Abstract
To handle the task of pointer meter reading recognition, in this paper, we propose a deep network model that can accurately detect the pointer meter dial and segment the pointer as well as the reference points from the located meter dial. Specifically, our proposed model is composed of three stages: meter dial location, reference point segmentation, and dial number reading recognition. In the first stage, we translate the task of meter dial location into a regression task, which aims to separate bounding boxes by an object detection network. This results in the accurate and fast detection of meter dials. In the second stage, the dial region image determined by the bounding box is further processed by using a deep semantic segmentation network. After that, the segmented output is used to calculate the relative position between the pointer and reference points in the third stage, which results in the final output of reading recognition. Some experiments were conducted on our collected dataset, and the experimental results show the effectiveness of our method, with a lower computational burden compared to some existing works.
1. Introduction
Pointer meters are important instruments for monitoring the status of operation devices. They have been widely used in industrial production due to their reliability and low cost [1]. The current way of reading a pointer meter is manual, which leads to issues such as low efficiency, poor accuracy, and high labor costs. In particular, manual meter reading in an unfavorable environment may lead to safety accidents [2]. Therefore, automatic and accurate pointer meter reading recognition is a natural solution, which is very desirable in industry.
With the recent development of deep learning techniques, many methods based on deep learning have been developed in the literature to handle various tasks [3,4,5,6], particularly automatic pointer meter reading. For example, Alexeev et al. [7] presented a deep network model for automatic meter reading detection that employs a convolutional network equipped with a non-linear network-in-network (NiN) kernel [8] and uses global regression to locate the pointer and reference points. The main goal of this model is to accurately detect the pointer position and all symbols of the meter dial. However, in practice, some symbols are not necessary for meter reading recognition, which may have a negative influence on accurate meter reading. In [9], a modified Mask-RCNN [10] with a precise RoI pooling (PrRoIPooling) [11] operation was developed that can identify the type of pointer meter and also fit the binary mask of the pointer and meter dial. Unlike these two methods, Dong et al. [12] focused on detecting the pointers of meters by using a method that takes the pointer as a 2D vector and utilizes a vector detection network to estimate the confidence map of this vector. The resulting vector is then used for the reading calculation by template matching and coordinate projection techniques.
Different from the methods mentioned above that employ object detectors to locate the pointer, some works determine the pointer position by using various deep segmentation networks. For example, Ref. [13] presented an attention U-Net for segmenting the pointer from the meter dial obtained by an object detector. Meanwhile, Yan et al. [14] designed a lightweight semantic segmentation model for fully automatic pointer recognition that leverages a context-guided network and a channel attention mechanism. In addition, in order to further improve the accuracy of reading recognition, various enhancement strategies, such as image skew correction and bilateral filtering for meter images, are discussed in [15]. Even though there have been many deep learning-based pointer meter reading models, the reading accuracy of these models is still unable to meet the requirements of real-world applications.
To overcome this limitation, we present a three-stage method for tackling the pointer meter reading recognition task, which is composed of meter dial location, reference point segmentation, and meter dial reading. The meter dial location stage aims to quickly locate the meter dials and output the corresponding bounding boxes. Different from the task of object location in a complex scene, meter dial location in industrial applications is generally easier to process. Therefore, we adopt a lightweight yet effective object detection network in this stage. In the segmentation stage, the dial region image determined by the bounding box is inputted into a deep semantic segmentation network. Then, the pointer and reference points from this segmentation network are used to compute the dial number in the meter dial reading stage. Due to it being robust to image distortion, we utilize the relative position, not the angle, between the pointer and reference points to obtain the final value of the meter dial. Additionally, we also collected 380 m images from the internet and two manufacturing plants, of which 304 images were used to train the model, and the remaining ones were used for testing.
The remainder of this work is organized as follows. First, we briefly review some related works on object detection and semantic segmentation in Section 2. Then, Section 3 describes the proposed meter reading model in detail. In Section 4, we present some experiments performed on our collected dataset, and the experimental results are reported to verify the effectiveness and efficiency of our model. Finally, we conclude this paper in Section 5.
