2. Background of LUT-Based Mealy FSMs
A Mealy FSM is characterized by sets of states
A, inputs
X, outputs
Y, state variables
T, and input memory functions (IMFs)
D [
6]. These sets are the following:
,
,
,
, and
. So, a Mealy FSM has M states, L inputs, N outputs, R state variables and R input memory functions. The values of the first three parameters are independent of the FSM circuit designer. The value of R can be chosen by a designer. The minimum value of R is determined as
The Formula (
1) determines so-called maximum binary state assignment. The maximum value of R corresponds to so-called one-hot state assignment:
[
20].
The state variables
are used for creating state codes
. An input memory function
can set up the binary value of the
r-th bit of the code
. To keep state codes, a special register RG is used. The RG consists on R flip-flops controlled by two pulses,
and
[
21]. The pulse
loads the code
of the initial state
into RG. The synchronization pulse
allows loading a state code into RG. This code is determined by the values of IMFs. We discuss a case when the RG consists of flip-flops with informational inputs of D type. This is the most popular type of flip-flops using in the FPGA-based design [
18].
In this article, we discuss a case when the internal resources of an FPGA chip are used for implementing FSM circuits. These resources include LUTs, flip-flops, programmable interconnections, synchronization tree, programmable input-outputs [
22,
23]. The LUTs and flip-flops are combined into CLBs.
A LUT is a block having
inputs and a single output [
20,
24]. A LUT may implement an arbitrary Boolean function including no more than
arguments. The value of
is rather small [
22]. If the number of arguments of a Boolean function exceeds
, then it is necessary to combine together some LUTs. It is quite possible that a function is represented by a multi-CLB circuit. In this case, it is necessary to diminish the number of LUTs and their levels in the corresponding circuit [
25,
26]. In this article we use the symbol LUTer to show that a corresponding logic blocks includes LUTs, flip-flops and interconnections.
An FSM logic circuit is represented by the following systems of Boolean functions (SBFs) [
9]:
The SBF (
2) represents the function of transitions, the SBF (
3) represents the function of outputs [
6]. The SBFs (
2) and (
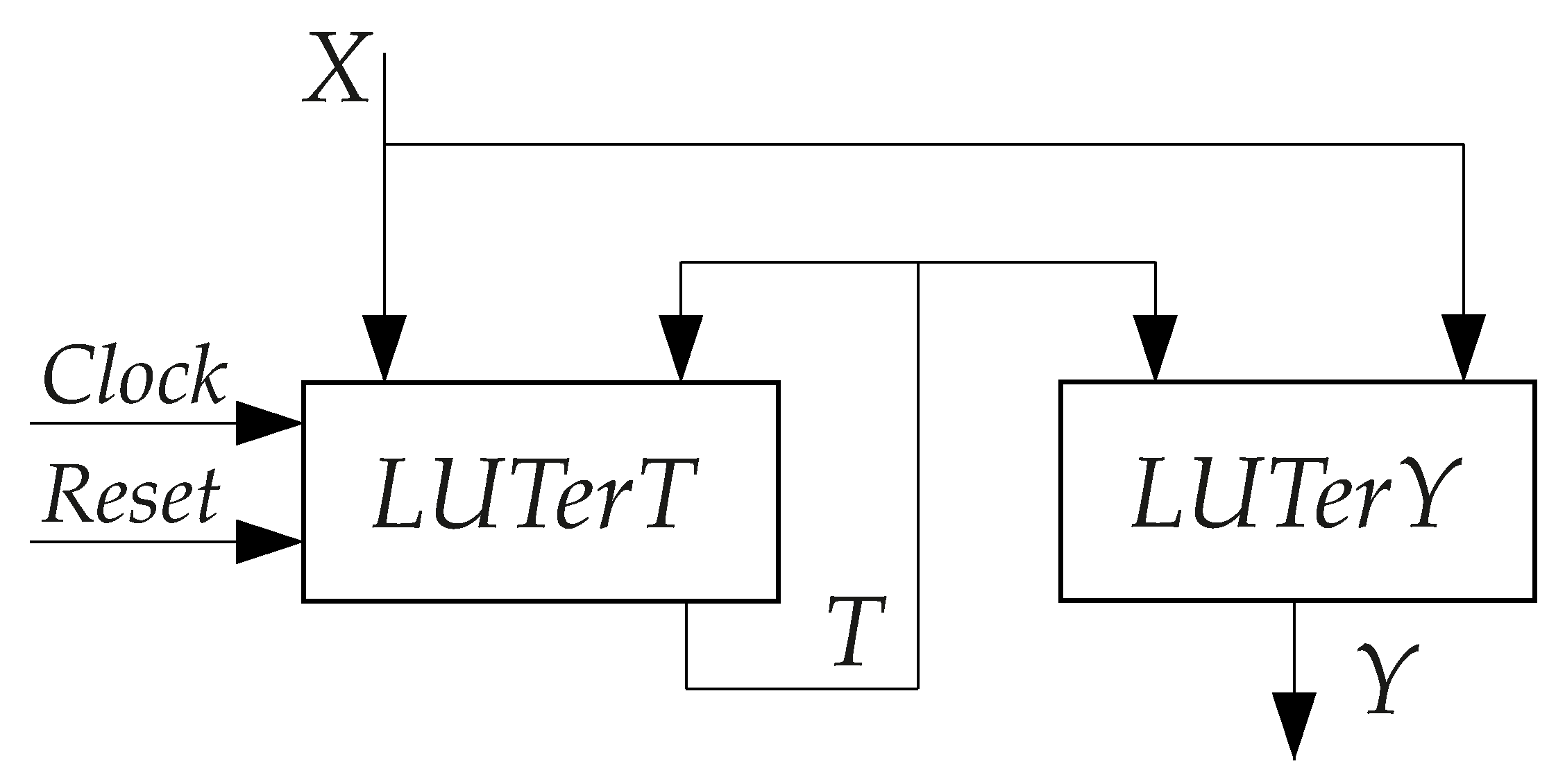
3) represent a structural diagram of
P Mealy FSM (
Figure 1) [
6].
In
P FSMs, the block
is a block of IMFs. This block implements the SBF (
2) and loads the next state code into RG. The register RG is distributed among the LUTs included into CLBs of
.The flip-flops of RG are controlled by pulses
and
. The block
is a block of output logic implementing the SBF (
3).
Obviously, the Functions (
2) and (
3) depend on state variables
and FSM inputs
. Let a function
depend on
state variables and
inputs. If the condition
holds, then a corresponding logic circuit consists of a single LUT. If the condition (
4) holds for each function
, then the FSM circuit includes exactly
LUTs. Such a circuit is single-level. This is the best possible solution providing minimum values of the required chip area, power consumption and cycle time (in other words, the maximum value of operating frequency).
However, FSMs can have up to 10 state variables and 30 inputs [
6]. At the same time, the modern LUTs have
inputs. So, it is quite possible that condition (
4) will be violated for at least a single function
. In this case, it is necessary to use various optimization strategies to optimize the characteristics of an FSM circuit. Our current paper deals with the area reducing problem. Let us analyze some approaches used to solve this problem.
3. Relative Works
Methods for solving this problem can be found in a huge number of scientific papers and monographs [
10,
21,
25,
27,
28,
29,
30,
31,
32,
33,
34]. In the case of LUT-based devices, the occupied chip area is estimated by the required numbers of LUTs (LUT counts) [
10]. To diminish the LUT count, three groups of methods are used: (1) the functional decomposition (FD); (2) the optimal state assignment; (3) the structural decomposition (SD). Methods from different groups can be applied simultaneously [
30].
In the case of decomposition, Functions (
2) and (
3) are represented by systems of partial functions [
29,
35]. Each partial Boolean function has no more than
arguments. Due to it, each PBF is represented by a single-LUT circuit. Both FD and SD lead to multi-level FSM circuits. However, these circuits differ in the nature of interconnections [
11]. In the case of FD, the resulting circuit has an irregular interconnect structure in which the same variables
and
appear at different logical levels of the circuit. In the case of SD, an FSM circuit includes from two to four large logic blocks [
30]. These blocks have unique systems of inputs and outputs. Due to it, the SD-based FSM circuits have regular systems of interconnections. As shown in the article [
11], SD-based circuits have better characteristics compared to equivalent FD-based circuits. In this article, we discuss a way for improvement some SD-based method.
