
Predicting Conversion from MCI to AD Combining Multi-Modality Data and Based on Molecular Subtype


Abstract
1. Introduction
2. Materials and Methods
2.1. Genomic Data and Imaging Data
2.2. MCI Subtype Identification Based on Similarity Network Fusion
2.3. Feature Selection Based on Lasso Method
2.4. Construction of the Variational Bayes Classification Model
3. Results
3.1. Identifying Subtypes of MCI Patients
3.2. Predicting Conversion from MCI to AD
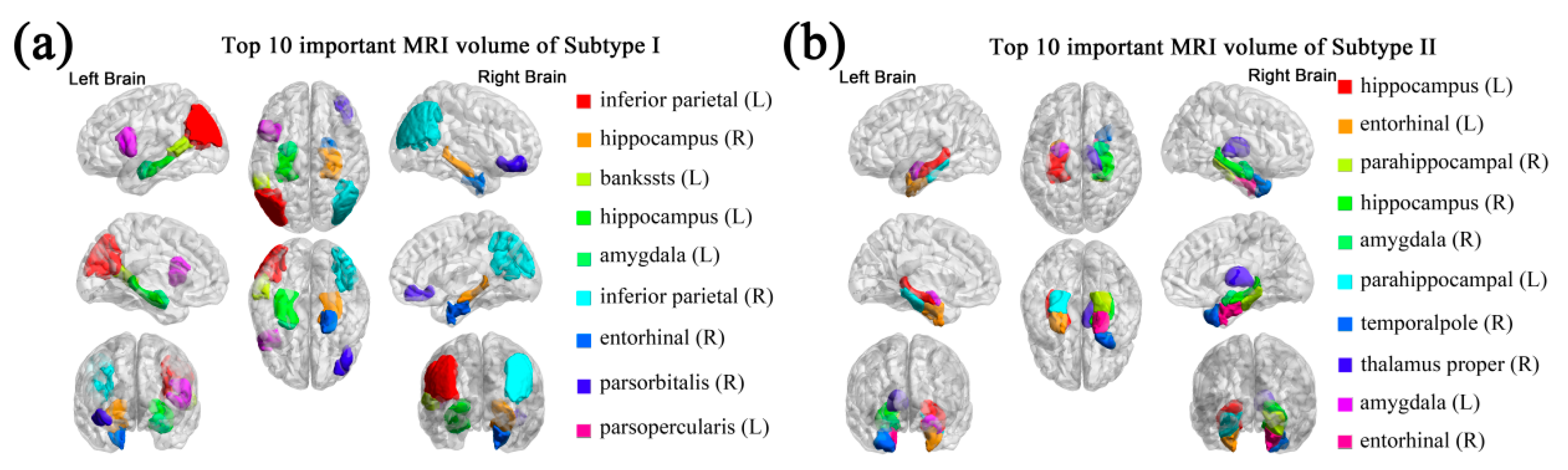
3.3. Important Features
3.4. Comparison with Current Models
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- 2020 Alzheimer’s Disease Facts and Figures. Alzheimer’s Dement. 2020, 16, 391–460. [CrossRef]
- Le, H.; La, B.; Pa, S.; Da, E. Annual Incidence of Alzheimer Disease in the United States Projected to the Years 2000 through 2050. Available online: https://pubmed.ncbi.nlm.nih.gov/11723367/ (accessed on 21 February 2021).
