1. Introduction
The recognition of the microconstituents of a steel micrograph is a complicated task and only within the reach of highly qualified personnel with broad experience in the field of materials science. Manual identification of steel phases can be a tedious and error-prone task; therefore, machine learning (ML) models have emerged as valuable complements to the traditional visual inspection methods employed by metallurgists. In recent years, many studies have addressed the challenge of developing artificial intelligence techniques that enable computers to handle complex tasks, such as microstructure identification [
1,
2,
3] and the inference of properties through these identification techniques utilizing ML has been investigated [
4,
5,
6,
7], yielding promising advancements. Nevertheless, given the complexity involved in microstructure identification, particularly within steel micrographs, the adoption of advanced techniques becomes necessary. For the realization of an effective image segmentation in the context of steel microstructures, a powerful tool, such as a deep neural network, is required.
In previous work [
8], it was determined that, for the categorization of steel microstructures, convolutional neural networks exhibit a notable superiority over classical machine learning algorithms. The present study constitutes a continuation of the exploration of deep learning techniques within the domain of optical micrographs of carbon steels, with a focus on segmentation algorithms. These networks allow us to establish a labeling of each pixel according to the phase of the microconstituent to be classified by means of supervised learning methods.
Recent advancements in the field of steel microstructure identification using segmentation techniques can be found. The following are discussed to provide background and context for the present article.
Luengo et al. [
9] present a comprehensive overview of AI techniques for metallographic image segmentation, utilizing two distinct datasets: The Ultra-High Carbon Steel Micrograph Database (UHCSM) and the Metallography Dataset from Additive Manufacturing of Steels (MetalDAM). The paper contributes significantly by introducing the novel dataset, MetalDAM, available at
https://dasci.es/transferencia/open-data/metal-dam/, accessed on 23 June 2023, providing an updated taxonomy of segmentation methods and exploring various deep learning-based ensemble strategies. Ensemble models exhibit superior performance in segmentation, achieving an Intersection over Union (IoU) metric of 76.71 for the UHCS dataset and 67.77 for the MetalDAM dataset. However, the performance achieved in both datasets is low. The authors conclude that microstructure segmentation faces limitations due to the insufficient availability of large datasets, the absence of pre-trained models tailored to this domain, and the notable challenges related to generalization errors in machine learning methods.
Bulgarevich et al. [
10] address the challenge of segmenting optical images of microstructures using a supervised machine learning approach. They employ the Random Forest (RF) algorithm along with image processing and segmentation protocols, including Euclidean distance conversion and structure tensor extraction, for accurate image analysis. This research recognizes the RF algorithm as a highly versatile method for segmenting various microstructures, such as ferrite, pearlite, bainite, martensite, and martensite–austenite, within steel microstructures. The results demonstrate that the segmentation quality achieved is practical and allows meaningful statistics on the volume fraction of each phase to be obtained.
Bachmann et al. [
11] present an exhaustive approach for detecting prior austenite grains (PAGs) in Nital-etched micrographs of bainitic and martensitic steels. The study utilizes a correlative microscopy technique, combining a light optical microscope (LOM), a scanning electron microscope (SEM), and electron backscatter diffraction (EBSD). The detection of PAGs is accomplished through semantic segmentation using advanced deep learning (DL) methods, specifically U-NET in conjunction with DenseNet, applied to LOM images.
To ensure effective model evaluation, the authors emphasize the critical importance of accurately measuring grain sizes in the metallurgical structure of the material. Their experiments reveal an IoU of around 70%, indicating potential discrepancies between metric values and visual perception of model quality. Recognizing the limitations of traditional metrics like IoU and pixel accuracy, particularly in the context of grain size measurement within segmentation tasks, they propose a novel approach. To address this, they introduce a method for quantifying grain size distribution from segmentation maps, calculating the mean, median, and standard deviation. By binning detected grains into intervals of a specific width (500 µm2) and calculating probability density, they accurately assess segmentation quality compared with values of the ground truth and identify potential errors in grain size determination. The results show a mean error of 6.1% in average grain size, underscoring the high quality of the DL model.
Han et al. [
12] introduced a segmentation method (CES) based on the extraction of center–environment features tailored for small material image samples. The proposed method is applied to several datasets that include carbon steels, titanium alloy, wood, and cross-sectional morphology of Pt-Al and WC-Co coating image data. Expert annotators are engaged in the process, drawing region-specific curves based on their domain knowledge. Additionally, the method takes advantage of several machine learning algorithms to achieve highly accurate segmentation. Notably, the results of the study indicate that the Gradient Boosting Decision Tree (GBDT) outperforms other methods in this context.
Additionally, a comparison is made with segmentation methods based on deep learning networks such as SegNet, PSPNet, and UNet++, which are found to be 10% higher in IoU and mean IoU metrics compared to the methodology used by the authors. This difference is attributed to the significantly fewer pixels annotated to create the masks using CES compared to deep learning methods. While the proposed method is commendable for its innovative approach and reduced annotation cost, it falls short in achieving comparable segmentation accuracy to deep learning algorithms. The observed 10% disparity in results highlights the limitations of this method, suggesting that a balance between annotation efficiency and segmentation performance has yet to be fully realized.
