Abstract
This study aims to address the issue of various defects on the surface of aluminum profile materials, which can significantly impact industrial production as well as the reliability and safety of products. An algorithmic model, BBW YOLO (YOLOv8-BiFPN-BiFormer-WIoU v3), based on an enhanced YOLOv8 model is proposed for aluminum profile material surface-defect detection. First, the model can effectively eliminate redundant feature information and enhance the feature-extraction process by incorporating a weighted Bidirectional Feature Pyramid Feature-fusion Network (BiFPN). Second, the model incorporates a dynamic sparse-attention mechanism (BiFormer) along with an efficient pyramidal network architecture, which enhances the precision and detection speed of the model. Meanwhile, the model optimizes the loss function using Wise-IoU v3 (WIoU v3), which effectively enhances the localization performance of surface-defect detection. The experimental results demonstrate that the precision and recall of the BBW YOLO model are improved by 5% and 2.65%, respectively, compared with the original YOLOv8 model. Notably, the BBW YOLO model achieved a real-time detection speed of 292.3 f/s. In addition, the model size of BBW YOLO is only 6.3 MB. At the same time, the floating-point operations of BBW YOLO are reduced to 8.3 G. As a result, the BBW YOLO model offers excellent defect detection performance and opens up new opportunities for its efficient development in the aluminum industry.
1. Introduction
The market demand for aluminum profiles is increasing across various sectors, including in aerospace, transportation, and electronics, due to their lightweight, corrosion-resistant, and easy-to-process characteristics. However, the surface quality of aluminum profiles can be compromised by factors such as the production process, environmental conditions, and service life. These influences may result in defects such as splashing, paint-bubbling, pitting, discoloration, and dirt inclusion. These defects not only compromise the visual appeal of aluminum but may also diminish its performance, shorten its service life, or even pose safety hazards [1]. Therefore, it is crucial to pay adequate attention to the detection of surface defects following the production and processing of aluminum profile materials. The development and application of efficient and accurate defect detection techniques are essential for identifying surface defects and play a key role in enhancing manufacturing process control and product quality assurance systems.
Traditional methods for detecting surface defects depend on experienced technicians conducting visual inspections or employing basic image processing techniques to identify flaws. However, these conventional manual inspection methods present several challenges, including high labor intensity, elevated costs, and low efficiency [2].
With the ongoing advancements in image processing techniques and significant improvements in computer hardware performance, technologists have increasingly begun to employ advanced image processing methods to provide assistance. These techniques include grayscale conversion [3], which highlights defective features in an image, and histogram equalization [4], which enhances the image contrast to make defects more visible. Additionally, the Canny algorithm [5] for edge detection identifies the contours of objects within the image, further aiding in defect detection. Image segmentation techniques—for example, thresholding [6]—can divide the image into multiple regions, allowing for more accurate identification of defects. Although these traditional methods have achieved some success in specific scenarios, they often rely on manual parameter adjustments. Furthermore, these methods are highly sensitive to variations in image quality and environmental conditions, which limits their applicability in complex environments.
In recent years, surface-defect detection algorithms based on deep learning have advanced rapidly. There are two predominant detection architectures for these algorithms: the two-stage detection architecture and the single-stage detection architecture. Among these, the two-stage network, exemplified by Fast R-CNN [7], is not suitable for real-time detection, despite its ability to effectively process large volumes of complex image data, thereby enhancing detection precision and efficiency. To meet the speed and precision requirements of modern manufacturing industries for detecting surface defects in workpieces, subsequent research has focused on the use of single-stage networks, such as the Single-Step Multi-Frame Detector (SSD) [8], You Only Look Once (YOLO) [9], and RetinaNet [10]. In addition, the DeepLab series [11], with its cavity convolution and depth-separable convolution characteristics, effectively expands the sensory field while maintaining computational efficiency, which is particularly suitable for the semantic segmentation task of fine material defects, and its ASPP module is able to capture multi-scale environmental information, which is potentially advantageous for the identification of defects of different sizes on the surface of aluminium profiles. In contrast, EfficientNet [12], through its composite scaling approach, balances the three dimensions of network depth, width, and resolution and achieves an optimal balance of parameter efficiency and accuracy, and its lightweight design is particularly suitable for deployment needs in industrial real-time inspection scenarios.
For instance, Yan et al. [13] proposed an enhanced SSD algorithm specifically for steel surface-defect detection. In their proposed algorithm, the Conv5_1 layer in the original SSD architecture is replaced with a Transformer multi-attention mechanism module, which enhances the speed of small-target detection. Additionally, Li et al. [14] introduced a deep learning detection algorithm based on an improved version of RetinaNet-GHM to address the issues of subpar results and inaccurate defect localization associated with traditional steel-plate surface-defect detection methods. This algorithm enhances the mean average precision (mAP) for each defect type on the surface, achieving an overall average mAP of 76.7%. Wang et al. [15] proposed a hybrid network called SSD-Faster Net for industrial defect detection on guide rails, insulators, commutators, and other components. This method attained an mAP of 84.03% on the dataset and improved the computational speed by nearly 7%. Wang et al. [16] concentrated on the ability to distinguish defects with similar optical features while balancing detection precision and speed. They introduced a new detection model named Yolo-SAGC, which reduced the leakage rate of six types of defects from 32.75% to 6.67%, achieving a better mAP and shorter computation times compared with the SSD and RetinaNet-GHM. Zhao et al. [17] developed a YOLOv5-based defect detection model for steel surface defects, named RDD-YOLO. Numerous experimental results demonstrate that RDD-YOLO achieves a precision of 81.1% mAP and 75.2% mAP on the NEU-DET and GC10-DET datasets, respectively, outperforming other leading models.
