Featured Application
This study provides efficient scheduling algorithms for cloud manufacturing platforms, enabling optimal resource allocation while guaranteeing urgent task deadlines. The proposed methods significantly improve platform operational efficiency, and service quality.
Abstract
The cloud manufacturing (CMfg) platform serves as a centralized hub for allocating and scheduling tasks to distributed resources. It features a concrete two-agent model that addresses real-world industrial needs: the first agent handles long-term flexible tasks, while the second agent manages urgent short-term tasks, both sharing a common due date. The second agent employs multitasking scheduling, which allows for the flexible suspension and switching of tasks. This paper addresses a novel scheduling problem aimed at minimizing the total weighted completion time of the first agent’s jobs while guaranteeing the second agent’s due date. For single-machine cases, a polynomial algorithm provides an efficient baseline; for parallel machines, an exact branch-and-price approach is developed, where the polynomial method informs the pricing problem and structural properties accelerate convergence. Computational results demonstrate significant improvements: the branch-and-price solves large-sized instances (up to 40 jobs) within 7200 s, outperforming CPLEX, which fails to find solutions for instances with more than 15 jobs. This approach is scalable for industrial cloud manufacturing applications, such as automotive parts production, and is capable of handling both design validation and quality inspection tasks.
1. Introduction
The cloud manufacturing (CMfg) platform [1,2] serves as a centralized hub for allocating requested services to distributed resources. Users submit their service requests to the platform, which then allocates and schedules these requests as tasks to distributed resources. Each task comprises multiple product requirements of the same type and can be further divided into partial tasks [3]. The execution of a task necessitates the utilization of distributed resources over a certain period of time. Among these tasks, the long-term ones offering high flexibility are categorized as the first agent, while the urgent short-term one-off tasks with high priority are grouped into the second agent. For example, in a cloud manufacturing platform for automotive parts production, the first agent handles long-term design validation tasks that require flexible scheduling over weeks, while the second agent manages urgent quality inspection tasks for real-time orders that must be completed within hours. To ensure fair treatment of tasks in the second agent, multitasking scheduling approaches in the literature [4] are employed.
Multitasking scheduling is a significant area of study within operational research [5,6]. In the context of the CMfg platform, multitasking refers to the capability of distributed resources to suspend processing an unfinished task from the second agent and switch to another. This approach allows for efficient utilization of resources and improves the scheduling of tasks from the second agent. In this paper, we address a novel scheduling problem using the three-field notation [7]. The problem is denoted as , where “” indicates that the jobs (tasks) belonging to the second agent are processed using multitasking scheduling. Additionally, the makespan of the second agent jobs (tasks), denoted as , must not exceed its specified time limit . The objective is to minimize the total weighted completion time of jobs (tasks) from the first agent.
Given the critical nature of meeting urgent task deadlines in CMfg platforms, we focus on exact methods to guarantee optimality. This guarantee is essential for maintaining service-level agreements and platform reliability. The contributions of this research are summarized as follows: (1) A novel scheduling problem is formulated, denoted as . This problem formulation provides a framework for effectively managing the allocation and scheduling of tasks within the CMfg platform. (2) For the special case of a single machine, a polynomial algorithm is proposed. For the scheduling of parallel machines, an exact branch-and-price (B&P) approach is developed. This algorithm takes advantage of proposed structural properties and dominance rules, resulting in an effective solution approach. (3) Through extensive experiments, we demonstrate that our proposed B&P algorithm significantly outperforms the commercial solver CPLEX 12.9, solving problems with up to 40 jobs to optimality within 7200 s, while CPLEX 12.9 fails to find optimal solutions for instances exceeding 15 jobs.
The remainder of this paper is organized as follows. In Section 2, a comprehensive literature review is presented. Section 3 defines the problem and derives some structural properties. In Section 4, both the master problem and the pricing problem of B&P are formulated. A two-phase label-setting algorithm (TP-LS) is described in detail. Other procedures, such as the primary heuristic and branching rule, are also explained. The numerical results are reported in Section 5. Finally, conclusions are given in Section 6.
2. Related Work
This research is related to three streams of research topics: (1) multitasking scheduling, (2) two-agent scheduling, and (3) parallel machine scheduling. Table 1 summarizes the recent literature that considers at least one of the mentioned topics.
Hall et al. [4,8] first introduced the concept of multitasking scheduling by investigating the administrative planning. Subsequent research continued to explore this area, incorporating other manufacturing features. In particular, some studies focused on two-agent scheduling under a multitasking environment [3,9,10,11], which was originally motivated by specific manufacturing contexts. Wang et al. [3] pointed out that the CMfg platform allows unfinished tasks to occupy the common and limited resources and interrupt the tasks under processing. Thus, several fundamental and practical scheduling problems arising from this context were fully investigated, including complexity analysis, structure properties, and polynomial procedures. Li et al. [9] explored two-agent multitasking scheduling where interruption time is proportional to the remaining processing time of the interrupting tasks. They examined combinations of different cost functions and proposed corresponding polynomial and pseudo-polynomial time algorithms. Wu et al. [10] studied a single-machine two-agent multitasking scheduling problem to minimize the total tardiness of one agent, subject to an upper bound on the total completion time of the other agent. They developed a branch-and-bound method and three improved metaheuristic algorithms. Yang et al. [11] integrated the unrestricted due date assignment method into two-agent multitasking scheduling. The model aims to minimize the weighted sum of due date assignment cost and the number of late jobs for one agent, while limiting the total completion time of the other agent. They proved that the problem is NP hardness and designed a dynamic programming algorithm along with a fully polynomial time approximation scheme. Consistent with the aforementioned research, this work focuses on allocating requested tasks to distributed resources of the CMfg platform under a multitasking environment.

Table 1.
Summary of the most-related works.
Table 1.
Summary of the most-related works.
| Literature | Single Machine | Parallel Machine | Multitasking Scheduling | Two-Agent | Due Date | Approach | Complexity |
|---|---|---|---|---|---|---|---|
| Hall et al. [4] | ✓ | - | ✓ | - | - | Polynomial algorithm | |
| Li et al. [9] | ✓ | - | ✓ | ✓ | ✓ | Polynomial algorithm | |
| Yang et al. [11] | ✓ | - | ✓ | ✓ | ✓ | Dynamic programming | |
| Wang et al. [12] | ✓ | - | ✓ | - | ✓ | Polynomial algorithm | |
| Wang et al. [3] | ✓ | - | ✓ | ✓ | - | Polynomial algorithm | |
| Wu et al. [10] | ✓ | - | ✓ | ✓ | - | Branch-and-bound, genetic algorithm, simulated annealing algorithm, cloud-simulated algorithm | - |
| Lee et al. [13] | - | ✓ | - | ✓ | ✓ | Branch-and-bound | - |
| Xiong et al. [14] | - | ✓ | ✓ | - | - | Branch-and-price | - |
| Gao et al. [15] | - | ✓ | ✓ | - | - | Branch-and-price | - |
Note: A checkmark (✓) indicates that the study addresses the corresponding scheduling environment or characteristic.