- Hebert, L.E.; Weuve, J.; Scherr, P.A.; Evans, D.A. Alzheimer Disease in the United States (2010–2050) Estimated Using the 2010 Census. Neurology 2013, 80, 1778–1783. [Google Scholar] [CrossRef]
- Ward, A.; Tardiff, S.; Dye, C.; Arrighi, H.M. Rate of Conversion from Prodromal Alzheimer’s Disease to Alzheimer’s Dementia: A Systematic Review of the Literature. Dement. Geriatr. Cogn. Dis. Extra 2013, 3, 320–332. [Google Scholar] [CrossRef] [PubMed]
- Mitchell, A.J.; Shiri-Feshki, M. Rate of Progression of Mild Cognitive Impairment to Dementia--Meta-Analysis of 41 Robust Inception Cohort Studies. Acta Psychiatr. Scand. 2009, 119, 252–265. [Google Scholar] [CrossRef]
- Murray, M.E.; Graff-Radford, N.R.; Ross, O.A.; Petersen, R.C.; Duara, R.; Dickson, D.W. Neuropathologically Defined Subtypes of Alzheimer’s Disease with Distinct Clinical Characteristics: A Retrospective Study. Lancet Neurol. 2011, 10, 785–796. [Google Scholar] [CrossRef]
- Park, J.-Y.; Na, H.K.; Kim, S.; Kim, H.; Kim, H.J.; Seo, S.W.; Na, D.L.; Han, C.E.; Seong, J.-K.; Alzheimer’s Disease Neuroimaging Initiative. Robust Identification of Alzheimer’s Disease Subtypes Based on Cortical Atrophy Patterns. Sci. Rep. 2017, 7, 43270. [Google Scholar] [CrossRef] [PubMed]
- Qiang, W.; Yau, W.-M.; Lu, J.-X.; Collinge, J.; Tycko, R. Structural Variation in Amyloid-β Fibrils from Alzheimer’s Disease Clinical Subtypes. Nature 2017, 541, 217–221. [Google Scholar] [CrossRef] [PubMed]
- Mukherjee, S.; Mez, J.; Trittschuh, E.H.; Saykin, A.J.; Gibbons, L.E.; Fardo, D.W.; Wessels, M.; Bauman, J.; Moore, M.; Choi, S.-E.; et al. Genetic Data and Cognitively Defined Late-Onset Alzheimer’s Disease Subgroups. Mol. Psychiatry 2018. [Google Scholar] [CrossRef] [PubMed]
- Li, H.-T.; Yuan, S.-X.; Wu, J.-S.; Zhang, X.-Z.; Liu, Y.; Sun, X.; For the Alzheimer’s Disease Neuroimaging Initiative. Molecular Subtyping of Mild Cognitive Impairment Based on Genetic Polymorphism and Gene Expression. J. Prev. Alzheimers Dis. 2020. [Google Scholar] [CrossRef]
- Russo, M.J.; Campos, J.; Vázquez, S.; Sevlever, G.; Allegri, R.F.; Alzheimer’s Disease Neuroimaging Initiative. Adding Recognition Discriminability Index to the Delayed Recall Is Useful to Predict Conversion from Mild Cognitive Impairment to Alzheimer’s Disease in the Alzheimer’s Disease Neuroimaging Initiative. Front. Aging Neurosci. 2017, 9, 46. [Google Scholar] [CrossRef]
- Barnes, D.E.; Cenzer, I.S.; Yaffe, K.; Ritchie, C.S.; Lee, S.J.; Alzheimer’s Disease Neuroimaging Initiative. A Point-Based Tool to Predict Conversion from Mild Cognitive Impairment to Probable Alzheimer’s Disease. Alzheimers Dement 2014, 10, 646–655. [Google Scholar] [CrossRef] [PubMed]
- Weiner, M.W.; Aisen, P.S.; Jack, C.R.; Jagust, W.J.; Trojanowski, J.Q.; Shaw, L.; Saykin, A.J.; Morris, J.C.; Cairns, N.; Beckett, L.A.; et al. The Alzheimer’s Disease Neuroimaging Initiative: Progress Report and Future Plans. Alzheimer’s Dement. 2010, 6, 202–211.e7. [Google Scholar] [CrossRef] [PubMed]
- Weiner, M.W.; Veitch, D.P.; Aisen, P.S.; Beckett, L.A.; Cairns, N.J.; Green, R.C.; Harvey, D.; Jack, C.R.; Jagust, W.; Morris, J.C.; et al. The Alzheimer’s Disease Neuroimaging Initiative 3: Continued Innovation for Clinical Trial Improvement. Alzheimer’s Dement. 2017, 13, 561–571. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Mezlini, A.M.; Demir, F.; Fiume, M.; Tu, Z.; Brudno, M.; Haibe-Kains, B.; Goldenberg, A. Similarity Network Fusion for Aggregating Data Types on a Genomic Scale. Nat. Methods 2014, 11, 333–337. [Google Scholar] [CrossRef] [PubMed]
- Damoulas, T.; Girolami, M.A. Pattern Recognition with a Bayesian Kernel Combination Machine. Pattern Recognit. Lett. 2009, 30, 46–54. [Google Scholar] [CrossRef]
- Damoulas, T.; Girolami, M.A. Combining Feature Spaces for Classification. Pattern Recognit. 2009, 42, 2671–2683. [Google Scholar] [CrossRef]