2. Related Works
2.1. Object Detection
Object detection plays a very important role in the field of machine vision, which aims to detect instances of visual objects of certain classes in images. That is, the purpose of object detection is to accurately locate objects in images by using effective detection algorithms. Currently, most existing object detection approaches are mainly based on various deep network models, and they can be roughly classified into two categories: convolutional neural network (CNN)-based detection approaches and transformer-based detection approaches. In general, the former has a lower computational cost than the latter. In the following, we briefly review some important representative works in deep object detection models based on both CNNs and transformers.
A representative method for object detection is the Fast-RCNN, first proposed by Girshick in [16], which utilizes a deep convolutional neural network (DCNN) [17] with multi-task loss functions to efficiently classify the object proposals and accelerates the detection model by using the classical truncated singular value decomposition strategy. After that, Ren et al. [18] presented the well-known Faster-RCNN by applying a region proposal network to produce several candidate boxes, significantly improving the quality of candidate boxes, as well as showing high detection accuracy. Another representative work is YOLO, presented by Redmon et al. in [19], which is designed with the purpose of completing object detection in a single forward pass, eliminating the computational burden of traditional multi-step detection processes. Due to their simple structure, high accuracy, and low computational costs, YOLO and its variants have been widely used to deal with various detection tasks and achieved excellent detection performance in practical applications. Specifically, YOLOv1 [19] is the first generation of the YOLO series, introducing an end-to-end object detection approach. It divides an input image into a fixed number of grid cells and predicts classes and bounding boxes within each grid cell. YOLOv2 [20] introduces anchor boxes to handle objects of different sizes and adopts deeper network architectures, i.e., Darknet-19 and Darknet-53. Furthermore, YOLOv3 [21] improves the detection performance by using more convolutional layers and reducing the size of the network stride. In particular, it employs three different scales of feature maps to capture features at different levels and also introduces cross-scale connections and multi-scale predictions to enhance detection performance for small objects.
The transformer presented in [22] was originally designed for natural language processing. It works very well in modeling long-term dependencies in time series. Many recent works [23,24,25,26,27] have extended it to deal with various computer vision tasks. Carion et al. [24] innovatively constructed a transformer-based object detection model called DETR by redesigning the object detection network structure. Specifically, it first applies CNNs to capture image features and aggregates these features with positional encodings, and then it passes them to the transformer’s encoder. Next, a set of object queries and the output of this encoder are processed together in the decoder. Finally, each output of the transformer’s decoder is passed through a feedforward network (FFN) to independently decode it into box coordinates and the corresponding class labels. In essence, DETR translates object detection into a prediction problem, which can simplify the overall process of object detection. Based upon the relationship between objects and the global context, it directly produces the final prediction set in parallel. Furthermore, Zhu et al. [28] proposed the deformable DETR, which integrates the advantages of deformable convolution in sparse spatial sampling and the transformer in relationship modeling. In [29], Sun et al. studied the limitations of the DETR model. For instance, the DETR model exhibits slow convergence and a bottleneck in the cross-attention module in the transformer’s decoder. Based upon these observations, an encoder-only variant of DETR was introduced. Inspired by the success of unsupervised pre-training, Dai et al. [30] presented an unsupervised pre-training DETR by introducing random query patch detection, which enables it to work well without any manual annotation. In addition, to address the issue of high computational complexity in DETR, an adaptive clustering transformer was further presented in [31], which is able to significantly reduce the training and inference cost of DETR and obtain a good trade-off between accuracy and speed.
2.2. Semantic Segmentation
The second stage in our model is to segment the pointer and reference points from the meter dial by the semantic segmentation technique, which is also a fundamental task in the fields of image processing and computer vision. Thus, some important deep models for semantic segmentation are reviewed in this subsection.
