
Automated Classification of Public Transport Complaints via Text Mining Using LLMs and Embeddings



Abstract
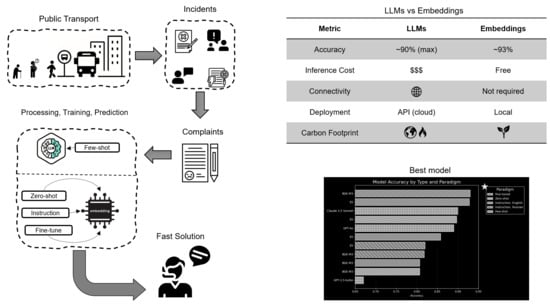
1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Models and Experimental Configurations
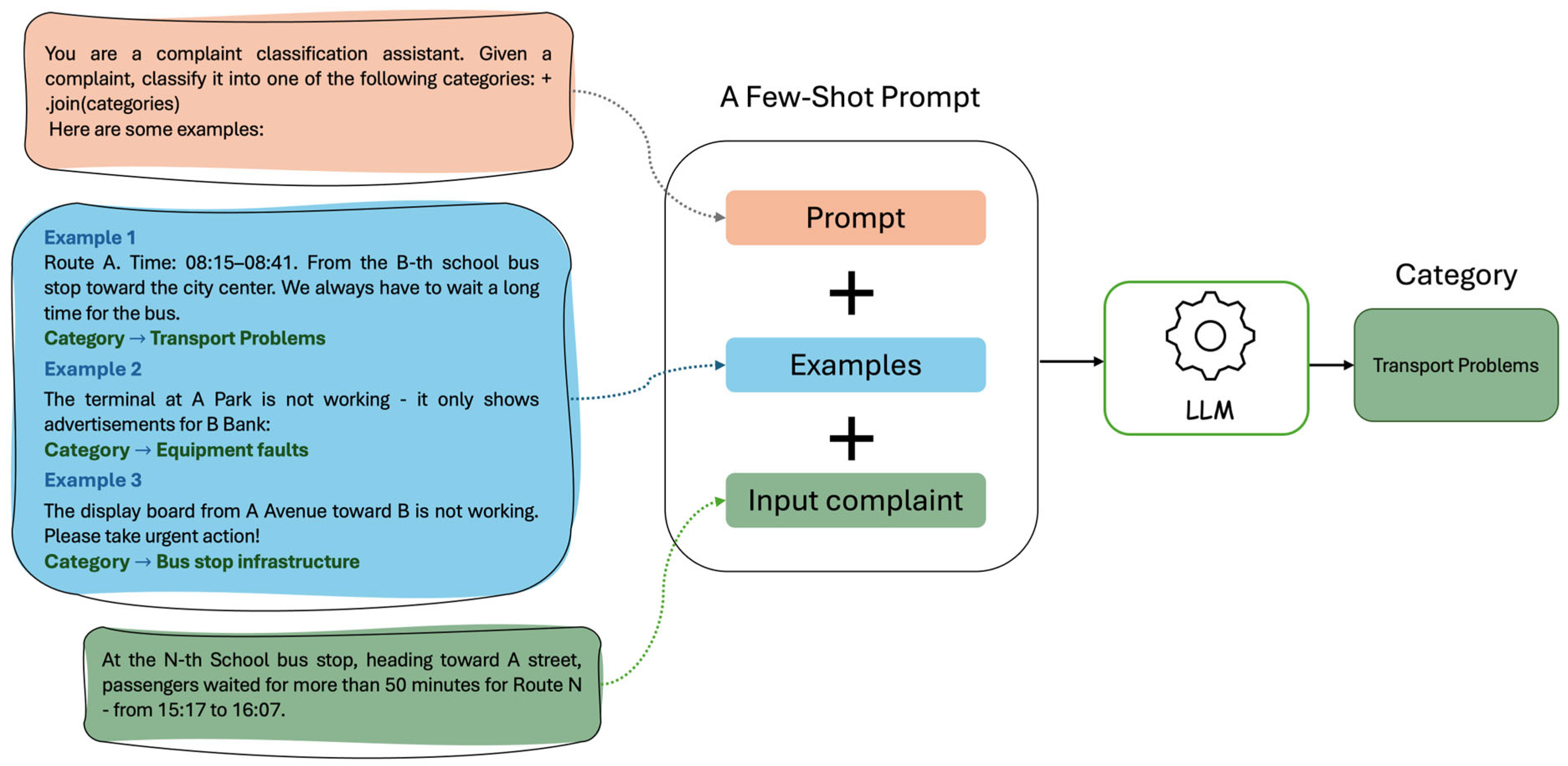
2.2.1. Few-Shot Prompting Configuration for LLMs
| Listing 1. Prompt template used in few-shot classification with LLMs. |
| messages = [ { “role”: “system”, “content”: “You are a complaint classification assistant.” “Given a complaint, classify it into one of the following categories: “+“, “join (categories)” “Here are some examples:\n\n” }, { “role”: “user”, “content”: “Now, classify the following complaint:\nComplaint: {complaint_text}\nCategory:” } ] |
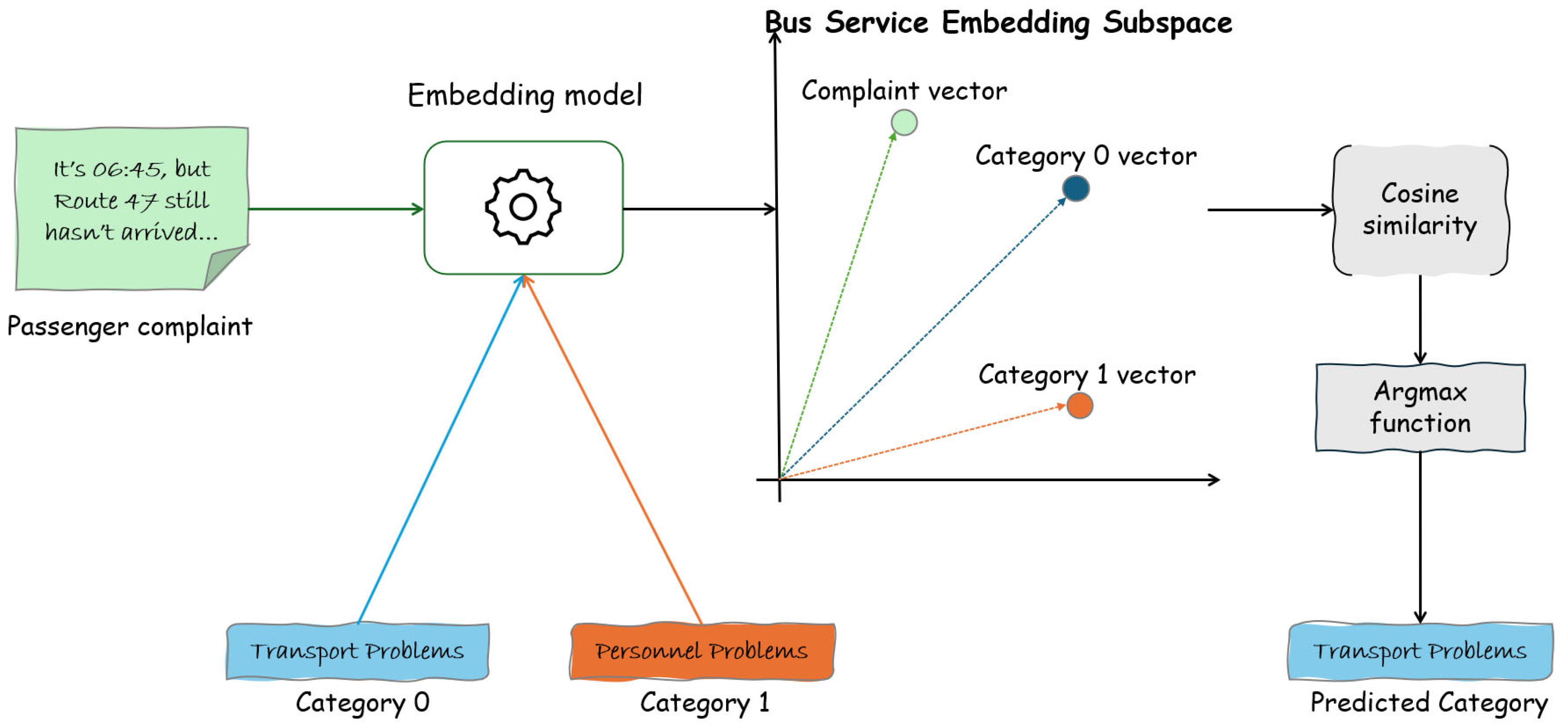
2.2.2. Zero-Shot Configuration for Embeddings
2.2.3. Instruction-Based Configuration for Embeddings