These single-stage detection algorithms simplify the detection process and significantly enhance the detection speed while maintaining high precision. However, the Single Shot MultiBox Detector (SSD) struggles with detecting small targets due to the loss of detailed information in the high-level feature map. Additionally, RetinaNet employs a large number of anchor boxes during the feature-extraction phase, which increases the computational effort and prolongs the training time. Consequently, it is evident that these two algorithms are not well suited for industrial applications that require real-time processing. In contrast, YOLO is renowned for its rapid processing speed and ease of deployment across various platforms. Although YOLO initially lagged in precision, subsequent iterations of the algorithm have enabled it to achieve precision levels comparable to those of two-stage detectors when detecting small targets. In summary, the YOLO family of models strikes a better balance between detection precision and speed, thereby garnering increased attention during the development of detection networks.
However, in actual industrial environments, the presence of similar defects and micro-defects in aluminum profile materials limits the detection precision and generalization performance of the YOLO model. Scholars, both domestically and internationally, are actively exploring this issue. Zheng et al. [18] introduced MD-YOLO, a surface-defect detection model based on YOLOv5, which achieved an mAP of 98.3% on the BAT-DET dataset. However, the model incorporates a multi-channel fusion module (MCF), resulting in a significant increase in the dimensionality and computational complexity of the feature vectors. Additionally, the model is highly dependent on the quality and characteristics of the input data, exhibiting insufficient generalization capability on new and diverse datasets, which limits its applicability. In contrast, Lu et al. [19] proposed a WSS-YOLO model based on YOLOv8 for detecting defects in industrial steel. This model reduces the computational complexity and the number of parameters while maintaining precision. The model introduces the GSConv and VOV-GSCSP modules in the neck network, which makes it overly sensitive to certain features while neglecting others. Furthermore, these modules necessitate additional debugging and optimization to ensure compatibility with other network components, which somewhat diminishes the benefit of their reduced computational requirements. Wang et al. [20] developed an enhanced detection model called Yolo-MSAPF to tackle the issue of low precision in the inspection of welded surfaces. This model significantly reduces the leakage rate of eight types of defect images. However, it demands substantial hardware resources and poses challenges for further debugging and optimization, thereby limiting its applicability.
In summary, while existing studies have confirmed the superiority and feasibility of the YOLO series of models for surface-defect detection, these models still encounter challenges. Specifically, they struggle to balance precision and computational efficiency in complex inspection environments and face difficulties in deployment due to their intricate model structures. To address these issues, we propose an advanced BBW YOLO model. The method presented in this study offers several significant advantages over prior approaches:
(1) Innovations in data enhancement strategies: We utilized StyleGAN2-ADA to generate a diverse array of high-quality images, thereby augmenting the original dataset. This approach enhances the generalization capability of the machine learning model and mitigates the risk of overfitting. StyleGAN2-ADA also improves the model’s ability to adapt to samples with unseen or rare aluminum alloy surface defects while simultaneously increasing the detection precision. Furthermore, this method conserves the time and resources typically required to collect substantial amounts of image data.
(2) Innovation in the channel information fusion mechanism: This study introduces the Bidirectional Feature Pyramid Network (BiFPN), an innovative fusion mechanism. BiFPN optimizes the information flow paths in both top–down and bottom–up directions through a bidirectional fusion strategy. As a result, detection precision is significantly enhanced while computational efficiency is maintained.
(3) Introduction of the dynamic sparse-attention mechanism: This study introduces BiFormer, a dynamic sparse-attention mechanism that facilitates a more flexible allocation of computational resources and enhances content sensing through dynamic query-aware sparsity. BiFormer offers robust support for addressing complex surface defects.
(4) Optimization of the bounding box regression loss function: WIoU v3 enhances the overall performance and generalization capability of the model through a unique dynamic non-monotonic mechanism and a gradient-gain assignment strategy. In particular, WIoU v3 can more accurately evaluate the position and shape matching of the target-detection frame, thereby effectively improving the model’s detection performance and speed while reducing the occurrence of missed and misdetected defects across different categories.
In summary, the BBW YOLO model proposed in this study not only advances the theoretical development of surface-defect detection technology but also offers an efficient and accurate solution for the practical application of surface-defect detection in aluminum profile materials.
The remainder of this study is organized as follows: Section 2 provides a detailed description of the research principles and the general architecture of the BBW YOLO model for detecting surface defects. Section 3 outlines the experimental setup, dataset construction, experimental results, and analyses. Finally, Section 4 summarizes the contributions of this study and offers an outlook for the future.
2. Methodology
2.1. Channel Information Fusion Mechanisms
The Bidirectional Feature Pyramid Network (BiFPN) [21] utilizes bidirectional fusion to reconstruct top–down and bottom–up paths. BiFPN can assign varying weights to scale features and conduct cross-scale weight suppression or feature expression to enhance feature fusion, thereby enhancing the target-detection performance. Compared with other feature-fusion networks, BiFPN has the following characteristics: First, to simplify the bi-directional network structure, nodes that contribute less to fusing different features in the feature network are removed. Second, an additional connection is established between the original input node and the output node to integrate more features without significantly increasing the cost. Finally, the top–down and bottom–up bi-directional paths are considered to be a feature-network layer, and this layer is repeated several times to achieve higher-level feature fusion. The BiFPN structure is shown in Figure 1.
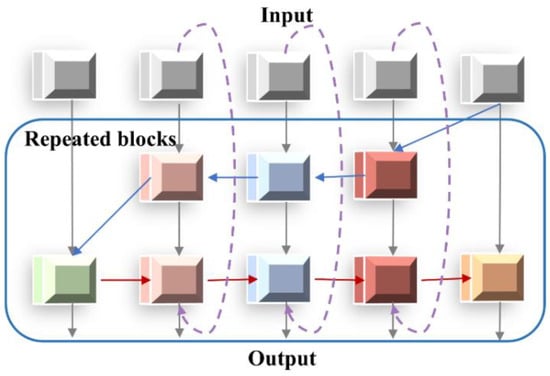
Figure 1.