Kim et al. [
13] displayed the segmentation of a low-carbon steel microstructure without the need for labeled images, employing a deep learning approach. Specifically, a convolutional neural network combined with the Simple Linear Iterative Clustering (SLIC) superpixel algorithm. By leveraging a diverse range of microstructure optical images containing ferrite, pearlite, bainite, and martensite, the model effectively distinguished and delineated regions corresponding to each constituent phase.
Breumier et al. [
14] trained a U-Net model to perform the segmentation of bainite, ferrite and martensite on EBSD maps using the kernel average misorientation and the pattern quality index as input. The model can differentiate the three constituents with a 92% mean accuracy in the test results.
Chaurasia et al. [
15] proposed a versatile approach for classifying multiphase steels. It involves generating 3D polycrystalline microstructure templates using the Johnson–Mehl–Avrami–Kolmogorov (JMAK) kinetic model, creating realistic single-phase microstructures through nucleation and growth concepts. Cropped images of pearlite and ferrite are strategically placed on these templates to synthesize accurately labeled ferrite–pearlite microstructures. Subsequently, a deep learning architecture, UNET, is trained using synthetic microstructures and tested on real microstructures. The results, compared with manually annotated microstructures, demonstrate a prominent level of agreement, reaching an accuracy of about 98%.
Liu et al. [
16] conducted a study that focuses on recognizing the microconstituents of ferrite and pearlite and making predictions of their mechanical properties. For this purpose, they elaborate a residual U-shaped network based on ResNet32 to identify grain boundaries and their size, obtaining better segmentation results than the conventional neural network FCN-8s, reaching over 93% in frequency weighted intersection over union (FWIoU).
Azimi et al. [
17] utilized fully convolutional networks (FCNs) along with a max-voting scheme for the classification of martensite, bainite, pearlite, and ferrite phases in low-carbon steels, achieving a classification accuracy of 93.94%.
Recently, works similar to the research in this paper have been published, such as Ostormujof et al. [
18] that accomplished the successful classification of ferrite–martensite dual-phase steel microstructures through the implementation of the U-Net model and achieved pixel-wise accuracies of around 98%, as well as Xie et al. [
19], who provided a comparison with different segmentation architectures for steel micrographs like DeepLabv3+, Enet, Unet, and PSPnet. They propose a new semantic network based on the improvement of a fully convolutional network (FCN) with the atrous spatial pyramid pooling (ASPP) technique for feature extraction, surpassing the previous ones according to the metric Intersection over Union (IoU), achieving a performance of up to 80.43%. In our specific study, we employed LOM images as opposed to the SEM images used in the referenced article. This choice might introduce differences in the characteristics and features of the micrographs, potentially impacting the performance of segmentation algorithms. It is worth noting that the selection of imaging modalities can influence the choice of segmentation techniques and their effectiveness in each context. Ma et al. [
20] conducted training on two datasets comprising images of steel alloys, one consisting of carbide and the other predominantly of ferrite microconstituents. They employed PSPNet and DeepLabv3+ with ResNet18 segmentation networks. The authors proposed enhancing the receptive field of the convolutional neural network (CNN) to improve contextual perception of images without altering the network architecture. This was achieved by scaling the original image size to 0.5 times during image loading. Additionally, the authors established an automated quantitative analysis of the microstructures using OpenCV software after segmentation, extracting morphological information from classified pixels to obtain the average carbide radius and the number of carbides. The results, evaluated on original large-size images, yielded a mean Intersection over Union (mIoU) score of approximately 80%.
Additionally, Bihani et al. [
21] present, in this case in the context of mudrock SEM images, a method for filtering and segmentation using deep learning to identify pore and grain features named MudrockNet, which is based on DeepLab-v3+. The predictions for the test data obtain a mean IoU of 0.6663 for silt grains, 0.7797 for clay grains, and 0.6751 for pores.
Automated phase identification in steel microstructures is a rapidly evolving field. While previous studies have addressed segmentation challenges with varying degrees of success, several issues remain unresolved, including the application of segmentation to low-magnification optical images and the scarcity of dedicated steel microstructure image databases. To address these shortcomings, this research delves into the exploration of optimal architectures for this problem, specifically targeting the development of a robust segmentation model capable of automatically identifying pearlite and ferrite phases in annealed steel microstructures, which have a major influence on the properties and behavior of annealed steels.
It can be concluded that numerous studies have explored the segmentation of steel microstructures, generating segmentation models created from ad hoc networks with varying degrees of success. Nevertheless, most experiments are conducted using data obtained from scanning electron microscopy (SEM) images, rendering them unsuitable for samples produced with optical technology. This work aims to delve deeper into obtaining segmentation models for the identification of pearlite and ferrite in images coming from optical microscopy. The Deeplabv3+ and U-Net architectures will be employed for the segmentation of LOM steel microstructure images. Leveraging convolutional neural networks, these architectures have demonstrated effectiveness in image segmentation across various domains.