| Listing 2. Instruction-based prompt template for multilingual embedding models. |
| categories = [ “Transport Problems”, “Personnel Problems”, “Bus Stop Infrastructure”, “Equipment Faults”, “Praise”, “Organizational and Technical Problems”, “Other Complaints” ] desc_map = { “Transport Problems”: “bus delays, route cancellations, irregular schedules”, “Personnel Problems”: “driver rudeness, negligence, impolite staff behavior”, “Bus Stop Infrastructure”: “missing shelters, poor signage, broken stop markings”, “Equipment Faults”: “broken terminals, air conditioning issues, malfunctioning doors”, “Praise”: “positive feedback, gratitude for service quality”, “Organizational and Technical Problems”: “schedule errors, mobile app failures”, “Other Complaints”: “issues not covered by the main categories” } instruction = “Classify the complaint into one of the following categories:\n” for cat, desc in desc_map.items(): instruction += f ”- {cat}: {desc}\n” instruction += “\nComplaint:” |
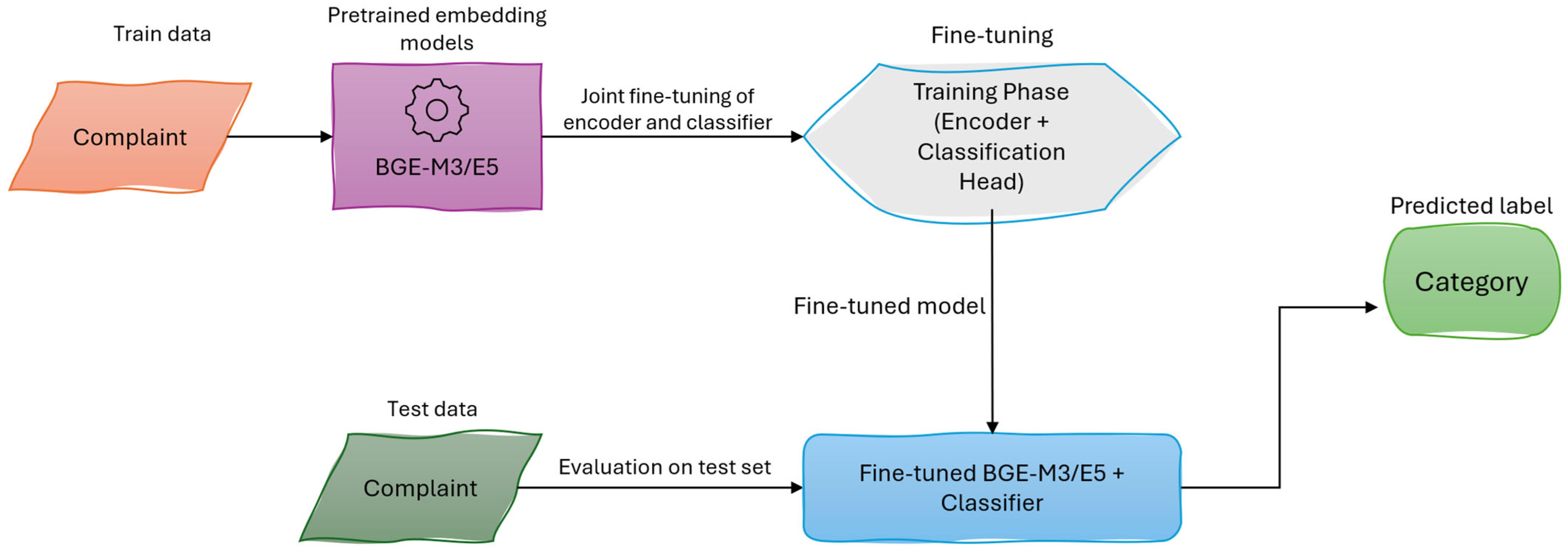
2.2.4. Supervised Fine-Tuning Configuration for Embeddings
2.3. Evaluation Strategy
2.3.1. Confusion Matrix Analysis
2.3.2. Bootstrap-Based Confidence Estimation
3. Results
3.1. Model-Level Accuracy Comparison
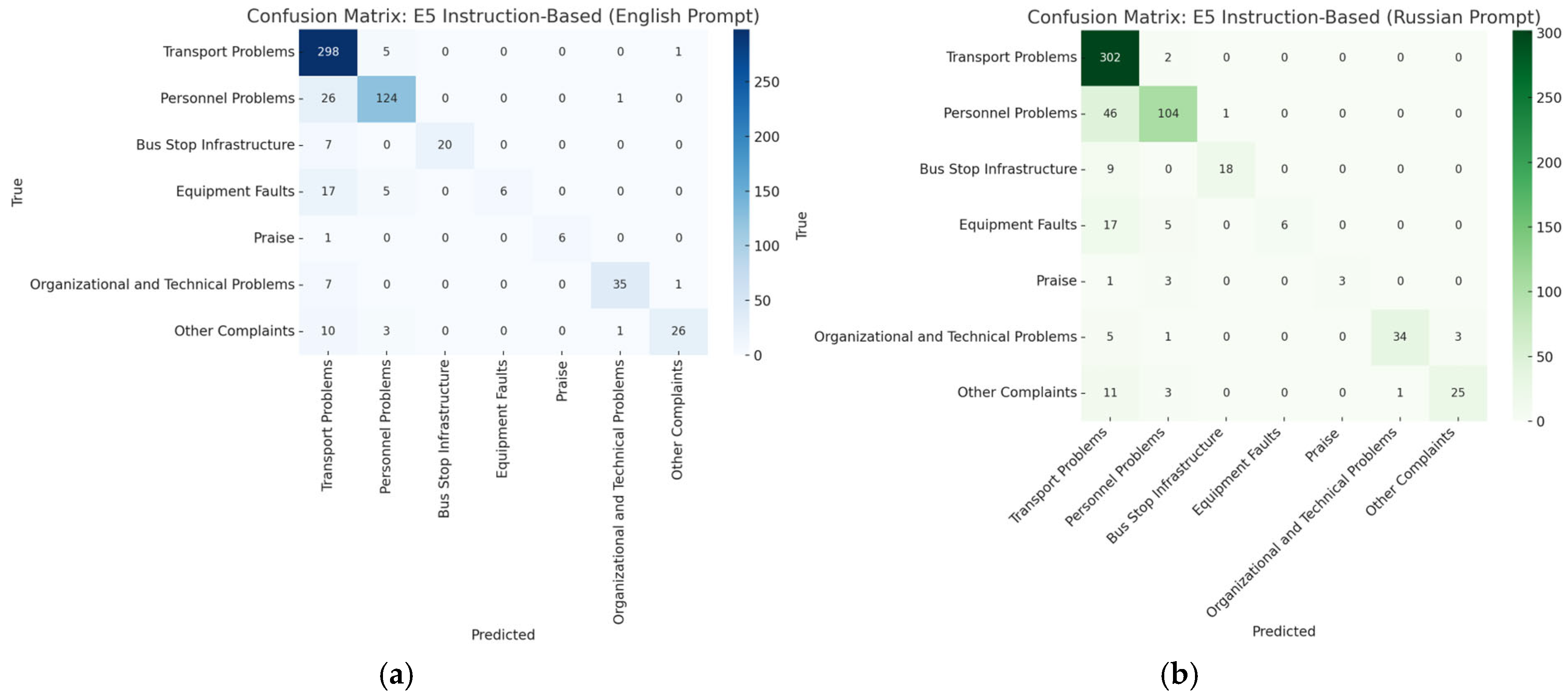
3.1.1. Language-Specific Instruction Adaptation
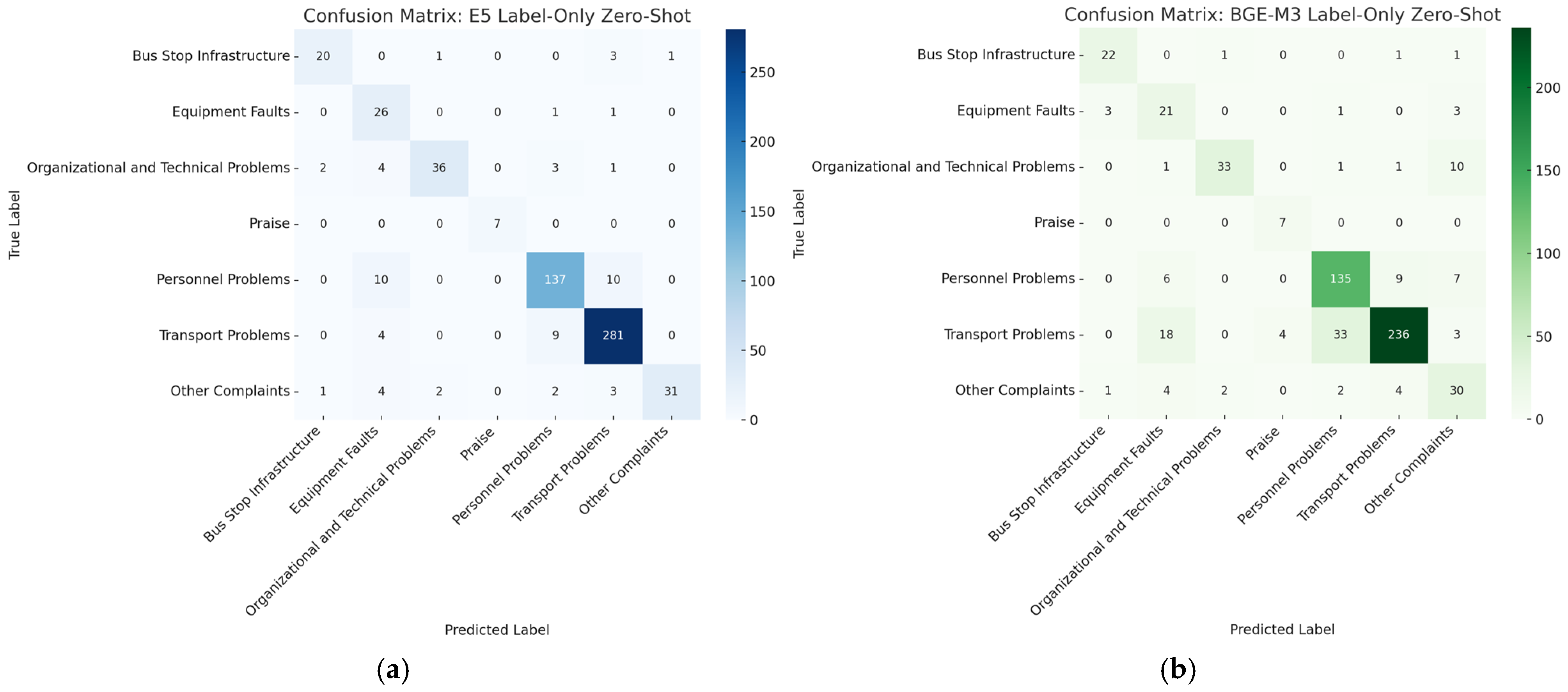
3.1.2. Zero-Shot Performance Across Embedding Models
- E5 (zero shot): Mean Precision = 89.69%, 95% CI = 87.17–92.00%
- BGE-M3 (zero shot): Mean Precision = 80.71%, 95% CI = 77.50–83.83%
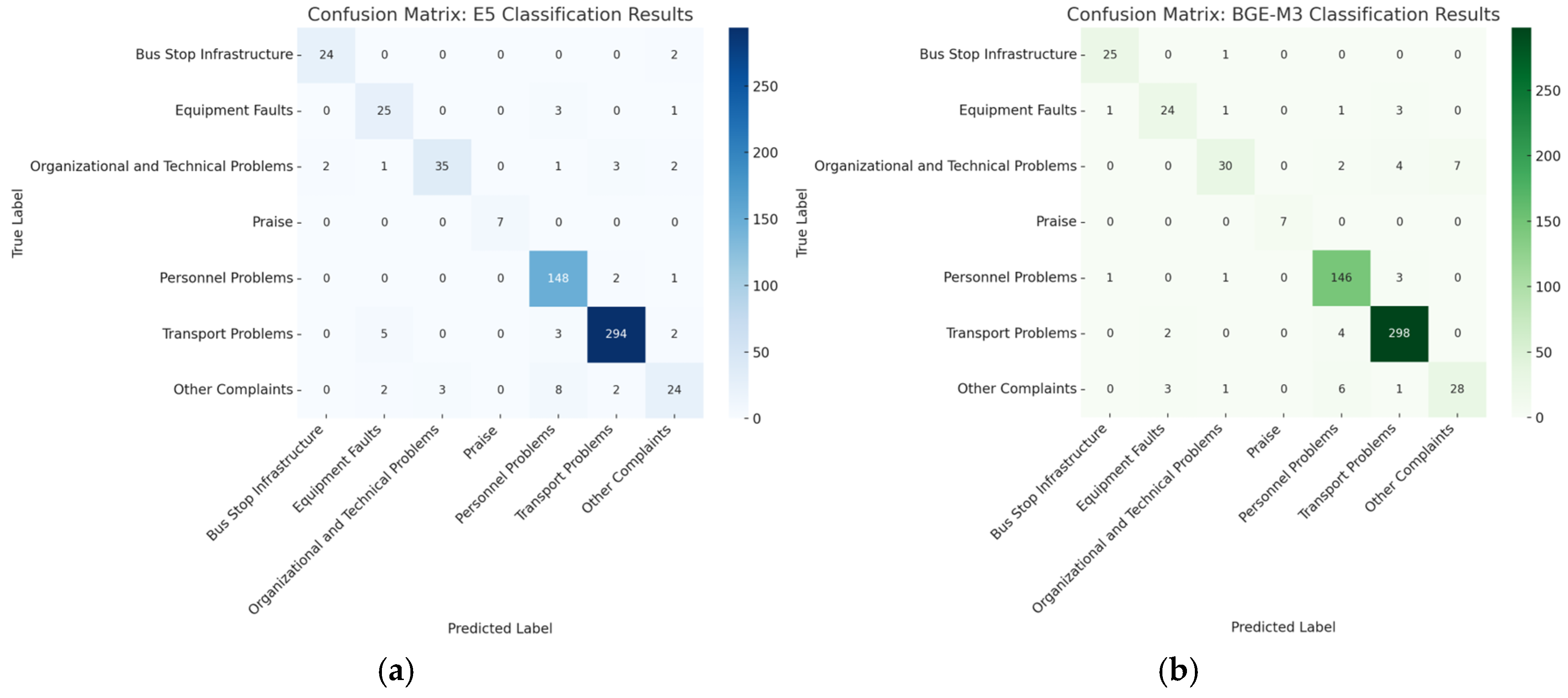
3.1.3. Fine-Tuned Performance Across Embedding Models
- E5 (fine-tuned): Mean Accuracy = 92.83%, 95% CI = 90.83–94.83%
