
A Novel Ultra-Low Power 8T SRAM-Based Compute-in-Memory Design for Binary Neural Networks



Abstract
:1. Introduction
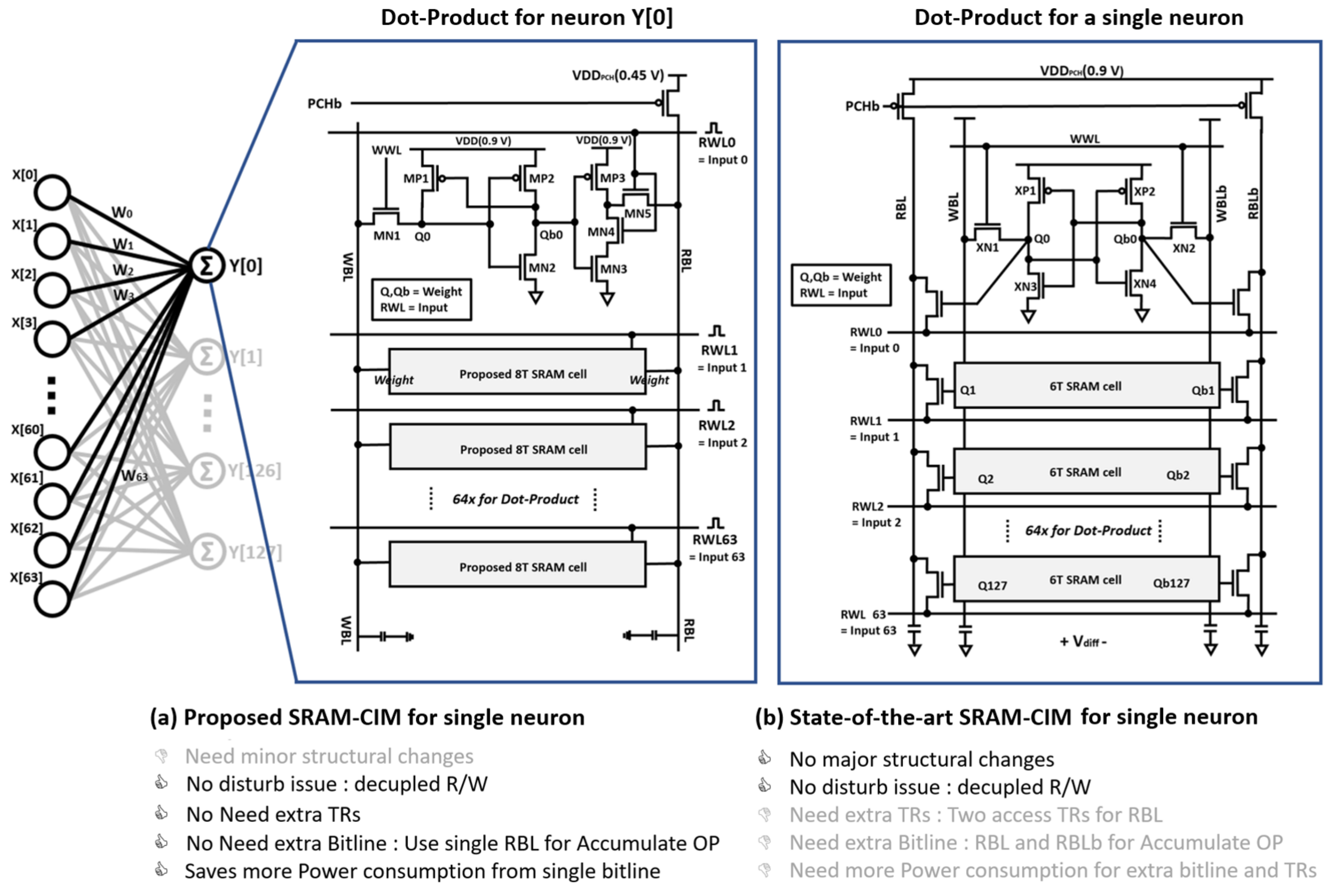
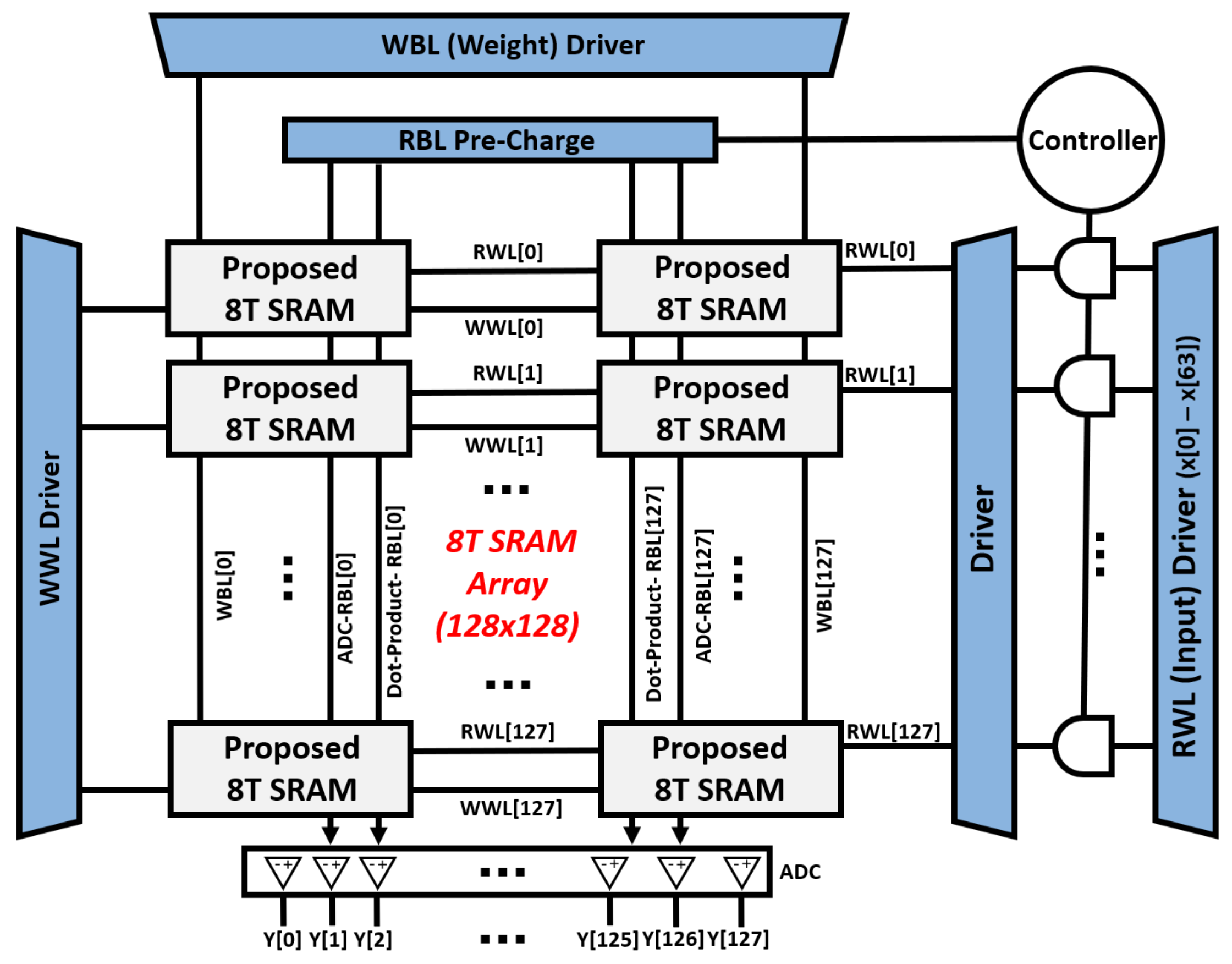
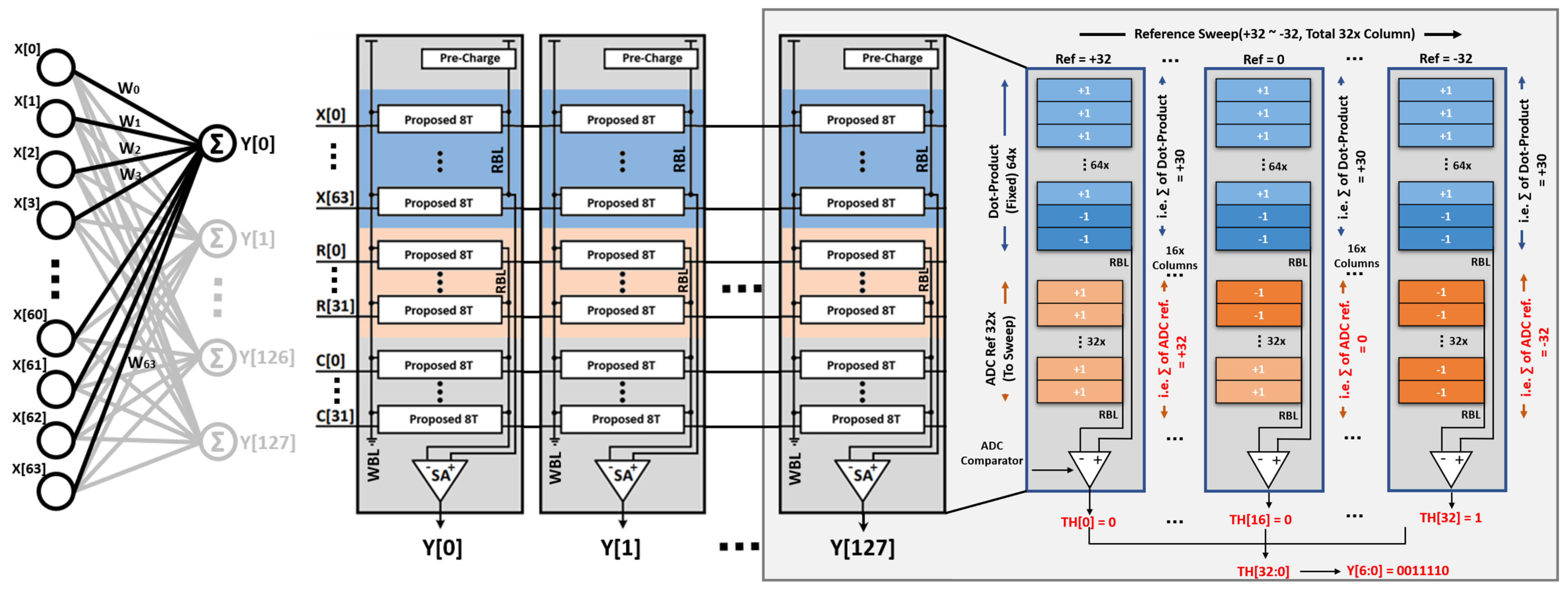
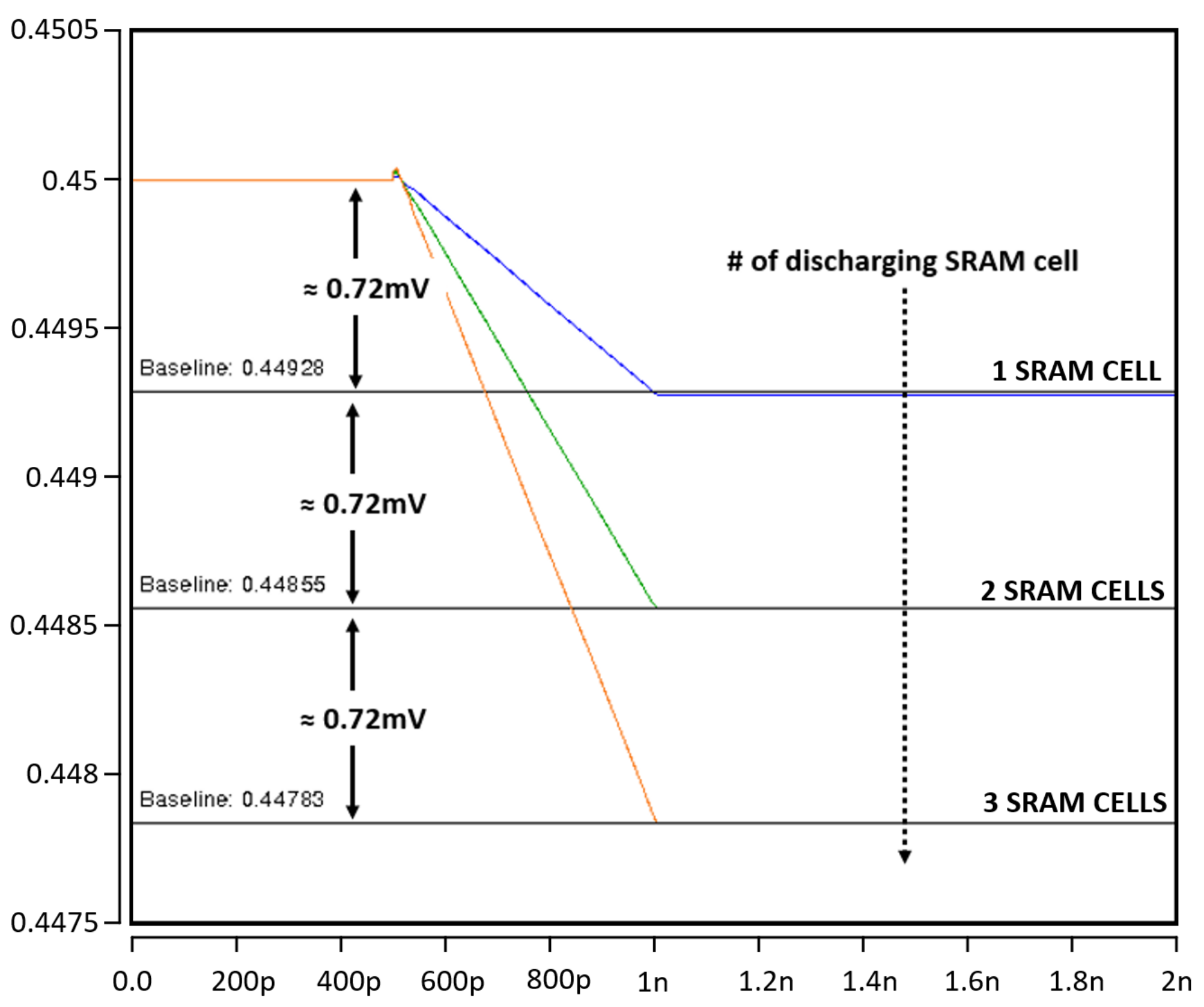
2. Proposed Compute-in-Memory Design
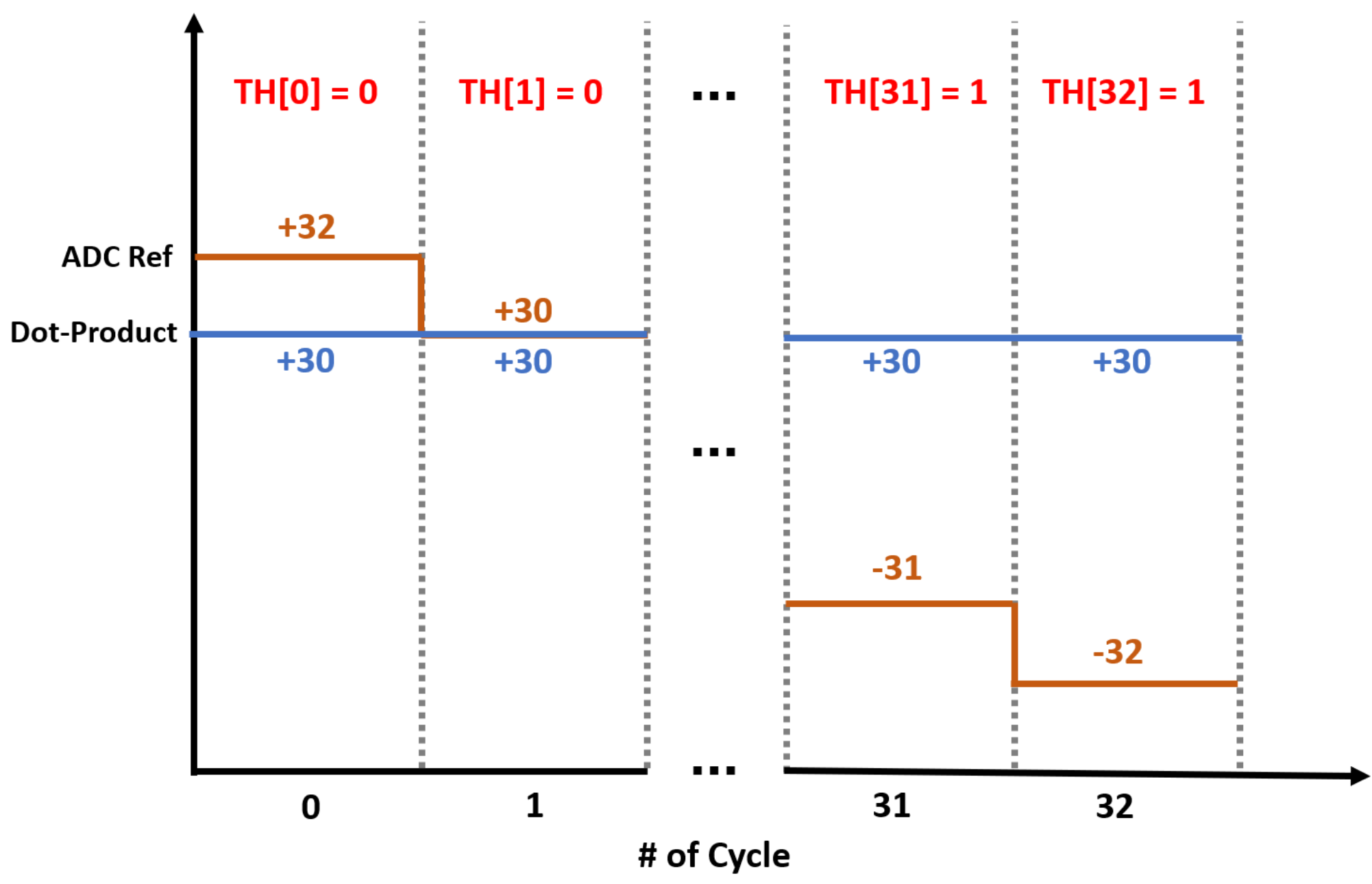
3. A Column-Based Neuron Design for BNN
4. Performance Evaluation and Analysis
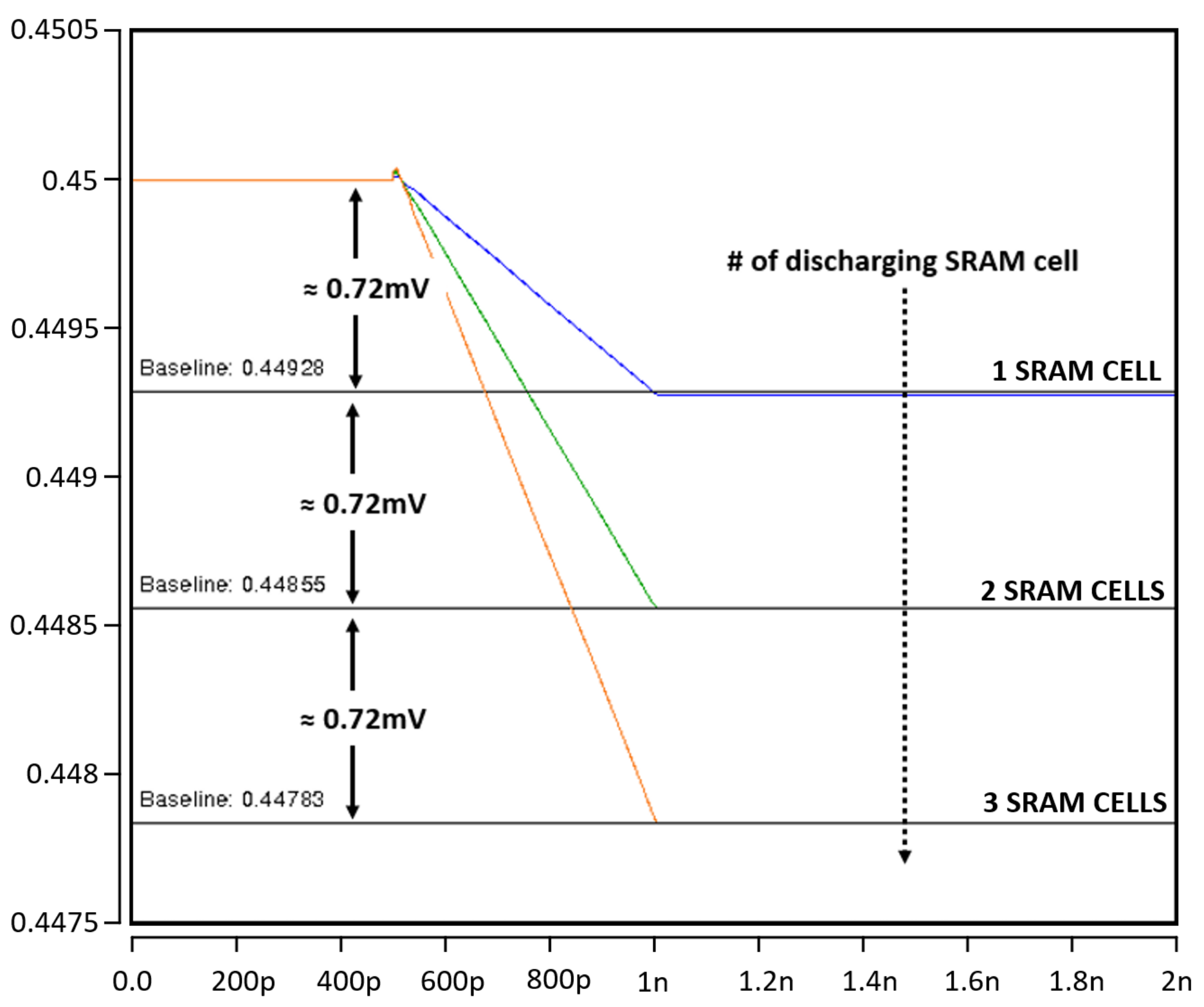
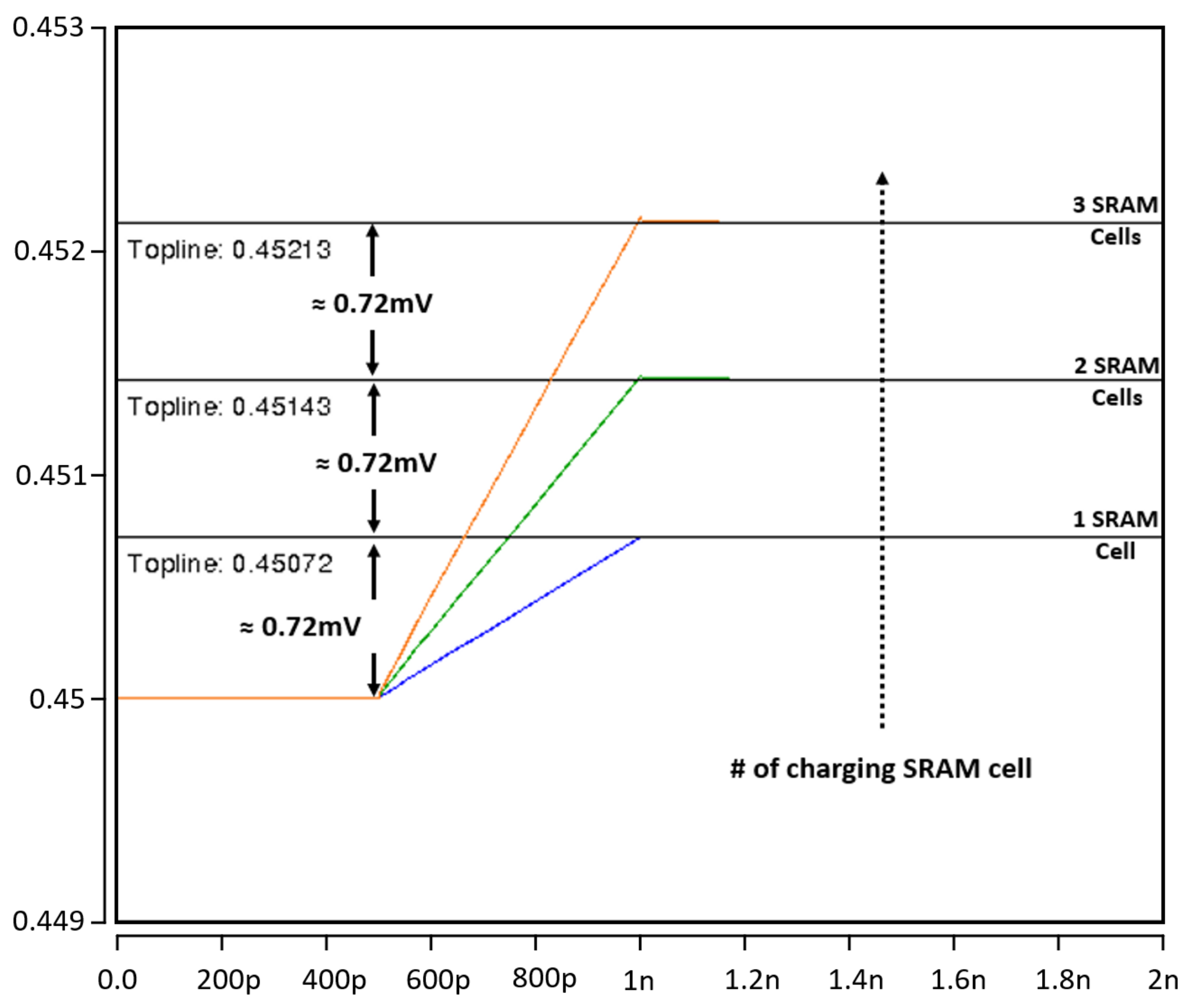
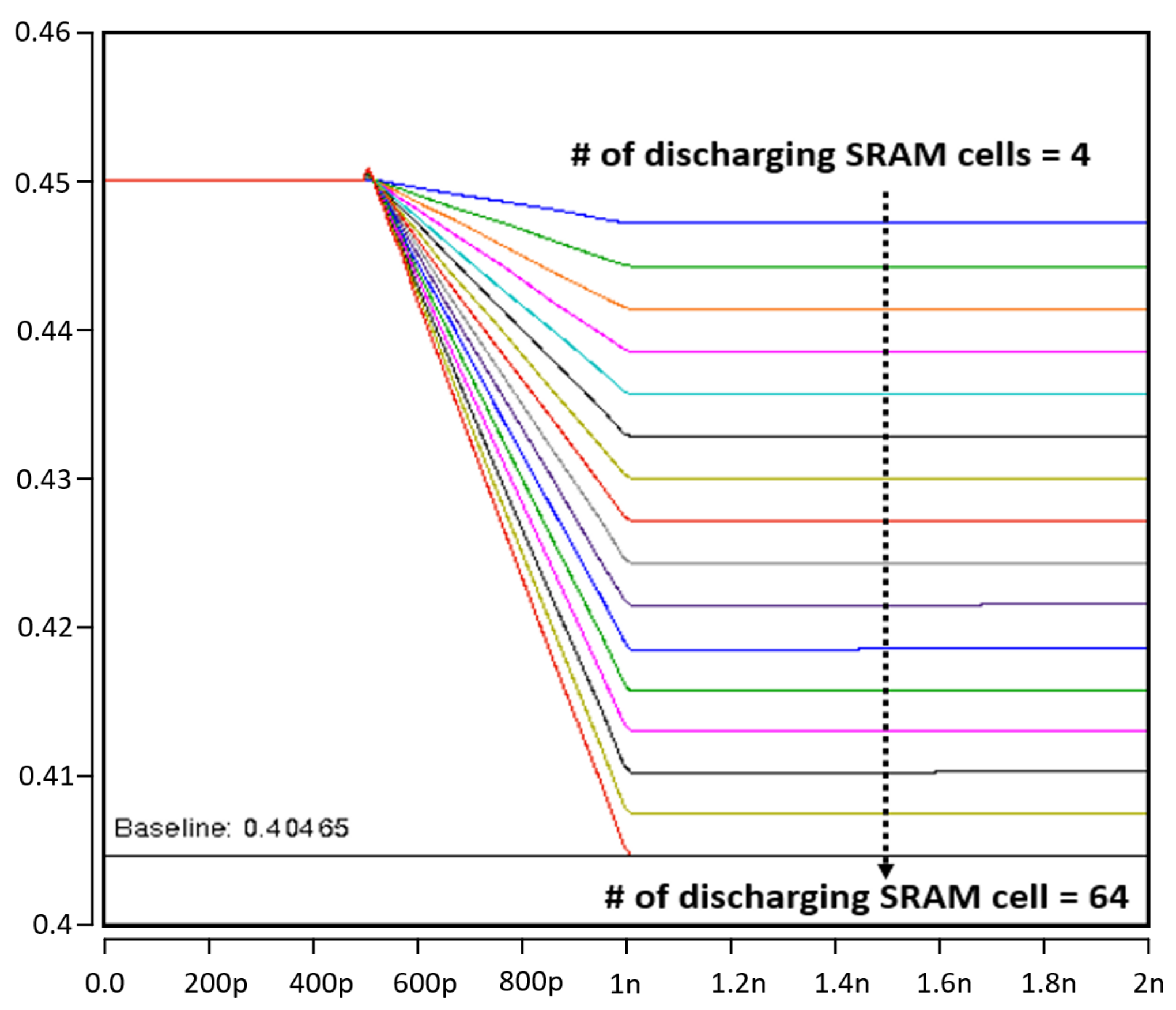
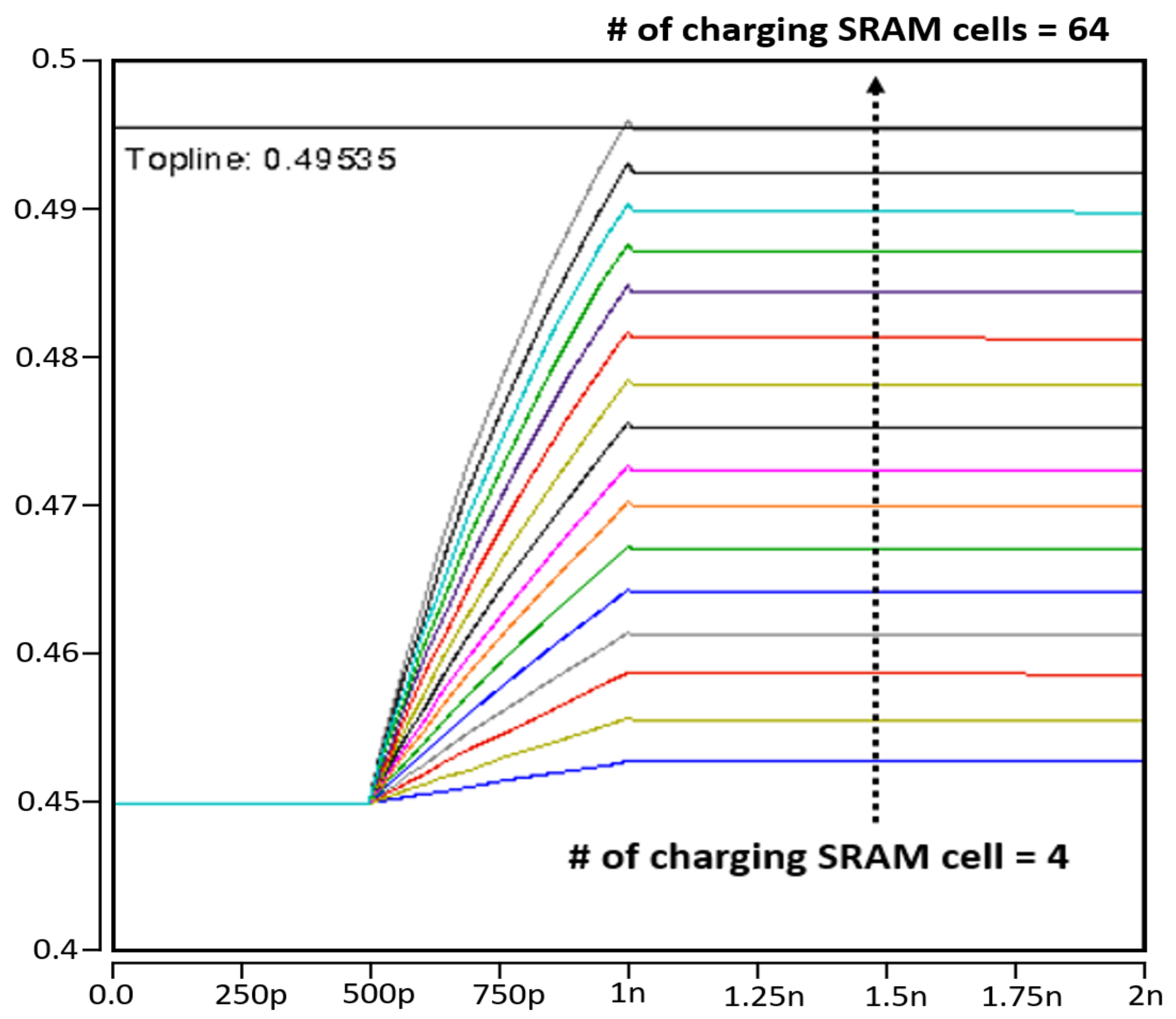
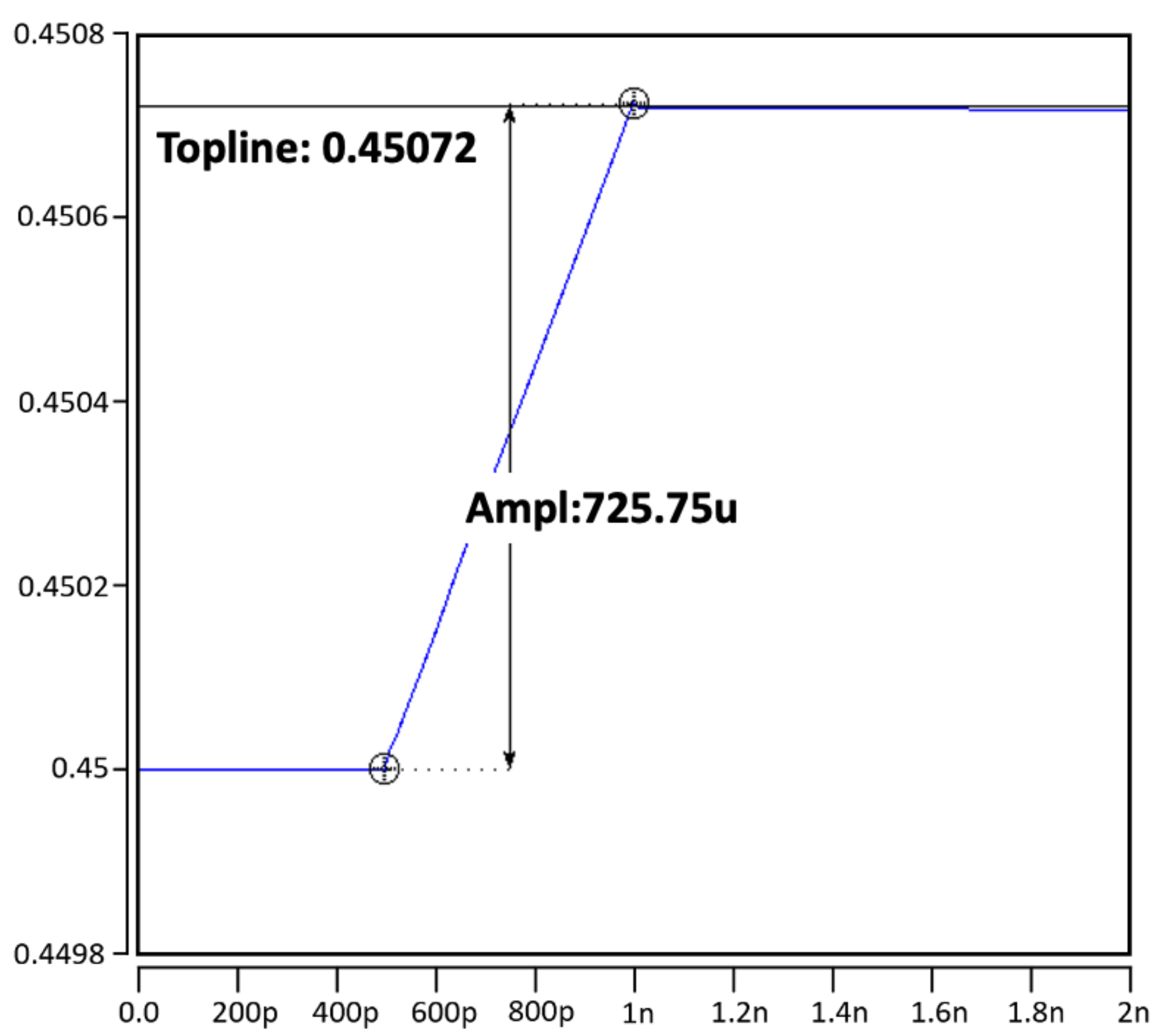
4.1. Proposed Compute-in-Memory Design
4.2. Proposed SRAM Bit Cell Design
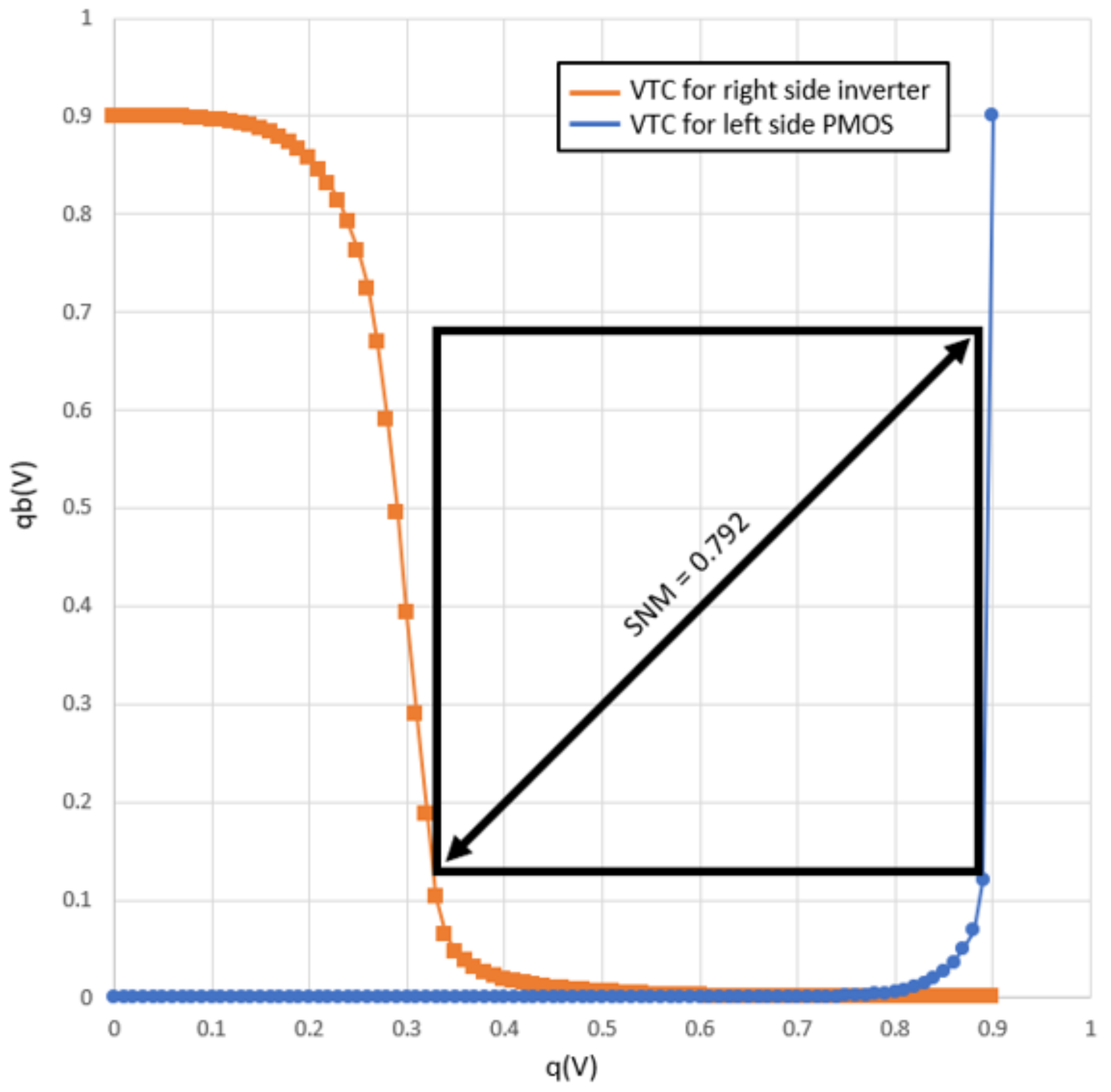
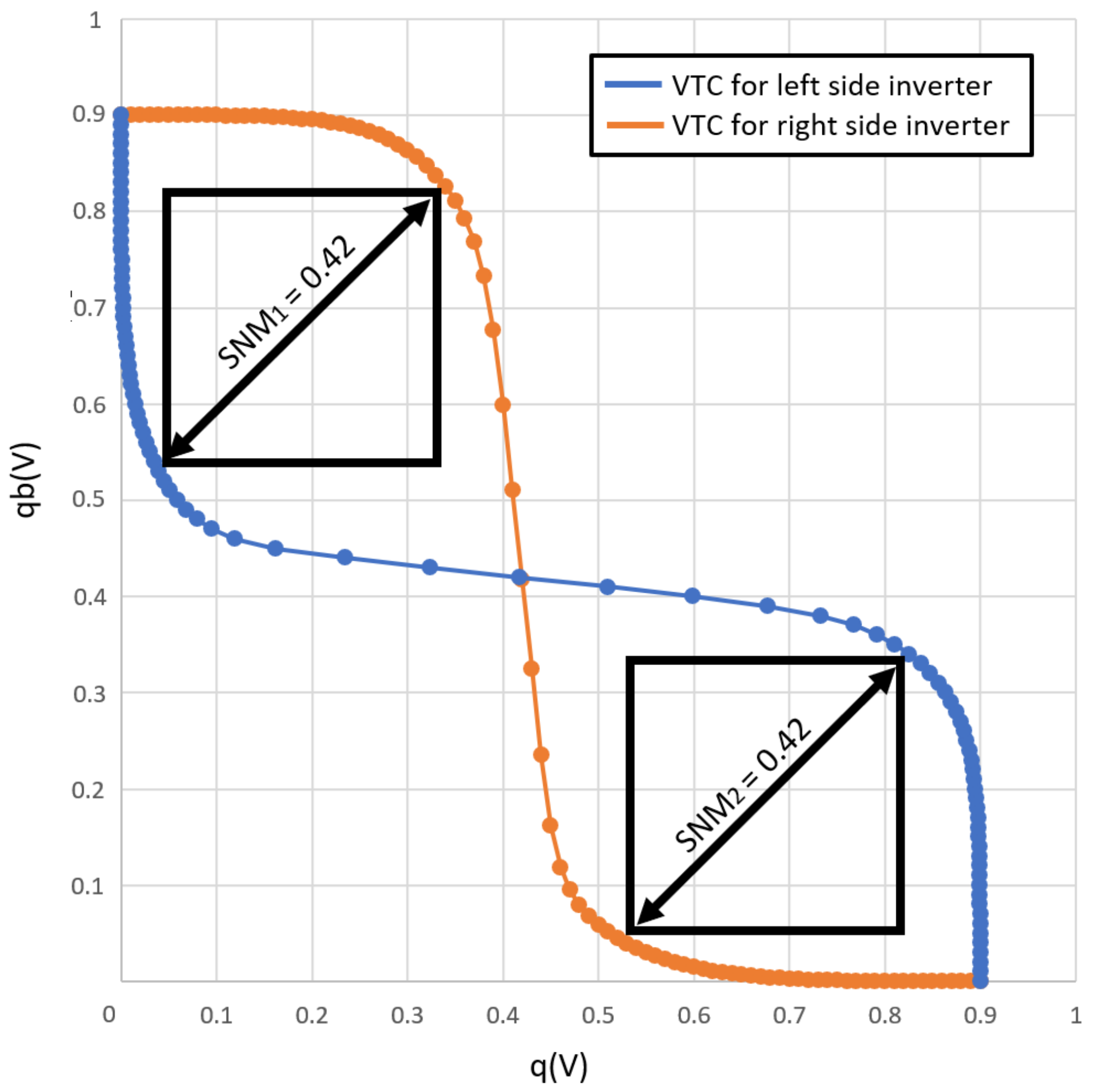
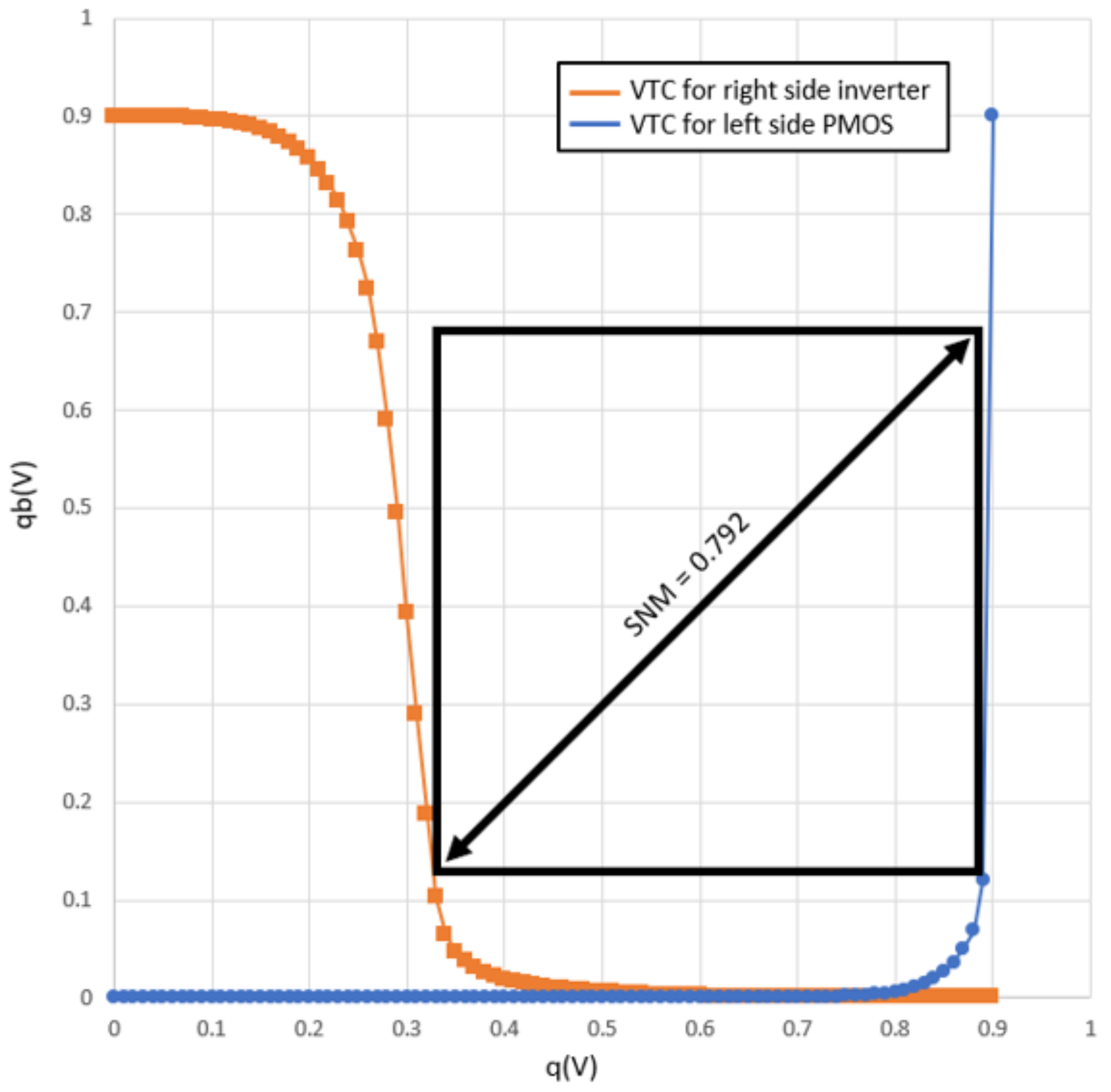
4.2.1. Hold Static Noise Margin (SNM)
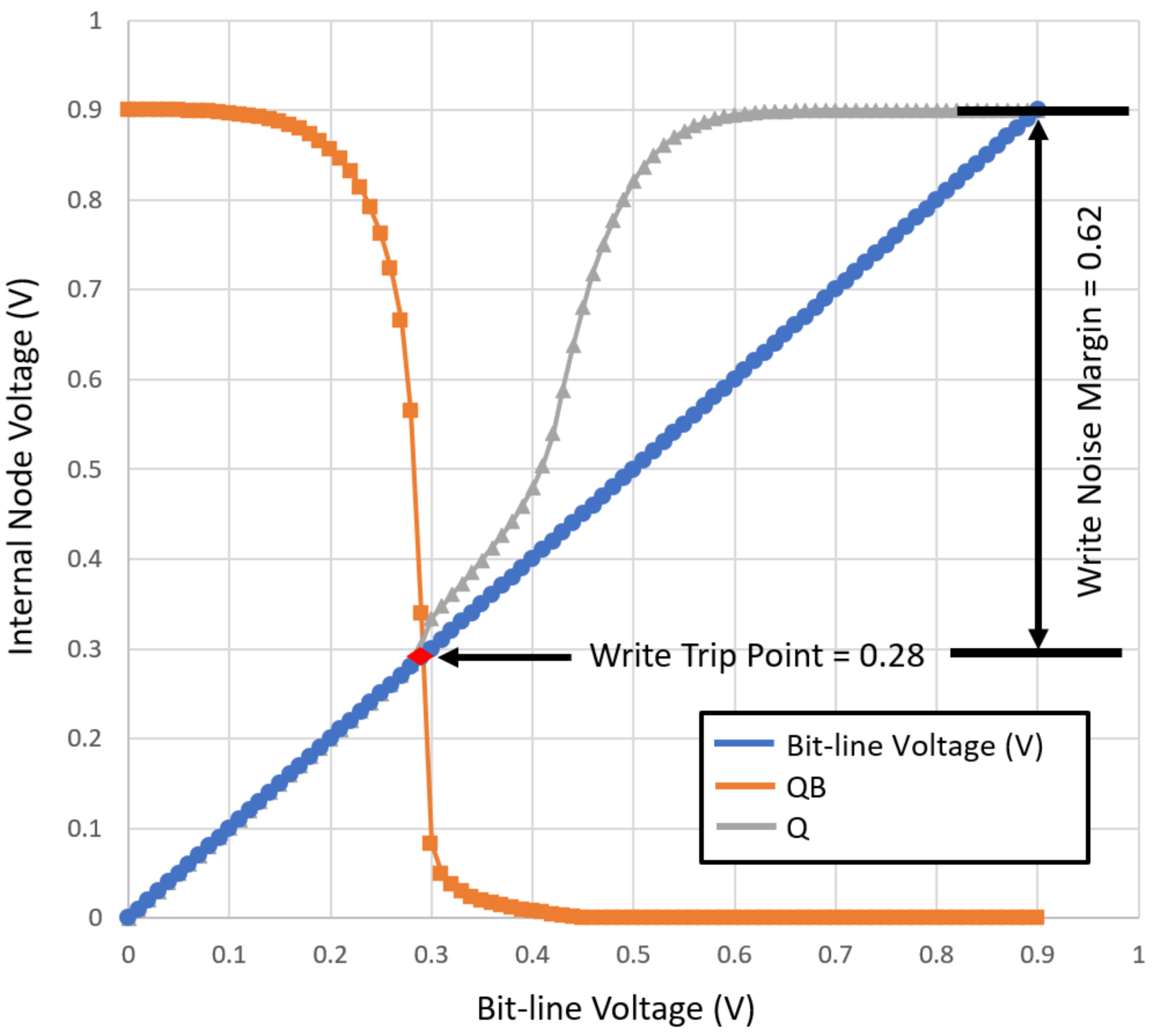
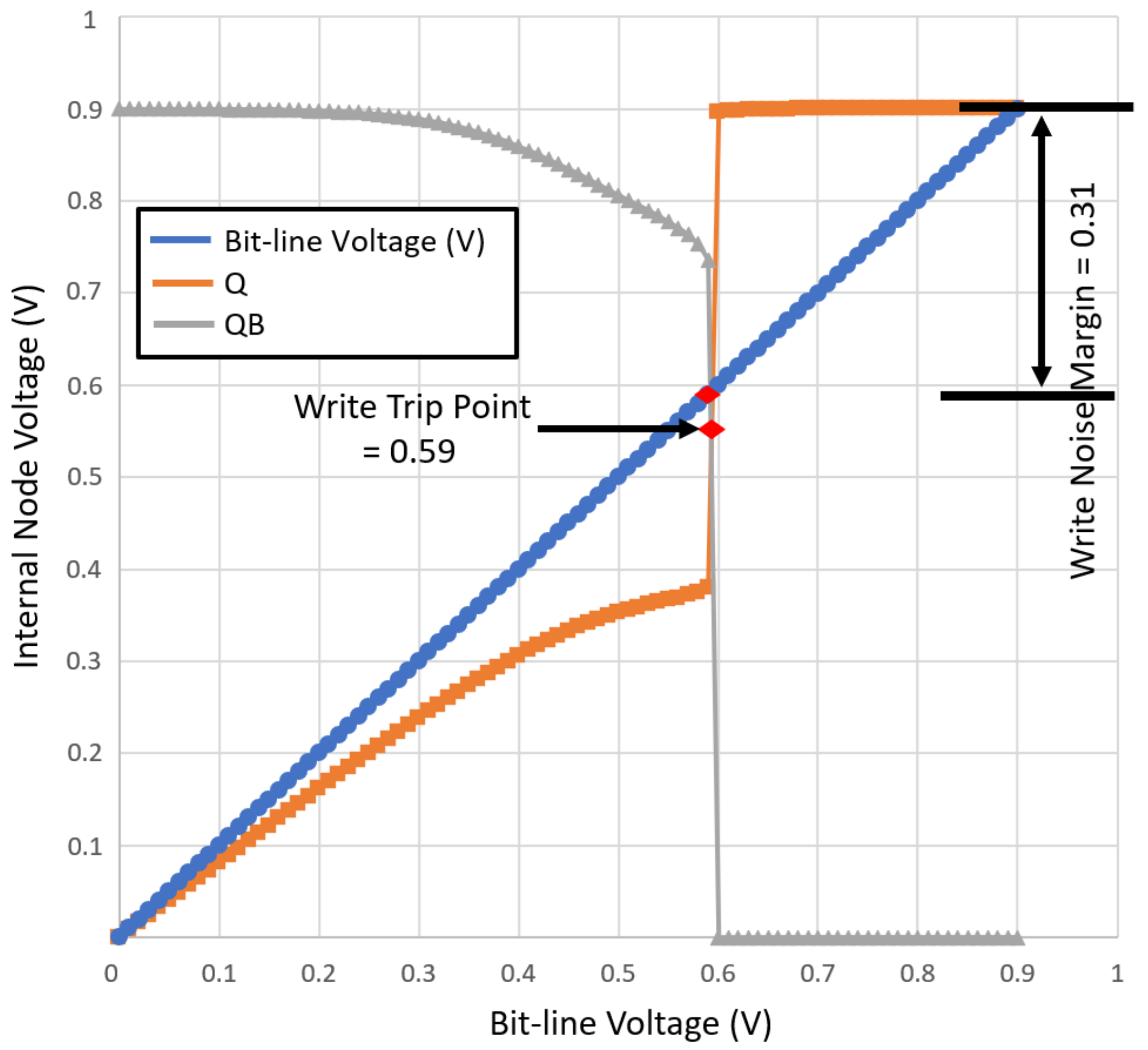
4.2.2. Write Noise Margin (WNM)
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SRAM | Static Random-Access Memory |
| CIM | Compute-In-Memory |
| ADC | Analog to Digital Converter |
| BNN | Binary Neural Networks |
