
Section Recommendation of Online Medical Platform Based on Keyword Expansion with Self-Adaptive-Attention-Prompt-BERT-RCNN Modeling

Abstract
1. Introduction
2. Related Work
2.1. Short Text Categorization Study
2.2. Cued Learning Categorization Study
3. General Framework and Methodology
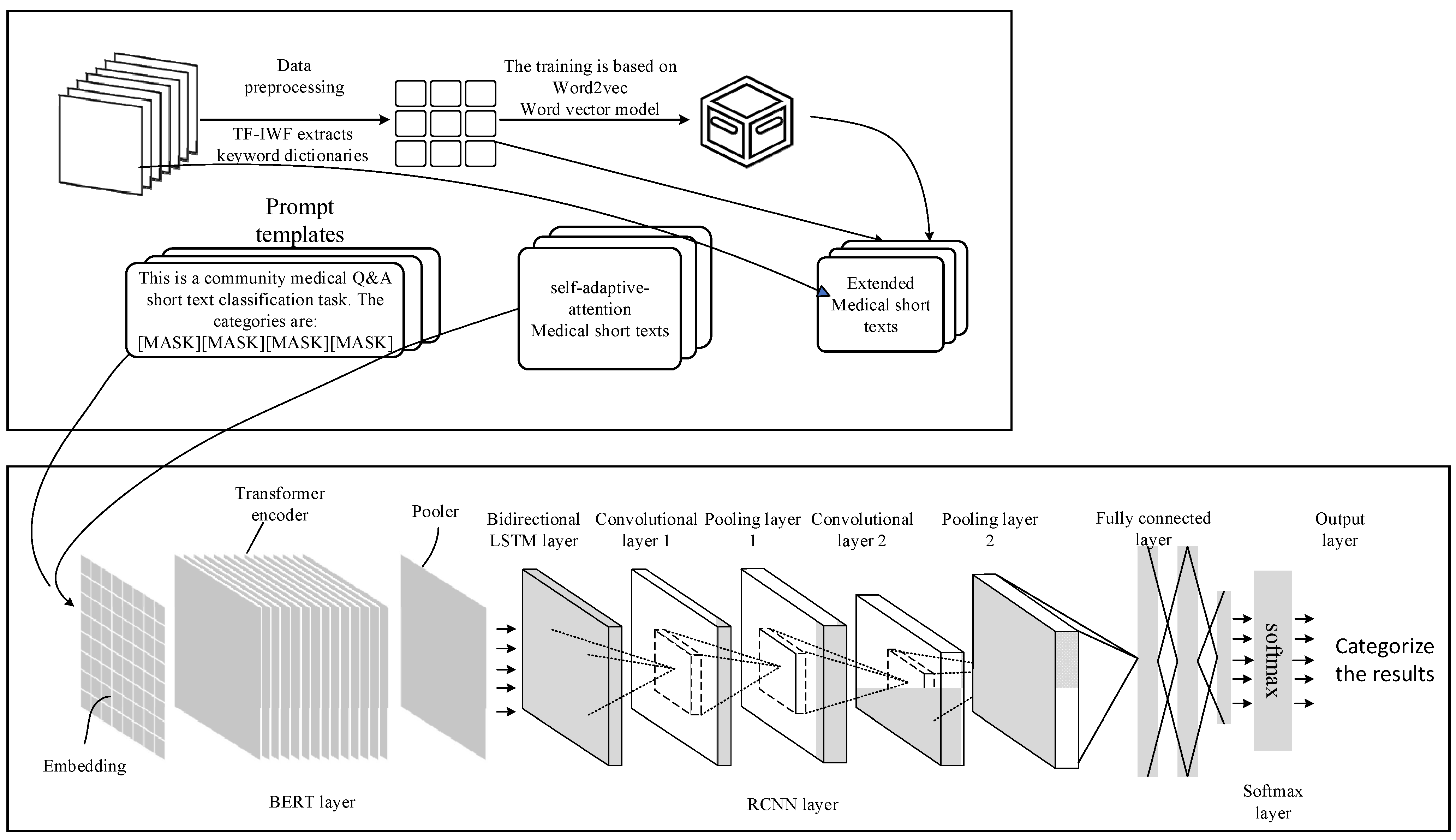
3.1. General Research Framework
3.2. Keyword Expansion Technique
3.2.1. TF-IWF
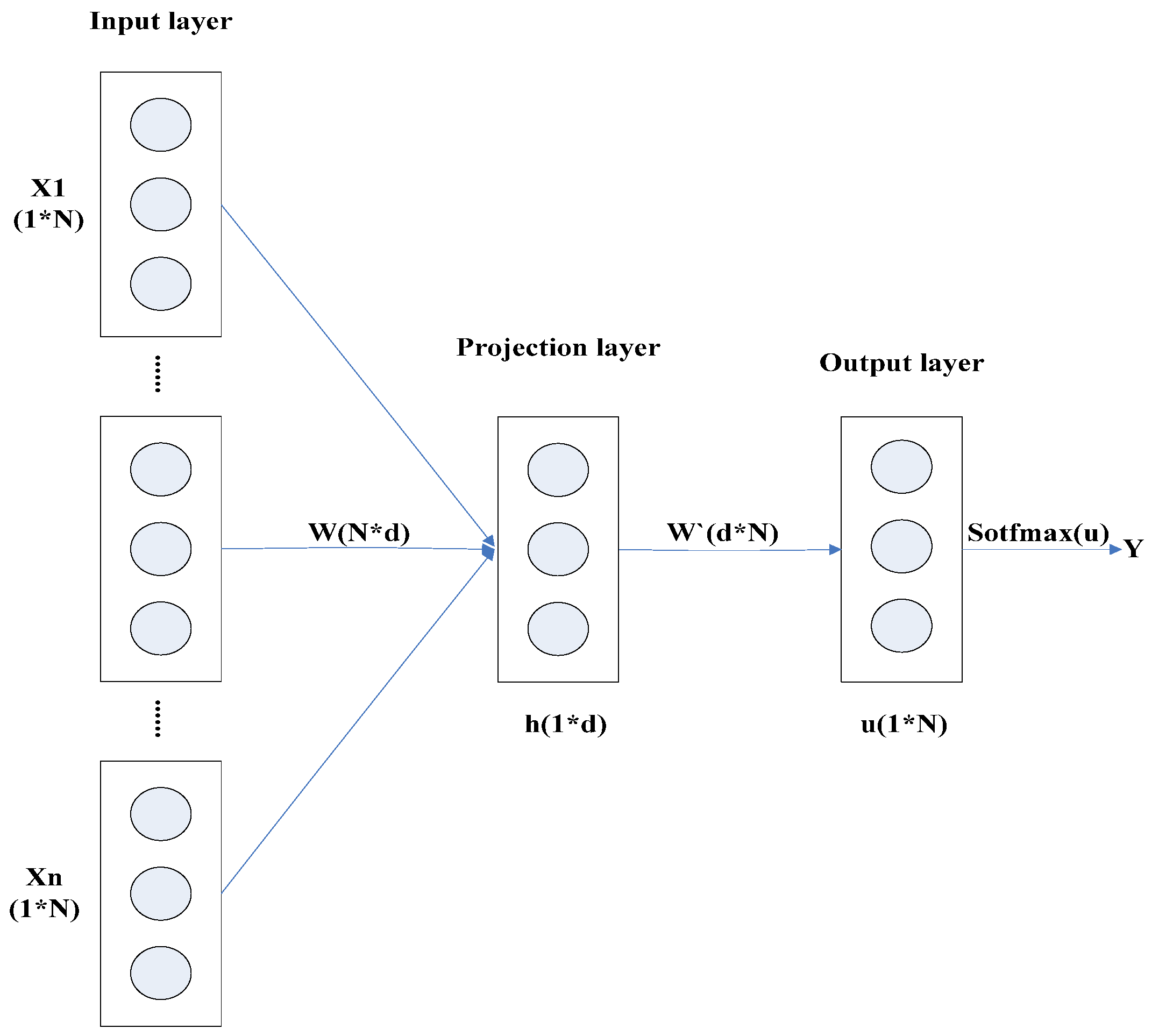
3.2.2. Word2Vec
- 1.
- The input layer takes the one-hot vectors X1 to Xn of the n words surrounding the current predicted word as input, each of which is 1 × N-dimensional.
- 2.
- Initialize the weight matrix W N × d. Multiplying the input layer vectors by W N × d yields n one-dimensional vectors of length d, where d is the predefined word vector dimension. Summing these vectors and taking their average yields the projection layer vector h.
- 3.
- Initialize the weight matrix W′. Multiply the vector h by W′ to obtain the vector u. Apply the Softmax function to calculate the probabilities of each predicted word. Set the position of the word with the highest probability to 1 and all others to 0, resulting in the final output being a one-hot vector for a single word.
- 4.
- Compare the calculated vector with the one-hot vector of the currently predicted word, continuously optimize the weight matrix to maximize the predicted probability of the predicted word, and converge. At this point, the weight matrix W is the desired word vector matrix, where each column represents the word vector of each word. Multiplying it by the one-hot vector of a specific word yields the corresponding word vector.
3.3. The Self-Adaptive-Attention-Prompt-BERT-RCNN Model
3.3.1. Self-Adaptive Attention
- 1.
- Compute the hidden representation of the features by a linear transformation and an activation function (e.g., tanh):where W ϵ Rh × d and b ϵ Rh are the learnable weight matrix and bias terms, and h is the dimension of the hidden layer.
- 2.
- Calculate the attention score for each keyword:where v ϵ Rh is the learnable attention vector and Hi is the hidden representation of the i-th keyword.
- 3.
- Weigh the keyword features based on attention scores:where αi is the attention weight of the i-th keyword and Xi is the feature vector of the i-th keyword.
