
Construction of Legal Knowledge Graph Based on Knowledge-Enhanced Large Language Models


Abstract
1. Introduction
- (1)
- Based on the principle of legal ontology consensus reuse [12,13], the structure of the CLKG is constructed combined with the professional knowledge of legal experts, where nine entities and two relationships are defined. The corpus of knowledge in this paper is derived from the Criminal Code of the People’s Republic of China and Annotated Code (New fourth edition) [14], supplemented by Internet encyclopedia data.
- (2)
- A JKEM is proposed based on prior knowledge embedded in LLM, which is fine-tuned with the prefix of prior knowledge data. The model demonstrates high recognition performance independent of (on the condition of not depending on) artificially set features, where the corresponding knowledge triples can be correctly extracted from legal annotations in natural language, achieving a knowledge extraction accuracy of .
- (3)
- Based on the superior performance of the legal JKEM, a knowledge graph of Chinese legal is constructed, which contains 3480 pairs of knowledge triples composed of 9 entities and 2 relationships. It provides structured knowledge information to further facilitate legal knowledge inference.
2. Related Works
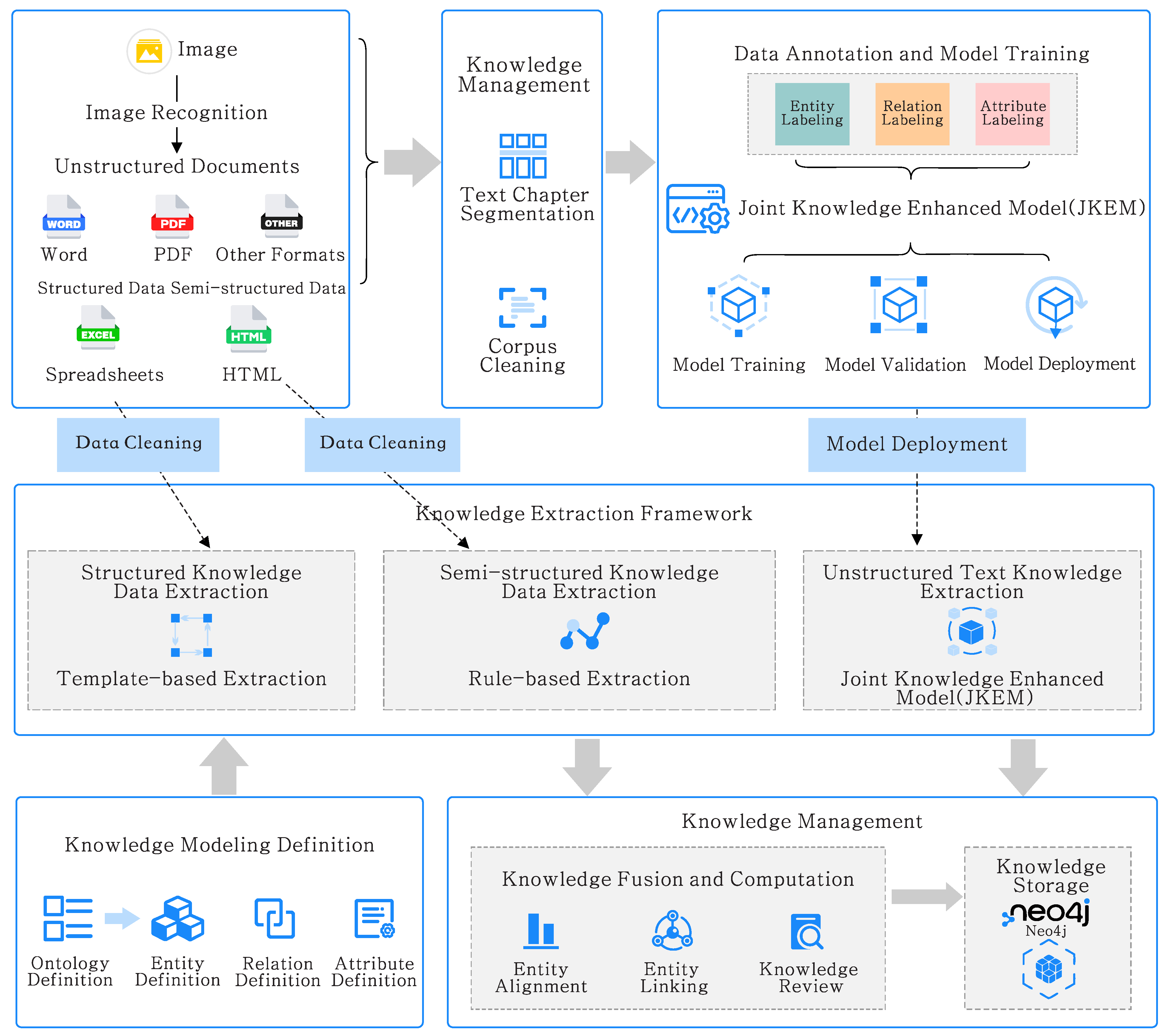
3. CLKG Construction and Management Framework
3.1. The Knowledge Sources of CLKG
3.2. The Framework of CLKG
- (1)
- Entity–With (EW): Entities with relationships.Example: The concept of the crime of damaging environmental resources protection, the constitutive features of the crime of damaging environmental resources protection, etc.
