
Explainable Ensemble Learning Approaches for Predicting the Compression Index of Clays


Abstract
1. Introduction
2. Data Overview and Analysis
3. Methodology
3.1. KNN Imputation for Missing Values
3.2. Ensemble Learning Algorithms
3.2.1. Random Forest
3.2.2. Gradient Boosting Decision Tree
3.2.3. Extreme Gradient Boosting
3.2.4. Stacking
3.3. SHAP for Model Interpretability
3.4. Implementation Pipeline
- Collect comprehensive global data, including LL, PI, , and w as input features and as the output feature, to minimize local bias.
- Apply KNN to impute missing values in the dataset, then partition the data into training and testing sets (80% training, 20% testing).
- Train and fine-tune different ensemble learning models—RF, GBDT, XGBoost, and Stacking—to realize data-driven prediction.
- Assess different models using Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), and Coefficient of Determination () to identify the best prediction model.
- Analyze and clarify the key factors influencing the performance of the best model via the interpretable machine learning algorithm SHAP.
4. Results
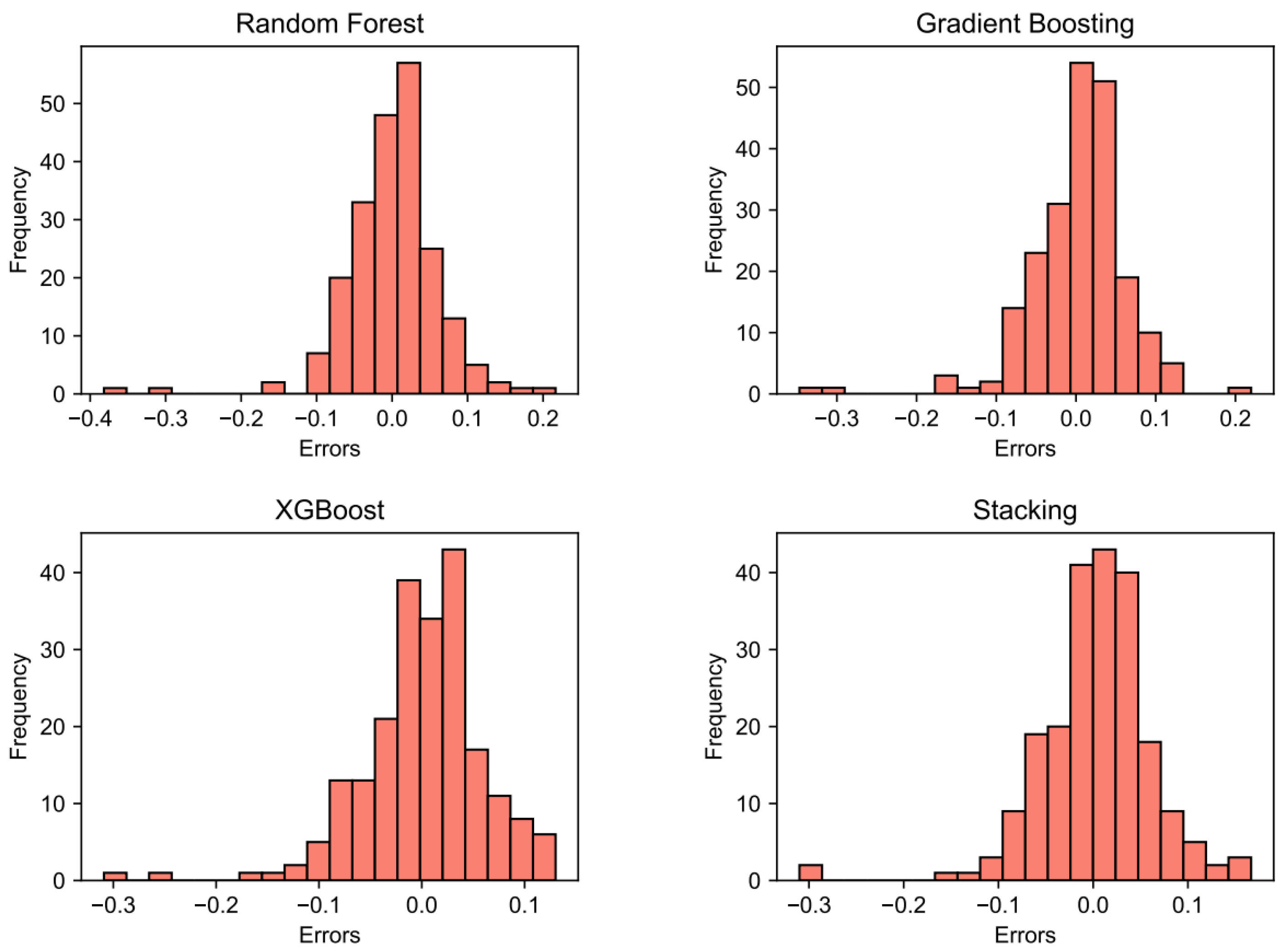
4.1. Prediction Results of ML Models
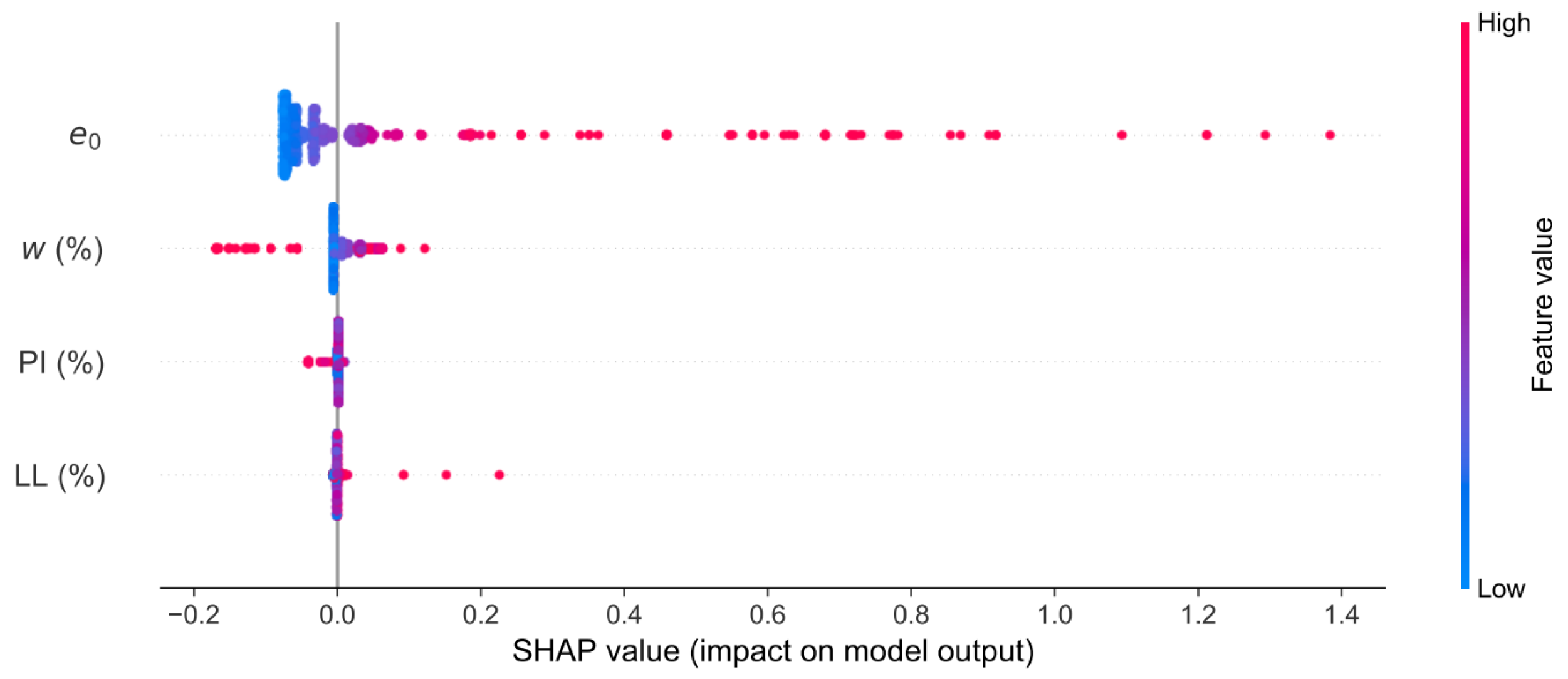
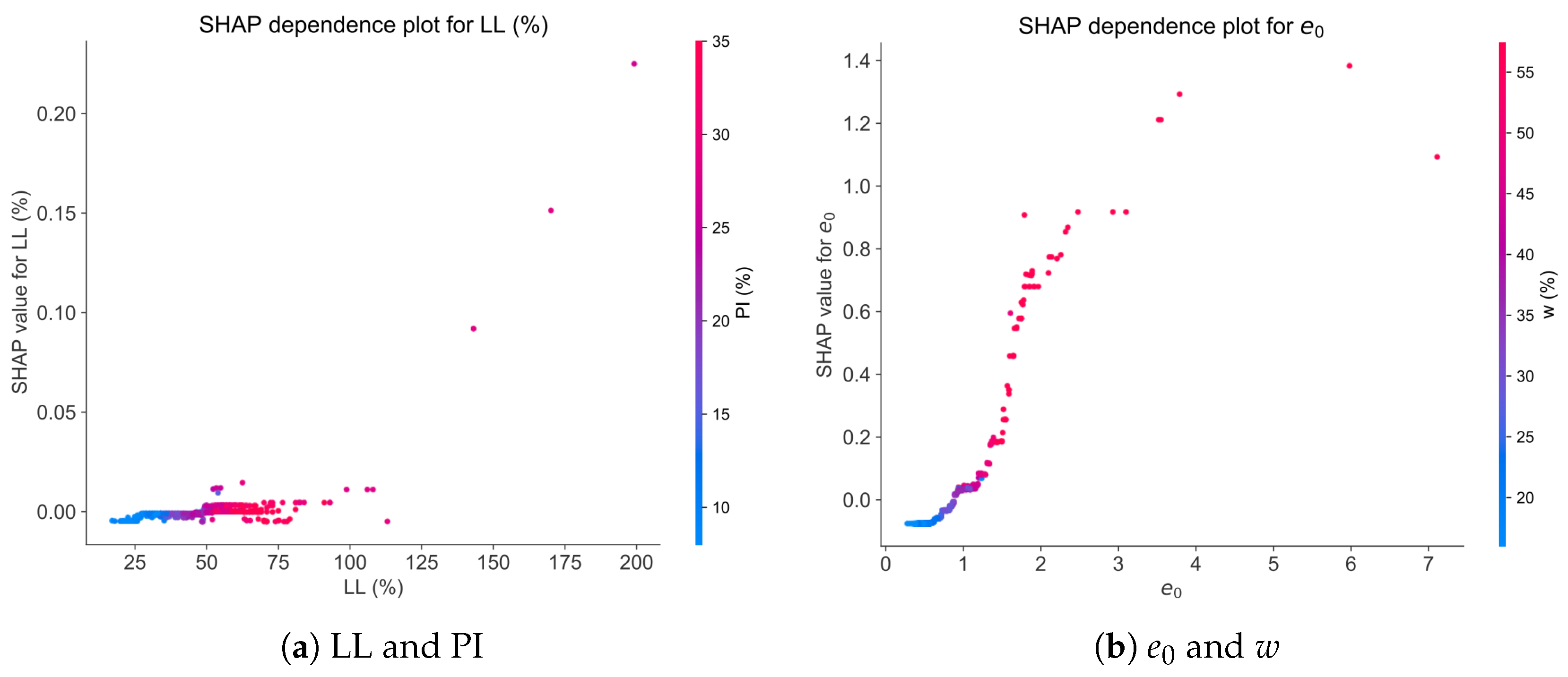
4.2. Analysis of Model Interpretability
5. Discussions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bugnot, A.; Mayer-Pinto, M.; Airoldi, L.; Heery, E.; Johnston, E.; Critchley, L.; Strain, E.; Morris, R.; Loke, L.; Bishop, M.; et al. Current and projected global extent of marine built structures. Nat. Sustain. 2021, 4, 33–41. [Google Scholar] [CrossRef]
- Li, J.; Chen, H.; Yuan, X.; Shan, W. Analysis of the effectiveness of the step vacuum preloading method: A case study on high clay content dredger fill in Tianjin, China. J. Mar. Sci. Eng. 2020, 8, 38. [Google Scholar] [CrossRef]
- Guo, X.; Fan, N.; Zheng, D.; Fu, C.; Wu, H.; Zhang, Y.; Song, X.; Nian, T. Predicting impact forces on pipelines from deep-sea fluidized slides: A comprehensive review of key factors. Int. J. Min. Sci. Technol. 2024, 34, 211–225. [Google Scholar] [CrossRef]