Two representative semantic segmentation models are the fully convolutional network (FCN) [32] and U-Net [33]. Due to its great success in handling the semantic segmentation task, the FCN has been a popular backbone, in which a skip connection is introduced to combine low-level detail information with high-level semantic information. The skip connection is very beneficial for preserving the boundary information of images and thus improving the segmentation performance. Furthermore, U-Net [33] and its variants [34] use dense skip connections to fuse the features of the encoder and the corresponding features of the decoder and achieve significant performance improvements in medical image segmentation. Different from the FCN and U-Net, the SegNet model, first proposed in [35,36], introduces an index preserving max pooling to compensate for the reduced spatial resolution caused by the max pooling operation used in the encoder. In addition, DeepLab and various improved versions employ dilated convolution to increase the receptive fields of convolution operations and also utilize spatial pyramid pooling to extract multi-scale contextual information, achieving a significant performance gain over previous semantic segmentation models. In order to aggregate the global information and further improve the segmentation performance, ref. [37] proposed a hybrid dilated convolution approach that can effectively increase the encoder’s receptive fields and also mitigate the gridding issue caused by traditional dilated convolution.
Multi-scale feature extraction is also very important for dealing with various semantic segmentation tasks, which can be implemented in different manners. A simple implementation approach is to directly feed multiple input images (i.e., different-resolution versions of an original input image) with different resolutions into one CNN. This method enables the network to extract discriminative multi-scale features [38]. Another way is to first construct a pyramid or steerable pyramid representation of an image [39] and then apply CNNs to process and fuse the feature maps at different scales. In [40], a pyramid pooling module was designed to fuse the local detail information and the global contextual information for effective feature extraction. Similarly, Chen et al. [41] developed atrous spatial pyramid pooling. To better integrate multi-scale feature maps, RefineNet [42] presented a multi-resolution fusion block for accurately producing the segmentation result, in which the feature maps of different resolutions are fused by the skip connection and convolution operations. Unlike the aforementioned segmentation models that use specially designed network structures, a neural architecture search strategy was presented in [43] to adaptively identify and combine multiple branches with different resolutions. Meanwhile, some works attempted to enhance semantic segmentation models using the attention mechanism [44]. For example, a feature pyramid attention module was developed in [45] by combining the feature pyramid representation and attention mechanism, which resulted in more accurate segmentation results. In [46], the self-attention mechanism was introduced to deal with the semantic segmentation task, in which a position attention module is adopted to fuse useful spatial features scattered at different positions, and a channel attention module is also used to focus on interdependent feature maps. In order to capture long-range contextual information, a point-wise network based on spatial attention was proposed in [47], which improves the segmentation performance via bi-directional information propagation. In addition, a criss-cross attention network was introduced in [48] for semantic segmentation, which can effectively extract image contextual information with a low computational cost.
Very recently, transformer-based semantic segmentation models have shown great potential and have outperformed most CNN-based segmentation models. To our best knowledge, ViT [26] is the first work to verify that a pure transformer framework can also obtain state-of-the-art performance in the task of computer vision. The core idea of ViT is to split an input image into patches and consider them a sequence of tokens. These tokens are fed into multiple transformer layers to generate the features of an image, which are used for the task of image classification. Furthermore, PVT [49] equips the standard transformer with a pyramid structure to handle dense prediction tasks. Some experimental results demonstrate that this pyramid transformer has better representation performance than CNN-based network models. Swin [50] introduces the multi-scale feature hierarchical strategy into the transformer, which computes the feature representation with shifted windows. This hierarchical transformer has the flexibility to model at different scales due to the efficiency of the shifted windowing scheme. In fact, the self-attention used in the transformer is a very effective technique for encoding spatial information. Thus, the current best position of semantic segmentation is dominated by transformer-based models. However, self-attention is computationally expensive. To handle this issue, Guo et al. [51] developed a convolutional attention-based segmentation model called SegNeXt. For encoding contextual information, convolutional attention is more efficient and effective than the standard self-attention mechanism. Due to the simplicity and efficiency of cheap convolution operations, this model can significantly improve the segmentation performance with low computational complexity. Despite this, compared to CNN-based models, the inference speed of transformer-based segmentation models is slow, which is undesirable for real-time applications.
