Abstract
The Learning with Errors (LWE) problem, particularly its efficient ternary variant where secrets and errors are small, is a fundamental building block for numerous post-quantum cryptographic schemes. Combinatorial attacks provide a potent approach to cryptanalyzing ternary LWE. While classical attacks have achieved complexities close to their asymptotic bound for a search space of size , their quantum counterparts have faced a significant gap: the attack by van Hoof et al. (vHKM) only reached a concrete complexity of , far from its asymptotic promise of . This work introduces an efficient quantum combinatorial attack that substantially narrows this gap. We present a quantum walk adaptation of the locality-sensitive hashing algorithm by Kirshanova and May, which fundamentally removes the need for guessing error coordinates—the primary source of inefficiency in the vHKM approach. This crucial improvement allows our attack to achieve a concrete complexity of approximately , markedly improving over prior quantum combinatorial methods. For concrete parameters of major schemes including NTRU, BLISS, and GLP, our method demonstrates substantial runtime improvements over the vHKM attack, achieving speedup factors ranging from to across different parameter sets and establishing the new state-of-the-art for quantum combinatorial attacks. As a second contribution, we address the challenge of polynomial quantum memory constraints. We develop a hybrid approach combining the Kirshanova–May framework with a quantum claw-finding technique, requiring only qubits while utilizing exponential classical memory. This work provides the first comprehensive concrete security analysis of real-world LWE-based schemes under such practical quantum resource constraints, offering crucial insights for post-quantum security assessments. Our results reveal a nuanced landscape where our combinatorial attacks are superior for small-weight parameters, while lattice-based attacks maintain an advantage for others.
1. Introduction
The Learning with Errors (LWE) problem [1] has become a cornerstone of post-quantum cryptography, serving as the security foundation for numerous cryptographic constructions [2,3,4]. In its standard form, LWE tries to find a secret vector given , where A is a random matrix and for some small error vector e. The hardness of LWE is supported by worst-case lattice reduction proofs [5], making it a robust basis for cryptographic constructions.
A particularly efficient variant is ternary LWE, where the entries of s and e are restricted to . This variant is employed in several practical schemes, including NTRU-based cryptosystems [6,7,8] and signature protocols such as BLISS [9] and GLP [10]. While the small domain of the secret and error does not fundamentally break LWE’s security, it does enable more efficient combinatorial attacks that exploit the sparsity and structure of the secrets.
Combinatorial attacks offer a distinct approach to cryptanalyzing LWE with small secrets, beginning with early Meet-in-the-Middle (MitM) attacks on NTRU by Odlyzko [11] and Howgrave-Graham [12]. A significant advancement came from May [13], who adapted the representation technique from subset-sum attacks [14,15,16] to reduce MitM complexity from to approximately for a search space of size . However, this improvement required guessing sub-linear error coordinates, which, while asymptotically negligible, raised concrete complexities to for practical NTRU, BLISS, and GLP parameters. This limitation was later addressed by Kirshanova and May [17] through an Odlyzko-based locality-sensitive hashing (LSH) technique that eliminated error guessing, finally achieving complexities near the asymptotic bound.
In the quantum setting, van Hoof et al. [18] investigated quantum speedups for May’s algorithm. Their asymptotic analysis demonstrates that the approach achieves a time complexity close to the bound; however, for concrete instantiations, the method only reaches a bound. Despite employing quantum search to accelerate the guessing phase, their quantum approach inherits the same fundamental limitation: for concrete cryptographic parameters, the realized complexity substantially deviates from the asymptotic bound, failing to bridge the gap between theoretical and practical performance.
1.1. Our Contribution
This work introduces a quantum adaptation of the LSH-based algorithm by Kirshanova and May [17] for solving ternary LWE. We reformulate the key recovery problem within a graph search framework. By implementing an optimized quantum walk over this graph, we eliminate the need for guessing the error coordinates—a fundamental limitation inherent to the quantum approach of van Hoof et al. [18]. As a result, our method substantially narrows the gap between asymptotic and concrete complexity, achieving a concrete bound of approximately compared to the bound of vHKM. For concrete parameters of major schemes such as NTRU, BLISS, and GLP, our method demonstrates speedup factors ranging from to over the vHKM [18] attack.
Our algorithm establishes the state of the art for quantum combinatorial attacks on ternary LWE. A comparison with quantum sieving algorithm shows a split in dominance: our method is superior for small-weight parameters, while lattice-based attacks maintain the lead for most others.
Current LWE parameter selection relies heavily on lattice reduction heuristics (e.g., Gaussian Heuristic and Geometric Series Assumption) and diverse BKZ runtime models, potentially underestimating security. In contrast, our combinatorial approach builds on heuristic principles derived from subset-sum or knapsack problems, which possess a stronger theoretical foundation. For knapsack-type distributions, it can be rigorously proven that pathological instances form only an exponentially small fraction, enabling the construction of provable probabilistic algorithms that avoid heuristics entirely. This theoretical robustness, combined with experimental validation in prior work [15], provides runtime predictions with significantly enhanced precision compared to lattice reduction heuristics that depend on unproven assumptions.
Our second contribution focuses on LWE key recovery under polynomial quantum memory constraints. While previous quantum-walk-based approaches achieve optimal time complexity among combinatorial methods, they require exponential qubit resources and rely on the strong Quantum Random Access Quantum Memory (QRAQM) model.
Building on recent work by Benedikt [19], who applied the quantum claw-finding algorithm of Chailloux et al. [20] to ternary LWE problems, we adopt a more practical approach that combines the Kirshanova–May framework [17] with this claw-finding technique. This hybrid strategy operates efficiently with only qubits under the Quantum Random Access Classical Memory (QRACM) model.
While Benedikt [19] provided valuable asymptotic analysis, their work left open the question of concrete security estimates for practical cryptographic parameter sets. Our work specifically addresses this gap by performing the first comprehensive concrete security analysis of real-world LWE-based schemes under polynomial-qubit constraints, providing crucial insights for post-quantum security assessments.
Furthermore, we provide the time–classical memory trade-offs for concrete schemes and explicitly compare our approach with the vHKM [18] method under strict polynomial classical memory constraints. Notably, across all evaluated schemes, our algorithm consistently achieves lower time complexity than vHKM under the same polynomial memory bound, further establishing its practical relevance in constrained settings.
1.2. Organization
The rest of this paper is organized as follows. In Section 2, we provide the necessary background, including the definition of the Ternary LWE, an introduction to Generalized Odlyzko’s Locality-Sensitive Hashing, and a review of the quantum primitives used in this work: amplitude amplification and quantum walks. Section 3 reviews the classical LSH-based MitM attack on ternary LWE by Kirshanova and May, which serves as the foundation for our quantum algorithms. In Section 4, we present our main contribution. We reformulate the ternary LWE key search problem as a graph search problem and introduce our novel quantum algorithm that combines the Kirshanova–May framework with a quantum walk. We provide a detailed description of the algorithm and a comprehensive concrete security analysis for major cryptographic schemes. Section 5 addresses the scenario of polynomial quantum memory constraints. We present a second algorithm that hybridizes the Kirshanova–May framework with a quantum claw-finding technique, requiring only a polynomial number of qubits. The concrete security of real-world schemes under this new algorithm is thoroughly analyzed. Finally, we conclude the paper in Section 6 with a summary of our findings.
