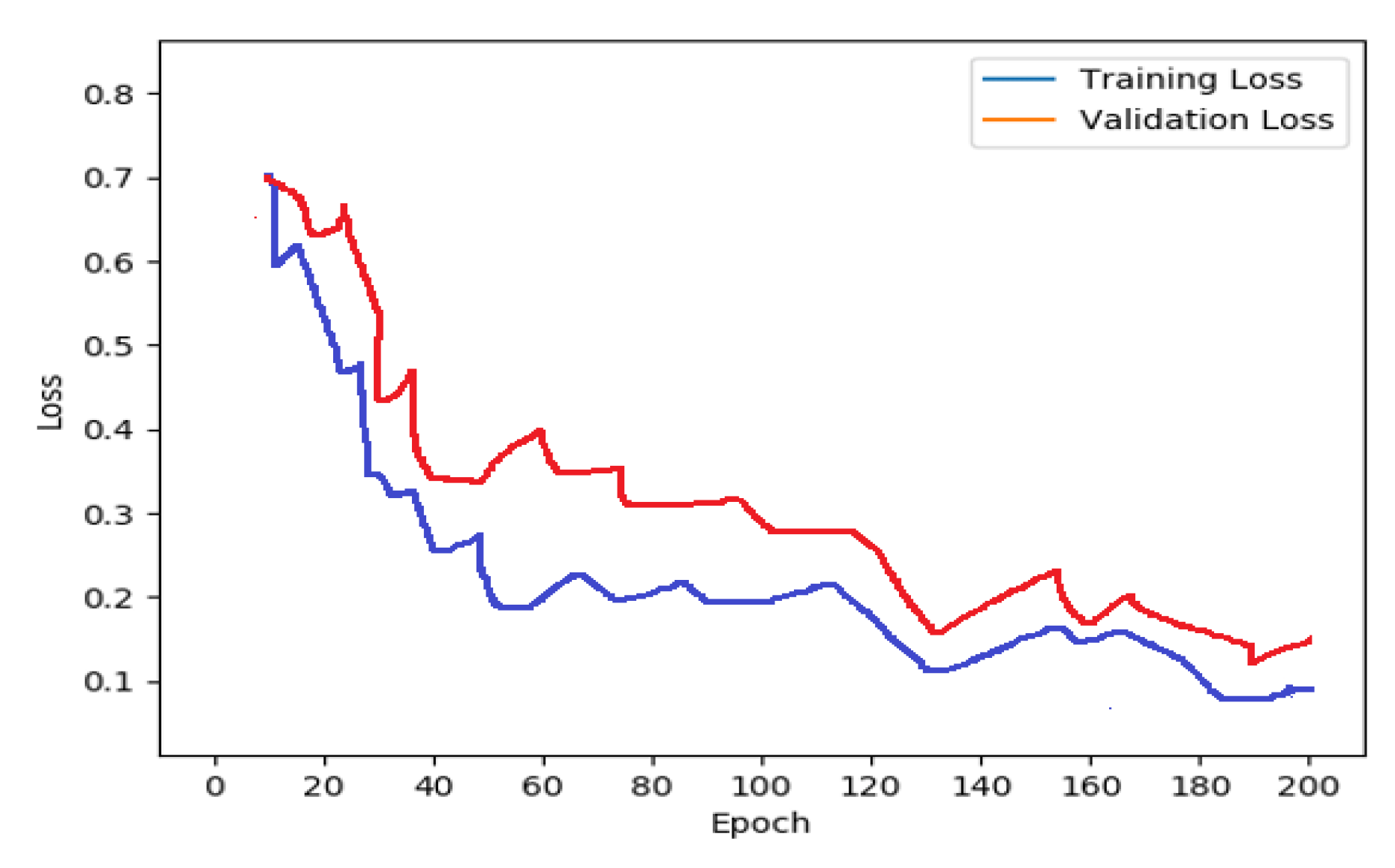
5.2. Results and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Triantafyllidis, A.K.; Tsanas, A. Applications of machine learning in real-life digital health interventions: Review of the literature. J. Med. Internet Res. 2019, 21, e12286. [Google Scholar] [CrossRef]
- Manjari, K.; Verma, M.; Singal, G. A survey on assistive technology for visually impaired. Internet Things 2020, 11, 100188. [Google Scholar] [CrossRef]
- Park, C.; Took, C.C.; Seong, J.K. Machine learning in biomedical engineering. Biomed. Eng. Lett. 2018, 8, 1–3. [Google Scholar] [CrossRef]
- Pellegrini, E.; Ballerini, L.; Hernandez, M.d.C.V.; Chappell, F.M.; González-Castro, V.; Anblagan, D.; Danso, S.; Muñoz-Maniega, S.; Job, D.; Pernet, C.; et al. Machine learning of neuroimaging for assisted diagnosis of cognitive impairment and dementia: A systematic review. Alzheimer’s Dementia Diagn. Assess. Dis. Monit. 2018, 10, 519–535. [Google Scholar] [CrossRef] [PubMed]
- Swenor, B.K.; Ramulu, P.Y.; Willis, J.R.; Friedman, D.; Lin, F.R. The prevalence of concurrent hearing and vision impairment in the United States. JAMA Intern. Med. 2013, 173, 312–313. [Google Scholar]
- Bhowmick, A.; Hazarika, S.M. An insight into assistive technology for the visually impaired and blind people: State-of-the-art and future trends. J. Multimodal User Interfaces 2017, 11, 149–172. [Google Scholar] [CrossRef]
- Lee, B.H.; Lee, Y.J. Evaluation of medication use and pharmacy services for visually impaired persons: Perspectives from both visually impaired and community pharmacists. Disabil. Health J. 2019, 12, 79–86. [Google Scholar] [CrossRef]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.Y. Traffic flow prediction with big data: A deep learning approach. IEEE Trans. Intell. Transp. Syst. 2014, 16, 865–873. [Google Scholar] [CrossRef]
- Welsh, R. Foundations of Orientation and Mobility; Technical Report; American Printing House for the Blind: Louisville, KY, USA, 1981. [Google Scholar]
- Martínez, B.D.C.; Villegas, O.O.V.; Sánchez, V.G.C.; Jesús Ochoa Domínguez, H.d.; Maynez, L.O. Visual perception substitution by the auditory sense. In Proceedings of the International Conference on Computational Science and Its Applications, Santander, Spain, 20–23 June 2011; pp. 522–533. [Google Scholar]
- Dakopoulos, D.; Bourbakis, N.G. Wearable obstacle avoidance electronic travel aids for blind: A survey. IEEE Trans. Syst. Man, Cybern. Part C (Appl. Rev.) 2009, 40, 25–35. [Google Scholar] [CrossRef]
- Li, Z.; Song, F.; Clark, B.C.; Grooms, D.R.; Liu, C. A wearable device for indoor imminent danger detection and avoidance with region-based ground segmentation. IEEE Access 2020, 8, 184808–184821. [Google Scholar] [CrossRef]