- Chen, X.; Yu, Y.; Wang, L. Assessing scour prediction models for monopiles in sand from the perspective of design robustness. Mar. Struct. 2024, 93, 103532. [Google Scholar] [CrossRef]
- Wang, J.; Dai, M.; Cai, Y.; Guo, L.; Du, Y.; Wang, C.; Li, M. Influences of initial static shear stress on the cyclic behaviour of over consolidated soft marine clay. Ocean Eng. 2021, 224, 108747. [Google Scholar] [CrossRef]
- Zheng, J.; Hu, X.; Gao, S.; Wu, L.; Yao, S.; Dai, M.; Liu, Z.; Wang, J. Undrained cyclic behavior of under-consolidated soft marine clay with different degrees of consolidation. Mar. Georesources Geotechnol. 2024, 42, 176–183. [Google Scholar] [CrossRef]
- Jiang, N.; Wang, C.; Wu, Q.; Li, S. Influence of structure and liquid limit on the secondary compressibility of soft soils. J. Mar. Sci. Eng. 2020, 8, 627. [Google Scholar] [CrossRef]
- Guo, X.; Nian, T.; Zhao, W.; Gu, Z.; Liu, C.; Liu, X.; Jia, Y. Centrifuge experiment on the penetration test for evaluating undrained strength of deep-sea surface soils. Int. J. Min. Sci. Technol. 2022, 32, 363–373. [Google Scholar] [CrossRef]
- Shimobe, S.; Spagnoli, G. A general overview on the correlation of compression index of clays with some geotechnical index properties. Geotech. Geol. Eng. 2022, 40, 311–324. [Google Scholar] [CrossRef]
- Alzabeebee, S.; Alshkane, Y.M.; Rashed, K.A. Evolutionary computing of the compression index of fine-grained soils. Arab. J. Geosci. 2021, 14, 2040. [Google Scholar] [CrossRef]
- Mawlood, Y.; Mohammed, A.; Hummadi, R.; Hasan, A.; Ibrahim, H. Modeling and statistical evaluations of unconfined compressive strength and compression index of the clay soils at various ranges of liquid limit. J. Test. Eval. 2022, 50, 551–569. [Google Scholar] [CrossRef]
- Sridharan, A.; Nagaraj, H. Compressibility behaviour of remoulded, fine-grained soils and correlation with index properties. Can. Geotech. J. 2000, 37, 712–722. [Google Scholar] [CrossRef]