- (2)
- Component–Whole (CW): Relationships between the whole and its components.Example: The crime of damaging environmental resources protection includes the crime of major environmental pollution accidents, the crime of endangering public safety includes the crime of placing dangerous substances and the crime of damaging transportation vehicles, etc.
3.3. Knowledge Annotation Scheme and Tools for CLKG
- (1)
- Fine annotation of entity location information: The BMEO (Begin, Middle, End, Other) character-level annotation strategy is adopted, where B is used to mark the starting position of the entity, M follows to represent the continuous characters within the entity, E marks the end of the entity, and O is applied to ordinary text characters of non-named entities. In this way, the entity boundaries can be accurately located and distinguished.
- (2)
- Detailed classification of entity category information: Nine specific entity categories are defined in this paper, which comprehensively cover the key elements and concepts in the legal knowledge graph. The specific classification details are shown in Table 2, which provides a rich semantic dimension for in-depth analysis.
- (3)
- Definition of entity relationship information: In order to deeply understand the interactions and connections between entities, this paper further clarifies two core relationship types, which form the basis of the complex associations between entities in the legal knowledge graph.
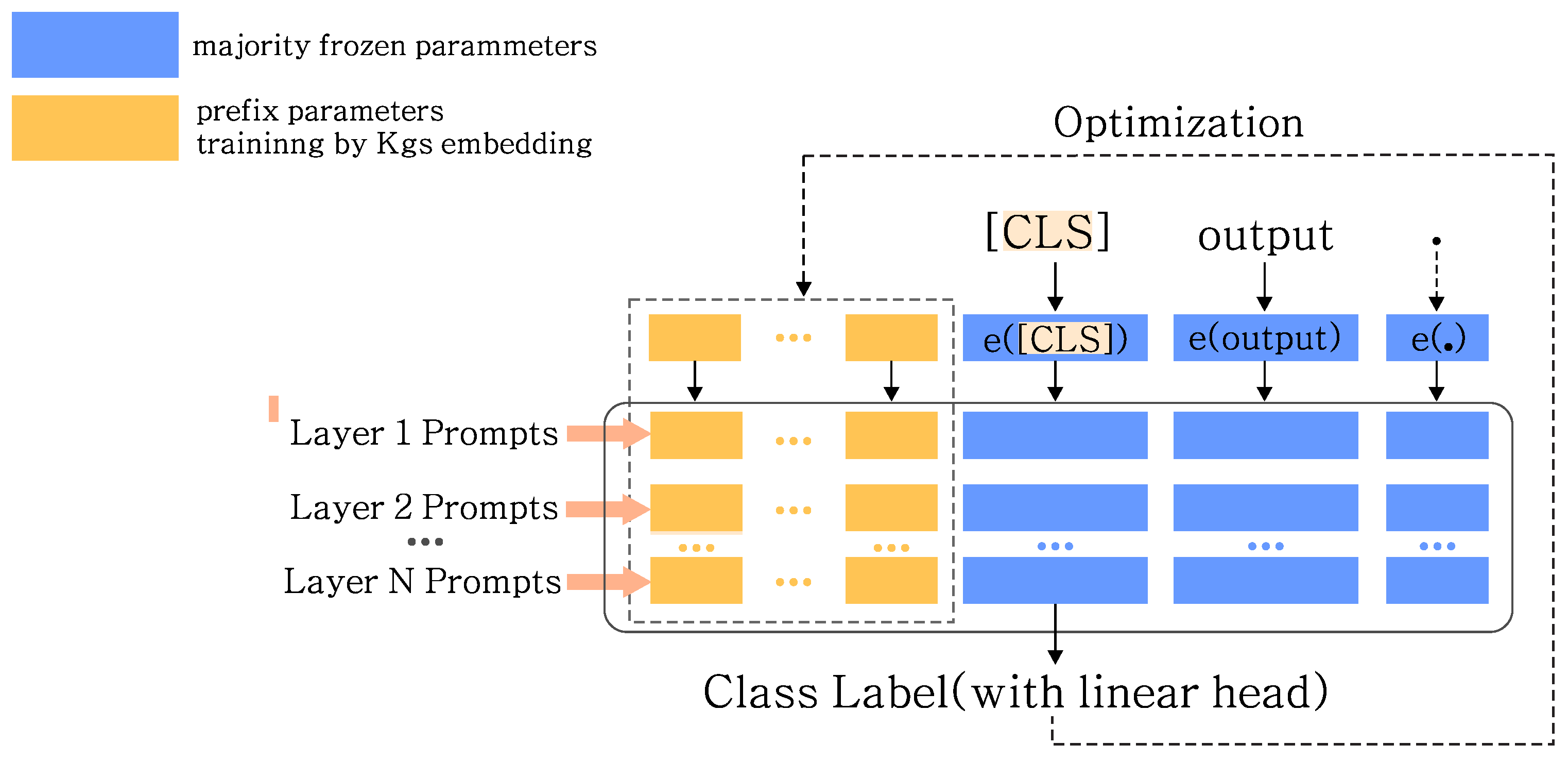
4. The Framework of JKEM
4.1. Overview of JKEM
4.2. Tasks Description
4.3. Objective Function
5. The Validation of JKEM
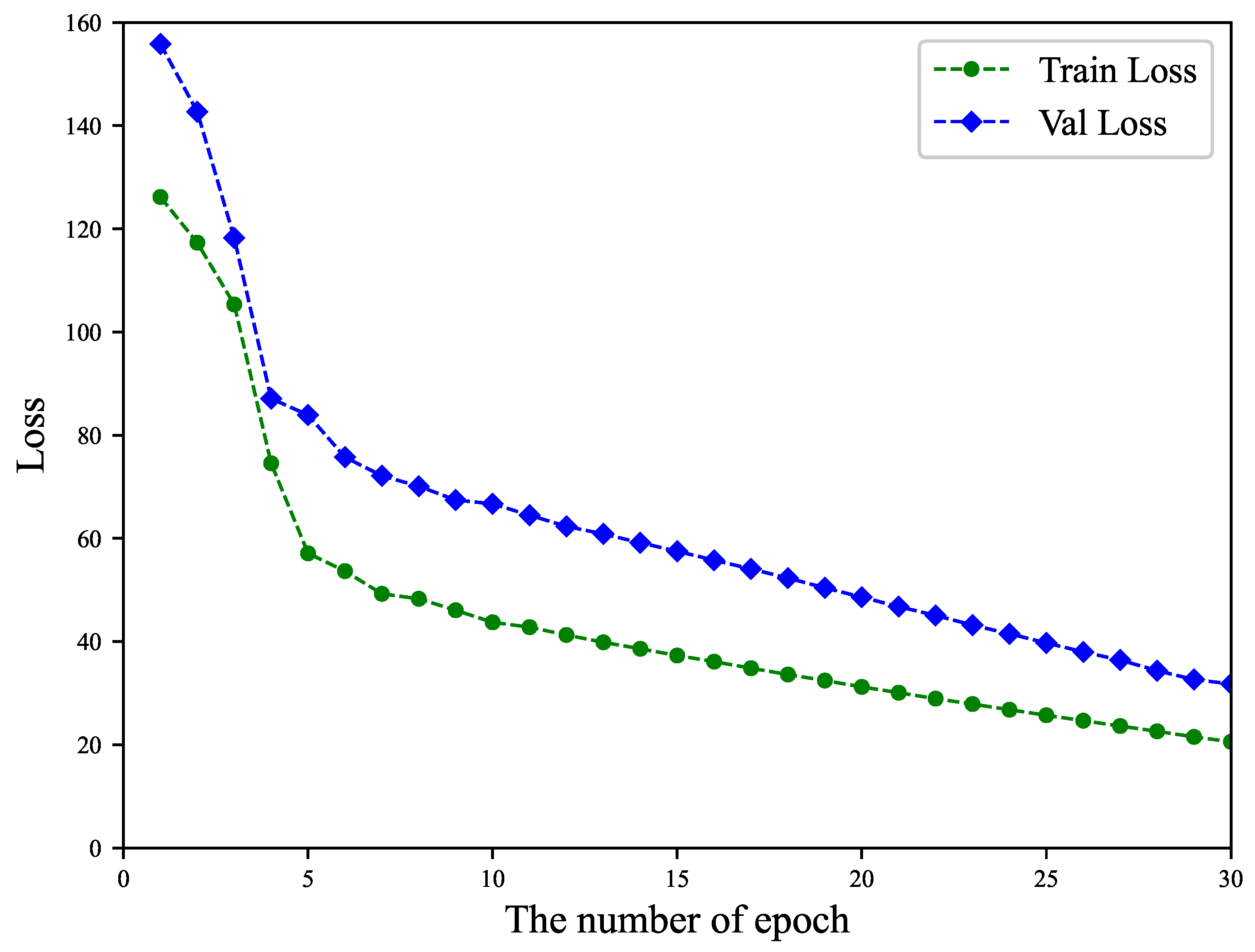
5.1. Experiment Setting
5.2. Corpus Information
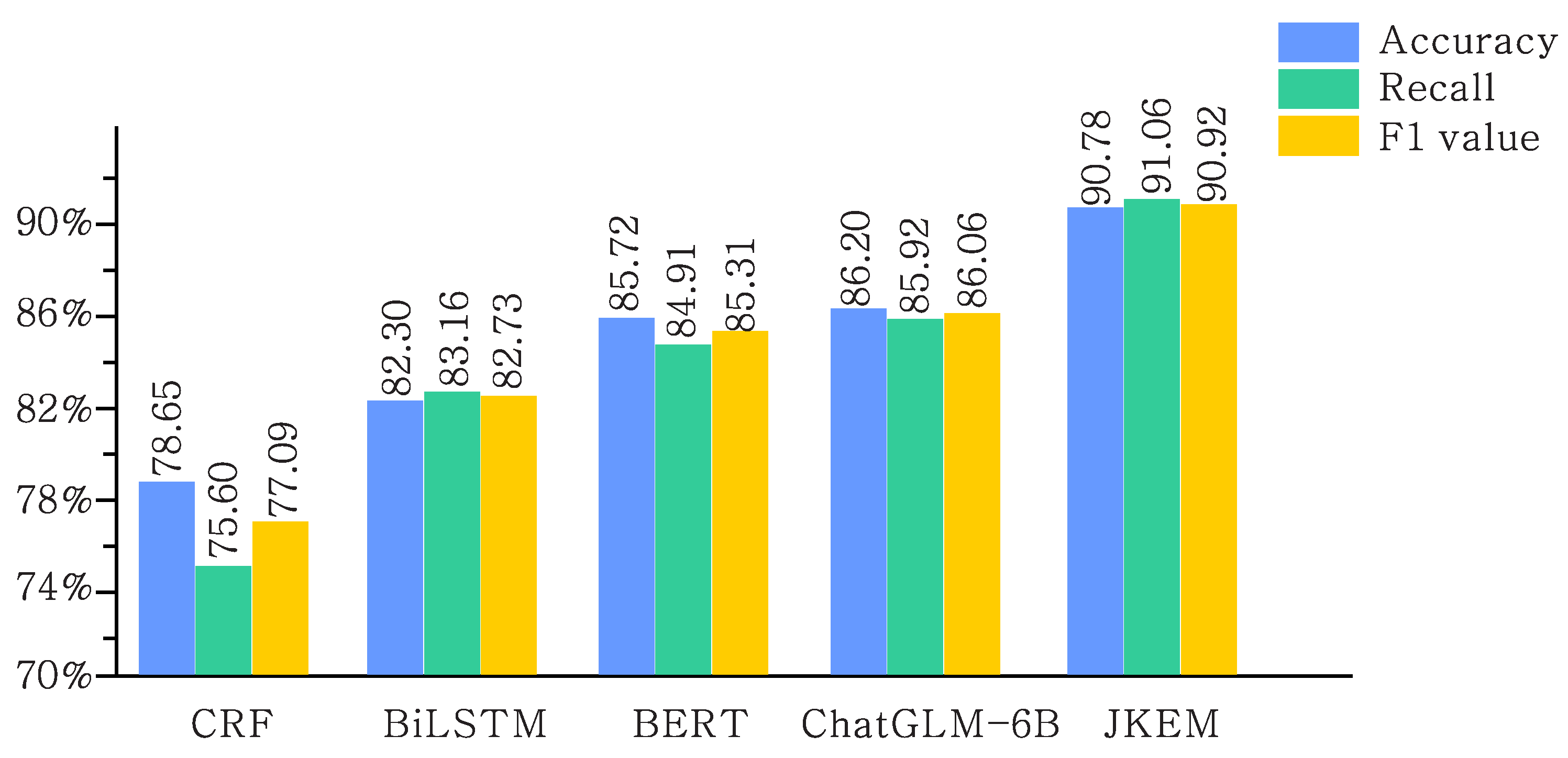
5.3. Experimental Results and Comparison of the JKEM on the Legal Knowledge Corpus
- (1)
- Crime entity: The JKEM model has achieved excellent results in the recognition of crime entities, with an accuracy and recall of and , respectively, and an F1 value as high as . which fully demonstrates the model’s strong ability to accurately capture the core crime information in legal texts.
