
Bayesian Hyper-Parameter Optimisation for Malware Detection


Abstract
:1. Introduction
- a demonstration of how well various ML-based Windows Portable Executable (PE) file classifiers perform when trained with default parameters.
- an evaluation of various HPO approaches applied to this problem, including:
- (a)
- established major model-free techniques (Grid Search and Random Search); and
- (b)
- a state-of-the-art Bayesian optimisation model-based approach (Bayesian Optimisation with Tree-Structured Parzen Estimators).
- a demonstration for our target problem that the optimal choices of ML hyper-parameters may vary considerably from the toolkit defaults.
2. Related Literature
3. Hyper-Parameter Optimisation
3.1. Formal Definition of HPO and Motivation for Its Use in Malware Classification
3.2. Model-Free Blackbox Optimisation Methods
3.3. Bayesian Optimisation (BO)
3.4. Sequential Model-Based Optimisation (SMBO)
3.5. Tree-Structured Parzen Estimators (TPE)
4. Experiments
4.1. Execution Environment and Dataset
4.2. Experiments with Default Settings
4.3. Model Hyper-Parameter Optimisation
5. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pandey, A.K.; Tripathi, A.K.; Kapil, G.; Singh, V.; Khan, M.W.; Agrawal, A.; Kumar, R.; Khan, R.A. Trends in Malware Attacks: Identification and Mitigation Strategies. In Critical Concepts, Standards, and Techniques in Cyber Forensics; IGI Global: Hershey, PA, USA, 2020; pp. 47–60. [Google Scholar]
- Al-Sabaawi, A.; Al-Dulaimi, K.; Foo, E.; Alazab, M. Addressing Malware Attacks on Connected and Autonomous Vehicles: Recent Techniques and Challenges. In Malware Analysis Using Artificial Intelligence and Deep Learning; Springer: Berlin/Heidelberg, Germany, 2021; pp. 97–119. [Google Scholar]
- Bergstra, J.; Komer, B.; Eliasmith, C.; Yamins, D.; Cox, D.D. Hyperopt: A python library for model selection and hyperparameter optimization. Comput. Sci. Discov. 2015, 8, 014008. [Google Scholar] [CrossRef]
- Anderson, H.S.; Roth, P. Ember: An open dataset for training static pe malware machine learning models. arXiv 2018, arXiv:1804.04637. [Google Scholar]
- Schultz, M.G.; Eskin, E.; Zadok, F.; Stolfo, S.J. Data mining methods for detection of new malicious executables. In Proceedings of the 2001 IEEE Symposium on Security and Privacy, S&P 2001, Oakland, CA, USA, 14–16 May 2000; IEEE: New York, NY, USA, 2000; pp. 38–49. [Google Scholar]
- Kolter, J.Z.; Maloof, M.A. Learning to detect and classify malicious executables in the wild. J. Mach. Learn. Res. 2006, 7, 2721–2744. [Google Scholar]
- Raff, E.; Barker, J.; Sylvester, J.; Brandon, R.; Catanzaro, B.; Nicholas, C.K. Malware detection by eating a whole exe. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2 February 2018. [Google Scholar]
- Pham, H.D.; Le, T.D.; Vu, T.N. Static PE malware detection using gradient boosting decision trees algorithm. In International Conference on Future Data and Security Engineering; Springer: Berlin/Heidelberg, Germany, 2018; pp. 228–236. [Google Scholar]
- Fawcett, C.; Hoos, H.H. Analysing differences between algorithm configurations through ablation. J. Heuristics 2016, 22, 431–458. [Google Scholar] [CrossRef] [Green Version]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Mantovani, R.G.; Horváth, T.; Cerri, R.; Vanschoren, J.; de Carvalho, A.C. Hyper-parameter tuning of a decision tree induction algorithm. In Proceedings of the 5th Brazilian Conference on Intelligent Systems (BRACIS), Recife, Brazil, 9–12 October 2016; IEEE: New York, NY, USA, 2016; pp. 37–42. [Google Scholar]
- Van Rijn, J.N.; Hutter, F. Hyperparameter importance across datasets. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2367–2376. [Google Scholar]