- Spagnoli, G.; Shimobe, S. Statistical analysis of some correlations between compression index and Atterberg limits. Environ. Earth Sci. 2020, 79, 532. [Google Scholar] [CrossRef]
- Heo, Y.; Hwang, I.; Kang, C.; Bae, W. Correlations Between the Physical Properties and Consolidation Parameter of West Shore Clay. J. Korean GEO-Environ. Soc. 2015, 16, 33–40. [Google Scholar] [CrossRef]
- Park, H.I.; Lee, S.R. Evaluation of the compression index of soils using an artificial neural network. Comput. Geotech. 2011, 38, 472–481. [Google Scholar] [CrossRef]
- Bardhan, A.; Kardani, N.; Alzo’ubi, A.K.; Samui, P.; Gandomi, A.H.; Gokceoglu, C. A comparative analysis of hybrid computational models constructed with swarm intelligence algorithms for estimating soil compression index. Arch. Comput. Methods Eng. 2022, 29, 4735–4773. [Google Scholar] [CrossRef]
- Saisubramanian, R.; Murugaiyan, V. Prediction of compression index of marine clay using artificial neural network and multilinear regression models. J. Soft Comput. Civ. Eng. 2021, 5, 114–124. [Google Scholar]
- Benbouras, M.A.; Kettab Mitiche, R.; Zedira, H.; Petrisor, A.I.; Mezouar, N.; Debiche, F. A new approach to predict the compression index using artificial intelligence methods. Mar. Georesources Geotechnol. 2019, 37, 704–720. [Google Scholar] [CrossRef]
- Zhang, P.; Yin, Z.Y.; Jin, Y.F.; Chan, T.H.; Gao, F.P. Intelligent modelling of clay compressibility using hybrid meta-heuristic and machine learning algorithms. Geosci. Front. 2021, 12, 441–452. [Google Scholar] [CrossRef]
- Asteris, P.G.; Mamou, A.; Ferentinou, M.; Tran, T.T.; Zhou, J. Predicting clay compressibility using a novel Manta ray foraging optimization-based extreme learning machine model. Transp. Geotech. 2022, 37, 100861. [Google Scholar] [CrossRef]
- Long, T.; He, B.; Ghorbani, A.; Khatami, S.M.H. Tree-based techniques for predicting the compression index of clayey soils. J. Soft Comput. Civ. Eng. 2023, 7, 52–67. [Google Scholar]
- Lee, S.; Kang, J.; Kim, J.; Baek, W.; Yoon, H. A Study on Developing a Model for Predicting the Compression Index of the South Coast Clay of Korea Using Statistical Analysis and Machine Learning Techniques. Appl. Sci. 2024, 14, 952. [Google Scholar] [CrossRef]