- (2)
- Concept entity, punishment entity, and legal provision entity: For these three key legal entities, the model also shows good prediction performance, with the accuracy and recall rates remaining at a relatively high level, and the F1 scores stably ranging from to . This indicates that the JKEM model has significant advantages in understanding and distinguishing legal concepts, punishment measures, and legal provisions.
- (3)
- Constitutive characteristic entity and judging standard entity: Although the prediction of these two types of entities is relatively more challenging, the model still achieved relatively satisfactory results, with F1 values reaching and , respectively, which reflects the robustness of the model in dealing with complex features and identification standards in legal texts.
- (4)
- Judicial interpretation entity and defense entity: The model also performed well in the recognition of judicial interpretation and defense entities, especially the recognition of defense entities achieved perfect accuracy and recall (both ). This further verifies the ability of the JKEM model to capture highly specialized and precision-demanding content in legal texts.
- (5)
- Case entity: Compared with other entity types, the recognition effect of case entity is slightly insufficient, with accuracy and recall rates of and , respectively, and an F1 value of . This may be related to the diversity and complexity of case descriptions, suggesting that the model needs to be further optimized in the future to better handle such texts.
- (1)
- Entity–With relationship: When identifying the basic association relationship between entities, the model also performed well, with high accuracy and recall ( and , respectively), and F1 value of , which shows that the JKEM model has good ability in understanding the basic relationship between entities in legal texts.
- (2)
- Component–Whole relationship: In the more sophisticated semantic relationship recognition task, i.e., the recognition of the whole–part relationship, the model demonstrated extremely high performance, with accuracy and recall reaching and , respectively, and F1 value as high as . This result fully demonstrates the superiority of the model in capturing the complex semantic structure in legal texts.
6. The Construction of CLKG
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A Survey on Knowledge Graphs: Representation, Acquisition, and Applications. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Kejriwal, M. Knowledge Graphs: A Practical Review of the Research Landscape. Information 2022, 13, 161. [Google Scholar] [CrossRef]
- Liu, P.; Qian, L.; Zhao, X.; Tao, B. Joint Knowledge Graph and Large Language Model for Fault Diagnosis and Its Application in Aviation Assembly. IEEE Trans. Ind. Inform. 2024, 20, 8160–8169. [Google Scholar] [CrossRef]
- Vrandečić, D.; Krötzsch, M. Wikidata: A Free Collaborative Knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; van Kleef, P.; Auer, S.; et al. DBpedia—A large-scale, multilingual knowledge base extracted from Wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Liu, P.; Qian, L.; Zhao, X.; Tao, B. The Construction of Knowledge Graphs in the Aviation Assembly Domain Based on a Joint Knowledge Extraction Model. IEEE Access 2023, 11, 26483–26495. [Google Scholar] [CrossRef]
- Hubauer, T.; Lamparter, S.; Haase, P.; Herzig, D.M. Use Cases of the Industrial Knowledge Graph at Siemens. In Proceedings of the Semantic Web—ISWC 2018, Cham, Switzerland, 8–12 October 2018; pp. 1–2. [Google Scholar]
- Al-Moslmi, T.; Gallofré Ocaña, M.; Opdahl, A.L.; Veres, C. Named Entity Extraction for Knowledge Graphs: A Literature Overview. IEEE Access 2020, 8, 32862–32881. [Google Scholar] [CrossRef]
- Li, J.; Sun, A.; Han, J.; Li, C. A Survey on Deep Learning for Named Entity Recognition. IEEE Trans. Knowl. Data Eng. 2022, 34, 50–70. [Google Scholar] [CrossRef]
- Wu, T.; You, X.; Xian, X.; Pu, X.; Qiao, S.; Wang, C. Towards deep understanding of graph convolutional networks for relation extraction. Data Knowl. Eng. 2024, 149, 102265. [Google Scholar] [CrossRef]
- Zheng, S.; Hao, Y.; Lu, D.; Bao, H.; Xu, J.; Hao, H.; Xu, B. Joint entity and relation extraction based on a hybrid neural network. Neurocomputing 2017, 257, 59–66. [Google Scholar] [CrossRef]