| SNM | Static Noise Margin |
| WNM | Write Noise Margin |
| WTP | Write Trip Point |
References
- Deng, L.; Li, G.; Han, S.; Shi, L.; Xie, Y. Model Compression and Hardware Acceleration for Neural Networks: A Comprehensive Survey. Proc. IEEE 2020, 108, 485–532. [Google Scholar] [CrossRef]
- Mühlroth, C.; Grottke, M. Artificial Intelligence in Innovation: How to Spot Emerging Trends and Technologies. IEEE Trans. Eng. Manag. 2020, 1–18. [Google Scholar] [CrossRef]
- Biswas, A.; Chandrakasan, A. Conv-RAM: An energy-efficient SRAM with embedded convolution computation for low-power CNN-based machine learning applications. In Proceedings of the 2018 IEEE International Solid—State Circuits Conference—(ISSCC), San Francisco, CA, USA, 11–15 February 2018; pp. 488–490. [Google Scholar]
- Jiang, Z.; Yin, S.; Seok, M.; Seo, J.S. XNOR-SRAM: In-Memory Computing SRAM Macro for Binary/Ternary Deep Neural Networks. IEEE J. Solid-State Circuits 2020, 55, 1733–1743. [Google Scholar] [CrossRef]
- Yang, Z.; Wei, L. Logic Circuit and Memory Design for In-Memory Computing Applications using Bipolar RRAMs. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Jiang, Z.; Yin, S.; Seo, J.S.; Seok, M. C3SRAM: In-Memory-Computing SRAM Macro Based on Capacitive-Coupling Computing. IEEE Solid-State Circuits Lett. 2019, 2, 131–134. [Google Scholar] [CrossRef]