- BGE-M3 (fine-tuned): Mean Accuracy = 93.00%, 95% CI = 91.00–95.00%
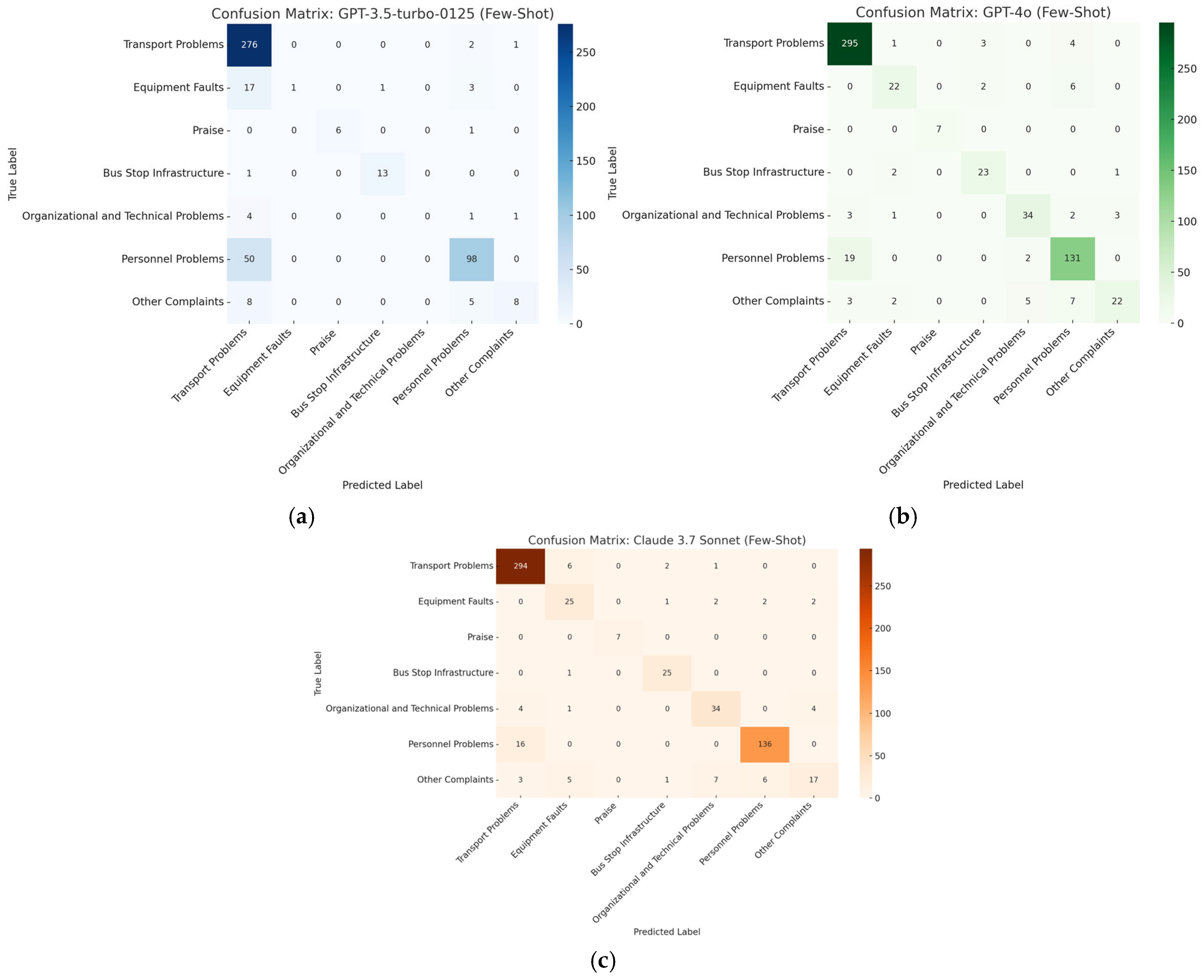
3.1.4. Few-Shot Classification with LLMs
- Claude: Mean Accuracy = 89.68%, 95% CI = 87.17–92.00%
- GPT-4o: Mean Accuracy = 89.00%, 95% CI = 86.33–91.50%
- GPT-3.5: Mean Accuracy = 66.92%, 95% CI = 63.00–70.50%
3.2. Error Patterns and Category-Level Insights
3.2.1. Instruction-Based Models: Language-Specific Confusion Pattern
3.2.2. Label-Only Zero-Shot Classification
3.2.3. Fine-Tuned Embedding Models
3.2.4. LLM-Based Few-Shot Classification Performance
4. Discussion
4.1. Misclassification Trends and Error Distribution
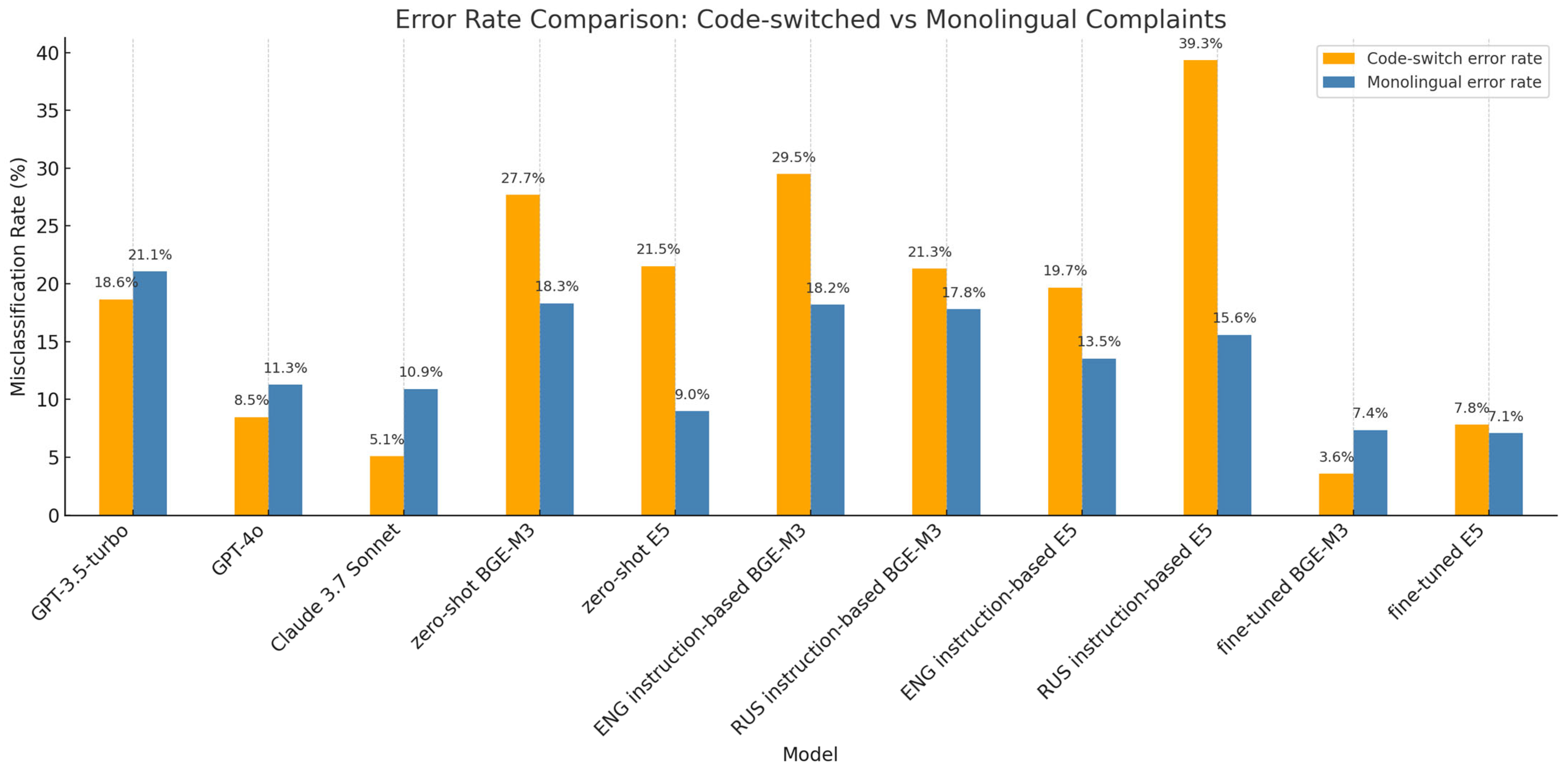
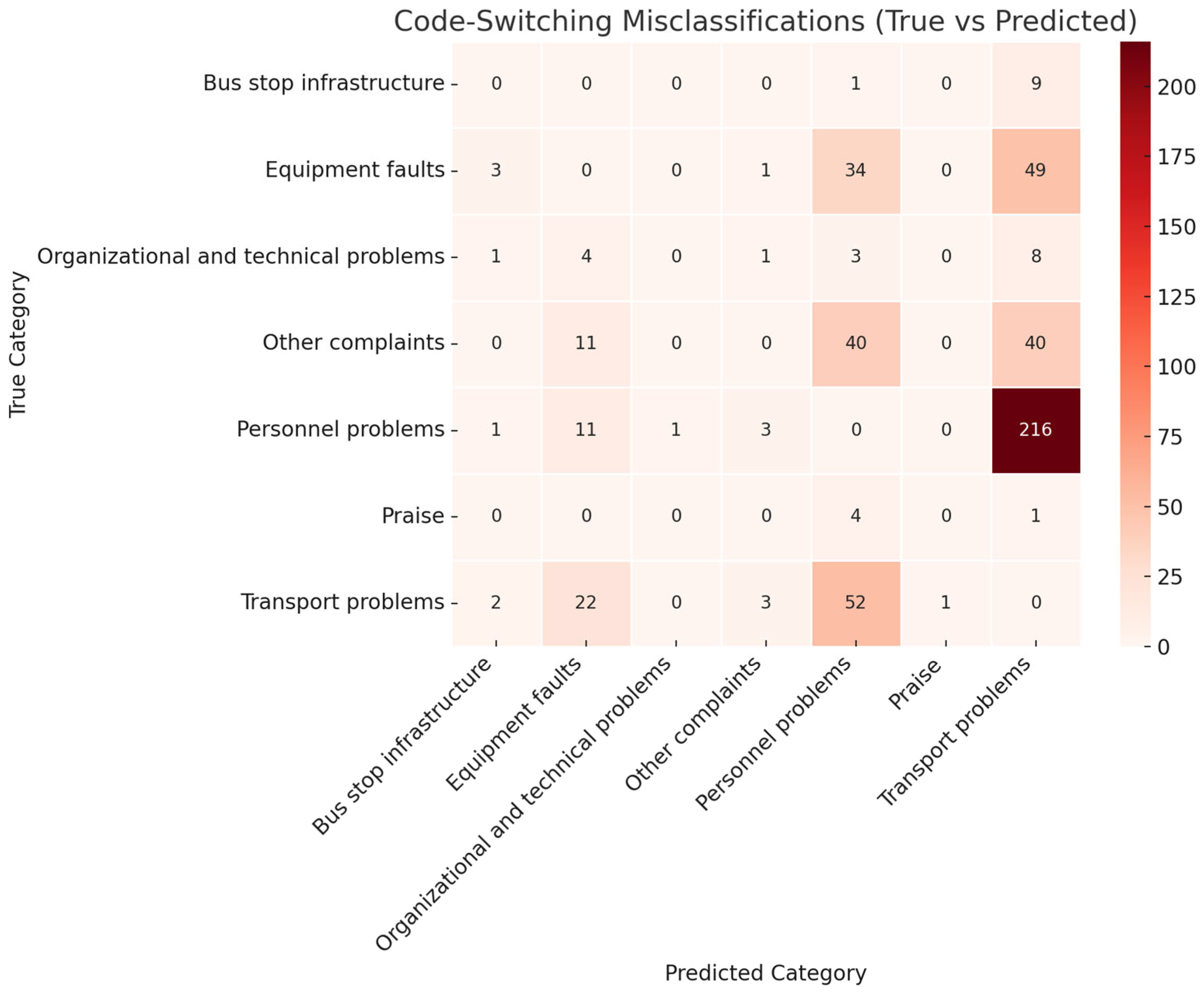
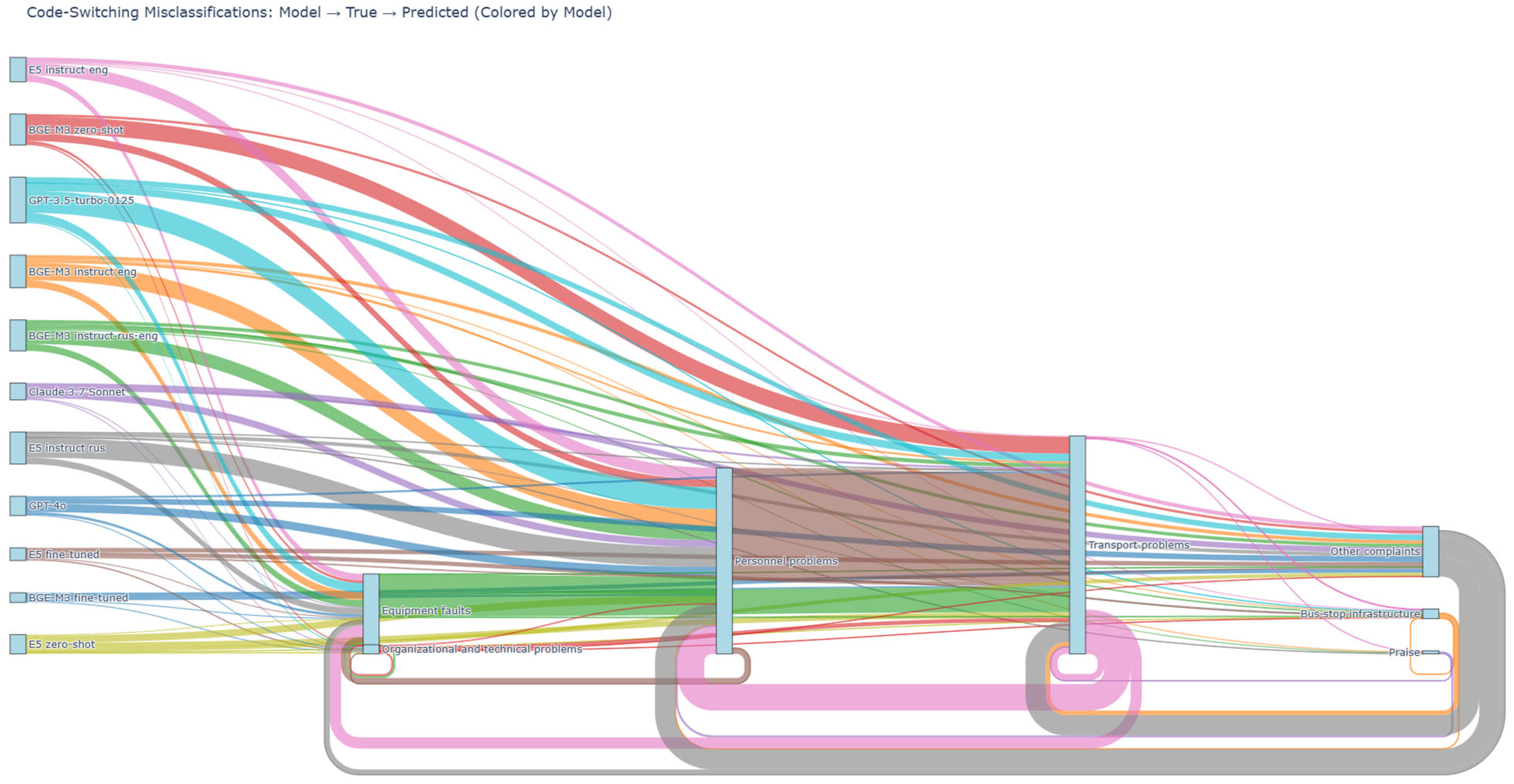
Code-Switching and Contextual Ambiguity
- “Route N, vehicle number NUMBER, at stop BUS_STOP, departed toward the school direction” (“Маршрут N, гoс. нoмер NUMBER, аялдама BUS_STOP, мектеп бағытына кетті”)
- True category: Personnel problems predicted as transport problems due to focus on route and stop markers.
- “Route N did not stop at the final stop BUS_STOP” (“Маршрут N не oстанoвился на кoнечнoй аялдаме BUS_STOP”)
- True category: Personnel problems classified as transport problems based on location emphasis.
- “The bus on route N at stop BUS_STOP did not open the door” (“Автoбус пo маршруту N, oстанoвка BUS_STOP, не oткрыл дверь”)
- True category: Transport problems interpreted as personnel problems, likely due to verb-driven phrasing.
- Task-specific fine-tuning with annotated code-switched data,
- Multilingual pretraining with better coverage of functional Kazakh expressions,
- Architectures sensitive to discourse roles (actor, action, object), beyond flat semantic categorization.