- Biedenkapp, A.; Lindauer, M.; Eggensperger, K.; Hutter, F.; Fawcett, C.; Hoos, H. Efficient parameter importance analysis via ablation with surrogates. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Eggensperger, K.; Lindauer, M.; Hoos, H.H.; Hutter, F.; Leyton-Brown, K. Efficient benchmarking of algorithm configurators via model-based surrogates. Mach. Learn. 2018, 107, 15–41. [Google Scholar] [CrossRef] [Green Version]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. In Proceedings of the 25th Annual Conference on Neural Information Processing Systems (NIPS 2011), Neural Information Processing Systems Foundation, Granada, Spain, 12–15 December 2011; Volume 24. [Google Scholar]
- Probst, P.; Boulesteix, A.L.; Bischl, B. Tunability: Importance of hyperparameters of machine learning algorithms. J. Mach. Learn. Res. 2019, 20, 1–32. [Google Scholar]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; De Freitas, N. Taking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 2015, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Feurer, M.; Hutter, F. Hyperparameter optimization. In Automated Machine Learning; Springer: Cham, Switzerland, 2019; pp. 3–33. [Google Scholar]
- Bischl, B.; Mersmann, O.; Trautmann, H.; Weihs, C. Resampling methods for meta-model validation with recommendations for evolutionary computation. Evol. Comput. 2012, 20, 249–275. [Google Scholar] [CrossRef] [PubMed]
- Thornton, C.; Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Auto-WEKA: Combined selection and hyperparameter optimization of classification algorithms. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 847–855. [Google Scholar]
- Klein, A.; Falkner, S.; Bartels, S.; Hennig, P.; Hutter, F. Fast bayesian hyperparameter optimization on large datasets. Electron. J. Stat. 2017, 11, 4945–4968. [Google Scholar] [CrossRef]
- Maron, O.; Moore, A.W. The racing algorithm: Model selection for lazy learners. Artif. Intell. Rev. 1997, 11, 193–225. [Google Scholar] [CrossRef]
- Bellman, R. Dynamic Programming Princeton University Press Princeton; Princeton University: Princeton, NJ, USA, 1957. [Google Scholar]
- Hutter, F.; Hoos, H.; Leyton-Brown, K. An efficient approach for assessing hyperparameter importance. In Proceedings of the International Conference On Machine Learning, PMLR, Beijing, China, 22–24 June 2014; pp. 754–762. [Google Scholar]
- Hutter, F.; Hoos, H.; Leyton-Brown, K. An evaluation of sequential model-based optimization for expensive blackbox functions. In Proceedings of the 15th Annual Conference Companion on Genetic and Evolutionary Computation, Amsterdam, The Netherlands, 6–10 July 2013; pp. 1209–1216. [Google Scholar]
- Bergstra, J.; Yamins, D.; Cox, D. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In Proceedings of the International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 17–19 June 2013; pp. 115–123. [Google Scholar]
- Falkner, S.; Klein, A.; Hutter, F. BOHB: Robust and efficient hyperparameter optimization at scale. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 1437–1446. [Google Scholar]
- Brochu, E.; Cora, V.M.; De Freitas, N. A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. arXiv 2010, arXiv:1012.2599. [Google Scholar]
- Dewancker, I.; McCourt, M.; Clark, S. Bayesian Optimization Primer; SIGOTOP: Kisumu, Kenya, 2015. [Google Scholar]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.T.; Blum, M.; Hutter, F. Auto-sklearn: Efficient and robust automated machine learning. In Automated Machine Learning; Springer: Cham, Switzerland, 2019; pp. 113–134. [Google Scholar]
- Donald, R.J. Efficient global optimization of expensive black-box function. J. Glob. Optim. 1998, 13, 455–492. [Google Scholar]
- Eggensperger, K.; Feurer, M.; Hutter, F.; Bergstra, J.; Snoek, J.; Hoos, H.; Leyton-Brown, K. Towards an empirical foundation for assessing bayesian optimization of hyperparameters. In Proceedings of the NIPS Workshop on Bayesian Optimization in Theory and Practice, Lake Tahoe, NV, USA, 10 December 2013; Volume 10, p. 3. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Anderson, H.S.; Roth, P. Ember. Available online: https://github.com/elastic/ember/blob/master/README.md (accessed on 19 November 2021).
- Mauricio. Benign Malicious. 2021. Available online: https://www.kaggle.com/amauricio/pe-files-malwares (accessed on 11 October 2021).