- Elkholy, H.A.; Azar, A.T.; Magd, A.; Marzouk, H.; Ammar, H.H. Classifying Upper Limb Activities Using Deep Neural Networks. In Proceedings of the International Conference on Artificial Intelligence and Computer Vision, Cairo, Egypt, 8–10 April 2020; pp. 268–282. [Google Scholar]
- Mohamed, N.A.; Azar, A.T.; Abbas, N.E.; Ezzeldin, M.A.; Ammar, H.H. Experimental Kinematic Modeling of 6-DOF Serial Manipulator Using Hybrid Deep Learning. In Proceedings of the International Conference on Artificial Intelligence and Computer Vision, Cairo, Egypt, 8–10 April 2020; pp. 283–295. [Google Scholar]
- Ibrahim, H.A.; Azar, A.T.; Ibrahim, Z.F.; Ammar, H.H.; Hassanien, A.; Gaber, T.; Oliva, D.; Tolba, F. A Hybrid Deep Learning Based Autonomous Vehicle Navigation and Obstacles Avoidance. In Proceedings of the International Conference on Artificial Intelligence and Computer Vision, Cairo, Egypt, 8–10 April 2020; pp. 296–307. [Google Scholar]
- Sayed, A.S.; Azar, A.T.; Ibrahim, Z.F.; Ibrahim, H.A.; Mohamed, N.A.; Ammar, H.H. Deep Learning Based Kinematic Modeling of 3-RRR Parallel Manipulator. In Proceedings of the International Conference on Artificial Intelligence and Computer Vision, Cairo, Egypt, 8–10 April 2020; pp. 308–321. [Google Scholar]
- Azar, A.T.; Koubaa, A.; Ali Mohamed, N.; Ibrahim, H.A.; Ibrahim, Z.F.; Kazim, M.; Ammar, A.; Benjdira, B.; Khamis, A.M.; Hameed, I.A.; et al. Drone Deep Reinforcement Learning: A Review. Electronics 2021, 10, 999. [Google Scholar] [CrossRef]
- Koubâa, A.; Ammar, A.; Alahdab, M.; Kanhouch, A.; Azar, A.T. DeepBrain: Experimental Evaluation of Cloud-Based Computation Offloading and Edge Computing in the Internet-of-Drones for Deep Learning Applications. Sensors 2020, 20, 5240. [Google Scholar] [CrossRef] [PubMed]
- Guo, T.; Dong, J.; Li, H.; Gao, Y. Simple convolutional neural network on image classification. In Proceedings of the 2017 IEEE 2nd International Conference on Big Data Analysis (ICBDA), Beijing, China, 10–12 March 2017; pp. 721–724. [Google Scholar]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Shelton, A.; Ogunfunmi, T. Developing a deep learning-enabled guide for the visually impaired. In Proceedings of the 2020 IEEE Global Humanitarian Technology Conference (GHTC), Seattle, WA, USA, 29 October–1 November 2020; pp. 1–8. [Google Scholar]
- Tapu, R.; Mocanu, B.; Zaharia, T. Wearable assistive devices for visually impaired: A state of the art survey. Pattern Recognit. Lett. 2020, 137, 37–52. [Google Scholar] [CrossRef]
- Swathi, K.; Vamsi, B.; Rao, N.T. A Deep Learning-Based Object Detection System for Blind People. In Smart Technologies in Data Science and Communication; Springer: Berlin/Heidelberg, Germany, 2021; pp. 223–231. [Google Scholar]
- Rao, A.S.; Gubbi, J.; Palaniswami, M.; Wong, E. A vision-based system to detect potholes and uneven surfaces for assisting blind people. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016; pp. 1–6. [Google Scholar]
