
A Generative Artificial-Intelligence-Based Workbench to Test New Methodologies in Organisational Health and Safety

 , ,
, ,  , and
, and
Abstract
Featured Application
Abstract
1. Introduction
2. Literature Background
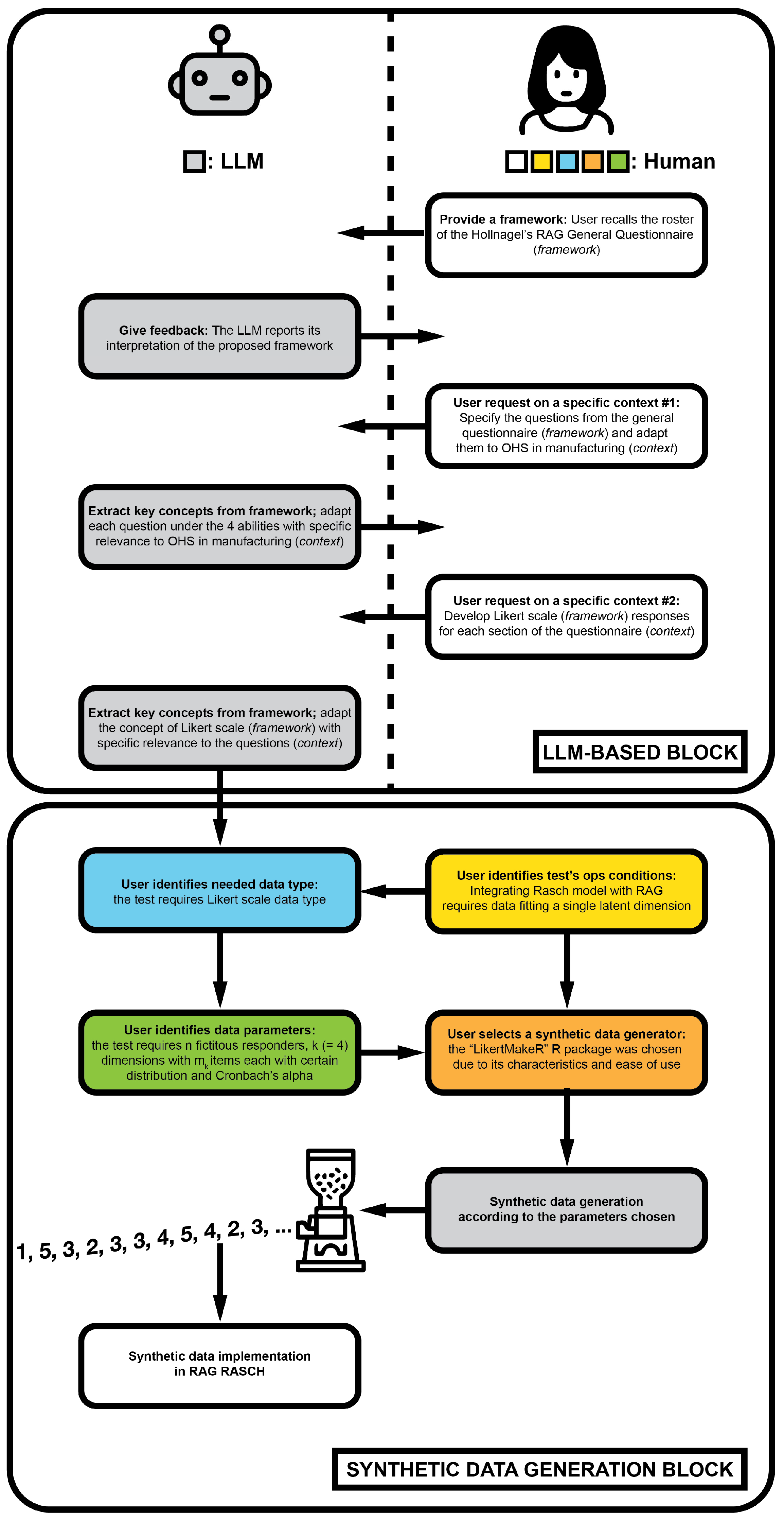
3. Proposed Workflow Workbench
3.1. General Structure
3.1.1. LLM-Based Block
3.1.2. Synthetic Data Generation Block
4. Walkthrough Application
- Starting from the general structure of the Analytic Hierarchy Process, the human asks the LLM to provide a specific AHP-based cost-benefit analysis on the implementation of Lock Out Tag Out procedures in a dairy factory, also defining the parameters for a synthetic discrete time simulation of the packaging machines;
- Starting from a typical measuring chain for an experimental setting in hydrogen natural storage, the goal is to develop a Functional Resonance Analysis Method model representing the sociotechnical system under the focus of the analysis and also providing the phenotypes for the associated Monte Carlo simulation;
- Starting from the general structure of Bayesian networks, the human asks the LLM to provide a specific model to evaluate emergency response strategies in high-rise buildings. This involves defining parameters for a synthetic simulation, such as building height, population density, and response times, which will demonstrate the effectiveness of various safety measures across different building configurations;
- Starting from Decision Tree analyses, the human asks the LLM to develop a model to assess optimal personal protective equipment (PPE) usage in chemical manufacturing. The model includes defining decision nodes based on chemical hazards and PPE types and parameters for synthetic scenarios that adapt to different plant sizes and exposure levels;
- Starting from dynamic systems modelling, the human agent asks the LLM to create a model for analysing supply chain resilience in the retail industry. This involves defining parameters that simulate disruptions like delivery delays and supply shortages due to the pandemic and tailoring the model to different scales of retail operations and geographic variables;
- Starting from the agent-based modelling notions, the human agent asks the LLM to simulate the spread of infectious diseases within corporate offices and evaluate health interventions. The model will require defining parameters such as office size, interaction patterns, and intervention efficacy, aiming to provide tailored health and safety strategies for different office environments;