- Carrera, E. Pefile. 2022. Available online: https://github.com/erocarrera/pefile (accessed on 15 January 2022).
- ALGorain, F.; Clark, J. Bayesian Hyper Parameter Optimization for Malware Detection. Available online: https://github.com/fahadgorain/Bayesian-Hyper-Parameter-Optimization-for-Malware-Detection-Extended (accessed on 11 October 2021).
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. arXiv 2013, arXiv:1309.0238. [Google Scholar]
- LightGBM Documentation. 2021. Available online: https://lightgbm.readthedocs.io/en/latest (accessed on 20 August 2021).
- Roc Auc. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_auc_score.html (accessed on 28 April 2022).



{kind=link}
{kind=link}
| ML Model | Time to Train | Score (AUC-ROC) |
|---|---|---|
| GNB | 11 min 56 s | 0.406 |
| SGD | 11 min 56 s | 0.563 |
| LightGBM Benchmark | 26 min | 0.922 |
| RF | 57 min and 52 s | 0.90 |
| LR | 1 h and 44 min | 0.598 |
| KNN | 3 h 14 min 59 s | 0.745 |
| Search Methods | Best ROC AUC Score | Number of Objective Evaluations | Time to Complete Search |
|---|---|---|---|
| Benchmark LightGBM Model | 0.922 | 100 | 26 min (MacBook) |
| Grid Search | 0.944 | 965 | Almost 3 months (MacBook) |
| Random Search | 0.955 | 60 | 15 days, 13 h and 12 min (Windows 10) |
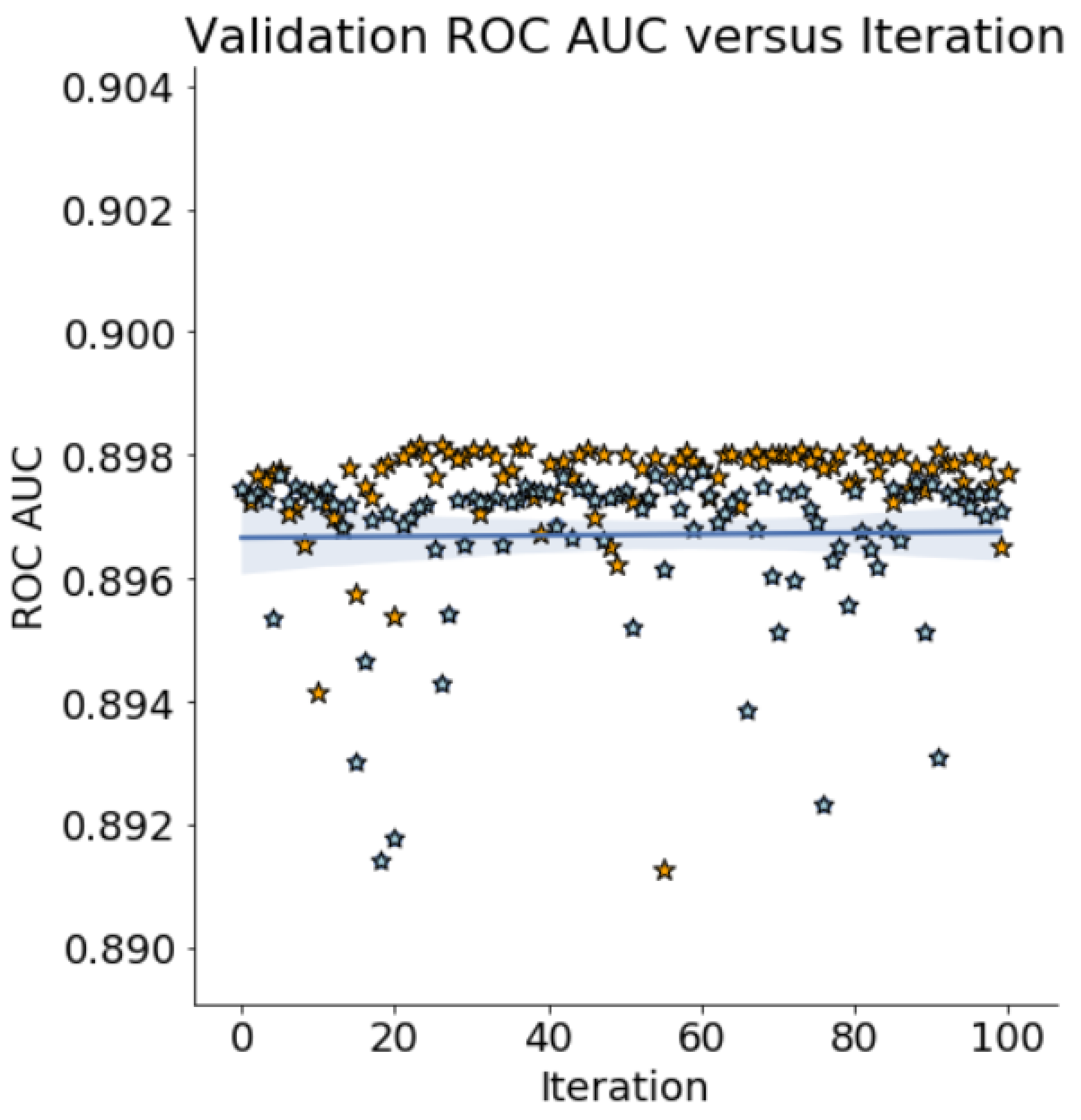
| AHBO-TPE with 100 iterations (results after 3 iterations) | 0.957 (0.955) | 26 (3) | 27 days (4 h) (Windows 10) |
| Hyper-Parameter | Grid Search Best Hyper-Parameter Settings | Range | Default Value |
|---|---|---|---|
| boosting_type | GBDT | GBDT, DART, GOSS | GBDT |
| num_iteration | 1000 | 500:1000 | 100 |
| learning_rate | 0.005 | 0.005:0.05 | 0.1 |
| num_leaves | 512 | 31:2048 | 31 |