- Purcell, S.; Neale, B.; Todd-Brown, K.; Thomas, L.; Ferreira, M.A.R.; Bender, D.; Maller, J.; Sklar, P.; de Bakker, P.I.W.; Daly, M.J.; et al. PLINK: A Tool Set for Whole-Genome Association and Population-Based Linkage Analyses. Am. J. Hum. Genet. 2007, 81, 559–575. [Google Scholar] [CrossRef]
- Howie, B.; Fuchsberger, C.; Stephens, M.; Marchini, J.; Abecasis, G.R. Fast and Accurate Genotype Imputation in Genome-Wide Association Studies through Pre-Phasing. Nat. Genet. 2012, 44, 955–959. [Google Scholar] [CrossRef]
- Irizarry, R.A.; Bolstad, B.M.; Collin, F.; Cope, L.M.; Hobbs, B.; Speed, T.P. Summaries of Affymetrix GeneChip Probe Level Data. Nucleic Acids Res. 2003, 31, e15. [Google Scholar] [CrossRef]
- Voevodskaya, O.; Simmons, A.; Nordenskjöld, R.; Kullberg, J.; Ahlström, H.; Lind, L.; Wahlund, L.-O.; Larsson, E.-M.; Westman, E.; Initiative, A.D.N. The Effects of Intracranial Volume Adjustment Approaches on Multiple Regional MRI Volumes in Healthy Aging and Alzheimer’s Disease. Front. Aging Neurosci. 2014, 6. [Google Scholar] [CrossRef]
- Zhu, X.; Ghahramani, Z. Learning from Labeled and Unlabeled Data with Label Propagation; Carnegie Mellon University: Pittsburgh, PA, USA, 2002. [Google Scholar]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Wang, J.; Wonka, P.; Ye, J. Lasso Screening Rules via Dual Polytope Projection; NIPS: San Diego, CA, USA, 2013. [Google Scholar]
- Liu, J.; Ji, S.; Ye, J. SLEP: Sparse Learning with Efficient Projections; Arizona State University: Tempe, AZ, USA, 2009. [Google Scholar]
- Damoulas, T.; Girolami, M.A. Probabilistic Multi-Class Multi-Kernel Learning: On Protein Fold Recognition and Remote Homology Detection. Bioinformatics 2008, 24, 1264–1270. [Google Scholar] [CrossRef] [PubMed]
- Korolev, I.O.; Symonds, L.L.; Bozoki, A.C.; Initiative, A.D.N. Predicting Progression from Mild Cognitive Impairment to Alzheimer’s Dementia Using Clinical, MRI, and Plasma Biomarkers via Probabilistic Pattern Classification. PLoS ONE 2016, 11, e0138866. [Google Scholar] [CrossRef]
- Xia, M.; Wang, J.; He, Y. BrainNet Viewer: A Network Visualization Tool for Human Brain Connectomics. PLoS ONE 2013, 8, e68910. [Google Scholar] [CrossRef] [PubMed]
- Gao, F.; Yoon, H.; Xu, Y.; Goradia, D.; Luo, J.; Wu, T.; Su, Y. AD-NET: Age-Adjust Neural Network for Improved MCI to AD Conversion Prediction. Neuroimage Clin. 2020, 27, 102290. [Google Scholar] [CrossRef] [PubMed]
- Lehallier, B.; Essioux, L.; Gayan, J.; Alexandridis, R.; Nikolcheva, T.; Wyss-Coray, T.; Britschgi, M.; Alzheimer’s Disease Neuroimaging Initiative. Combined Plasma and Cerebrospinal Fluid Signature for the Prediction of Midterm Progression From Mild Cognitive Impairment to Alzheimer Disease. JAMA Neurol. 2016, 73, 203–212. [Google Scholar] [CrossRef]
- Westman, E.; Muehlboeck, J.-S.; Simmons, A. Combining MRI and CSF Measures for Classification of Alzheimer’s Disease and Prediction of Mild Cognitive Impairment Conversion. NeuroImage 2012, 62, 229–238. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Shen, D.; Alzheimer’s Disease Neuroimaging Initiative. Multi-Modal Multi-Task Learning for Joint Prediction of Multiple Regression and Classification Variables in Alzheimer’s Disease. Neuroimage 2012, 59, 895–907. [Google Scholar] [CrossRef] [PubMed]
- Young, J.; Modat, M.; Cardoso, M.J.; Mendelson, A.; Cash, D.; Ourselin, S.; Alzheimer’s Disease Neuroimaging Initiative. Accurate Multimodal Probabilistic Prediction of Conversion to Alzheimer’s Disease in Patients with Mild Cognitive Impairment. Neuroimage Clin. 2013, 2, 735–745. [Google Scholar] [CrossRef]
- Hinrichs, C.; Singh, V.; Xu, G.; Johnson, S.C. Predictive Markers for AD in a Multi-Modality Framework: An Analysis of MCI Progression in the ADNI Population. NeuroImage 2011, 55, 574–589. [Google Scholar] [CrossRef]