Research on other topics has extended the concept to areas such as human opera-tor fatigue in a multitasking environment [5,16], including rate-modifying activity [17,18,19], deterioration effect [12], and job efficiency promotion [20]. Another extension is the multitasking scheduling considering due dates [21,22,23,24]. The mentioned works only considered the multitasking scheduling on a single machine. The idea of combining meta heuristics with elements of exact mathematical programming algorithms has been introduced for solving parallel machine scheduling under multitasking [14,15]. Xiong et al. [14] proposed an exact branch-and-price algorithm that utilizes a genetic algorithm (GA) to achieve an in–out column generation scheme for maintaining the stability of dual variables. Gao et al. [15] solved batches of jobs scheduled on parallel machines by a branch-and-price algorithm, combined with an artificial bee colony heuristic for quickly solving the pricing problem. Notably, Li et al. [25] explored the integration of worker multitasking into flexible job shop scheduling, proposing a mixed-integer linear programming model and an improved genetic algorithm (IGA4MW) to optimize total weighted tardiness and makespan. This work differs significantly from earlier studies by rigorously addressing the gap in exact solution methods for the parallel machine environment under hard due-date constraints for . Since the existing literature offers heuristic approaches or focuses on single-machine settings, they cannot guarantee optimality, which is critical for maintaining service-level agreements in commercial CMfg platforms. Our approach fills this gap by developing an exact branch-and-price algorithm that leverages proven structural properties.
Multi-agent scheduling is first proposed to address different agents with distinct preferred criteria [26,27]. Two-agent scheduling aims to determine the best solution for the first agent while the second agent has a certain value restriction [28]. Leung et al. [29] confirmed that the problem is NP hardness. Further studies considering manufacturing management characteristics have been widely carried out, such as total weighted earliness Ctardiness [30], just-in-time criterion [31], total weighted completion time [32], and total weighted late work [33]. For environments with more than two identical parallel machines, studies have focused on the scheduling of orders from different customers [13,34,35]. Lee et al. [13] developed a branch-and-bound algorithm using GA as initial solution generation, and then the branch-and-bound searching procedure achieved the scheduling of online and offline orders by utilizing the estimated lower bound of GA.
The most relevant optimal solution property of this research is the shortest weighted processing time (SWPT) rule [36]. The original typical application of SWPT is to solve the NP-hard problem [37], and SWPT is embedded into the column generation to enumerate the promising time nodes [38]. The studies of include those by Kowalczyk and Leus [39] and Kramer et al. [40], which proved tighter lower and upper bounds of the last job makespan on any machine and achieved great improvements for very large-sized instances. Recently, column generation combined with heuristics, such as GA-CG [41] and matheuristic [42], achieved good performance for vehicle scheduling problems. In this work, we prove that the investigated problem also has structure properties similar to SWPT and the upper bound of a makespan on any machine.
3. Problem Statement and Optimal Solution Properties
This section defines two problems associated with multitasking scheduling. The first one is the multitasking scheduling with two competitive agents ( and ) on single machines (); the other is the multitasking scheduling with two competitive agents on parallel machines (). is a long-term agent with high flexibility, and is a short-term one-off agent with a common due date. In the three-field notations, indicates that jobs in are scheduled according to multitasking rule; means the makespan constraint of due date; and represents the objective of the weighted completion time of jobs.
3.1. The Problem
Initially, we consider the case of two agents ( and ) on a single machine. has a promised or urgent common due date and a coefficient , and the objective is to minimize the total weighted completion time of while the makespan of satisfies the time limit . Suppose that is a multitasking schedule of . Because of multitasking, the processing time is position-dependent. The concept of position-dependent processing time encompasses not only the actual processing time of a task but also other factors such as the interruption time and switching time. As is processed at the first position; its actual processing time is , and its interruption time and switching time are and . Thus, the position-dependent processing time is . For the second job , because the jobs have been processed but not completed, the actual processing time is , and its interruption time and switching time are and . Therefore, the position-dependent processing time of is . According to the characteristics of multitasking scheduling [4], the processing time of th job is
Subsequently, symbols and represent jobs from ; and represent jobs from ; and represents jobs from .
- Parameters
| : | The processing time and weight of job , where . |
| : | The number of jobs contained in and . |
| : | The due date coefficient and the due date of . |
| : | A job interruption factor, where . |
| : | The job switching time, the time consumption required once switching. |
- Variables
| : | The position-dependent processing time of job , where . |
| : | The makespan of jobs from the second agent. |
| : | The completion time of job from the first agent, where . |
Remark 1.
The duration of an schedule is always if all jobs are processed on the same machine.
Remark 1 is proofed by Gao et al. [43] and is widely utilized in this paper.
Property 1.
As takes the constraint, there is an optimal schedule in which all jobs belonging are processed consecutively.
Proof .
Suppose that is an optimal schedule, with disjointed sub-schedules and , where are sub-schedules of and job . For the duration of , it can be concluded that
where is the schedule length of . That of is
Thus, there is another schedule . The weighted completion time of and in and is the same, since durations of and are equivalent. Then, the difference in weighted completion time between and is
Because of and , the weighted completion time of is larger than that of , which contradicts the assumption of . □
Property 2.
For the problem , the optimal schedule exists, if any, such that the jobs in are scheduled according to SWPT order and the block of is inserted into the SWPT sequence of to satisfy and .
Proof .
which contradicts the assumption of . proves that jobs scheduled in the SWPT order is optimal. The observation of is consistent with the SWPT order. □
The SWPT order is a scheduling rule that sequences jobs in ascending order of , where is a job’s processing time and is its weight. Suppose that is an optimal schedule, where satisfy . According to Property 1, the jobs belonging to can be regarded as a block, which can be inserted either in or , while just satisfying the due date of and . Here, we interchange and consider another schedule . Let be the duration of schedule . Because of the same sub-schedules and , the weighted completion time of is
Algorithm 1 is the polynomial algorithm (PolALG) for problem. In the worst case, the time complexity of Algorithm 1 is .
| Algorithm 1 Polynomial Algorithm PolALG |
| Input: , |
| Output: , , , . |
| 1: Let , , , . |
| 2: Determine duration of and : |
| , . |
| 3: for starts from the last job to the first job in do |
| 4: |
| 5: if then |
| 6: Record the inserted position of block |
| 7: break |
| 8: end if |
| 9: end for |
| 10: for starts from the first job to the last job in do |
| 11: if then |
| /* Determine the completion time of block */ |
| 12: ,. |
| 13: end if |
| 14: , ,. |
| 15: end for |
Figure 1 depicts a result of Algorithm 1. For Property 1, jobs 6–7 are processed consecutively, with . In the block, job 6 is processed at the first position; according to Formula (1), the processing time is . Since the percent of job 5 has been processed in , the processing time of job 5 is . As for jobs, jobs 1–4 are processed according to SWPT order, and the inserted position of the block just satisfies , resulting in minimized weighted completion time. The optimal weighted completion time depicted in Figure 1 is .
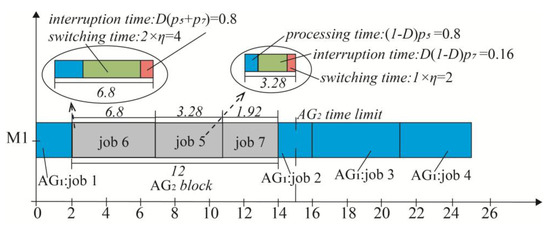
Figure 1.
