Abstract
Object detection and action/gesture recognition have become imperative in security and surveillance fields, finding extensive applications in everyday life. Advancement in such technologies will help in furthering cybersecurity and extended reality systems through the accurate identification of users and their interactions, which plays a pivotal role in the security management of an entity and providing an immersive experience. Essentially, it enables the identification of human–object interaction to track actions and behaviors along with user identification. Yet, it is performed by traditional camera-based methods with high difficulties and challenges since occlusion, different camera viewpoints, and background noise lead to significant appearance variation. Deep learning techniques also demand large and labeled datasets and a large amount of computational power. In this paper, a novel approach to the recognition of human–object interactions and the identification of interacting users is proposed, based on three-dimensional hand pose data from an egocentric camera view. A multistage approach that integrates object detection with interaction recognition and user identification using the data from hand joints and vertices is proposed. Our approach uses a statistical attribute-based model for feature extraction and representation. The proposed technique is tested on the HOI4D dataset using the XGBoost classifier, achieving an average F1-score of 81% for human–object interaction and an average F1-score of 80% for user identification, hence proving to be effective. This technique is mostly targeted for extended reality systems, as proper interaction recognition and users identification are the keys to keeping systems secure and personalized. Its relevance extends into cybersecurity, augmented reality, virtual reality, and human–robot interactions, offering a potent solution for security enhancement along with enhancing interactivity in such systems.
1. Introduction
Human–object interaction (HOI) generally refers to the understanding of how humans interact with surrounding objects through image or video analysis, among other forms of data. Most the previous studies have applied object detection algorithms to identify humans and surrounding objects; this usually requires considering spatial relationships and multiple body poses for a better understanding of these interactions, such as grasping objects. This can be crucial for cybersecurity in extended reality (XR) systems, where the tracking and analysis of user interactions with objects may inherently enhance security and surveillance protocols to better manage the authentication services.
Video analysis involves capturing finer details of human actions over time. HOI recognition becomes important for a host of applications in robotics, assistive technologies, and XR systems, where secure and personalized user experiences are of utmost importance. However, HOI recognition brings a lot of challenges and complexities along with it. Most of the prior works in this regard relied on texture, color, and dimensional features of objects [1,2,3]. These solutions generally have the problems of illumination variation, occlusions, and a change in object appearance and are most likely to generate ambiguous results with a loss in robustness. Moreover, HOI recognition (HOIR) with deep learning needs high volumes of datasets which capture the complexity of human–object interaction at very high costs and are time-consuming [4]. Subtle interpretation of interactions such as recognizing whether an object is being held or used is highly challenging and requires a deep understanding of human behavior [5]. In addition, most of the deep learning models lack generalization ability in different contexts, which often turns out to be inefficient in situations not seen earlier. These methods are also computationally expensive in time, energy, and hardware resources [6,7], and therefore might not be as effective in runtime security scenarios of XR systems.
To understand such issues, several studies looked into the use of egocentric camera views for HOIR [8]. In contrast to normal third-person views, egocentric views offer a host of advantages in capturing user interactions from a personal, first-person view. This has been highly instrumental in XR environments where capturing a user’s natural interactions is key to providing secure, personalized experiences. Egocentric views restrict the visual data only to relevant objects and areas so that insight into user attention and intention can be clearly grasped. Hand-pose information extraction from the first-person view is very important for HOIR, since rich information about hand motion may lead to more accurate interaction recognition. With the advancement of computer vision and machine learning, hand pose tracking has become increasingly accurate. Leading to object recognition through hand motion [9].Hand-pose data infused into HOIR improve the capability of robustness against occlusion and background clutter, among other real challenges, by finding small changes in object manipulation. A lot of previous studies estimated hand poses from images and videos, which showed decent results. For example, one of such studies introduced an approach for estimating hand pose data from appearances and achieved radical improvement in recognition accuracy [10]. Another study demonstrated the use of deep learning approaches to extract hand pose data from images and videos [11]. Motivated by these advancements, this study is going to present the use of hand pose data to enhance HOIR with a particular emphasis on the improvement of user recognition for security-sensitive applications.
This paper is based on a new model that leverages the statistical features obtained from 3D hand pose data, captured by egocentric views, for conducting HOIR. Our approach emphasizes the dynamics of hand movements and hand poses in understanding the HOI, and importantly, identifying the users. A multi-stage method is proposed where, first, the objects are recognized, which guides the classification of interactions. These steps together result in the final identification of the user, which is quite a key aspect for secure systems. The identification of users in cybersecurity and XR is quite critical because this makes sure that only the authorized users can interact with certain objects or take certain actions within immersive environments. Our model contributes to more secure, privacy-sensitive, and personalized systems by addressing the need for user identification with high accuracy based on their hand pose data. The results for our method per category along with detailed analysis are provided in Section 4. This study infers from the obtained results that our proposed HOIR model achieves good performance related to accuracy and computational efficiency. It opens new avenues for interactive systems, assistive technologies, and privacy-sensitive applications by minimizing the dependence on extraneous information while increasing security throught the identification of users.