3. Proposed Method
As discussed above, CNN-based detection and segmentation models generally have a low computational burden. Therefore, in this work, we focus on CNN-based models for pointer meter dial reading. Figure 1 illustrates the proposed model, which consists of three main components: the meter dial location network, the reference point segmentation network, and the reading dial number module. The location network aims to detect the meter dial, which translates the task of meter dial location into a regression problem that spatially separates bounding boxes by an object detection network. After that, the segmentation network segments the reference points, including pointer and grid points. Once the reference points are obtained, we can read (i.e., recognize) the meter dial number by computing the relative position between the pointer and grid reference points. Even though the structure of each part of our model is very simple, experimental results on our collected dataset demonstrate its efficiency and effectiveness. In the following, we describe the three components of our model in detail.

Figure 1.
The architecture of our proposed pointer meter reading model.
3.1. Meter Dial Location Network
In order to achieve real-time meter dial location, we employ a lightweight version of the Darknet-19 framework, first presented in [19], as the backbone of our model. The main motivation is that Darknet-19 has been widely used in the YOLO family, and its effectiveness has been verified in many practical applications. Specifically, this lightweight network has 19 convolutional layers and 5 max pooling layers, the same as the original Darknet-19. The only difference between them is that the number of filters employed in each convolutional layer of our model is half that in Darknet-19. As a result, this lightweight network can locate the meter dial at a fast inference speed with satisfactory location accuracy.
Figure 2 illustrates the architecture of the meter dial location network used in the first stage of our model. This network model first processes the input image via a series of convolution and pooling operations. Then, it applies an average pooling layer followed by a softmax layer to produce the output information about the confidence score, position, and size of each bounding box. At last, a non-maximum suppression operation is performed to further select the bounding box with the highest likelihood and output its coordinate information. After that, according to the coordinates of each bounding box, the input image is cropped to obtain the meter dial and feed it into the next stage to segment the pointer and reference points. Note that, in our model, k1 × 1 and k3 × 3 used in the Con2d layer represent 1 × 1 and 3 × 3 convolution kernels, respectively. In the Maxpool layer, k2 and s1 denote a pooling kernel of size 2 × 2 and a pooling stride of size 1, respectively, and p1 means that the padding size is 1.
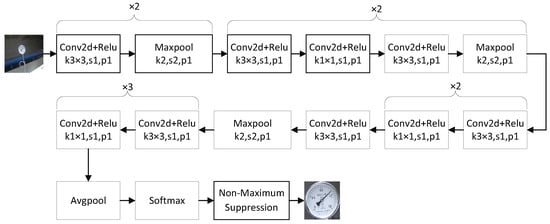
Figure 2.
The architectural details of the meter dial location network used in the first stage.
3.2. Reference Point Segmentation Network
After obtaining the meter dial region of the input image, we further segment the pointer and reference points from the meter dial by using a fully convolutional segmentation network. In this reference point segmentation network, we adopt the atrous convolution proposed in [52], which is an efficient and effective way to increase the receptive field of a deep network and also keep the spatial resolution of the resulting feature maps. Due to its fully convolutional framework, the reference point segmentation network is easy to implement and speeds up the inference process on various hardware platforms. This is very important for real-time applications.
Figure 3 shows the architectural details of the reference point segmentation network used in the second stage of our model. This network employs the widely used VGG16 [53] as its backbone but removes the fully connected layers of VGG16 and only retains the convolutional and max pooling layers. In order to capture the global contextual information of an input image, atrous convolution with a stride ratio is utilized to enlarge the model’s receptive field. A Conv2d layer equipped with 1 × 1 convolution is adopted to fuse all the feature maps to output the segmentation result. It is necessary to point out that the segmentation result obtained by the last Conv2d layer is reduced with a downsampling factor of 8x, which is caused by the max pooling layers. Therefore, we apply an upsampler based on the classic bicubic interpolation method to resize the segmentation result to the original image resolution.