- Díaz, E.; Spagnoli, G. A super-learner machine learning model for a global prediction of compression index in clays. Appl. Clay Sci. 2024, 249, 107239. [Google Scholar] [CrossRef]
- Castelvecchi, D. Can we open the black box of AI? Nat. News 2016, 538, 20. [Google Scholar] [CrossRef] [PubMed]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. (CSUR) 2018, 51, 1–42. [Google Scholar] [CrossRef]
- Rios, A.J.; Seghier, M.E.A.B.; Plevris, V.; Dai, J. Explainable ensemble learning framework for estimating corrosion rate in suspension bridge main cables. Results Eng. 2024, 23, 102723. [Google Scholar] [CrossRef]
- Zaman, M.W.; Hossain, M.R.; Shahin, H.; Alam, A. A study on correlation between consolidation properties of soil with liquid limit, in situ water content, void ratio and plasticity index. Geotech. Sustain. Infrastruct. Dev. 2016, 5, 899–902. [Google Scholar]
- McCabe, B.A.; Sheil, B.B.; Long, M.M.; Buggy, F.J.; Farrell, E.R. Empirical correlations for the compression index of Irish soft soils. Proc. Inst. Civ.-Eng. Eng. 2014, 167, 510–517. [Google Scholar] [CrossRef]
- Saha, A.; Nath, A.; Dey, A.K. Multivariate geophysical index-based prediction of the compression index of fine-grained soil through nonlinear regression. J. Appl. Geophys. 2022, 204, 104706. [Google Scholar] [CrossRef]
- Widodo, S.; Ibrahim, A. Estimation of primary compression index (Cc) using physical properties of Pontianak soft clay. Int. J. Eng. Res. Appl. 2012, 2, 2231–2235. [Google Scholar]
- Kalantary, F.; Kordnaeij, A. Prediction of compression index using artificial neural network. Sci. Res. Essays 2012, 7, 2835–2848. [Google Scholar] [CrossRef]
- Alhaji, M.M.; Alhassan, M.; Tsado, T.Y.; Mohammed, Y.A. Compression Index Prediction Models for Fine-grained Soil Deposits in Nigeria. In Proceedings of the 2nd International Engineering Conference, Charleston, SC, USA, 1–3 April 2017; Federal University of Technology: Minna, Nigeria, 2017. [Google Scholar]
