
Hyperparameter-Optimization-Inspired Long Short-Term Memory Network for Air Quality Grade Prediction

 , and
, and
Abstract
1. Introduction
2. Background
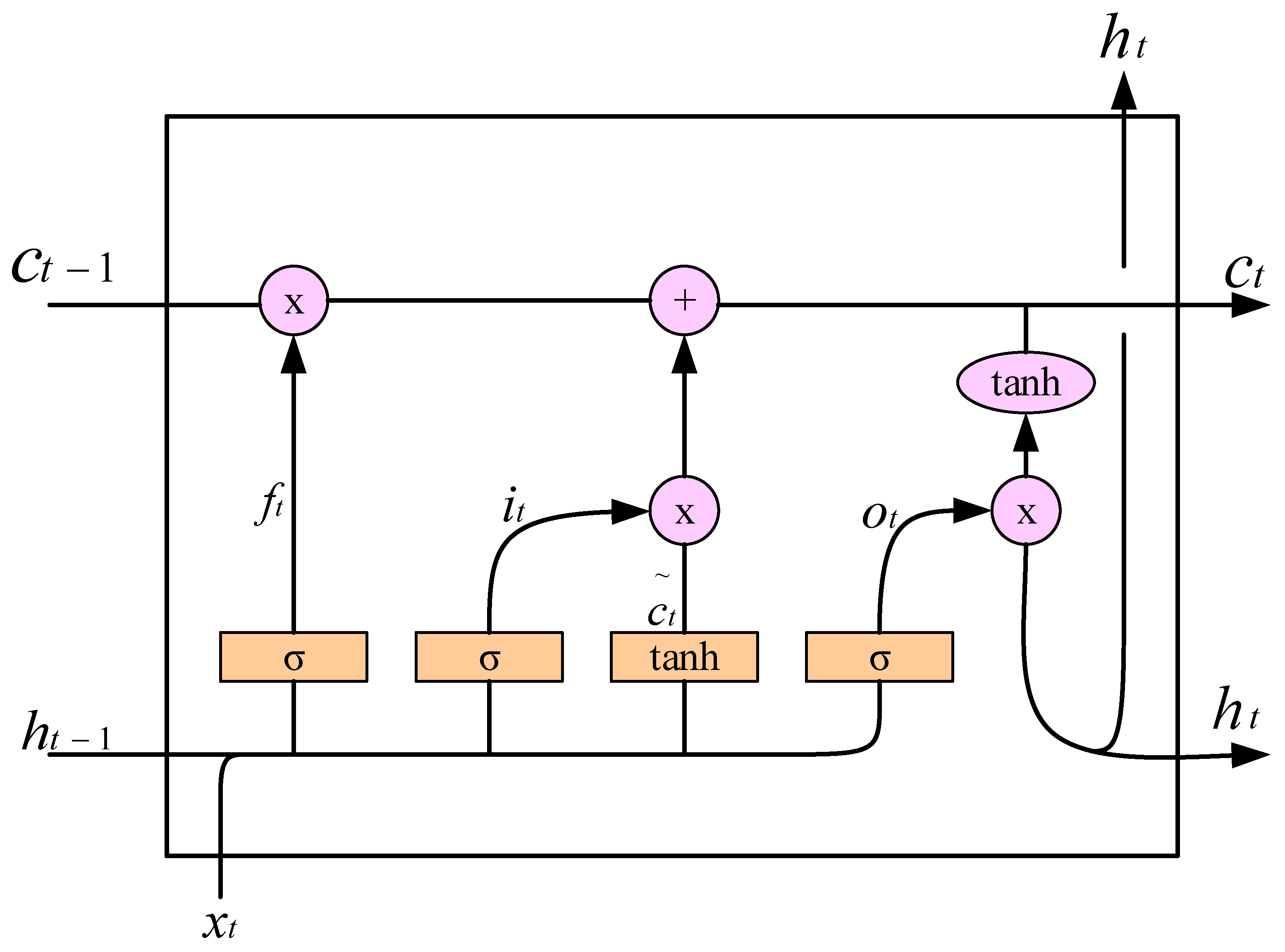
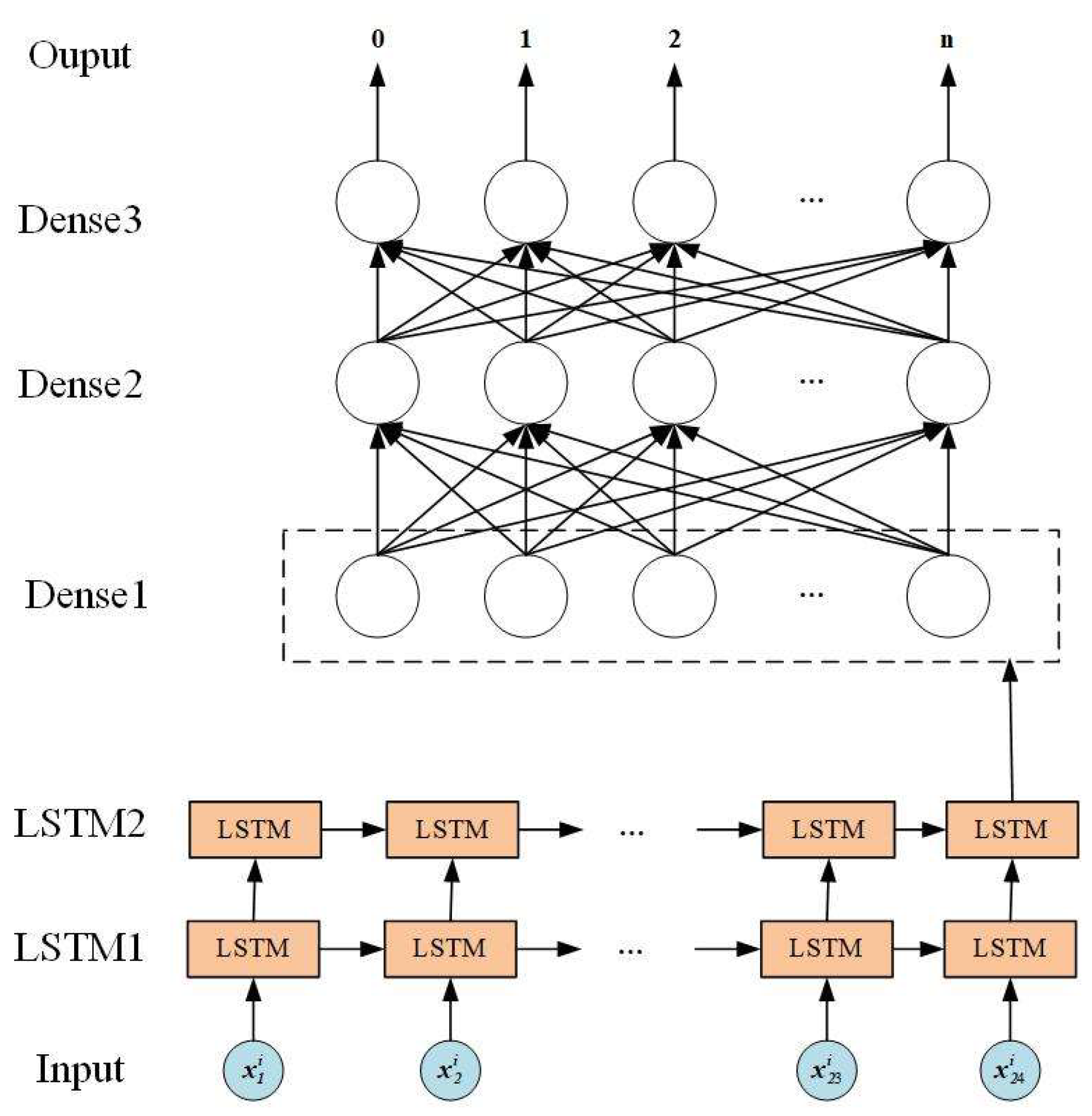
2.1. Long Short-Term Memory

2.2. Hunter–Prey Optimization Algorithm
3. The Proposed Method
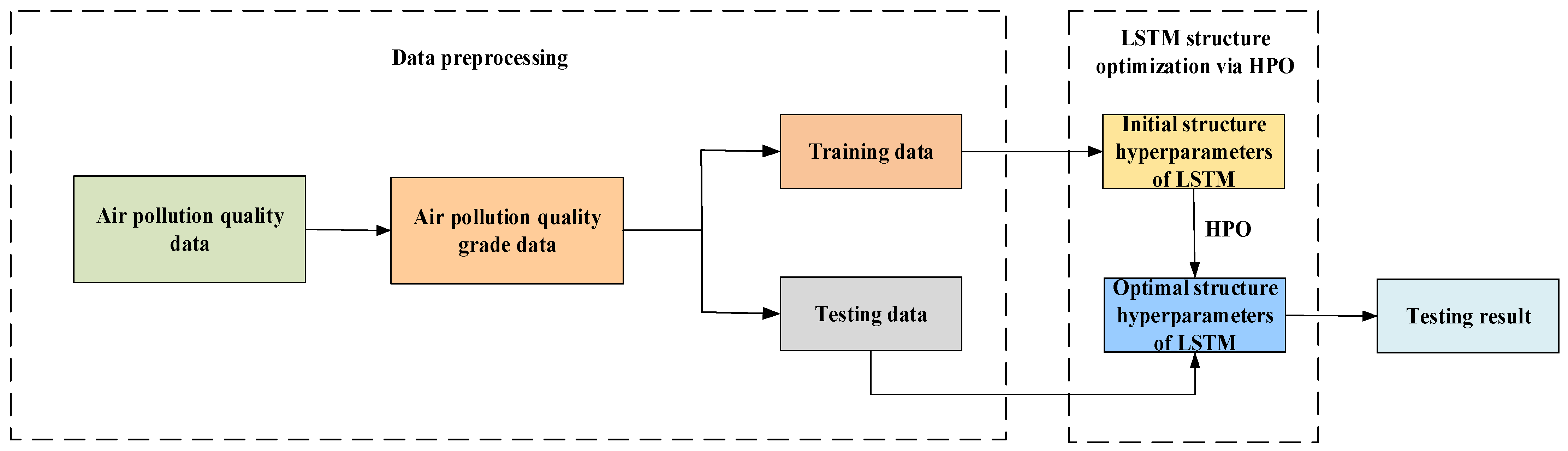
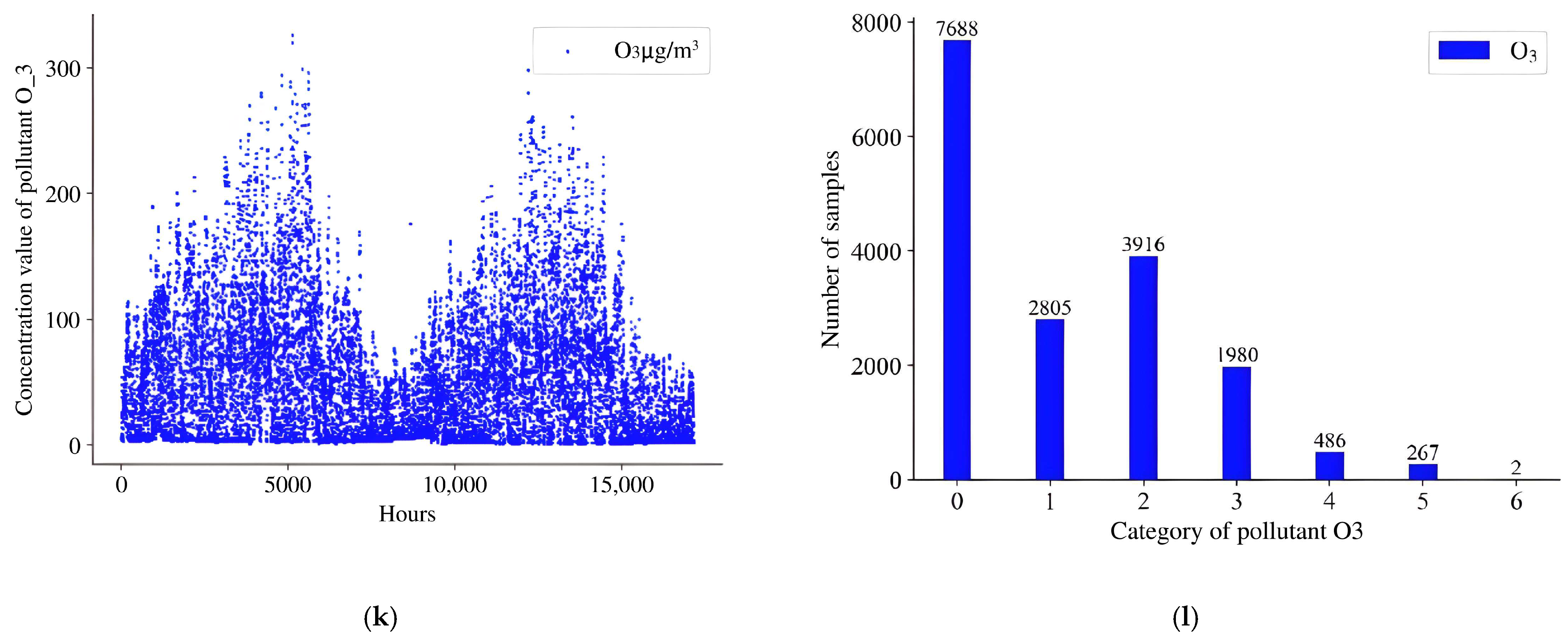
3.1. Data Preprocessing
3.2. The Network Hyperparameters of LSTM Optimized via HPO Algorithm
| Algorithm 1: The process for the hyperparameters of the LSTM network structure optimized using the HPO algorithm. |
| 1: Input: The number of layers of the LSTM network , the number of LSTM units , the number of fully connected layers , the number of fully connected units , the batch size , the value of dropouts and the value of recurrent dropouts ; 2: Initialization: Adjusting parameter , the maximum number of iterations and the global optimal value ; 3: For t = 1, 2, 3, …, T do 4: If range parameter < , update the predator or prey location according to Formula (8); 5: If range parameter , update the predator or prey location according to Formula (11); 6: Calculating the fitness and the current optimal value ; 7: Updating the adaptive parameter Z; 8: End for; 9: Output: The final optimal solution. . |
3.3. Training and Testing
4. Experiments and Analysis
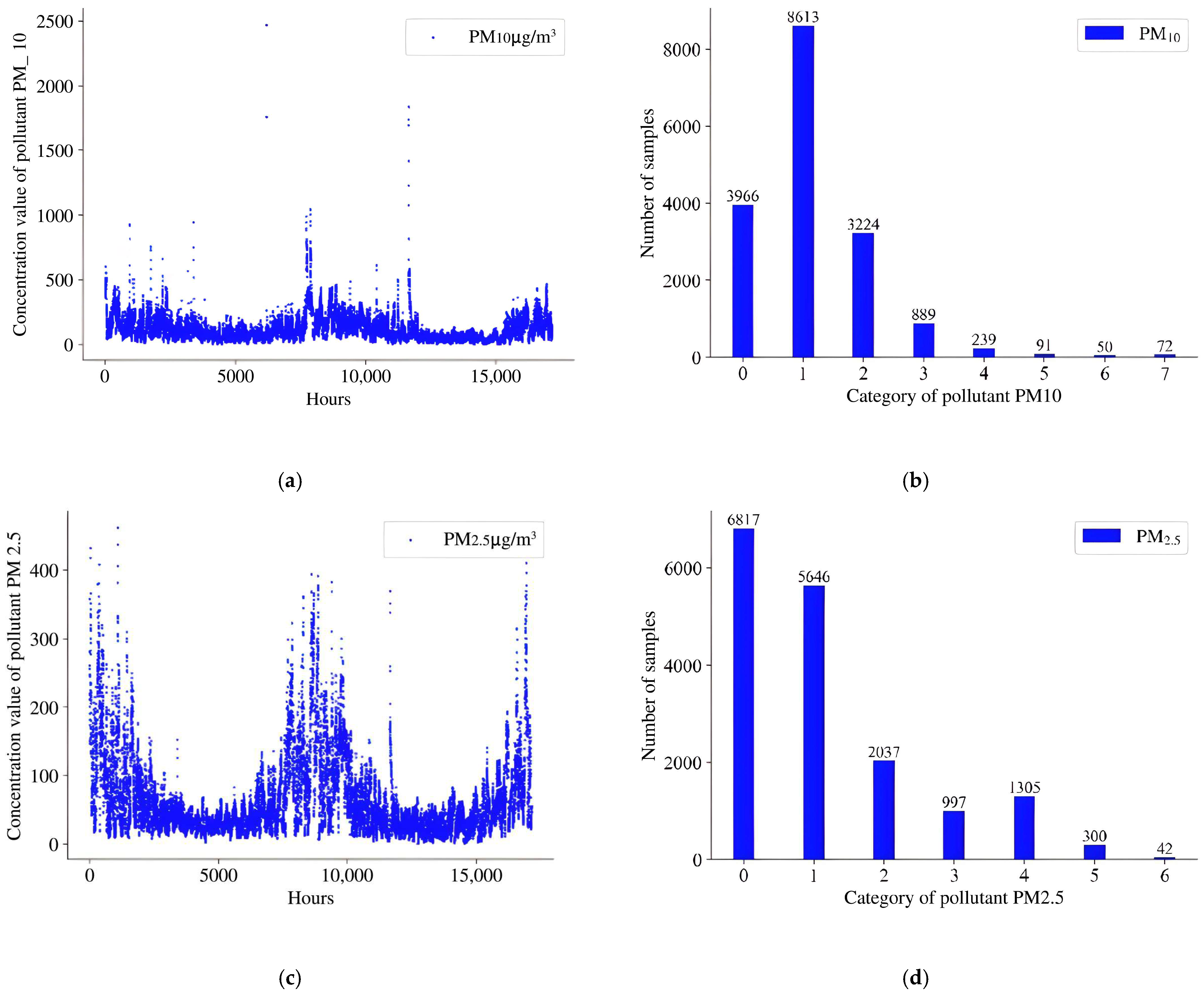
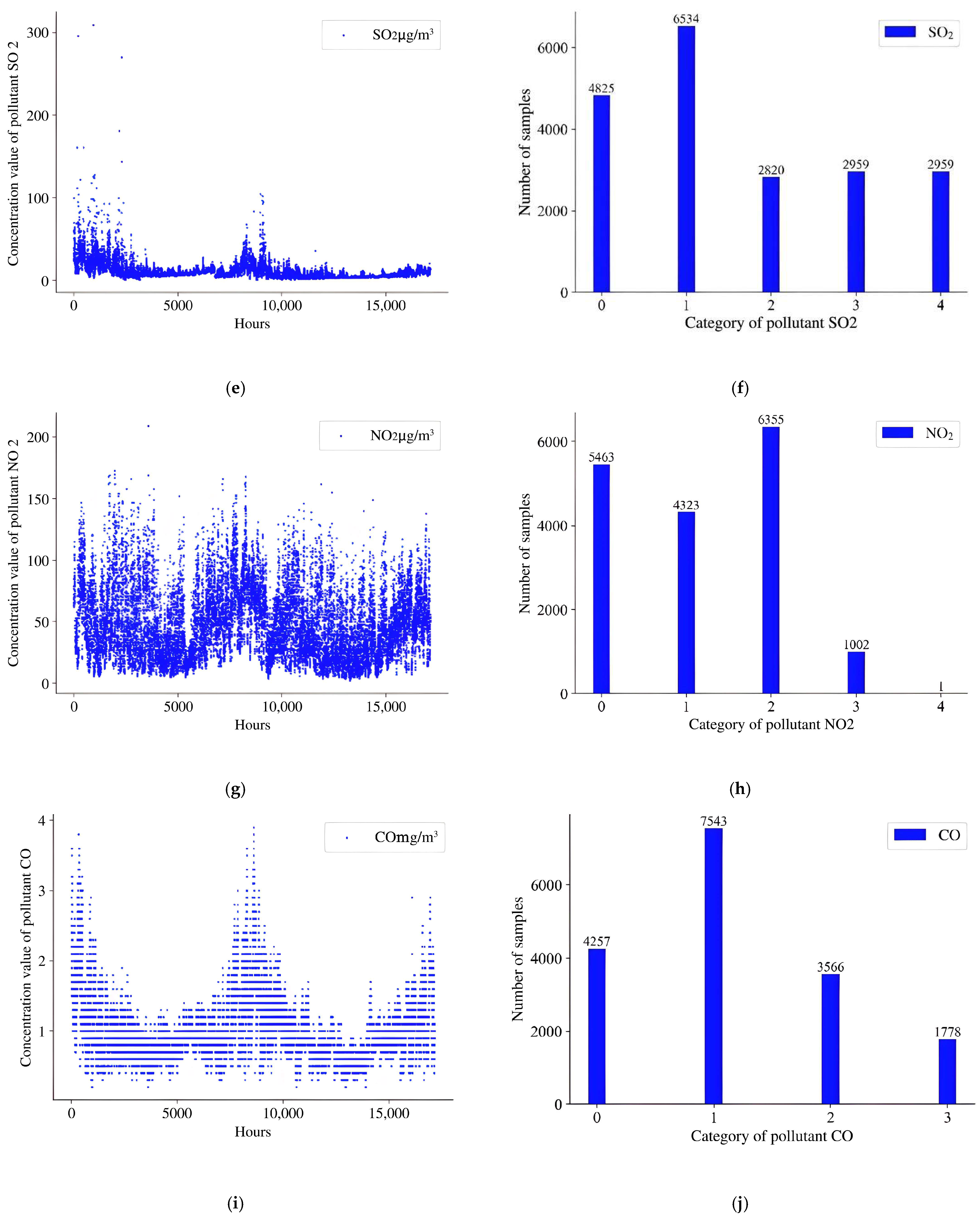
4.1. Datasets
4.2. The Experimental Environment
4.3. The Experimental Evaluation Index
4.4. The LSTM Network
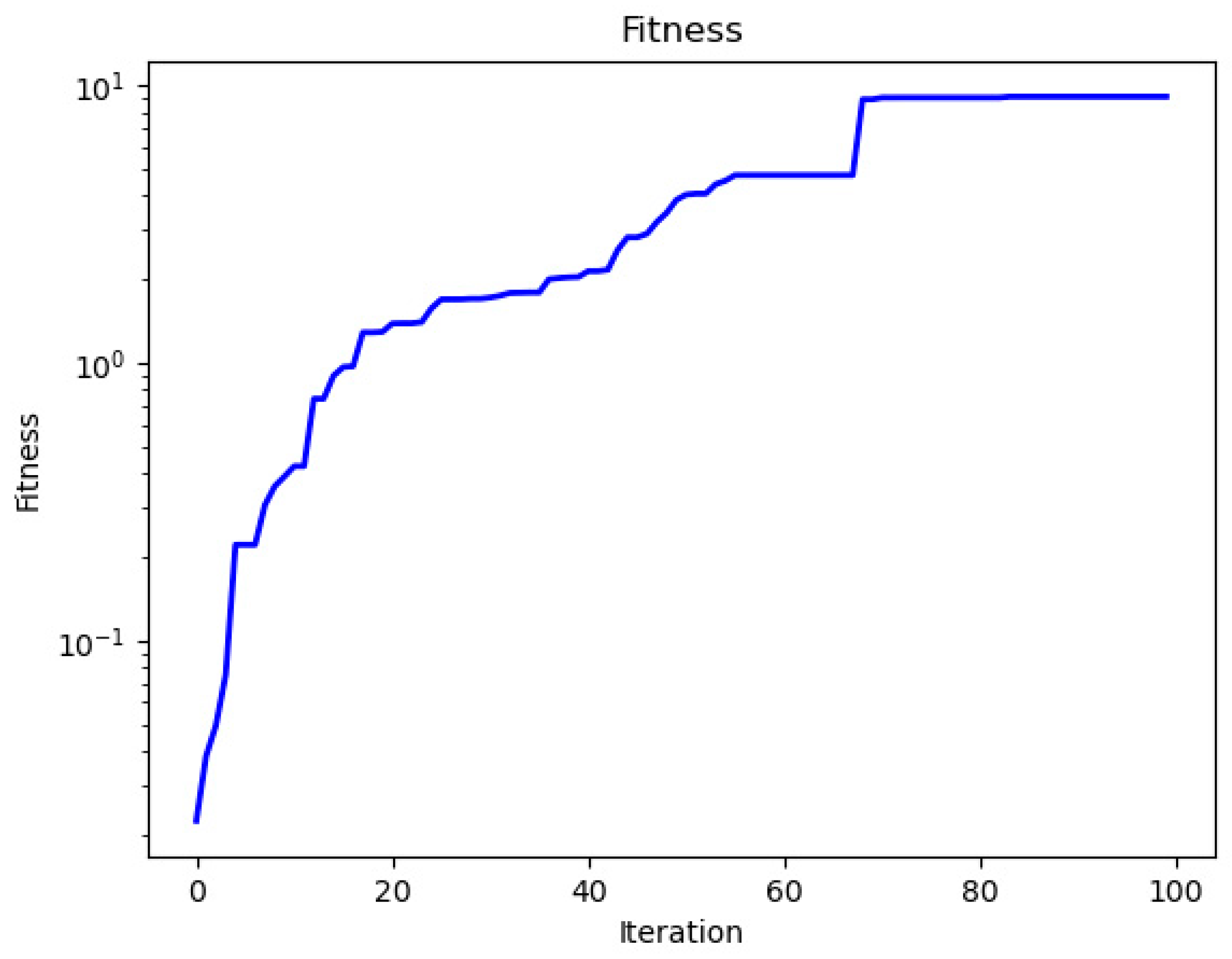
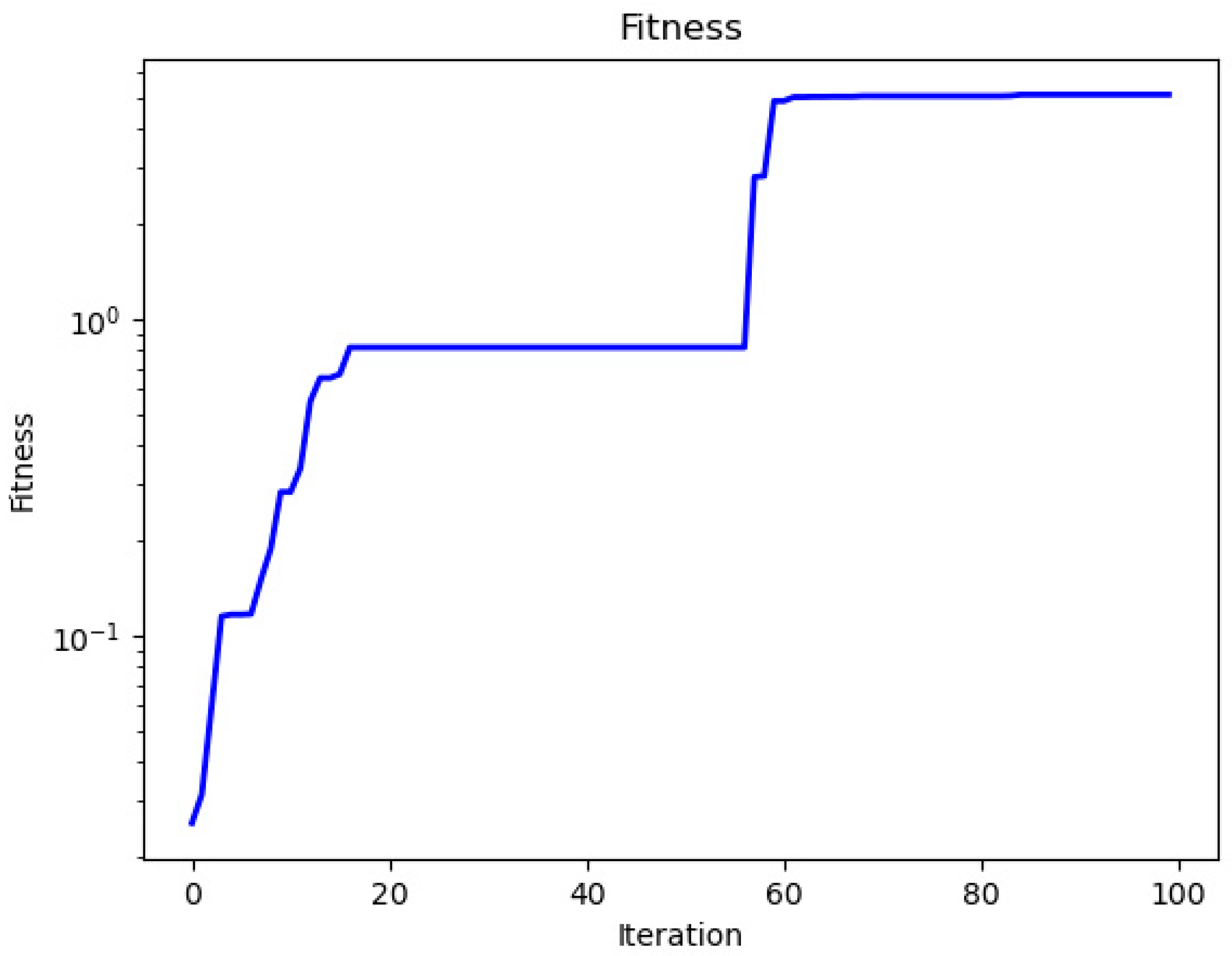
4.5. The LSTM Optimized via Hunter–Prey Optimization Algorithm
4.6. The Proposed Method Compared with LSTM and LSTM Optimized via WOA
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| Symbol | Property | Units |
| PM10 | Particulate matter smaller than 10 microns | μg/m3 |
| PM2.5 | Particulate matter smaller than 2.5 microns | μg/m3 |
| SO2 | Sulfur dioxide | μg/m3 |
| NO2 | Nitrogen dioxide | μg/m3 |
| CO | Carbon monoxide | μg/m3 |
| O3 | Ozone | μg/m3 |
| SVM | Support vector machine | - |
| BP | Back-propagation network | - |
| CNN | Convolutional neural network | - |
| LSTM | Long short-term memory network | - |