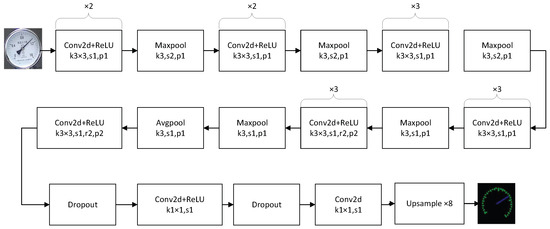
Figure 3.
The architectural details of the reference point segmentation network adopted in the second stage.
3.3. Reading Dial Numbers
In this stage, the pointer and grid points segmented from the previous stage are further used to recognize the dial numbers. In general, we need to first determine the center point of the meter dial region that is generated by the meter dial location network. For ease of presentation, let the center point coordinate be . Based on this coordinate, it is easy to find the pointer by searching similar pixels around the center point. After determining the position and direction of the pointer, a simple method for reading the dial number is to utilize the angle ratio to compute the value, as shown in Figure 4a. This method has been used in some existing works [15,54].
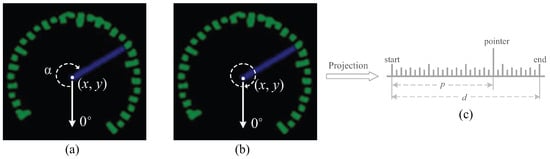
Figure 4.
A diagram of different methods for computing the dial number.
Unlike the above method that obtains the dial value of the meter dial by calculating the angle between the pointer direction and the minimum scale direction, we consider the center point to be the origin of a polar coordinate system. Based upon the transform relationship between the polar and Cartesian coordinates, circular grid points are projected into uniformly aligned points along with a straight line, which is illustrated in Figure 4b,c. At last, we achieve the final scale value of the meter dial (i.e., reading of dial numbers) by computing the relative position between the pointer and the aligned reference points, which is expressed as
where d denotes the distance between the starting and end points shown in Figure 4c, p is the distance between the starting point and the pointer, and scale represents the largest dial value of the target meter and needs to be known in advance. It is necessary to point out that our distance-based method for reading dial numbers can achieve higher accuracy than the angle-based method. The major reason is that the latter is very sensitive to the distortion of the meter image. Unfortunately, image distortion is inevitable in practical applications.
3.4. Loss Functions
To train our proposed deep model, we apply the widely used Intersection over Union (IoU) loss [55] for the task of bounding box regression and the cross-entropy (CE) loss for the dense prediction task. Specifically, we first optimize the weight parameters of the meter dial location network by minimizing the IoU loss and then train the reference point segmentation network using the CE loss, which is summed up over all the pixels. The IoU loss is defined as
where and , respectively, denote the located bounding box of a meter and the corresponding ground truth, and is the overlapping area of and . The CE loss is formulated as follows:
where represents the predicted label, and refers to the ground truth. Note that, although various loss functions have been designed for detection and segmentation tasks, we found that the IoU and CE loss functions work well for our model.
