Abstract
Coronavirus (COVID-19) has caused a global disaster with adverse effects on global health and the economy. Early detection of COVID-19 symptoms will help to reduce the severity of the disease. As a result, establishing a method for the initial recognition of COVID-19 is much needed. Artificial Intelligence (AI) plays a vital role in detection of COVID-19 cases. In the process of COVID-19 detection, AI requires access to patient personal records which are sensitive. The data shared can pose a threat to the privacy of patients. This necessitates a technique that can accurately detect the COVID-19 patients in a privacy preserving manner. Federated Learning (FL) is a promising solution, which can detect the COVID-19 disease at early stages without compromising the sensitive information of the patients. In this paper, we propose a novel hybrid algorithm named genetic clustered FL (Genetic CFL), that groups edge devices based on the hypertuned parameters and modifies the parameters cluster wise genetically. The experimental results proved that the proposed Genetic CFL approach performed better than conventional AI approaches.
1. Introduction
The COVID-19 outbreak disturbed public health and human life [1]. The spread of COVID-19 [2] is still ongoing, and researchers are trying to find effective ways in early detection of the disease. The aim is to identify and isolate affected people, which results in limiting the spread of COVID-19. AI plays a vital role in detection of COVID-19, allowing researchers to identify it by analyzing symptoms such as throat infection, cold sweats, difficulty in breathing, and also with the assistance of a X-ray [3]. AI, with help of historical data related to COVID-19, can help in predicting and providing essential guidelines to control the spread of the COVID-19 pandemic. The historical data used by AI requires patient records, which are confidential. The patients will hesitate to share their sensitive information as their privacy can be compromised. This creates a scarcity of data required for predictions. A robust model cannot be developed due to this challenge [1]. A novel strategy is required, that allows the development of models that can provide accurate predictions without compromising the patients’ personal information.
FL was introduced as an innovative ML approach by Google in 2016 [4]. The goal of FL is to create a ML method consisting of multiple datasets without gathering actual data while preserving confidentiality, privacy, transparency, and security [5,6]. In every iteration of the FL process, local system builds a classifier that uses native information and delivers parameters to a global system without transmitting actual data.
FL provides collaborative environment among different healthcare organizations in preparing a COVID-19 prediction framework while maintaining data privacy [7,8]. Researchers used FL to assess COVID-19 disease from computed tomography or X-ray pictures [1,9]. Current FL studies focus on issues related to communication costs and performance issues. In FL, communication costs increase with frequent updates in patient data to the server. FL addresses the privacy and security issues in healthcare sector by allowing data servers to classify their designs locally and distribute each other’s models without compromising patient’s data privacy [10].
Every iteration of an FL approach consists of client-server communication, native mentoring, and prototype clustering [11,12,13,14]. The transmission of model from the server to all the clients and vice versa can cause communication overhead. Each connectivity session involves implementation issues due to poor data usage, network congestion, and ethical concerns. Modified communication algorithms such as privacy-preserving and communication efficient scheme for federated learning (PCFL) [15,16], minimize the model dimensions and improve security with compression and encryption. The number of edge devices also influence the communication load. The implementation of communication sparsification [17] over clients is modeled to increase the convergence rate and reduce network traffic on the server. The hierarchical clustering [18] approach is also used in many models to summarize related customer strategies and minimize clustering difficulty.
In a heterogeneous environment, not only communication but also AI model training is more challenging [19]. Clients train on the server model using hyper-parameters including client ratio (e.g., choosing 100 clients), epochs per round, batch size, learning rate. Edge devices differ in computational power and data properties, making it difficult to integrate broadly developed client models. The optimization methods such as FedMA and FedAvg [20] are more focused on integrating weights of model parameters. Training and aggregation are both affected by integration rate and training intensity. There are many new techniques for model clustering, such as combining new and existing features [21] or identifying the standard client models [22] to improve the classification. Several studies use various global models such as Federated Cloning-and-Deletion (FedCD) to improve convergent analysis [23].