- Hoang, V.N.; Nguyen, T.H.; Le, T.L.; Tran, T.T.H.; Vuong, T.P.; Vuillerme, N. Obstacle detection and warning for visually impaired people based on electrode matrix and mobile Kinect. In Proceedings of the 2015 2nd National Foundation for Science and Technology Development Conference on Information and Computer Science (NICS), Ho Chi Minh City, Vietnam, 16–18 September 2015; pp. 54–59. [Google Scholar]
- Calabrese, B.; Velázquez, R.; Del-Valle-Soto, C.; de Fazio, R.; Giannoccaro, N.I.; Visconti, P. Solar-Powered Deep Learning-Based Recognition System of Daily Used Objects and Human Faces for Assistance of the Visually Impaired. Energies 2020, 13, 6104. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, K.; Yi, W.; Lian, S. Deep learning based wearable assistive system for visually impaired people. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–29 October 2019. [Google Scholar]
- Afif, M.; Ayachi, R.; Said, Y.; Pissaloux, E.; Atri, M. An evaluation of retinanet on indoor object detection for blind and visually impaired persons assistance navigation. Neural Process. Lett. 2020, 51, 1–15. [Google Scholar] [CrossRef]
- Tasnim, R.; Pritha, S.T.; Das, A.; Dey, A. Bangladeshi Banknote Recognition in Real-Time Using Convolutional Neural Network for Visually Impaired People. In Proceedings of the 2021 2nd International Conference on Robotics, Electrical and Signal Processing Techniques (ICREST), Dhaka, Bangladesh, 5–7 January 2021; pp. 388–393. [Google Scholar]
- Mukhiddinov, M.; Cho, J. Smart glass system using deep learning for the blind and visually impaired. Electronics 2021, 10, 2756. [Google Scholar] [CrossRef]
- Mishra, P.; Kumar, S.; Chaube, M.K.; Shrawankar, U. ChartVi: Charts summarizer for visually impaired. J. Comput. Lang. 2022, 69, 101107. [Google Scholar] [CrossRef]
- Zamir, M.F.; Khan, K.B.; Khan, S.A.; Rehman, E. Smart Reader for Visually Impaired People Based on Optical Character Recognition. In Proceedings of the International Conference on Intelligent Technologies and Applications, Bahawalpur, Pakistan, 6–8 November 2019; pp. 79–89. [Google Scholar]
- Cheng, R.; Hu, W.; Chen, H.; Fang, Y.; Wang, K.; Xu, Z.; Bai, J. Hierarchical visual localization for visually impaired people using multimodal images. Expert Syst. Appl. 2021, 165, 113743. [Google Scholar] [CrossRef]
- Sahithi, P.; Bhavana, V.; ShushmaSri, K.; Jhansi, K.; Madhuri, C. Speech Mentor for Visually Impaired People. In Smart Intelligent Computing and Applications; Springer: Berlin/Heidelberg, Germany, 2022; Volume 1, pp. 441–450. [Google Scholar]
- Chauhan, S.; Patkar, D.; Dabholkar, A.; Nirgun, K. Ikshana: Intelligent Assisting System for Visually Challenged People. In Proceedings of the 2021 2nd International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 7–9 October 2021; pp. 1154–1160. [Google Scholar]