- He, C.; Tan, T.P.; Zhang, X.; Xue, S. Knowledge-Enriched Multi-Cross Attention Network for Legal Judgment Prediction. IEEE Access 2023, 11, 87571–87582. [Google Scholar] [CrossRef]
- Vuong, T.H.Y.; Hoang, M.Q.; Nguyen, T.M.; Nguyen, H.T.; Nguyen, H.T. Constructing a Knowledge Graph for Vietnamese Legal Cases with Heterogeneous Graphs. In Proceedings of the 2023 15th International Conference on Knowledge and Systems Engineering (KSE), Hanoi, Vietnam, 18–20 October 2023; pp. 1–6. [Google Scholar]
- State Council Legislative Affairs Office (Compiler). Criminal Law Code of the People’s Republic of China: Annotated Edition (Fourth New Edition); Annotated Edition; China Legal Publishing House: Beijing, China, 2018. [Google Scholar]
- Tagarelli, A.; Zumpano, E.; Anastasiu, D.C.; Calì, A.; Vossen, G. Managing, Mining and Learning in the Legal Data Domain. Inf. Syst. 2022, 106, 101981. [Google Scholar] [CrossRef]
- Re, R.M.; Solow-Niederman, A. Developing Artificially Intelligent Justice. Stanf. Technol. Law Rev. 2019, 22, 242. [Google Scholar]
- Remus, D.; Levy, F.S. Can Robots Be Lawyers? Computers, Lawyers, and the Practice of Law. Georget. J. Leg. Ethics 2015, 30, 501. [Google Scholar] [CrossRef]
- Yao, S.; Ke, Q.; Wang, Q.; Li, K.; Hu, J. Lawyer GPT: A Legal Large Language Model with Enhanced Domain Knowledge and Reasoning Capabilities. In Proceedings of the 2024 3rd International Symposium on Robotics, Artificial Intelligence and Information Engineering (RAIIE ’24), Singapore, 5–7 July 2024; pp. 108–112. [Google Scholar]
- Savelka, J. Unlocking Practical Applications in Legal Domain: Evaluation of GPT for Zero-Shot Semantic Annotation of Legal Texts. In Proceedings of the Nineteenth International Conference on Artificial Intelligence and Law (ICAIL ’23), Braga, Portugal, 19–23 June 2023; pp. 447–451. [Google Scholar]
- Ammar, A.; Koubaa, A.; Benjdira, B.; Nacar, O.; Sibaee, S. Prediction of Arabic Legal Rulings Using Large Language Models. Electronics 2024, 13, 764. [Google Scholar] [CrossRef]
- Licari, D.; Bushipaka, P.; Marino, G.; Comandé, G.; Cucinotta, T. Legal Holding Extraction from Italian Case Documents using Italian-LEGAL-BERT Text Summarization. In Proceedings of the Nineteenth International Conference on Artificial Intelligence and Law (ICAIL ’23), Braga, Portugal, 19–23 June 2023; pp. 148–156. [Google Scholar]
- Moreno Schneider, J.; Rehm, G.; Montiel-Ponsoda, E.; Rodríguez-Doncel, V.; Martín-Chozas, P.; Navas-Loro, M.; Kaltenböck, M.; Revenko, A.; Karampatakis, S.; Sageder, C.; et al. Lynx: A knowledge-based AI service platform for content processing, enrichment and analysis for the legal domain. Inf. Syst. 2022, 106, 101966. [Google Scholar] [CrossRef]
- Tong, S.; Yuan, J.; Zhang, P.; Li, L. Legal Judgment Prediction via graph boosting with constraints. Inf. Process. Manag. 2024, 61, 103663. [Google Scholar] [CrossRef]
- Bi, S.; Ali, Z.; Wu, T.; Qi, G. Knowledge-enhanced model with dual-graph interaction for confusing legal charge prediction. Expert Syst. Appl. 2024, 249, 123626. [Google Scholar] [CrossRef]
- Zou, L.; Huang, R.; Wang, H.; Yu, J.X.; He, W.; Zhao, D. Natural language question answering over RDF: A graph data driven approach. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 313–324. [Google Scholar]
- Chen, J.; Teng, C. Joint entity and relation extraction model based on reinforcement learning. J. Comput. Appl. 2019, 39, 1918–1924. [Google Scholar]
- Pan, S.; Luo, L.; Wang, Y.; Chen, C.; Wang, J.; Wu, X. Unifying Large Language Models and Knowledge Graphs: A Roadmap. IEEE Trans. Knowl. Data Eng. 2024, 36, 3580–3599. [Google Scholar] [CrossRef]
- Yang, R.; Zhu, J.; Man, J.; Fang, L.; Zhou, Y. Enhancing text-based knowledge graph completion with zero-shot large language models: A focus on semantic enhancement. Knowl.-Based Syst. 2024, 300, 112155. [Google Scholar] [CrossRef]
- Kumar, A.; Pandey, A.; Gadia, R.; Mishra, M. Building Knowledge Graph using Pre-trained Language Model for Learning Entity-aware Relationships. In Proceedings of the 2020 IEEE International Conference on Computing, Power and Communication Technologies (GUCON), Greater Noida, India, 2–4 October 2020; pp. 310–315. [Google Scholar]