BiFPN information fusion mechanism. The grey lines indicate the top-down passages of the different layers, and the red lines indicate the bottom-up pathways passing low-level features with location information. The blue line indicates the fusion of bypass information and input features given different weights. Purple dashed lines indicate new jump-connected pathways added to the input and output nodes in the same layer.
In the feature-fusion process, different input features have varying resolutions and contribute unequally to the output features. BiFPN utilizes a rapid normalized fusion module to adjust various feature weights. Due to the large number of multi-scale aluminum alloy crack targets collected under natural conditions, BiFPN can extract deep information from the crack targets and reduce the false positives and false negatives caused by the complex environment. The relationship between the input and output of BiFPN is defined as follows:
where is the learning weight corresponding to the input feature ; to ensure that , this needs to be followed by the application of Relu. To avoid numerical instability, an initial learning rate of was set. Similarly, each normalized weight has a value between 0 and 1. To further enhance efficiency, the feature-fusion stage utilizes deep separable convolution with batch normalization, and the activation operations are added after convolution.
2.2. Dynamic Sparse-Attention Mechanism
Aluminum profile material surfaces may develop a variety of easily overlooked and undetected cracks due to die design defects, improper extrusion parameters, mechanical damage during production, and other factors. The enhanced attention mechanism can focus the learning on crucial information and is extensively utilized, but it faces challenges due to high computational and memory demands. The dynamic sparse-attention mechanism BiFormer [22], on the other hand, is an efficient pyramidal network architecture that uses Bi-level Rounding Attention (BRA) as a core building block. BiFormer enables more flexible computational allocation and content awareness through dynamic query-aware sparsity. Therefore, BiFormer demonstrates good performance and high computational efficiency.
BiFormer’s four-layer pyramid network architecture is illustrated in Figure 2. The core idea of BiFormer is to process a two-dimensional input feature map through four stages of feature extraction to obtain feature layers of varying sizes. Specifically, the first stage involves overlapping patch embedding, and the subsequent three stages involve patch merging. Each stage utilizes N consecutive BiFormer modules to transform features. The BiFormer module consists of a 3 × 3 deep convolution, a BRA module, a normalization layer (LN), and a multilayer perceptron (MLP). Among these, BRA is the core module of BiFormer, and its specific process is divided into three parts:
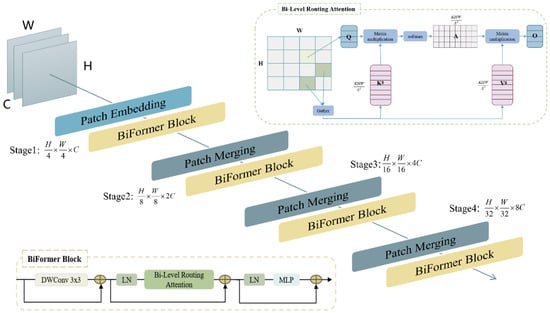
Figure 2.
BiFormer pyramid network architecture. The arrows indicate the direction of data propagation through the network, the forward feature propagation path from the input layer to the output layer.
Zoning and input projection calculations: The two-dimensional input feature map is first divided into non-overlapping regions, such that each region contains feature vectors. Then, the query, key, and value tensor is derived by linear mapping.
Inter-area routing calculations: The region-level query and key are first derived by averaging and in each region separately. Then, the adjacency matrix , which represents the degree of semantic relatedness of two regions, is obtained by the matrix multiplication of with the transpose . Next, the association graph is pruned by keeping only the most relevant connections for each region. Specifically, matrix sparsification is performed on to derive the path from the index moments . The ith row of contains the indicators of the most relevant region of the ith zone.
Inter-token attention computation: According to (2), the middle way consists of the index matrix , which performs the attention computation on the fine-grained region. The key and value tensor of the most relevant regions are first collected, and then attention is computed on the collected key and value tensor.
BiFormer enables multiple positions or channels to share the same weights. This strategy of parameter sharing reduces the number of parameters in the model, making it more lightweight.
2.3. Loss Function Optimization
The bounding-box-regression loss function is a crucial component of the target-detection loss function. A well-designed loss function will lead to a substantial enhancement in the performance of the target-detection model. YOLOv8 utilizes the CIoU loss function [23], as illustrated in Figure 3a. The aspect ratio of the CIoU loss function describes relative values, which could compromise the performance of model detection when the aspect ratio of the real frame closely resembles that of the predicted frame. The EIoU loss function [24] enables the penalty term to be directly applied to the prediction frame, thereby effectively enhancing the regression precision and convergence speed. However, the EIoU loss function does not fully exploit the potential of the non-monotonic focusing mechanism.
where is the corresponding position of the target frame , is the loss of the high-quality anchor frame, and represents the separation operation. and represent the centres of the prediction and real frames. , , and denote the width and height of the real and predicted boxes, respectively.
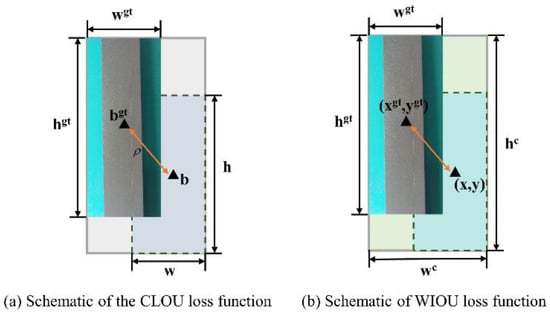
Figure 3.
Schematic diagram of the true and predicted frames. The example image with the broken area of aluminium profile material in the background is the real frame, and the light blue and light green under the dotted line are the predicted frames.
However, WIoU v1 does not introduce aspect ratios and does not eliminate factors that prevent convergence. For this purpose, the WIoU v3 loss function [25] will be used in this study, as illustrated in Figure 3b. The focusing mechanism is attached by constructing a gradient gain, a method that avoids large harmful gradients for lower-quality samples. WIoU v3 is constructed using and WIoU v1, as shown in the following equation:
where is the non-monotonic focusing coefficient, is the outlier, and is the gradient gain.