- Yan, B.; Li, B.; Qiao, X.; Xue, C.X.; Chang, M.F.; Chen, Y.; Li, H.H. Resistive Memory-Based In-Memory Computing: From Device and Large-Scale Integration System Perspectives. Adv. Intell. Syst. 2019, 1, 1900068. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Lin, B. Trained Biased Number Representation for ReRAM-Based Neural Network Accelerators. J. Emerg. Technol. Comput. Syst. 2019, 15, 1–17. [Google Scholar] [CrossRef]
- Huang, S.; Ankit, A.; Silveira, P.; Antunes, R.; Chalamalasetti, S.R.; Hajj, I.E.; Kim, D.E.; Aguiar, G.; Bruel, P.; Serebryakov, S.; et al. Mixed Precision Quantization for ReRAM-based DNN Inference Accelerators. In Proceedings of the 2021 26th Asia and South Pacific Design Automation Conference (ASP-DAC), Tokyo, Japan, 18–21 January 2021; pp. 372–377. [Google Scholar]
- Yu, S. Resistive Random Access Memory (RRAM). Synth. Lect. Emerg. Eng. Technol. 2016, 2, 1–79. [Google Scholar] [CrossRef]
- Suri, M.; Gupta, A.; Parmar, V.; Lee, K.H. Performance Enhancement of Edge-AI-Inference Using Commodity MRAM: IoT Case Study. In Proceedings of the 2019 IEEE 11th International Memory Workshop (IMW), Monterey, CA, USA, 12–15 May 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Gao, S.; Chen, B.; Qu, Y.; Zhao, Y. MRAM Acceleration Core for Vector Matrix Multiplication and XNOR-Binarized Neural Network Inference. In Proceedings of the 2020 International Symposium on VLSI Technology, Systems and Applications (VLSI-TSA), Hsinchu, Taiwan, 10–13 August 2020; pp. 153–154. [Google Scholar] [CrossRef]
- Xu, T.C.; Leppänen, V. Analysing emerging memory technologies for big data and signal processing applications. In Proceedings of the 2015 Fifth International Conference on Digital Information Processing and Communications (ICDIPC), Sierre, Switzerland, 7–9 October 2015; pp. 104–109. [Google Scholar] [CrossRef]
- Sun, X.; Liu, R.; Peng, X.; Yu, S. Computing-in-Memory with SRAM and RRAM for Binary Neural Networks. In Proceedings of the 2018 14th IEEE International Conference on Solid-State and Integrated Circuit Technology (ICSICT), Qingdao, China, 31 October–3 November 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Z.; Verma, N. A machine-learning classifier implemented in a standard 6T SRAM array. In Proceedings of the 2016 IEEE Symposium on VLSI Circuits (VLSI-Circuits), Honolulu, HI, USA, 15–17 June 2016; pp. 1–2. [Google Scholar] [CrossRef]