- Schröder, J.; Pantel, J. Neuroimaging of Hippocampal Atrophy in Early Recognition of Alzheimer’s Disease—A Critical Appraisal after Two Decades of Research. Psychiatry Res. Neuroimaging 2016, 247, 71–78. [Google Scholar] [CrossRef] [PubMed]
- Lu, D.; Popuri, K.; Ding, G.W.; Balachandar, R.; Beg, M.F.; Alzheimer’s Disease Neuroimaging Initiative. Multiscale Deep Neural Network Based Analysis of FDG-PET Images for the Early Diagnosis of Alzheimer’s Disease. Med. Image Anal. 2018, 46, 26–34. [Google Scholar] [CrossRef] [PubMed]
- Wei, R.; Li, C.; Fogelson, N.; Li, L. Prediction of Conversion from Mild Cognitive Impairment to Alzheimer’s Disease Using MRI and Structural Network Features. Front. Aging Neurosci. 2016, 8, 76. [Google Scholar] [CrossRef] [PubMed]
- Horvath, S.; Zhang, Y.; Langfelder, P.; Kahn, R.S.; Boks, M.P.; van Eijk, K.; van den Berg, L.H.; Ophoff, R.A. Aging Effects on DNA Methylation Modules in Human Brain and Blood Tissue. Genome Biol. 2012, 13, R97. [Google Scholar] [CrossRef] [PubMed]
- Sattler, C.; Toro, P.; Schönknecht, P.; Schröder, J. Cognitive Activity, Education and Socioeconomic Status as Preventive Factors for Mild Cognitive Impairment and Alzheimer’s Disease. Psychiatry Res. 2012, 196, 90–95. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | AUC-ROC | Acc (%) | Sn (%) | Sp (%) |
|---|---|---|---|---|
| VBpMKL (Subtype I) | 0.8581 | 81.97 | 70.00 | 93.55 |
| VBpMKL (Subtype II) | 0.8623 | 78.13 | 88.89 | 73.91 |
| MCI-CPS (5-fold) | 0.8260 | 79.20 | 81.25 | 77.92 |
| Raw classifier | 0.7849 | 76.00 | 77.08 | 75.32 |
| Model | AUC-ROC | Acc (%) | Sn (%) | Sp (%) |
|---|---|---|---|---|
| MCI-CPS | 0.7809 | 74.49 | 74.19 | 74.63 |
| Raw classifier | 0.7646 | 69.39 | 67.74 | 70.15 |
| Method | AUC-ROC | Acc (%) | Sn (%) | Sp (%) |
|---|---|---|---|---|
| MCI-CPS | 0.7809 | 74.49 | 74.19 | 74.63 |
| Logistic regression | 0.5541 | 64.71 | 71.42 | 60.00 |
| Support vector machine | 0.7005 | 69.39 | 48.39 | 69.39 |
| Random forest | 0.7313 | 70.58 | 64.28 | 75.00 |
| Study | Markers | AUC-ROC | Acc (%) | Sn (%) | Sp (%) |
|---|---|---|---|---|---|
| MCI-CPS (5-fold) | SNP, mRNA expression data, sMRI | 0.83 | 79.20 | 81.25 | 77.92 |
| Raw classifier | SNP, mRNA expression data, sMRI | 0.78 | 76.00 | 77.08 | 75.32 |
| Lu et al. (2018) | PET | - | 81.55 | 73.33 | 83.83 |
| Wei et al. (2016) | sMRI | 0.74 | 66.00 | 55.30 | 75.90 |
| Gao et al. (2020) | sMRI, age | 0.81 | 76.00 | 80.00 | 73.00 |
| Lehallier et al. (2016) | CSF, sMRI, CICS | 0.82 | 80.00 | 88.00 | 70.00 |
| Westman et al. (2012) | sMRI, CSF | 0.76 | 68.50 | 74.10 | 63.00 |
| Zhang et al. (2012) | CSF, PET, sMRI | 0.80 | 73.90 | 68.60 | 73.60 |
| Young et al. (2013) | PET, sMRI | 0.80 | 74.10 | 78.70 | 65.60 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.-T.; Yuan, S.-X.; Wu, J.-S.; Gu, Y.; Sun, X. Predicting Conversion from MCI to AD Combining Multi-Modality Data and Based on Molecular Subtype. Brain Sci. 2021, 11, 674. https://doi.org/10.3390/brainsci11060674
Li H-T, Yuan S-X, Wu J-S, Gu Y, Sun X. Predicting Conversion from MCI to AD Combining Multi-Modality Data and Based on Molecular Subtype. Brain Sciences. 2021; 11(6):674. https://doi.org/10.3390/brainsci11060674
Chicago/Turabian StyleLi, Hai-Tao, Shao-Xun Yuan, Jian-Sheng Wu, Yu Gu, and Xiao Sun. 2021. "Predicting Conversion from MCI to AD Combining Multi-Modality Data and Based on Molecular Subtype" Brain Sciences 11, no. 6: 674. https://doi.org/10.3390/brainsci11060674
APA StyleLi, H.-T., Yuan, S.-X., Wu, J.-S., Gu, Y., & Sun, X. (2021). Predicting Conversion from MCI to AD Combining Multi-Modality Data and Based on Molecular Subtype. Brain Sciences, 11(6), 674. https://doi.org/10.3390/brainsci11060674