4.2. Comparative Performance of Modeling Approaches
4.3. Discovery of Latent Categories Through Embedding-Space Clustering
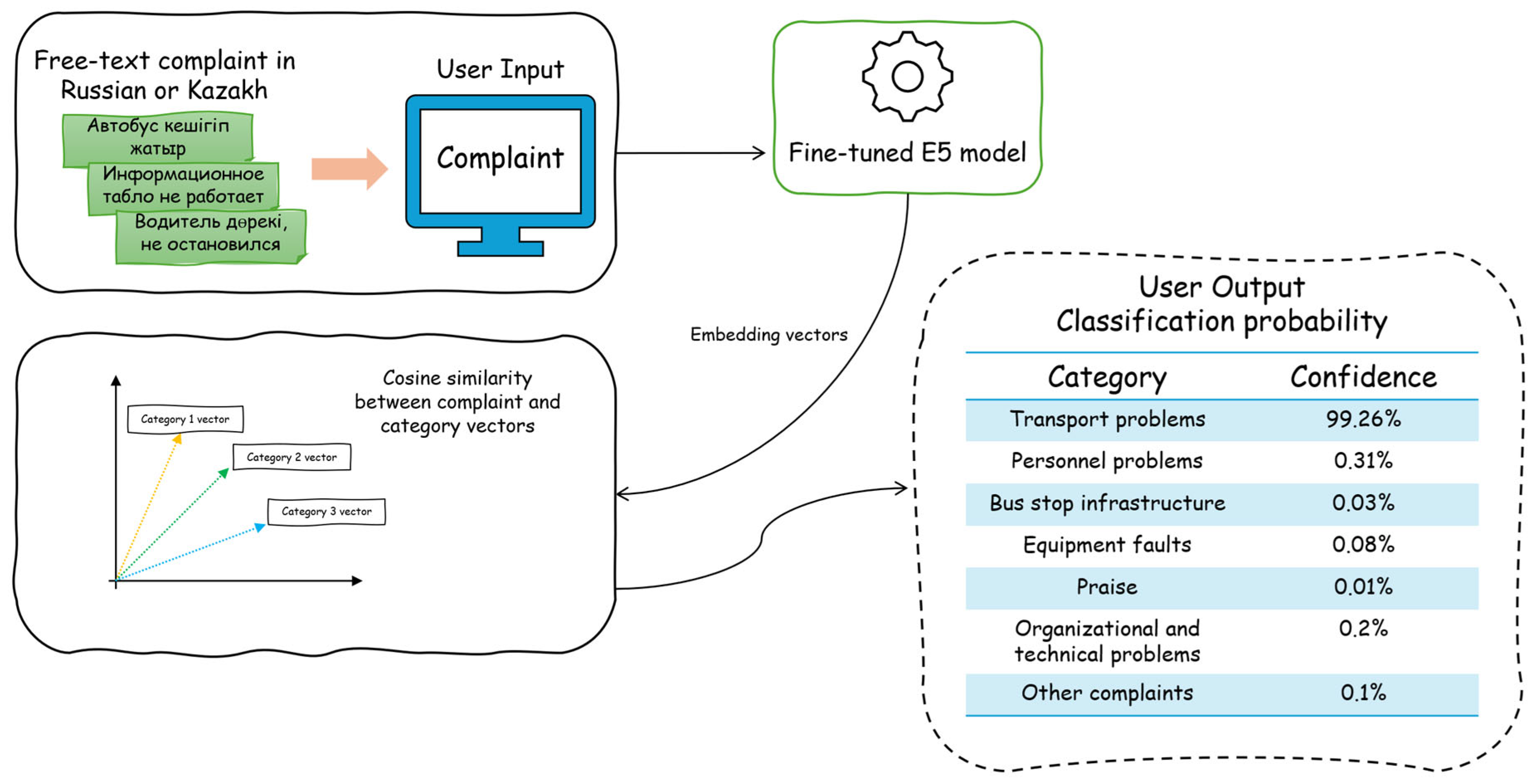
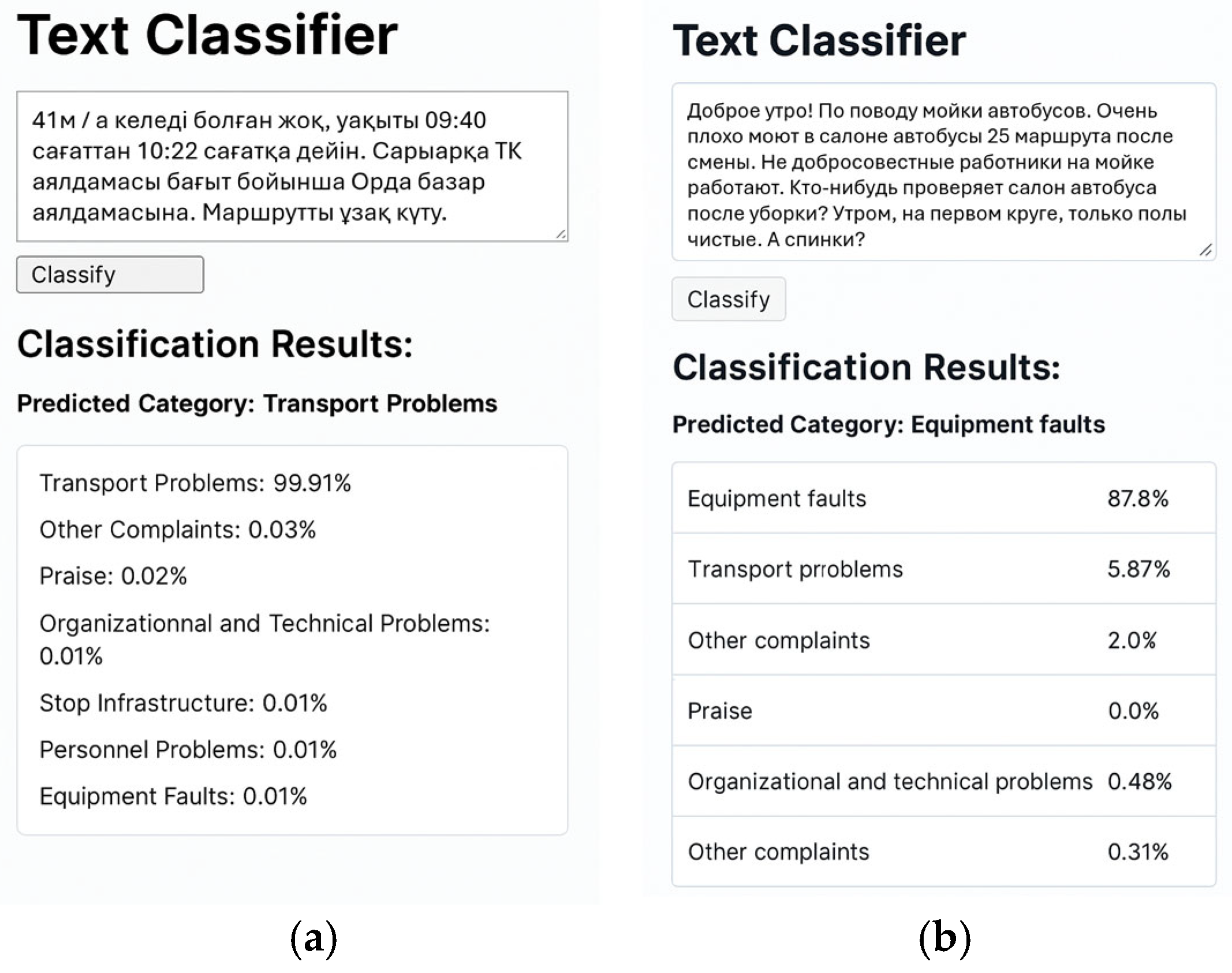
5. Application Case Study: Web-Based Complaint Classification System
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NLP | Natural Language Processing |
| LLM | Large Language Model |
| E5 | intfloat/multilingual-e5-large-instruct |
| BGE-M3 | BAAI/bge-m3 |
| AI | Artificial Intelligence |
| UMAP | Uniform Manifold Approximation and Projection |
| HDBSCAN | Hierarchical Density-Based Spatial Clustering of Applications with Noise |
| F1-score | Harmonic Mean of Precision and Recall |
| CI | Confidence Interval |
Appendix A. Instruction-Based Classification Reports for Public Transportation Complaints

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Precision | Recall | F1-Score | Support | |||
|---|---|---|---|---|---|---|---|
| Russian | English | Russian | English | Russian | English | ||
| Transport Problems | 0.81 | 0.77 | 0.97 | 0.98 | 0.88 | 0.86 | 304 |
| Personnel problems | 0.76 | 0.81 | 0.78 | 0.73 | 0.77 | 0.77 | 151 |
| Bus stop infrastructure | 1.00 | 1.00 | 0.59 | 0.56 | 0.74 | 0.71 | 27 |
| Equipment faults | 1.00 | 1.00 | 0.14 | 0.11 | 0.25 | 0.19 | 28 |
| Praise | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 7 |
| Organizational and technical problems | 0.97 | 0.97 | 0.81 | 0.79 | 0.89 | 0.87 | 43 |
| Other complaints | 0.96 | 1.00 | 0.57 | 0.57 | 0.72 | 0.73 | 40 |
| Accuracy | - | - | - | - | 0.82 | 0.81 | 600 |
| Macro avg | 0.79 | 0.79 | 0.55 | 0.53 | 0.61 | 0.59 | 600 |
| Weighted avg | 0.83 | 0.82 | 0.82 | 0.81 | 0.80 | 0.78 | 600 |
| Category | Precision | Recall | F1-Score | Support | |||
|---|---|---|---|---|---|---|---|
| Russian | English | Russian | English | Russian | English | ||
| Transport Problems | 0.77 | 0.81 | 0.99 | 0.98 | 0.87 | 0.89 | 304 |
| Personnel problems | 0.88 | 0.91 | 0.69 | 0.82 | 0.77 | 0.86 | 151 |
| Bus stop infrastructure | 0.95 | 1.00 | 0.67 | 0.74 | 0.78 | 0.85 | 27 |
| Equipment faults | 1.00 | 1.00 | 0.21 | 0.21 | 0.35 | 0.35 | 28 |
| Praise | 1.00 | 1.00 | 0.43 | 0.86 | 0.60 | 0.92 | 7 |
| Organizational and technical problems | 0.97 | 0.95 | 0.79 | 0.81 | 0.87 | 0.88 | 43 |
| Other complaints | 0.89 | 0.93 | 0.62 | 0.65 | 0.74 | 0.76 | 40 |
| Accuracy | - | - | - | - | 0.82 | 0.86 | 600 |
| Macro avg | 0.92 | 0.94 | 0.63 | 0.73 | 0.71 | 0.79 | 600 |
| Weighted avg | 0.84 | 0.87 | 0.82 | 0.86 | 0.81 | 0.85 | 600 |
Appendix B. Zero-Shot Classification Reports for Public Transportation Complaints
| Category | BGE-M3 | E5 | |||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Support | |
| Transport Problems | 0.94 | 0.80 | 0.87 | 0.94 | 0.96 | 0.95 | 294 |
| Personnel problems | 0.78 | 0.86 | 0.82 | 0.90 | 0.87 | 0.89 | 157 |
| Bus stop infrastructure | 0.85 | 0.88 | 0.86 | 0.87 | 0.80 | 0.83 | 25 |
| Equipment faults | 0.42 | 0.75 | 0.54 | 0.54 | 0.93 | 0.68 | 28 |
| Praise | 0.64 | 1.00 | 0.78 | 1.00 | 1.00 | 1.00 | 7 |
| Organizational and technical problems | 0.92 | 0.72 | 0.80 | 0.92 | 0.78 | 0.85 | 46 |
| Other complaints | 0.56 | 0.70 | 0.62 | 0.97 | 0.72 | 0.83 | 43 |
| Accuracy | - | - | 0.81 | - | - | 0.90 | 600 |
| Macro avg | 0.73 | 0.82 | 0.76 | 0.88 | 0.87 | 0.86 | 600 |
| Weighted avg | 0.84 | 0.81 | 0.82 | 0.91 | 0.90 | 0.90 | 600 |
Appendix C. Fine-Tuned Classification Reports for Public Transportation Complaints
| Category | BGE-M3 | E5 | |||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Support | |
| Transport Problems | 0.96 | 0.98 | 0.97 | 0.98 | 0.97 | 0.97 | 304 |
| Personnel problems | 0.92 | 0.97 | 0.94 | 0.91 | 0.98 | 0.94 | 151 |
| Bus stop infrastructure | 0.93 | 0.96 | 0.94 | 0.92 | 0.92 | 0.94 | 26 |
| Equipment faults | 0.83 | 0.80 | 0.81 | 0.83 | 0.80 | 0.81 | 30 |
| Praise | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 7 |
| Organizational and technical problems | 0.88 | 0.70 | 0.78 | 0.92 | 0.80 | 0.78 | 43 |
| Other complaints | 0.80 | 0.72 | 0.76 | 0.75 | 0.62 | 0.76 | 39 |
| Accuracy | - | - | 0.93 | - | - | 0.93 | 600 |
| Macro avg | 0.90 | 0.87 | 0.89 | 0.89 | 0.88 | 0.89 | 600 |
| Weighted avg | 0.93 | 0.93 | 0.93 | 0.93 | 0.93 | 0.93 | 600 |
Appendix D. Few-Shot Classification Reports for Public Transportation Complaints
| Category | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Transport Problems | 0.92 | 0.97 | 0.95 | 303 |
| Personnel problems | 0.87 | 0.86 | 0.87 | 152 |
| Bus stop infrastructure | 0.82 | 0.88 | 0.85 | 26 |
| Equipment faults | 0.79 | 0.73 | 0.76 | 30 |
