1. Introduction
The “Guiding Opinions on Accelerating the Intelligent Development of Coal Mines” point out that it is necessary to accelerate the supply-side structural reform and high-quality development of the coal industry, which is a milestone for the development of China’s coal industry [
1]. With the ongoing development of intelligent technology in coal mines, the degree of informatization and intelligence of coal mine equipment has also been constantly improved. Intelligent mines are trying to introduce big data analysis and other technologies, with the key equipment of the comprehensive release working face as the research object. It forms the multi-source heterogeneous big data-driven intelligent identification of the fault state of the comprehensive coal mine equipment and the fault prediction technology system through multi-source heterogeneous data collection and the cleaning and distribution storage [
2], the state identification of the equipment of the comprehensive working face [
3,
4,
5], and the quantitative fault diagnosis and state degradation trend prediction of the key equipment [
6,
7]. In addition, it provides technical support for the guarantee of the safe and efficient production of the intelligent comprehensive working face and the reasonable maintenance of the equipment. Nevertheless, these systems are mainly aimed at researchers, and there is a lack of direct methods for general personnel or enterprise employees like the Q&A system. Each system of coal mining equipment is designed independently, and the problems of “information silos” and sub-system fragmentation exist among the sub-systems, which do not make appropriate management and direct use of the large amount of knowledge resources accumulated in the process of the intelligent production of coal mining equipment. Currently, many coal mining companies in China have gradually moved from traditional person-to-person investigation and control to computer technology-based information management in the management of coal mine equipment maintenance knowledge (CEMK). The fact is that there are still numerous coal mine enterprises that manage equipment maintenance and repair by reading a large number of maintenance manuals or consulting an expert. This leads to a restrictive and inefficient query. At present, there is no scientific, effective, and unified knowledge expression and structure composition in the field of knowledge in coal mine equipment maintenance. Structured knowledge is mostly stored in tables or forms, semi-structured knowledge is mostly stored in web pages related to coal mine equipment maintenance, and unstructured knowledge is often retained in the form of text in maintenance manuals, maintenance case bases, and maintenance standards. The correlations between the knowledge are not strong, and it is extremely difficult to obtain a unified form of the expression of knowledge. These problems have seriously hindered the efficiency and progress of the intelligent development and construction of coal mine equipment maintenance. Obviously, the degree of sharing and the reuse of multi-source coal mine equipment knowledge is low, so it is urgent and necessary to build an efficient knowledge management system, dig equipment maintenance knowledge for deep information, and enhance the level of equipment maintenance information.
2. Related Work
Traditional coal mine equipment maintenance is often accomplished with the help of personnel experience, maintenance manuals and expert connectivity, etc. This type of approach has problems such as a small knowledge retrieval range and low efficiency, which in turn prolongs equipment downtime. Expert systems and fault trees [
8] are overly dependent on manual experience, which is fairly difficult to adapt to the digital and informationized knowledge management of coal mine equipment maintenance. It is possible for a knowledge graph (KG) to express semantic information in a structured way by leveraging nodes. Pan et al. [
9] constructed a core coal mine knowledge graph based on ontology technology and developed a security monitoring and surveillance system for coal mines that realized the reasoning and relationship query of mine equipment, personnel, and other information, which provides the basis for the safe production and management of the mine. Li et al. [
10] constructed a knowledge graph of coal mine electro-mechanical equipment based on the data ties for the four-cluster quantum ontology model, which was used to assist the equipment maintenance staff in quickly searching incidents and locating the causes of accidents. Cao et al. [
11] constructed a coal mine equipment maintenance knowledge graph based on ontology and used a graph database to store coal mine equipment maintenance knowledge that provided strong and powerful underpinning for the intelligent management of the coal mine equipment. Ye et al. [
12] realized an effective knowledge archival in the field of coal mines by the knowledge graph they constructed. However, when performing the retrieval of the knowledge graph, it will not be able to be retrieved when multiple entities appear. Knowledge graphs are more standardized compared to the construction of semantic networks and have a concise and intuitive structure. They are flexible and rich in use and have high-quality data, which can carry out the fusion of multi-source data [
13]. It is widely acknowledged that a KG is a key technology for the realization of cognitive intelligence [
14]. As a technology that organizes knowledge in a graphical representation, knowledge graphs have widespread applications in semantic search, intelligent Q&A, recommender systems and other fields. Nevertheless, the inference ability of the knowledge graph is deficient compared to some advanced machine learning models.