List of Contributions
The key contributions of this paper are as follows:
- This work presents a novel multi-stage approach that incorporates hand pose data with regard to both hand joints and vertices, especially to recognize human–object interaction and identify which one of the users interacts. Here, the statistical features are applied independently on hand joints and vertices, and the resulting features are fused to enhance recognition performance.
- It proposes a new mathematical model for feature extraction and description, which captures distinctive statistical attributes from hand joints and vertices. These attributes are then represented as a feature vector for HOIR, enhancing both interaction recognition and user identification with an average F1-Score of 81% for HOI recognition and an average F1-Score of 80% for user identification.
2. Related Studies
In the field of HOIR, previous studies present various models and approaches that have considerably enhanced the comprehension and capabilities of such systems for various practices [12,13,14,15,16,17,18,19]. These works present a core background to the present study on HOIR. For instance, a study presents a model that generates captions for identifying the activities of sports players with the help of an ontology-based identification scheme. The authors further define the relationships between different objects and humans based on logical semantic reasoning. In [20,21], the authors harness graph convolutional neural networks with several multilayer perceptrons in the task of HOI detection. On the other hand, in the task of human interaction recognition, a similar method is employed using a Hidden Markov Model in [22] with precise target localization. Other uses in the literature [23] are that they applied this with important techniques that involve a hybrid model fusing object detection with the skeletal method on different sets of data. It is seen that the proposed technique achieved an average performance of 98.5% in recognizing HOIs. The model presents as being not only effective in predicting interactions between humans and different objects but also provides a scheme for detection that is scalable and reliable with a small dataset for training. The authors of [24] also pointed to the fact that organizing a comprehensive dataset including all possible combinations of human and objects was a time-consuming process and computationally very expensive. They propose a model for an HOI detector that can work with new and unseen instances. Their model is composed of a two-stream component for the visual data and another for text detection and recognition. Their proposed model leverages the layered structure of a human–object interaction transformer that substantially performs the detection of HOIs. Similarly, the RPNN method has been utilized for the detection of HOIs in the study by the authors of [25]. Their approach uses two graphs to model the relationship between humans and objects. One graph models a person’s relationship with their body poses while the other graph acquires the interaction of the surrounding object with the body parts.They further integrate a parsing machine for actions into their model to link these two graphs. The authors of [26] propose a mechanism for detecting objects in unseen data with new instances by leveraging an external knowledge graph for learning. Their method not only outperforms state-of-the-art techniques in unseen combination classification but also delivers the strongest performance on detecting novel concepts. The authors of [27] further present a NN-based mechanism to detect human motion by leveraging the use of neighboring frames to predict occluded frames for assistive detection. Furthermore, they presented a pose prediction network which is able to recover object poses even in the case of heavy occlusions. Ref. [28] utilized a scene graph to recognize semantic relationships within an image dataset, which in turn aids in finding essential contextual information to infer human–object interaction. The literature reviewed above has concentrated on techniques that use visual datasets from images/videos for HOI recognition and has shown better classfication performance but at the cost of high computational resources. These models are typically designed for detecting and recognizing HOIs from images or videos captured using standard views of exocentric cameras. For data-privacy applications, however, a first-person camera view is imminent [29,30]. Indeed, some studies have proposed HOI recognition techniques based on first-person camera views, which are relevant in augmented reality, human–robot collaboration and virtual reality [31]. To this regard, this work presents a video-based egocentric camera HOIR method using the publically available dataset (HOI4D). This study also proposes a method that facilitates the HOI process using the availability of hand pose data. The motivation behind the proposed method comes from the simple analysis that most of the HOIs engage hands; as a result, the hand pose is a key indicator for human–object interactions (HOIs). In the process, our method focuses only on hand gestures, avoiding complicated DL algorithms and reducing the computational cost. This ensures that the system remains computationally efficient and can be deployed on devices with limited processing power, such as mobile devices or edge-computing environments. This research, therefore, further pushes the boundary of HOI detection technologies to now enable improved capabilities of essence in numerous applications, like robotics, healthcare, human–robot interaction, human–computer interaction (HCI), AR, VR, and interactive systems.