In summary, WIoU v3 effectively enhances the model’s performance in the target-detection task through its unique dynamic non-monotonic mechanism and gradient-gain allocation strategy. Meanwhile, WIoU v3 can pay more attention to ordinary-quality samples, which, in turn, improves the generalization ability and overall performance of the network model. This is especially advantageous for detecting surface defects in aluminum alloys. Therefore, WIoU v3 is used by default in YOLOv8 instead of the CIoU loss function.
2.4. Improved YOLOv8 Structure
The YOLOv8 model used in the detection of surface defects on actual aluminum profiles still has some limitations that can be improved. For example, the YOLOv8 model’s feature-fusion network is prone to feature information loss during sampling operations, so BiFPN and BiFormer are added. The loss function is optimized to account for the varying sizes of defects in the aluminum profile material and the complex distribution of pixels in the image. This can result in a significant deviation in the position of the prediction frame. The structure of the BBW YOLO model is shown in Figure 4.
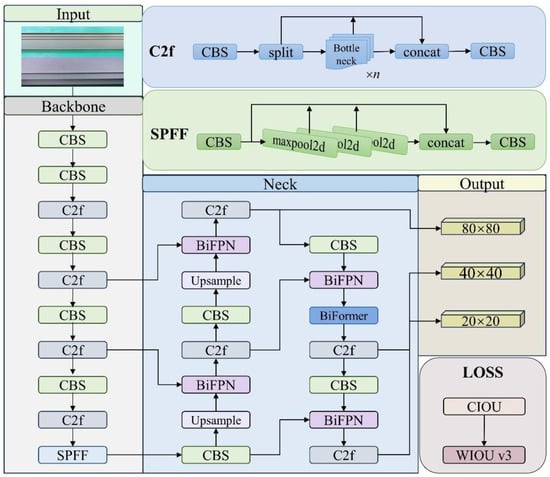
Figure 4.
BBW YOLO model structure.
The BBW YOLO model structure is divided into four parts: input, feature-extraction network, feature-fusion network, and output. The feature-extraction network follows the basic structure of CSPDarkNet53. The image input undergoes multiple convolutions, batch normalization, the SiLU activation function, and the C2f module. The image is finally fused with three scales of feature maps through the spatial pyramid-pooling module and then fed into the feature-fusion network. Among them, the C2f structure consists of convolutional channels spliced across layers and several residual modules to obtain richer gradient-flow information. In feature-fusion networks, the concatenate is replaced by BiFPN. While integrating multi-scale feature information, BiFPN can compensate for the loss of information resulting from enhancing multi-layer convolutions and enhance the model’s generalization ability. Finally, YOLOv8 replaces the coupled header detected by YOLOv7 with a decoupled header that separates the classification and detection headers. It outputs results at three different scales: large, medium, and small.
Corresponding to the model structure in Figure 4, the training and validation process of the BBW YOLO model is shown in Table 1. Initially, the training network can perform localization, classification, and confidence error analyses for detecting surface defects on aluminum profile materials. Second, the validation network can adjust the learning rate, update the training strategy, and optimize the model parameters. Finally, testing the network produces visualization results for recognition, localization, and classification to compare the model’s performance.

Table 1.
Model training and validation process.
2.5. StyleGAN2-ADA
Data expansion is a critical aspect in detection research. StyleGAN2 with Adaptive Discriminator Augmentation (ADA) [26] was used to generate a wide range of high-quality images. StyleGAN2-ADA efficiently extends the original dataset, enhances the generalization ability of the machine learning model, and reduces the risk of overfitting. This approach not only enhances the model’s capability to handle the stress of unseen or rare aluminum profile material samples but also boosts the detection precision while conserving time and resources that would be spent on collecting extensive image data. As a result, StyleGAN2-ADA was used to generate images of aluminum profile materials at a resolution of 640 pixels × 640 pixels.
The generator of StyleGAN2-ADA comprises a mapping network and a synthesis network, while the discriminator consists of a feature extractor and a classifier, as illustrated in Figure 5.
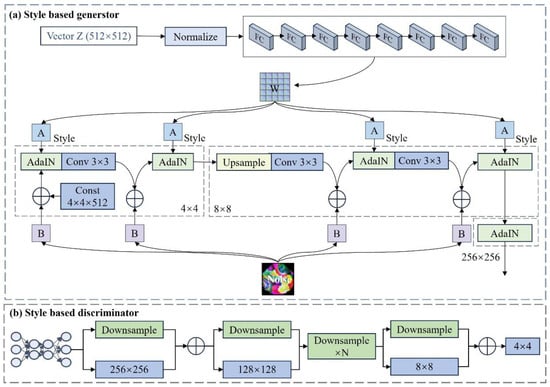
Figure 5.
Schematic diagram of the GAN structure. The arrows indicate the forward propagation in the generation and confrontation process.
Initially, a set of potential vectors, Z, following a Gaussian distribution is fed into a mapping network consisting of 8 fully connected (FC) layers, resulting in intermediate vectors of the same size W. These intermediate vectors W, which control various visual features, are then used to generate style-controlling vectors S through an affine transformation, A. The initial input dimensions for the synthetic network are 4 × 4 × 512, which include an upsampling layer, a convolutional layer, an Adaptive Instance Normalization Module (AdaIN), and a style control vector noise B.
The adaptive discriminator process in StyleGAN2-ADA begins by establishing a random probability for enhancement and then fine-tuning the enhancement value based on the presence of overfitting. This probabilistic decision allows for choosing whether to enhance the image, which involves adjustments such as to the rotation angle and changes in the range. The same enhancement method can be applied to both real and generated images. The generator (G) and discriminator (D) represent the network being trained. While StyleGAN2-ADA shares similarities with the regular StyleGAN2 in terms of its loss function and network architecture, the incorporation of ADA can improve the network stability and mitigate overfitting issues. Therefore, StyleGAN2-ADA was chosen to improve the data.