The methodology employed in this study integrates ImageJ with trainable Weka segmentation, Random Forest classifier training, and data augmentation to prepare a diverse dataset for the subsequent creation and training of U-Net, SegNet and DeepLabV3+ segmentation models for steel micrograph analysis. In the following sections, we will delve into the methodology and analyze the results and discussions.
2. Materials and Methods
2.1. Steel Specimens and LOM Images
The experimental procedures involved the utilization of three steel samples that underwent annealing treatment to produce ferrite and pearlite microstructures, with their respective chemical compositions detailed in
Table 1. Metallographic sample preparation was conducted by grinding and polishing according to the typical procedure used for optical microscopy and were etched with Nital-1-(alcoholic nitric acid at 1%) for 30 s, permitting observation of the grain boundaries and microstructures to be distinguished.
For the development of segmentation models, a dataset comprising 34 steel micrography images, each with a resolution of 2080 × 1542 pixels, was compiled. The selection of these images aimed to provide a comprehensive representation of the diverse microstructural features inherent in various steel samples.
As seen in
Figure 1a,b, once the steel undergoes an annealing heat treatment, a crystalline structure is obtained, revealing two distinctive zones. One zone is characterized by ferrite, appearing as a whitish matrix, while the other zone appears darker with a lamellar constituent, indicating the presence of pearlite. The normalizing heat treatment results in a similar microstructure, albeit with finer constituents, as shown in
Figure 1c.
Figure 2 provides a detailed depiction of these constituents. As observed in
Figure 2b, the pearlite consists of alternating fine bands of ferrite and cementite, maintaining a dark aspect, as mentioned earlier.
2.2. Image Preprocessing
In the preprocessing stage of the segmentation deep learning experiment carried out in this work, a comprehensive approach was implemented to enhance the quality and diversity of the dataset. This involved the initial creation of masks using specialized software, followed by a thorough data augmentation process. ImageJ, with its trainable Weka segmentation plugin, was utilized for the creation of masks [
22,
23]. This allowed for the creation of masks, outlining specific regions of interest within the steel microstructure images. Manual annotations made by the authors guided the algorithm in learning the features necessary for accurate segmentation. The annotations of the pearlite areas have been manually performed on two of the original images for each sample. Subsequently, the trainable Weka segmentation option has been applied to the rest of the images to automate the generation of masks since manual mask generation is a time-consuming process and prone to errors. Thus, by using the ImageJ segmentation assistant, the quality of the masks was improved, and the processing time was reduced. Nevertheless, the authors reviewed each generated mask, making adjustments to images containing any errors.
The trainable classifier employed for mask creation was based on the Random Forest algorithm. Configured with 200 decision trees, this algorithm demonstrated robustness in handling the complexity of steel micrography images. The training process involved feeding the algorithm with the manually annotated masks, allowing it to learn and generalize patterns within the dataset. Following the initial mask creation and classifier training, a data augmentation step was introduced to enhance the dataset’s diversity. This involved applying various transformations such as rotation, scaling, and flipping to the original 34 steel micrography images. The augmented dataset served to increase the model’s ability to generalize across a broader range of microstructural variations.
Each original image captured by the optical microscope has a resolution of 2080 × 1542 pixels. For the execution of the experiments, we have chosen to use images of 224 × 224 pixels. This choice is based on various practical and efficiency considerations. Smaller images demand fewer computational resources for both training and inference. The utilization of 224 × 224 images enables the model to execute more rapidly. Furthermore, for the transfer learning from pretrained models utilized in the experiments, such as ResNet50, ResNet18, or MobileNetV2, these models are often trained on massive datasets with specific image sizes. Employing the same image size during both training and inference eases the transfer of knowledge from pretrained models, as the initial layers are tailored to that size. It is important to note that although 224 × 224 pixels is a commonly used size, it is not a strict constraint. The image size can be adjusted to conduct experiments with a different set of images, but it might be necessary to adjust other model parameters and, in some cases, retrain the model to accommodate the new input size.
For data augmentation, each original image and mask were cropped into 54 images of size 224 × 224 pixels. Subsequently, rotations of 90°, 180°, and 270° were applied to the cropped images, resulting in 216 images for each original image. This process yielded a final dataset of 7344 images. These images were distributed randomly, with 70% allocated for training data, 20% for validation data, and 10% for the test data.
Taking into consideration the information provided before, an example of the result of the cropping and rotating images can be appreciated in
Figure 3. The masking process intended to isolate the ferrite areas contained in the images can also be observed.