- Amagu, A.; Eze, S.; Jun-Ichi, K.; Nweke, M. Geological and geotechnical evaluation of gully erosion at Nguzu Edda, Afikpo Sub-basin, southeastern Nigeria. J. Environ. Earth Sci. 2018, 8, 148–158. [Google Scholar]
- Amagu, C.A.; Enya, B.O.; Kodama, J.i.; Sharifzadeh, M. Impacts of Addition of Palm Kernel Shells Content on Mechanical Properties of Compacted Shale Used as an Alternative Landfill Liners. Adv. Civ. Eng. 2022, 2022, 9772816. [Google Scholar] [CrossRef]
- Murti, D.M.P.; Pujianto, U.; Wibawa, A.P.; Akbar, M.I. K-nearest neighbor (k-NN) based missing data imputation. In Proceedings of the 2019 5th International Conference on Science in Information Technology (ICSITech), Yogyakarta, Indonesia, 23–24 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 83–88. [Google Scholar]
- Jadhav, A.; Pramod, D.; Ramanathan, K. Comparison of performance of data imputation methods for numeric dataset. Appl. Artif. Intell. 2019, 33, 913–933. [Google Scholar] [CrossRef]
- Bhattacharya, G.; Ghosh, K.; Chowdhury, A.S. Test point specific k estimation for kNN classifier. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1478–1483. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ge, Q.; Liu, Z.q.; Sun, H.y.; Lang, D.; Shuai, F.x.; Shang, Y.q.; Zhang, Y.q. Robust design of self-starting drains using Random Forest. J. Mt. Sci. 2021, 18, 973–989. [Google Scholar] [CrossRef]
- Schapire, R.E. The boosting approach to machine learning: An overview. In Nonlinear Estimation and Classification; Springer: New York, NY, USA, 2003; pp. 149–171. [Google Scholar]
- Dong, X.; Guo, M.; Wang, S. GBDT-based multivariate structural stress data analysis for predicting the sinking speed of an open caisson foundation. Georisk Assess. Manag. Risk Eng. Syst. Geohazards 2024, 18, 333–345. [Google Scholar] [CrossRef]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T.; et al. Xgboost: Extreme Gradient Boosting. R Package Version 0.4-2. 2015. Available online: https://rdocumentation.org/packages/xgboost/versions/0.4-2 (accessed on 8 October 2015).