2. Preliminaries
2.1. Notational Conventions
We adopt the following notation throughout this paper:
- Let represent the quotient ring of integers modulo .
- Vector quantities are denoted using lowercase letters (e.g., x, y), while matrices use uppercase letters (e.g., A, B).
- For any vector x, its -norm is defined as .
- The cardinality of a set S is denoted by .
- For positive integers n and summing to n, the multinomial coefficient is given by the productA compact notation is commonly used, where the dot signifies the remaining value .
2.2. Ternary LWE Secret Key
We focus on LWE instances where both the secret and error vectors are ternary and matrix A is square. This specific case captures numerous practical implementations in lattice-based cryptography.
Definition 1
(Ternary LWE Secret Key). Let be an LWE public key satisfying . The pair is called a ternary LWE secret key if both s and e belong to the set , i.e., .
The ternary constraint ensures cryptographic efficiency while maintaining security guarantees. For a randomly chosen A, the correct solution s is uniquely identifiable with high probability through the condition that also falls within .
Practical implementations often impose additional structural constraints by fixing the number of non-zero entries in ternary vectors, leading to optimized security parameters and implementation characteristics.
Definition 2
(Weight). Let . The weight w of s is defined as its Hamming weight . For ternary vectors with balanced non-zero coefficients, we define the specialized set:
Rounding considerations are handled appropriately in concrete parameterizations. Weight restrictions naturally emerge in the context of NTRU-type cryptosystems, where optimal values typically reside in the interval . The specific choice appears in several standardized parameter sets, representing a careful equilibrium between security and performance requirements.
2.3. Generalized Odlyzko’s Locality-Sensitive Hashing
A key technique in combinatorial attacks on ternary LWE is the use of LSH to efficiently identify pairs of vectors that are close in the -norm. Odlyzko’s original LSH function [11] partitions into two halves and assigns binary labels, but it requires special handling of border values.
Kirshanova and May [17] generalized this approach to avoid explicit border checks and to enable more flexible bucketing. Their LSH family is defined as follows. For a bucket size parameter and a random shift vector , the hash function is given by
This function maps each coordinate of x to a bucket index after a random cyclic shift. The probability that two vectors with collide under a random is .
Algorithm 1 solves the close pairs problem in the -norm: given two lists , find a -fraction of all pairs such that .
Example 1.
We illustrate Algorithm 1 with , , and lists:
Choose , . Hash computations:
Matching hash yields candidate pair . Verification:
This pair is 1-close. With repetitions using different random shifts u, Algorithm 1 finds all 1-close pairs with high probability.
| Algorithm 1 LSH-Odlyzko algorithm [17] |
| Input: Two lists of i.i.d. uniform vectors from , each of size |
| Output: fraction of all pairs such that |
| 1: Choose suitably. Choose . |
| 2: Apply to all elements in and . Sort and according to their hash values. |
| 3: Merge the sorted lists and collect all pairs with matching hash labels. Filter and output only those pairs satisfying . |
| 4: Repeat Steps 1–3 times. |
The space and time complexities of Algorithm 1 are given by
When combining approximate matching on coordinates with exact matching on coordinates, the complexity becomes
This generalized LSH technique is crucial for efficiently merging partial solutions in Meet-in-the-Middle attacks on ternary LWE, as it allows for approximate matching without guessing error coordinates.
2.4. Amplitude Amplification
Amplitude amplification [21] is a fundamental technique in quantum computing that amplifies the probability amplitudes of the target states, which are identified by an oracle.
Consider a quantum algorithm that prepares a uniform superposition over some subset . Let be a computable Boolean function with its quantum oracle acting as .
Define as the set of “good” elements. The probability of obtaining a good element by measuring is . The amplitude amplification algorithm finds an element with high probability using only iterations, where each iteration comprises one call each to , , and .
Let and denote the time complexities of implementing and , respectively. The total time complexity of amplitude amplification is
Amplitude amplification generalizes Grover search [22]. In the Grover setting, we take , and applies a Hadamard gate to each qubit, which can be implemented efficiently with .
2.5. Quantum Walk Search on Graphs
Consider a connected, d-regular, undirected graph with a subset of marked vertices. The objective is to find a marked vertex. The classical random walk on the graph G is characterized by a symmetric transition matrix P of size , where the entry is defined as if , and zero otherwise. A classical random walk search proceeds as follows:
- Sample a vertex from an initial probability distribution over V and initialize an associated data structure .
- Repeat the following times:
- (a)
- Check whether u is marked using . If marked, output u and halt.
- (b)
- Otherwise, perform steps of the random walk: at each step, move uniformly to a random neighbor v of the current vertex u, updating to .
Let denote the spectral gap of G, defined as the difference between the two largest eigenvalues of its adjacency matrix. The mixing time required to approximate the uniform distribution from an arbitrary starting vertex is known to satisfy .
Let be the fraction of marked vertices, so that a vertex sampled uniformly at random is marked with probability . Then, the expected number of trials needed to find a marked vertex is .
We define the following cost parameters:
- Setup cost : the cost of sampling the initial vertex and constructing the data structure .
- Update cost : the cost incurred per random walk step, which encompasses moving from a node u to a neighbor v and updating to .
- Checking cost : the cost of checking whether u is marked using .
The overall cost of the classical random walk search is then given by
In the quantum setting, the walk is initialized by preparing a uniform superposition over all vertices, together with two auxiliary registers (we omit normalization for simplicity):
where represents the uniform superposition over the neighbors of u.
The coin register uses the same number of qubits as the vertex register and encodes the direction of the quantum walk. The data register contains the classical data structure associated with vertex u, which is used to determine if u is marked.
The quantum walk step is a unitary operation that coherently simulates one step of the random walk. It consists of a coin operation followed by a shift operation. The coin operation creates a superposition over the neighbors of the current vertex, while the shift operation updates the vertex register accordingly. Throughout this process, the data structure in the register is updated coherently to reflect the new vertex. The checking operation is a phase oracle that applies a phase to marked vertices.
We define the quantum analogues of the classical cost parameters as follows:
- Setup cost : The cost of preparing the initial state .
- Update cost : The cost of implementing one quantum walk step.
- Checking cost : The cost of applying the checking oracle.
The quantum walk search algorithm achieves a quadratic speedup over classical approaches, requiring only iterations via amplitude amplification. A key component of this algorithm is the implementation of a reflection operator about the stationary state of the quantum walk, which corresponds to the quantum analog of the classical stationary distribution. Remarkably, this reflection can be approximated using phase estimation applied to the quantum walk operator, which requires only steps. This efficiency stems from the quadratic relationship between the classical spectral gap and the phase gap of the quantum walk: while the classical mixing time scales as , the quantum phase estimation converges in time .