With hundreds of millions of references, the large language model (LLM) has the ability of common sense understanding and logical reasoning that traditional AI models do not have [
15]. It is widely used as a powerful tool in various fields. Recent advances in large language models [
16] include OpenAI’s GPT-3.5 [
17], GPT-4 [
18], Google’s PaLM [
19], and Tsinghua University’s ChatGLM [
20], which have demonstrated impressive performances in a variety of natural language processing (NLP) tasks. Despite the fact that the LLMs have achieved excellent performance in general NLP tasks, they possess the knowledge of a particular field in a constrained way. The distribution of languages across different domains and the subtleties of specific knowledge necessitate the fine-tuning or prompt engineering of models tailored for specific domains [
21], otherwise they lack specializations when faced with vertical tasks. Therefore, a wide range of domain-specific LLMs have been proposed to meet the unique needs of specific tasks. For example, FinGPT and XuanYuan 2.0 can accomplish a wide range of financial tasks such as financial news data analysis [
22,
23]. ChatLaw and Lawyer LLama enhances the performance of legal macro-modelling by incorporating a knowledge base [
24,
25]. Tuning models such as Hua Tuo, Chatdoctor, and DoctorGLM have been improved for tasks such as patient multi-round conversations and disease diagnosis [
26,
27,
28]. TrafficSafetyGPT improved the capability of large language models to respond to tasks in the field of traffic safety with reliable government guidebooks and ChatGPT instruction pairs [
29]. Lowin, M proposed applying association rule mining to maintenance requests to identify upcoming needs in facility management by coupling temporal association rule mining with the concept of semantic similarity derived from large language models [
30]. InstructGPT aligns with human feedback through reinforcement learning to generate useful responses [
31]; however, this is a complex and often less stable process. The above models have been known to achieve favorable results in their particular areas, but the field of coal mine equipment maintenance is still in a void, resulting in the problem that the current knowledge resources for coal mine equipment maintenance are abundant but not efficiently utilized.
To summarize, this paper proposes a knowledge management method for coal mine equipment maintenance based on the XCoalChat large model. Aiming at the specific knowledge of coal mine equipment maintenance, a relatively complete coal mine equipment maintenance domain dataset was constructed based on ReliableCEMK-Self-Instruction. The constraint relationship between knowledge groups in the coal mine equipment maintenance knowledge graph was leveraged to enhance the learning and problem-solving capabilities of the model. Based on the triple LoRA fine-tuning mechanism and direct preference optimization, XCoalChat, a large language model for the vertical domains of coal mine equipment conversation, coal mine equipment expertise, and maintenance decision analysis, was trained. This model is capable of generating informative answers based on input coal mine equipment maintenance questions, thus improving the efficiency of coal mine equipment maintenance, which holds significant implications for knowledge management research in the field of coal mine equipment maintenance.
The paper presents the following contributions
Multi-source text coal mine equipment maintenance datasets were constructed based on Reliable-CMEK-Self-Instruction to obtain a wide range of diverse coal mine equipment maintenance knowledge, a specially prepared dataset for the coal mine equipment maintenance vertical.
A knowledge graph enhancement method is presented to reduce the illusion phenomenon of the large language model.
A triple LoRA mechanism fine-tuning architecture and a direct preference optimization (DPO) model are proposed to support the execution of coal mining equipment related tasks for different types of user groups and scenarios.
The rest of this paper is organized as follows.
Section 2 analyzes and reviews the current state-of-the-art of coal mine equipment maintenance knowledge and large language models.
Section 3 presents the specific methodology of XCoalChat, a LLM for coal mine equipment maintenance based on the multi-source text proposed in this paper.
Section 4 proposes a comprehensive evaluation system for coal mine equipment maintenance big language models, based on which comparative tests were conducted. The last section summarizes this research and the future research objectives of coal mine equipment maintenance big models.
3. Methodology
XCoalChat was proposed to train a professional large language model in the field of coal mine equipment maintenance by building a professional dataset for coal mine equipment maintenance. The performance of the model was improved through knowledge graph enhancement, the triple LoRA fine-tuning mechanism, and direct preference optimization so that it could better realize the three tasks of coal mine dialog consultation, professional consulting, and maintenance decision analysis. The specific framework for XCoalChat is illustrated in
Figure 1.