3.3.2. Prompts to Learn (Prompt)
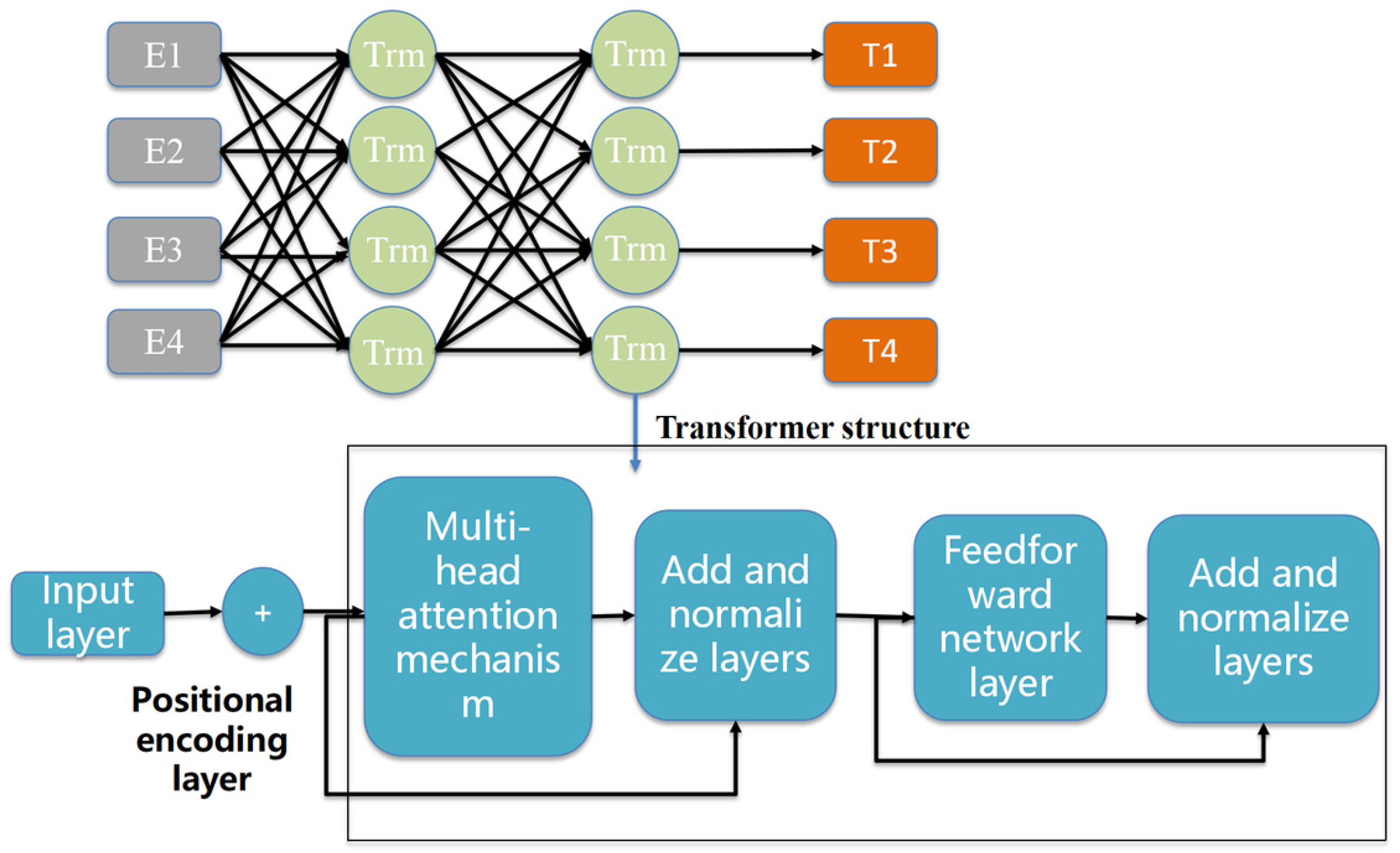
3.3.3. The BERT-RCNN Classification Model
- 1.
- BERT Layer
- 2.
- RCNN layer
4. Empirical Studies
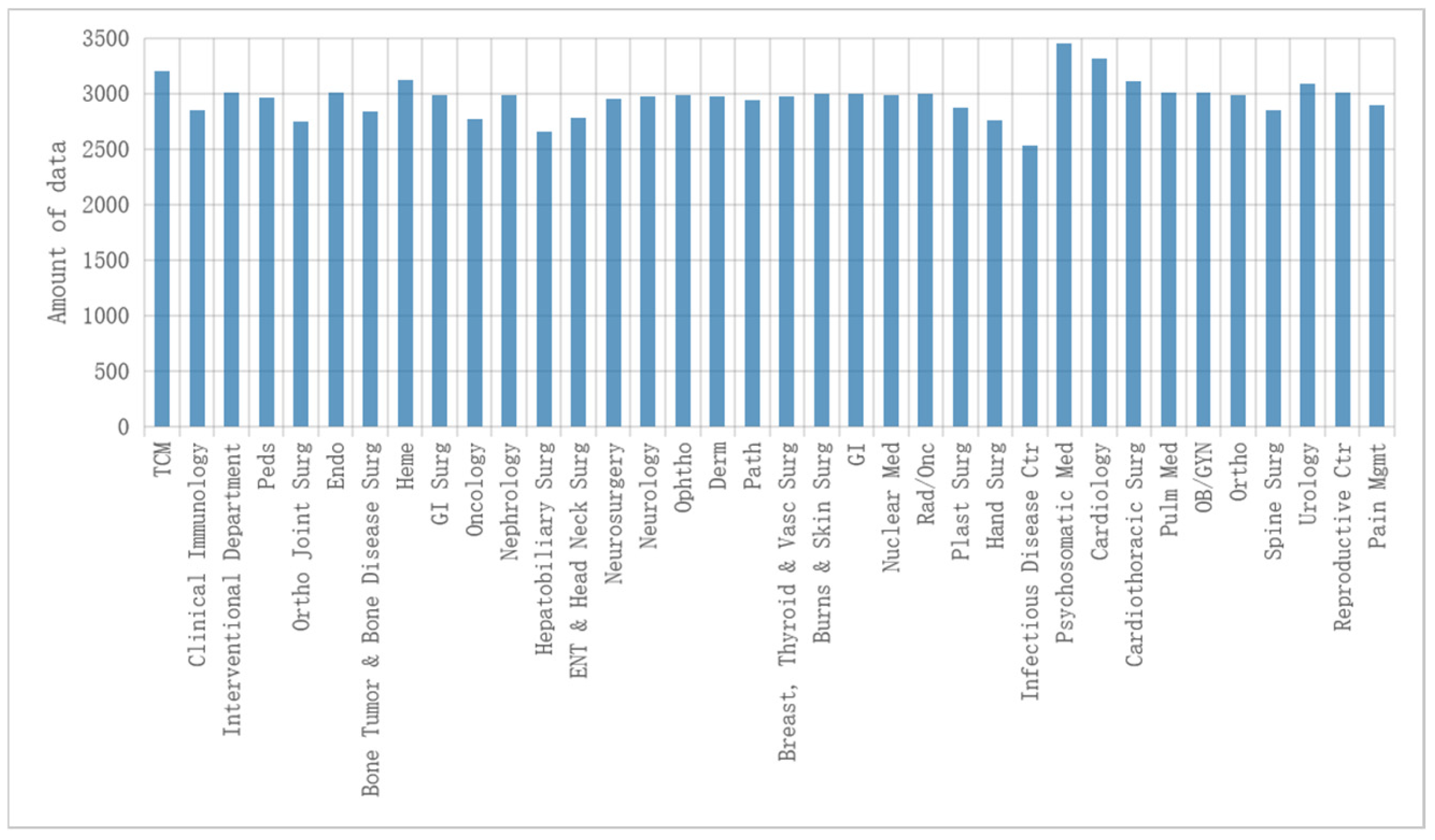
4.1. Experimental Data, Environment, and Categorical Measures
- 1.