In the case of LUT-based FSMs, a state assignment is optimal if it allows excluding the maximum possible number of literals from the sum-of-products of Functions (
2) and (
3) [
36]. For the possibility of a single-level implementation of an FSM circuit, it is necessary to exclude such amount of literals that condition (
4) is satisfied for each function
. However, this result is possible only for sufficiently simple FSMs [
34]. Therefore, in most cases, state encoding methods have an auxiliary nature. If condition (
4) is not satisfied after the state assignment, then it is necessary to use other optimization methods.
Very often, the methods of SD are based on finding a partition of the state set
A by classes of compatible states. One of such methods is a method of twofold state assignment (TSA) [
12,
37]. The method is based on construction a partition
of the set A. Each class
determines sets
. The set
includes
FSM inputs causing transitions from states
. The set
consists of FSM outputs produced during the transitions from states
. The set
includes input memory functions determining MBCs of transition states.
There are
states in each class
. Inside each class, these states are encoded by partial maximum binary codes
having
bits:
To encode states
, the variables
are used. The sets
form a set
V having
elements:
A state
is compatible with states
, if the including this state into
does not violate the following condition:
To optimize the FSM logic circuit, it is necessary to minimize the value of
I. This approach leads to the so-called
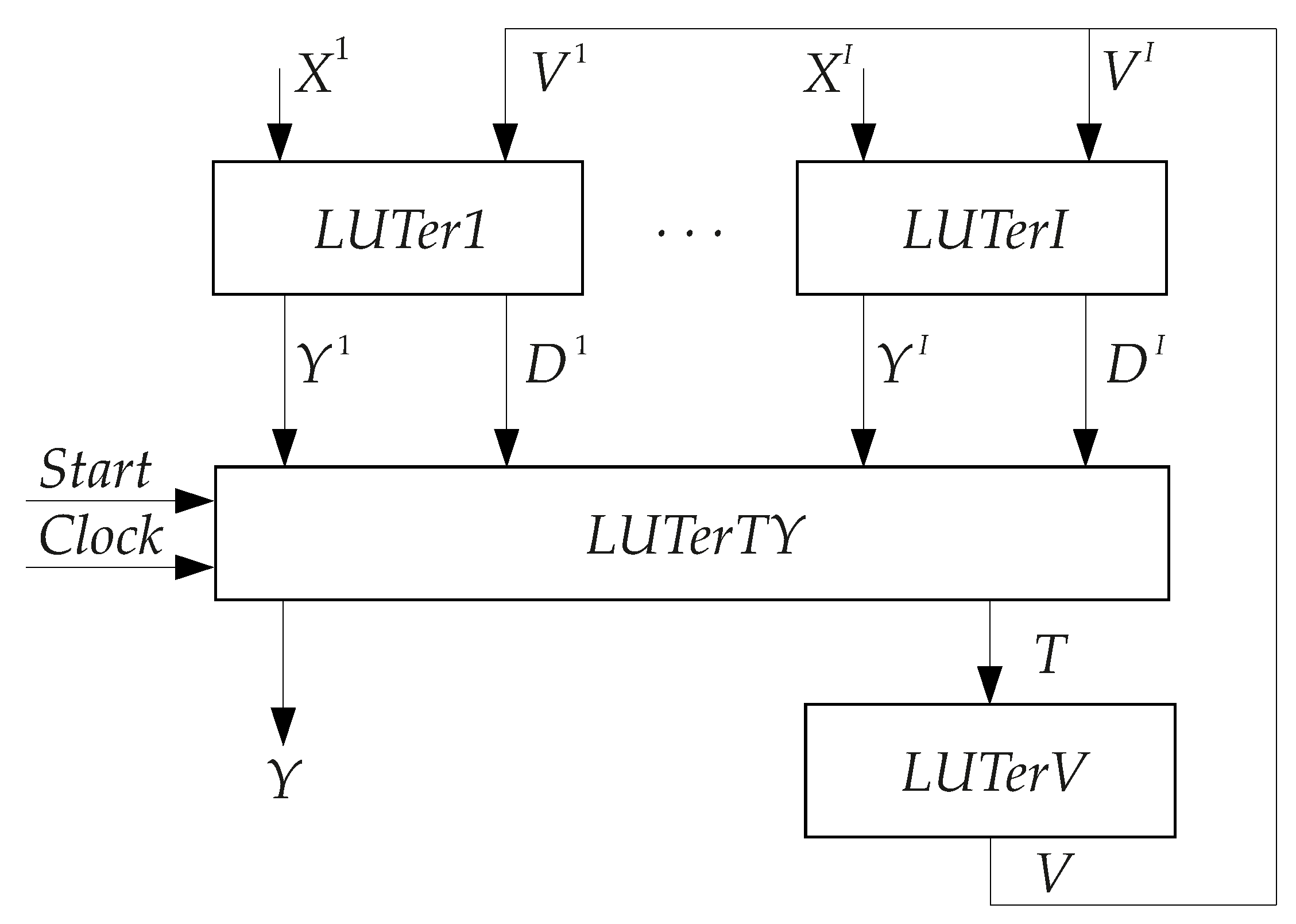
Mealy FSM (
Figure 2).
In
Mealy FSMs, each state
has two codes. These codes are: (1) the maximum binary state code
and (2) the partial state code
determining a particular state as an element of a particular class. A block
corresponds to the class
. This block generates the following systems of PBFs:
The LUTerTY creates resulting values of functions
. Each element of LUTerTY implements the following SBFs:
The block
contains the flip-flops of RG. The pulses
and
enter this block to control the operation of RG.
As follows from (
8) and (
9), the partial functions depend on state variables
. These state variables are produced by the transformation of the state variables
. To transform the codes
, the block
generates the following SBF:
As follows from [
37], the circuits of
FSMs require fewer LUTs than the circuits of equivalent
P Mealy FSMs. If the condition
holds, then the circuits of
FSMs have exactly three levels of LUTs. As a rule [
37], they have higher values of maximum operating frequencies than they are for circuits of equivalent
P Mealy FSMs.