3.1. Construction Dataset Based on ReliableCEMK-Self-Instruction
Comprehensively considering the two aspects of coal mine safety management and equipment maintenance, this study collated a large number of different coal mine related materials. We mainly referenced coal mine safety regulations, the fault knowledge corpus in cooperation with enterprises, and the operation instructions of different fully mechanized mining face equipment as long as it involved the fault maintenance decision records of the coal mine electrical equipment and the exam questions concerning the mining system, driving system, transport system, ventilation system, safety system, and coal processing system. This will contain the basic knowledge of the coal mining equipment, the professional operation knowledge, coal mining equipment intelligence, and other related contents investigated within the scope of this study. These texts mainly have structured, semi-structured, or unstructured multi-source representation, and this paper will adopt the corresponding processing means for different data types. For the structured data such as the operation data and staff information stored in the database of the equipment production monitoring system of coal mining enterprises, it can be transformed into the ternary format by means of direct mapping and defining rules; for semi-structured data such as data on the Internet and the web page data of the coal mine equipment forum, the data are extracted from the web page using a web wrapper and the extracted web page-like data into structured form; for unstructured data such as maintenance cases, integrity standards, and maintenance guide books of coal mine equipment, etc., the key information contained therein was obtained through natural language processing techniques.
ReliableCEMK-Self-Instruction, on the strength of specific knowledge in the field of mine equipment maintenance, enhances the reliability of the dataset. After providing correlatively specific knowledge text of the coal mine equipment, ChatGPT was first asked to generate several questions pertaining to the text and their logical relationship, and then ChatGPT was asked to answer the questions through the “text segment–question” pair. In this way, XCoalChat can generate answers containing relevant normative information to ensure the accuracy of the answers. Finally, a 92 k coal mine dialog dataset, 24 k coal mine examination dataset, and 32 k maintenance decision analysis dataset were constructed.
3.2. Knowledge Graph Enhancement Based on “Coal Mine Equipment Maintenance System—Full Life Cycle—Specification”
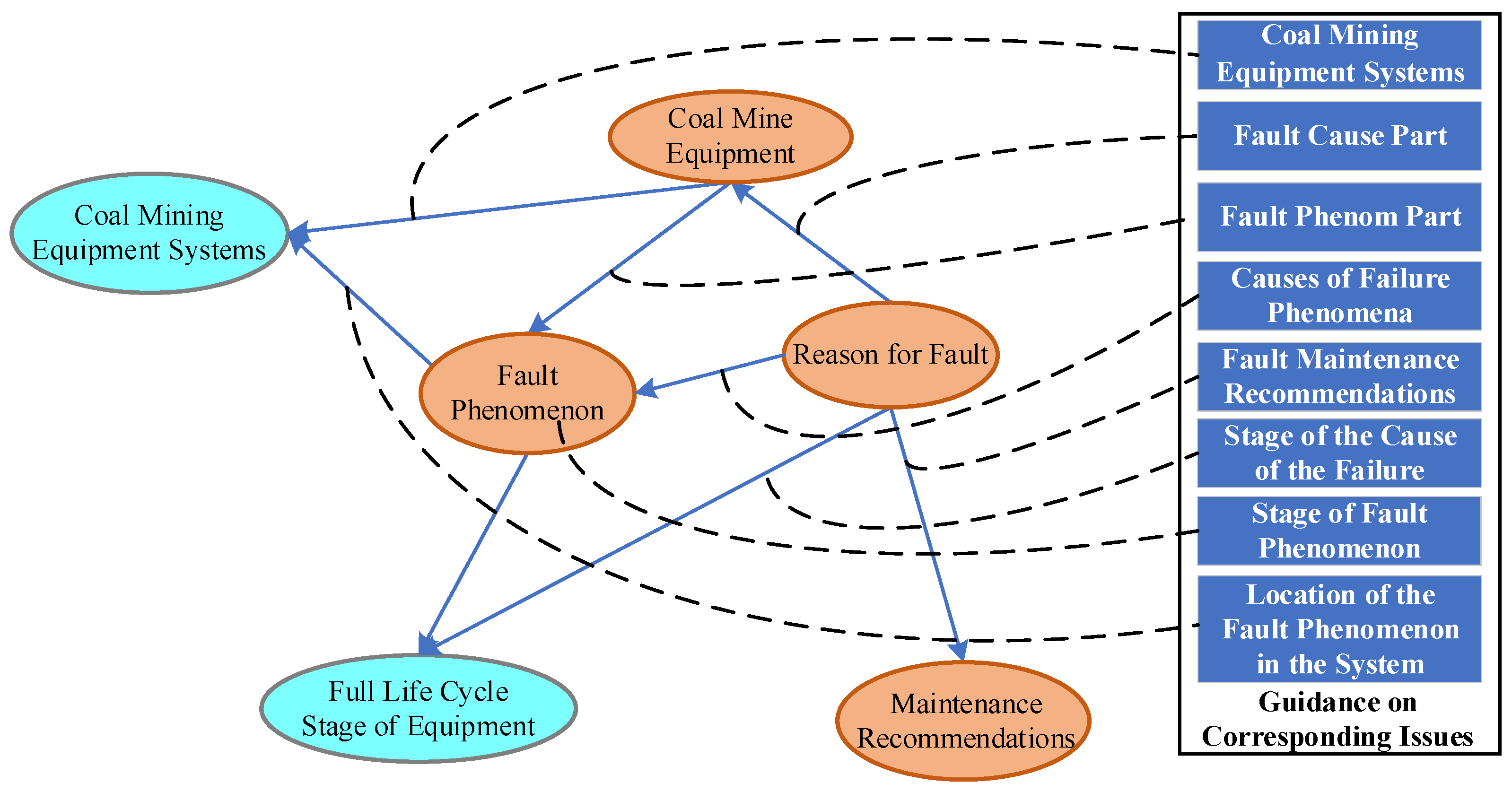
In an effort to enable LLM to identify information as well as the potential information from the coal mine equipment maintenance knowledge more systematically, completely and objectively, this paper constructed a three-dimensional coal mine equipment maintenance text database representation method based on the “Coal Mine Equipment System—Full Life Cycle—Specification”. As shown in