- Si, X.; Khwa, W.S.; Chen, J.J.; Li, J.F.; Sun, X.; Liu, R.; Yu, S.; Yamauchi, H.; Li, Q.; Chang, M.F. A Dual-Split 6T SRAM-Based Computing-in-Memory Unit-Macro With Fully Parallel Product-Sum Operation for Binarized DNN Edge Processors. IEEE Trans. Circuits Syst. I Regul. Pap. 2019, 66, 4172–4185. [Google Scholar] [CrossRef]
- Kim, H.; Chen, Q.; Kim, B. A 16K SRAM-Based Mixed-Signal In-Memory Computing Macro Featuring Voltage-Mode Accumulator and Row-by-Row ADC. In Proceedings of the 2019 IEEE Asian Solid-State Circuits Conference (A-SSCC), Macao, China, 4–6 November 2019; pp. 35–36. [Google Scholar] [CrossRef]
- Yu, C.; Yoo, T.; Kim, T.T.; Tshun Chuan, K.C.; Kim, B. A 16K Current-Based 8T SRAM Compute-In-Memory Macro with Decoupled Read/Write and 1-5bit Column ADC. In Proceedings of the 2020 IEEE Custom Integrated Circuits Conference (CICC), Boston, MA, USA, 22–25 March 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Maddah, R.; Melhem, R.; Cho, S. RDIS: Tolerating Many Stuck-At Faults in Resistive Memory. IEEE Trans. Comput. 2015, 64, 847–861. [Google Scholar] [CrossRef]