After the preprocessing stage was completed, the model creation phase was initiated. This involved training various segmentation models to identify important features in the preprocessed dataset. Using the enriched dataset, different model setups and methods were experimented with. The aim was to determine which approach worked best for accurately outlining the steel microstructure images. In the following section, the training process details and metrics are described.
2.3. Segmentation Model Training
In executing the experiments, various segmentation networks were employed to establish a comparative analysis and identify the most suitable one for the context of microstructures in steels subjected to an annealing heat treatment. The segmentation networks utilized include U-Net [
24], SegNet [
25], and DeepLabV3+ [
26]. Diverse pre-trained backbones, such as ResNet18, ResNet50, and MobileNetV2, were employed for the latter.
The same algorithm has been applied to all networks. Initially, each model undergoes training using the selected images for training and validation. Once the model is generated, it is applied to the test images, subsequently obtaining various metrics [
27] that facilitate result analysis. In
Appendix A, comprehensive details regarding each layer within the architectures of the segmentation networks utilized are presented in tabular form. The description of the networks employed in the experiments is provided next.
2.3.1. U-Net
U-Net is commonly used in the context of semantic image segmentation, and its effectiveness in capturing both global context and fine details makes it particularly well-suited for tasks such as medical image segmentation and satellite image analysis, and it is also employed for the segmentation of materials microstructures [
28,
29]. U-Net is characterized by a U-shaped architecture with an encoder–decoder structure and skip connections. The encoder, on the left side of the U, consists of down-sampling layers that capture hierarchical features from the input image. The decoder, on the right side, involves up-sampling layers and skip connections that preserve high-resolution details and aid in precise localization. Skip connections connect corresponding encoder and decoder stages, facilitating the retention of spatial information. The bottleneck at the base of the U combines abstract features from the encoder with detailed spatial information from the decoder.
In the conducted experiments with U-Net, the bias term of all convolutional layers is initialized to zero. Additionally, the convolution layer weights in the encoder and decoder subnetworks are initialized using the ‘He’ weight initialization method [
30]. The encoder–decoder has a depth of 3, resulting in a U-Net comprising 46 layers with 48 connections. The most relevant hyperparameters configured for training include the Adam optimizer, a learning rate of 0.001, L2 regularization, and a maximum number of epochs set to 2. Experiments were conducted by increasing the number of epochs, yet substantial improvements were not achieved; instead, there was an increase in computational time. The loss layer utilizes cross-entropy loss to quantify the disparity between the predicted values and their corresponding actual data. The formula is expressed as follows in Equation (1).
Here, N represents the number of samples, K is the number of classes, wi denotes the weight for class i, tni is the indicator of whether the nth sample belongs to the ith class, and yni represents the output for sample n for class i.
2.3.2. SegNet
SegNet [
31] is a convolutional neural network architecture tailored for semantic image segmentation. Its distinctive features include a conventional encoder–decoder structure, where the encoder captures hierarchical features, and the decoder reconstructs the segmented output through up-sampling layers. Notably, SegNet utilizes max-pooling indices from the encoder during decoding to recover spatial information lost during down-sampling, contributing to accurate segmentation. The network leverages feature maps from the encoder for precise localization. Employing a class-specific softmax activation in the final layer enables pixel-wise classification. Although SegNet lacks skip connections between the encoder and decoder, its design, particularly the incorporation of pooling indices, makes it well-suited for tasks demanding detailed pixel-wise segmentation.
In this study, the segmentation experiments have utilized the SegNet architecture in conjunction with VGG16 [
32,
33]. In this context, VGG16 plays a role as a feature extractor, capturing high-level semantic information from the input images. It complements the segmentation capabilities of SegNet, contributing to an enhanced overall performance of the segmentation model.
2.3.3. DeepLabV3+
The segmentation models were built by integrating the DeepLabV3+ architecture with various pre-trained backbones, including ResNet50, ResNet18 [
34], and MobileNetV2 [
35]. This diverse combination harnesses the strengths of DeepLabV3+ for pixel-wise segmentation and different backbone architectures for feature extraction. The models were trained using an augmented dataset, integrating insights obtained from the Random Forest classifier.
In
Figure 4, a schematic representation of the DeepLabV3+ architecture is shown. The model employs a pretrained backbone (ResNet50, ResNet18 and MobileNetv2) for feature extraction. The Atrous Spatial Pyramid Pooling (ASPP) module is employed to capture multi-scale contextual information. The subsequent decoder, featuring skip connections, refines and up-samples the features to produce a high-resolution semantic segmentation map. This architecture provides detailed pixel-wise predictions for accurate object recognition in images.
2.4. Training Parameters, Metrics and Other Details
The training process involved optimizing various parameters, including learning rates, batch sizes, and epochs. A validation set was used to monitor the model’s performance and prevent overfitting.
When conducting experiments, identical training parameters were chosen to ensure a more faithful comparison of results. Adam optimizer with a learning rate of 0.001 and a maximum number of epochs set to 3 were selected. Additionally, the ‘Validation Patience’ parameter was set to 4 to avoid unnecessary computation. All the aforementioned information is summarized in
Table 2, which compiles essential data regarding the networks for computational time considerations.