3. Proposed System Model
The schematic diagrams of proposed mathematical model, as illustrated in Figure 1 and in Algorithm 1, shows a step-by-step approach. The following subsections will discuss these steps in detail.
| Algorithm 1 HOI Recognition Model |
|
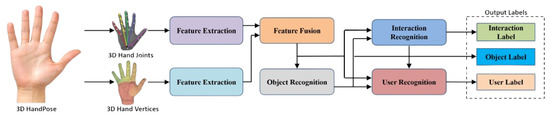
Figure 1.
Multi-stage HOI recognition.
3.1. Data Acquisition
This work developed our model to benefit with an egocentric dataset that uses a first-person view. In fact, there are a lot of datasets available using the conventional third-person views; for this kind of task, comprehensive datasets are lacking. Most relevant datasets, like the one used in [32], rely on artificial data, where real 2D images were transformed into 3D artificial images of hands for further processing. In contrast, the HOI4D dataset, built by Liu and their team [33], is very suitable for our study due to the fact that it provides real image-based hand annotations. HOI4D provides high variability by containing videos from four different, independently operated cameras capturing different indoor conditions. It features 2.4 M RGB egocentric video-frames from 4000 videos of actions conducted by 9 subjects with 800 object instances from 16 categories in a wide range of indoor scenes. Every interaction is captured under a large diversity of conditions, including the room type, furniture, participants, camera views, backgrounds, and complexity of the interactions. The HOIs can be categorized into simple scenarios and complex scenarios, where the simple scenarios provide clear vision with relatively constant lighting conditions, while the complex scenarios add more variability. For details, refer to Table 1 for the objects and their relevant interactions. In this study, we conducted thorough testing on the HOI4D dataset to make our algorithm more robust under real-world conditions. This avoids biases in results since every data instance, coming from different individuals, rooms, and cameras, is used for train and test sets in various iterations.

Table 1.
List of objects and associated interactions in the HOI4D dataset (where ‘C’ represents Object Category and ‘T’ represents Task).
3.2. Preprocessing
Required preprocessing of video sequences is done before recognizing human–object interactions. First, the window-based segmentation cuts the video sequence into pieces of non-overlapping 5-s segments. This duration was chosen as it was found to capture interactions optimally within such a period for an accurate and effective analysis of hand dynamics. Every segment is then maintained and named as a video snippet regarding the whole video.
3.2.1. Window-Based Segmentation
Initially, window-based segmentation is performed on each video sequence, dividing it into non-overlapping segments of seconds each. Let V represent a video sequence with a total duration of t seconds. The number of segments n is given by:
Each video sequence is converted into four snippets corresponding to the complete video:
where represents the i-th video sequence. are the individual snippets of the i-th video sequence, with corresponding to the first snippet and to the last snippet.
3.2.2. Snippet-to-Frame Conversion
Each 5-second segment is converted into frames, represented by a 2D RGB matrix. Let denote the j-th frame in the i-th segment.
Given a frame rate of 15 frames per second (fps), for a 5-second segment: .
3.2.3. Hand Pose Data Extraction
A set of 21 keypoints per frame are identified that represent standard hand joints and 778 hand vertices as 2D landmarks [33,34]. These keypoints and hand vertex landmarks are mapped 3D through a MANO Parametric Hand Model [34].
For each frame , hand pose data is extracted, including hand joints and vertices.
The keypoints per frame are represented by:
where represents the k-th hand joint keypoint in frame .
The hand vertices per frame are represented by:
where represents the k-th hand vertex in frame .
3.2.4. 3D Hand Joint and Vertex Representation
These keypoints and hand vertex landmarks are mapped to 3D through the MANO Parametric Hand Model. The 2D keypoints and landmarks and are used to estimate the 3D shape and pose parameters.
Let be the estimated 3D pose parameters, and be the estimated 3D shape parameters. The optimization process minimizes the reprojection error to refine these parameters. The refined parameters and are applied to the MANO model to generate 3D points.
The 3D hand joint representation for each frame is stored as a matrix:
The 3D hand vertex representation for each frame is stored as a matrix:
This process ensures that each frame within a segment consistently captures hand interactions, enabling the accurate extraction of hand pose information. Final representation for each segment consists of:
where represents the i-th segment of the video sequence, consisting of frames that consistently capture hand interactions. is the 3D joint representation for the i-th segment. represents the 3D vertex representation for the j-th frame of the i-th segment. Moreover, , indicates that each 5-second segment consists of 75 frames. These frames are used to accurately extract and represent the 3D joint positions and velocities, which are crucial for analyzing hand pose and motion dynamics. Algorithm 2 illustrates the preprocessing and hand pose extraction process. Furthermore, Figure 2 shows an example of the 3D hand joint and vertex model represented by MANO.
| Algorithm 2 Segmentation and Hand Pose Extraction |
|
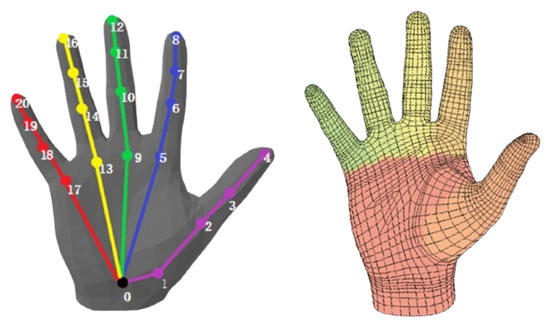
Figure 2.