Solution to an illustrative example of Table 1 with parameters , , , , and .
3.2. Mathematical Model of the Problem
The problem requires considering the allocation of all jobs on identical parallel machines. Therefore, a mixed-integer programming model (MIP) is provided.
- Variables of MIP along with their brief descriptions
| Binary variable, if is arranged at th position of block on machine , ; otherwise, . | |
| Binary variable, if is arranged at th position of block on machine , ; otherwise, . | |
| Binary variable, if the block is inserted after th position of on machine , ; otherwise, . | |
| Non-negative variable, the duration of th position of block which is allocated to machine . | |
| Non-negative variable, the makespan of th position job from on machine . | |
| Non-negative variable, the duration of the block which is allocated to machine . | |
| Non-negative variable, the makespan of job . |
Since the position-dependent processing time of jobs from AG2 is determined by Formula (1), we refer to reference [15] to rewrite the formula by binary variable as
where is the actual processing time of job ; and are its interruption time and switching time, respectively. The rewritten expression is adopted to constraint (15).
Subject to
The objective function (7) aims to minimize the total weighted completion time of jobs from . Constraints (8) and (9) ensure a unique allocation of jobs from and . Constraints (10) and (11) guarantee that each position of and can only be occupied by at most one job, thus allowing for some positions to be idle. Constraints (12) and (13) prevent interruptions in the occupation of consecutive positions in and . Constraint (14) ensures that each block can only be inserted after one position of on the same machine, with representing the insertion position of the block for on machine . Constraint (15) provides the duration of each position associated with multitasking scheduling in the block on each machine. Then the duration of the first position is set to 0 in constraint (18). Constraints (16) and (17) model a lower bound for the job allocated to the th position from , using a big- method to invalidate one of the two constraints. Subsequently, the duration of the first position is set to 0 in constraint (19). Constraint (20) defines the total duration of the block time on machine . Constraint (21) is a hard time limit constraint on each machine. If , the makespan of the block is , and the makespan must be less than the time limit . Otherwise, the constraint is invalid. Constraint (22) establishes the relationship between the completion time of a job from and its occupied position. If , constraint (22) is valid; otherwise, corresponds to the position-dependent completion time . For the big- in constraints (16) and (17) and constraints (21) and (22), it can be set as . This is because the constraint pairs are mutually exclusive constraints, and big-, as a sufficiently large value, only needs to ensure that when one constraint is active, the other does not affect the solution.
To facilitate better understanding, e.g., the concepts of the “ block”, the “duration of block”, and the “inserted position of block”, a simple example is provided in Table 2 and Figure 2.
Table 2.
A simple example input data.
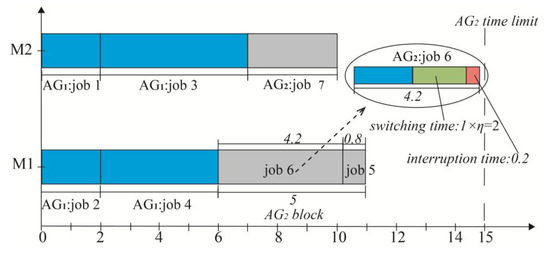
Figure 2.
Solution to an illustrative example of Table 2 with parameters , , , , and .
The optimal weighted completion time depicted in Figure 2 is , with . Specifically, Figure 2 shows that jobs and are allocated to , which demonstrates , and , . The block consists of jobs , and the insertion position is . In the block, the duration of the first and second positions are
Thus, the duration of the block is . Due to the insert position only at , the corresponding position makespan in is
and the time limit constraint is . Therefore, the makespan of jobs 2 and 4 from are
3.3. Structural Property of the Problem
Some similar structure optimal properties are proposed based on the research of Azizoglu and Kirca [44], which is originally mentioned by Elmaghraby and Park [45].
Property 3.
If the last job belongs to , in any optimal schedule the total processing time on any machine is less than
Proof .
Let represent the last job performed on machine in an optimal schedule, and let denote its makespan. For any other machine , it must satisfy
If the inequality did not hold, the total weighted completion time would be decreased by taking from machine and putting it last on machine . Thus, by summing the other inequalities associated with each , it can be concluded that
For each or , let and be the total processing time of the block on machines and . Given the relationship , it can be concluded that . Due to the multitasking scheduling formula, must satisfy
where indicates that all jobs from are only allocated to one machine, and denotes that jobs are equally allocated to machines. Utilizing the right side, the upper bound of job is as follows:
The is the upper bound for a schedule on parallel machines, and the upper bound efficiently cuts useless branches of the two-phase label-setting algorithm. □
4. Branch-and-Price Algorithm
The branch-and-price (B&P) algorithm [46] utilizes the subset-row inequality [47] technique and the label-setting algorithm [48]. This approach is effective for solving routes planning [49] and scheduling problems [50]. This section introduces each part of B&P. Section 4.1 depicts the restricted master problem (RMP). Section 4.2 describes the pricing problem considering the subset-row inequality. A developed label-setting algorithm is introduced in Section 4.3, named the two-phase label-setting algorithm (TP-LS). The rest of the sections detail other procedures of the B&P algorithm.
4.1. Restricted Master Problem
The master problem is to find several partition schedules containing all jobs while minimizing the total weighted completion time of . For each partition schedule, the completion time of jobs must satisfy . Let denote the set of all feasible partition schedules and be one of partition schedules. Binary decision variable indicates whether schedule is selected or not. is a binary indicator indicating whether job is selected or not in schedule . is the corresponding weighted completion time. Thus, the formulations of the master problem are shown as follows:
Subject to
The objective (34) is to minimize the total cost of selected partition schedules. Constraint (35) guarantees that each job must be selected on parallel machines. Constraint (36) ensures that each machine must select a feasible schedule. Constraint (37) is the subset-row inequality [47]. Usually, is a job set , and is a subset of . It provides a class of cuts to reduce the pricing searches on relaxed solution nodes of the RMP. Constraint (38) is the definition of decision variables.
When the binary variables are relaxed as , the master problem is relaxed as RMP. In B&P, a series of dual variables and relaxed linear solutions are obtained from the RMP. Let be a vector associated with the objective coefficients and let be a binary indicator matrix according to constraint (35). Vector and matrix will be mentioned frequently in Section 4.
4.2. Pricing Problem
The basic idea of B&P is to start with a small subset of high-quality feasible solutions to form up the RMP. The RMP is solved to obtain its dual solution. The pricing problem then aims to find columns with negative reduced costs, which are subsequently added to the RMP. Let be the dual variables corresponding to constraint (35) and let be related to constraint (36). Consequently, is the dual variable of constraint (37). The reduced cost of schedule is defined by
where is the total weighted completion time of jobs belonging to . and are sequences indicating job processing orders for and , respectively. is a binary variable. If at least two jobs of are in , then ; if at most one job of is in , then . Because is a constant, the objective function (39) of the pricing problem becomes .