Figure 2, the entire coal mine equipment system was divided into seven subsystems. Next, with the intention of highlighting the characteristics of problem evolution over time, the full life cycle phases of the coal mine equipment maintenance system were divided into the equipment installation stage, equipment operation stage, and equipment maintenance stage. Together with the division method of the coal mine equipment system, all problem text that needed to be identified in different periods and different subsystems were identified. Finally, through one-by-one analysis of the laws, regulations and technical specifications, industry standards, the literature, and the qualification certificate examination questions related to coal mine equipment maintenance, all of the text information that needed to be identified was classified. After integration, the potential information database of the coal mine equipment maintenance system was obtained. For example, “the shearer cannot be reversed due to damage of potentiometer or solenoid valve” was expressed in the form of “equipment operation phase—mining equipment system—maintenance record”.
Due to the lack of understanding of the deep meaning of the generated text in the large model, hallucinations occurred. For instance, when the LLM is asked how to cook reinforced concrete, the model may directly generate the recipe and the production process. This obviously contradicts our basic understanding. Knowledge graph enhancement improved the knowledge density, alleviating to some extent the illusion of large language models and the limitations of LLMs in performing tasks that require more knowledge about the world.
As shown in
Figure 3, the knowledge graph enhancement method centered on the “Coal mine Equipment Maintenance System—Full Life Cycle—Specification” can guide the LLM to answer questions about downstream tasks. There is rich semantic knowledge among the knowledge graphs of coal mine equipment maintenance, that is, there are structural constraints between the triples.
As can be seen, if a pair of entities contains the types “failure phenomenon” and “failure cause”, the prediction probability will be relatively high in the relationship “failure phenomenon cause” and relatively low in the other relationships. Correspondingly, a relationship also constrains the type of its entity. An example of a knowledge graph enhancement prompt template, as shown in
Table 1, converts each knowledge triplet into a prompt that allows the model to learn the constraints of a question pair and generate a response that contains both the constraint information and the target knowledge. As shown in
Table 1, using the example Knowledge Graph Enhanced Prompt Template converts each knowledge triplet into a Prompt that allows the model to learn the constraint relationships of the Q&A pairs and generate a response that contains the constraint information with the target knowledge. When the input is “emulsion leakage”, the model initially identifies the hydraulic system according to the presence of “emulsion” and “leakage”. It then considers relevant constraints, infers components within the hydraulic system such as seals, and whether there are any defects or cracks. Finally, it generates a response indicating potential causes of failure.