Representation of set of 21 3D hand Landmarks and vertices.
3.3. Hand Joint and Vertex Transformation: 3D to 7D Space
This work enhances the 3D hand joint and vertex matrices by concatenating additional metrics to represent each hand joint and vertex in a 7D space. Specifically, it includes the Euclidean norm and the pair-wise planar distances.
3.3.1. Enhanced Hand Joint Representation
For each hand joint , it computes the following additional metrics:
Thus, the enhanced representation for each hand joint is:
The 3D hand joint representation for each frame, , is expanded to a matrix:
3.3.2. Enhanced Hand Vertex Representation
Similarly, for each hand vertex , the additional metrics are:
The enhanced representation for each hand vertex is:
The 3D hand vertex representation for each frame, , is expanded to a matrix:
3.3.3. Normalization
To make the feature set more robust and comparable, each column in the hand joint and vertex matrices is standardized on a scale from 0 to 1. Let represent either or . The normalization is performed as follows:
This ensures that all features contribute equally to the classification process, avoiding domination by one feature due to scale differences. The final representation for each frame includes the following:
This comprehensive and robust representation of hand poses improves the recognition of human–object interactions by reducing variability due to different hand orientations. Algorithm 3 illustrates the details of tne hand joint and vertex transformation process.
| Algorithm 3 Hand Joint and Vertex Transformation |
|
3.4. Feature Extraction and Description
3.4.1. Statistical Feature Extraction
From each hand joint and vertex matrix, it extracts eighteen statistical (time-domain) features, denoted as , which are described in Table 2. These features capture the time-domain attributes of the hand joints and vertiex data, which are beneficial in pattern identification tasks related to movement recognition.
Table 2.
List of statistical features extracted for HOIR.
Let represent the enhanced hand joint or vertex matrix for the i-th segment, j-th frame, and k-th hand joint or vertex. For each metric , it computes the eighteen statistical features. This results in a feature vector for each metric:
Concatenating these feature vectors, it obtains the feature vector for each hand joint and vertex:
The feature vector for each frame is:
3.4.2. Mean Pooling
To combine these features over the whole video segment, mean pooling is applied:
3.4.3. Feature Vector Concatenation
Finally, it concatenates the two feature vectors to obtain the final feature vector:
Algorithm 4 illustrates the details of the feature extraction and description process.
| Algorithm 4 Feature Extraction and Description |
|
3.5. Classification
Finally, in Fuse3D, HOI is classified using a multi-stage technique: In the case of the multi-stage method, the process involves three steps: first, the classification of the object using a fused feature set composed of hand joint features and vertex features; second, based on the recognized object label and the fused features, the recognition of the HOIs; and last, based on the recognized object label and interaction label and fused features, the recognition of users. For instance, it may first recognize the object as “Bottle” and then classify the interaction as “pick and place”. and classify the user as ‘H1’. In a multi-stage approach, at the first level of abstraction, it recognizes 16 different classes of objects and in the second, a varying number of classes depending upon the interaction associated with each object and then, finally, the user interacting with the object.
This study use a XGBoost classifier for all these tasks. In the case of the multi-stage method, it trains 18 classifiers separately, where 1 is for object recognition, 16 are for interaction recognition and 1 is for user recognition.
4. Experimental Results and Analysis
In this section, the study evaluates the performance of the proposed mathematical model. It will provide a detailed result analysis with implementation details and the methods of evaluation.
4.1. Implementation Details
Our proposed model has a multi-stage recognition technique: object recognition, interaction recognition and user identification. These require different strategies for labeling within the dataset. In this technique, an object, an interaction, and a user label is assigned to each video snippet. Consequently, all interactions associated with a particular object are assigned a unique label for object recognition. To recognize an interaction, all instances of interactions associated with an object are collected and the corresponding interaction label is accorded to it. Moreover, to recognize a user, all instances of an interaction are collected and the corresponding user label is assigned to it. Ground truth for such labels is obtained from videos in the dataset. All experiments were conducted on the enabled various feature sets. Furthermore, this study obtained results with the hand joints feature set enabled and the hand vertex feature set enabled separately. It also performed other fusion techniques with different arrangements of the obtained hand joints and vertex feature sets: mean pooling, max pooling, min pooling, sum pooling, and concatenation. Our results show that fusion by concatenation gives the most promising outcome. The study implemented an XGBoost classifier using scikit-learn. The model implementation was evaluated using experimentation performed on a personal desktop computer configured with an Intel(R) Core(TM) and 8.00 GB RAM.