- Dong, X.; Wu, X.; Sun, G.; Xie, Y.; Li, H.; Chen, Y. Circuit and microarchitecture evaluation of 3D stacking magnetic RAM (MRAM) as a universal memory replacement. In Proceedings of the 2008 45th ACM/IEEE Design Automation Conference, Anaheim, CA, USA, 8–13 June 2008; pp. 554–559. [Google Scholar]
- Klostermann, U.; Angerbauer, M.; Gruning, U.; Kreupl, F.; Ruhrig, M.; Dahmani, F.; Kund, M.; Muller, G. A Perpendicular Spin Torque Switching based MRAM for the 28 nm Technology Node. In Proceedings of the 2007 IEEE International Electron Devices Meeting, Washington, DC, USA, 10–12 December 2007; pp. 187–190. [Google Scholar] [CrossRef]
- Raajitha, K.; Meenakshi, K.; Rao, Y.M. Design of Thermometer Coding and One-Hot Coding. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 601–609. [Google Scholar] [CrossRef]
- Kim, Y.; Patel, S.; Kim, H.; Yadav, N.; Choi, K.K. Ultra-Low Power and High-Throughput SRAM Design to Enhance AI Computing Ability in Autonomous Vehicles. Electronics 2021, 10, 256. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SRAM | DRAM | MRAM | RRAM | |
|---|---|---|---|---|
| Cell Size (F) | 50–120 | 6–8 | 4–20 | 1–10 |