| HPO | Hunter–prey optimization algorithm | - |
| WOA | Whale optimization algorithm | - |
References
- Aliyu, Y.A.; Botai, J.O. Reviewing the local and global implications of air pollution trends in Zaria, northern Nigeria. Urban Clim. 2018, 26, 51–59. [Google Scholar] [CrossRef]
- Chen, Y.; Jiao, Z.; Chen, P.; Fan, L.; Zhou, X.; Pu, Y.; Du, W.; Yin, L. Short-term effect of fine particulate matter and ozone on non-accidental mortality and respiratory mortality in Lishui district, China. BMC Public Health 2021, 21, 1661. [Google Scholar] [CrossRef] [PubMed]
- Mądziel, M.; Campisi, T. Investigation of Vehicular Pollutant Emissions at 4-Arm Intersections for the Improvement of Integrated Actions in the Sustainable Urban Mobility Plans (SUMPs). Sustainability 2023, 15, 1860. [Google Scholar] [CrossRef]
- Jensen, S.S.; Ketzel, M.; Becker, T.; Christensen, J.; Brandt, J.; Plejdrup, M.; Winther, M.; Nielsen, O.-K.; Hertel, O.; Ellermann, T. High resolution multi-scale air quality modelling for all streets in Denmark. Transp. Res. Part D Transp. Environ. 2017, 52, 322–339. [Google Scholar] [CrossRef]
- Chauhan, A.J.; Johnston, S.L. Air pollution and infection in respiratory illness. Br. Med. Bull. 2003, 68, 95–112. [Google Scholar] [CrossRef] [PubMed]
- Plummer, L.E.; Smiley-Jewell, S.; Pinkerton, K.E. Impact of air pollution on lung inflammation and the role of Toll-like receptors. Int. J. Interferon Cytokine Mediat. Res. 2012, 4, 43–57. [Google Scholar]
- Cohen, A.J.; Brauer, M.; Burnett, R.; Anderson, H.R.; Frostad, J.; Estep, K.; Balakrishnan, K.; Dandona, L.; Dandona, R.; Feigin, V. Estimates and 25-year trends of the global burden of disease attributable to ambient air pollution: An analysis of data from the Global Burden of Diseases Study 2015. Lancet 2017, 389, 1907–1918. [Google Scholar] [CrossRef]
- Yin, P.; He, G.; Fan, M.; Chiu, K.Y.; Fan, M.; Liu, C.; Xue, A.; Liu, T.; Pan, Y.; Mu, Q.; et al. Particulate air pollution and mortality in 38 of China’s largest cities: Time series analysis. BMJ 2017, 356, j667. [Google Scholar] [CrossRef]
- Nations, U. The World’s Cities in 2018—Data Booklet; Department of Economic and Social Affairs: New York, NY, USA, 2018; Population Division. [Google Scholar]