4.3. Two-Phase Label-Setting Algorithm
The two-phase label-setting (TP-LS) algorithm is proposed in this section. The first phase only involves the jobs, and the labels can be treated as root nodes. The second phase only associates with jobs, and the labels are regarded as leaf nodes. The second phase starts with a transferred label of the first phase, performs a search, and outputs the best-found result. In short, during the searching process of every root node, all leaf nodes must be considered.
- Symbols of the first phase label-setting algorithm
| The label associates with node , and it ends with job, where . | |
| The partitioning schedule of label , which only includes the set of jobs belonging to and ends with job . | |
| The set of jobs that are available and can be extended at job . | |
| The reduced cost of label . | |
| The recursive algorithm of the first phase label-setting algorithm, where the inputs are . |
- Symbols of the second phase label-setting algorithm
| The label associates with node , and ends with job , where . | |
| The partitioning schedule of label , which only includes the set of jobs belonging to and ends with job . | |
| The set of jobs that are available and can be extended at job . | |
| The reduced cost of label . | |
| The overall schedule includes the transferred and , and it is obtained by PolALG. | |
| The duration of the block. | |
| The completion time of the job , where . | |
| The total weighted completion time of jobs at label . | |
| The recursive algorithm of the second phase of the label-setting algorithm, where the inputs are , and is set to before starts. |
4.3.1. First Phase Label-Setting Algorithm
In the first phase label-setting (FPLS) algorithm, a label represents a feasible partition schedule of jobs. Suppose that the set contains all labels associated with . Let job be a node indicating a path ended at job , and be a label associated with node . Let be a consecutive successor label of . From to , the extension equations are formulated as follows:
where denotes that is inserted at the end of sequence , and represents that is removed from the sequence . Moreover, indicates that is obtained by the second phase label-setting algorithm. is the minimum reduced cost, obtained by exploring all leaf nodes of SPLS. In Equation (42), the inputs of SPLS, such as , are of dummy label , which will be detailed in Algorithm 2.
Lemma 1.
The label dominates if , where .
Proof .
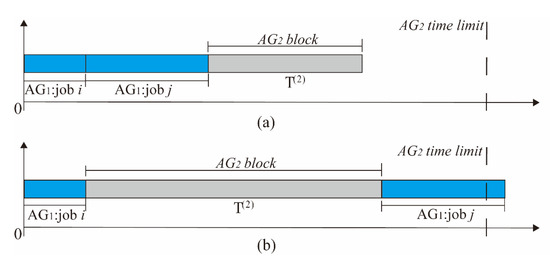
Suppose that the starting time of the last job in is . If , we need to discuss two cases of the labels. ① In case 1, of the block from SPLS is not a long duration so that the time limit is sufficient for allocating block after job . We have (as shown in Figure 3a). ② In case 2, of the block from SPLS is a long duration, and the time limit is tight. In this scenario, the block of is scheduled between jobs and , and we have (as shown in Figure 3b). For both and , it indicates that the reduced cost increment ( or ) of job =has a negative impact on searching for minimum reduced cost. As a result, it is evident that label dominates . □
Figure 3.
Typical examples of a successor label for Lemma 1: (a) an illustrative Gannt chart of case 1; (b) an illustrative Gannt chart of case 2.
| Algorithm 2 First phase label-setting algorithm FPLS |
| Input |
| Output |
| 1: while do |
| 2: , |
| 3: Initialize consecutive label |
| 4: Initialize dummy label |
| 5: /* Initialize data structure of SPLS */ |
| 6: |
| 7: if then |
| 8: |
| 9: end if |
| 10: if then / *Lemma 1 */ |
| 11: / * Start next recursion */ |
| 12: end if |
| 13: end while |
Algorithm 2 FPLS is the primary algorithm of TP-LS. The FPLS starts from a dummy label , where , and contains jobs according to the SWPT order. FPLS is a recursive function that calls itself repeatedly. The data structures for storing the best-found solutions need to be initialized before FPLS starts; that is,. Similarly, lines 4–5 in FPLS initialize the dummy label and the data structure of SPLS. The best-found solutions from FPLS are obtained in line 6, and lines 7–9 are used to store them.
4.3.2. Second Phase Label-Setting Algorithm
In the second phase label-setting (SPLS) algorithm (Algorithm 3), let be the set of labels based on a transferred label of , which contains all labels associated with . Let be a node indicating a path ended at job , and be a label associated with node . Let be a consecutive successor label of . From to , the extension equations are formulated as follows:
where Formula (45) indicates that Algorithm 1 is adopted to obtain the schedule associated with and , the duration of , the makespan, and the total weighted completion time. In short, each available leaf node of SPLS needs to adopt PolALG to quickly obtain the corresponding results. of Equation (46) is a binary indicator indicating whether there are at least two jobs of in . After generating the overall schedule , we provide a binary vector by inspecting both and . Therefore, the length of the vector is the same as that of , and every comes from .
Lemma 2.
If the last job of the overall schedule belongs to , is dominated if is more than
Lemma 2 is the dominance rule corresponding to structural Property 3 (see Section 3.3).
Lemma 3.
The label dominates if and , where .
Because of the strict due-date constraint , it implies that the duration of any search label cannot exceed . It is obvious that any duration () of cannot be larger than the due date , which leads to Lemma 3. In addition, Lemma 4 is provided to omit useless leaf nodes for the searching of SPLS.
Lemma 4.
The label dominates if , where .
Proof .
If , the allocation of job cannot decrease the reduced cost, and dominates . Here, two cases of SPLS need to be discussed. ➀ In case 1, of the block at label is not a long duration, so the time limit is sufficient (see Figure 4a). However, after allocating job to the block, we have . ➁ In case 2, is a long duration, so the time limit is tight (see Figure 4b). After allocating job to the block, we have . In both cases, it satisfies . □

Figure 4.
Typical examples of a successor label for Lemma 4: (a) an illustrative Gannt chart of case 1; (b) an illustrative Gannt chart of case 2.
| Algorithm 3 Second phase label-setting algorithm SPLS |
| Input: |
| Output: |
| 1: while do |
| 2: , |
| 3: Initialize consecutive label |
| 4: |
| 5: Obtain reduced cost: |
| 6: if then |
| 7: , |
| 8: end if |
| 9: if then |
| 10: , |
| 11: end if |
| 12: if then / *Lemma 3 */ |
| 13: if then / *Lemma 4 */ |
| 14: |
| 15: if is in and then / *Lemma 2 */ |
| 16: / * Start next recursion */ |
| 17: end if |
| 18: end if |
| 19: end if |
| 20: end while |
| a Remove the last item from the sequence. b Insert at the head of . c Obtain the last item from the sequence. |
In Algorithm 2, SPLS starts at dummy label and transferred label of FPLS and supplies the minimum reduced cost for FPLS after searching all leaf nodes. Line 4 in SPLS obtains the optimal overall schedule by Algorithm 1. Lines 12–19 apply the proposed Lemmas 2–4 to prune useless leaf nodes, thereby speeding up the algorithm.