To evaluate the performance of the segmentation models, various metrics were employed. Accuracy measures the proportion of correctly classified pixels to the total number of pixels in each class, as defined by the ground truth, and its score is calculated using Equation (2), where TP represents true positives, and FN represents false negatives. Mean Accuracy, computed as the average Accuracy of all classes across all images, provides an aggregate assessment of model performance. Global Accuracy, on the other hand, considers the ratio of correctly classified pixels, irrespective of class, to the total number of pixels.
Additionally, the Boundary F1 (BF) score, known as the BF Score, evaluates the alignment between predicted boundaries and true boundaries. Calculated using Equation (3), precision assesses the accuracy of the predicted boundaries, while recall gauges the model’s ability to capture true boundaries. A higher BF score indicates better agreement between predicted and true boundaries. The Mean BF Score offers an aggregate measure of boundary prediction performance across all classes and images.
Furthermore, the Intersection over Union (IoU) score assesses the ratio of correctly classified pixels to the total number of ground truth and predicted pixels in each class. The IoU score is computed using Equation (4), where TP represents true positives, FP represents false positives, and FN represents false negatives. The Mean IoU provides an average IoU score across all classes and images, offering insights into the overall segmentation accuracy of the model.
The trained segmentation models were evaluated on a separate test set of steel micrograph images not seen during training. The metrics used for the evaluation of the models have been previously specified.