- Flores, I.; Lacdang, G.C.; Undangan, C.; Adtoon, J.; Linsangan, N.B. Smart Electronic Assistive Device for Visually Impaired Individual through Image Processing. In Proceedings of the 2021 IEEE 13th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management (HNICEM), Manila, Philippines, 28–30 November 2021; pp. 1–6. [Google Scholar]
- Aravindan, C.; Arthi, R.; Kishankumar, R.; Gokul, V.; Giridaran, S. A Smart Assistive System for Visually Impaired to Inform Acquaintance Using Image Processing (ML) Supported by IoT. In Hybrid Artificial Intelligence and IoT in Healthcare; Springer: Berlin/Heidelberg, Germany, 2021; pp. 149–164. [Google Scholar]
- Rahman, M.A.; Sadi, M.S. IoT enabled automated object recognition for the visually impaired. Comput. Methods Programs Biomed. Update 2021, 1, 100015. [Google Scholar] [CrossRef]
- Chun, P.J.; Yamane, T.; Maemura, Y. A deep learning-based image captioning method to automatically generate comprehensive explanations of bridge damage. Comput.-Aided Civ. Infrastruct. Eng. 2022, 37, 1387–1401. [Google Scholar] [CrossRef]
- Yang, Q.; Ni, Z.; Ren, P. Meta captioning: A meta learning based remote sensing image captioning framework. ISPRS J. Photogramm. Remote Sens. 2022, 186, 190–200. [Google Scholar] [CrossRef]
- Wang, Y.; Xiao, B.; Bouferguene, A.; Al-Hussein, M.; Li, H. Vision-based method for semantic information extraction in construction by integrating deep learning object detection and image captioning. Adv. Eng. Inform. 2022, 53, 101699. [Google Scholar] [CrossRef]
- Afyouni, I.; Azhar, I.; Elnagar, A. AraCap: A hybrid deep learning architecture for Arabic Image Captioning. Procedia Comput. Sci. 2021, 189, 382–389. [Google Scholar] [CrossRef]
- Shen, X.; Liu, B.; Zhou, Y.; Zhao, J.; Liu, M. Remote sensing image captioning via Variational Autoencoder and Reinforcement Learning. Knowl.-Based Syst. 2020, 203, 105920. [Google Scholar] [CrossRef]
- Denić, D.; Aleksov, P.; Vučković, I. Object Recognition with Machine Learning for People with Visual Impairment. In Proceedings of the 2021 15th International Conference on Advanced Technologies, Systems and Services in Telecommunications (TELSIKS), Nis, Serbia, 20–22 October 2021; pp. 389–392. [Google Scholar]
- Felix, S.M.; Kumar, S.; Veeramuthu, A. A smart personal AI assistant for visually impaired people. In Proceedings of the 2018 2nd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 11–12 May 2018; pp. 1245–1250. [Google Scholar]
- Durgadevi, S.; Thirupurasundari, K.; Komathi, C.; Balaji, S.M. Smart Machine Learning System for Blind Assistance. In Proceedings of the 2020 International Conference on Power, Energy, Control and Transmission Systems (ICPECTS), Chennai, India, 10–11 December 2020; pp. 1–4. [Google Scholar]