- Zhang, Z.; Liu, X.; Zhang, Y.; Su, Q.; Sun, X.; He, B. Pretrain-KGE: Learning Knowledge Representation from Pretrained Language Models. In Findings of the Association for Computational Linguistics: EMNLP 2020; Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 16 November 2020; pp. 259–266. [Google Scholar]
- Zhang, J.; Chen, B.; Zhang, L.; Ke, X.; Ding, H. Neural, symbolic and neural-symbolic reasoning on knowledge graphs. AI Open 2021, 2, 14–35. [Google Scholar] [CrossRef]
- Abu-Salih, B. Domain-specific knowledge graphs: A survey. J. Netw. Comput. Appl. 2021, 185, 103076. [Google Scholar] [CrossRef]
- Mitchell, T.; Cohen, W.; Hruschka, E.; Talukdar, P.; Yang, B.; Betteridge, J.; Carlson, A.; Dalvi, B.; Gardner, M.; Kisiel, B.; et al. Never-ending learning. Commun. ACM 2018, 61, 103–115. [Google Scholar] [CrossRef]
- Cadeddu, A.; Chessa, A.; De Leo, V.; Fenu, G.; Motta, E.; Osborne, F.; Reforgiato Recupero, D.; Salatino, A.; Secchi, L. Optimizing Tourism Accommodation Offers by Integrating Language Models and Knowledge Graph Technologies. Information 2024, 15, 398. [Google Scholar] [CrossRef]
- Nakayama, H.; Kubo, T.; Kamura, J.; Taniguchi, Y.; Liang, X. Doccano: Text Annotation Tool for Human. Available online: https://github.com/doccano/doccano (accessed on 1 May 2020).
- Li, X.L.; Liang, P. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 4582–4597. [Google Scholar]
- Du, Z.; Qian, Y.; Liu, X.; Ding, M.; Qiu, J.; Yang, Z.; Tang, J. GLM: General Language Model Pretraining with Autoregressive Blank Infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 320–335. [Google Scholar]
- Goyal, A.; Gupta, V.; Kumar, M. Recent Named Entity Recognition and Classification techniques: A systematic review. Comput. Sci. Rev. 2018, 29, 21–43. [Google Scholar] [CrossRef]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the NAACL, San Diego, CA, USA, 16 June 2016; pp. 260–270. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Red Hook, NY, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Advantages | Disadvantages |
|---|---|---|
| Soft Prompts | 1. No additional training: Immediate utilization without the need for further model training. 2. Rapid Deployment: Enables swift implementation due to the absence of a training phase. | 1. Significant Randomness: Outputs can vary widely, leading to inconsistency. 2. Uncontrollable Results: Lack of precise control over the generated outputs. |
| Pipelined Scheme | 1. High Technical Maturity: Well-established methods with a solid foundation in existing research and practice. 2. Modular Approach: Allows for independent optimization of each stage in the pipeline. | 1. Labeled Data Requirement: Necessitates labeled training samples, which can be costly and time-consuming to obtain. 2. Cumulative Errors: Errors from each stage can propagate and accumulate, affecting final output quality. |
| Fine-tuning LLMs | 1. Strong Consistency: Ensures coherence and uniformity in the generated knowledge graph. 2.Error Mitigation: Avoids cumulative errors by integrating knowledge directly into the model. | 1. Labeled Data Requirement: Similarly, requires labeled training data, which may limit applicability in certain domains. 2. Heavy Training: Involves extensive computational resources and time for fine-tuning large models. |
| Entity Names | Entity Definitions | Entity Examples |
|---|---|---|
| Crime entity | The crime in criminal law | Crimes endangering national security, treason against the state, etc. |
| Concept entity | The definition of the crime | The crime of treason against the state refers to the act of colluding with foreign countries or overseas institutions, organizations, or individuals to endanger the sovereignty, territorial integrity, and security of the People’s Republic of China. |
| Constitutive characteristic entity | Object elements constituting a crime | The object of this crime is the People’s Republic of China, its territorial integrity, and security. |
| Judging standard entity | The standard for determining the crime and the difference from other crimes | The boundary between this crime and the crime of subverting state power, etc. |
| Punishment entity | The intensity of punishment | Whoever commits this crime shall be sentenced to life imprisonment or imprisonment of ten years or above. According to the provisions of Articles 56 and 113 of this Law, whoever commits this crime shall be additionally deprived of political rights and may be concurrently sentenced to confiscation of property. |