Researchers have mainly focused on model aggregation to make FL concepts adaptable to non-IID user information [24]. The local training model has a significant impact on determining the model’s accuracy. In this study, a novel solution based on genetic algorithm is proposed for hyper-parameter tuning for improved model aggregation in a cluster, as illustrated in Figure 1. The proposed genetic CFL model involve the following steps:
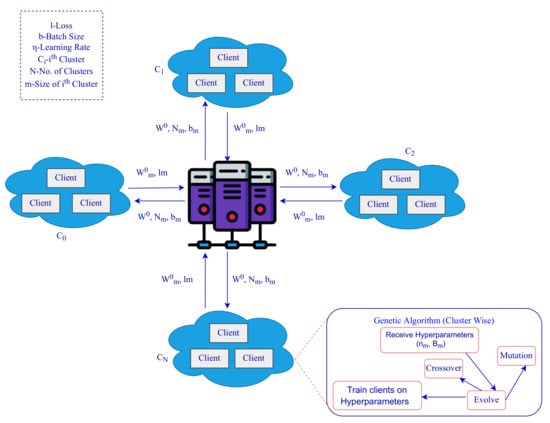
Figure 1.
Genetic CFL Architecture.
- The clients are grouped based on the hyper-parameters thereby increasing the learning efficiency per training unit.
- Genetic algorithm is used to tune the hyper-parameters and better model aggregation in a cluster.
The genetically optimization FL approach is a novel method for enhancing COVID-19 detection and improve the AI model efficiency and performance. In this study, we create a genetically optimization FL system architecture to detect COVID-19. When compared to basic FL’s technique, the proposed technique is more accurate and ensures provacy preservation.
2. Literature Survey
This section presents a survey on the current literature on FL, clustering, and evolutionary algorithms, respectively, in order to understand their limitations.
2.1. Federated Learning
Recent studies have focused on FL as a distributed and edge AI architecture [25,26]. In a heterogeneous environment containing non-IID data, FL’s decentralized nature directly contradicts traditional AI algorithms which are centralized. Many novel approaches have tried to address the aggregation of non-IID data with various aggregation algorithms, including FedMA [20], feature fusion [21], and grouping of similar client models [22] for better personalized and accurate results. The clustering process makes use of client-model similarity [27] and provides efficient communication to improve data generalization [28].
Clustering will help in optimizing the communication in FL. The convergence of the model may be significantly reduced if there are thousands of nodes in a realistic scenario. Algorithms for partitioning clusters, such as k-means clustering [29], require a predetermined number of clusters which is not feasible. Clusters based on generative adversarial networks and agglomerative hierarchical clustering [18] are examples of non-definitive clusters.
2.2. Evolutionary Algorithms
A model’s hyper-parameters selection determine its ability to learn from datasets. Many researchers are working on the optimization of AI models and parameters using evolutionary algorithms [30], such as genetic algorithms [31] and whale optimization [32].
The ensemble models developed using evolutionary algorithms with deep learning techniques have become increasingly popular for optimization tasks [33].
The use of evolutionary algorithms with FL is not yet fully realised. Due to the ambiguity of data, hyper-parameter tuning is even more critical. Optimization algorithms assist with tuning these parameters beyond manual capabilities. Genetic algorithm is used to optimize learning rates and batch sizes for each of the individual end device models. Agrawal et al., in [34] showed that FL is restricted by efficiency of client training, thus involves selecting hyper-parameters effectively, model adjustment, and procedure streamlining. FedTune automatically tunes FL hyper-parameters during model training based on application training preferences [35]. To achieve diverse training preferences, it can be challenging to tune multiple hyper-parameters, particularly when several aspects of the system have to be optimized. FedEx estimates gradients based on client-side hyper-parameter distributions in federated settings [36]. This approach uses weight-sharing methods for searching neural architectures. The training process for FL must not only be aimed at high accuracy but also at reducing the training time and resource consumption in practical environments, using low-capacity computing devices [37,38]. FL uses best epoch algorithm to determine how many epochs are necessary per training round. A summary of the key findings from the above discussion can be found in Table 1.