In general, the pricing problem may have multiple optimal solutions. Adding multiple columns to the RMP at each iteration can improve performance by reducing computational time [51]. Here, let be the best-found reduced cost of TP-LS, then and are queues containing a series of high-quality solutions for the pricing problem. is the queue size, and it is set to 10. For a better understanding, Table 3 and Table 4 provide a simple example to illustrate the procedure of the TP-LS algorithm.
Table 3.
A simple example of the pricing problem corresponds to the input data of Table 2.
Table 4.
The detailed results of the pricing problem of Table 2.
Table 3 shows the dual variable values from one iteration of the B&P algorithm. In Table 3, is the time upper bound of job according to Lemma 2. For example, the time upper bound of job in Figure 5c can be obtained by
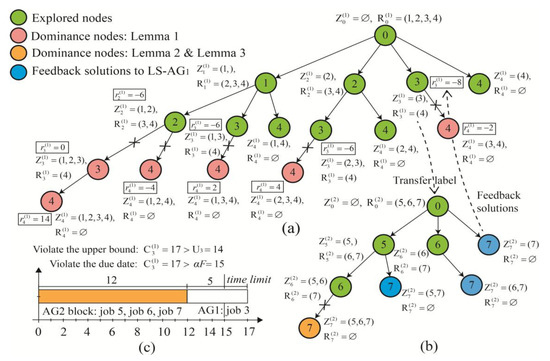
Figure 5.
The recursive paths of the pricing problem in Table 2: (a) the recursive paths of FPLS; (b) the recursive paths of SPLS; (c) the violation node of Lemma 2 in SPLS recursive paths.
Indeed, before starting a round of iteration, the time upper bounds of jobs are obtained by Lemma 2. In Figure 5, both FPLS and SPLS are based on depth first search order. On the left-most branch in Figure 5a, both and are larger than ; this implies that label dominates and , which demonstrates the effectiveness of Lemma 1. Figure 5b depicts the recursive paths when the transferred label is , and Table 4 lists results of all nodes in Figure 5b. , , and represent the makespan, the completion time of , and the duration of . The schedules with the same minimum reduced cost can be found in Table 4, such as , , and . For explaining Lemma 2 and Lemma 3, Figure 5c depicts the violation of node 7 in Figure 5b. The jobs are 5, 6, and 7, and the block time is . Thus, the completion time of job 3 is , which violates the upper bound of Lemma 2 and the due date of Lemma 3. As mentioned in Section 4.2, is a constant and is not considered during the searching process. Finally, the final results of the pricing problem are and .
4.4. Primary Heuristic
Because the common time limit () in this paper is regarded as a hard constraint, obtaining a series of initial solutions without violating deadlines is a laborious work. By utilizing Algorithm 1, this procedure aims to obtain a series of feasible solutions with good qualities. Let and . Then, and are randomly shuffled. For the first machines, extract and jobs from and , respectively. For the th machine, extract all remaining jobs from and , respectively. Note that the extracted job sequences for each machine are . Call Algorithm 1 to obtain the schedule and the weighted completion time . If the result violates the time limit (), reshuffle and and perform the above procedures again; otherwise, transform to a binary vector and add it to the coefficient matrix .
4.5. Branching Rule
To guarantee integrality of solutions, we execute branching on the relaxed variables . The branching rule does not change the structure of the pricing problem. Given a series of RMP solutions (), the solution set may have fractional values. Let be the index of fractional values of and be the index of integer values of , . Hence, two branching rules are adopted in hierarchy.
Branching on jobs. We branch on the value of close to 0.5. Two child nodes of , which are set to 0 and 1 (the integer child node of is denoted as ), are generated by forbidding or selecting the partitioning schedule separately. By forcing all to satisfy that , a series of integer is obtained.
Branching on the number of machines. The obtained must obey that . Otherwise, the branching on jobs is repeated to guarantee that must satisfy .
The two branching rules are adopted in hierarchy until a ground of do not violate the constraints. Specifically, the branching on jobs guarantees its integer child nodes to satisfy constraint (35) of the RMP, and branching on the number of machines pledges the integer child nodes to satisfy constraint (36). The integer solutions (the selections: , the cost: ) are stored.
4.6. The Structure of the Branch-and-Price Algorithm
The basic idea of B&P is to start with a subset of high-quality feasible solutions to form the RMP. van den Akker et al. [52] emphasized that running the primary heuristic between 2000 and 5000 times and storing the 10 best-found solutions achieves better efficiency. The B&P algorithm can be summarized as follows: the pricing problem aims to find a new set of columns with the minimum negative reduced cost, which is then added in the RMP.
| Step 1 | Perform the primary heuristic (see Section 4.4) 5000 times, then store the 10 best solutions found. Initial coefficient matrix , and of the RMP; go to Step 2. |
| Step 2 | Solve the RMP and obtain the dual values (, and ). Initialize the dummy label of Algorithm 2, where , , and , and perform Algorithm 2. Simultaneously, input from Algorithm 1 to Algorithm 2, then perform Algorithm 2 (see Section 4.3). Obtain a set of pricing solutions ,, and ; go to Step 3. |
| Step 3 | If the reduced cost , transform as a set of binary vectors, then add and the binary vectors into the coefficient matrix ( and ) of the RMP and go to Step 2; otherwise, terminate B&P iteration. Go to Step 4. |
| Step 4 | If has fractional values, perform the branching rule (see Section 4.5), which obtains a series of integer solutions of and the corresponding objective value; otherwise, record solutions of and the corresponding objective value. Output all solutions. |
Figure 6 provides a comprehensive depiction of the operational workflow of the B&P approach, while explicitly elucidating the intricate relationships among its constituent steps. For the reduced cost, B&P can suffer from poor convergence due to the so-called tailing off phenomenon, where the objective values tend to be very close (but not equal) to the final LP value for numerous iterations [53]. Here, we do not compare the reduced cost against zero but check whether it is greater than a small number (e.g., ).
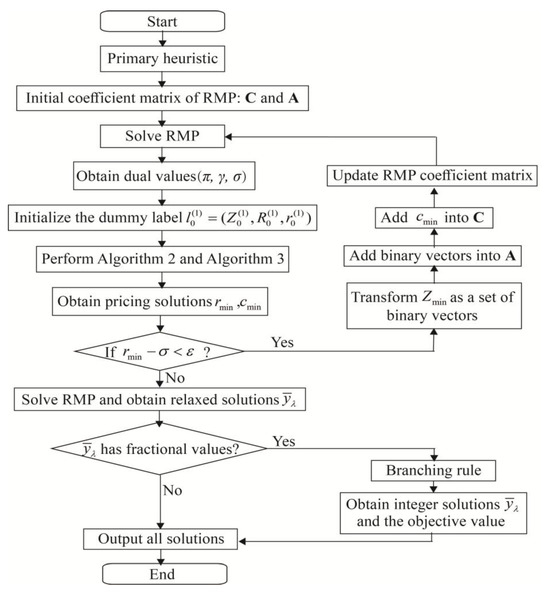
Figure 6.
Flowchart of the branch-and-price approach structure.