- Alegria, A.; Barbera, R.; Boluda, R.; Errecalde, F.; Farré, R.; Lagarda, M.J. Environmental cadmium, lead and nickel contamination: Possible relationship between soil and vegetable content. Fresenius’ J. Anal. Chem. 1991, 339, 654–657. [Google Scholar] [CrossRef]
- Ercilla-Montserrat, M.; Muñoz, P.; Montero, J.I.; Gabarrell, X.; Rieradevall, J. A study on air quality and heavy metals content of urban food produced in a Mediterranean city (Barcelona). J. Clean. Prod. 2018, 195, 385–395. [Google Scholar] [CrossRef]
- Huang, M.; Zhang, T.; Wang, J.; Zhu, L. A new air quality forecasting model using data mining and artificial neural network. In Proceedings of the 6th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 September 2015; pp. 259–262. [Google Scholar]
- Kang, G.K.; Gao, J.Z.; Chiao, S.; Lu, S.; Xie, G. Air quality prediction: Big data and machine learning approaches. Int. J. Environ. Sci. Dev 2018, 9, 8–16. [Google Scholar] [CrossRef]
- Afzali, A.; Rashid, M.; Afzali, M.; Younesi, V. Prediction of air pollutants concentrations from multiple sources using AERMOD coupled with WRF prognostic model. J. Clean. Prod. 2017, 166, 1216–1225. [Google Scholar] [CrossRef]
- Ghaemi, Z.; Farnaghi, M.; Alimohammadi, A. Hadoop-based distributed system for online prediction of air pollution based on support vector machine. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 215. [Google Scholar] [CrossRef]
- Wang, P.; Liu, Y.; Qin, Z.; Zhang, G. A novel hybrid forecasting model for PM10 and SO2 daily concentrations. Sci. Total Environ. 2015, 505, 1202–1212. [Google Scholar] [CrossRef]
- Rybarczyk, Y.; Zalakeviciute, R. Machine learning approaches for outdoor air quality modelling: A systematic review. Appl. Sci. 2018, 8, 2570. [Google Scholar] [CrossRef]
- Taghavifar, H.; Mardani, A.; Mohebbi, A.; Khalilarya, S.; Jafarmadar, S. Appraisal of artificial neural networks to the emission analysis and prediction of CO2, soot, and NOx of n-heptane fueled engine. J. Clean. Prod. 2016, 112, 1729–1739. [Google Scholar] [CrossRef]
- Taylan, O. Modelling and analysis of ozone concentration by artificial intelligent techniques for estimating air quality. Atmos. Environ. 2017, 150, 356–365. [Google Scholar] [CrossRef]