The cost of the quantum walk search is given by the following theorem:
Theorem 1
(Quantum walk search on graphs [23]). Let be a regular graph with spectral gap , and suppose at least an fraction of its vertices are marked. For a quantum walk on G with setup, update, and checking costs denoted by , , and , respectively, there exists a quantum algorithm that finds a marked vertex with high probability in time:
The graphs used in our quantum walk search algorithms are the Cartesian products of Johnson graphs.
Definition 3
(Johnson graph). The Johnson graph, denoted as , is an undirected graph whose vertices correspond to all k-element subsets of a universe of size N. Two vertices S and are adjacent if and only if . This implies that can be obtained from S by replacing exactly one element. The spectral gap of is given by
Definition 4
(Cartesian product of Johnson graphs). Let denote the Cartesian product of m copies of the Johnson graph . Each vertex in is an m-tuple of k-element subsets. Two vertices and are adjacent if and only if they differ in exactly one coordinate i, and for that index, . The spectral gap satisfies
Remark 1
(Quantum Walk Heuristics [18]). A key difference in the design of classical versus quantum subroutines lies in termination guarantees: quantum updates must complete within a predetermined time bound, while classical algorithms—though with negligible probability—may exhibit unbounded worst-case running times. This fundamental issue was systematically examined in (Section 6 in [24]), where it was demonstrated that enforcing termination within a polynomial multiple of the expected runtime introduces only negligible distortion to the resulting quantum states. Consequently, for complexity analysis purposes, evaluating quantum walk efficiency via expected costs remains valid up to polynomial overhead.
3. LSH-Based MitM Attacks for Ternary LWE
The combinatorial attack on ternary LWE by Kirshanova and May [17] introduces a MitM approach improved with LSH and representation techniques. We refer to the two instantiations of their attack as Rep-0 and Rep-1, which we will introduce in turn, as they form the basis for our quantum algorithms.
3.1. Rep-0: First Instantiation of LSH-Based MitM Attacks
Let be a ternary LWE secret vector of weight w. Rep-0 represents the secret vector into two vectors such that . Such a pair is called a representation of s. There are such representations in total. The key idea is to leverage this representation to split the LWE equation into two parts:
In the standard MitM approach, one would enumerate all possible and and look for pairs where and differ by a ternary error vector e. However, this requires checking all pairs, which is inefficient. Instead, Rep-0 uses a tree-based search with LSH to efficiently find matching pairs.
Rep-0 constructs a depth-2 search tree as illustrated in Figure 1. At the top level (level 2), each is further splitted into two vectors, yielding a total of four lists:
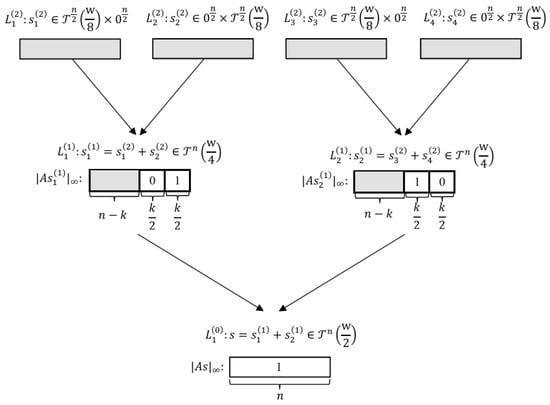
Figure 1.
The tree structure of Rep-0. The shaded regions represent the parts where the matching operation has not been performed.
The merge process proceeds level by level. At each step, we perform both exact matching and approximate matching, employing the LSH-Odlyzko method from Section 2.3 for the latter. To ensure that expect one solution survives after merging, the parameter k must satisfy . More precisely, k is calculated as
The pseudocode of Rep-0 is presented in Algorithm 2.
| Algorithm 2 Rep-0 |
| Input: An LWE public key , weight w |
| Output: Secret vector satisfying of ⊥ if no such secret is found |
| 1: Enumerate four level-2 lists as above. |
| 2: Choose k that satisfies . |
| 3: Merge and into using approximate matching on coordinates and exact matching on the other coordinates. |
| 4: Merge and into similarly. |
| 5: Merge and into using LSH on the remaining coordinates, and filter out any vector not in . |
| 6: If is non-empty, return any ; otherwise, return ⊥. |
After Step 3–4 in Algorithm 2, we obtain two level-1 lists with the following structure:
This means that vectors in satisfy on coordinates (exact matching) and on another coordinates (approximate matching), while vectors in satisfy on coordinates and on the other coordinates.
Step 5 in Algorithm 2 merges and using LSH-Odlyzko on the coordinates that were not involved in the previous matching steps. This finds pairs such that and are 1-close in the -norm, which ensures that satisfies with .
The correctness of Algorithm 2 follows from the representation technique: each valid secret s has multiple representations as , and we expect that one of these representations survives the merging process. The LSH-based matching efficiently identifies pairs that satisfy Equation (12) without explicitly checking all possible pairs.
Let denote the common size of the lists at level j, for . We have
The space complexity is determined by the maximum list size encountered during the merging process:
The time complexity is dominated by the largest list size and the cost of LSH-based merging at each level:
Here, the last equality follows from Equation (5). The bucket size B is a parameter that needs to be optimized.
3.2. Rep-1: Optimized LSH-Based MitM Attacks
Rep-1 generalizes Rep-0 by allowing more flexible decompositions. In addition to representing non-zero entries of s as sums of non-zero entries in and , Rep-1 also allows zero entries in s to be represented as or . This increases the number of representations and allows for a more efficient search tree.
We now describe Rep-1 with depth-3, as illustrated in Figure 2. The ternary LWE secret vector is decomposed as
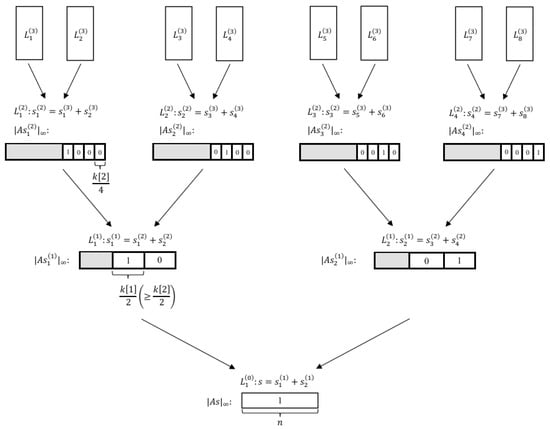
Figure 2.
The tree structure of Rep-1 with depth 3. The shaded regions represent the parts where the matching operation has not been performed.