| Legal provision entity | Original legal text | Article 102 Whoever colludes with a foreign State to endanger the sovereignty, territorial integrity and security of the People’s Republic of China shall be sentenced to life imprisonment or fixed-term imprisonment of not less than 10 years. etc. |
| Judicial interpretation entity | The interpretations made by the highest judicial organ of the state on specific application legal issues in the process of applying the law. | The Supreme People’s Court and the Supreme People’s Procuratorate issued the “Interpretation on Several Issues Concerning the Specific Application of Laws in Handling Criminal Cases of Organizing and Utilizing Cult Organizations” (1999, 10, 20 Interpretation No. 19 [1999]), etc. |
| Defense entity | Sample defense statements based on actual cases | Dear Chief Judge and Judge, entrusted by the relatives of the defendant and appointed by Beijing Jietong Law Firm, I am the defender of the defendant Chen. Based on the facts and cross-examination evidence of the trial investigation and in accordance with the relevant laws of our country, the following defense opinions are expressed, etc. |
| Case entity | Representative cases that actually occurred | In his statement on 20 July 2009, Xu xx admitted to receiving the wool sweaters from Sifang Company, and witness Li xx (Chairman of Sifang Yitong Automobile Trading Co., Ltd.) also mentioned in his statement on 21 April 2009 that he sent wool sweaters, mobile phones, computers and other items to the two defendants in this case, etc. |
| Entity or Relationship Category | Number of Entities/Relationships |
|---|---|
| Crime Name Entities | 460 |
| Concept Entities | 435 |
| Constituent Feature Entities | 433 |
| Identification Standard Entities | 394 |
| Punishment Entities | 412 |
| Legal Provision Entities | 417 |
| Judicial Interpretation Entities | 237 |
| Defense Statement Entities | 169 |
| Case Entities | 169 |
| Total Number of Entities | 2957 |
| Entities with Relationships | 435 |
| Whole–Part Relationships | 3045 |
| Total Number of Relationships | 3480 |
| Entity or Relationship Category | Number of Entities/Relationships |
|---|---|
| Crime Name Entities | 35 |
| Concept Entities | 35 |
| Constituent Feature Entities | 35 |
| Identification Standard Entities | 34 |
| Punishment Entities | 35 |
| Legal Provision Entities | 34 |
| Judicial Interpretation Entities | 19 |
| Defense Statement Entities | 15 |
| Case Entities | 15 |
| Entities with Relationships | 35 |
| Whole–Part Relationships | 254 |
| Types of Model | Accuracy/% | Recall/% | F1 Value/% |
|---|---|---|---|
| CRF | 78.65 | 75.60 | 77.09 |
| BiLSTM | 82.30 | 83.16 | 82.73 |
| BERT | 85.72 | 84.91 | 85.31 |
| ChatGLM-6B | 86.20 | 85.92 | 86.06 |
| JKEM (Ours) | 90.78 | 91.06 | 90.92 |
| Category | Accuracy/% | Recall/% | F1 Value/% |
|---|---|---|---|
| Crime | 100.00 | 97.14 | 98.55 |
| Concept | 91.43 | 94.29 | 92.84 |
| Characteristic | 88.57 | 91.43 | 89.98 |
| Judging standard | 97.06 | 91.18 | 94.03 |
| Punishment | 91.43 | 94.29 | 92.84 |
| Legal provision | 97.06 | 88.24 | 92.44 |
| Interpretation | 89.47 | 89.47 | 89.47 |
| Defense | 100.00 | 100.00 | 100.00 |
| Case | 80.00 | 86.67 | 83.20 |
| Entity–With | 91.43 | 94.29 | 92.84 |
| Component–Whole | 98.82 | 97.24 | 98.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Qian, L.; Liu, P.; Liu, T. Construction of Legal Knowledge Graph Based on Knowledge-Enhanced Large Language Models. Information 2024, 15, 666. https://doi.org/10.3390/info15110666
Li J, Qian L, Liu P, Liu T. Construction of Legal Knowledge Graph Based on Knowledge-Enhanced Large Language Models. Information. 2024; 15(11):666. https://doi.org/10.3390/info15110666
Chicago/Turabian StyleLi, Jun, Lu Qian, Peifeng Liu, and Taoxiong Liu. 2024. "Construction of Legal Knowledge Graph Based on Knowledge-Enhanced Large Language Models" Information 15, no. 11: 666. https://doi.org/10.3390/info15110666
APA StyleLi, J., Qian, L., Liu, P., & Liu, T. (2024). Construction of Legal Knowledge Graph Based on Knowledge-Enhanced Large Language Models. Information, 15(11), 666. https://doi.org/10.3390/info15110666