| feature_fraction | 1.0 | 0.5:1.0 | 1.0 |
| bagging_fraction | 0.5 | 0.5:1.0 | 1.0 |
| objective | binary | binary | None |
| Hyper-Parameter | Random Search Best Hyper-Parameter Settings | Range | Default Value |
|---|---|---|---|
| boosting_type | GBDT | GBDT or GOSS | GBDT |
| num_iteration | 60 | 1:100 | 100 |
| learning_rate | 0.0122281 | 0.005:0.05 | 0.1 |
| num_leaves | 150 | 1:512 | 31 |
| feature_fraction | 0.8 | 0.5:1.0 | 1.0 |
| bagging_fraction | 0.8 | 0.5:1.0 | 1.0 |
| objective | binary | binary only | None |
| min_child_samples | 165 | 20:500 | 20 |
| reg_alpha | 0.102041 | 0.0:1.0 | 0.0 |
| reg_lambda | 0.632653 | 0.0:1.0 | 0.0 |
| colsample_bytree | 1.0 | 0.0:1.0 | 1.0 |
| subsample | 0.69697 | 0.5:1.0 | 1.0 |
| is_unbalance | True | True or False | False |
| ML Model | Score (AUC-ROC) | Score (AUC-ROC) after Optimisation |
|---|---|---|
| GNB | 0.406 | same |
| SGD | 0.563 | 0.597 |
| RF | 0.901 | 0.936 |
| LR | 0.598 | 0.618 |
| KNN | 0.745 | 0.774 |
| ML Model | Time to Train | Training Time Reduction |
|---|---|---|
| GNB | 11 min 56 s | same |
| SGD | 4 min 35 s | 14 min 35 s |
| LightGBM Benchmark | 18 min 30 s | 7 min 30 s |
| RF | 31 min 14 s | 26 min |
| LR | 1 h 5 min 37 s | 38 min |
| KNN | 4 h 37 min and 30 s | increased by 1 h 23 min 29 s |
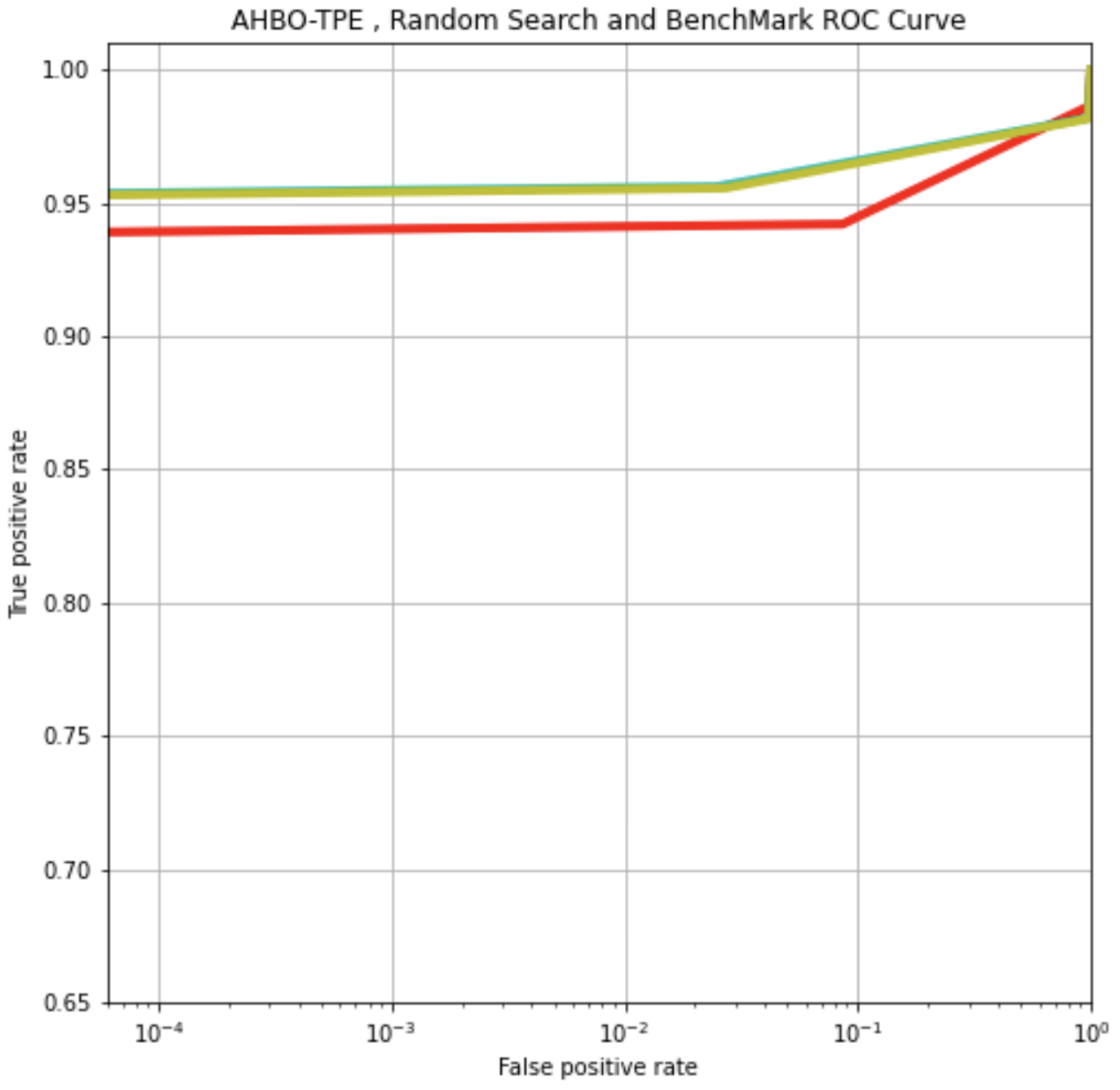
| ML Model | Default AUC ROC Score | Grid Search Optimised AUC ROC Score | Random Search AUC ROC Score | AHBO-TPE AUC ROC Score |
|---|---|---|---|---|
| LightGBM | 0.97914 | 0.98247 | 0.99809 | 0.99755 |
| RF | 0.97965 | N/A | N/A | 0.97819 |
| KNN | 0.94888 | N/A | N/A | 0.95954 |
| LR | 0.5 | N/A | N/A | 0.50729 |
| SGD | 0.84065 | N/A | N/A | 0.84322 |
| * GNB | 0.54475 | N/A | N/A | Same |