Table 1.
Summary of important surveys on FL and rvolutionary algorithms.
3. Proposed Methodology
This section describes genetic CFL optimization technique using a comprehensive statistical method. There are two sections in the workflow, the first round of broadcasting is represented by Algorithm 1, which tells about the number of clusters and the federated training which uses genetic algorithm is represented by Algorithm 2. This section mainly describes the differential behavior of the algorithm with various hyper parameters that includes number of iterations, client ratio(n), minimum samples, batch size, and learning rate (). The following Table 2 highlights most of the symbols used during the algorithm.
| Algorithm 1 Clustering and initial broadcasting N = no. of clients : Learning Rate : Learning Rate List |
|
Table 2.
Symbol representations.
| Algorithm 2 FL-based genetic optimization for clustered data. rounds: The number of loops required to train the decentralized approach |
|
Dataset Description
The dataset used in this work is taken from the kaggle repository https://www.kaggle.com/datasets/mykeysid10/covid19-dataset-for-year-2020?select=covid_data_2020-2021.csv (accessed on 26 July 2022). There are 10 attributes, among which the attribute Corona result indicates whether a person has a positive or negative Corona result. Table 3 displays an overview of the information of each column that is used in our implementation.
Table 3.
Dataset description.
The objective of Algorithm 1 is to identify the attribute values of an edge device distinctly without violating its security. The server model() is broadcasted to N all the clients, C ⊆ {}. Along with the distributed server models, three different learning rates are also broadcasted. The learning rates are selected from the array (), which ranges from . The sample size is also chosen randomly and a more number of samples can also improve the training accuracy. Every edge device is offered , which is duplicated for all values and supervised independently for a full iteration. Some data features such as complexity, size, ambiguity, and variance are unique to edge devices. These data features will effect the training and thus the hyper-parameters are selected carefully. Out of the three models at the edge device only one model with least loss is selected. Every edge device will return , , and . These statistics are important because of their ability to represent data on respective edge devices.
The models , learning rates and their respective losses are obtained at the server. The server model is developed by integrating edge device models using the model aggregation technique. The model weights () are added iteratively as follows:
The output of the aggregation is divided by the number of clients, and the equation is as follows:
In phase 2, we assign every edge device, a cluster-ID, as demonstrated by Algorithm 2. This algorithm component has been restricted by the algorithm’s main control loop, which continues for i iterations. Each i-th cycle,
- genetic algorithms optimize hyper-parameters based on mutation, crossover, and evolution;
- clients receive optimized hyper-parameters for cluster-based servers;
- every client is prepared using a set of parameters;
- combining client models produces the most effective server model.
Each cluster contains a unique range of hyper-parameters personalized towards the edge devices which are a part of it. Training initiates the development of such aggregated parameters every ith iteration. During genetic optimization, hyper-parameters interact with the ideal range for each iteration. Every iteration changes the contents of , which stores the learning rates for every cluster. The shape of the data is , where C shows the set of clusters, shows the cluster and shows the wide range of edge devices in every cluster. The losses of a cluster with the shape are used to sort the hyper-parameters.
After sorting, we achieve different users across crossover and mutation. The ideal performers continue to pass on their genetic mutations to the next generation, while others have developed by mating with previous transmission users as
The updated learning rates determine whether effectively or partially through natural selection. The sum of obtained from previous generations can differ slightly. The modified parameters are derived from (5):
There are two locations in which and .
All devices are configured according to their specific cluster hyper-parameters after genetic evolution. A training process involves repeating model aggregation, genetic optimization, and training for iterations before a new epoch is achieved.