- Gao, M.; Yin, L.; Ning, J. Artificial neural network model for ozone concentration estimation and Monte Carlo analysis. Atmos. Environ. 2018, 184, 129–139. [Google Scholar] [CrossRef]
- García Nieto, P.J.; García-Gonzalo, E.; Bernardo Sánchez, A.; Rodríguez Miranda, A.A. Air quality modeling using the PSO-SVM-based approach, MLP neural network, and M5 model tree in the metropolitan area of Oviedo (Northern Spain). Environ. Model. Assess. 2018, 23, 229–247. [Google Scholar] [CrossRef]
- Gholizadeh, M.H.; Darand, M. Forecasting the Air Pollution with using Artificial Neural Networks: The Case Study; Tehran City. J. Appl. Sci. 2009, 9, 3882–3887. [Google Scholar] [CrossRef]
- Ai, H.; Shi, Y. Study on prediction of haze based on BP neural network. Comput. Simul. 2015, 32, 402–405 + 415. [Google Scholar]
- Zhao, W.; Xia, L.; Gao, G.; Cheng, L. PM2.5 prediction model based on weighted KNN-BP neural network. J. Environ. Eng. Technol. 2019, 9, 14–18. [Google Scholar]
- Biancofiore, F.; Busilacchio, M.; Verdecchia, M.; Tomassetti, B.; Aruffo, E.; Bianco, S.; Di Tommaso, S.; Colangeli, C.; Rosatelli, G.; Di Carlo, P. Recursive neural network model for analysis and forecast of PM10 and PM2.5. Atmos. Pollut. Res. 2017, 8, 652–659. [Google Scholar] [CrossRef]
- Liu, D.R.; Hsu, Y.K.; Chen, H.-Y.; Jau, H.-J. Air pollution prediction based on factory-aware attentional LSTM neural network. Computing 2021, 103, 75–98. [Google Scholar] [CrossRef]
- Yang, C.; Wang, Y.; Shu, Z.; Liu, J.; Xie, N. Application of LSTM Model Based on TensorFlow in Air Quality Index Prediction. Digit. Technol. Appl. 2021, 39, 203–206. [Google Scholar]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef]
- Zhao, J.; Deng, F.; Cai, Y.; Chen, J. Long short-term memory-Fully connected (LSTM-FC) neural network for PM2.5 concentration prediction. Chemosphere 2019, 220, 486–492. [Google Scholar] [CrossRef]
- Yin, X.; Goudriaan, J.; Lantinga, E.A.; Vos, J.; Spiertz, H.J. A flexible sigmoid function of determinate growth. Ann. Bot. 2003, 91, 361–371. [Google Scholar] [CrossRef]
- Fan, J.; Li, Q.; Hou, J.; Feng, X.; Karimian, H.; Lin, S. A spatiotemporal prediction framework for air pollution based on deep RNN. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 15. [Google Scholar] [CrossRef]
- Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Naruei, I.; Keynia, F.; Sabbagh Molahosseini, A. Hunter–Prey optimization: Algorithm and applications. Soft Comput. 2022, 26, 1279–1314. [Google Scholar] [CrossRef]
- Mądziel, M.; Campisi, T. Energy Consumption of Electric Vehicles: Analysis of Selected Parameters Based on Created Database. Energies 2023, 16, 1437. [Google Scholar] [CrossRef]
- Xiang, C.; Gu, J.; Luo, J.; Qu, H.; Sun, C.; Jia, W.; Wang, F. Structural Damage Identification Based on Convolutional Neural Networks and Improved Hunter–Prey Optimization Algorithm. Buildings 2022, 12, 1324. [Google Scholar] [CrossRef]
- Berryman, A.A. The orgins and evolution of predator-prey theory. Ecology 1992, 73, 1530–1535. [Google Scholar] [CrossRef]
- Krebs, C.J. Ecology: The Experimental Analysis of Distribution and Abundance; Harper and Row: New York, NY, USA, 1972; pp. 1–14. [Google Scholar]
- Nasiri, J.; Khiyabani, F.M. A whale optimization algorithm (WOA) approach for clustering. Cogent Math. Stat. 2018, 5, 1483565. [Google Scholar] [CrossRef]
- Wu, H.; Li, Z. WOA-LSTM. Acad. J. Environ. Earth Sci. 2022, 4, 1–6. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | PM10 (μg/m3) | PM2.5 (μg/m3) | SO2 (μg/m3) | NO2 (μg/m3) | CO (μg/m3) | O3 (μg/m3) |
|---|---|---|---|---|---|---|
| 2018-01-01 01:00 | 436 | 201 | 27 | 85 | 2.2 | 5 |
| 2018-01-01 02:00 | 403 | 261 | 24 | 77 | 2.5 | 6 |
| 2018-01-01 03:00 | 477 | 358 | 33 | 79 | 2.9 | 7 |
| Grade | PM10 (μg/m3) | PM2.5 (μg/m3) | SO2 (μg/m3) | NO2 (μg/m3) | CO (μg/m3) | O3 (μg/m3) |
|---|---|---|---|---|---|---|
| 0 | 0–50 | 0–35 | 0–150 | 0–100 | 0–5 | 0–160 |
| 1 | 51–150 | 35–75 | 150–500 | 100–200 | 5–10 | 160–200 |
| 2 | 150–250 | 75–115 | 500–650 | 200–700 | 10–35 | 200–300 |
| 3 | 250–350 | 115–150 | 650–800 | 700–1200 | 35–60 | 300–400 |
| 4 | 350–420 | 150–250 | 800+ | 1200–2340 | 60–90 | 400–800 |
| 5 | 420–500 | 250–350 | - | 2340–3090 | 90–120 | 800–1000 |
| 6 | 500–600 | 350–500 | - | 3090–3840 | 120–150 | 1000–1200 |
| 7 | 600+ | 500+ | - | 3840+ | 150+ | 1200+ |
| Time | PM10 Grades | PM2.5 Grades | SO2 Grades | NO2 Grades | CO Grades | O3 Grades |
|---|---|---|---|---|---|---|
| 2018-01-01 01:00 | 5 | 4 | 0 | 0 | 0 | 0 |
| 2018-01-01 02:00 | 4 | 5 | 0 | 0 | 0 | 0 |