All experiments were conducted on a robust computing system equipped with an Intel(R) Core(TM) i7-5930K CPU @ 3.50 GHz, DIMM 64 GB RAM, and an NVIDIA® GEFORCE RTX 3080 (10 GB). MATLAB® (R2023b, The MathWorks, Inc., Natick, MA, USA) was utilized for coding and generating segmentation models, and ImageJ was employed for mask creation, guaranteeing a stable and reproducible computational environment. All codes performed for this research are available upon request.
3. Results
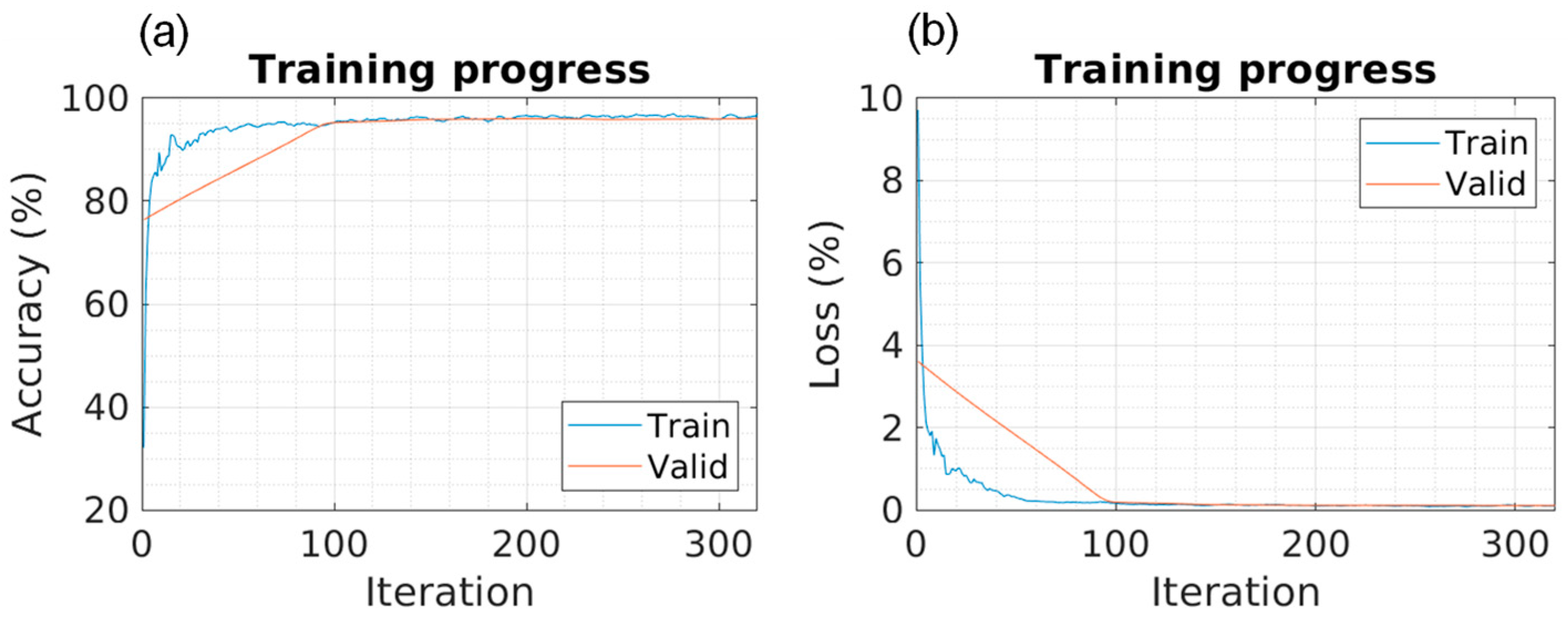
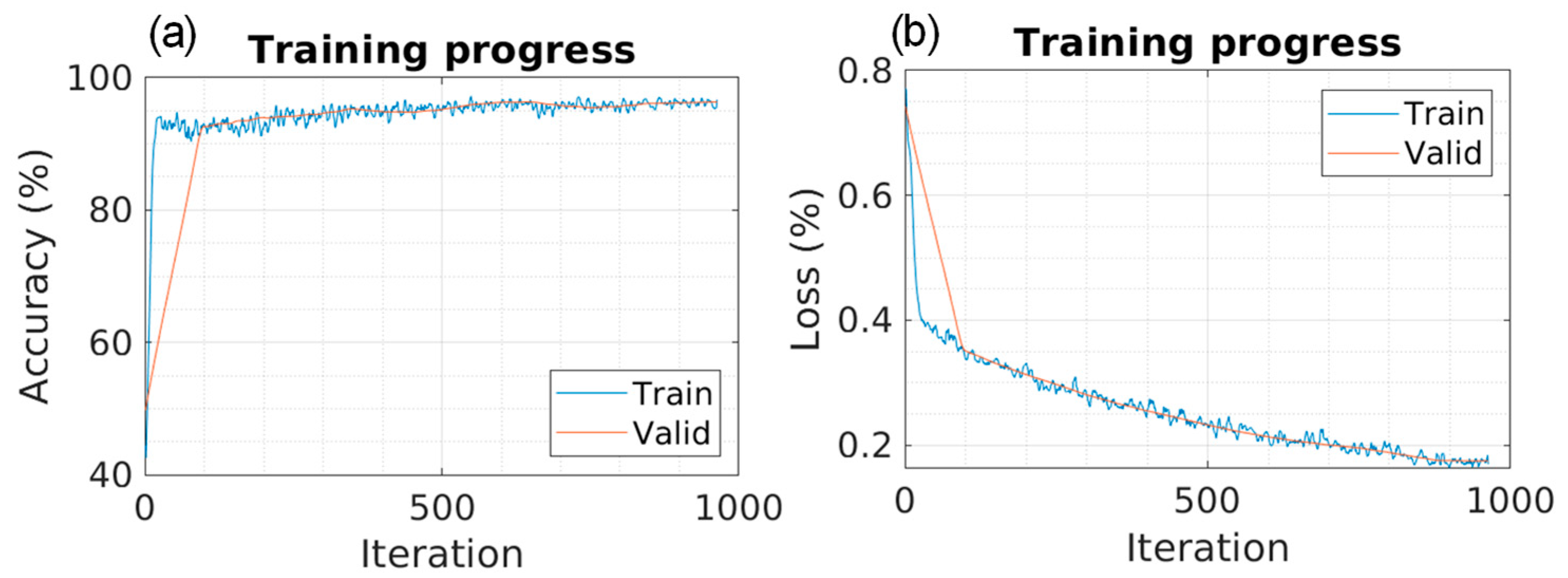
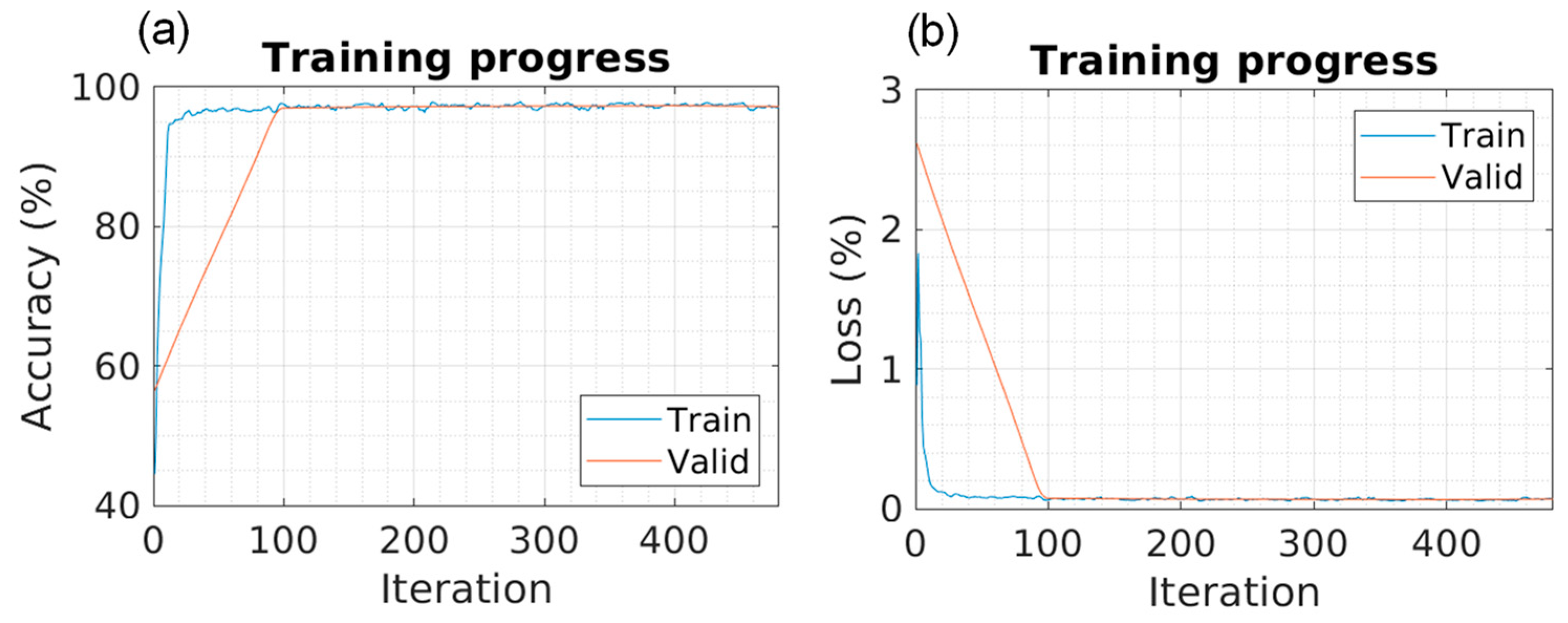
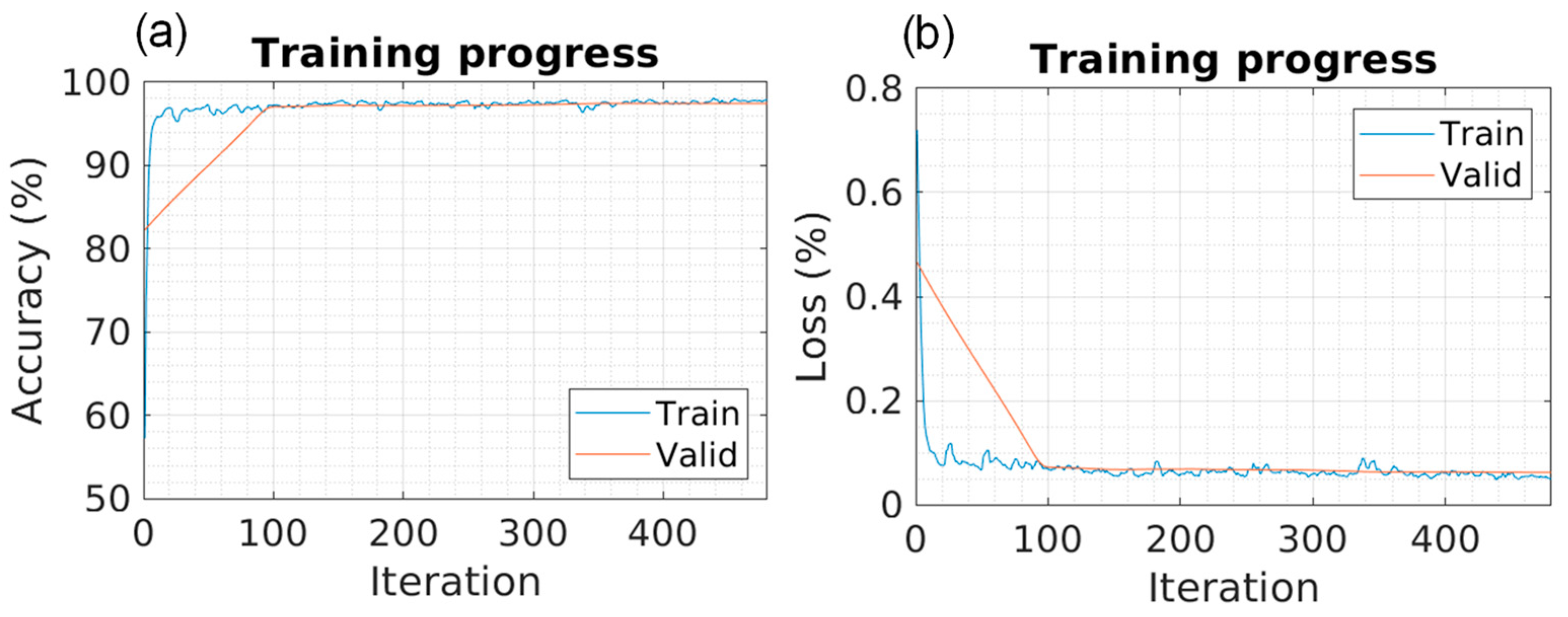
Five different models were trained using 5141 training images and 1469 validation images. The training results are presented in
Table 3, and the training progress can be observed in
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
Figure 9 for each of the models. The progression of both accuracy and the loss function is depicted.