- Experimental data
- 2.
- Experimental environment
- 3.
- Disaggregated Measurement Indicators
- (1)
- Accuracy is the number of correct predictions in the sample as a proportion of the total sample, as shown in the following equation:
- (2)
- The precision rate, also known as the rate of checking accuracy, is the proportion of samples predicted to be such samples that are actually such samples, which is defined as shown in the following formula:
- (3)
- The recall rate, also known as the check rate, is the proportion of correctly predicted samples among all samples that are actually of this type, which is defined as shown in the following equation:
- (4)
- The F1 score is the reconciled average of precision and recall, which is commonly used to assess model stability, and it is defined as shown in the following equation:
- (5)
- The ROC curve is obtained using the FPR as the horizontal coordinate and the TPR as the vertical coordinate. The FPR true rate refers to the proportion of such samples that will be predicted correctly and is defined as shown in the equation below:
4.2. Keyword Feature Expansion
- 1.
- Data pre-processing
- 2.
- Keyword extraction
- 3.
- Keyword expansion results
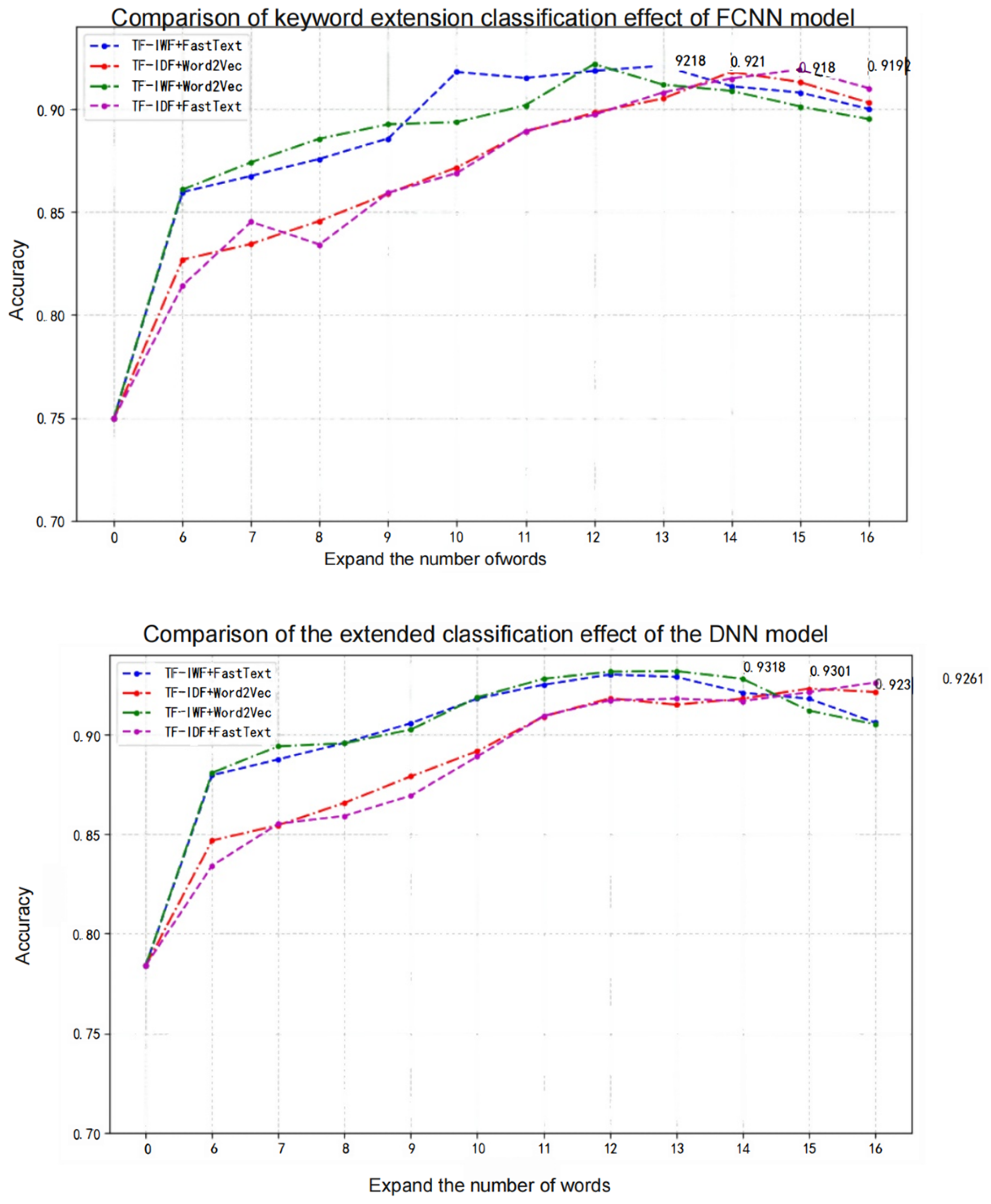
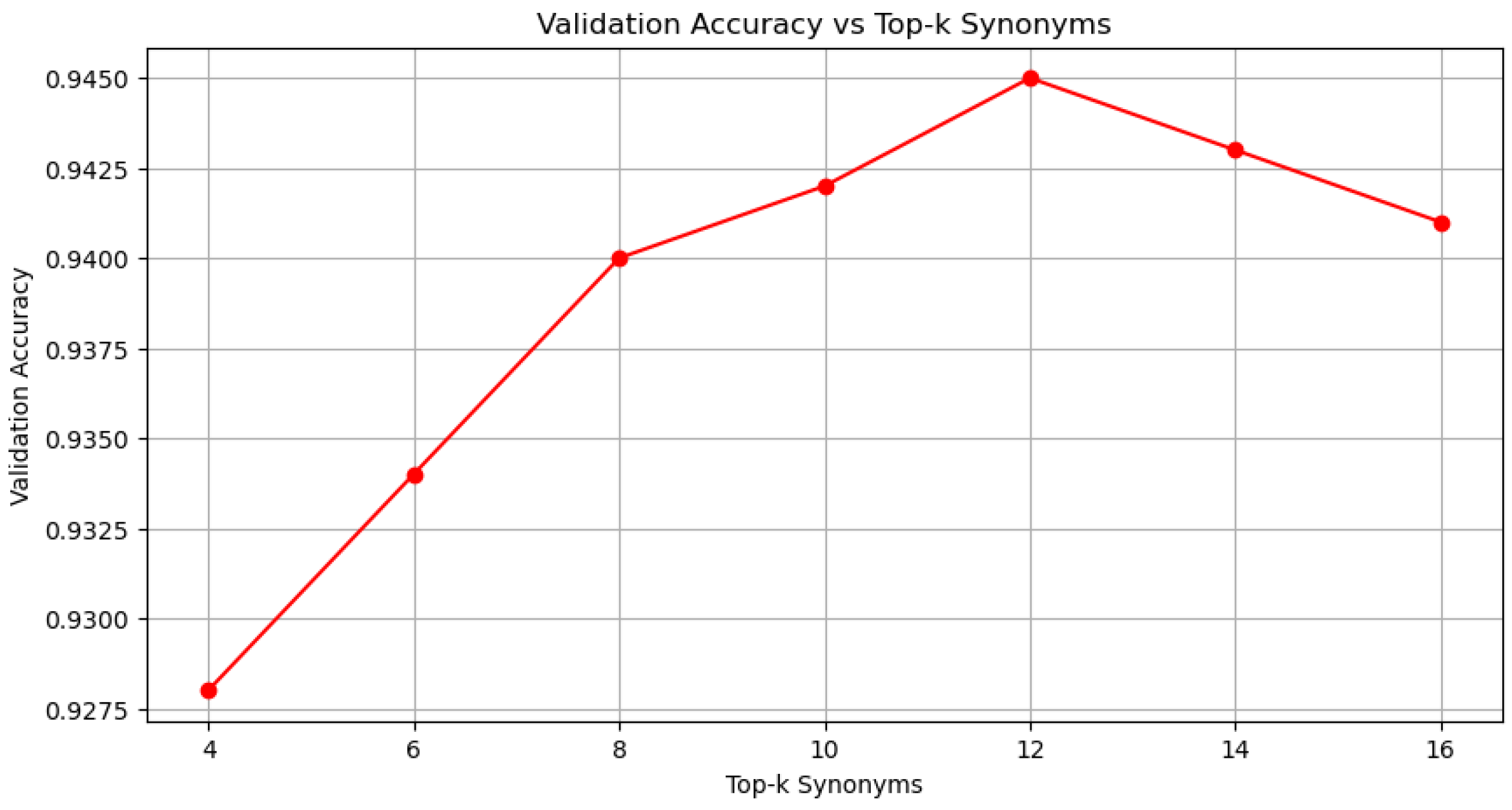
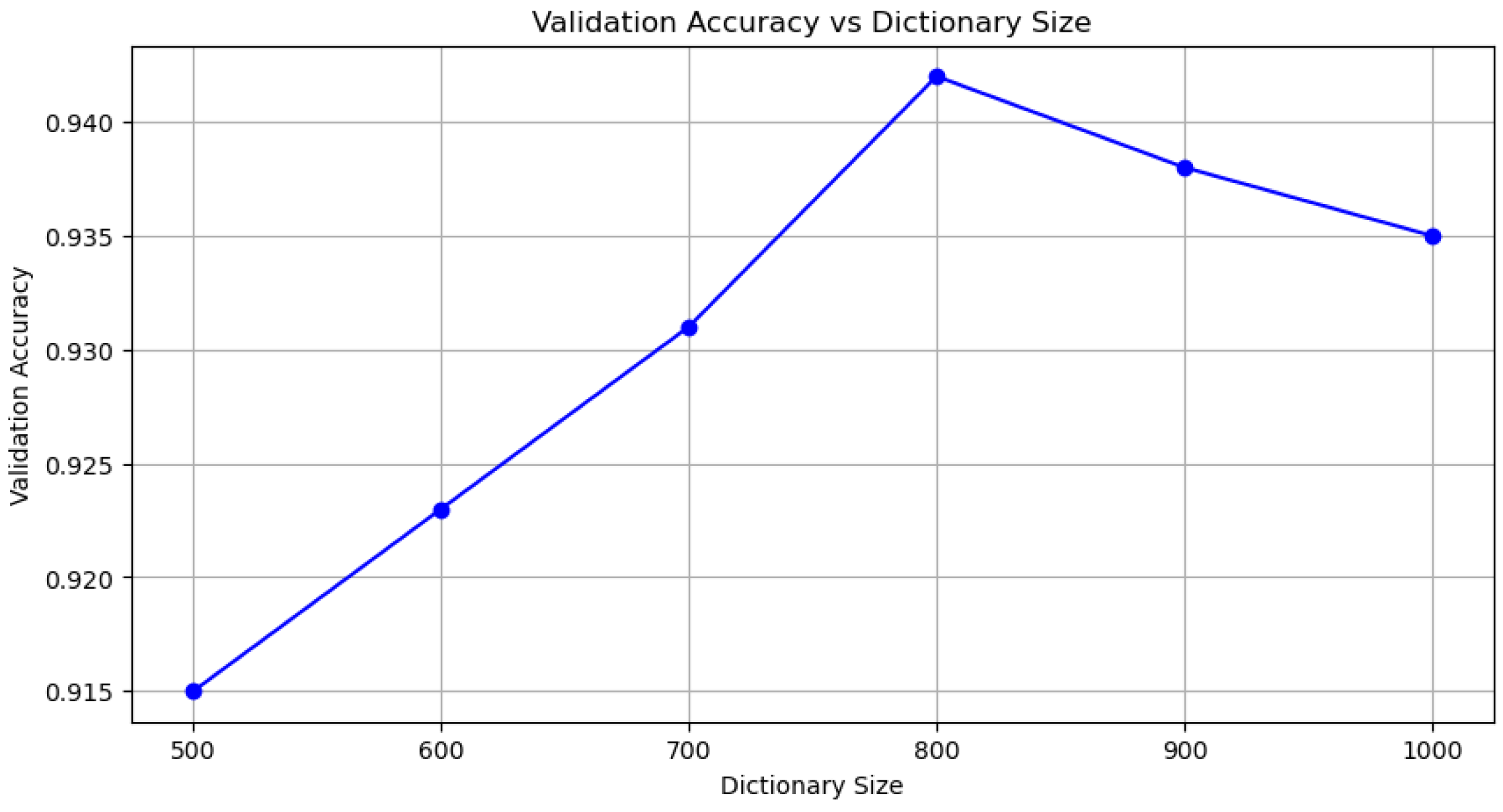
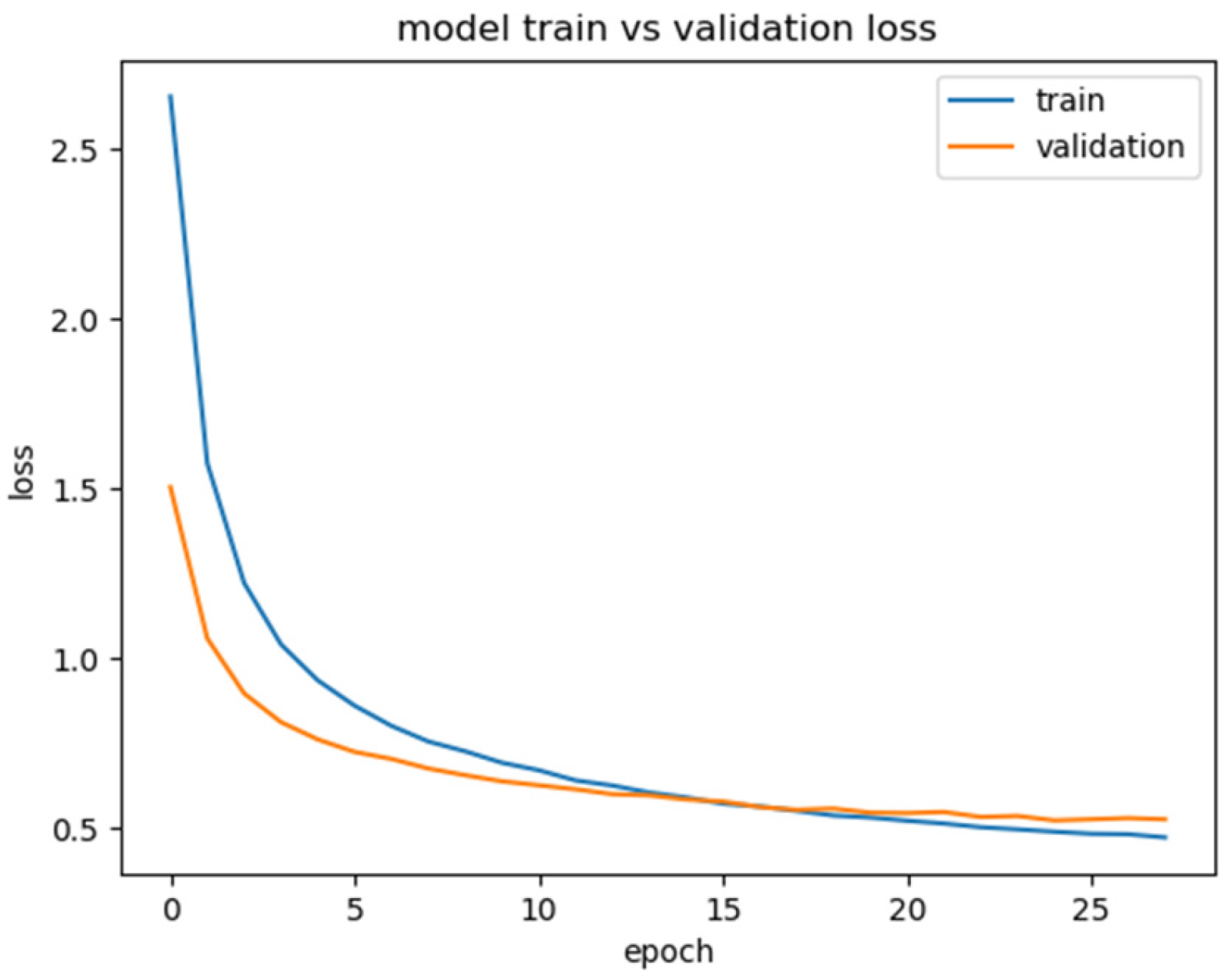
4.3. Prompt-BERT Model Classification Effect
- 1.