| 2018-01-01 03:00 | 5 | 6 | 0 | 0 | 0 | 0 |
| Grade | PM10 (μg/m3) | PM2.5 (μg/m3) | SO2 (μg/m3) | NO2 (μg/m3) | CO (μg/m3) | O3 (μg/m3) |
|---|---|---|---|---|---|---|
| 0 | 0–50 | 0–35 | 0–5 | 0–30 | 0–0.6 | 0–25 |
| 1 | 50–150 | 35–75 | 5–10 | 30–50 | 0.6–1.0 | 25–50 |
| 2 | 150–250 | 75–115 | 10–15 | 50–100 | 1.0–1.5 | 50–100 |
| 3 | 250–350 | 115–150 | 15–150 | 100–200 | 1.5–5 | 100–160 |
| 4 | 350–420 | 150–250 | 150–500 | 200–700 | - | 160–200 |
| 5 | 420–500 | 250–350 | - | - | - | 200–300 |
| 6 | 500–600 | 350–500 | - | - | - | 300–400 |
| 7 | 600+ | - | - | - | - | - |
| Time | PM10 Grades | PM2.5 Grades | SO2 Grades | NO2 Grades | CO Grades | O3 Grades |
|---|---|---|---|---|---|---|
| 2018-01-01 01:00 | 5 | 4 | 3 | 2 | 3 | 0 |
| 2018-01-01 02:00 | 4 | 5 | 3 | 2 | 3 | 0 |
| 2018-01-01 03:00 | 5 | 6 | 3 | 2 | 3 | 0 |
| Dataset Name | Xin Cheng Center Square Station | Cao Tang Base | Gao Xin West Station |
|---|---|---|---|
| Number | Dataset 1 | Dataset 2 | Dataset 3 |
| Original Datasets | 25,545 | 14,543 | 14,544 |
| Reconstructed Datasets | 25,064 | 14,321 | 13,711 |
| Dataset | Number of Samples | |
|---|---|---|
| Training Set | Testing Set | |
| Dataset 1 | 17,120 | 7896 |
| Dataset 2 | 6976 | 6976 |
| Dataset 3 | 6476 | 6476 |
| Methods | PM10 | PM2.5 | SO2 | NO2 | CO | O3 |
|---|---|---|---|---|---|---|
| BP | 84.3% | 89.9% | 72.8% | 76.4% | 74.9% | 66.2% |
| RNN | 84.6% | 88.8% | 85.5% | 81.6% | 83.7% | 82.0% |
| LSTM | 87.2% | 90.0% | 88.5% | 83.2% | 85.7% | 83.3% |
| Methods | PM10 | PM2.5 | SO2 | NO2 | CO | O3 |
|---|---|---|---|---|---|---|
| BP | 85.2% | 90.8% | 75.0% | 82.2% | 82.3% | 78.3% |
| RNN | 81.2% | 87.2% | 71.2% | 79.3% | 82.2% | 74.6% |
| LSTM | 86.2% | 91.3% | 83.9% | 83.8% | 86.0% | 83.2% |
| Methods | PM10 | PM2.5 | SO2 | NO2 | CO | O3 |
|---|---|---|---|---|---|---|
| BP | 87.2% | 77.7% | 84.4% | 81.0% | 81.0% | 84.2% |
| RNN | 84.4% | 77.6% | 70.3% | 78.3% | 72.3% | 84.5% |
| LSTM | 86.9% | 85.6% | 85.2% | 82.9% | 83.3% | 85.1% |
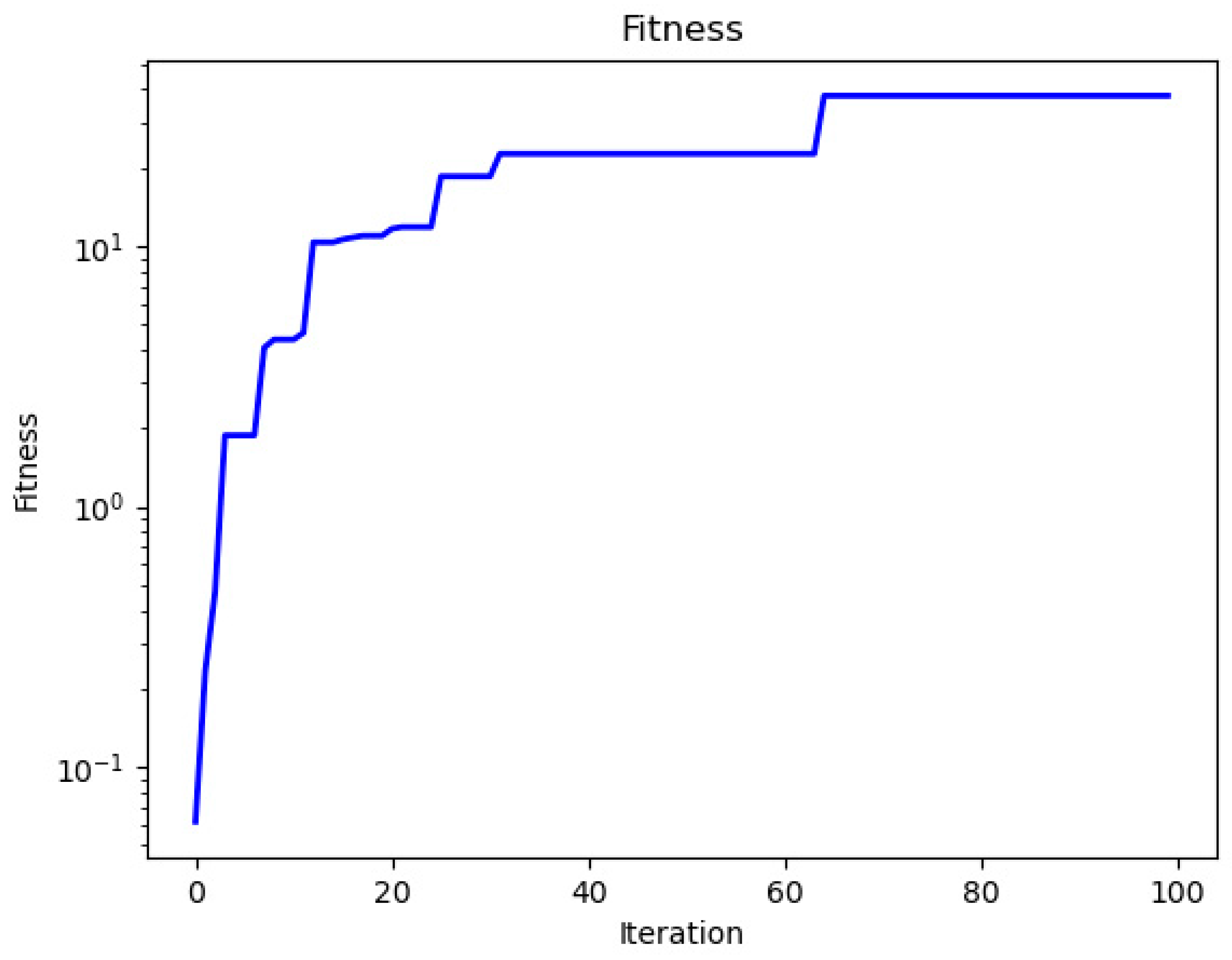
| Iterations | Fitness | Network Hyperparameters |
|---|---|---|
| 00 | 0.019 | {1, 24, 2, 6, 128, 0.1, 0.1} |
| 01 | 0.073 | {1, 24, 2, 6, 128, 0.1, 0.1} |
| 03 | 0.096 | {1, 24, 2, 6, 128, 0.1, 0.1} |
| 05 | 0.102 | {1, 24, 2, 6, 128, 0.1, 0.1} |