5. Computational Experiments
The B&P algorithm was coded by C++ and compiled with MinGW. The MIP and the proposed original RMP were solved by IBM ILOG CPLEX 12.9 solver. All computational experiments were solved by a PC with a 2.80 GHz Intel Pentium Core (TM) i7-7700HQ CPU and 8 GB of RAM. In order to explore the performance of B&P, the large-sized instance problems were solved under a time limit of 7200 s (2.0 h).
5.1. Description of Datasets
To evaluate the effectiveness and optimality of B&P, two sets of instance problems were adopted. The first dataset was generated from the literature [13]. The proposed MIP (see Section 3.2) is able to solve and utilizes one of the state-of-the-art solvers (CPLEX 12.9) as the standard comparison. In dataset 1, each group of jobs has and , where represents the percentage of job out of the total number of jobs. and are set to 0.1 and 0.5, respectively.
The second dataset consists of large-sized instance problems related to multitasking. The processing time , weight , and time limit were randomly generated as follows:, , and , respectively. To simulate the short-term and urgent online tasks, each group of jobs is assigned parameters for and , where represents the percentage of jobs out of total jobs. The interruption factor is set to 0.2 and is set to 2. To our best knowledge, there is no exact approach to completely solve these problems associated with multitasking scheduling, even for the MIP model.
5.2. Comparison Results of Problems
Table 5 and Table 6 report the results of instance problems with jobs 10 and 11, respectively. The tables include information about optimality and CPU time for each combination of instances. displays the objective values obtained by MIP and B&P using binary variables. represents the objective values obtained by B&P using relaxed binary variables in the RMP. is calculated by , reflecting the tightness of B&P’s optimality. The objective values are obtained by B&P using relaxed binary variables in the RMP. shows the running CPU time.
Table 5.
B&P compared to MIP with , , and .
Table 6.
B&P compared to MIP with , , and .
As can be seen in columns 5–9 in Table 5, for the problem, the superiority comparisons of the optimality of B&P and MIP are the same. From the gap column of B&P, it can be observed that the average gap is 0.00, and all 10-job instances achieve a gap of 0.00, which fully reflects the excellent tightness of B&P’s optimal solution. For average time consumption, it is . The maximum time difference between B&P and MIP is . Thus, B&P is superior to MIP.
In Table 6, the superiority comparisons of the optimality of B&P and MIP are still the same. Consistently, the average gap of B&P in 11-job instances remains 0.00, with no gap existing in all instances—this further verifies that B&P’s optimal solution maintains high tightness even when the number of jobs increases to 11. The average time consumption ranking is . The maximum time difference between B&P and MIP is . The proposed B&P algorithm demonstrates superior performance in terms of .
The optimality of B&P has been verified by comparing it with MIP in Table 5 and Table 6. Since B&P is one of the exact algorithms, its optimality can be directly demonstrated by the reduced cost (see Section 4.6). Due to the large number of variables in MIP for large-sized problems, long time consumption of CPLEX 12.9 leads to a large memory on the PC device.
5.3. Computational Results of Large-Sized Problems
MIP is utilized as a comparison in Table 7 with a time limit of 1800 s. Table 8 is used to demonstrate the ultimate performance of the B&P algorithm. Table 7 and Table 8 report the results of large-sized instances with and . denotes the total number of columns generated for the RMP. indicates the average number of nodes explored by TP-LS for the pricing problem. To demonstrate the efficiency of the procedures, PRI:, TP-LS: , and B&P: show the time consumption of the primary heuristic, the running time of TP-LS, and the total time consumption of B&P. For the instance problems in Table 8, the time limit is set to 7200 s.
Table 7.
The performance of B&P and MIP with , , and .
Table 8.
The performance of B&P with , , and .
Table 7 shows that the proposed B&P optimally solves 36 problems, while MIP optimally solves 14 problems. The success rates of B&P and MIP are 100% and 38.89%, respectively. The gap data shows that B&P’s average gap for these large-sized instances (15, 20, 25 jobs) is only 0.01, and most instances have a gap of 0.00 This indicates that B&P still maintains high-quality solutions despite handling larger problem scales. In particular, there is a small difference in the upper bound () obtained by B&P and MIP for instances (15, 2, 0.8, 0.5) and (20, 4, 1.0, 0.75). However, both solutions are still regarded as optimal. This discrepancy can be attributed to fractional values of position-dependent processing time for multitasking, resulting in inconsistent objective values. The and of 15 instance problems are consistent. This consistency is achieved through the inclusion of subset-row inequality constraints. During the iterations of the B&P method, the subset-row inequalities force the RMP to obtain integer solutions as much as possible. In terms of average time consumption, it is observed that . The maximum time difference between B&P and MIP is . In summary, the B&P method outperforms the MIP method in terms of optimality and efficiency.
Solving the instance problems with is computationally intensive. Table 8 shows that B&P optimally solves 23 instance problems within 7200 s, while the other 9 problems are hard to solve. B&P still efficiently solves 71.88% of large-sized problems. Even for these more computationally intensive instances (30, 35, 40 jobs), B&P’s average gap is only 0.05, and most of the optimally solved instances have a gap of 0.00—this fully demonstrates that the branching rules in B&P can still effectively maintain a tight upper bound. Notably, the two instances with large gaps (0.52 for (35, 7, 1.0, 0.50) and 0.28 for (40, 7, 0.8, 0.50)) are linked to their massive, explored nodes (over 116 million) and TP-LS times nearing 7200 s. This indicates an overly expansive solution space and complex pricing problems, which prevented the gap from being efficiently narrowed. The time consumption of the nine problems is recorded in bold. A total of 78% of the hard problems are with parameter set . The explored nodes of these problems are over , indicating that even the dominance rules cannot effectively reduce the search region. After all, the average time consumption of the pricing problem is 3410.94 s.
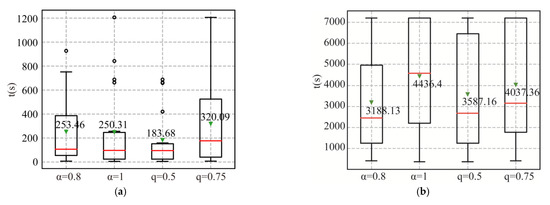
The results depicted in Figure 7 demonstrate that B&P is highly effective in solving large-sized problems with a tighter time limit of or containing fewer jobs. In the boxplots, red lines represent medians, green triangles denote mean values, and black circles indicate outliers. For example, in the first subfigure, when , the mean is 253.46 s and the median is around 100 s; for , the mean is 183.68 s (median ~80 s), indicating lower time consumption. A larger (e.g., , mean 320.09 s) or (mean 250.31 s) leads to increased time in the first subfigure, while in the second subfigure, (mean 4436.4 s) and (mean 4037.36 s) also show higher time than (mean 3188.13 s) and (mean 3587.16 s). This confirms that a larger lead to smaller time consumption of B&P, as a smaller number of machines prevents efficient reduction of reduced cost in the pricing problem, causing repeated fluctuations. In summary, this study can efficiently satisfy the due date and minimize the total weighted completion time of . Computational results demonstrate that the proposed B&P algorithm has excellent performance in both optimality and efficiency.