3. Experimental Analysis
3.1. Pre-Experimental Work
3.1.1. Data Collection and Dataset Construction
A diverse dataset enhances the model’s generalization and mitigates overfitting, leading to a more accurate representation of realistic scenarios for detecting surface defects in aluminum profiles. The original images in this study’s dataset were sourced from the Tenchi Aluminium Surface Defects dataset, which includes 1885 images, as well as from various aluminium manufacturers, contributing an additional 1531 images. This dataset encompasses different manufacturing processes and production batches, ensuring a diverse and representative collection of data. In total, the dataset comprises 3416 original images that depict 10 types of defects, including electrically nonconductive, scratching, edge-exposed, orange peel, base exposure, splashing, paint-bubbling, pitting, discoloration, and dirt inclusion. An example from the dataset is presented in Figure 6. Among the categories, defective sample data for base exposure represents the largest proportion, accounting for 15.6%. In contrast, the number of defective samples for paint-bubbling is the smallest, comprising only 4.8%. The remaining categories exhibit a similar distribution, each accounting for approximately 10% of the total sample size.

Figure 6.
Examples of the sample data.
The dataset must consider the effects of the production process, environmental factors, the age of use, and other relevant variables. Additionally, it should account for various defects that may appear on the surface of the aluminum profile material, as well as the impacts of image contours, shadows, and overlaps. To address these complexities, the dataset was enhanced using the StyleGAN2-ADA technique. With the expanded dataset, especially in the rare-defect category, the sample size was increased to 14,600 images. The raw images in the aluminum profile material dataset were manually annotated using LabelImg software to identify specific areas and types of defects. The annotations were saved in TXT format according to the YOLO standard for training purposes. Additionally, the training, validation, and test sets were allocated in a ratio of 8:1:1 [7,9,27,28,29]. In this way, a dataset for the detection of surface defects in aluminium profiles in YOLO format was developed. The experimental results before and after the StyleGAN2-ADA extension are presented in Table 2. As shown in Table 2, the overall precision, mAP@0.5 and mAP@0.5:0.95 of each model improved following the dataset expansion. Notably, the enhanced BBW YOLO model exhibited the most significant improvements, with increases of 15.95% in precision and 9.25% in mAP@0.5:0.95, respectively.
Table 2.
Comparison of the different models before and after data enhancement.
The data extension significantly enhances the model’s generalization ability and performs more consistently when handling scenes with complex backgrounds or lighting variations. By increasing the sample size of rare-defect categories, the model effectively improves the detection precision in these areas. Furthermore, the extended dataset mitigates overfitting, resulting in more robust performance on the test set.
3.1.2. Experimental Platform and Parameters
The experiment was conducted using a Win10 operating system with an Intel Core i9-10900k@3.7GHz CPU (Santa Clara, CA, USA) and an NVIDIA GeForce RTX 4090 GPU, 24564MiB (Santa Clara, CA, USA). We also utilized the pytorch 2.0.1 deep learning framework, Python version 3.9, OpenCV2, and Pycharm code IDE, using a CUDA11.8 accelerated GPU.
The optimal hyperparameter settings obtained after several training tunings were as follows: an initial learning rate of 0.1, a cosine annealing hyperparameter of 0.1, a weight decay coefficient of 0.0005, and a momentum parameter of 0.937 in the gradient descent with momentum. The training process consisted of 500 iterations, with a batch size of 16, and the early stopping mechanism was set to 50. The stochastic gradient descent (SGD) strategy was used for optimizing the network training.
3.1.3. Evaluation Indicators
In order to improve the measurement of the lightweightness, precision, and real-time performance of aluminum profile surface-defect detection, this study selects a variety of indicators to evaluate and analyze this target-detection model. In the context of model lightweighting, this is primarily assessed by the number of parameters, floating-point operations (FLOPs), training duration, model size, and GPU utilization.
In terms of model precision, Precision (P), Recall (R), mean average precision (mAP), and reconciled mean (F1) are mainly used as evaluation indices. In terms of the real-time monitoring speed of the model, this is measured by the number of image or video frames processed per second (frames per second; FPS) in real-time.
3.2. Performance Comparison of Different Models
To further validate the performance of the BBW YOLO model, we conducted comparative experiments with various models from the YOLO series (YOLOv3, YOLOv5, YOLOv6, YOLOv7, and YOLOv9), as well as RT-DETR models and other enhanced YOLO models referenced in the literature. Throughout these experiments, we ensured that the experimental platform and parameters remained consistent. The experimental results are presented in Table 3.
Table 3.
Comparison of different models.
As depicted in Table 3, the YOLOv3 model network consists of more layers and demands a significant number of parameters to achieve high precision. The YOLOv3 model is computationally intensive and lacks real-time performance, which makes it challenging to deploy on mobile devices. On the contrary, the YOLOv6 model has the least number of network layers and the fastest real-time detection speed, but it lacks an advantage in overall performance, such as in precision. The YOLOv8 model has the least number of parameters, floating-point operations, and model volume. YOLOv8 model training consumes the shortest time and has a real-time detection speed of 201.3 f/s. The lightweight nature of the YOLOv8 model sets the foundation for its deployment in hardware devices with limited computing resources. The enhanced BBW YOLO model achieves a precision of 87.51%, which is approximately 10.09 percentage points higher than the least accurate YOLOv9 model. Compared with the RT-DETR model, the recall rate of the improved BBW YOLO model is approximately 13.04 percentage points higher, and the mAP@0.5 is approximately 16.63 percentage points higher. The FPS of the BBW YOLO model is 91 points higher than that of the original YOLOv8 model. This result indicates that BBW YOLO is able to provide faster processing speed in real-time target-detection tasks. Meanwhile, in comparison with the improved RDD-YOLO model [15], the BBW YOLO model enhances precision by 7.24% and increases the real-time detection speed by 128.9 f/s while also reducing the model size by 2.2 MB. Furthermore, the BBW YOLO model demonstrates performance comparable to that of the WSS-YOLO model [17] in terms of precision and other metrics. Notably, the BBW YOLO model significantly decreases the number of parameters, the count of floating-point operations, and the overall model size. In summary, the proposed BBW YOLO model can balance detection precision and speed, achieving the best overall performance in detecting surface defects on aluminum profiles.