| 10 | 0.548 | {2, 24, 2, 6, 128, 0.1, 0.1} |
| 20 | 0.955 | {3, 24, 2, 6, 128, 0.1, 0.2} |
| 30 | 1.312 | {3, 24, 3, 6, 128, 0.1, 0.3} |
| 50 | 4.823 | {3, 24, 3, 12, 128, 0.12, 0.3} |
| 80 | 9.753 | {3, 24, 3, 12, 128, 0.15, 0.3} |
| 100 | 9.753 | {3, 24, 3, 12, 128, 0.15, 0.3} |
| Iterations | Fitness | Network Hyperparameters |
|---|---|---|
| 00 | 0.026 | {1, 24, 2, 6, 128, 0.1, 0.1} |
| 01 | 0.035 | {1, 24, 2, 6, 128, 0.1, 0.1} |
| 03 | 0.059 | {1, 24, 2, 6, 128, 0.1, 0.1} |
| 05 | 0.082 | {1, 24, 2, 6, 128, 0.1, 0.1} |
| 10 | 0.211 | {2, 24, 2, 6, 128, 0.1, 0.1} |
| 20 | 0.929 | {3, 24, 2, 6, 128, 0.1, 0.1} |
| 30 | 0.929 | {3, 24, 2, 6, 128, 0.1, 0.1} |
| 50 | 0.929 | {3, 24, 2, 6, 128, 0.1, 0.1} |
| 80 | 8.675 | {3, 24, 3, 16, 128, 0.2, 0.25} |
| 100 | 8.675 | {3, 24, 3, 16, 128, 0.2, 0.25} |
| Iterations | Fitness | Network Hyperparameters |
|---|---|---|
| 00 | 0.047 | {1, 24, 2, 6, 128, 0.1, 0.1} |
| 01 | 0.083 | {1, 24, 2, 6, 128, 0.1, 0.1} |
| 03 | 0.356 | {1, 24, 2, 6, 128, 0.1, 0.1} |
| 05 | 0.643 | {1, 24, 2, 6, 128, 0.1, 0.1} |
| 10 | 2.711 | {2, 24, 2, 6, 128, 0.15, 0.2} |
| 20 | 9.743 | {3, 24, 3, 12, 128, 0.2, 0.2} |
| 30 | 14.349 | {3, 24, 3, 16, 128, 0.2, 0.35} |
| 50 | 15.652 | {3, 24, 3, 16, 128, 0.2, 0.3} |
| 80 | 18.238 | {3, 24, 3, 16, 128, 0.2, 0.35} |
| 100 | 18.238 | {3, 24, 3, 16, 128, 0.2, 0.35} |
| Methods | PM10 | PM2.5 | SO2 | NO2 | CO | O3 |
|---|---|---|---|---|---|---|
| LSTM | 87.2% | 90.0% | 88.5% | 83.2% | 85.7% | 83.3% |
| LSTM_WOA | 89.0% | 91.1% | 90.3% | 87.0% | 86.8% | 86.2% |
| LSTM_HPO | 90.4% | 91.7% | 92.1% | 88.9% | 88.3% | 87.7% |
| Methods | PM10 | PM2.5 | SO2 | NO2 | CO | O3 |
|---|---|---|---|---|---|---|
| LSTM | 86.2% | 91.3% | 83.9% | 83.8% | 86.0% | 83.2% |
| LSTM_WOA | 89.6% | 91.6% | 87.0% | 85.4% | 87.1% | 85.4% |
| LSTM_HPO | 89.4% | 92.2% | 88.1% | 86.9% | 89.1% | 86.4% |
| Methods | PM10 | PM2.5 | SO2 | NO2 | CO | O3 |
|---|---|---|---|---|---|---|
| LSTM | 86.9% | 85.6% | 85.2% | 82.9% | 83.3% | 85.1% |
| LSTM_WOA | 88.9% | 89.5% | 88.9% | 83.2% | 86.4% | 86.9% |
| LSTM_HPO | 90.1% | 90.1% | 89.0% | 85.7% | 87.3% | 88.2% |
| Lead Time | PM10 | PM2.5 | SO2 | NO2 | CO | O3 |
|---|---|---|---|---|---|---|
| First hour | 90.4% | 91.7% | 92.1% | 88.9% | 88.3% | 87.7% |