The model was then applied to 734 test images that it had not seen previously. The results of the test experiments are included in
Table 4, which displays the usual metrics for segmentation problems. Additionally, the confusion matrices are shown in
Figure 10. It can be inferred that the DeepLabv3+ model with MobileNetv2 achieves a performance improvement, though only slightly surpassing the other networks that also accurately solve the segmentation problem.
To visually explore the results, two test images were utilized, and each was processed by every trained model. These images are depicted in
Figure 11. The segmentation performed by each model can be observed for comparison with the original sample, as well as with the mask or ground truth generated during data preprocessing before training. The objective is to distinguish between the two microconstituents: ferrite as the matrix element represented by the lighter zone in the micrograph and pearlite composed of alternating layers of cementite and ferrite. It is crucial to emphasize that the ferrite constituting the pearlite should not be segmented together with the ferrite, forming the matrix of the microstructure.
In the training phase, it can be observed that the SegNet model requires more iterations and, consequently, more computational time to achieve maximum accuracy, as depicted in
Figure 6, exceeding more than twice the others. However, its final training accuracy does not differ significantly from the rest, trailing only by a couple of percentage points compared to DeepLabv3+, which yields the best results. This increased number of iterations is due to the reduction in MiniBatchSize to 16 samples for SegNet, compared to the MiniBatchSize of 32 samples used for the other networks. Notably, when employing a MiniBatchSize of 32 samples, the performance of SegNet decreases to approximately 91% to 93%, emphasizing the need to reduce the MiniBatchSize to 16 for optimal performance. Despite the longer training time associated with the reduced MiniBatchSize, SegNet’s final accuracy remains competitive, showcasing its ability to achieve high performance even with a smaller batch size. As shown in
Figure 7,
Figure 8 and
Figure 9 achieving maximum accuracy during training requires only a few iterations for DeepLabv3+ segmentation networks. The encoder that leads to the shortest training time is ResNet18, which has the fewest layers among the three. However, MobileNetV2 exhibits slightly superior results to the other networks, achieving excellent scores in all metrics as indicated in
Table 4.
During the training process of the segmentation model, anomalies or irregularities that might occur in individual images are likely to diminish or be addressed as the model learns from a diverse set of images. The learning process, driven by probabilities, helps the model to generalize and effectively segment objects or regions of interest in images, even in cases where there might be variations or anomalies in the data. In this case, the model might not learn extensively about these imperfections due to their limited occurrence in the training data.
4. Discussion
Different random test samples were selected for segmentation using the obtained models. The accuracy and loss values in
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
Figure 9 are obtained during training. The overall values, as shown in
Table 4, are calculated based on test images that the model had not previously seen. These test values closely resemble those observed during training, indicating that no “overfitting” has occurred in any of the models.
Algorithms with lower loss rates and higher accuracy during training may demonstrate superior generalization performance on unseen data, resulting in higher final accuracy.
In
Figure 11 (segmented samples), a comparison of 224 × 224 images of annealed steel is presented, highlighting the region considered as perlite in green hues and the matrix or ferrite, which appears light in the original image and violet in the segmented image. The grayscale image corresponds to the mask generated during data preprocessing. Although the results are very similar, subtle differences can be perceived. It is important to note that some masks were created manually, while the rest underwent preprocessing using a Random Forest algorithm with WEKA software (ImageJ2-Figi GPLv3+, Waikato University, New Zeland). This process may have introduced errors in pixel annotation in some masks, causing the model to learn from imperfect images. As shown in microstructure A, there is an error in the bottom right part of the mask (slightly pointed area),
Figure 12a, where the ferrite zone connecting with the one in the top right has not been completely obtained. This flaw is highlighted in red in
Figure 12b. This error has also been transferred to the training models, which consequently failed to detect the ferrite in that zone. However, a slight improvement in the segmented area compared to the mask is noticeable. Similarly, in image B, impurities can be observed on the ferrite area (two dots on the left side), which were also transferred to the training dataset. In this case, models like DeepLabv3 with ResNet50-18 have effectively eliminated these impurities during the segmentation process.
As shown in
Figure 13, another test sample was selected, and errors in the identification of ferrite and perlite were marked on the corresponding mask image. The segmented images by the models demonstrate improvement over the mask created for training. We can observe that in the original image, it is difficult to appreciate the laminar structure of perlite. Although ferrite, as the matrix element of the microstructure, should be easily detected due to its more uniform and clear texture, the models encounter issues in some areas, such as the band in
Figure 13b, which is indicated in the red rectangular area. Considering perlite as alternating layers of ferrite and cementite, the thickness of this bright band between two darker zones causes the models to interpret that area as perlite. The models with DeepLabv3+/MobileNetv2, shown in
Figure 13f and, to some extent, U-Net, manage to enhance segmentation in that specific area.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}