4.2. Evaluation Metrics and Validation Method
This work measured performance on our proposed model using accuracy, precision, recall, and the F1-Score. Computational time is assessed as a metric of computational overhead. In this research, it considered 5-fold cross-validation and split our dataset into five equal parts. These parts are further stratified class-wise; that is, they maintain exactly the same target class distribution as in the whole dataset. It ensures that class balance is maintained in both the training and test sets, not only during the training phase but also during the testing phase. We are using this whole dataset to train and test in different iterations so that model evaluation will be robust and not biased due to data splitting.
4.3. Analysis of Multi-Stage HOI Recognition
This section consists of two steps: objects’ classification and their relevant interaction classification. Results for both are described below.
4.3.1. Stage 1: Analysis of Object Recognition
This study trained an XGBoost for object recognition, fusing features extracted from hand joints and vertex data, in order to recognize 16 different objects. Table 3 illustrates the numerical results for object classification using the XGBoost classifier. These results reflect that the classification of the classes “Bottle”, “Bowl”, “Chair”, “Kettle”, “Laptop”, “Scissors”, and “Stapler” is better, all with an accuracy and F1-score greater than 80%. In particular, both “Chair” and “Bowl” achieved the highest accuracy of 90%. On the other hand, “Safe”, “Toy Car”, and “Storage Furniture” have relatively low recognition performance: the accuracy and F1-scores are both below 70%, indicating that these objects are harder to recognize from hand joints and vertex information.
Table 3.
Experimental results for object recognition (where ‘C’ represents the object category).
This causes confusion during classification due to the similarity in hand motion patterns related to these objects. Figure 3, i.e, the confusion matrix with hand joints feature set, illustrates that the model can very accurately distinguish items like “Bottle” and “Mugs” since the diagonal values are high in the confusion matrix generated using the hand joints feature set. It also tells about the specific confusions mixing up “Bowls” with “Buckets”, where the model mistakes similarities. It is likely that special improvement is required in “Toy Car” because of the high prevalence of mislabeling. Given this set of features, the average F1-score for object recognition is 73%.
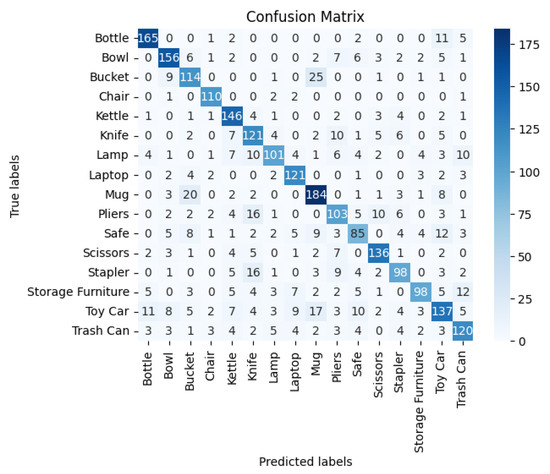
Figure 3.
Confusion matrix for object recognition (hand joints).
In Figure 4, the confusion matrix of the hand vertex feature set evidences that the model has strong discriminative power for many objects, such as “Bottle” and “Mugs”, reflected in the high diagonal values. On the other hand, specific confusions arise, like mixing “Mug” with “Buckets”, showing where the model has gone wrong in finding similarities. The frequent mislabeling of “Safe” suggests this category needs particular attention. The overall average performance (F1-score) for object classification with this feature set used is 73%.
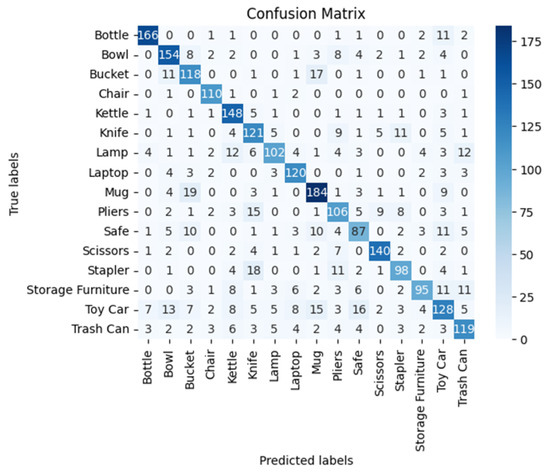
Figure 4.
Confusion matrix for object recognition (aand vertices).