| Second hour | 87.3% | 89.1% | 90.5% | 86.3% | 86.3% | 86.6% |
| Third hour | 84.7% | 86.5% | 88.2% | 83.6% | 83.2% | 85.1% |
| Fourth hour | 83.7% | 84.3% | 86.3% | 79.1% | 80.6% | 84.2% |
| Fifth hour | 81.9% | 82.0% | 83.9% | 76.4% | 75.0% | 82.8% |
| Sixth hour | 77.5% | 80.1% | 81.5% | 73.8% | 71.4% | 81.3% |
| Lead Time | PM10 | PM2.5 | SO2 | NO2 | CO | O3 |
|---|---|---|---|---|---|---|
| First hour | 89.4% | 92.2% | 88.1% | 86.9% | 89.1% | 86.4% |
| Second hour | 86.3% | 90.4% | 85.9% | 84.2% | 86.4% | 84.7% |
| Third hour | 83.7% | 88.5% | 83.2% | 81.3% | 83.5% | 83.1% |
| Fourth hour | 79.7% | 86.7% | 81.6% | 78.6% | 80.6% | 80.8% |
| Fifth hour | 76.9% | 82.0% | 78.4% | 74.2% | 77.4% | 78.9% |
| Sixth hour | 72.5% | 79.5% | 74.9% | 71.0% | 73.8% | 76.3% |
| Lead Time | PM10 | PM2.5 | SO2 | NO2 | CO | O3 |
|---|---|---|---|---|---|---|
| First hour | 90.1% | 90.1% | 89.0% | 85.7% | 87.3% | 88.2% |
| Second hour | 86.3% | 88.3% | 87.6% | 82.2% | 85.1% | 86.7% |
| Third hour | 83.8% | 85.7% | 85.6% | 79.3% | 82.5% | 84.5% |
| Fourth hour | 80.9% | 82.4% | 83.2% | 76.9% | 78.6% | 82.3% |
| Fifth hour | 77.5% | 79.5% | 80.8% | 72.6% | 73.4% | 80.1% |
| Sixth hour | 74.8% | 77.4% | 78.1% | 69.7% | 68.6% | 77.9% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, D.; Zheng, S.; Chen, J.; Zheng, Z.; Ding, C.; Zhang, L. Hyperparameter-Optimization-Inspired Long Short-Term Memory Network for Air Quality Grade Prediction. Information 2023, 14, 243. https://doi.org/10.3390/info14040243
Wen D, Zheng S, Chen J, Zheng Z, Ding C, Zhang L. Hyperparameter-Optimization-Inspired Long Short-Term Memory Network for Air Quality Grade Prediction. Information. 2023; 14(4):243. https://doi.org/10.3390/info14040243
Chicago/Turabian StyleWen, Dushi, Sirui Zheng, Jiazhen Chen, Zhouyi Zheng, Chen Ding, and Lei Zhang. 2023. "Hyperparameter-Optimization-Inspired Long Short-Term Memory Network for Air Quality Grade Prediction" Information 14, no. 4: 243. https://doi.org/10.3390/info14040243
APA StyleWen, D., Zheng, S., Chen, J., Zheng, Z., Ding, C., & Zhang, L. (2023). Hyperparameter-Optimization-Inspired Long Short-Term Memory Network for Air Quality Grade Prediction. Information, 14(4), 243. https://doi.org/10.3390/info14040243