Here, is a parameter that controls the number of additional entries used to represent zeros in s. The total number of representations at level 1 is
Each is further decomposed into two vectors at level 2:
The number of representations at level 2 is
Finally, at level 3, Rep-1 enumerates the vectors directly. The merging process uses a combination of exact and approximate matching at each level, with the number of matched coordinates chosen to satisfy
The pseudocode of Rep-1 is outlined in Algorithm 3.
| Algorithm 3 Rep-1 with Depth 3 |
| Input: An LWE public key , weight w |
| Output: Secret vector satisfying of ⊥ if no such secret is found |
| 1: Enumerate eight level-3 lists with weights as above. |
| 2: Compute from and merge pairs into four level-2 lists using exact and approximate matching. |
| 3: Compute from and merge into two level-1 lists using exact and approximate matching. |
| 4: Merge level-1 lists into using LSH on the remaining coordinates, and filter out any vector not in . |
| 5: If is non-empty, return any ; otherwise, return ⊥. |
Let denote the common size of the lists at level j, for . We have
where .
The space complexity is determined by the maximum list size encountered during the merging process:
The time complexity is dominated by the largest list size and the cost of LSH-based merging at each level:
where is the cost at level i for ,
The parameters are optimized to minimize the overall complexity.
4. LSH-Based MitM Attacks on Ternary LWE via Quantum Walks
In this work, we develop new LSH-based MitM quantum algorithms for ternary LWE, which transform the key recovery problem into a graph search task amenable to quantum walks. We first present QRep-0, the quantum adaptation of Rep-0, to establish the foundational approach. We then introduce QRep-1, which builds upon Rep-1 and achieves a lower complexity through enhanced representation techniques.
4.1. QRep-0: Foundational Instantiation of LSH-Based MitM Quantum Algorithms
The ternary LWE problem aims to recover a ternary secret vector satisfying , with a ternary error vector e. We cast this cryptographic recovery problem as a graph search task solvable by quantum walks, where marked vertices represent valid LWE solutions.
Rep-0 features a level-2 search tree, as illustrated in Figure 1. The quantum walk operates on a graph constructed as the Cartesian product of four identical Johnson graphs. The construction begins with the four level-2 lists , each of size . From these, we define restricted subsets of size , where is a parameter to be optimized. Setting and , the graph is formally given by
Each vertex is a 4-tuple . Two vertices u and v are adjacent if and only if, for some index j, the components of u and v differ by exactly one element, while the other three components are identical.
The data structure associated with a vertex in comprises all intermediate lists generated during the execution of Rep-0, which takes the vertex’s 4-tuple as its level-2 input lists. Here, corresponds to the j-th list at level-i, for and .
A vertex is marked if its resultant top-level list contains at least one valid ternary secret s satisfying and . This direct correspondence guarantees that finding any marked vertex solves the original LWE problem.
We begin by explaining the role of the parameter : it governs the trade-off between the setup cost of QRep-0 and the cost of the quantum walk required to reach a marked vertex.
When is large (close to 1), the setup cost dominates the overall complexity. In the extreme case of , all vertices become marked (since ), and QRep-0 reduces to the classical Rep-0 method, no longer relying on quantum walk.
Conversely, when is small (close to 0), the setup cost is minimized, but the fraction of marked vertices becomes negligible. As a result, the cost of amplifying these marked vertices via quantum walk becomes the dominant factor in the overall complexity.
We now analyze the quantum resources—specifically, circuit width and depth—required by QRep-0 as detailed in Algorithm 4.
| Algorithm 4 QRep-0 |
| Input: An LWE public key , weight w |
| Output: Secret vector satisfying or ⊥ if no such secret is found. |
|
1: Prepare the initial state (normalization omitted): |
| 2: Repeat times: |
|
(2.1) Apply the phase flip if u is marked: |
| (2.2) Perform the quantum walk for steps. |
| 3: Measure the register |
| 4: If is non-empty, return any ; otherwise, return ⊥. |
Let denote the size of level-i lists in QRep-0, for . These sizes follow the recurrence relations:
The quantum circuit width, which corresponds to the space complexity, is determined by three registers: the vertex register encoding a 4-tuple of subsets , requiring qubits; the coin register of similar size; and the data register , which dominates the space complexity with qubits. Hence, the overall circuit width (space complexity) is given by
The circuit depth, which corresponds to the time complexity, follows the quantum walk complexity:
where encompasses the initial state preparation and data structure construction, captures the cost per quantum walk step including data updates, and represents the phase oracle for marked vertices.
From Equation (11), the spectral gap of is
Since the classical Rep-0 algorithm yields, in expectation, a single element in , the fraction of marked vertices corresponds to the probability that all four subsets contain the necessary elements to reconstruct s. This fraction is given by
To determine the circuit depth, we analyze the setup cost and update cost for the quantum walk in QRep-0. Following the methodology in Section 6 of [24], these costs correspond to the classical computational complexity of constructing and updating the hierarchical data structure used in Rep-0.
The setup cost involves creating the hierarchical lists according to Rep-0. The level-2 lists (for ) are constructed by randomly sampling elements from . The level-1 lists such as are formed by mergeing and via exact matching and LSH. Finally, the level-0 list is built from the two level-1 lists using LSH. Therefore,
The update cost involves involves inserting or deleting an element from one of the level-2 lists. Without loss of generality, we assume the element to be updated, denoted as x, belongs to . The update of x in can be performed in time .
The insertion or deletion of x subsequently triggers updates in the level-1 list , which is formed by merging and . Specifically, this requires inserting or deleting all elements that are constructed by pairing x with some , where x and y satisfy the matching conditions on k coordinates: approximate matching on coordinates and exact matching on the other coordinates.
To analyze the number of such elements y (and thus the corresponding z) and the time complexity of locating them, we employ the following theorem:
Theorem 2.
Given an element and a list L of size with independent and identically distributed elements drawn uniformly from , there exists a classical algorithm that can find a -fraction of satisfying for some set I of size and for some set J of size . The time complexity of this algorithm is
where the first term corresponds to the expected number of elements y that meet the above conditions.
Proof.
A detailed derivation of this result is provided in Appendix A. □
Applying Theorem 2, the time required to update due to the modification of x is given by
The number of elements that need to be updated is . For each such z, applying Theorem 2 again, the time required to update the level-0 list is . Therefore, the total update time for the level-0 list is
Consequently, the overall update cost is given by
An important observation is that and satisfy the relation . Combining this observation with Equations (31)–(33) and , we obtain the circuit depth (time complexity) of QRep-0:
The parameter is chosen to minimize the overall time complexity by balancing the two dominant terms in the expression: the setup cost and the cost of performing the quantum walk to find a marked vertex .
To achieve this balance, we set the exponents of the two terms equal to each other:
Solving this equation for yields the optimal value .
4.2. Concrete Security Analysis of QRep-0
We now present the concrete security analysis of our foundational QRep-0 algorithm and compare it with the vHKM’s QRep-0. Table 1 evaluates both methods on major ternary-LWE-based cryptographic schemes that were also analyzed by van Hoof et al. [18], including NTRU variants (Encrypt and Prime), BLISS signatures, and GLP signatures. These schemes all rely on the hardness of ternary LWE, where both the secret and error vectors have entries in .