Similarly, the confusion matrix for the fusion feature set, shown in Figure 5, has high diagonal values, which indicates that items such as “Bottle”, “Bowl”, and “Mugs” are very well distinguished by the model. It will also show specific confusions—for example, mixing “Bowls” with “Buckets”—and say where the model misinterprets similarities. For example, “Storage Furniture” is one of the more often mislabeled ones, so this category probably especially needs attention. The overall average performance (F1-score) for object classification using this set of features is 79%.
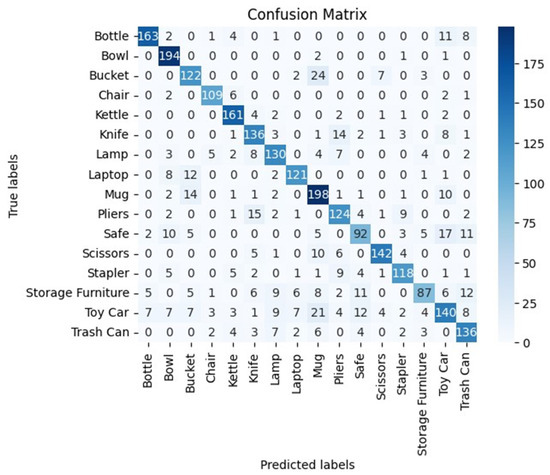
Figure 5.
Confusion matrix for object recognition (fusion concatenation).
4.3.2. Stage 2: Analysis of Interaction Recognition
After recognizing objects, it classifies the interactions made with those objects using the same set of extracted features. The feature vector and the object label classify each HOI through the XGBoost classifier. The detailed performance metrics for object-wise interaction recognition are shown in Table 4 and Figure 6. It can be noticed that the interactions with “Bucket”, “Kettle”, “Knife”, “Laptop”, “Lamp”, “Scissors”, and “Stapler” have been classified more accurately. The results differ for different objects and their corresponding interactions. For example, the interaction of “Pick and place” shows an excellent average F1-score for a number of objects: “Bowl” with 0.91, “Bucket” with 0.90, “Kettle” with 0.94, “Knife” with 0.96, and “Lamp” with 0.95.
Table 4.
Experimental results for interaction recognition (where ‘C’ represents the object category and ’T’ represents the corresponding task).
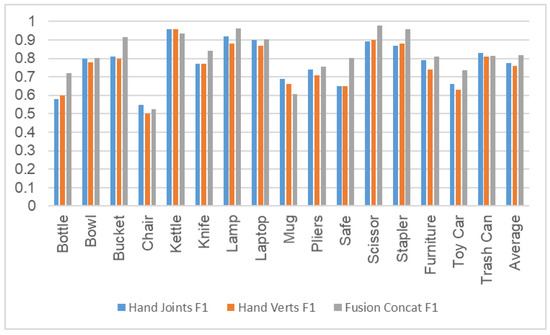
Figure 6.
Object based F1-Score for interaction classification.
4.3.3. Stage 3: Analysis of User Recognition
After recognizing objects and their respective interactions, it classifies the users based on the patterns of how they performed the interactions with objects using the same set of extracted features. The feature vector along with the object label and interaction label classify each user through the XGBoost classifier. The detailed performance metrics for user recognition are shown in Table 5. It can be noticed that the users performing interactions with “Bowl”, “Kettle”, “Stapler”, “Chair”, “Toy Car”, “Trash Can”, and “Lamp” have been identified more accurately. The results differ for different objects and their corresponding interactions. In contrast, users performing interactions with “Bucket” and “Storage Furniture” have been misclassified mostly. Avergae F1-Scores of user identifications for the interactions they performed object wise are shown in Figure 7.
Table 5.
Experimental results for user recognition.
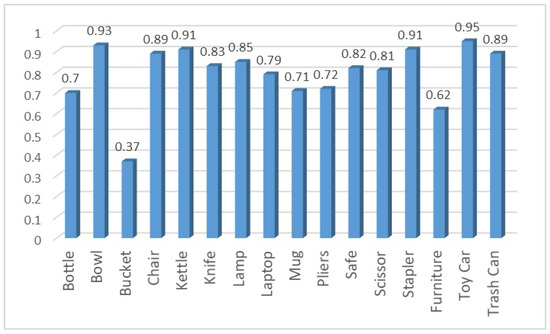
Figure 7.
User identification average F1-Score in object-wise interactions.