4. Experiments
4.1. Dataset and Setting
At present, there are no publicly available datasets for the task of pointer meter reading recognition. To address this issue, we collected 380 images with the size 1024 × 1024 from the internet and two manufacturing plants in Shandong, each of which has at least one pointer meter. Figure 5 shows six example cases from this dataset. In order to achieve accurate image labels, two annotators performed the label operation, and their annotations were averaged to produce the final label of each image. The annotation information includes the position, height, and width of each bounding box and the positions of the pointer and different scales. Considering that our pointer meter dataset has a limited number of images, we first pre-trained both the meter dial location network and the reference point segmentation network based on the COCO dataset [56]. Then we further fine-tuned the weight parameters of these two networks based on our meter dataset. All the meter images were randomly sampled and divided into two sets with a ratio of 8:2, namely, one set for model training and the other for model testing. For data augmentation in the training phase, we applied the commonly used random rotation and resizing operations, which can enhance the performance of our model and also alleviate the overfitting problem caused by the small dataset. Note that all the deep models in the experiments were trained with the same data augmentation techniques. In addition, we conducted all experiments on a PC equipped with an Intel Core i7-10700k CPU (Santa Clara, CA, USA), 32GB memory, and an NVIDIA GeForce GTX2080Ti GPU (Santa Clara, CA, USA).

Figure 5.
Some examples from our pointer meter dataset.
4.2. Evaluation Metric
Due to our model being composed of three stages, we evaluate the output of each stage to completely quantify the performance of our method. Specifically, for the first stage, the average precision (AP) metric is utilized to measure the location accuracy of the meter dial location network. The AP is measured by computing the area under the precision–recall (P-R) curve, where the definitions of the precision and recall are as follows:
where TP, FP, and FN are, respectively, the number of true positives, false positives, and false negatives. The P-R curve can indicate the relationship between precision and recall for different thresholds. Note that we only consider a bounding box to be correct if its IoU with the ground truth is higher than 0.5. For the second stage, we employ the mean IoU (mIoU) between the segmentation result and its ground truth to assess the performance of the reference point segmentation network, which is formulated as
where refers to the i-th class being segmented as class j, and k is the total number of all classes. In addition, for the stage of reading dial numbers, the relative error (RE) is used to evaluate the accuracy of dial value estimation, which is defined as
where and denote the estimated value and the corresponding actual value, respectively. In essence, the RE measures the ratio of the absolute error of the pointer reading value to the actual value, and it is a widely used metric for value estimation.
4.3. Experimental Results
We first used 304 images in our dataset to train the meter dial location network and then used the remaining images (i.e., 76 images) to test our location network. The AP metric and running time are employed to evaluate the detection performance of different methods. Table 1 reports the quantitative results of our method and three widely used deep detection networks, i.e., SSD [57], RetinaNet [58], and YOLOv4 [59]. From this table, it can observed that all detection methods achieve satisfying performance, resulting in very close AP values. This means that meter dial detection is not a very challenging task for existing state-of-the-art generic object detection models. Meanwhile, although YOLOv4 has a slightly higher AP value than our method, the proposed method obtains approximately 3 times the computational efficiency.

Table 1.
Quantitative results of different detection methods for meter dial location.
We further compare the performance of the proposed reference point segmentation model with three representative deep segmentation models, i.e., FCN [32], SegNet [35], and U-Net [33]. The comparison results in terms of mIoU and running time are listed in Table 2. It can be easily found that the proposed segmentation model outperforms the other competing models, while it has a slight degeneration in efficiency. More importantly, a slightly increased computational cost results in a significant gain in the accuracy of dial number reading. Meanwhile, the relative error of the recognized pointer value from our method is approximately 0.011. In most practical applications, this small relative error indicates a high reading accuracy. Specifically, it means that the proposed method can achieve an accuracy of 98.9%. For U-Net, FCN, and SegNet, the relative errors are 0.057, 0.094, and 0.116, respectively. The proposed segmentation method is significantly better than the competing segmentation methods. In addition, Figure 6 shows six meter images and their reading results obtained by our method. It can also be found that the proposed method accurately locates the meter dials and recognizes the values of dial pointers. These results clearly verify the effectiveness of our method.
Table 2.
Quantitative results of different methods for dial point segmentation.

Figure 6.
Some meter images and their corresponding reading results obtained by our method.