Artificial Neural Networks (ANN) were used in this work for classification of the data in each cluster. In this work, we used an ANN with three layers, input layer, a hidden layer, and the output layer. The hyper-parameters used in the ANN are as follows: activation function used in the hidden layer is relu, whereas sigmoid activation function is used in the output layer. The optimization function used is adam.
4. Results and Discussion
The objective of this section is to provide an overview of the experiments which were conducted for the evaluation and assessment of the genetic CFL architecture. Section 4.1 examines how genetic CFL architecture performs on the COVID dataset and how they compare with generic FL architecture. The genetic CFL architecture’s performance analysis is discussed in Section 4.2.
4.1. COVID Dataset Performance for Genetic CFL Architecture
This subsection discusses the models’ training and performance evaluation. COVID-19 dataset samples are first used to train the server model. In turn, clients are allocated the model based on their client ratio. For this experiment, 100 clients are randomly selected, and three client ratios are tested: , , and . Models’ performance is generally evaluated using 10, 15, and 30 clients, respectively. Observations are chosen at random for each client device in the dataset. The purpose is to ensure that its observations are non-IID and replicate the key features of an actual situation. Section III discusses how the hyper-parameters are genetically modified after two training epochs. Table 4 and Table 5 shows all such iterations, and Figure 2 plots the most successful performance against each round.
Table 4.
Comparison of the performance of FL on various hyper-parameters on the COVID test data.
Table 5.
Comparison of the performance of genetic CFL on various hyper-parameters on the COVID test data.
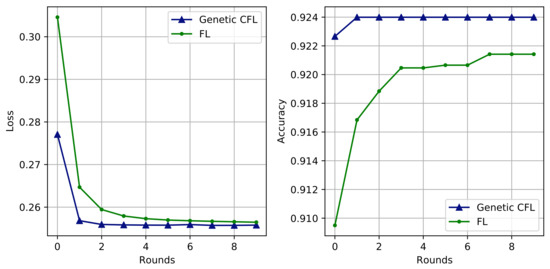
Figure 2.
Evaluation of Loss and Accuracy on COVID-19 dataset- FL vs Genetic CFL.
As the training hyper-parameters cannot be determined earlier, the training and performance of the model are locally optimized, and the training is said to be more personalized [24,40]. Server models learn smoothly and converge faster than typical FL models after training. Table 4 and Table 5 and Figure 2 illustrate the performance of the models for both the architectures in terms of accuracy, loss, precision, recall, and F1-Score. Each iteration shows how genetic CFL outperforms generic FL. The accuracy and loss are higher and lower in genetic CFL architecture than in the generic FL architecture. The accuracy and loss indicates that useful information is aggregated at the server. The loss value is used to train the ANN. However, accuracy or other metrics such as precision, recall, and F1-Score are also used to assess the training outcome. Table 6 depicts the training accuracy, training loss, validation accuracy and validation loss of the proposed genetic CFL algorithm on the COVID-19 dataset. From the table, it can be observed that in the first round, the maximum training and validation accuracy and minimum training and validation loss is attained after 1st epoch. After 1st epoch, the performance is reduced, indicating that genetic CFL algorithm has encountered overfitting problem. Similar performance can be noted in rounds 2, 3, 4 and 5. Hence, we can conclude that, in order to reduce the training time and the resource consumption (CPU and memory consumption) in the proposed genetic CFL approach, 1 epoch is sufficient for all the rounds.
Table 6.
Accuracy and loss of genetic CFL in several rounds.
4.2. Genetic CFL Performance Analysis
The Genetic CFL method appears to perform better with a larger data set. As a result, improving the quality of test results for every sample might help overall hyper-parameter optimization. Considering several datasets that differ in data characteristics and data points, an ideal grouping of similar scenarios leads to higher model accuracy. There needs to be a balance between cluster size and cluster number. In the given instance, a perfect combination could verify that the performance of such methods as in decentralized design produces better results. In a practical application, the predicted number of edge devices is more than in an artificial environment. Increasing the number of clients results in improved performance. Genetic CFL optimizes hyper-parameters to increase throughput for a relatively small set of optimization iterations.