Table 1.
Comparative analysis of bit complexity: our QRep-0 vs. vHKM’s QRep-0.
The parameter triple for each scheme specifies the polynomial dimension n (ring dimension), the modulus q, and the weight w (number of non-zero entries in the ternary secret vector). The complexity is measured in , where T represents the time complexity of the attack. For quantum walk-based combinatorial attacks, including both our approach and vHKM’s method, the time complexity T and quantum space complexity M (measured in qubits) are essentially equivalent, i.e., . This resource equivalence arises because both methods rely on quantum walks over Johnson graphs that require storing the entire quantum state during computation.
Table 1 provides concrete complexity estimates for QRep-0. Across all cryptographic schemes evaluated, our QRep-0 implementation demonstrates superior performance over the vHKM variant in all cases except for BLISS I+II. As will be shown subsequently, when enhanced with improved representation techniques, our quantum algorithm achieves comprehensive advantage over the vHKM approach.
As shown in Table 1, our QRep-0 implementation outperforms the vHKM variant in all cases except for BLISS I+II. As will be shown subsequently, when enhanced with improved representation techniques, our quantum algorithm achieves comprehensive advantage over the vHKM approach.
4.3. QRep-1: Improved LSH-Based MitM Quantum Algorithms
Following the introduction of the foundational instantiation, we proceed to QRep-1—a superior instantiation of our quantum algorithm which leverages a more powerful representation technique. In this instantiation, the depth of the search tree is also treated as an optimization parameter.
We begin by describing QRep-1 with a depth of 3; its search tree structure is illustrated in Figure 2. Since the top level (level 3) contains 8 lists, the quantum walk is performed on the Cartesian product of 8 identical Johnson graphs. Consider subsets of size where parameter balances the quantum walk cost.
The spectral gap of the graph is , and the fraction of marked vertices is .
Analogously to Section 4.1, we can recursively derive the list sizes from level 2 down to level 0:
The space complexity of QRep-1 with depth 3 is
Similarly, the setup cost of the quantum walk for QRep-1 with depth 3 is
where is the setup cost at level i for ,
The parameters are optimized to minimize the overall complexity.
The update cost of the quantum walk for QRep-1 with depth 3 is
where represents the update cost at level i for .
Following an analysis similar to that in Section 4.1 and applying Theorem 2, we establish the relationship between the update cost and setup cost at each level: , and consequently . This relationship enables us to estimate the time complexity of QRep-1 as follows:
Similarly, for QRep-1, we balance the setup cost and the search cost to find the optimal . The balancing equation is . Solving this equation gives the optimal value .
A similar analysis at depth 4 gives . This demonstrates that the performance of QRep-1 converges to that of Rep-1 as the depth of the classical search tree increases.
4.4. Concrete Security Analysis of QRep-1
This subsection presents a comprehensive security analysis of our optimized QRep-1 algorithm, comparing it against previous quantum combinatorial attacks and lattice-based quantum sieving methods. Table 2 extends our evaluation to include additional ternary-LWE-based schemes from the NTRU-IEEE family, using the same methodology established in Section 4.2.
Table 2.
Comparative analysis of bit complexity for ternary-LWE schemes.
All evaluated schemes rely on the hardness of ternary LWE with secret and error vectors restricted to entries. The parameter triple for each scheme specifies the polynomial dimension, modulus, and weight of the secret vector, respectively. The complexity is measured in two forms: represents the base-2 logarithm of the time complexity, while expresses the time complexity relative to the search space size S, providing a normalized measure of efficiency.
Our QRep-1 algorithm achieves a concrete complexity bound of approximately , substantially improving upon the bound of vHKM’s quantum combinatorial attack. This represents a significant reduction in the gap between asymptotic predictions and concrete performance. As shown in Table 2, our method demonstrates dramatic runtime improvements over vHKM, with speedup factors ranging from for NTRU-Enc-821 to for NTRU-Prime-761. For signature schemes, we observe speedups of for BLISS I+II and for GLP I.
The comparison with quantum sieving reveals a nuanced security landscape. While lattice-based attacks maintain advantages for most parameter sets, our combinatorial approach demonstrates superiority for small-weight parameters. This divergence highlights the importance of considering both attack paradigms in security assessments.
It is crucial to distinguish the resource models between these approaches. Quantum walk-based combinatorial attacks (including both our QRep-1 and vHKM’s) exhibit equivalence between time and quantum space complexity due to the quantum walk framework requiring storage of the entire quantum state. In contrast, quantum sieving employs a hybrid classical-quantum model where only the locality-sensitive filtering step is quantumized, resulting in a two-component resource model with both classical and quantum memory requirements.
Our combinatorial method leverages representation techniques derived from subset-sum or knapsack problems. This approach has strong theoretical foundations: for knapsack-type distributions, it can be rigorously proven that pathological instances constitute an exponentially small fraction, enabling the construction of provable probabilistic algorithms that avoid heuristics [15]. Experimental validation in prior work [15] confirms that observed runtimes align closely with theoretical predictions, providing enhanced precision in security estimates compared to lattice reduction heuristics that rely on unproven assumptions like the Geometric Series Assumption.
Our QRep-1 algorithm establishes the new state of the art for quantum combinatorial attacks on ternary LWE, offering both theoretical advances and practical security implications for post-quantum cryptography standardization.
5. LSH-Based MitM Quantum Algorithms with Polynomial Qubits
5.1. The Impact of Memory Models
Section 4 established the state of the art for quantum combinatorial attacks in terms of time complexity, operating under the strong QRAQM assumption. This model, which allows for coherent, efficient queries to an exponentially large quantum memory, is fundamental to the optimal performance of quantum walk-based approaches like our QRep0 and QRep1. However, the QRAQM model presents a significant barrier to practical implementability, as it requires maintaining and coherently manipulating a number of qubits that grows exponentially with the problem size—a requirement far beyond the capabilities of current and foreseeable quantum hardware due to constraints on qubit count, coherence time, and error rates.
In contrast, the QRACM model offers a more pragmatic alternative for early quantum cryptanalysis. The QRACM model assumes that large amounts of data can be stored in classical memory (which is cheap and abundant) and accessed in a quantum superposition—an operation often considered more feasible than full QRAQM. While this access may incur a polynomial overhead, it drastically reduces the quantum hardware requirements to only qubits. This distinction between QRAQM and QRACM is critical for assessing the practical viability of quantum algorithms. Our work directly addresses this implementability challenge by introducing a hybrid algorithm that functions efficiently under the more realistic QRACM assumption.
This leads to two distinct algorithmic paradigms for quantum combinatorial attacks: one prioritizing theoretical time efficiency (using quantum walks under QRAQM), and the other minimizing quantum hardware requirements for practical realization (using claw-finding under QRACM). The existence of this trade-off underscores that both asymptotic complexity and concrete resource constraints must be considered for a comprehensive security assessment.
