
Data Shepherding in Nanotechnology. The Initiation



Abstract

1. Introduction
- -
- the handling of research data during and after the end of the project;
- -
- what data will be collected, processed and/or generated;
- -
- which methodology and standards will be applied;
- -
- whether data will be shared/made open access;
- -
- how data will be curated and preserved (including after the end of the project).
- -
- -
- Machine learning (ML) FAIRification supporting the end-to-end reproducibility of ML pipelines. Samuel et al. [17] investigated which factors beyond the availability of source code and datasets affect the reproducibility of ML experiments and proposed ways to incorporate FAIR data practices into ML workflows;
- -
- Evaluation of FAIRness [18]. It is often useful to determine to what extent a resource (data or metadata) adheres to the FAIR principles. A number of different initiatives are currently focused on defining frameworks, approaches and criteria for assessing FAIRness. Thompson et al. [19] captures a variety of initiatives, as well as a number of available online evaluation tools.
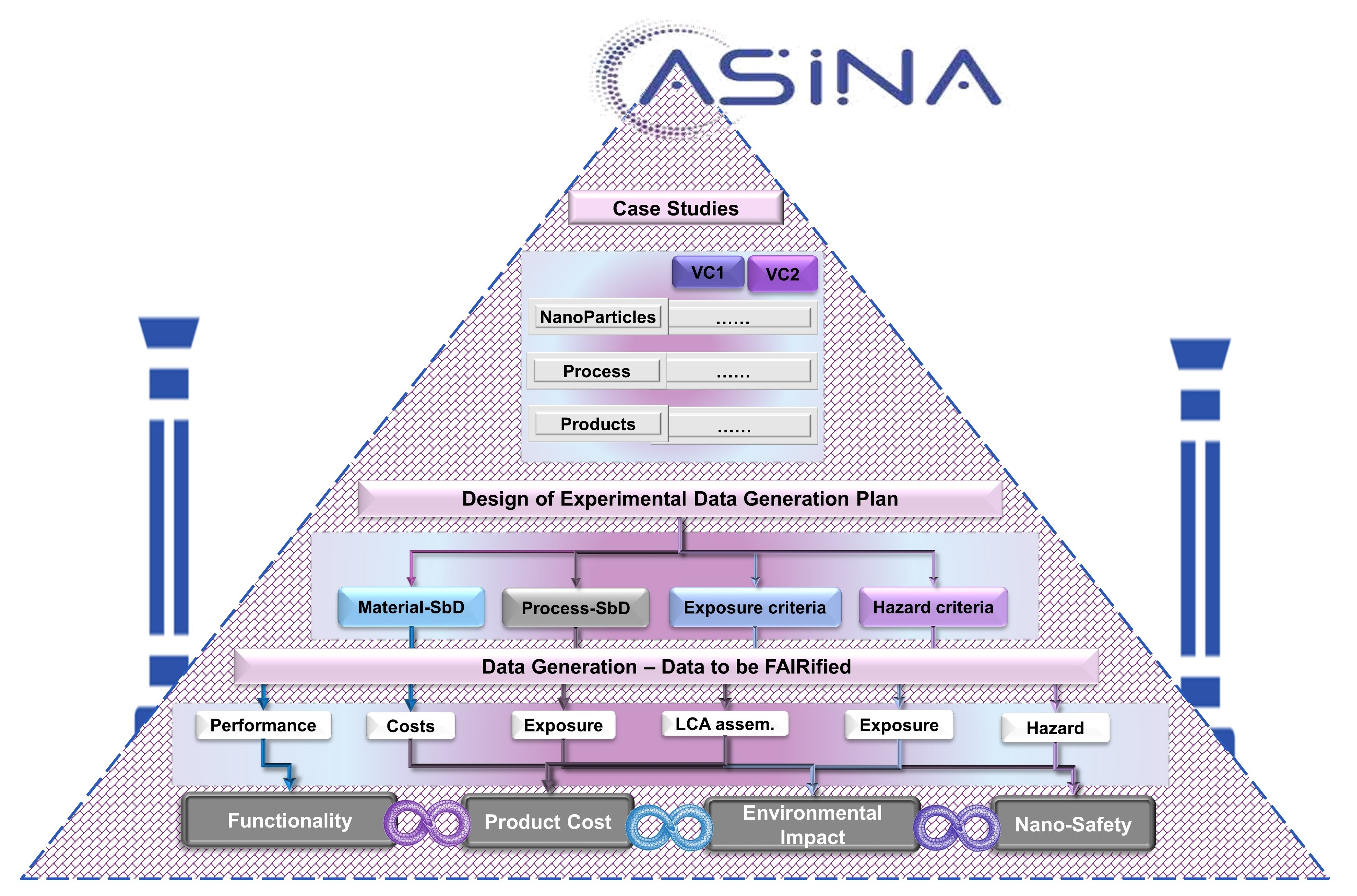
2. Materials and Methods
3. Results
3.1. Cases Identification
- -
- data from the characterization for the identification of physicochemical (p-chem) characteristics, e.g., particle size and surface properties, chemical substance information;
- -
- data from the assessment of the functionality, i.e., antibacterial, antimicrobial, photocatalytic or antioxidant capacity and of the cost-effectiveness (e.g., costing analysis and financial parameters);
- -
- exposure assessment for workers, consumers and the environment, e.g., release, fate processes, exposure routes (life cycle assessment data);
- -
- assessment of biokinetics such as bio-durability, uptake and dissolution rates, sedimentation, and impaction in the airways or airway bifurcations (internal fate estimation data coupled with modeling);
- -
- human nanotoxicological data through in vitro assays (such as inhalation, intestinal, skin cell cultures), alternative in vivo toxicity (zebrafish), Adverse Outcome Pathways framework;
- -
- eco-nanotoxicological data (Enchytraeids, Collembola, C. elegans, Daphnia magna, etc., species sensitivity distribution);
- -
- field monitoring campaigns for exposure assessment in pilot plants, using online particle sizers and diffusion chargers providing time-series data that enable exposure modeling;