3.3. Performance Comparison of Different Defect Types
To clarify the detection capabilities of the models before and after improvements across various defect types, comparative tests were conducted. Table 4 provides a detailed performance analysis of the model on different defect types, comparing the existing YOLOv8 model with the BBW YOLO proposed in this study. A consistent experimental platform and consistent parameters were maintained throughout the experiment. As shown in Table 4, the BBW YOLO model demonstrates higher precision and precision for most defect types, particularly in detecting edge exposure, orange peel, base exposure, and discoloration. As a whole, for all defect types, the enhanced model increases the precision and mAP@0.5:0.95 by 5% and 4.7%, respectively, compared with the original model. In summary, the BBW YOLO model proposed in this study effectively enhances the detection capabilities for various types of surface defects on aluminum profiles in most cases.
Table 4.
Comparison of model performance for different types of defects.
In the defect detection dataset, substrate-exposure defects constitute the largest proportion of samples, accounting for 15.6% of the total dataset, while paint-bubble defects are the least represented, comprising only 4.8%. The remaining defect classes each represent approximately 10% of the total samples. The baseline BBW YOLO model achieved an mAP@0.5:0.95 of 72.3% across all defect classes. After applying StyleGAN2 ADA for data augmentation, the enhanced BBW YOLO model exhibited the most significant improvements, with increases of 9.25% in mAP@0.5:0.95. This improvement was observed across all defect classes, with specific gains of 8.6% for base-exposure defects and 13.9% for paint-bubble defects. These results highlight the efficacy of the proposed augmentation strategy in improving detection performance.
3.4. Ablation Experiment
In order to verify the optimization effect of each module in detecting surface defects on aluminum profiles, an ablation test was designed based on YOLOv8. Separate BiFPN, BiFormer, and WIoU v3 modules were added to Model 1, Model 2, and Model 3, respectively. As shown in Table 5, the precision of Model 1 with the BiFPN model for feature fusion reached 83.84% compared with the original algorithmic model. BiFPN can better achieve the fusion of high-level semantic features and shallow detailed features of aluminum profile surface defects. With the integration of the BiFormer module into Model 2, the detection precision was significantly enhanced. The precision rate and recall rate of Model 2 increased by 3.3 and 2.68 percentage points, respectively, while the mAP@0.5:0.95 effectively improved by 7.86 percentage points. The recall of Model 3 with the WIoU v3 replacement loss function was 78.19%. At the expense of precision, Model 3 had the highest detection speed of 300.2 f/s. Optimizing the loss function reduces the penalty term, which, in turn, decreases the model complexity. This improvement enhances the real-time detection speed of the model. Model 4 incorporates BiFPN and BiFormer, Model 5 integrates BiFPN and WIoU v3, and Model 6 combines BiFormer and WIoU v3. It can be seen that the proposed BBW YOLO model demonstrates the best overall performance when comparing Model 4, Model 5, and Model 6. The BBW YOLO model has the highest precision and recall, of 87.51% and 75.24%, respectively.
Table 5.
Comparison of results of ablation experiments.
3.5. Comparison of Different Models of Attention Mechanisms
In order to verify the effectiveness of the BiFormer mechanism, we replaced the Bi-FPN mechanism and optimized the WIoU v3 loss function. Subsequently, we added the SE, CBAM, CA, ECA, and BiFormer attention mechanisms for comparative experiments. The experimental results are shown in Table 6.
Table 6.
Comparison of experimental results with different attention mechanisms added.
As can be seen from the table, the precision of the models with the addition of other attentional mechanisms all reaches 80%, while the improved BBW YOLO model achieves a precision as high as 87.51%. The recall of this model surpasses that of the model with the lowest additional classification precision by approximately 2.33 percentage points. The original YOLOv8 model failed to detect the surface defect on the aluminum profile in the center of the image. The model with the additional ECA attention mechanism could only concentrate on a few areas of certain aluminum profiles, while other models with various attention mechanisms were able to focus on surface defects as well as a portion of the background. The BBW YOLO model proposed in this study can focus on the critical features of aluminum profile surface defects.
3.6. Model Performance
3.6.1. Model Lightweight Analysis
Lightweighting the aluminum profile material surface-defect inspection model can increase the inspection speed and reduce the hardware requirements, thereby enhancing its performance and flexibility in real-time inspection and deployment applications. Therefore, lightweight models are important for enhancing the detection of surface defects in aluminum profile materials.
In order to verify the lightweight performance of the BBW YOLO aluminum profile surface-defect detection model proposed in this study, we compared its performance with that of YOLOv5, YOLOv6, YOLOv7, YOLOv8, YOLOv9, and the RT-DETR algorithm models. The results are shown in Figure 7.
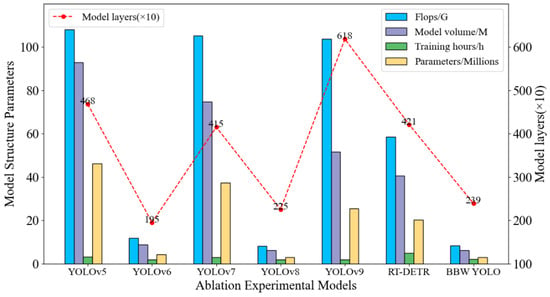
Figure 7.
Comparison of model lightweighting.
As shown in Figure 7, the BBW YOLO model has a smaller model size and the smallest number of network layers. The BBW YOLO model has successfully reduced its parameters and floating-point operations, resulting in a compressed model volume. In other words, the BBW YOLO model is simple in structure, requires minimal computation, and consumes fewer hardware resources, offering clear lightweight advantages.