- Parameter selection
- 2.
- Comparison of classifier classification effects
4.4. Classification of Short Medical Texts in Different Sections
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Circular on the issuance of the “14th Five-Year Plan” for national health informatization. In Bulletin of the National Health Commission of the People′s Republic of China; NHC: Beijing, China, 2022; pp. 7–18.
- Song, D.; Zhou, X.; Guo, M. Analysis of Essentials in Network Health Information Ecology System. Libr. Inf. 2015, 35, 11–18. [Google Scholar]
- Wang, Y.; Yu, W.; Chen, J. Automatic Q&A in Chinese medical Q&A community by fusing knowledge graph. Data Anal. Knowl. Discov. 2023, 7, 97–109. [Google Scholar]
- Hu, F. Code of Ethics for Educational Virtual Communities for Learning Assistants; Beijing Science Press: Beijing, China, 2024; pp. 31–32. [Google Scholar]
- Zhang, Q.; Wang, H.; Wang, L. A short text categorization method integrating word vector and LDA. Mod. Book Inf. Technol. 2016, 27–35. [Google Scholar]
- Di, W.; Yang, R.; Shen, C. Sentiment word co-occurrence and knowledge pair feature extraction based LDA short text clustering algorithm. Intell. Inf. Syst. 2020, 56, 1–23. [Google Scholar]
- Tang, X.; Gao, H. A study on health question classification based on keyword word vector feature extension. Data Anal. Knowl. Discov. 2020, 4, 66–75. [Google Scholar]
- He, D.P.; He, Z.L.; Liu, C. Recommendation Algorithm Combining Tag Data and Naive Bayes Classification. In Proceedings of the 2020 3rd International Conference on Electron Device and Mechanical Engineering (ICEDME), Suzhou, China, 1–3 May 2020; IEEE: New York, NY, USA, 2020; pp. 662–666. [Google Scholar]
- Zhang, M.; Ai, X.; Hu, Y. Chinese Text Classification System on Regulatory Information Based on SVM. IOP Conf. Ser. Earth Environ. Sci. 2019, 252, 022133. [Google Scholar] [CrossRef]
- Chen, Z.; Zhou, L.; Li, X.; Zhang, J.; Huo, W. The Lao Text Classification Method Based on KNN. Procedia Comput. Sci. 2020, 166, 523–528. [Google Scholar] [CrossRef]
- Liu, W.; Cao, Z.; Wang, J.; Wang, X. Short text classification based on Wikipedia and Word2vec. In Proceedings of the 2016 2nd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 14–17 October 2016; IEEE: New York, NY, USA, 2016; pp. 1195–1200. [Google Scholar]
- Wang, D.; Xiong, S. Short Text Classification Based on Synonym Dictionary Expansion. J. Lanzhou Univ. Technol. 2015, 41, 104–108. [Google Scholar]
- Sun, F.; Chen, H. Feature extension for Chinese short text classification based on LDA and Word2vec. In Proceedings of the 2018 13th IEEE Conference on Industrial Electronics and Applications (ICIEA), Wuhan, China, 31 May–2 June 2018; IEEE: New York, NY, USA, 2018; pp. 1189–1194. [Google Scholar]
- Zhang, M.; Ding, J. Research on Semantic Enhancement for Short Text Classification. Libr. Inf. Work 2023, 67, 4–11. [Google Scholar]
- Cheng, J.; Zhu, Y.; Liu, X. Innovation and Development of Library Service System in the Era of Big Data; China Social Science Press: Beijing, China, 2023; p. 149. [Google Scholar]
- Shao, Y.; Liu, D. Research on short text categorization method based on category feature extension. Data Anal. Knowl. Discov. 2019, 3, 60–67. [Google Scholar]
- Mansoor, H.; Supavadee, A. Transformer’s Role in Brain MRI: A Scoping Review. IEEE Access 2024, 12, 12345–12356. [Google Scholar] [CrossRef]
- Liu, Y.; Li, P.; Hu, X. Combining context-relevant features with multi-stage attention network for short text classification. Comput. Speech Lang. 2022, 71, 101268. [Google Scholar] [CrossRef]
- Shen, Y.; Zhang, Q.; Zhang, J.; Huang, J.; Lu, Y.; Lei, K. Improving medical short text classification with semantic expansion using word-cluster embedding. In Information Science and Applications 2018: ICISA 2018; Springer: Singapore, 2019; pp. 401–411. [Google Scholar]
- Timo, S.; Hinrich, S. Exploiting cloze questions for few shot text classification and natural language inference. arXiv 2021, arXiv:2001.07676. [Google Scholar] [CrossRef]