The proposed genetic CFL architecture performance is better than regular CFL architecture while using fewer iterations. According to COVID data, our architecture is more efficient and iterative in clustering. It provides that the proposed genetic CFL is flexible and adjustable method for optimizing hyper-parameters. The proposed architecture has the advantage of adaptability over other methods by allowing it to be tailored to meet the dataset and the necessary situation. The majority of other architectures require a lot of manual effort to adjust hyper-parameters. It resets the mechanism and loads a new set of parameters for data analysis and applications. There are both time and resource costs associated with the conventional mechanism. Furthermore, each client is tested separately, which affects server and client performance. The proposed genetic CFL model ensures service delivery for all client devices while increasing the server model’s performance.
5. Conclusions and Future Directions
In this paper, we used the genetic algorithm to optimize the rate at which hyper-parameters are learned and the batch size for clustering through FL. To evaluate the performance of the proposed genetic CFL algorithm, we used the COVID-19 dataset. In addition, we discussed the best deployment conditions and limitations of the algorithm. In future, we would like to test the genetic CFL model on scalable and real-time datasets. The refinement of model parameters becomes accurate when the sample size increases, resulting in higher performance in the real-time scenario. We would also like to test the proposed model on several applications such as recommendation systems, image classification, and natural language processing. Furthermore, time-sensitive techniques could be combined with genetic CFL.
Author Contributions
Conceptualization, D.R.K.; Data curation, D.R.K. and T.R.G.; Formal analysis, D.R.K.; Methodology, D.R.K.; Resources, T.R.G.; Software, D.R.K.; Supervision, T.R.G.; Validation, T.R.G.; Visualization, T.R.G.; Writing—original draft, D.R.K. and T.R.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The dataset used in this work is taken from the kaggle repository https://www.kaggle.com/datasets/mykeysid10/covid19-dataset-for-year-2020?select=covid_data_2020-2021.csv(accessed on 4 April 2022).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| COVID-19 | Coronavirus |
| AI | Artificial Intelligence |
| ML | Machine Learning |
| FL | Federated Learning |
| GCFL | Genetic Clustered Federated Learning |
| PCFL | Privacy-preserving and Communication efficient scheme for Federated Learning |
| FedCD | Federated Cloning-and-Deletion |
| FedMA | Federated Matched Averaging |
| IFCA | Iterative Federated Clustering Algorithm |
| FeSEM | Federated Stochastic Expectation Maximization method |
| WOA | Whale Optimization Algorithm |
| MLP | Multilayer Perceptrons |
| ANN | Artificial Neural Networks |
References
- Liu, B.; Yan, B.; Zhou, Y.; Yang, Y.; Zhang, Y. Experiments of federated learning for covid-19 chest X-ray images. arXiv 2020, arXiv:2007.05592. [Google Scholar]
- Hageman, J.R. The coronavirus disease 2019 (COVID-19). Pediatr. Ann. 2020, 49, 99–100. [Google Scholar] [CrossRef] [PubMed]
- Saleem, K.; Saleem, M.; Zeeshan, R.; Javed, A.R.; Alazab, M.; Gadekallu, T.R.; Suleman, A. Situation-aware BDI reasoning to detect early symptoms of covid 19 using smartwatch. IEEE Sens. J. 2022. [Google Scholar] [CrossRef]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Zhang, W.; Zhou, T.; Lu, Q.; Wang, X.; Zhu, C.; Sun, H.; Wang, Z.; Lo, S.K.; Wang, F.Y. Dynamic-Fusion-Based Federated Learning for COVID-19 Detection. IEEE Internet Things J. 2021, 8, 15884–15891. [Google Scholar] [CrossRef]