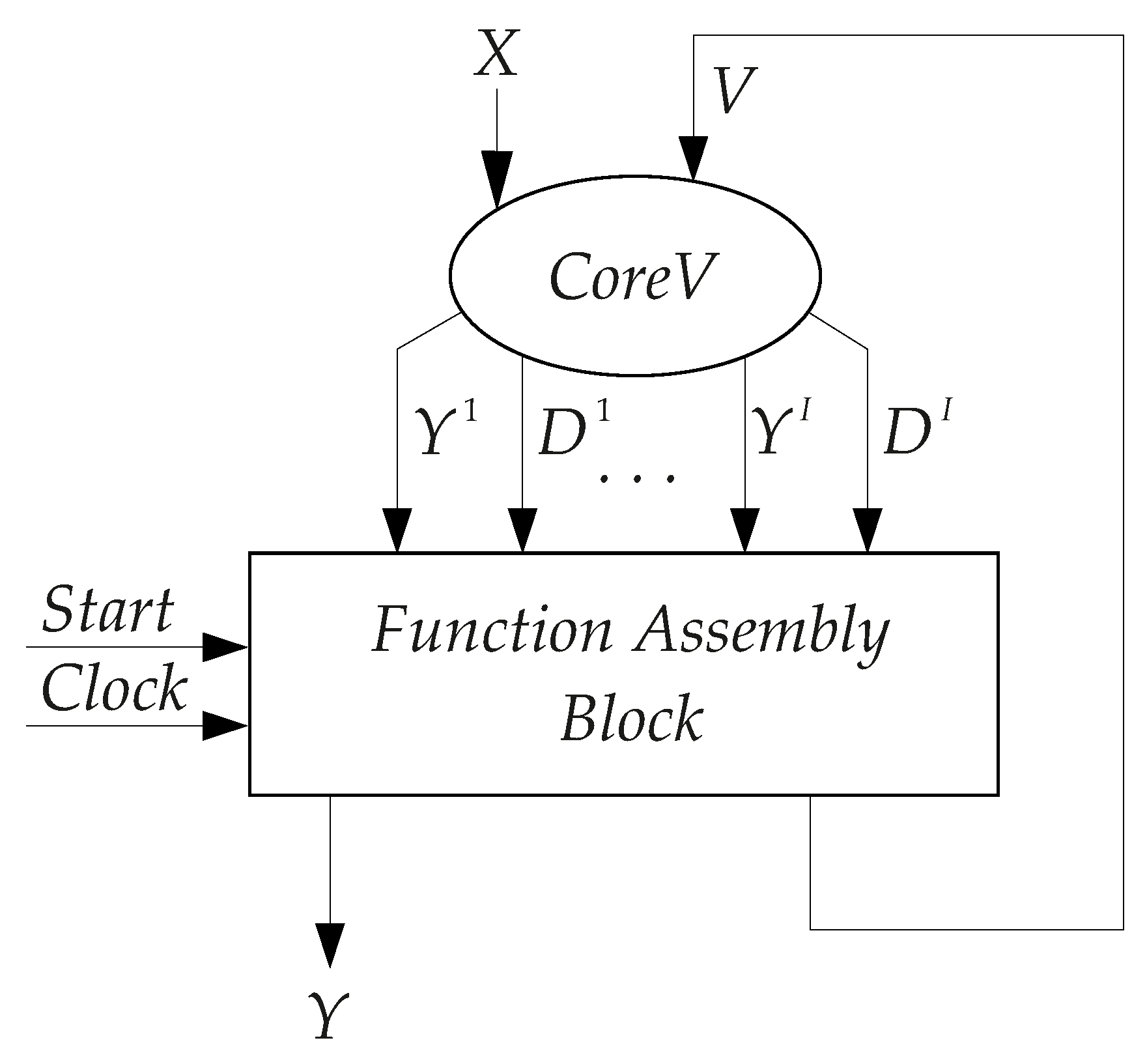
We will call the FSM core a block generating partial functions depending on state variables. In
FSMs, there is the
consisting of blocks
-
. All other functions are generated by a function assembly block (FAB). In
FSMs, the FAB consists of blocks
and
. Using this terminology, we can represent the structural diagram of
FSM in its generalized form (
Figure 3).
As follows from
Figure 3, all PBFs depend on both inputs
and state variables
. So, the transformation
into
is executed for all states
. However, if condition (
4) is satisfied for some state
, then there is no need for the code transformation noted above. If we reduce the number of states whose codes are transformed, then it is possible to reduce both the number of classes (
I) and the value of the parameter
. This is an approach proposed in our current paper.
4. Main Idea of the Proposed Method
The transitions from a state
depend on FSM inputs from a set
. This set includes
elements. Let the following condition hold:
If the condition (
14) takes place, then each PBF generated during the transitions from
is represented by a single-LUT circuit. So, there is no need in the partial codes for such states
. So, the partial codes
should be generated only for states for which the condition (
14) is violated. This conclusion is the basis for a method proposed in this article.
We propose to divide the set
A by sets
and
. If the condition (
14) holds for a state
, then this state is included into the set
. Otherwise, this state is included into the set
. The states
form a core denoted as a
, whereas the states
form a core denoted as a
. The transformation of state codes is executed only for the states
.
The
determines the sets
,
, and
. The first set includes FSM inputs determining the transitions from the states
. The second set consists of FSM outputs produced during the transitions from these states. The outputs from the set
are produced only during transitions from the states of the
. The outputs from the set
are shared between both cores. The third set includes IMFs generated during the transitions from the states
. The following SBFs determine the
:
The
determines the sets
and
. The first set includes FSM inputs determining the transitions from the states
. The second set consists of FSM outputs produced during the transitions from these states. The following SBFs determine the
:
The
is based on the partition
of the set
. This partition is constructed in the same way as the partition
. Each class of the partition
determines the sets
,
,
and
. These sets are similar to the corresponding sets of partial functions considered for the partition
. The circuit of
is determined by SBFs similar to SBFs (
8) and (
9). These SBFs are the following:
To generate the outputs
and state variables, it is necessary to use FAB. We propose to combine together the blocks FAB,
, and
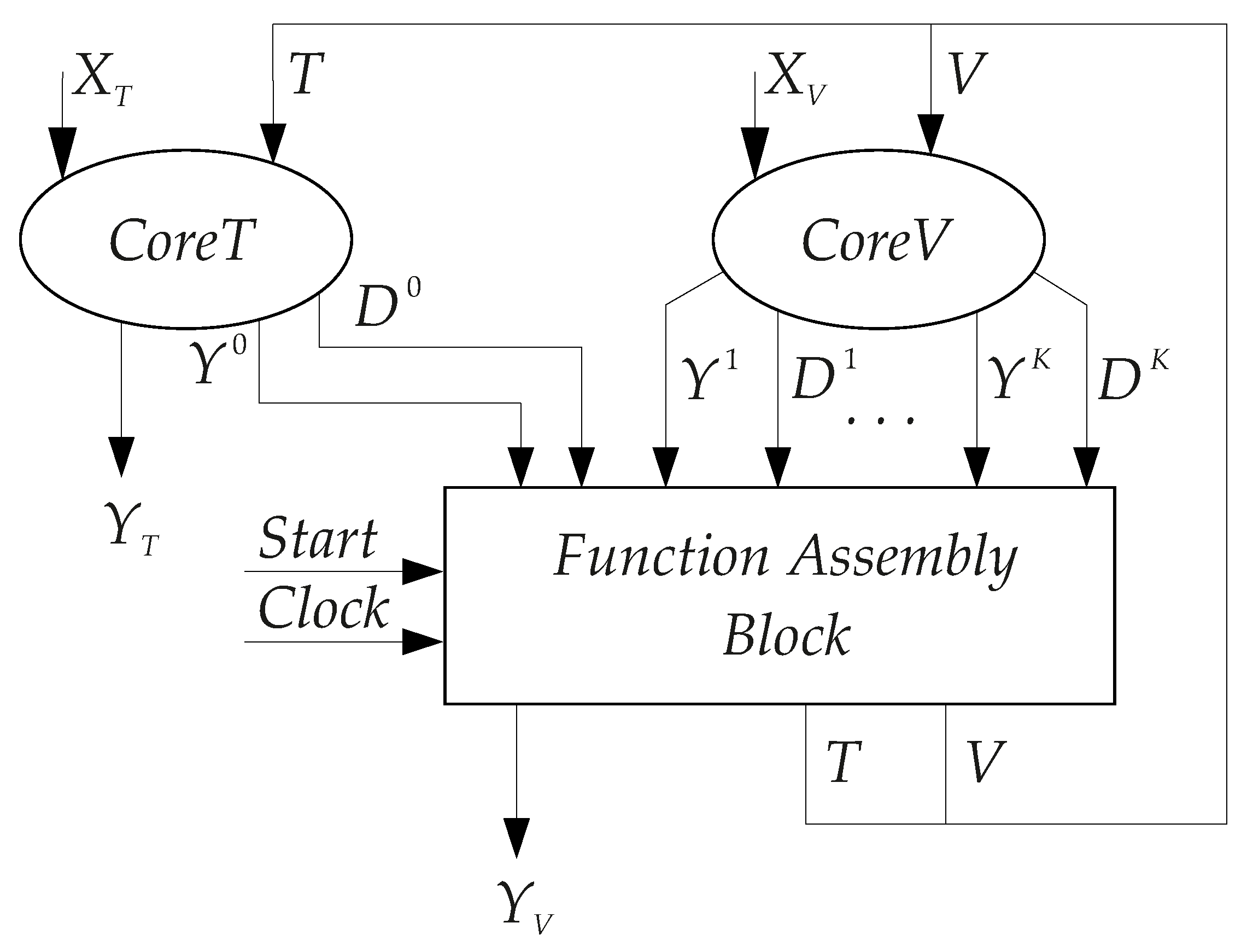
. The proposed connection of blocks leads to a double-core FSM
. Its generalized structural diagram is shown in
Figure 4.
In Mealy FSM
, the block
implements SBFs (
15) and (
17). The block
generates functions from SBFs (
18) and (
19). The block FAB includes two blocks,
and
. The block
transforms functions (
15) and (
16), (
18) and (
19) into resulting values of functions (
20) and (
21). The block
implements SBF (
12).