- Brian, L.; Rami, A.-R.; Noah, C. The power of scale for parameter-efficient prompt tuning. arXiv 2021, arXiv:2104.08691. [Google Scholar] [CrossRef]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J. GPT understands, too. AI Open 2024, 5, 208–215. [Google Scholar] [CrossRef]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Ju, Z. Research on Small Sample Text Categorization Method Based on Cue Learning. Master’s Thesis, Qilu University of Technology, Jinan, China, 2024. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Projected Results | ||
|---|---|---|
| actual result | standard practice | counter-example |
| standard practice | TP (true example) | FN (false negative) |
| counter-example | FP (False Positive) | TN (true counterexample) |
| Dictionary Size | Validation Set Accuracy |
|---|---|
| 500 | 0.915 |
| 600 | 0.923 |
| 700 | 0.931 |
| 800 | 0.942 |
| 900 | 0.938 |
| 1000 | 0.935 |
| Top-k Number of Synonyms | Validation Set Accuracy |
|---|---|
| 4 | 0.928 |
| 6 | 0.934 |
| 8 | 0.940 |
| 10 | 0.942 |
| 12 | 0.945 |
| 14 | 0.943 |
| 16 | 0.941 |
| Top-k Number of Synonyms | Validation Set Accuracy | Standard Deviation |
|---|---|---|
| 8 | 0.940 | 0.003 |
| 12 | 0.945 | 0.002 |
| 16 | 0.941 | 0.004 |
| Model | Accuracy | Weighted Avg F1 |
|---|---|---|
| FCNN | 0.9210 | 0.9208 |
| DNN | 0.9318 | 0.9315 |
| BERT | 0.9620 | 0.9608 |
| BERT-RNN | 0.9632 | 0.9624 |
| BERT-RCNN | 0.9668 | 0.9664 |
| Prompt-BERT-RCNN | 0.9784 | 0.9782 |
| Administrative Division | Precision | Recall | Weighted Avg F1 |
|---|---|---|---|
| TCM | 0.970 | 0.961 | 0.9654 |
| Clinical Immunology | 0.980 | 0.973 | 0.9765 |
| Interventional Department | 0.958 | 0.951 | 0.9543 |
| Peds | 0.976 | 0.969 | 0.9723 |
| Ortho Joint Surg | 0.968 | 0.959 | 0.9634 |
| Endo | 0.970 | 0.961 | 0.9654 |
| Bone Tumor & Bone Disease Surgery | 0.956 | 0.949 | 0.9523 |
| Heme | 0.965 | 0.957 | 0.9610 |
| GI Surg | 0.961 | 0.952 | 0.9565 |
| Oncology | 0.959 | 0.950 | 0.9545 |
| Nephrology | 0.958 | 0.949 | 0.9534 |
| Hepatobiliary Surg | 0.978 | 0.971 | 0.9745 |
| ENT & Head Neck Surg | 0.967 | 0.958 | 0.9623 |
| Neurosurgery | 0.962 | 0.952 | 0.9567 |
| Neurology | 0.964 | 0.954 | 0.9587 |
| Ophtho | 0.975 | 0.968 | 0.9712 |
| Derm | 0.975 | 0.966 | 0.9703 |
| Path | 0.966 | 0.957 | 0.9612 |
| Breast, Thyroid & Vasc Surg | 0.978 | 0.971 | 0.9745 |
| Burns & Skin Surg | 0.968 | 0.959 | 0.9634 |
| GI | 0.969 | 0.960 | 0.9645 |
| Nuclear Med | 0.960 | 0.952 | 0.9556 |
| Rad/Onc | 0.972 | 0.964 | 0.9676 |
| Plast Surg | 0.964 | 0.955 | 0.9590 |
| Hand Surg | 0.971 | 0.962 | 0.9665 |
| Infectious Disease Ctr | 0.962 | 0.952 | 0.9565 |
| Psychosomatic Med | 0.971 | 0.961 | 0.9656 |
| Cardiology | 0.997 | 0.992 | 0.9944 |
| Cardiothoracic Surg | 0.955 | 0.946 | 0.9501 |
| Pulm Med | 0.987 | 0.979 | 0.9828 |
| OB/GYN | 0.989 | 0.981 | 0.9846 |
| Ortho | 0.987 | 0.979 | 0.9828 |
| Spine Surg | 0.966 | 0.956 | 0.9609 |
| Urology | 0.982 | 0.973 | 0.9771 |
| Reproductive Ctr | 0.997 | 0.991 | 0.9936 |
| Pain Mgmt | 0.992 | 0.983 | 0.9872 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, T.; Han, Y.; Duan, G.; Yang, S.; Zhang, S.; Shao, Y. Section Recommendation of Online Medical Platform Based on Keyword Expansion with Self-Adaptive-Attention-Prompt-BERT-RCNN Modeling. Appl. Sci. 2025, 15, 6746. https://doi.org/10.3390/app15126746
Xie T, Han Y, Duan G, Yang S, Zhang S, Shao Y. Section Recommendation of Online Medical Platform Based on Keyword Expansion with Self-Adaptive-Attention-Prompt-BERT-RCNN Modeling. Applied Sciences. 2025; 15(12):6746. https://doi.org/10.3390/app15126746
Chicago/Turabian StyleXie, Tianbao, Yuqi Han, Ganglong Duan, Siyu Yang, Shaoyang Zhang, and Yongcheng Shao. 2025. "Section Recommendation of Online Medical Platform Based on Keyword Expansion with Self-Adaptive-Attention-Prompt-BERT-RCNN Modeling" Applied Sciences 15, no. 12: 6746. https://doi.org/10.3390/app15126746
APA StyleXie, T., Han, Y., Duan, G., Yang, S., Zhang, S., & Shao, Y. (2025). Section Recommendation of Online Medical Platform Based on Keyword Expansion with Self-Adaptive-Attention-Prompt-BERT-RCNN Modeling. Applied Sciences, 15(12), 6746. https://doi.org/10.3390/app15126746