Building on Benedikt’s [19] application of the Chailloux et al. [20] (CNPS) quantum claw-finding technique to ternary LWE, we extend this line of work through a novel integration with the Kirshanova–May [17] framework. This hybrid construction operates efficiently with only qubits under the QRACM model. We now detail this approach.
5.2. Reformulating LWE Key Recovery as a Consistent Claw-Finding Problem
Let be a ternary LWE secret vector, and consider a representation , where for some . We rewrite the LWE identity given in Equation (12) for convenience:
Let . We define a pair of random, efficiently computable functions and (i.e., ) given by
A 1-close claw for is defined as a pair that satisfies .
While every representation of the secret s yields a 1-close claw, the converse is not true: a 1-close claw pair does not necessarily satisfy . Define a 1-close claw pair as consistent when . The representation of s is then in one-to-one correspondence with a consistent 1-close claw .
Consequently, the problem of recovering LWE secret s reduces to finding a consistent 1-close claw. The CNPS algorithm serves as an effective approach for solving the claw finding problem, as it utilizes only qubits, which aligns with our objectives. We now present a variant of CNPS, recently proposed by Benedikt and tailored for addressing the LWE problem, as detailed in Algorithm 5.
| Algorithm 5 Quantum Consistent 1-Close Claw Finding |
| Input: Random functions and |
| Output: A consistent 1-close claw |
| 1: Define for . |
| Construct a sorted list (by the second entry): |
| 2: Execute amplitude amplification using the following subroutines: |
| (2.1) : Prepare the quantum state |
| (2.2) : Apply the set-membership oracle |
|
where |
| 3: Amplitude amplification eventually yields a state . Measure this state. |
| 4: For the measured , search for a corresponding such that forms a consistent 1-close claw. |
Algorithm 5 identifies a consistent 1-close claw with qubits in two phases. First, it constructs a classically sorted list L. Then, it applies amplitude amplification to process a superposition of candidates. A set-membership oracle for L is used to find an L-suitable , i.e., one for which a corresponding exists such that and constitute a consistent 1-close claw.
Let R denote the number of consistent 1-close claws. The parameter r must satisfy the constraint to guarantee the existence of at least one claw satisfying . Since a uniformly random can be extended to a consistent 1-close claw with probability , the list size parameter ℓ must consequently satisfy .
Regarding the construction of the classic list L, the original CNPS algorithm builds the list in an element-wise manner using Grover search. However, Benedikt observed that Grover search offers no asymptotic advantage when multiple solutions are required. Consequently, his method employs a classical algorithm proposed by May to construct L. To achieve more accurate security estimates for practical cryptographic schemes, we adopt the LSH-based MitM technique introduced by Kirshanova and May for building L.
Recall the search tree structure of Rep-0 and Rep-1 from Section 3. We can set and . This ensures that contains at least one pair , and the set derived from contains a -suitable such that forms a consistent 1-close claw.
5.3. Quantum Consistent 1-Close Claw Finding for Rep-0
To make the better use of the representation technique, we reduce the size of list L by narrowing the search space for . This is accomplished by adjusting the weight constraints to and , where . Consequently, the number of representations becomes
With this adjustment, the sizes of the level-2 and level-1 lists are given as follows:
The corresponding parameter k satisfies
It follows that
which is the constraint that the parameter ℓ must satisfy.
Using Rep-0, the list is constructed classically, requiring time and space complexities of
Let . In Step 2.1 of Algorithm 5, subroutine begins by preparing a uniform superposition over , which corresponds to a ternary Dicke state. This state can be constructed using qubits in linear time. Subsequently, executes a Grover search—without the final measurement—to generate the state . The overall qubit requirement for remains . Due to the randomness of , any satisfies with probability , leading to a runtime of
For Step 2.2 of Algorithm 5, the quantum set-membership oracle for L operates with time complexity and utilizes qubits [19].
A uniformly random can be extended to a consistent 1-close claw with probability . This probability distribution remains unchanged when sampling from . Consequently, the expected number of consistent 1-close claws with is . It follows that for any , the probability of is given by
Applying Equation (6), the runtime complexity for Step 2 of Algorithm 5 becomes
The space requirement for this step is qubits.
Step 3 of Algorithm 5, which leverages the sorted structure of L, executes in time . The overall time complexity of the algorithm for Rep-0 is therefore bounded by
with total resource requirements of classical memory and qubits.
5.4. Concrete Security Analysis of Rep-0 Instantiation
We provide concrete complexity estimates for the quantum consistent 1-close claw finding subroutine (Rep-0 instantiation) in Table 3.
Table 3.
Bit complexities for the quantum consistent 1-close claw finding subroutine (Rep-0 instantiation).
The parameter triple for each scheme specifies the polynomial dimension, the modulus, and the weight of the secret vector, respectively. The complexity is measured in , where T represents the time complexity of the classical–quantum hybrid attack. The quantum space complexity, corresponding to the number of qubits required, is polynomial in n for all instances. The classical memory complexity, measured in , is often exponential; a value of 0 in Table 3 indicates that the required classical memory is polynomial.
We further consider the trade-off between time and classical memory. By constraining the available classical memory, we can optimize the time complexity of our algorithm. We present the trade-off curves for five representative examples, as shown in Figure 3. A similar analysis can be conducted for other parameter sets.
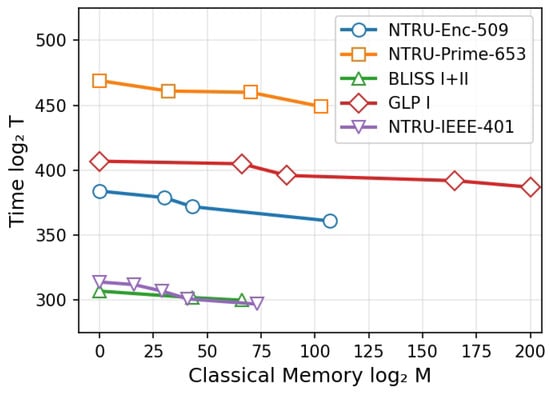
Figure 3.
Time–classical memory trade-offs for five representative schemes under the Rep-0 instantiation.
5.5. Quantum Consistent 1-Close Claw Finding for Rep-1
Consider quantum consistent 1-close claw finding for Rep-1 with depth 3. Similar to Section 5.3, we adjusting the weight constraints to and , where . Consequently, the number of representations becomes
With this adjustment, the sizes of the level-i lists (for ) are given as follows:
where .
The corresponding parameter (for ) satisfies
Similarly, it follows that .
Using Rep-1, the list is constructed classically, requiring time and space complexity of
where represents the classical memory.
Let . Similar to the analysis from Section 5.3, we get
Thus, the runtime complexity for Step 2 of Algorithm 5 becomes
The overall time complexity of Algorithm 5 for Rep-1 with depth 3 is therefore bounded by
with total resource requirements of classical memory and qubits.