There are K classes in the partition
. The following condition holds:
Then, replacing the subscript
i by subscript
k turns the Formula (
5) into a formula determining the number of state variables in the codes
for states
. Having these values allows obtaining the total number of variables
:
Obviously, the following condition takes place:
Due to the validity of condition (
22), the following is true: (1) the circuit of
for FSM
must include fewer LUTs than this circuit for the equivalent FSM
and (2) the circuit of FSM
must include no more levels of logic than it is for the circuit for the equivalent FSM
. Both
and
FSMs incorporate the block
executing the transformation of state codes. Obviously, the fewer LUTs has included in the circuit of this block, the less power it consumes. As follows from the validity of condition (
24), the circuit of
for FSM
must include fewer LUTs than this circuit for the equivalent FSM
. Therefore, the block
of
FSM has less static power consumption than this block of equivalent FSM
. Since some PBFs are generated by the block
, then in some cycles of FSM operation the elements LUTs of the block
do not change their states. So, in these cycles, the block
has the dynamic power consumption close to zero. This analysis suggests that the block
of
FSM has less power consumption than that block of an equivalent FSM
.
So, we assume that the circuits of Mealy FSMs will have fewer LUTs and almost the same or even faster performance compared to circuits of equivalent FSMs . We can also argue that FSMs require less energy for the code transformation than equivalent FSMs . However, only the experimental studies can show the real energy budgets of equivalent and FSMs.
Using the above information, we propose a method for synthesis of LUT-based
Mealy FSMs. As the initial form of FSM representation we use state transition graphs (STGs) [
9]. Next, we transform this STG in an equivalent state transition table (STT) [
9]. To implement an FSM circuit, we use LUTs having
inputs. The proposed method includes the following steps:
Transforming the initial STG into STT of P Mealy FSM.
Preliminary constructing sets and .
Preliminary constructing the partition of the set .
Redistribution of states between sets , and .
Encoding of FSM states by maximum binary codes .
Creating table of the block
and SBFs (
15)–(
17).
Encoding states by partial state codes .
Creating tables of blocks from
and SBFs (
18) and (
19).
Creating table of
and SBFs (
20) and (
21).
Creating table of
and SBF (
12).
Implementing Mealy FSM circuit using internal resources of a chip.
We use a symbol to show that the model of FSM is used to implement the logic circuit of some FSM S. In the next section, we discuss an example of synthesis of Mealy FSM, where we explain how each step is executed.
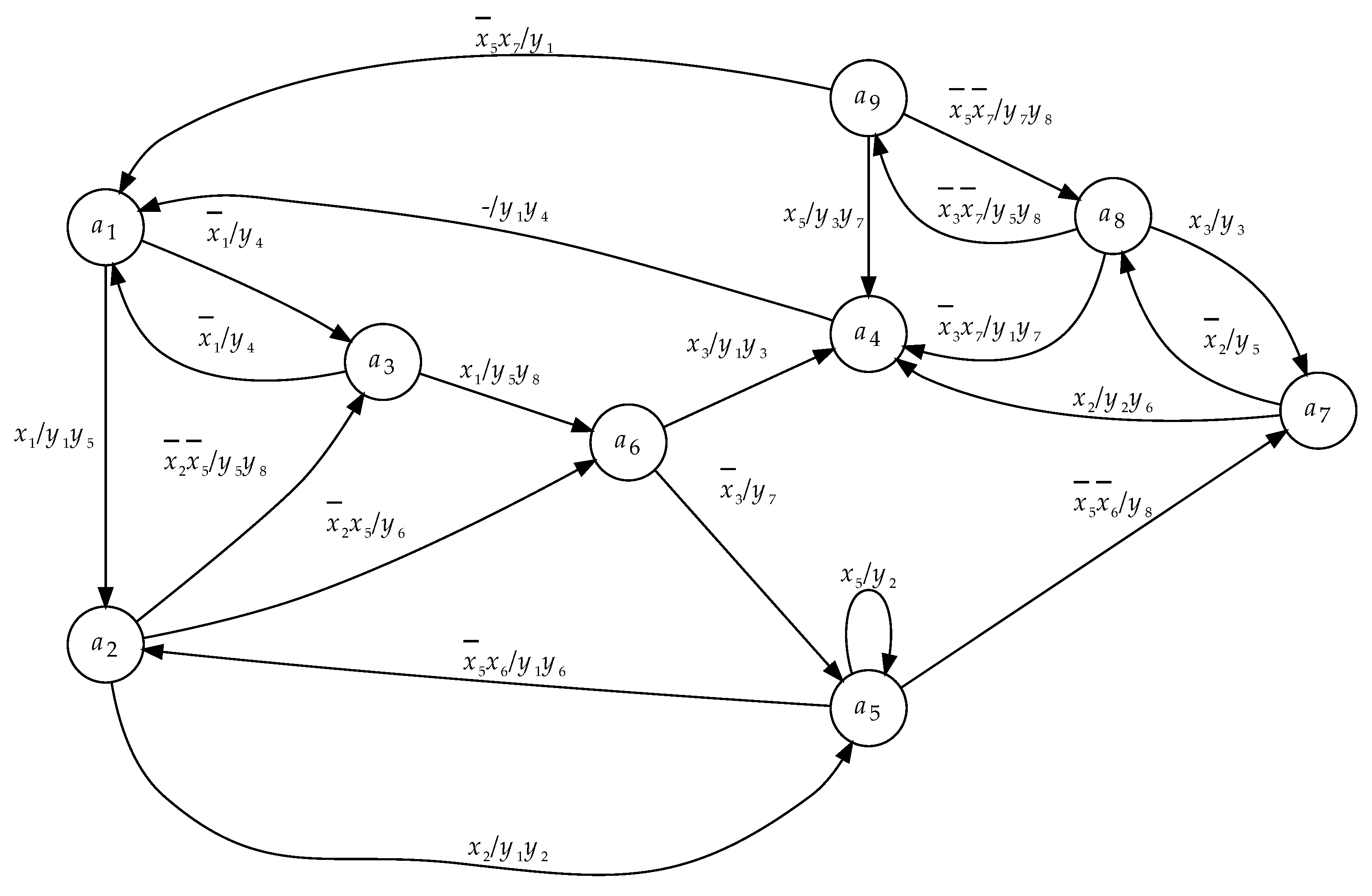
5. Example of Synthesis
We discuss a case of
FSM synthesis using LUTs with
. The FSM
is represented by an STG shown in
Figure 5.
Each node of an STG corresponds to the FSM state. Each arc of an STG corresponds to an interstate transition [
9]. There are
H arcs in an STG. The
h-th arc is marked by a pair <input signal
, collection of outputs
>. An input signal
is a conjunction of FSM inputs
determining the
h-th interstate transition. A collection of outputs
includes FSM outputs
generating during the
h-th interstate transition.
So, the FSM
is characterised by the following sets:
,
and
. This gives the following values:
,
, and
. As follows from
Figure 5, there is
.
Step 1. This step is executed in the trivial way [
6]. Each arc of the STG corresponds to a single line of a corresponding STT. So, this table has the columns
,
,
,
,
h. The state
corresponds to a vertex from which the
h-th arc comes out (this is a current state); the state
corresponds to a vertex into which this arc enters (this is a state of transition). The column
includes the input signal written above the
h-th arc. The column
includes the collection of outputs written above the
h-th arc. Using this approach transforms the STG (
Figure 5) into the equivalent STT (
Table 1).
Step 2. To divide the set
A by sets
and
, it is necessary to find values of
for states
. The following values can be found from
Table 1:
;
for states
,
,
,
;
for states
,
,
,
. There is
. As follows from (
14), there are the sets
and
. As we show in the next section, some elements of the set
can be transferred to the set
. Thus, these sets do not yet have a final form. Now, we can find sets
and
. The set
includes inputs determining transitions from states
, the set
includes inputs determining transitions from states
. In the discussed case, there are the following sets:
and
.
Step 3. Using approach [
12] gives the partition
of the set
. The classes of this partition are the following:
and
. This gives the following values of
:
. Using (
5) gives
and
. Since the set
can be changed, the partition
is also preliminary.