4.4. Additional Discussion
In Table 1, we observe that the AP values of different detection models have no significant differences. The reason is that the dataset for the task of pointer meter location generally contains one object class, i.e., the meter class. Therefore, the meter detection task is more easy to tackle than the generic object detection task. Generally, most deep models designed for generic object detection are well suited to locate the pointer meter. Meanwhile, the mIoU results listed in Table 2 show that the segmentation models have clear differences in performance. This means that some attention should be paid to developing a more precise method for reference point segmentation. Considering that the reference points are directional and regular, we can design some specific segmentation models by integrating this prior information.
Intuitively, there is a cumulative error from the meter dial location stage and the reference point segmentation stage. It is necessary to point out that meter dial location in industrial applications is generally easier than object location in complex scenes. Therefore, we adopt a lightweight yet effective object detection network to locate meter dials in the first stage. Although it is not perfect, almost all meter dials in the test images can be located with entire bounding boxes. Meanwhile, the segmentation network used in the second stage is able to correct small detection errors using data augmentation techniques in the training phase. In the experiments, we found that this cumulative error can be negligible.
5. Conclusions
For the task of automatic and accurate meter pointer reading, which is very desirable in intelligent factories, this work presents a deep learning-based method. The proposed method first detects the meter dial object, and its bounding box is output by our meter dial location network, which is a lightweight YOLO-like deep convolutional network. Next, the dial region image from the preceding stage is fed into a reference point segmentation network to segment the positions of the dial pointer and reference points. Then, we project the regular points onto uniformly aligned points along with a straight line and calculate the relative position between the pointer and aligned points to achieve the final scale value of the meter dial. Some quantitative evaluation results are provided to demonstrate the good recognition performance of our proposed method.
In addition, this paper focuses on analog meter reading recognition, which is mainly built upon the object detection and segmentation techniques. Different from this task, digital meter reading recognition generally depends on the optical character recognition (OCR) technique. A generic reading approach is desirable to recognize both analog meters and digital ones. Another possible direction is to further compress the number of the model’s parameters, resulting in a more lightweight detection model for platforms with low computational resources. In fact, pointer meters come in several specific shapes, e.g., a circular shape and a square shape. This is very important, and available geometric information is required for designing more efficient and effective pointer meter location models. All these studies could be future work.
Author Contributions
Conceptualization, Y.L.; methodology, Y.L. and X.L.; validation, Y.L.; formal analysis, C.Z.; investigation, X.L.; writing—original draft preparation, Y.L.; writing—review and editing, X.L.; supervision, C.Z.; funding acquisition, C.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, grant numbers U22A2033 and 62072281.
Data Availability Statement
Restrictions apply to the availability of these data. Data were obtained from two factories of a company in Shandong, China and are available by authors with the permission of the company.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Xu, W.; Wang, W.; Ren, J.; Cai, C.; Xue, Y. A novel object detection method of pointer meter based on improved YOLOv4-tiny. Appl. Sci. 2023, 13, 3822. [Google Scholar] [CrossRef]
- Zhang, H.; Rao, Y.; Shao, J.; Meng, F.; Pu, J. Reading various types of pointer meters under extreme motion blur. IEEE Trans. Instrum. Meas. 2023, 72, 5019815. [Google Scholar] [CrossRef]
- Hui, S.; Guo, Q.; Geng, X.; Zhang, C. Multi-guidance CNNs for salient object detection. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 117. [Google Scholar] [CrossRef]
- Lu, S.; Guo, Q.; Zhang, Y. Salient object detection using recurrent guidance network with hierarchical attention features. IEEE Access 2020, 8, 151325–151334. [Google Scholar] [CrossRef]
- Guo, Q.; Fang, L.; Wang, R.; Zhang, C. Multivariate time series forecasting using multiscale recurrent networks with scale attention and cross-scale guidance. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–5, early access. [Google Scholar] [CrossRef] [PubMed]