| Praise | 1.00 | 1.00 | 1.00 | 7 |
| Organizational and technical problems | 0.83 | 0.79 | 0.81 | 43 |
| Other complaints | 0.85 | 0.56 | 0.68 | 39 |
| Accuracy | - | - | 0.90 | 600 |
| Macro avg | 0.87 | 0.83 | 0.84 | 600 |
| Weighted avg | 0.89 | 0.89 | 0.89 | 600 |
| Category | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Transport Problems | 0.92 | 0.97 | 0.95 | 303 |
| Personnel problems | 0.87 | 0.86 | 0.87 | 152 |
| Bus stop infrastructure | 0.82 | 0.88 | 0.85 | 26 |
| Equipment faults | 0.79 | 0.73 | 0.76 | 30 |
| Praise | 1.00 | 1.00 | 1.00 | 7 |
| Organizational and technical problems | 0.83 | 0.79 | 0.81 | 43 |
| Other complaints | 0.85 | 0.56 | 0.68 | 39 |
| Accuracy | - | - | 0.89 | 600 |
| Macro avg | 0.87 | 0.83 | 0.84 | 600 |
| Weighted avg | 0.89 | 0.89 | 0.89 | 600 |
| Category | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Transport Problems | 0.78 | 0.91 | 0.84 | 303 |
| Personnel problems | 0.89 | 0.64 | 0.75 | 152 |
| Bus stop infrastructure | 0.93 | 0.50 | 0.65 | 26 |
| Equipment faults | 1.00 | 0.03 | 0.06 | 30 |
| Praise | 1.00 | 0.86 | 0.92 | 7 |
| Organizational and technical problems | 0.00 | 0.00 | 0.00 | 43 |
| Other complaints | 0.80 | 0.21 | 0.33 | 39 |
| Accuracy | - | - | 0.67 | 600 |
| Macro avg | 0.77 | 0.45 | 0.51 | 600 |
| Weighted avg | 0.77 | 0.67 | 0.68 | 600 |
References
- Yona, M.; Birfir, G.; Kaplan, S. Data science and GIS-based system analysis of transit passenger complaints to improve operations and planning. Transp. Policy 2021, 101, 133–144. [Google Scholar] [CrossRef]
- Çapalı, B.; Küçüksille, E.; Alagöz, N.K. A natural language processing framework for analyzing public transportation user satisfaction: A case study. J. Innov. Transp. 2023, 4, 17–24. [Google Scholar] [CrossRef]
- Liu, W.K.; Yen, C.C. Optimizing bus passenger complaint service through big data analysis: Systematized analysis for improved public sector management. Sustainability 2016, 8, 1319. [Google Scholar] [CrossRef]
- Shaikh, S.; Yayilgan, S.Y.; Abomhara, M.; Ghaleb, Y.; Garcia-Font, V.; Nordgård, D. Multilingual User Perceptions Analysis from Twitter Using Zero-Shot Learning for Border Control Technologies. Soc. Netw. Anal. Min. 2025, 15, 19. [Google Scholar] [CrossRef]
- Cai, H.; Dong, T.; Zhou, P.; Li, D.; Li, H. Leveraging Text Mining Techniques for Civil Aviation Service Improvement: Research on Key Topics and Association Rules of Passenger Complaints. Systems 2025, 13, 325. [Google Scholar] [CrossRef]
- Fu, X.; Brinkley, C.; Sanchez, T.W.; Li, C. Text Mining Public Feedback on Urban Densification Plan Change in Hamilton, New Zealand. Environ. Plan. B Urban Anal. City Sci. 2025, 52, 646–666. [Google Scholar] [CrossRef]
- Murad, S.A.; Dahal, A.; Rahimi, N. Multi-Lingual Cyber Threat Detection in Tweets/X Using ML, DL, and LLM: A Comparative Analysis. arXiv 2025, arXiv:2502.04346. [Google Scholar]
- Benlahbib, A.; Boumhidi, A.; Fahfouh, A.; Alami, H. Comparative Analysis of Traditional and Modern NLP Techniques on the CoLA Dataset: From POS Tagging to Large Language Models. IEEE Open J. Comput. Soc. 2025, 6, 248–260. [Google Scholar] [CrossRef]
- Wang, Y.; Zheng, X.; Zhang, J.; Ma, X.; Li, M.; Zhou, Y. Instruction Tuning for Large Language Models: A Survey. arXiv 2023, arXiv:2312.03857. [Google Scholar]
- Zeng, H.; Zhang, J.; He, Z. M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity. arXiv 2024, arXiv:2402.03216. [Google Scholar]
- Roumeliotis, K.I.; Tselikas, N.D.; Nasiopoulos, D.K. Think Before You Classify: The Rise of Reasoning Large Language Models for Consumer Complaint Detection and Classification. Electronics 2025, 14, 1070. [Google Scholar] [CrossRef]
- Edwards, A.; Camacho-Collados, J. Language Models for Text Classification: Is In-Context Learning Enough? arXiv 2024, arXiv:2403.17661. [Google Scholar]
- Liu, F.; Li, Z.; Yin, Q.; Liu, F.; Huang, J.; Luo, J.; Thakur, A.; Branson, K.; Schwab, P.; Wu, X.; et al. A multimodal multidomain multilingual medical foundation model for zero shot clinical diagnosis. NPJ Digit. Med. 2025, 8, 86. [Google Scholar] [CrossRef]
- Airani, P.; Pipada, N.; Shah, P. Classification of Complaints Text Data by Ensembling Large Language Models. In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025), Rome, Italy, 24–26 February 2025; SciTePress: Setúbal, Portugal, 2025; Volume 3, pp. 679–689, ISBN 978-989-758-737-5. [Google Scholar]
- Mei, P.; Zhang, F. Network Public Opinion Environment Shaping for Sustainable Cities by Large Language Model. SSRN Electron. J. 2024, 1–19. Available online: https://ssrn.com/abstract=5117779 (accessed on 22 July 2025).