Step 4. We discuss this step in
Section 6. Now, we only show the outcome of this step. It is the following:
and
. Now, the classes of
are the following:
and
. This gives the following values of
. Using (
5) gives
and
. So, there is no change in the total number of state variables
before and after refining the sets
and
. So, there is the set
. However, now there are fewer states in the set
. This means that the number of LUTs in the circuit of
should be reduced compared to this number corresponding to the set
obtained during the Step 2.
Step 5. There is
. Using (
1) gives
. So, there are the following sets:
and
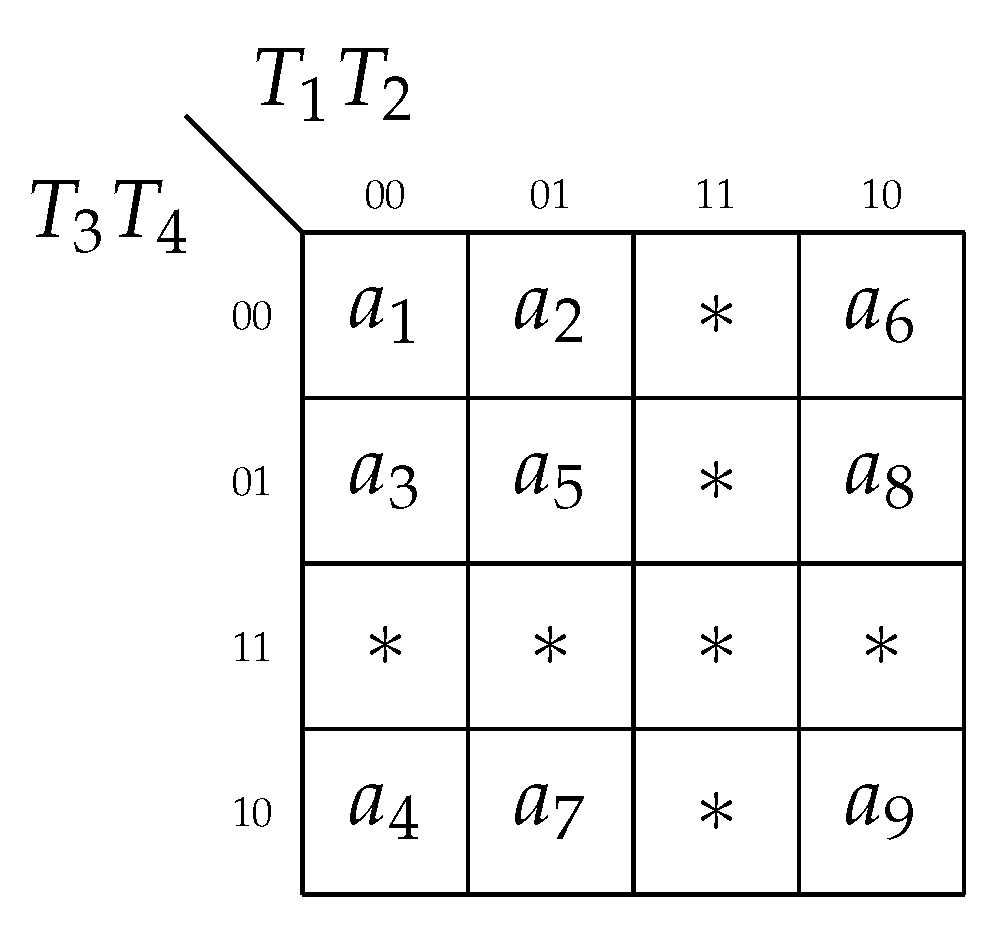
. To minimize the sum-of-products (SOPs) of functions (
12), it is necessary to place the states from the same class into minimum possible amount of generalized cubes of
-dimensional Boolean space [
9]. Let us encode the states in a way shown in
Figure 6.
As follows from
Figure 6, the states
are placed into the cube 00xx. This allows optimizing SOPs of functions (
15)–(
17). The states
are placed in the cube x100, the states
are placed in the cube 1x00. This gives the opportunity to optimize SOPs of functions (
12).
Step 6. The table of
is constructed using the lines 1–2 and 6–8 of
Table 1. Three more columns are added in this table:
,
and
. The first and second additional columns include the codes of current and next states, respectively. The column
includes IMFs equal to 1 to load the code
into the RG. We changed the names for columns
and
compared to
Table 1. Now we use the notation
and
. The
is represented by
Table 2.
Using
Table 2 gives the following SBFs:
This system is used to create the circuit of
. Let us point out that the function
is generated only by some LUT of
. This gives
. Furthermore, the following sets can be derived from
Table 2:
,
and
.
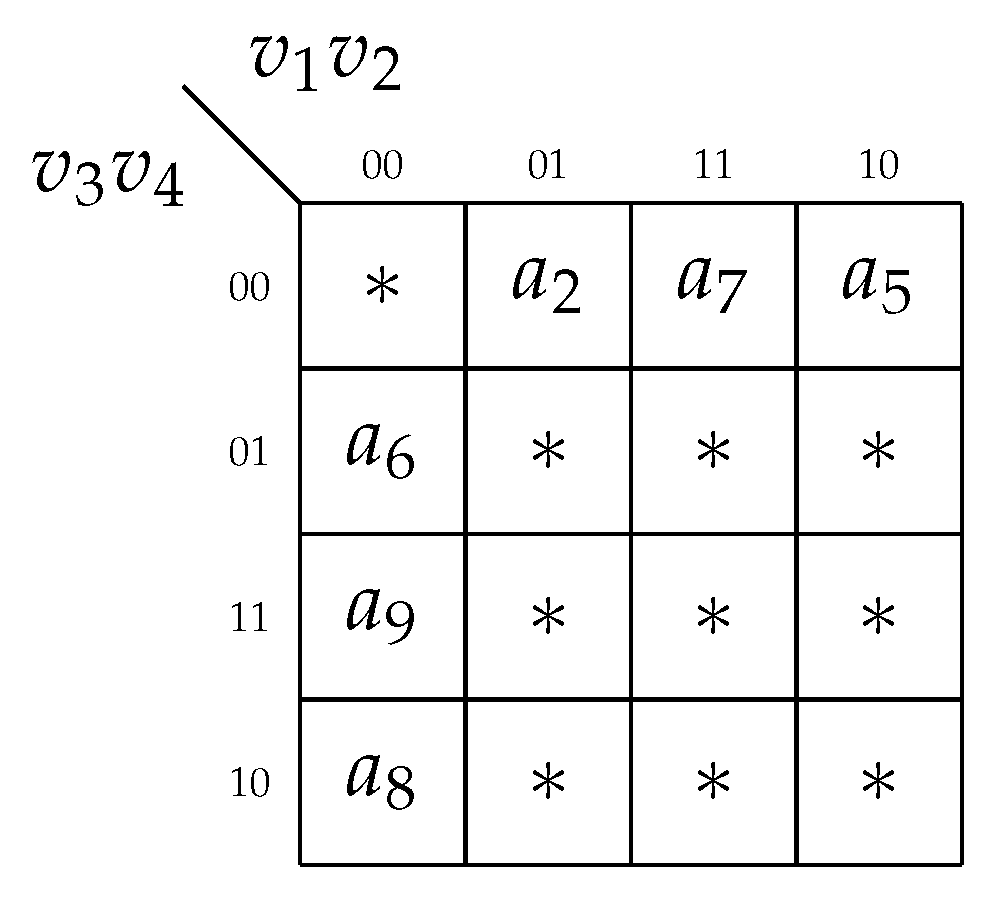
Step 7. To encode the states
, the variables
are used. To encode the states
, the variables
,
are used. We use the code 00xx to show that a particular state does not belong to the class
. The code xx00 shows that a particular state does not belong to the class
. The outcome of state assignment is shown in
Figure 7.
The following partial codes can be found from the Karnaugh map (
Figure 7):
,
, and
. These codes are used in LUTs of
.