3.6.2. Precision and Recall Analysis
The IoU parameter represents the ratio of intersection to union between the ground truth and the bounding box. During the variation of IoU thresholds from 0 to 1, each threshold corresponds to the precision and recall values, respectively. An R-P curve is generated with R as the horizontal coordinate and P as the vertical coordinate. The area under the curve can be used to comprehensively assess the reliability of the model. The larger the area below the line of the R-P curve, the more reliable the model and the higher the average precision. A comparison of the R-P curves of the BBW YOLO model and the YOLOv8 model is shown in Figure 8.
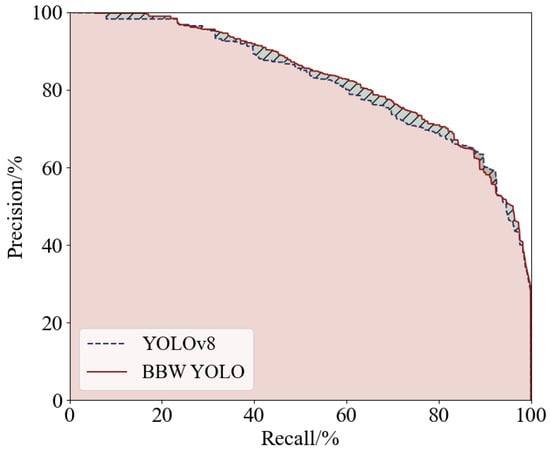
Figure 8.
Comparison of R-P curves. The pink filled area is the area below the R-P curve line of the YOLOv8 algorithm, and the shaded area is the area where the BBW YOLO algorithm has an advantage in the R-P curve.
As shown in Figure 8, the area under the curve of the R-P curve for the BBW YOLO algorithm is significantly larger than that of the original YOLOv8 algorithm. Therefore, the average detection precision of the BBW YOLO algorithm is also higher than that of the YOLOv8 algorithm. This demonstrates that the BBW YOLO algorithm exhibits superior monitoring performance and reliability when detecting surface defects on aluminum profiles.
3.6.3. Real-Time Performance Analysis
In real-time monitoring of surface defects on aluminum profile stock, the performance of the model is evaluated based on the FPS. Typically, real-time monitoring performance requires detection efficiencies of more than 30 frames per second. For the real-time monitoring of defects, the best model derived from the training process was utilized, and the first 33 images from the test set were selected for the real-time performance monitoring. The real-time performance comparison is shown in Figure 9.
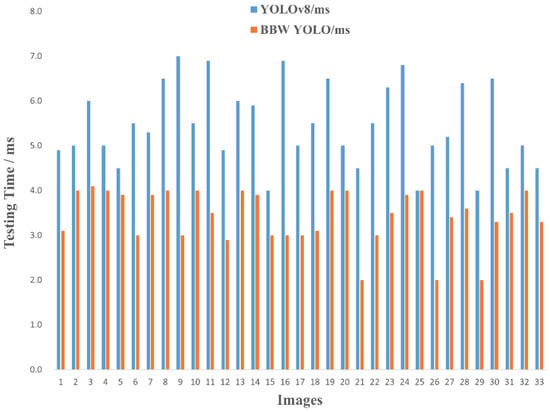
Figure 9.
Comparison chart of real-time performance testing.
BBW YOLO achieves an FPS value of 292.3, while YOLOv8 reaches 201.3 f/s. Thus, compared with YOLOv8, BBW YOLO offers a 91% increase in real-time detection speed. Figure 9 shows that the BBW YOLO algorithm monitors each frame within the range of 2 ms to 5 ms, with the monitoring time for 8 images stabilizing at 3 ms. The YOLOv8 algorithm processes each frame in just 4 ms~67 ms, and the monitoring time for 10 images stabilizes at 5 s. Therefore, the enhanced BBW YOLO algorithm effectively improves the detection speed of the network. The BBW YOLO algorithm enables the monitoring of aluminum profile defects in complex backgrounds.
3.6.4. Comparison of Model Visualization Detection
In order to visually compare the detection effect of each model, YOLOv8 and the enhanced BBW YOLO were utilized to detect surface defects on aluminum profile material. The results are presented in Figure 10. For the discoloration defects on the aluminum profile surface, as depicted in Figure 10a, YOLOv8 indicates a confidence level of 0.80, whereas the improved BBW YOLO algorithm shows a confidence level of 0.92. In contrast, the optimized loss function of BBW YOLO detection is relatively ideal. It can effectively reduce false detections while meeting real-time requirements. As shown in Figure 10b,c for edge-exposed defects and base-exposure defects, these are detected by the BBW YOLO model with higher confidence compared with the YOLOv8 model. In conclusion, the BBW YOLO algorithm exhibits higher recall and confidence levels. Meanwhile, the BBW YOLO algorithm incorporates the BiFPN algorithm with an attention mechanism, enhancing the feature screening of defects and reducing leakage detection.

Figure 10.
Visualization results of the model.
4. Conclusions
Our aim was to address the issue of quality degradation caused by surface defects in aluminum profile materials, which pose a threat to industrial production as well as product reliability and safety. In this study, a novel neural network, the BBW YOLO model, was developed using computer vision techniques and deep learning methods. The model introduces BiFPN with BiFormer in the feature-fusion network, which enhances feature extraction and improves the precision and detection speed of the model. The model loss function utilizes WIoU v3, which enhances the model’s localization ability in surface-defect detection. Comparative experimental results show that the BBW YOLO model has high detection precision in identifying surface defects. The BBW YOLO model has a faster detection speed and is lighter in weight compared with the frontier model. Therefore, the model in this study enhances the precision and speed of surface-defect detection in aluminum profiles. We aim for our work to offer innovative ideas for future defect detection in aluminum profiles.