- Koubaa, A.; Azar, A.T. Deep Learning for Unmanned Systems; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Popescu, M.C.; Balas, V.E.; Perescu-Popescu, L.; Mastorakis, N. Multilayer perceptron and neural networks. WSEAS Trans. Circuits Syst. 2009, 8, 579–588. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.; Asari, V.K. A state-of-the-art survey on deep learning theory and architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Yan, S. Understanding LSTM Networks, Volume 11. 2015. Available online: https://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 11 October 2022).
- Hodosh, M.; Young, P.; Hockenmaier, J. Framing image description as a ranking task: Data, models and evaluation metrics. J. Artif. Intell. Res. 2013, 47, 853–899. [Google Scholar] [CrossRef]
- Johnson, J.; Karpathy, A.; Fei-Fei, L. Densecap: Fully convolutional localization networks for dense captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4565–4574. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author(s) | Year | Technique Used | Developed System |
|---|---|---|---|
| Denic et al. [44] | 2019 | CNN | Object Detection System |
| Felix et al. [45] | 2019 | Android Mobile App | Blind Assistive technology |
| Durgadevi et al. [46] | 2020 | Image classification | Indoor object detection |
| Lin et al. [27] | 2019 | DL | Develop a system that assists people in determining their perspective of their environment. |
| Zamir et al. [32] | 2019 | Raspberry Pi | OCR based Text Detection system |
| Calabrese et al. [26] | 2020 | DL | object detection system |
| Afif et al. [28] | 2020 | Deep CNN | indoor object detector system |
| Afif et al. [28] | 2020 | Deep CNN | indoor object detector system |
| Shen et al. [43] | 2020 | CNN Variational Autoencoder and Reinforcement Learning | Remote sensing image captioning |
| Cheng et al. [33] | 2021 | NetVLAD | image description System |
| Tasnim et al. [29] | 2021 | CNN | Bangladeshi banknotes detection system |
| Mukhiddinov et al. [30] | 2021 | CNN | Smart Glass for object detection |
| Afyouni et al. [42] | 2021 | CNN, LSTM | Arabic Image Caption Generation |
| Sahithi et al. [34] | 2022 | Raspberry Pi and OCR | Voice mentor system that reads text content |
| Chauhan et al. [35] | 2021 | Raspberry Pi and OCR | Ikshana: Character, Facial, object and currency identification system |
| Flores et al. [36] | 2021 | Image processing techniques and ultrasonic sensors | Obstacle/object detection |
| Aravindan et al. [37] | 2021 | Machine Learning and IoT | Recognise visually impaired people’s acquaintances in their regular activities. |
| Rahman [38] | 2021 | Deep Learning and IoT | Object and currency note identification |
| Mishra et al. [31] | 2022 | CNN-VGG16 | Generate the summarization of Chart images |