3.3. Large Language Model Construction Based on Triple-LoRA Fine-Tuning and DPO
3.3.1. Benchmark Model
In this work, the ChatGLM-6B model was chosen as the benchmark model. This is shown in
Figure 4. ChatGLM-6B is an open-source conversational language model with support for Chinese-English bilingual Q&A and is optimized for Chinese. The model was founded on the general language model (GLM) architecture and has 6.2 billion parameters. The probability of text can be expressed as
where
stands for the size of the text.
The process is shown in
Figure 5a,b. Concatenating the three fragments together gives the model input
,
,
,
,
,
,
,
, and the model output is the occluded fragment, as shown in
Figure 5c above. Two position codes are used here: the first code injects position information for the entire input, representing the location of the masked part in the original input, and the second code injects location information for tokens within the masked part. Position encoding uses rotary position encoding (RoPE) and it selects the GeLU activation function to optimize FFN. Training objectives include not only self-supervised GLM autoregressive blank filling, but also multi-task learning for a small number of tokens to improve the performance of their downstream zero-shot tasks.
3.3.2. Triple-LoRA Fine-Tuning Mechanisms
To ensure the specialization and task-oriented function of a coal mine equipment maintenance LLM, a multi-expert fine-tuning strategy was proposed. Low rank adaptive (LoRA), a mechanism for effective parameter fine-tuning [
32], is used to train individual components of the model on a specialized dataset. They can operate autonomously without interfering with each other. LoRA applies adaptation to the pre-trained language model by introducing a low-rank matrix in its weight matrix. The pivotal steps in the LoRA adaptation process are as follows
Initialization: Start with a pre-trained language model and add a low-rank adaptation layer to its weight matrix array. This layer is represented by a low-rank matrix that is initialized to random values.
Fine-tuning: Train the model on a new task or domain, updating only the low-rank adaptation layer while keeping the weights of the pre-trained model fixed. This allows the model to learn task-specific information in a targeted way without changing its general knowledge.
Prediction: Use the fine-tuned model to make predictions about new, unseen data from the target task or domain.
LoRA indirectly trains some of the dense layers in a neural network. Afterward, LoRa employs trainable rank-decomposition matrices at each layer of the transformer architecture, thereby significantly reducing the required number of training parameters for downstream tasks. For the pre-trained weight matrix, LoRA uses low-rank decomposition, indicating the latter to constrain its updates.
where
,
and
. During training,
is frozen and does not receive gradient updates, but
and
contain trainable parameters. Note that both
and
both multiply with the identical inputs, and their corresponding output vectors are added in the coordinate direction. The original forward propagation is
The modified forward propagation is:
Ultimately, the inference speed is increased and the inference delay is reduced.
Specifically, we trained the three LoRA modules with fine-tuning of the base model for the corresponding part of the instruction. Switching between different functions during deployment only requires replacing the LoRA parameters loaded on the current base model. This eliminates the need to retrain the entire model. In addition, this approach improves the efficiency of the model for each mission. In this paper, three modules were set: LoRA for coal mine equipment dialog consultation, LoRA for coal mine professional advisory service, and LoRA for maintenance program analysis and decision. The triple LoRA mechanism is illustrated in
Figure 6.
Coal mine equipment dialog consulting: The first LoRA model was designed to address the problems and consulting dialog challenges in the context of coal mine equipment including the basic knowledge of coal mine equipment such as the development of coal mine equipment and the introduction of fully mechanized coal mining equipment like related structures and components. It mainly provides basic dialog and consultation services.
Coal mine professional consulting services: The second LoRA model aimed to train the model in the standard operation of coal mine equipment such as the operation involved in the installation and operation of the equipment as well as the ability of professional skills consulting. The main object of this service are the operators who actually participate in coal mine production or carry out coal mine-related equipment.
Maintenance program analysis and decision: The third LoRA model was mainly used to deal with various tasks of coal mine equipment fault analysis. These tasks include, but are not limited to, fault diagnosis and maintenance decision-making in the mine text. On being asked about common failure topics such as overheating, overcurrent, gear failure etc., the model can be analyzed like an expert based on relevant documentation and eventually provide maintenance recommendations.