Author Contributions
Conceptualization, Z.Y. and H.L.; methodology, Z.Y.; software, Z.Y.; validation, Z.Y., H.L. and B.Q.; formal analysis, Z.Y. and G.S.; investigation, Z.Y.; resources, H.L.; data curation, Z.Y.; writing—original draft preparation, Z.Y.; writing—review and editing, H.L.; visualization, B.Q.; supervision, H.L.; project administration, H.L.; funding acquisition, H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key R&D Program of China (Grant No. 2023YFB3710801), the National Natural Science Foundation of China (Grant No. 52105382), and the Class III Peak Discipline of Shanghai-Materials Science and Engineering (High-Energy Beam Intelligent Processing and Green Manufacturing).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon request.
Acknowledgments
The authors sincerely thank the team for their guidance. The authors sincerely express their thanks to the reviewers for taking time out of their busy schedules to review the paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Tang, Y.; Liu, R.; Wang, S. YOLO-SUMAS: Improved Printed Circuit Board Defect Detection and Identification Research Based on YOLOv8. Micromachines 2025, 16, 509. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Lyu, Q.; Zeng, H.; Ling, Z.; Zhai, Z.; Lyu, H.; Riffat, S.; Chen, B.; Wang, W. A Defect Detection Algorithm for Optoelectronic Detectors Utilizing GLV-YOLO. Micromachines 2025, 16, 267. [Google Scholar] [CrossRef] [PubMed]
- Saravanan, C. Color image to grayscale image conversion. In Proceedings of the Second International Conference on Computer Engineering and Applications, Bali, Indonesia, 19–21 March 2010; IEEE: New York, NY, USA, 2010; Volume 2, pp. 196–199. [Google Scholar] [CrossRef]
- Yan, Z.; Zhang, B.; Wang, D. An FPGA-Based YOLOv5 Accelerator for Real-Time Industrial Vision Applications. Micromachines 2024, 15, 1164. [Google Scholar] [CrossRef] [PubMed]
- Tsanakas, J.A.; Ha, L.D.; Al Shakarchi, F. Fault diagnosis of photovoltaic modules through image processing and Canny edge detection on field thermographic measurements. Int. J. Sustain. Energy 2015, 34, 351–372. [Google Scholar] [CrossRef]
- Zhu, S.; Zhang, R.; An, Y.; Liu, H. An image segmentation algorithm in image processing based on threshold segmentation. In Proceedings of the Third International IEEE Conference on Signal-Image Technologies and Internet-Based System, Shanghai, China, 16–19 December 2007; IEEE: New York, NY, USA, 2007; pp. 673–678. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Song, Z.; Zou, S.; Zhou, W.; Huang, Y.; Shao, L.; Yuan, J.; Gou, X.; Jin, W.; Wang, Z.; Chen, X.; et al. Clinically applicable histopathological diagnosis system for gastric cancer detection using deep learning. Nat. Commun. 2020, 11, 4294. [Google Scholar] [CrossRef] [PubMed]
- Kabir, H.; Wu, J.; Dahal, S.; Joo, T.; Garg, N. Automated estimation of cementitious sorptivity via computer vision. Nat. Commun. 2024, 15, 9935. [Google Scholar] [CrossRef] [PubMed]
- Wei, J.; Liang, J.; Song, J.; Zhou, P. YOLO-PBESW: A Lightweight Deep Learning Model for the Efficient Identification of Indomethacin Crystal Morphologies in Microfluidic Droplets. Micromachines 2024, 15, 1136. [Google Scholar] [CrossRef] [PubMed]
- Li, X.L.; Yang, Y.H.; Chu, M.X. Steel plate surface defect detection based on improved RetinaNet-GHM algorithm. Electron. Meas. Technol. 2023, 46, 100–105. [Google Scholar] [CrossRef]
- Wang, G.Y.; Yu, N.G. SSD-Faster Net: A hybrid network for industrial defect inspection. arXiv 2022, arXiv:2207.00589. [Google Scholar] [CrossRef]
- Wang, G.Q.; Zhang, X.; Li, Z.; Chen, J. A high-precision and lightweight detector based on a graph convolution network for strip surface defect detection. Adv. Eng. Inform. 2024, 59, 102280. [Google Scholar] [CrossRef]
- Zhao, C.; Shu, X.; Yan, X.; Liu, Y. RDD-YOLO: A modified YOLO for detection of steel surface defects. Measurement 2023, 214, 112776. [Google Scholar] [CrossRef]
- Zheng, H.; Liu, Y.; Chen, J.; Wang, Z. MD-YOLO: Surface defect detector for industrial complex environments. Opt. Lasers Eng. 2024, 178, 108170. [Google Scholar] [CrossRef]
- Lu, M.; Liu, Y.; Wang, Z.; Chen, J. WSS-YOLO: An improved industrial defect detection network for steel surface defects. Measurement 2024, 236, 115060. [Google Scholar] [CrossRef]
- Wang, G.Q.; Li, Z.; Zhang, X.; Chen, J. YOLO-MSAPF: Multi-scale alignment fusion with parallel feature filtering model for high precision weld defect detection. IEEE Trans. Instrum. Meas. 2023, 72, 5022914. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: New York, NY, USA, 2020; pp. 10781–10790. [Google Scholar] [CrossRef]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R. BiFormer: Vision transformer with bi-level routing attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; IEEE: New York, NY, USA, 2023; pp. 10323–10333. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; AAAI Press: Palo Alto, CA, USA, 2020; Volume 34, pp. 12993–13000. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IoU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar] [CrossRef]
- Woodland, M.; Uzun, D.; Johnston, P.; Tan, K.L.; Giger, M.L. Evaluating the performance of StyleGAN2-ADA on medical images. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Strasbourg, France, 27 September 2022; Springer: Cham, Switzerland, 2022; pp. 44–53. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Zhang, Y. A comprehensive survey on regularization strategies in machine learning. Inf. Fusion 2022, 80, 146–166. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).