Step 8. There are two blocks of LUTs in the
. The block
implements SBFs for the class
; the block
implements SBFs for the class
. The table of
is constructed using the lines 3–5, 9–11 and 14–15 of
Table 1. This is
Table 3. The table of
is constructed using the lines 12–13 and 16–21 of
Table 1. This is
Table 4.
Both tables use partial state codes
for current states and the MBCs
for states of transition. The following sets can be found from
Table 3:
,
and
. The following sets can be found from
Table 4:
,
and
.
The SBFs (
18) and (
19) are constructed in the same way as this is for SBFs (
15)–(
17). For example, the following SOPs can be obtained for functions
(
Table 3) and
(
Table 4):
Step 9. There are the following columns in table of
:
(a function generated by
),
,
. If a function
is generated by a LUT of
, then there is 1 in the intersection of the line with this function and the column of the corresponding core. Otherwise, this intersection is marked by 0. There are
K sub-columns in the column
. If a function
is generated by
of
, then there is 1 in the intersection of the line with this function and the sub-column k. In the discussed case, the block
is represented by
Table 5.
Using
Table 5, we can construct the following SBFs:
Each function
is represented by a disjunction of its partial components. The principle of constructing each function of (
27) is clear from the comparison of these functions with contents of
Table 5.
Step 10. To create the table of
, we should use the full codes
and partial state codes
. So, there are the following columns in this table:
,
,
,
. Inside this table, we use only states
. In the discussed case, there are six lines in the table of
(
Table 6).
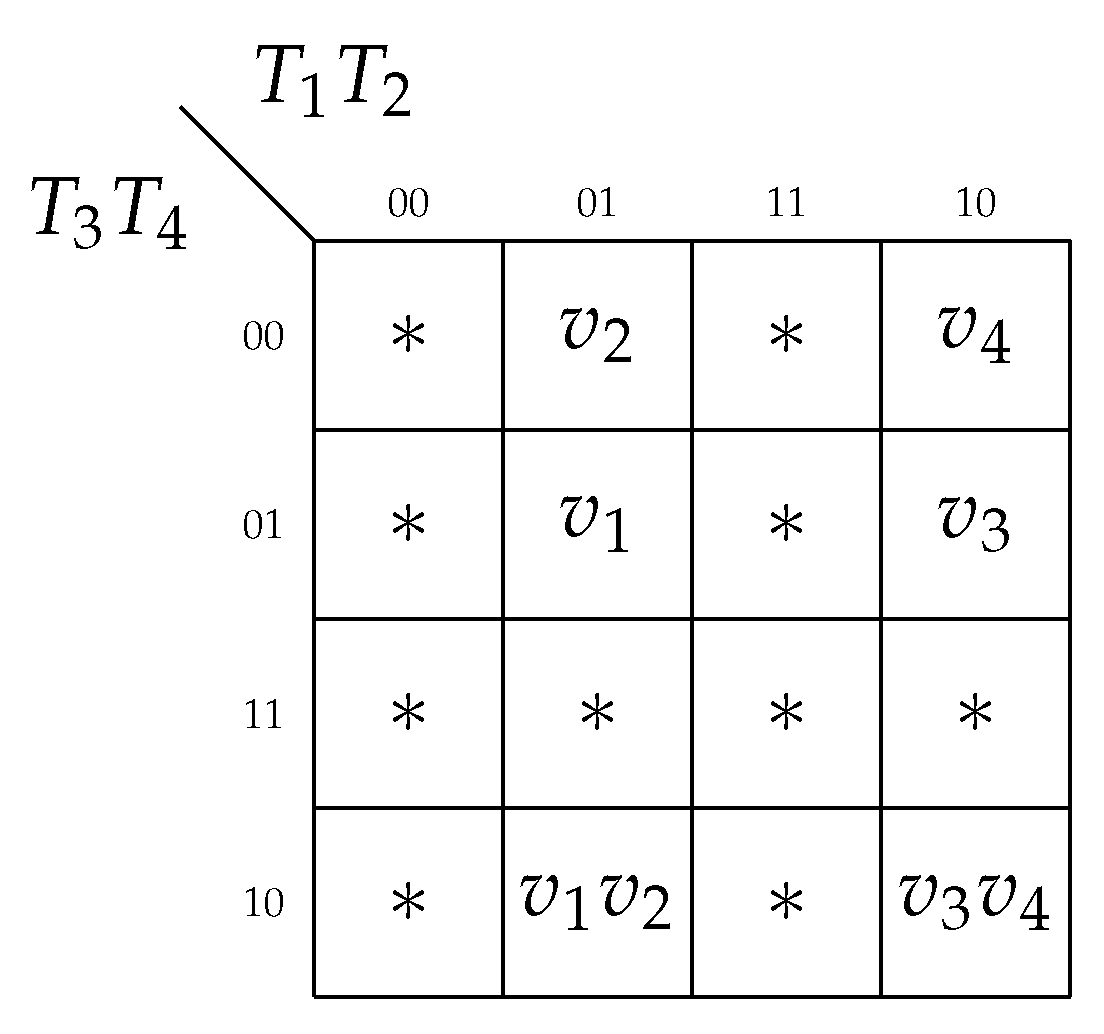
To fill the column
, we use the state codes from
Figure 6. The column
is filled using the partial state codes from
Figure 7.
To optimize the SBF (
12), we represent its functions by the Karnaugh map (
Figure 8). In this map, we treat the codes of states
as the “don’t care” input assignment.
Using the Karnaugh map (
Figure 8) gives the following SBF:
In the worst case, each function
is represented by a SOP having
literals. So, the maximum number of literals is calculated as the product of
by
. In the discussed case, this number is equal to 16. If we analyze the SBF (
28), we find that it includes 10 literals. So, using our approach allows reducing the number of literals by a factor of 1.6. Each literal corresponds to an interconnection between outputs of RG and inputs of LUTs creating the circuit of
. It is known that minimizing the number of interconnections allows reducing the value of power consumption [
26,
38].
Step 11. To implement the circuit of
Mealy FSM, it is necessary to use, for example, the CAD tool Vivado by Xilinx [
39]. This package solves all problems connected with the step of technology mapping [
40,
41]. In
Section 7, we use Vivado to compare the proposed method with some known FSM design methods.
6. Algorithm of State Redistribution
If a class
includes
states, then it is necessary
state variables to encode the states
by the partial state codes
. The value of
is determined by (
5). We denote as
the maximum possible number of states in a class
. This value is determined as
Our research shows that it is quite possible that some class
includes fewer states compared to the value of
. For example, we have the following classes for FSM
:
and
. Using (
5) gives
. Using (
29) gives
. So, both classes might be supplemented by states from the set
. One state can be added to each of the classes
.
So, it is quite possible that we need to redistribute states between sets and . Obviously, these new elements of should be added into some classes . It is obvious that it is expedient to transfer states in such a way as to reduce the number of states in the set as much as possible.
We propose to use an estimate , which we called the influence of the state on the sets and . In the discussed case, these sets are the following: and .