5.6. Concrete Security Analysis of Rep-1 Instantiation
We provide concrete complexity estimates for the quantum consistent 1-close claw finding subroutine (Rep-1 instantiation) in Table 4.
Table 4.
Bit complexities for the quantum consistent 1-close claw finding subroutine (Rep-1 instantiation).
The parameter triple for each scheme specifies the polynomial dimension, modulus, and weight of the secret vector, respectively. The complexity is measured in two forms: represents the base-2 logarithm of the time complexity, while expresses the time complexity relative to the search space size S, providing a normalized measure of efficiency. The classical memory requirement is given by .
In the work of Benedikt [19], an asymptotic analysis of quantum claw-finding was provided for , concluding that the time complexity T falls within the range . In our concrete analysis shown in Table 4, for schemes where , the time complexity T ranges from to , which aligns reasonably well with the asymptotic predictions, demonstrating the consistency between our concrete implementations and theoretical asymptotic analysis.
We further examine the trade-off between time and classical memory by optimizing the time complexity under constrained classical memory resources. Figure 4 illustrates this trade-off for five representative examples, showing how attack time varies with available classical memory. Similar analysis can be extended to other parameter sets, providing a comprehensive understanding of the resource-performance landscape.
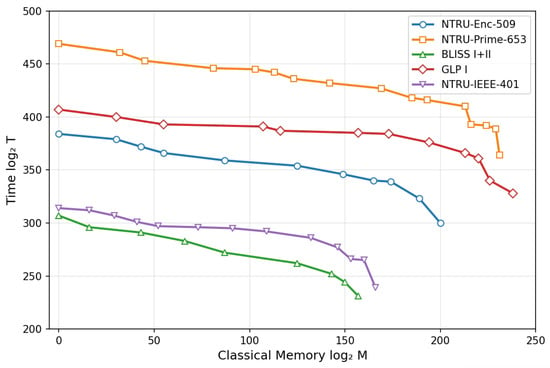
Figure 4.
Time–classical memory trade-offs for five representative schemes under the Rep-1 instantiation.
Finally, we consider the scenario where both quantum and classical memory complexities are constrained to polynomial bounds. Table 5 compares our method with the vHKM [18] approach under such strict polynomial memory constraints. The results demonstrate that our algorithm achieves superior performance across all evaluated schemes, consistently requiring fewer computational resources than the vHKM method while maintaining the same polynomial memory footprint.
Table 5.
Comparison of time complexity under polynomial memory.
6. Conclusions
In this work, we have advanced the frontier of quantum combinatorial cryptanalysis for ternary LWE. We introduced a novel quantum key search algorithm that effectively addresses the critical limitation of prior quantum approaches—the costly need to guess error coordinates. By reformulating the problem as a graph search and integrating the classical LSH-based Meet-in-the-Middle framework of Kirshanova and May with a quantum walk, our attack achieves a significant reduction in concrete time complexity. This allows it to bridge the gap between the asymptotic promise of quantum combinatorial attacks and their practical performance, establishing a new state of the art. Our comprehensive security analysis provides revised, and more precise, quantum security estimates for a wide range of practical cryptographic schemes, including NTRU, BLISS, and GLP. The primary and most effective defense against the quantum combinatorial attacks presented in this work is to appropriately increase the size of the search space. This can be achieved by scaling parameters such as the polynomial dimension n or the weight w of the secret vector.
Furthermore, we addressed the critical issue of quantum resource constraints by presenting a second algorithm tailored for a polynomial-qubit setting. By combining the Kirshanova–May framework with a quantum claw-finding technique, we demonstrated that effective attacks remain feasible even with minimal quantum memory, albeit at the cost of increased classical storage and time. This analysis provides the first concrete security assessment of major schemes under such practical quantum hardware limitations.
Funding
This work was supported by the Innovation Program for Quantum Science and Technology under Grant No. 2024ZD0300502 and the Beijing Nova Program under Grants No. 20220484128 and 20240484652.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Source code for reproducing our results is available at: https://gitee.com/li-yang777777/lwe (accessed on 22 October 2025).
Acknowledgments
The author thank the reviewers for their valuable feedback and insightful suggestions, which greatly improved this manuscript.
Conflicts of Interest
The author declares no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| LWE | Learning with Errors |
| vHKM | van Hoof–Kirshanova–May algorithm |
| NTRU | Number Theory Research Unit |
| BLISS | Bimodal Lattice Signature Scheme |
| GLP | Güneysu–Lyubashevsky–Pöppelmann signature scheme |
| MitM | Meet-in-the-Middle |
| LSH | Locality-Sensitive Hashing |
| QRAQM | Quantum Random Access Quantum Memory |
| QRACM | Quantum Random Access Classical Memory |
| CNPS | Chailloux–Naya–Plasencia–Schrottenloher algorithm |
Appendix A. Proof of Theorem 2
We begin by introducing the combined approximate and exact matching hash function, which will be used in the proof of Theorem 2.
Let be a vector. We partition the coordinates into three disjoint sets:
- I: set of coordinates for approximate matching
- J: set of coordinates for exact matching
- Remaining coordinates for subsequent processing
The combined hash function is defined as:
where:
- Approximate hash component for coordinates I:with and random shift . Each coordinate maps to .
- Exact hash component for coordinates J:This is simply the identity function on the exact matching coordinates.
The overall hash label is the concatenation of these two components, forming a -dimensional vector.
We now proceed to prove Theorem 2.
Proof.
We analyze the complexity of Algorithm A1 for finding vectors that are approximately close to x on coordinates and exactly matching on coordinates.
In Step 2, the operations of hashing and sorting require both time and memory on the order of .
The expected count of elements in L whose hash values coincide with that of x is . Step 3 retrieves these candidates in time proportional to , after which we apply a filter to exclude vectors failing the condition .
The expected number of valid elements satisfying both the approximate condition on coordinates and exact equality on coordinates is . This arises because each coordinate in the approximate matching set admits 3 possible differences with probability , while exact matches occur with probability per coordinate.
Each iteration captures only a subset of valid elements. We demonstrate that the number of iterations specified in Step 4 suffices to recover nearly all valid vectors with high probability.
Consider a valid element and define event E as . Then
After repetitions, E happens with probability
Applying a union bound over all potentially valid vectors guarantees that, with high probability, a -fraction of all valid elements will be recovered.