Experimental results indicate that the various best interactions include “Bottle: Pick and place with water”, “Bowl: Put the ball in the bowl”, “Toy Car: Take it out of the drawer”, “Scissors: Cut something”, where significant high scores are obtained for accuracy, precision, recall, and F1-score in the user recognition system. However, interactions like “Bucket: Pour water into another bucket” and “Bottle: Put it in the drawer” see poor system performance with metrics below 0.60. These results reveal the good overall capability of the system since it averages an accuracy of 0.80 but also reveals that there is much work to be done in improving recognition for more complex and similarly performed tasks as a way of enhancing the general reliability of this system.
The graph shown in Figure 7 depicts the user recognition system, which is acting at its best for interactions involving the Toy Car (0.95), Bowl (0.93), and Chair (0.91), while recognizing with very good accuracy and being quite reliable. While it has fared rather poorly on the interaction for Bucket, with a score of 0.37, and Storage Furniture, with a score of 0.62. Meanwhile, the low-performing areas indicate that the system, though robust and effective in most of the interactions, needs focused improvements in recognition for more complex or challenging scenarios.
In the proposed HOI recognition model, only time statistical features are used, making it computationally much more efficient than state-of-the-art DL models. Mathematically, such simpler operations for feature extraction result in linear time complexity, while deep models have complex operations, nonlinear activations, and backpropagation, which add asignificant computation overhead.
5. Conclusions
In this work, the study presents the potential of incorporating 3D hand pose information into an integrated model that recognizes objects and interprets HOIs concerning user identification in secure extended reality environments. Our approach is based on a model that relies on video data processing: first, frame-by-frame hand-joint-and-vertex estimation occurs; second, a feature extraction and description module which leverages hand pose information is used; and finally, the XGBoost classifier is used, classifying objects and HOIs. These results demonstrate that 3D hand joint and vertex data indeed capture fine details of interactions with a mean F1 score of 81%. The model can be further extended for future improvements by considering hand pose together with visual characteristics of the objects, such as color, shape, and texture. Besides, future work on the development of deep learning models for feature extraction from joints and vertices of the hands could further improve the robustness of this system. These results therefore indicate that this approach has great potential for development into a very effective technique in user identification and recognition for HOI, especially in immersive reality applications focused on cybersecurity.
Author Contributions
Conceptualization, M.E.U.H.; Methodology, D.H., A.Y., F.M. and M.A.A.; Validation, D.H. and A.Y.; Formal analysis, F.M.; Investigation, D.H., A.Y. and F.M.; Writing—original draft, D.H.; Writing—review & editing, M.E.U.H. and M.A.A.; Supervision, M.E.U.H. and M.A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this study are openly available in [Dataset: HOI4D] https://www.hoi4d.top/ accessed on 12 September 2024.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Gupta, S.; Malik, J. Visual semantic role labeling. arXiv 2015, arXiv:1505.04474. [Google Scholar]
- Hou, Z.; Yu, B.; Qiao, Y.; Peng, X.; Tao, D. Affordance transfer learning for human-object interaction detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 495–504. [Google Scholar]
- Li, Q.; Xie, X.; Zhang, J.; Shi, G. Few-shot human–object interaction video recognition with transformers. Neural Netw. 2023, 163, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Chao, Y.W.; Wang, Z.; He, Y.; Wang, J.; Deng, J. Hico: A benchmark for recognizing human-object interactions in images. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1017–1025. [Google Scholar]
- Sadhu, A.; Gupta, T.; Yatskar, M.; Nevatia, R.; Kembhavi, A. Visual semantic role labeling for video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 5589–5600. [Google Scholar]
- Li, Y.; Ouyang, W.; Zhou, B.; Shi, J.; Zhang, C.; Wang, X. Factorizable net: An efficient subgraph-based framework for scene graph generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 335–351. [Google Scholar]
- Zhou, T.; Wang, W.; Qi, S.; Ling, H.; Shen, J. Cascaded human-object interaction recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4263–4272. [Google Scholar]
- Bansal, S.; Wray, M.; Damen, D. HOI-Ref: Hand-Object Interaction Referral in Egocentric Vision. arXiv 2024, arXiv:2404.09933. [Google Scholar]
- Cai, M.; Kitani, K.; Sato, Y. Understanding hand-object manipulation by modeling the contextual relationship between actions, grasp types and object attributes. arXiv 2018, arXiv:1807.08254. [Google Scholar]