6. Conclusions
This research addresses the problem of multitasking scheduling for two competitive agents on identical parallel machines, a challenge directly motivated by resource allocation in loud manufacturing (CMfg) platforms. The objective is to minimize the total weighted completion time of the first agent’s () long-term tasks, subject to the constraint that the makespan of the second agent’s () urgent tasks satisfies in a strict time limit. We established key structural properties and developed an exact branch-and-price (B&P) approach, enhanced by a two-phase label-setting algorithm and dominance rules. Computational experiments demonstrated that the B&P approach successfully solved 92.31% of instances and provided a robust solution for optimizing platform operations by efficiently balancing urgent and flexible task commitments.
Despite its effectiveness, the approach’s computational efficiency is challenged by very large-scale instances with tight due-date constraints, highlighting a limitation in scalability. From a managerial perspective, this model offers clear value to CMfg platforms by enabling efficient resource allocation. It guarantees urgent service deadlines without compromising the scheduling of long-term projects, thereby enhancing operational reliability and customer satisfaction.
For future work, promising directions include hybridizing the exact B&P algorithm with metaheuristics to improve scalability and extending the model to unrelated parallel machines to better handle heterogeneous manufacturing resources. Investigating the multi-objective problem that also minimizes the makespan of presents another valuable research avenue.
Author Contributions
Conceptualization: J.G.; methodology: J.G.; writing—original draft preparation: X.X.; writing—review and editing: J.G.; supervision: S.Z.; project administration: X.X. and J.G.; funding acquisition: X.X. and J.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Postdoctoral Fellowship Program of CPSF (Grant No. GZC20230790), the Fundamental Research Funds for the Central Universities (Grant No. 2024MS028), the China Postdoctoral Science Foundation (Grant No. 2024M750894), Funding for Postdoctoral Research Activities in Beijing Municipality (Grant No. ZZ-2024-60), and the Cultivation Project Funds for Beijing University of Civil Engineering and Architecture (Grant No. X24018).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available in the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yuan, C.; Wang, Y. Design and strategy selection for quality incentive mechanisms in the public cloud manufacturing model. Comput. Ind. Eng. 2024, 198, 110681. [Google Scholar] [CrossRef]
- Jiang, Y.; Tang, D.; Zhu, H.; Liu, C.; Chen, K.; Zhang, Z.; Chen, J. A skill vector-based multi-task optimization algorithm for achieving objectives of multiple users in cloud manufacturing. Adv. Eng. Inform. 2025, 65, 103295. [Google Scholar] [CrossRef]
- Wang, D.; Yu, Y.; Yin, Y.; Cheng, T.C.E. Multi-agent scheduling problems under multitasking. Int. J. Prod. Res. 2021, 59, 3633–3663. [Google Scholar] [CrossRef]
- Hall, N.G.; Leung, J.Y.T.; Li, C.-L. The effects of multitasking on operations scheduling. Prod. Oper. Manag. 2015, 24, 1248–1265. [Google Scholar] [CrossRef]
- Xu, S.; Hall, N.G. Fatigue, personnel scheduling and operations: Review and research opportunities. Eur. J. Oper. Res. 2021, 295, 807–822. [Google Scholar] [CrossRef]
- Xue, H.; Bai, D.; Shu, X.; Wang, L.; Chu, F.; Cai, G. A multitasking scheduling problem of emergency medical response in mass casualty incident. IISE Trans. 2025, 1–19. [Google Scholar] [CrossRef]
- Graham, R.; Lawler, E.; Lenstra, J.; Kan, A. Optimization and Approximation in Deterministic Sequencing and Scheduling: A Survey. Ann. Discrete Math. 1979, 5, 287–326. [Google Scholar] [CrossRef]
- Hall, N.G.; Leung, J.Y.T.; Li, C.-L. Multitasking via alternate and shared processing: Algorithms and complexity. Discrete Appl. Math. 2016, 208, 41–58. [Google Scholar] [CrossRef]
- Li, S.-S.; Chen, R.-X.; Tian, J. Multitasking scheduling problems with two competitive agents. Eng. Optim. 2020, 52, 1940–1956. [Google Scholar] [CrossRef]
- Wu, C.-C.; Azzouz, A.; Chen, J.-Y.; Xu, J.; Shen, W.-L.; Lu, L.; Ben Said, L.; Lin, W.-C. A two-agent one-machine multitasking scheduling problem solving by exact and metaheuristics. Complex Intell. Syst. 2022, 8, 199–212. [Google Scholar] [CrossRef]
- Yang, Y.; Yin, G.; Wang, C.; Yin, Y. Due date assignment and two-agent scheduling under multitasking environment. J. Comb. Optim. 2020, 44, 2207–2223. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, J.-Q.; Yin, Y. Due date assignment and multitasking scheduling with deterioration effect and efficiency promotion. Comput. Ind. Eng. 2020, 146, 106569. [Google Scholar] [CrossRef]
- Lee, W.-C.; Wang, J.-Y.; Lin, M.-C. A branch-and-bound algorithm for minimizing the total weighted completion time on parallel identical machines with two competing agents. Knowl. Based Syst. 2016, 105, 68–82. [Google Scholar] [CrossRef]
- Xiong, X.; Zhou, P.; Yin, Y.; Cheng, T.C.E.; Li, D. An exact branch-and-price algorithm for multitasking scheduling on unrelated parallel machines. Nav. Res. Logist. 2019, 66, 502–516. [Google Scholar] [CrossRef]
- Gao, J.; Zhu, X.; Zhang, R. A branch-and-price approach to the multitasking scheduling with batch control on parallel machines. Int. Trans. Oper. Res. 2022, 29, 3464–3485. [Google Scholar] [CrossRef]
- Santos, F.; Fukasawa, R.; Ricardez-Sandoval, L. An integrated machine scheduling and personnel allocation problem for large-scale industrial facilities using a rolling horizon framework. Optim. Eng. 2021, 22, 2603–2626. [Google Scholar] [CrossRef]
- Zhu, Z.; Li, J.; Chu, C. Multitasking scheduling problems with deterioration effect. Math. Probl. Eng. 2017, 2017, 4750791. [Google Scholar] [CrossRef]
- Zhu, Z.; Zheng, F.; Chu, C. Multitasking scheduling problems with a rate-modifying activity. Int. J. Prod. Res. 2017, 55, 296–312. [Google Scholar] [CrossRef]
- Zhu, Z.; Liu, M.; Chu, C.; Li, J. Multitasking scheduling with multiple rate-modifying activities. Int. Trans. Oper. Res. 2019, 26, 1956–1976. [Google Scholar] [CrossRef]