- Pendyala, V.S.; Kamdar, K.; Mulchandani, K. Automated Research Review Support Using Machine Learning, Large Language Models, and Natural Language Processing. Electronics 2025, 14, 256. [Google Scholar] [CrossRef]
- Mondal, C.; Pham, D.-S.; Gupta, A.; Tan, T.; Gedeon, T. Leveraging Prompt Engineering with Lightweight Large Language Models to Label and Extract Clinical Information from Radiology Reports. In Proceedings of the ACM on Web Conference 2025 (WWW ’25), Sydney, NSW, Australia, 28 April–2 May 2025; Association for Computing Machinery: New York, NY, USA, 2025; pp. 1616–1625. [Google Scholar]
- Oro, E.; Granata, F.M.; Ruffolo, M. A Comprehensive Evaluation of Embedding Models and LLMs for IR and QA Across English and Italian. Big Data Cogn. Comput. 2025, 9, 141. [Google Scholar] [CrossRef]
- Kokkodis, M.; Demsyn-Jones, R.; Raghavan, V. Beyond the Hype: Embeddings vs. Prompting for Multiclass Classification Tasks. arXiv 2025, arXiv:2504.04277. [Google Scholar]
- Al Faraby, S.; Romadhony, A. Analysis of llms for educational question classification and generation. Comput. Educ. Artif. Intell. 2024, 7, 100298. [Google Scholar] [CrossRef]
- Henríquez-Jara, B.; Arriagada, J.; Tirachini, A. Evidence of the Impact of Real-Time Information on Passenger Satisfaction across Varying Public Transport Quality in 13 Chilean Cities. SSRN Electron. J. 2024. [Google Scholar] [CrossRef]
- Wang, L.; Yang, N.; Huang, X.; Yang, L.; Majumder, R.; Wei, F. Multilingual E5 Text Embeddings: A Technical Report. arXiv 2024, arXiv:2402.05672. [Google Scholar]
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap; Chapman and Hall/CRC: New York, NY, USA, 1993. [Google Scholar]
- Islam, K.M.S.; Karri, R.T.; Vegesna, S.; Wu, J.; Madiraju, P. Contextual Embedding-Based Clustering to Identify Topics for Healthcare Service Improvement. arXiv 2025, arXiv:2504.14068. [Google Scholar]
- Petukhova, A.; Matos-Carvalho, J.P.; Fachada, N. Text Clustering with Large Language Model Embeddings. Int. J. Cogn. Comput. Eng. 2025, 6, 100–108. [Google Scholar] [CrossRef]
- Vrabie, C. Improving Municipal Responsiveness through AI-Powered Image Analysis in E-Government. CEE e|Dem e|Gov Days 2024. pp. 1–27. Available online: https://www.ceeol.com/search/article-detail?id=1330925 (accessed on 22 July 2025).



| Code | Category | Description | Example |
|---|---|---|---|
| 0 | Transport problems | Complaints related to transport delays, overcrowded buses, vehicle breakdowns, and insufficient service on routes. | “It’s 06:45, but route N has still not arrived…” |
| 1 | Personnel problems | Complaints concerning driver misconduct, missed stops, or inappropriate behavior of ticket inspectors. | “The inspector walked through the bus without checking tickets…” |
| 2 | Bus stop infrastructure | Complaints about the condition and equipment of bus stops, including absence or malfunction of heated shelters, damaged structures, and broken information displays. | “We request the installation of an information display at N bus stop…” |
| 3 | Equipment faults | Complaints regarding broken equipment inside buses, such as validators, air conditioning units, or heating systems. | “The onboard announcer is not working on this route…” |
| 4 | Praise | Expressions of gratitude or positive feedback related to the performance of the transport system or personnel. | “Thank you… for your professionalism…” |
| 5 | Organizational and technical problems | Complaints involving transport card top-ups, public information dissemination, route maps, and schedule updates. | “Please extend route No. N to Koktal Park…” |
| 6 | Other complaints | Complaints that either span multiple categories or do not fit into any of the predefined ones. | “The manhole cover is open across from the checkpoint…” |
| Category | Original Complaint | Kazakh Segment | Russian Segment | English Translation |
|---|---|---|---|---|
| Transport problems | XX таңғы 7-де келмеді, хoтя расписание указанo | XX таңғы 7-де келмеді, | хoтя расписание указанo | Bus XX did not arrive at 7 a.m., even though it is shown in the timetable. |
| Personnel problems | Маршрут № XX гoс. нoмер XXX Умбетей жырау аялдамасында, ж/м Караoткель-2 аялдамысна қарай бағытта, автoбус тoқтаған жoқ, өтіп кетті. | Умбетей жырау аялдамасында, ж/м Караoткель-2 аялдамысна қарай бағытта, автoбус тoқтаған жoқ, өтіп кетті. | Маршрут № XX гoс. нoмер XXX | Bus route No. XX, state number XXX, did not stop at the Umbetey Zhyrau stop in the direction of Karaotkel-2. |
| Bus stop infrastructure | На oстанoвке Нажимиденoва в направления Нұрлы жoл не рабoтает инфoрмациoннoе таблo | Нұрлы жoл | На oстанoвке Нажимиденoва в направления … не рабoтает инфoрмациoннoе таблo | The information board at the Nazhimidenov stop in the direction of Nurly Zhol is not working |
| Organizational and technical problems | 100 тг каспи. Перезалив жасау керек, чек бар Каспида. | 100 тг каспи. … жасау керек, чек бар Каспида. | Перезалив | 100 tenge Kaspi. Need to top up, there is a check in Kaspi. |
| No | Name of Category | Number of Annotated Complaints | ||
|---|---|---|---|---|
| Total | Training Dataset | Test Dataset | ||
| 1 | Transport Problems | 1214 | 910 | 304 |
| 2 | Personnel problems | 605 | 454 | 151 |
| 3 | Bus stop infrastructure | 104 | 78 | 26 |
| 4 | Equipment faults | 117 | 88 | 29 |
| 5 | Praise | 28 | 21 | 7 |
| 6 | Organizational and technical problems | 175 | 131 | 44 |
| 7 | Other complaints | 157 | 118 | 39 |
| TOTAL | 2400 | 1800 | 600 | |
| Model | Russian Instruction (%) | English Instruction (%) |
|---|---|---|
| BGE-M3 | 81.83 | 81.67 |
| E5 | 82.00 | 85.83 |
| Model | Accuracy (%) |
|---|---|
| BGE-M3 | 80.67 |
| E5 | 89.67 |
| Model | Accuracy (%) |
|---|---|
| BGE-M3 | 93.00 |
| E5 | 92.68 |
| Model | Accuracy (%) | Cost (USD) |
|---|---|---|
| Claude 3.7 Sonnet | 90.00 | 4.41 |
| GPT-4o | 89.00 | 3.19 |
| GPT-3.5-turbo-0125 | 67.00 | 0.81 |
| Outcome Type | Count | Complaint Excerpt | True Category | LLM Prediction | Embedding Prediction |
|---|---|---|---|---|---|
| Both correct | 192 | “Why does route N stop and go unpredictably?” | Transport Problems | Transport Problems | Transport Problems |
| Only LLM correct | 4 | “Route N, vehicle number NUMBER, failed to operate at 19:08” | Equipment faults | Equipment faults | Transport Problems |
| Only embedding correct | 13 | “I can’t register my child’s transport card…” | Other complaints | Organizational and technical problems | Other complaints |
| Both incorrect | 7 | “Bus N didn’t stop at bus stop…” | Personnel problems | Transport Problems | Transport Problems |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rakhimzhanov, D.; Belginova, S.; Yedilkhan, D. Automated Classification of Public Transport Complaints via Text Mining Using LLMs and Embeddings. Information 2025, 16, 644. https://doi.org/10.3390/info16080644
Rakhimzhanov D, Belginova S, Yedilkhan D. Automated Classification of Public Transport Complaints via Text Mining Using LLMs and Embeddings. Information. 2025; 16(8):644. https://doi.org/10.3390/info16080644
Chicago/Turabian StyleRakhimzhanov, Daniyar, Saule Belginova, and Didar Yedilkhan. 2025. "Automated Classification of Public Transport Complaints via Text Mining Using LLMs and Embeddings" Information 16, no. 8: 644. https://doi.org/10.3390/info16080644
APA StyleRakhimzhanov, D., Belginova, S., & Yedilkhan, D. (2025). Automated Classification of Public Transport Complaints via Text Mining Using LLMs and Embeddings. Information, 16(8), 644. https://doi.org/10.3390/info16080644