- Kavzoglu, T.; Teke, A. Advanced hyperparameter optimization for improved spatial prediction of shallow landslides using extreme gradient boosting (XGBoost). Bull. Eng. Geol. Environ. 2022, 81, 201. [Google Scholar] [CrossRef]
- Naimi, A.I.; Balzer, L.B. Stacked generalization: An introduction to super learning. Eur. J. Epidemiol. 2018, 33, 459–464. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Ma, Y.; Zhao, Y.; Yu, J.; Zhou, J.; Kuang, H. An interpretable gray box model for ship fuel consumption prediction based on the SHAP framework. J. Mar. Sci. Eng. 2023, 11, 1059. [Google Scholar] [CrossRef]
- Baptista, M.L.; Goebel, K.; Henriques, E.M. Relation between prognostics predictor evaluation metrics and local interpretability SHAP values. Artif. Intell. 2022, 306, 103667. [Google Scholar] [CrossRef]
- Ben Seghier, M.E.A.; Knudsen, O.Ø.; Skilbred, A.W.B.; Höche, D. An intelligent framework for forecasting and investigating corrosion in marine conditions using time sensor data. Npj Mater. Degrad. 2023, 7, 91. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maximum | Minimum | Mean | Median | SD | Range | |
|---|---|---|---|---|---|---|
| LL (%) | 199.0 | 17.1 | 45.4 | 44.0 | 14.5 | 181.9 |
| PI (%) | 69.0 | 2.0 | 21.3 | 21.5 | 9.0 | 67.0 |
| 7.1 | 0.3 | 0.8 | 0.7 | 0.4 | 6.8 | |
| w (%) | 244.1 | 8.0 | 29.2 | 25.9 | 15.2 | 236.1 |
| 2.2 | 0.01 | 0.2 | 0.2 | 0.2 | 2.2 |
| Model | RMSE | MAE | ||||
|---|---|---|---|---|---|---|
| Training | Test | Training | Test | Training | Test | |
| RF | 0.066 | 0.062 | 0.044 | 0.043 | 0.868 | 0.843 |
| GBDT | 0.061 | 0.062 | 0.042 | 0.044 | 0.890 | 0.844 |
| XGBoost | 0.062 | 0.063 | 0.042 | 0.043 | 0.884 | 0.839 |
| Stacking | 0.060 | 0.061 | 0.041 | 0.043 | 0.893 | 0.848 |
| PI Values | Mean | Maximum | Minimum | Median | Variance |
|---|---|---|---|---|---|
| Original data with missing values | 21.3 | 69.0 | 2.0 | 21.5 | 81.4 |
| After KNN interpolation | 21.6 | 69.0 | 2.0 | 22.0 | 79.6 |
| After polynomial interpolation | 21.8 | 100.8 | −4.8 | 22.0 | 102.6 |
| After spline interpolation | 21.8 | 99.8 | −12.2 | 22.0 | 107.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, Q.; Xia, Y.; Shu, J.; Li, J.; Sun, H. Explainable Ensemble Learning Approaches for Predicting the Compression Index of Clays. J. Mar. Sci. Eng. 2024, 12, 1701. https://doi.org/10.3390/jmse12101701
Ge Q, Xia Y, Shu J, Li J, Sun H. Explainable Ensemble Learning Approaches for Predicting the Compression Index of Clays. Journal of Marine Science and Engineering. 2024; 12(10):1701. https://doi.org/10.3390/jmse12101701
Chicago/Turabian StyleGe, Qi, Yijie Xia, Junwei Shu, Jin Li, and Hongyue Sun. 2024. "Explainable Ensemble Learning Approaches for Predicting the Compression Index of Clays" Journal of Marine Science and Engineering 12, no. 10: 1701. https://doi.org/10.3390/jmse12101701
APA StyleGe, Q., Xia, Y., Shu, J., Li, J., & Sun, H. (2024). Explainable Ensemble Learning Approaches for Predicting the Compression Index of Clays. Journal of Marine Science and Engineering, 12(10), 1701. https://doi.org/10.3390/jmse12101701