3.3.3. Direct Preference Data Optimization Model
The direct preference optimization model skips the explicit reward modeling step and avoids the process of reinforcement learning [
33]. Starting from the loss of the RL model, the optimal solution of the reward maximization objective of the KL constraint is as follows:
where
is a partition function. We can rearrange the formula to represent the reward function depending on the matching optimal strategy
, reference strategy
, and partition function
We developed a maximum likelihood target for the parameterized strategies. As this is similar to the reward modeling approach, the policy goal becomes:
This converts the loss function of the reward function to the loss function of the policy function, skipping the explicit reward modeling step. The policy networks represent both language models and rewards. The
is a sigmoid function and
is a hyperparameter, generally between 0.1 and 0.5.
and
denote the good response and the poor response in a given preference data, respectively.
represents the cumulative probability that the current policy model generates a good response given input
.
represents the cumulative probability that the original reference model will generate a bad response given input
. The good/bad responses generated by the model were annotated with preferences using GPT-4 and then trained using DPO to achieve XCoalChat outputs that were more orientated toward human preferences.
4. Results and Discussion
To verify the feasibility and validity of the proposed model, this paper conducted experiments around the following four aspects and analyzed them in comparison with other mainstream LLMs.
Experiment 1: The experiment of dialog consultation for coal mine equipment was conducted on the dialog dataset of coal mine equipment with a training set of 73.6 k and a test set of 18.4 k. The purpose was to verify the ability of the model to generate answers.
Experiment 2: The experiment of professional consultant for coal mine equipment was conducted on the dataset of professional consultants for coal mine equipment with a training set of 19.2 k and a test set of 4.8 k. In the form of multiple-choice questions, the model was tested to determine its professional ability in coal mine equipment.
Experiment 3: The experiment of maintenance decision analysis used the maintenance decision analysis dataset with a training set of 25.6 k and a test set of 6.4 k to judge whether the model could generate corresponding maintenance decision schemes for equipment failures.
Experiment 4: The experiment of inference time comparison recorded and compared the inference time of the models during the above experiment.
For the purpose of validating the proposed multi-source text coal mine equipment maintenance model, comparison methods such as Bloom-7b and LLama-7b were employed. Bloom-7b is a large language model developed and open sourced by BigScience with seven billion references [
34]. It is trained on a dataset containing multiple languages, allowing for smoother training on raw sequence length and better downstream performance. LLama-7b is an open and efficient large base language model published by Meta AI, based on LLama, which uses the efficient implementation of causal multi-head attention mechanisms to reduce memory usage and runtime, resulting in several “Alpaca family” models such as Vicuna and Alpaca [
35].
4.1. Experimental Environment and Parameter Setting
This experiment was run under the deep learning server A100 with 40 GB of memory. The model proposed in this paper was based on a Pytorch1.10 deep learning framework and CUDA version 11.3.
Because of its open-source nature and ability to support multiple languages, ChatGLM was chosen as our benchmark large language model. Following the references with the actual referencing process, for the supervised fine-tuning process, we set the learning rate to 2 × 10−4, batch size to 128, maximum length to 1024, and trained across three epochs. For the DPO process, we applied a learning rate of 5 × 10−4 and a maximum length of 1024 to train 5000 steps. To effectively train the large language model, LoRA fine-tuned r to 8, alpha to 16, and dropout to 0.05.
4.2. Experimental Results Analysis
4.2.1. Coal Mine Equipment Dialog Consultation
An experiment in which prior historical dialogs were randomly used as input in sequence in light of evaluating the performance of dialog consultation for coal mining equipment was conducted. Sample responses are shown in
Table 2. BLEU [
36] and ROUGE [
37] were used to assess the quality of the dialog. BLEU is a commonly used metric that compares a candidate translation to one or more reference texts based on n-element syntactic precision. The larger the value, the better. On the other hand, ROUGE is a particularly important index for evaluating automatic summarization and machine translation. This is useful as it focuses on the recall aspect of the generated abstracts by comparing them with the references. As with the former, the larger the value, the better.
The results of the experiment are illustrated in
Table 3, showing that XCoalChat achieved excellent ratings on all metrics in the BLEU and ROUGE scores. It revealed that the dataset constructed in this paper contains more diverse and rich knowledge about coal mine equipment maintenance, and the knowledge density of the model was improved by the method of knowledge graph enhancement, which allows the model to cover the information provided by the reference text more effectively by generating responses under the consideration of the constraints between the knowledge triples.
4.2.2. Coal Mine Equipment Professional Consulting
The categories evaluated in the coal mine equipment professional consulting comparison experiment were based on the classes with the highest frequency in the coal mining exam dataset. The categories selected included coal mining systems, boring systems, transport systems, coal preparation systems, ventilation systems, and safety management. The question and candidate options were given as inputs and the text answers generated by the model were subsequently used to calculate accuracy. A sample response is shown in
Table 4.