| Chun et al. [39] | 2022 | CNN | Bridge damage detection captioning method |
| Yang et al. [40] | 2022 | LSTM | Remote sensing image captioning |
| Wang et al. [41] | 2022 | CNN, Mask-RCNN | Extract Visual information about construction images |
 |  |
|---|---|
| GoogleNet | Alxenet |
 |  |
| ResNet | VGG16 |
 | |
| SqueezeNet |
| Sample Image | Description/Caption |
|---|---|
 | A child in a pink dress is climbing up a set of stairs in an entry way. |
 | A man stands in front of a very tall building. |
 | The white dog is playing in a green field with a yellow toy. |
| CNNs Architectures | Input Image Size | Activation Function | Batch Size, Epochs | Top 5 Error Rate |
|---|---|---|---|---|
| Alexnet | 227 × 227 × 3 | Softmax | 15.3% | |
| GoogleNet | 224 × 224 × 3 | ReLU | 6.67% | |
| VGG 16 | Softmax | 512, 200 | 7.32% | |
| ResNet | ReLU | 3.6% | ||
| SqueezeNet | ReLU | 19.7% |
| Architecture | BLEU-1 | BLEU-2 |
|---|---|---|
| Alexnet | 0.6347 | 0.6217 |
| GoogleNet | 0.7286 | 0.7368 |
| VGG 16 | 0.7824 | 0.7303 |
| ResNet | 0.8126 | 0.8026 |
| SqueezeNet | 0.6012 | 0.6175 |
| Author(s) | Deep Learning Technique Utilized | Application | BLEU-1 | BLEU-2 |
|---|---|---|---|---|
| Chun et al. | CNN Model | Bridge Damage Detection | 0.768 | 0.732 |
| Yang et al. | LSTM | Remote sensing image captioning | 0.8108 | 0.7451 |
| Wang et al. | CNN, Mask R-CNN | Extract Visual information about construction images | 0.6100 | 0.5200 |
| Afyouni et al. | CNN, LSTM | Arabic Image Caption Generation | 0.81 (Similarity Score) | |
| Shen et al. | CNN, VA and Reinforcement Learning | Remote sensing image captioning | 0.7934 | 0.6794 |
| The Proposed Method | CNN, LSTM– Alexnet | Image Captioning for Visually Impaired People | 0.6347 | 0.6217 |
| CNN, LSTM–GoogleNet | 0.7286 | 0.7368 | ||
| CNN, LSTM–VGG 16 | 0.7824 | 0.7303 | ||
| CNN, LSTM–ResNet | 0.8126 | 0.8026 | ||
| CNN, LSTM–SqueezeNet | 0.6012 | 0.6175 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ganesan, J.; Azar, A.T.; Alsenan, S.; Kamal, N.A.; Qureshi, B.; Hassanien, A.E. Deep Learning Reader for Visually Impaired. Electronics 2022, 11, 3335. https://doi.org/10.3390/electronics11203335
Ganesan J, Azar AT, Alsenan S, Kamal NA, Qureshi B, Hassanien AE. Deep Learning Reader for Visually Impaired. Electronics. 2022; 11(20):3335. https://doi.org/10.3390/electronics11203335
Chicago/Turabian StyleGanesan, Jothi, Ahmad Taher Azar, Shrooq Alsenan, Nashwa Ahmad Kamal, Basit Qureshi, and Aboul Ella Hassanien. 2022. "Deep Learning Reader for Visually Impaired" Electronics 11, no. 20: 3335. https://doi.org/10.3390/electronics11203335
APA StyleGanesan, J., Azar, A. T., Alsenan, S., Kamal, N. A., Qureshi, B., & Hassanien, A. E. (2022). Deep Learning Reader for Visually Impaired. Electronics, 11(20), 3335. https://doi.org/10.3390/electronics11203335