- -
- Life-Cycle Inventory (LCI) of material, energy, environmental release inputs for each production unit and assessment of the resulting environmental impacts.
3.2. Initial Data Description—Questionnaire
- Data identification: This part includes dataset description, which is a general description of forthcoming data (e.g., characterization, functionality analysis, cost effectiveness, life cycle analysis, fate in relevant matrices, toxicological data, exposure data, etc.). This will allow the generated data to be captured in different categories, harmonized and integrated. The source concerns whether the data are to be experimentally generated or simulated and the location of the analysis (e.g., partners lab or the software tool).
- Partner’s activities and responsibilities: This part includes personal information of the partners in charge of data collection/analysis and storage. In addition, related WPs and task(s) need to be captured in case communication or data integration is required.
- Expected input variables: For each analysis, some information will be needed in advance. For example, when in toxicological studies information on p-chem properties is required, data from particle characterization are necessary, and the template needs to be circulated among different/related partners. This part reveals which specific partners are related and how data are associated among WPs and/or tasks. It allows the capturing and exchange of data to be performed in a controlled manner while tracking additional contributions.
- Expected outcomes: This part is outcome-specific. Descriptions of the exact outcomes that are going to be produced are needed for the forthcoming integration of the pillars. Each WP/task, however, is expected to have several outcomes (for example, several toxicological assays will be performed for one NP). A description of each case should be recorded.
- Standards: Detailed description of the methods/protocols that will be followed to generate the data. This information will enable the data curation process and increase the FAIRness of data. The partners should describe which standards are applied for each case, and at this stage the data capturing structure is defined, informing partners and managers who might not be familiar with all the protocol applicability domains.