- Sun, H.; Guo, Q. DSG-GAN: Multi-turn text-to-image synthesis via dual semantic-stream guidance with global and local linguistics. Intell. Syst. Appl. 2023, 20, 200271. [Google Scholar] [CrossRef]
- Alexeev, A.; Kukharev, G.; Matveev, Y.; Matveev, A. A highly efficient neural network solution for automated detection of pointer meters with different analog scales operating in different conditions. Mathematics 2020, 8, 1104. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Netwrok in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Zuo, L.; He, P.; Zhang, C.; Zhang, Z. A robust approach to reading recognition of pointer meters based on improved mask-RCNN. Neurocomputing 2020, 388, 90–101. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Patten Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of localization confidence for accurate object detection. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 784–799. [Google Scholar]
- Dong, Z.; Gao, Y.; Yan, Y.; Chen, F. Vector detection network: An application study on robots reading analog meters in the wild. IEEE Trans. Artif. Intell. 2021, 2, 394–403. [Google Scholar] [CrossRef]
- Hou, L.; Wang, S.; Sun, X.; Mao, G. A pointer meter reading recognition method based on YOLOX and semantic segmentation technology. Measurement 2023, 218, 113241. [Google Scholar] [CrossRef]
- Yan, F.; Xu, W.; Huang, Q.; Wu, S. Fully automatic reading recognition for pointer meters based on lightweight image semantic segmentation model. Laser Optoelectron. Prog. 2022, 59, 2410001. [Google Scholar]
- Wu, X.; Shi, X.; Jiang, Y.; Gong, J. A high-precision automatic pointer meter reading system in low-light environment. Sensors 2021, 21, 4891. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 31–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Parmar, N.; Vasani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image transformer. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Chen, M.; Radford, A.; Child, R.; Wu, J.; Jun, H.; Luan, D.; Sutskever, I. Generative pretraining from pixels. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1691–1703. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. Taming transformers for high- resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12873–12883. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Sun, Z.; Cao, S.; Yang, Y.; Kitani, K.M. Rethinking transformer-based set prediction for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3611–3620. [Google Scholar]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. UP-DETR: Unsupervised pretraining for object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1601–1610. [Google Scholar]
- Zheng, M.; Gao, P.; Zhang, R.; Wang, X.; Li, H.; Dong, C. End-to-end object detection with adaptive clustering transformer. In Proceedings of the British Machine Vision Conference, Online, 22–25 November 2021. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A nested U-Net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision; 2018; pp. 801–818. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Chen, W.; Jiang, Z.; Wang, Z.; Cui, K.; Qian, X. Collaborative global-local networks for memory-efficient segmentation ofultra-high resolution images. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8924–8933. [Google Scholar]
- Simoncelli, E.P.; Freeman, W.T. The steerable pyramid: A flexible architecture for multi-scale derivative computation. In Proceedings of the IEEE International Conference on Image Processing, Washington, DC, USA, 23–26 October 1995; pp. 444–447. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2018, arXiv:1706.05587. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Chen, W.; Gong, X.; Liu, X.; Zhang, Q.; Li, Y.; Wang, Z. Fasterseg: Searching for faster real-time semantic segmentation. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Li, X.; Zhong, Z.; Wu, J.; Yang, Y.; Lin, Z.; Liu, H. Expectation-maximization attention networks for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9167–9176. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Change, L.C.; Lin, D.; Jia, J. PSANet: Point-wise spatial attention network for sceneparsing. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 267–283. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Guo, M.-H.; Lu, C.-Z.; Hou, Q.; Liu, Z.; Cheng, M.M.; Hu, S.M. SegNeXt: Rethinking convolutional attention design for semantic segmentation. Adv. Neural Inf. Process. Syst. 2022, 35, 1140–1156. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zou, L.; Wang, K.; Wang, X.; Zhang, J.; Li, R.; Wu, Z. Automatic recognition reading method of pointer meter based on YOLOv5-mr model. Sensors 2023, 23, 6644. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An advanced object detection network. In Proceedings of the 24th ACM international conference on Multimedia, Amsterdam The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Lawrence Zitnick, C. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).