| Read Delay (ns) | 1–10 | 10–30 | 5–10 | 5–10 |
| Write Delay (ns) | 1–10 | 10–30 | 10–20 | 10–30 |
| Read Power | Low | Low-Medium | High | Low-Medium |
| Write Power | Low | Low-Medium | Low-Medium | Low-Medium |
| Input (RWL) | 0 (RWL = L) | 1 (RWL = H) | |
|---|---|---|---|
| Weight (Q,Qb) | |||
| −1 (Q = L, Qb = H) | 0 (No change) | −1 (−V) | |
| +1 (Q = H, Qb = L) | 0 (No change) | +1 (+V) | |
| Input (RWL) | 0 (RWL = L) | 1 (RWL = H) | |||||
|---|---|---|---|---|---|---|---|
| Weight (Q,Qb) | |||||||
| −1 (Q = L, Qb = H) | 0 (No change) | −1 (−V) | |||||
| State-of-the -art CIM [18] | Proposed CIM | Improvement | State-of-the -art CIM [18] | Proposed CIM | Improvement | ||
| 7.825 × 10−5 | 2.479 × 10−8 | 99.96% | 9.887 × 10−5 | 7.566 × 10−6 | 92.34% | ||
| +1 (Q = H, Qb = L) | 0 (No change) | +1 (+V) | |||||
| State-of-the -art CIM [18] | Proposed CIM | Improvement | State-of-the -art CIM [18] | Proposed CIM | Improvement | ||
| 7.825 × 10−5 | 2.912 × 10−8 | 99.96% | 9.887 × 10−5 | 1.266 × 10−6 | 98.71% | ||
| No. | Transistors | Ratio | Size of Transistors |
|---|---|---|---|
| 1 | MN1 | 2 | m |
| 2 | MN2 | 4 | m |
| 3 | MN3 | 4 | m |
| 4 | MN4 | 4 | m |