The best candidate for transfer to the set
is the state
that minimizes the number of inputs in the set
and minimally increases this number in the set
. The influence of a state
on the set
is determined as
The influence of a state
on the set
is determined as
So, the overall influence of the state
is defined as
Obviously, it is necessary to transfer the states with the greatest influence. This is the basis of our proposed redistribution algorithm (
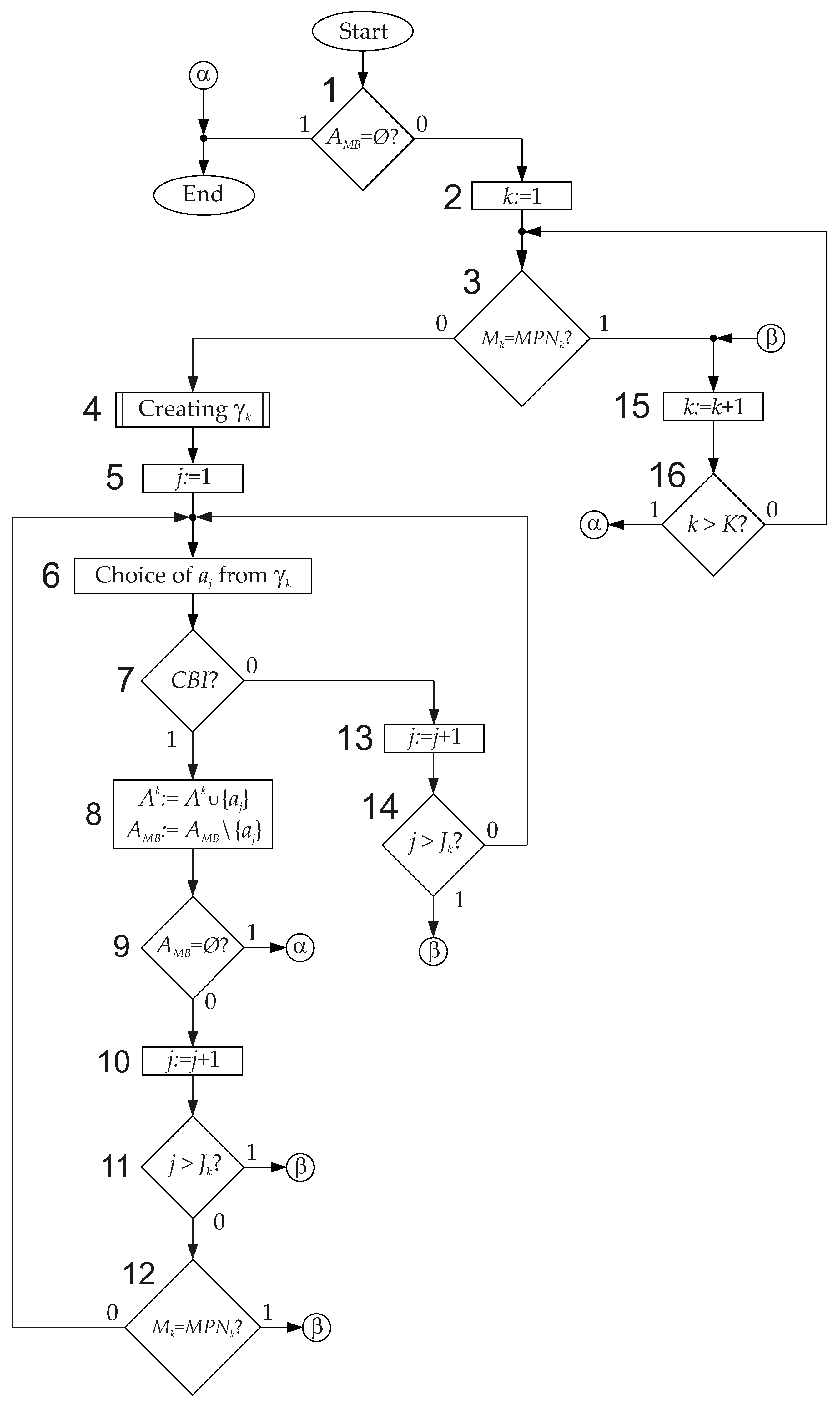
Figure 9).
During the redistribution, a queue
is formed from the states
. This queue is based on the following rule: the states are placed as the value of
decreases. If the influence is the same for states
, then, in the queue, the state with lower subscript precedes a state with higher subscript. A state can be included into a class
, if its including does not violate the condition (
4). In our algorithm, we use the abbreviation CBI (can be included). For each class
, the queue
includes
elements. This preliminary information is quite enough to proceed to the description of the proposed algorithm.
We start the redistribution from the testing the set (Block 1). If this set is empty (output 1), then the redistribution cannot be executed. If there are some states in the set (output 0), then the redistribution process begins. The analysis starts with class (Block 2). If the analyzed class includes the maximum number of states (output 1 from Block 3), then it is necessary to proceed to the analysis of the next class (go to Block 15). The algorithm is terminated when all classes are analyzed (output 1 of Block 16). Otherwise, the next class is analyzed (go to from Block 16 to Block 3).
If an additional state can be included in the class (output 0 from Block 3), then there is created a queue having elements (Block 4). Next, the sequential analysis of the states from the queue is performed. The analysis starts from the first element of the queue (Block 5).
The j-th element is taken from the queue (Block 6). If it cannot be included into the class (output 0 from Block 7), then the next element of the queue should be analyzed (go to Block 13). If all elements are analyzed (output 1 of Block 14), then it is necessary to analyze the class (go to Block 15). Otherwise (output 0 of Block 14), the next element of the queue is analyzed (go to Block 6).
If the j-th element can be included into the class (output 1 from Block 7), then the following actions are executed (Block 8): (1) the state is included into the set ; (2) the state is excluded from the set . If now (after excluding state ) the set becomes empty (output 1 of Block 9), the redistribution process is terminated (go to End). Otherwise (output 0 of Block 9), the next element of queue should be analyzed (go to Block 10). If all elements are already analyzed (output 1 of Block 11), then it is necessary to analyze the class (go to Block 15). Otherwise (output 0 of Block 11), the next element of queue should be analyzed. This can be done if the class does not contain the maximum possible number of elements. This is checked in the Block 12. If the class is full (output 1 of Block 12), then it is necessary to analyze the class (go to Block 15). Otherwise (output 0 of Block 12), the next element of the queue is analyzed (go to Block 6).
There are two conditions to terminate this redistribution process. First, if there are no elements in the set (outputs 1 from Blocks 1 and 9). Second, all classes have been tested and, if it was possible, supplemented by states (output 1 from Block 16).
So, the
k-th step of the redistribution process starts from creating current sets
and
. Next, it is necessary to find the values of
for states
and create the current queue
. So, there are
K columns corresponding to classes
in the table of redistribution. Each column is divided by the following sub-columns:
,
,
,
,
. In this table, the line
includes states
transferred in the particular class
. The lines for these states are marked by ⊕. If a state cannot be included into the class
, the corresponding line includes the sign “−”. The last line of the table contains the classes
.
Table 7 shows the redistribution process for FSM
.
Let us go back to the previous section. After executing the step 2, we have the following sets: , , and . After executing the step 3, we have the partition with the following classes: and . These classes are characterized by the sets and .
So, for
, the column
contains the states
. For the state
, we can find the set
. Let us find the value of
. Using (
30) gives the following:
. Using (
31) gives
. Using (
32) gives
. This value is written in the intersection of the line
and sub-column
for
. In the same way, the values of
for all other states
are calculated.
Using the values of , we can get the queue . In the intersection of the line and the sub-column , there is written the place of this state in this queue. So, we should check the possibility of redistribution starting from the state . If we place the state into the class , then there is no change for values of and . So, the state is included into and excluded from . Now, there is . So, during the step no state can be added into the class .
Now, there are the following modified sets: , and . Using the modified sets and , we can start the next step of redistribution ().
The values of are shown in the corresponding sub-column of the column . Using them gives the queue . If we place the state into the class , then there is no change for values of and . So, the state is included into and excluded from . Now, there is . So, during the step no state can be added into the class . So, the class is ready.
Now, there are the following modified sets: , , and . Obviously, these sets are the same as we use as the outcome of Step 4 in our example.
7. Experimental Results
In this section, the results of experiments conducted with the benchmarks [
42] are shown. The library [
42] consists of 48 benchmarks. The benchmark FSMs are represented by their STTs. To represent the STTs, the format KISS2 is used. These benchmarks have a wide range of basic characteristics (numbers of states, inputs, and outputs). Different researchers use these benchmarks to compare various characteristics of FSM circuits [
28,
29,
32]. The characteristics of benchmarks are shown in
Table 8.
Our current research is connected with Mealy FSMs which are the parts of digital systems. It is known that Mealy FSMs are not stable [
6],: fluctuations at the inputs lead to fluctuations at the outputs. This can lead to errors in the operation of the digital system as a whole. To avoid these errors, the FSM inputs should be stabilized. The stabilization presumes using an additional input register (AIR) [
30]. When input values stabilize, they are loaded into the AIR. Now, fluctuations at the inputs (which are the outputs of some system’s blocks) do not lead to fluctuations at the FSM outputs. However, the AIR consumes some resources of a chip: (1) it requires L additional LUTs and flip-flops and (2) it is synchronized (due to it, AIR uses some resources of the synchronization tree). So, this register consumes additional LUTs, flip-flops, power and time (it adds some delay to the whole synchronization cycle time). Such an approach allows taking into account this overhead connected with the stabilization of FSM operation.