The experimental results are shown in
Figure 7, indicating that XCoalChat had an average accuracy of 77.21% and outperformed other LLMs in all evaluation categories. Specifically, XCoalChat achieved a strong performance, surpassing ChatGLM-6B, BLOOM-7B, and LLama7B’s average scores of 53.59%, 47.16%, and 48.42%, respectively. It was not surprising to find that the model output the referenced normative regulations when answering questions, which was due to the ReliableCEMK-Self-Instruction methodology used in this study, based on the specific knowledge in the field of coal mine equipment maintenance and greatly improved the reliability of the model. This makes the model’s answers more informative, and the model can provide coal mine equipment operators with a reasoned guide to equipment maintenance that can reduce the incidence of incorrect operation.
4.2.3. Coal Mine Equipment Maintenance Decision
The maintenance decision analysis capability of the LLM was evaluated on the maintenance decision analysis dataset. Electrical faults, hydraulic faults, mechanical faults, and auxiliary system faults were selected for evaluation. With each fault record as the input and the generated text as the output, the accuracy of the models was calculated by comparing the generated text with the diagnostic labels in the fault records. Looking at
Table 5, it is an example of a maintenance decision analysis response. This indicates that the knowledge graph enhancement guides the larger model to incorporate the underlying relationships between the fault phenomena, fault causes, and maintenance decisions in the reasoning process, which improves the model’s logical capability and interpretability. Providing DPO methods to correct the model makes the model more suitable to the field of coal mine equipment maintenance, generates more relevant responses, and the model has a strong ability to understand and explain different fault groups.
The experimental results for each failure group are displayed in
Figure 8, where it can be seen that XCoalChat outperformed the other language models in all failure groups. XCoalChat had an average accuracy of 81.77% in all fault groups compared with ChatGLM-6B, LLama 7B, and Bloom-7B, which improved the accuracy by 47.96%, 37.25% and 39.69%, respectively. XCoalChat performed particularly strongly in terms of the hydraulic and mechanical failures, achieving an accuracy of 90.12% and 86.04%, respectively. This demonstrates the robustness of the model to understand and account for different groups of faults and will provide maintenance personnel with more accurate maintenance decision support. Maintenance specialists can refer to XCoalChat for a reference maintenance program, reducing the time spent.
4.2.4. Inference Time Comparison
The reasoning time of the model in the above experiment was recorded, and the reasoning time of the base model was the benchmark for calculating the relative reasoning speeds of the other models and comparing their average time in each experiment; results are shown in
Figure 9. Among the two tasks of dialog consultation and coal mine maintenance decision analysis, XCoalChat took the least reasoning time. The average time required for all task inference was the least, which was 89.66% of the running time of the benchmark model, and had a high practical efficiency. The triple LoRA fine-tuning mechanism enabled the model to maintain exceptional performance across all downstream tasks while significantly reducing the model’s computational overhead. XCoalChat still had a good reasoning speed while maintaining accuracy.
5. Conclusions
Aiming at the characteristics of coal mine equipment maintenance knowledge such as complexity, dispersion, low sharing and a lack of effective management, a large language model, XCoalChat, in the coal mine equipment maintenance domain based on multi-source text, was proposed. The large language model was introduced as a pioneer into the field of coal mine equipment maintenance, and the vertical field dataset of coal mine equipment maintenance was especially prepared. Compared with other mainstream large models, the method in this paper had the highest scores of BLEU and ROUGE in the dialog consultation experiment of coal mine equipment; in the professional consulting experiment of coal mine equipment, the accuracy increased by 44.08%, 63.72%, and 59.46% compared with ChatGLM-6b, Bloom-7b, and LLaMA-7b, respectively. In the maintenance decision analysis experiment, the accuracy increased by 47.96%, 37.25%, and 39.69% compared with ChatGLM-6b, Bloom-7b, and LLaMA-7b, respectively. Furthermore, the entire model inference only requires 13.28 G of GPU, which can be deployed both personally and in enterprises.
In future research, due to the fact that there is also a large amount of complex and diverse multimodal coal mining equipment maintenance knowledge, we will conduct an in-depth study into the multi-modal large language model and multi-agent mechanism, combining document intelligence and the reasoning ability of the large model to constantly update and iterate as well as continue to promote mine intelligence. An exploration of potential interdisciplinary applications and social intelligence mines as a feature approach for such analysis will be considered in the future.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}