3.3. Collaboration with External FAIR Initiatives—NanoCommons
3.4. Data Descriptors—Preliminary Template
3.5. Template’s Completion
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Romanos, N.; Kalogerini, M.; Koumoulos, E.; Morozinis, A.; Sebastiani, M.; Charitidis, C. Innovative Data Management in advanced characterization: Implications for materials design. Mater. Today Commun. 2019, 20, 100541. [Google Scholar] [CrossRef]
- Van Vlijmen, H.; Mons, A.; Waalkens, A.; Franke, W.; Baak, A.; Ruiter, G.; Kirkpatrick, C.; da Silva Santo, L.O.B.; Meerman, B.; Jellema, R.; et al. The Need of Industry to Go FAIR. Data Intell. 2020, 2, 276–284. [Google Scholar] [CrossRef]
- Wise, J.; de Barron, A.G.; Splendiani, A.; Balali-Mood, B.; Vasant, D.; Little, E.; Mellino, G.; Harrow, I.; Smith, I.; Taubert, J.; et al. Implementation and relevance of FAIR data principles in biopharmaceutical R&D. Drug Discov. Today 2019, 24, 933–938. [Google Scholar] [PubMed]
- Boeckhout, M.; Zielhuis, G.A.; Bredenoord, A.L. The FAIR guiding principles for data stewardship: Fair enough? Eur. J. Hum. Genet. 2018, 26, 931–936. [Google Scholar] [CrossRef] [PubMed]
- Papadiamantis, A.G.; Klaessig, F.C.; Exner, T.E.; Hofer, S.; Hofstaetter, N.; Himly, M.; Williams, M.A.; Doganis, P.; Hoover, M.D.; Afantitis, A.; et al. Metadata Stewardship in Nanosafety Research: Community-Driven Organisation of Metadata Schemas to Support. FAIR Nanoscience Data. Nanomaterials 2020, 10, 2033. [Google Scholar] [CrossRef] [PubMed]
- European Commission. H2020 Programme: Guidelines on FAIR Data Management in Horizon 2020; Directorate-General for Research & Innovation: Brussels, Belgium, 2016. [Google Scholar]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed]
- Jacobsen, A.; Azevedo, R.D.M.; Juty, N.; Batista, D.; Coles, S.; Cornet, R.; Courtot, M.; Crosas, M.; Dumontier, M.; Evelo, C.T.; et al. FAIR Principles: Interpretations and Implementation Considerations. Data Intell. 2020, 2, 10–29. [Google Scholar] [CrossRef]
- Bloemers, M.; Montesanti, A. The FAIR Funding Model.: Providing a Framework for Research Funders to Drive the Transition toward FAIR Data Management and Stewardship Practices. Data Intell. 2020, 2, 171–180. [Google Scholar] [CrossRef]
- Furxhi, I.; Murphy, F.; Mullins, M.; Arvanitis, A.; Poland, C.A. Practices and Trends of Machine Learning Application in Nanotoxicology. Nanomaterials 2020, 10, 116. [Google Scholar] [CrossRef] [PubMed]
- Furxhi, I.; Murphy, F.; Mullins, M.; Arvanitis, A.; Poland, C.A. Nanotoxicology data for in silico tools: A literature review. Nanotoxicology 2020, 14, 612–637. [Google Scholar] [CrossRef]
- Powers, C.M.; Mills, K.; Morris, S.A.; Klaessig, F.; Gaheen, S.; Lewinski, N.; Hendren, C.O. Nanocuration workflows: Establishing best practices for identifying, inputting, and sharing data to inform decisions on nanomaterials. Beilstein J. Nanotechnol. 2015, 6, 1860–1871. [Google Scholar] [CrossRef]
- Jacob, D.; David, R.; Aubin, S.; Gibon, Y. Making experimental data tables in the life sciences more FAIR: A pragmatic approach. GigaScience 2020, 9. [Google Scholar] [CrossRef] [PubMed]
- Galhotra, S.; Shanmugam, K.; Sattigeri, P.; Varshney, K.R. Fair Data Integration. arXiv 2020, arXiv:abs/2006.06053. Available online: https://arxiv.org/abs/2006.06053 (accessed on 1 May 2021).
- Rashid, S.M.; Chastain, K.; Stingone, J.A.; McGuinness, D.L.; McCusker, J.P. The Semantic Data Dictionary Approach to Data Annotation & Integration. In Proceedings of the SemSci@ISWC, Vienna, Austria, 21–25 October 2017. [Google Scholar]
- Karcher, S.; Willighagen, E.; Rumble, J.; Ehrhart, F.; Evelo, C.T.; Fritts, M.; Gaheen, S.; Harper, S.L.; Hoover, M.D. Integration among databases and data sets to support productive nanotechnology: Challenges and recommendations. NanoImpact 2018, 9, 85–101. [Google Scholar] [CrossRef] [PubMed]
- Samuel, S.; Löffler, F.; König-Ries, B. Machine Learning Pipelines: Provenance, Reproducibility and FAIR Data Principles. arXiv 2020, arXiv:abs/2006.12117. Available online: https://arxiv.org/abs/2006.12117 (accessed on 1 May 2021).