| 5 | MN5 | 2 | m |
| 6 | MP1 | 1 | m |
| 7 | MP2 | 1 | m |
| 8 | MP3 | 1 | m |
| Delay(s) | State-of-the-Art 8T SRAM Bit Cell | Proposed 8T SRAM Bit Cell | Improvement |
|---|---|---|---|
| Write 0 | 91.2% | ||
| Write 1 | 71.9% | ||
| Read 0 | 6.2% | ||
| Read 1 | 0.2% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.; Li, S.; Yadav, N.; Choi, K.K. A Novel Ultra-Low Power 8T SRAM-Based Compute-in-Memory Design for Binary Neural Networks. Electronics 2021, 10, 2181. https://doi.org/10.3390/electronics10172181
Kim Y, Li S, Yadav N, Choi KK. A Novel Ultra-Low Power 8T SRAM-Based Compute-in-Memory Design for Binary Neural Networks. Electronics. 2021; 10(17):2181. https://doi.org/10.3390/electronics10172181
Chicago/Turabian StyleKim, Youngbae, Shuai Li, Nandakishor Yadav, and Kyuwon Ken Choi. 2021. "A Novel Ultra-Low Power 8T SRAM-Based Compute-in-Memory Design for Binary Neural Networks" Electronics 10, no. 17: 2181. https://doi.org/10.3390/electronics10172181
APA StyleKim, Y., Li, S., Yadav, N., & Choi, K. K. (2021). A Novel Ultra-Low Power 8T SRAM-Based Compute-in-Memory Design for Binary Neural Networks. Electronics, 10(17), 2181. https://doi.org/10.3390/electronics10172181