- Ji, M.; Zhang, Y.; Zhang, Y.; Cheng, T.C.E.; Jiang, Y. Single-machine multitasking scheduling with job efficiency promotion. J. Comb. Optim. 2022, 44, 446–479. [Google Scholar] [CrossRef]
- Liu, M.; Wang, S.; Zheng, F.; Chu, C. Algorithms for the joint multitasking scheduling and common due year assignment problem. Int. J. Prod. Res. 2017, 55, 6052–6066. [Google Scholar] [CrossRef]
- Ji, M.; Zhang, W.; Liao, L.; Cheng, T.C.E.; Tan, Y. Multitasking parallel-machine scheduling with machine-dependent slack due-window assignment. Int. J. Prod. Res. 2019, 57, 1667–1684. [Google Scholar] [CrossRef]
- Xu, C.; Xu, Y.; Zheng, F.; Liu, M. Multitasking scheduling problems with a common due-window. RAIRO–Oper. Res. 2021, 55, 1787–1798. [Google Scholar] [CrossRef]
- Xu, X.; Yin, G.; Wang, C. Multitasking scheduling with batch distribution and due data assignment. Comput. Int. Syst. 2021, 7, 191–202. [Google Scholar] [CrossRef]
- Li, J.; Li, X.; Gao, L.; Wang, C.; Chen, H. A multitasking workforce-constrained flexible job shop scheduling problem: An application from a real-world workshop. J. Manuf. Syst. 2025, 83, 196–215. [Google Scholar] [CrossRef]
- Hu, M.; Zhang, W.; Ren, X.; Qin, S.; Chen, H.; Zhang, J. A novel resilient scheduling method based on multi-agent system for flexible job shops. Int. J. Prod. Res. 2025, 1–21. [Google Scholar] [CrossRef]
- Zhang, L.; Yan, Y.; Hu, Y. Dynamic flexible scheduling with transportation constraints by multi-agent reinforcement learning. Eng. Appl. Artif. Intell. 2024, 134, 108699. [Google Scholar] [CrossRef]
- Agnetis, A.; Mirchandani, P.B.; Pacciarelli, D.; Pacifici, A. Scheduling problems with two competing agents. Oper. Res. 2004, 52, 229–242. [Google Scholar] [CrossRef]
- Leung, J.Y.-T.; Pinedo, M.; Wan, G. Competitive two-agent scheduling and its applications. Oper. Res. 2010, 58, 458–469. [Google Scholar] [CrossRef]
- Gerstl, E.; Mosheiov, G. Scheduling problems with two competing agents to minimized weighted earliness-tardiness. Comput. Oper. Res. 2013, 40, 109–116. [Google Scholar] [CrossRef]
- Shabtay, D.; Dover, O.; Kaspi, M. Single-machine two-agent scheduling involving a just-in-time criterion. Int. J. Comput. Prod. Res. 2015, 53, 2590–2604. [Google Scholar] [CrossRef]
- Li, H.; Gajpal, Y.; Bector, C. Single machine scheduling with two-agent for total weighted completion time objectives. Appl. Soft Comput. 2018, 70, 147–156. [Google Scholar] [CrossRef]
- Zhang, X. Two competitive agents to minimize the weighted total late work and the total completion time. Appl. Math. Comput. 2021, 406, 126286. [Google Scholar] [CrossRef]
- Lin, W.-C.; Yin, Y.; Cheng, S.-R.; Cheng, T.; Wu, C.-H.; Wu, C.-C. Particle swarm optimization and opposite-based particle swarm optimization for two-agent multi-facility customer order scheduling with ready times. Appl. Soft Comput. 2017, 52, 877–884. [Google Scholar] [CrossRef]
- Choi, B.C.; Park, M.J. Two-agent parallel machine scheduling with a restricted number of overlapped reserved tasks. Eur. J. Oper. Res. 2017, 260, 514–519. [Google Scholar] [CrossRef]
- Smith, W.E. Various optimizers for single-stage production. Nav. Res. Logist. Q. 1956, 3, 59–66. [Google Scholar] [CrossRef]
- Bruno, J.; Coffman, E.G.; Sethi, R. Scheduling independent tasks to reduce mean finishing time. Commun. ACM 1974, 17, 382–387. [Google Scholar] [CrossRef]
- Chen, Z.-L.; Powell, W.B. Solving Parallel Machine Scheduling Problems by Column Generation. INFORMS J. Comput. 1999, 11, 78–94. [Google Scholar] [CrossRef]
- Kowalczyk, D.; Leus, R. A branch-and-price algorithm for parallel machine scheduling using ZDDs and generic branching. INFORMS J. Comput. 2018, 30, 768–782. [Google Scholar] [CrossRef]
- Kramer, A.; Dell’Amico, M.; Iori, M. Enhanced arc-flow formulations to minimize weighted completion time on identical parallel machines. Eur. J. Oper. Res. 2019, 275, 67–79. [Google Scholar] [CrossRef]
- Wang, C.; Guo, C.; Zuo, X. Solving multi-depot electric vehicle scheduling problem by column generation and genetic algorithm. Appl. Soft Comput. 2021, 112, 107774. [Google Scholar] [CrossRef]
- Gunawan, A.; Widjaja, A.T.; Vansteenwegen, P.; Yu, V.F. A matheuristic algorithm for the vehicle routing problem with cross-docking. Appl. Soft Comput. 2021, 103, 107163. [Google Scholar] [CrossRef]
- Gao, J.; Zhu, X.; Zhang, R. Scheduling for trial production with a parallel machine and multitasking scheduling model. Appl. Intell. 2023, 53, 26907–26926. [Google Scholar] [CrossRef]
- Azizoglu, M.; Kirca, O. On the minimization of total weighted Flow time with identical and uniform parallel machines. Eur. J. Oper. Res. 1999, 32, 91–100. [Google Scholar] [CrossRef]
- Elmaghraby, S.E.; Park, S.H. Scheduling jobs on a number of identical machines. AIIE Trans. 1974, 6, 1–13. [Google Scholar] [CrossRef]
- Muts, P.; Bruche, S.; Nowak, I.; Wu, O.; Hendrix, E.M.T.; Tsatsaronis, G. A column generation algorithm for solving energy system planning problems. Optim. Eng. 2023, 24, 317–351. [Google Scholar] [CrossRef]
- Jepsen, M.; Petersen, B.; Spoorendonk, S.; Pisinger, D. Subset-row inequalities applied to the vehicle-routing problem with time windows. Oper. Res. 2008, 56, 497–511. [Google Scholar] [CrossRef]
- Sedeño-Noda, A.; González-Martín, C. An efficient label setting/correcting shortest path algorithm. Comput. Optim. Appl. 2012, 51, 437–455. [Google Scholar] [CrossRef]
- Li, C.; Gong, L.; Luo, Z.; Lim, A. A branch-and-price-and-cut algorithm for a pickup and delivery problem in retailing. Omega 2019, 89, 71–91. [Google Scholar] [CrossRef]
- Muter, I. Exact algorithms to minimize makespan on single and parallel batch processing machines. Eur. J. Oper. Res. 2020, 285, 470–483. [Google Scholar] [CrossRef]
- Kramer, H.H.; Uchoa, E.; Fampa, M.; Köhler, V.; Vanderbeck, F. Column generation approaches for the software clustering problem. Comput. Optim. Appl. 2016, 64, 843–864. [Google Scholar] [CrossRef]
- van den Akker, J.M.; Hoogeveen, J.; van de Velde, A.S.L. Parallel Machine Scheduling by Column Generation. Oper. Res. 1999, 47, 862–872. [Google Scholar] [CrossRef]
- Dell’Amico, M.; Iori, M.; Martello, S.; Monaci, M. Heuristic and exact algorithms for the identical parallel machine scheduling problem. INFORMS J. Comput. 2008, 20, 333–344. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).