- Lian, X.; Zhang, C.; Zhang, H.; Hsieh, C.J.; Zhang, W.; Liu, J. Can decentralized algorithms outperform centralized algorithms? A case study for decentralized parallel stochastic gradient descent. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Manoj, M.; Srivastava, G.; Somayaji, S.R.K.; Gadekallu, T.R.; Maddikunta, P.K.R.; Bhattacharya, S. An incentive based approach for COVID-19 planning using blockchain technology. In Proceedings of the 2020 IEEE Globecom Workshops GC Wkshps, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Alazab, M.; Tang, M. Deep Learning Applications for Cyber Security; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Kumar, R.; Khan, A.A.; Kumar, J.; Golilarz, N.A.; Zhang, S.; Ting, Y.; Zheng, C.; Wang, W. Blockchain-federated-learning and deep learning models for covid-19 detection using ct imaging. IEEE Sens. J. 2021, 21, 16301–16314. [Google Scholar] [CrossRef]
- Yarradoddi, S.; Gadekallu, T.R. Federated Learning Role in Big Data, Jot Services and Applications Security, Privacy and Trust in Jot a Aurvey. In Trust, Security and Privacy for Big Data; CRC Press: Boca Raton, FL, USA, 2022; pp. 28–49. [Google Scholar]
- Nilsson, A.; Smith, S.; Ulm, G.; Gustavsson, E.; Jirstrand, M. A performance evaluation of federated learning algorithms. In Proceedings of the Second Workshop on Distributed Infrastructures for dEep Learning, Rennes, France, 10 December 2018; pp. 1–8. [Google Scholar]
- Victor, N.; Alazab, M.; Bhattacharya, S.; Magnusson, S.; Maddikunta, P.K.R.; Ramana, K.; Gadekallu, T.R. Federated Learning for IoUT: Concepts, Applications, Challenges and Opportunities. arXiv 2022, arXiv:2207.13976. [Google Scholar]
- Sattler, F.; Müller, K.R.; Wiegand, T.; Samek, W. On the byzantine robustness of clustered federated learning. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 4–8 May 2020; pp. 8861–8865. [Google Scholar]
- Malekijoo, A.; Fadaeieslam, M.J.; Malekijou, H.; Homayounfar, M.; Alizadeh-Shabdiz, F.; Rawassizadeh, R. Fedzip: A compression framework for communication-efficient federated learning. arXiv 2021, arXiv:2102.01593. [Google Scholar]
- Fang, C.; Guo, Y.; Hu, Y.; Ma, B.; Feng, L.; Yin, A. Privacy-preserving and communication-efficient federated learning in internet of things. Comput. Secur. 2021, 103, 102199. [Google Scholar] [CrossRef]
- Alazab, M.; Huda, S.; Abawajy, J.; Islam, R.; Yearwood, J.; Venkatraman, S.; Broadhurst, R. A hybrid wrapper-filter approach for malware detection. J. Netw. 2014, 9, 1–14. [Google Scholar] [CrossRef]
- Ozfatura, E.; Ozfatura, K.; Gündüz, D. Time-correlated sparsification for communication-efficient federated learning. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, VI, Australia, 12–20 July 2021; pp. 461–466. [Google Scholar]
- Briggs, C.; Fan, Z.; Andras, P. Federated learning with hierarchical clustering of local updates to improve training on non-IID data. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–9. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated learning with matched averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Yao, X.; Huang, T.; Wu, C.; Zhang, R.; Sun, L. Towards faster and better federated learning: A feature fusion approach. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–29 September 2019; pp. 175–179. [Google Scholar]
- Ghosh, A.; Chung, J.; Yin, D.; Ramchandran, K. An efficient framework for clustered federated learning. Adv. Neural Inf. Process. Syst. 2020, 33, 19586–19597. [Google Scholar] [CrossRef]