□
| Algorithm A1 LSH-Odlyzko with Combined Approximate and Exact Matching |
| Input: A vector , a list L of size with i.i.d. uniform elements from , sets I () and J (). |
| Output: -fraction of satisfying and for all . |
| 1: Choose suitably. Choose . |
| 2: Apply to x and all vectors in L. Sort L according to their hash values. |
| 3: Output all y satisfying and . |
| 4: Repeat Steps 1-3 times. |
References
- Regev, O. New lattice-based cryptographic constructions. J. ACM 2004, 51, 899–942. [Google Scholar] [CrossRef]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. (Leveled) fully homomorphic encryption without bootstrapping. ACM Trans. Comput. Theory 2014, 6, 1–36. [Google Scholar] [CrossRef]
- Bos, J.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schanck, J.M.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS-Kyber: A CCA-secure module-lattice-based KEM. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy (EuroS&P), London, UK, 24–26 April 2018; pp. 353–367. [Google Scholar]
- Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schwabe, P.; Seiler, G.; Stehlé, D. Crystals-dilithium: A lattice-based digital signature scheme. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2018, 2018, 238–268. [Google Scholar] [CrossRef]
- Lyubashevsky, V.; Peikert, C.; Regev, O. On ideal lattices and learning with errors over rings. In Advances in Cryptology—EUROCRYPT 2010, Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, French Riviera, French, 30 May–3 June 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–23. [Google Scholar]
- IEEE Std 1363.1-2008; IEEE Standard Specification for Public Key Cryptographic Techniques Based on Hard Problems over Lattices. IEEE: Piscataway, NJ, USA, 2009. Available online: https://ieeexplore.ieee.org/document/4800404 (accessed on 10 March 2009).
- Bernstein, D.J.; Chuengsatiansup, C.; Lange, T.; van Vredendaal, C. NTRU Prime: Reducing Attack Surface at Low Cost. In Selected Areas in Cryptography—SAC 2017, Proceedings of the SAC 2017, 24th International Conference, Ottawa, ON, Canada, 16–18 August 2017; Adams, C., Camenisch, J., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 10719. [Google Scholar]
- Hülsing, A.; Rijneveld, J.; Schanck, J.; Schwabe, P. High-speed key encapsulation from NTRU. In Proceedings of the International Conference on Cryptographic Hardware and Embedded Systems, Taipei, Taiwan, 25–28 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 232–252. [Google Scholar]
- Ducas, L.; Durmus, A.; Lepoint, T.; Lyubashevsky, V. Lattice signatures and bimodal Gaussians. In Advances in Cryptology, Proceedings of the CRYPTO 2013: Annual Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 40–56. [Google Scholar]
- Güneysu, T.; Lyubashevsky, V.; Pöppelmann, T. Practical lattice-based cryptography: A signature scheme for embedded systems. In Cryptographic Hardware and Embedded Systems—CHES 2012, Proceedings of the 14th International Workshop, Leuven, Belgium, 9–12 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7428, pp. 530–547. [Google Scholar]
- Hoffstein, J.; Pipher, J.; Silverman, J.H. NTRU: A ring-based public key cryptosystem. In Algorithmic Number Theory, Proceedings of the Third International Symposium, Portland, OR, USA, 21–25 June 1998; Buhler, J.P., Ed.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 267–288. [Google Scholar]
- Howgrave-Graham, N. A hybrid lattice-reduction and meet-in-the-middle attack against NTRU. In Annual International Cryptology—CRYPTO 2007, Proceedings of the 27th Annual International Cryptology Conference, Santa Barbara, CA, USA, 19–23 August 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 150–169. [Google Scholar]
- May, A. How to meet ternary LWE keys. In Advances in Cryptology—CRYPTO 2021, Proceedings of the 41st Annual International Cryptology Conference, Virtual Event, 16–20 August 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 701–731. [Google Scholar]
- Howgrave-Graham, N.; Joux, A. New generic algorithms for hard knapsacks. In Advances in Cryptology—EUROCRYPT 2010, Proceedings of the 29th Annual International Conference on the Theory and Applications of Cryptographic Techniques, French Riviera, French, 30 May–3 June 2010; Springer International Publishing: Berlin/Heidelberg, Germany, 2010; pp. 235–256. [Google Scholar]
- Becker, A.; Coron, J.; Joux, A. Improved generic algorithms for hard knapsacks. In Advances in Cryptology—EUROCRYPT 2011, Proceedings of the 30th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Tallinn, Estonia, 15–19 May 2011; Springer International Publishing: Berlin/Heidelberg, Germany, 2011; pp. 364–385. [Google Scholar]
- Bonnetain, X.; Bricout, R.; Schrottenloher, A.; Shen, Y. Improved classical and quantum algorithms for subset-sum. In Advances in Cryptology—ASIACRYPT 2020, Proceedings of the 26th International Conference on the Theory and Application of Cryptology and Information Security, Daejeon, South Korea, 7–11 December 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 633–666. [Google Scholar]
- Kirshanova, E.; May, A. How to Find Ternary LWE Keys Using Locality Sensitive Hashing. In Proceedings of the IMA International Conference on Cryptography and Coding, Oxford, UK, 14–16 December 2021. [Google Scholar]
- van Hoof, I.; Kirshanova, E.; May, A. Quantum Key Search for Ternary LWE. In Post-Quantum Cryptography, Proceedings of the 12th International Workshop, Daejeon, South Korea, 20–22 July 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 117–132. [Google Scholar]
- Benedikt, B.J. Reducing the Number of Qubits in Solving LWE. In Post-Quantum Cryptography, Proceedings of the 16th International Workshop, Taipei, Taiwan, 8–10 April 2025; Springer International Publishing: Cham, Switzerland, 2025; pp. 231–263. [Google Scholar]
- Chailloux, A.; Naya-Plasencia, M.; Schrottenloher, A. An efficient quantum collision search algorithm and implications on symmetric cryptography. In Advances in Cryptology—ASIACRYPT 2017, Proceedings of the 23rd International Conference on the Theory and Applications of Cryptology and Information Security, Hong Kong, China, 3–7 December 2017; Springer International Publishing: Cham, Switzerland, 2017; pp. 211–240. [Google Scholar]
- Brassard, G.; Hoyer, P.; Mosca, M.; Tapp, A. Quantum amplitude amplification and estimation. arXiv 2000, arXiv:quant-ph/0005055. [Google Scholar] [CrossRef]
- Grover, L.K. Quantum computers can search arbitrarily large databases by a single query. Phys. Rev. Lett. 1997, 79, 4709–4712. [Google Scholar] [CrossRef]
- Magniez, F.; Nayak, A.; Roland, J.; Santha, M. Search via quantum walk. SIAM J. Comput. 2011, 40, 142–164. [Google Scholar] [CrossRef]
- Ambainis, A. Quantum walk algorithm for element distinctness. SIAM J. Comput. 2007, 37, 210–239. [Google Scholar] [CrossRef]
- Bonnetain, X.; Chailloux, A.; Schrottenloher, A.; Shen, Y. Finding many collisions via reusable quantum walks: Application to lattice sieving. In Advances in Cryptology—EUROCRYPT 2023, Proceedings of the 42nd Annual International Conference on the Theory and Applications of Cryptographic Techniques, Lyon, France, 23–27 April 2023; Springer International Publishing: Cham, Switzerland, 2023; pp. 221–251. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).