| Hyper-Parameter | Random Search Best Hyper-Parameter Settings | Range | Default Value |
|---|---|---|---|
| boosting_type | GBDT | GBDT or GOSS | GBDT |
| num_iteration | 26 | 1:100 | 100 |
| learning_rate | 0.02469 | 0.005:0.05 | 0.1 |
| num_leaves | 229 | 1:512 | 31 |
| feature_fraction | 0.78007 | 0.5:1.0 | 1.0 |
| bagging_fraction | 0.93541 | 0.5:1.0 | 1.0 |
| objective | binary | binary only | None |
| min_child_samples | 145 | 20:500 | 20 |
| reg_alpha | 0.98803 | 0.0:1.0 | 0.0 |
| reg_lambda | 0.45169 | 0.0:1.0 | 0.0 |
| colsample_bytree | 0.89595 | 0.0:1.0 | 1.0 |
| subsample | 0.63005 | 0.0:1.0 | 1.0 |
| is_unbalance | True | True or False | False |
| n_estimators | 1227 | 1:2000 | 100 |
| Subsample_for_bin | 160,000 | 2000:200,000 | 200,000 |
| Hyper-Parameter | AHBO-TPE Search Hyper-Parameter Results | Range | Default Value |
|---|---|---|---|
| Penalty | L2 | L1, L2, elasticnet | L1 |
| Loss | Hinge | hinge, log, modified-huber, squared-hinge | Hinge |
| Max-iterations | 10 | 10:200 | 1000 |
| Hyper-Parameter | AHBO-TPE Search Hyper-Parameter Results | Range | Default Value |
|---|---|---|---|
| n_estimators | 100 | 10:100 | 10 |
| max_depth | 30 | 2:60 | None |
| max_features | auto | auto, log2, sqrt | auto |
| min_samples_split | 10 | 2:10 | 2 |
| min_samples_leaf | 30 | 1:10 | 1 |
| criterion | gini | gini, entropy | gini |
| Hyper-Parameter | AHBO-TPE Search Hyper-Parameter Results | Range | Default Value |
|---|---|---|---|
| max_iter | 200 | 10:200 | 100 |
| C | 8.0 | 0.0:20.0 | auto |
| solver | sag | liblinear, lbfgs, sag, saga | lbfgs |
| Hyper-Parameter | AHBO-TPE Search Hyper-Parameter Results | Range | Default Value |
|---|---|---|---|
| n_neighbors | 15 | 1:31 | 5 |