- Kopparapu, K.; Lin, E.; Zhao, J. Fedcd: Improving performance in non-iid federated learning. arXiv 2020, arXiv:2006.09637. [Google Scholar]
- Gadekallu, T.R.; Pham, Q.V.; Huynh-The, T.; Bhattacharya, S.; Maddikunta, P.K.R.; Liyanage, M. Federated learning for big data: A survey on opportunities, applications, and future directions. arXiv 2021, arXiv:2110.04160. [Google Scholar]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečnỳ, J.; Mazzocchi, S.; McMahan, B.; et al. Towards federated learning at scale: System design. Proc. Mach. Learn. Syst. 2019, 1, 374–388. [Google Scholar]
- Xie, M.; Long, G.; Shen, T.; Zhou, T.; Wang, X.; Jiang, J.; Zhang, C. Multi-center federated learning. arXiv 2020, arXiv:2005.01026. [Google Scholar]
- Chai, Z.; Ali, A.; Zawad, S.; Truex, S.; Anwar, A.; Baracaldo, N.; Zhou, Y.; Ludwig, H.; Yan, F.; Cheng, Y. Tifl: A tier-based federated learning system. In Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing, Stockholm, Sweden, 23–26 June 2020; pp. 125–136. [Google Scholar]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef]
- Kim, J.Y.; Cho, S.B. Evolutionary optimization of hyperparameters in deep learning models. In Proceedings of the 2019 IEEE Congress on Evolutionary Computation (CEC), Wellington, New Zealand, 10–13 June 2019; pp. 831–837. [Google Scholar]
- Xiao, X.; Yan, M.; Basodi, S.; Ji, C.; Pan, Y. Efficient hyperparameter optimization in deep learning using a variable length genetic algorithm. arXiv 2020, arXiv:2006.12703. [Google Scholar]
- Aljarah, I.; Faris, H.; Mirjalili, S. Optimizing connection weights in neural networks using the whale optimization algorithm. Soft Comput. 2018, 22, 1–15. [Google Scholar] [CrossRef]
- Beruvides, G.; Quiza, R.; Rivas, M.; Casta no, F.; Haber, R.E. Online detection of run out in microdrilling of tungsten and titanium alloys. Int. J. Adv. Manuf. Technol. 2014, 74, 1567–1575. [Google Scholar] [CrossRef][Green Version]
- Agrawal, S.; Sarkar, S.; Alazab, M.; Maddikunta, P.K.R.; Gadekallu, T.R.; Pham, Q.V. Genetic CFL: Hyperparameter optimization in clustered federated learning. Comput. Intell. Neurosci. 2021, 2021, 7156420. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Zhang, M.; Liu, X.; Mohapatra, P.; DeLucia, M. FedTune: Automatic Tuning of Federated Learning Hyper-Parameters from System Perspective. arXiv 2021, arXiv:2110.03061. [Google Scholar]
- Khodak, M.; Tu, R.; Li, T.; Li, L.; Balcan, M.F.F.; Smith, V.; Talwalkar, A. Federated hyperparameter tuning: Challenges, baselines, and connections to weight-sharing. Adv. Neural Inf. Process. Syst. 2021, 34, 19184–19197. [Google Scholar]
- Ibraimi, L.; Selimi, M.; Freitag, F. BePOCH: Improving federated learning performance in resource-constrained computing devices. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar]
- Taheri, R.; Shojafar, M.; Alazab, M.; Tafazolli, R. FED-IIoT: A robust federated malware detection architecture in industrial IoT. IEEE Trans. Ind. Inform. 2020, 17, 8442–8452. [Google Scholar] [CrossRef]
- Qayyum, A.; Ahmad, K.; Ahsan, M.A.; Al-Fuqaha, A.; Qadir, J. Collaborative federated learning for healthcare: Multi-modal covid-19 diagnosis at the edge. arXiv 2021, arXiv:2101.07511. [Google Scholar]
- Arikumar, K.; Prathiba, S.B.; Alazab, M.; Gadekallu, T.R.; Pandya, S.; Khan, J.M.; Moorthy, R.S. FL-PMI: Federated learning-based person movement identification through wearable devices in smart healthcare systems. Sensors 2022, 22, 1377. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).