The experiments are conducted using a personal computer with the following characteristics: CPU: Intel Core i5-11300H, Memory: 16GB RAM LPDDR4X. To get the FSM circuits, we use the Virtex-7 VC709 Evaluation Platform (xc7vx690tffg1761-2) [
43] by AMD Xilinx. There is
for LUTs used in this platform includes. The CAD tool Vivado v2019.1 (64-bit) [
39] executes the technology mapping. The results of experiments are taken from reports produced by Vivado. To connect the library with Vivado, we use VHDL-based FSM models. These models are obtained by a transformation of the files in KISS2 format into VHDL codes. The transformation is executed by the CAD tool K2F [
30].
We have found three main characteristics of
Mealy FSMs. They are: the occupied chip area (the LUT count), performance (both the values of cycle time and maximum operating frequency), and power consumption. We compared the obtained values with the corresponding values for four different FSMs. Three of them are
P Mealy FSMs based on: (1) Auto of Vivado (it uses MBCs); (2) One-hot of Vivado; (3) JEDI (it uses MBCs, too). Moreover, for the comparison, we use
-based FSMs [
12] whose circuits we try to improve.
As shown in [
30], all main characteristics of LUT-based FSM circuits depend on the relation between the values of
, on the one hand, and the value of
, on the other hand:
Analysis of
Table 8 allows dividing the benchmarks into five sets. The benchmarks belong to class of trivial FSMs (set 0), if
(it gives
). I The benchmarks belong to set of simple FSMs (set 1), if
(it gives
). The benchmarks belong to set of average FSMs (set 2), if
(it gives
). The benchmarks belong to set of big FSMs (set 3), if
(it gives
). The benchmarks belong to set of very big FSMs (set 4), if
(it gives the relation
). As research [
37] shows, the larger the set number, the bigger the gain from using methods of twofold state assignment.
The results of experiments are shown in
Table 9,
Table 10 and
Table 11. These tables are organized in the same manner. The table columns are marked by the names of investigated methods. The last column includes the number of the benchmark set to whom the particular benchmark belongs. The table rows are marked the names of benchmarks. There are results of summation of values from columns in the row “Total”. The row “Percentage” includes the percentage of summarized characteristics of FSM circuits produced by other methods respectively to
-based FSMs. We start the analysis of experiments from
Table 9. This table contains the values of LUT counts for each benchmark used in the experiments.
As follows from
Table 9, the circuits of
-based FSMs use a minimum number of LUTs compared to other investigated methods. There is the following gain: (1) 36.92% compared to Auto-based FSMs; (2) 56.23% compared to One-hot–based FSMs; (3) 16.11% compared to JEDI-based FSMs; (4) 5.74% compared to
-based FSMs. In our opinion, this gain is associated with a decrease in the number of variables used in partial state codes (compared to equivalent
-based FSMs). The second source of a decrease in the LUT counts can be a decrease in the number of partition classes. If the relation
takes place, then there is a decrease in the required number of LUT inputs for elements of
. If the condition (
13) is violated but the condition
holds, then the circuit of
is multi-level for a
-based FSM as opposed to the single-level block circuit of an equivalent
-based FSM.
Careful analysis of the table reveals the following feature of the proposed method: there are the same values of LUT counts for equivalent
- and
-based FSMs for the Set 0. This can be explained as follows. For this set, the condition (
14) holds. This means that each function
does not require being decomposed. Only a single LUT is enough to implement a logic circuit for any function
. In this case, there is the same single class into both partitions,
and
. Due to it, the block FAB is absent. This means that both
and
FSMs turn into
P FSMs. So, there are the same circuits for
and
FSMs. Obviously, these circuits have the same values of LUT counts. The same should take place also for other characteristics of these two models.
Furthermore, from
Table 9 we see that the values of LUT counts are the same for some equivalent
and
FSMs that do not belong to the set 0. This phenomenon occurs for the following benchmarks:
dk16,
ex1,
planet,
planet1,
s1488,
s1494,
s1a,
s420,
s510,
s810,
s832,
sand and
styr. Analysis of
Table 8 reveals the nature of this phenomenon: there are more than
bits in state codes for these FSMs. This means that the following condition holds:
In this case, the condition (
14) is violated. This leads to the empty set
. In turn, this makes correct the following relations:
and
. So, if the condition (
34) holds, then
FSMs turn into
FSMs. Obviously, there are the same LUT counts for such equivalent
and
FSMs.
As follows from
Table 10, the circuits of
-based FSMs are the fastest compared to the circuits produced by other investigated methods. There is the following gain: (1) 14.60% compared to Auto-based FSMs; (2) 14.89% compared to One-hot–based FSMs; (3) 8.88% compared to JEDI-based FSMs; (4) 5.46% compared to
-based FSMs. We think that this gain is due to the fact that in some cases the circuits of
-based FSMs have fewer levels of LUTs than the circuits of
-based FSMs. We discussed the reasons for this phenomenon in the analysis of
Table 9. It is interesting to note that the average gain in the cycle time almost coincides with the average gain in the LUT counts (for
- and
-based FSMs).
As follows from
Table 10, for the Set 0, there are the same values of cycle times for equivalent benchmarks using models of single-core and dual-core FSMs. The explanation is the same as it is for the equality of LUT counts. Moreover, from
Table 10 we can find out that the temporal characteristics are the same for the following benchmarks:
dk16,
ex1,
planet,
planet1,
s1488,
s1494,
s1a,
s420,
s510,
s810,
s832,
sand and
styr. The reasons for this phenomenon have also been analyzed in the previous paragraphs.
Using values of cycle times, we can trivially compute the values of maximum operating frequencies. These values are shown in
Table 11.
As follows from
Table 11, the circuits of
-based FSMs have the highest values of maximum operating frequencies compared to the circuits based on other investigated methods. There is the following gain: (1) 12.26% compared to Auto-based FSMs; (2) 12.40% compared to One-hot–based FSMs; (3) 7.09% compared to JEDI-based FSMs; (4) 5.42% compared to equivalent
-based FSMs. Obviously, the gain in frequency is related to the gain in cycle time. We discussed all the reasons for this phenomenon above.
The value of power consumption is one of the most important characteristics of FSM circuits [
44]. Very often, the gain in area-temporal characteristics is accompanied with an increase in the power consumption [
27]. Using Vivado reports allows constructing
Table 12 with values of consumed power.
The main goal of the proposed method is to obtain FSM circuits with fewer LUTs than it is in circuits of equivalent
-based FSMs. Of course, this improvement can lead to an increase in power consumption. As follows from
Table 12, this increase is extremely small. Compared to
-based FSMs, the circuits of equivalent
-based FSMs consume less than one percent more power (0.76%). If compare
-based FSMs with other investigated methods, then there is the following gain: (1) 16.38% compared to Auto-based FSMs; (2) 24.02% compared to One-hot–based FSMs; (3) 1.90% compared to JEDI-based FSMs.
We associate this loss with the following. In
-based FSMs, the state variables
are connected only with the block
. However, in
-based FSMs, these variables are connected with LUTs of both
and
. This increase in the number of connections leads to an increase in the value of parasitic capacitance in an FSM circuit [
26]. Due to it,
-based FSMs consume more power than equivalent
-based FSMs. Obviously, this phenomenon does not occur for FSMs from the Set 0. Moreover, for the benchmarks
dk16,
ex1,
planet,
planet1,
s1488,
s1494,
s1a,
s420,
s510,
s810,
s832,
sand and
styr both
- and
-based FSMs consume equal values of power.
So, the proposed method allows obtaining circuits with either better or the same values of area-temporal characteristics than they are for equivalent -based FSMs. Our main purpose is to get the FSM circuits with fewer LUTs than it is for equivalent -based FSMs. As follows from the conducted experiments, this goal has been achieved. Furthermore, the proposed method has an additional positive effect: it allows getting faster FSM circuits than the circuits of equivalent -based FSMs. Our method loses slightly in terms of the amount of power consumed. However, this loss does not exceed 1% on average. We think that our approach can be used instead of FSMs if area-temporal characteristics determine the optimality of the resulting FSM circuits.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}