- Chen, L.; Lin, S.Y.; Xie, Y.; Lin, Y.Y.; Xie, X. Mvhm: A large-scale multi-view hand mesh benchmark for accurate 3d hand pose estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 836–845. [Google Scholar]
- Ge, L.; Ren, Z.; Yuan, J. Point-to-point regression pointnet for 3d hand pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 475–491. [Google Scholar]
- Wan, B.; Zhou, D.; Liu, Y.; Li, R.; He, X. Pose-aware multi-level feature network for human object interaction detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9469–9478. [Google Scholar]
- Chu, J.; Jin, L.; Xing, J.; Zhao, J. UniParser: Multi-Human Parsing with Unified Correlation Representation Learning. arXiv 2023, arXiv:2310.08984. [Google Scholar] [CrossRef] [PubMed]
- Chu, J.; Jin, L.; Fan, X.; Teng, Y.; Wei, Y.; Fang, Y.; Xing, J.; Zhao, J. Single-Stage Multi-human Parsing via Point Sets and Center-based Offsets. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 1863–1873. [Google Scholar]
- Wang, T.; Yang, T.; Danelljan, M.; Khan, F.S.; Zhang, X.; Sun, J. Learning human-object interaction detection using interaction points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4116–4125. [Google Scholar]
- He, T.; Gao, L.; Song, J.; Li, Y.F. Exploiting scene graphs for human-object interaction detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15984–15993. [Google Scholar]
- Nagarajan, T.; Feichtenhofer, C.; Grauman, K. Grounded human-object interaction hotspots from video. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8688–8697. [Google Scholar]
- Ehatisham-ul Haq, M.; Azam, M.A.; Loo, J.; Shuang, K.; Islam, S.; Naeem, U.; Amin, Y. Authentication of smartphone users based on activity recognition and mobile sensing. Sensors 2017, 17, 2043. [Google Scholar] [CrossRef] [PubMed]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. A survey of online activity recognition using mobile phones. Sensors 2015, 15, 2059–2085. [Google Scholar] [CrossRef] [PubMed]
- Ye, Q.; Xu, X.; Li, R. Human-object Behavior Analysis Based on Interaction Feature Generation Algorithm. Int. J. Adv. Comput. Sci. Appl. 2023, 14. [Google Scholar] [CrossRef]
- Yang, N.; Zheng, Y.; Guo, X. Efficient transformer for human-object interaction detection. In Proceedings of the Sixth International Conference on Computer Information Science and Application Technology (CISAT 2023), Hangzhou, China, 26–28 May 2023; Volume 12800, pp. 536–542. [Google Scholar]
- Zaib, M.H.; Khan, M.J. An HMM-Based Approach for Human Interaction Using Multiple Feature Descriptors; Elsevier: Amsterdam, The Netherlands, 2023. [Google Scholar]
- Ozaki, H.; Tran, D.T.; Lee, J.H. Effective human–object interaction recognition for edge devices in intelligent space. SICE J. Control Meas. Syst. Integr. 2024, 17, 1–9. [Google Scholar] [CrossRef]
- Gkioxari, G.; Girshick, R.; Dollár, P.; He, K. Detecting and recognizing human-object interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8359–8367. [Google Scholar]
- Zhou, P.; Chi, M. Relation parsing neural network for human-object interaction detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 843–851. [Google Scholar]
- Kato, K.; Li, Y.; Gupta, A. Compositional learning for human object interaction. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 234–251. [Google Scholar]
- Xie, X.; Bhatnagar, B.L.; Pons-Moll, G. Visibility aware human-object interaction tracking from single rgb camera. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 4757–4768. [Google Scholar]
- Purwanto, D.; Chen, Y.T.; Fang, W.H. First-person action recognition with temporal pooling and Hilbert–Huang transform. IEEE Trans. Multimed. 2019, 21, 3122–3135. [Google Scholar] [CrossRef]
- Liu, T.; Zhao, R.; Jia, W.; Lam, K.M.; Kong, J. Holistic-guided disentangled learning with cross-video semantics mining for concurrent first-person and third-person activity recognition. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 5211–5225. [Google Scholar] [CrossRef] [PubMed]
- Yao, Y.; Xu, M.; Choi, C.; Crandall, D.J.; Atkins, E.M.; Dariush, B. Egocentric vision-based future vehicle localization for intelligent driving assistance systems. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9711–9717. [Google Scholar]
- Liu, O.; Rakita, D.; Mutlu, B.; Gleicher, M. Understanding human-robot interaction in virtual reality. In Proceedings of the 2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Lisbon, Portugal, 28 August–1 September 2017; pp. 751–757. [Google Scholar]
- Leonardi, R.; Ragusa, F.; Furnari, A.; Farinella, G.M. Exploiting multimodal synthetic data for egocentric human-object interaction detection in an industrial scenario. Comput. Vis. Image Underst. 2024, 242, 103984. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.; Jiang, C.; Lyu, K.; Wan, W.; Shen, H.; Liang, B.; Fu, Z.; Wang, H.; Yi, L. Hoi4d: A 4d egocentric dataset for category-level human-object interaction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21013–21022. [Google Scholar]
- Romero, J.; Tzionas, D.; Black, M.J. Embodied hands. ACM Trans. Graph. 2017, 36, 245. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).