- Wilkinson, M.D.; Sansone, S.-A.; Schultes, E.; Doorn, P.; da Silva Santos, L.O.B.; Dumontier, M. A design framework and exemplar metrics for FAIRness. Sci. Data 2018, 5, 180118. [Google Scholar] [CrossRef] [PubMed]
- Thompson, M.; Burger, K.; Kaliyaperumal, R.; Roos, M.; da Silva Santos, L.O.B. Making FAIR Easy with FAIR Tools: From Creolization to Convergence. Data Intell. 2020, 2, 87–95. [Google Scholar] [CrossRef]
- Pendleton, I.M.; Cattabriga, G.; Li, Z.; Najeeb, M.A.; Friedler, S.A.; Norquist, A.J.; Chan, E.M.; Schrier, J. Experiment Specification, Capture and Laboratory Automation Technology (ESCALATE): A software pipeline for automated chemical experimentation and data management. MRS Commun. 2019, 9, 846–859. [Google Scholar] [CrossRef]
- Simms, S.; Jones, S. Next-Generation Data Management Plans: GlobalMachine-Actionable FAIR. Int. J. Digit. Curation 2017, 12, 36–45. [Google Scholar] [CrossRef]
- Sinaci, A.A.; Núñez-Benjumea, F.J.; Gencturk, M.; Jauer, M.-L.; Deserno, T.; Chronaki, C.; Cangioli, G.; Cavero-Barca, C.; Rodríguez-Pérez, J.M.; Pérez-Pérez, M.M.; et al. From Raw Data to FAIR Data: The FAIRification Workflow for Health Research. Methods Inf. Med. 2020, 59, e21–e32. [Google Scholar] [CrossRef] [PubMed]
- Forsström, P.-L.; Haapio, H.; Passera, S. FAIR Design Jam: A Case Study on Co-Creating Communication About FAIR Data Principles. In Trends and Communities of Legal Informatics, Proceedings of the 20th International Legal Informatics Symposium IRIS 2017, Vienna, Austria, 23 February 2017; Jusletter IT: Bern, Switzerland, 2017. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | |
| Data Identification | |
| Dataset description | ….. |
| Source | ….. |
| Partner’s activities and responsibilities | |
| Partner owner of the data; copyright holder (if applicable) | ….. |
| Partner in charge of data collection | ….. |
| Partner in charge of data analysis | ….. |
| Partner in charge of data storage | ….. |
| Related WP(s) and task(s) | ….. |
| Expected input variables | |
| Description of the information required (working packages (WPs) and/or tasks) in order to move forward. | ….. |
| Expected outcomes | |
| Description of the specific endpoint measurement variables/outcomes. | ….. |
| Standards | |
| Detailed description of the methods/protocols | ….. |
| Dataset Name | ||||
|---|---|---|---|---|
| Data exploitation and sharing | ||||
| Data exploitation (purpose/use of the data analysis) | … | |||
| Data access policy/dissemination level: | Public | … | Confidential * | … |
| Data sharing, re-use, distribution, publication (How?) | ASINA private server | … | ASINA private server | … |
| CORDIS ¤ | … | |||
| Publication (Embargo) | … | |||
| NanoCommons Knowledge Base † | … | |||
| Personal data protection: are they personal data? If so, have you gained (written) consent from data subjects to collect this information? | … | |||
| Archiving and preservation (including storage and backup) | ||||
| Data storage (including backup): Where? For how long? | … | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Furxhi, I.; Arvanitis, A.; Murphy, F.; Costa, A.; Blosi, M. Data Shepherding in Nanotechnology. The Initiation. Nanomaterials 2021, 11, 1520. https://doi.org/10.3390/nano11061520
Furxhi I, Arvanitis A, Murphy F, Costa A, Blosi M. Data Shepherding in Nanotechnology. The Initiation. Nanomaterials. 2021; 11(6):1520. https://doi.org/10.3390/nano11061520
Chicago/Turabian StyleFurxhi, Irini, Athanasios Arvanitis, Finbarr Murphy, Anna Costa, and Magda Blosi. 2021. "Data Shepherding in Nanotechnology. The Initiation" Nanomaterials 11, no. 6: 1520. https://doi.org/10.3390/nano11061520
APA StyleFurxhi, I., Arvanitis, A., Murphy, F., Costa, A., & Blosi, M. (2021). Data Shepherding in Nanotechnology. The Initiation. Nanomaterials, 11(6), 1520. https://doi.org/10.3390/nano11061520