| ML Models | Hyper-Parameter | Range | Best Hyper-Parameter Results |
|---|---|---|---|
| LightGBM | num_leaves Min_child samples n_estimators boosting_type learning_rate Subsample_for_bin Colsample_bytree feature_fraction Bagging_fraction Reg_alpha Reg_lambda Is_unbalance objective | 1:512 20:500 10:100 gbdt 0.01:0.5 2000:200,000 0.6:1.0 0.5:1.0 0.5:1.0 0.0:1.0 0.0:1.0 True, False Binary | 10 90 19 Gbdt 0.4418140187193226 80,000 0.7307181013749854 0.6726481091942302 0.5893616201923844 0.195989486417426 0.1939778453324642 False Binary |
| RF | n_estimators max_depth max_features min_samples_split min_samples_leaf criterion | 10:200 10:50 auto, sqrt 10:50 10:50 entropy, gini | 100 15 sqrt 19 10 entropy |
| KNN | n_neighbors | 1:100 | 3 |
| GNB | N/A | N/A | N/A |
| SGD | penalty loss max_iter alpha | none, l1, l2, elasticnet hinge, log, modified_huber, squared_hinge, perceptron 20:1000 0.0001:0.2 | L2 log 790 0.0001 |
| LR | Max_iter C solver | 20:500 1.0:50.0 lbfgs, sag, saga | 155 7 sag |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
ALGorain, F.T.; Clark, J.A. Bayesian Hyper-Parameter Optimisation for Malware Detection. Electronics 2022, 11, 1640. https://doi.org/10.3390/electronics11101640
ALGorain FT, Clark JA. Bayesian Hyper-Parameter Optimisation for Malware Detection. Electronics. 2022; 11(10):1640. https://doi.org/10.3390/electronics11101640
Chicago/Turabian StyleALGorain, Fahad T., and John A. Clark. 2022. "Bayesian Hyper-Parameter Optimisation for Malware Detection" Electronics 11, no. 10: 1640. https://doi.org/10.3390/electronics11101640
APA StyleALGorain, F. T., & Clark, J. A. (2022). Bayesian Hyper-Parameter Optimisation for Malware Detection. Electronics, 11(10), 1640. https://doi.org/10.3390/electronics11101640