- Starting from system dynamics theory, the human asks the LLM to analyse energy consumption patterns and sustainability strategies across various industrial complexes. The setup involves defining dynamic parameters such as energy source types, machinery efficiency, and operational practices, which adapt the model for diverse industrial sectors and scales.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
OHS RAG Questionnaire

{kind=link}
{kind=link}
{kind=link}
| Possible Answers | |||||||
|---|---|---|---|---|---|---|---|
| ID | Item | Question | 1 | 2 | 3 | 4 | 5 |
| R1 | Event list | What are the key OHS incidents for which the system has predefined responses (e.g., machinery accidents, chemical spills, fire, electrical hazards, slips/trips)? Are there prepared responses for different types of injuries (e.g., fractures, burns)? | No prepared responses for any events | Very few events have prepared responses | Some events have prepared responses, but important gaps exist | Most events have prepared responses | All critical events have detailed, prepared responses |
| R2 | Background | How were these OHS events identified as critical? Was it based on risk assessments, regulatory requirements (e.g., OSHA, EU regulations), historical incidents within the manufacturing sector, or industry-wide trends? | No clear rationale for event selection | Some events were selected with rationale, but most were not | Selection process is based on partial evidence or incomplete analysis | Selection process is mostly thorough and follows industry standards | Event selection is fully based on comprehensive risk assessments and regulatory requirements |
| R3 | Relevance | When was this list of OHS-related events created? How frequently is it reviewed or updated? Is the list modified after a near-miss, safety audit, or based on new regulatory requirements? Who is responsible for updating it—HR, Safety Officers, or the Compliance Team? | The list has never been revised | The list is rarely revised (e.g., only in response to incidents) | The list is updated occasionally (e.g., after audits or inspections) | The list is regularly updated based on industry trends or regulatory changes | The list is continuously and proactively revised with a formal review process |
| R4 | Threshold | What is the threshold for activating a safety response (e.g., injury severity, exposure to hazardous substances)? Does it vary depending on internal factors like production demands or external factors like weather conditions? Is there a trade-off between safety and maintaining production schedules? | There are no defined criteria for triggering a response | Criteria exist but are vague or rarely followed | Some criteria are clear, but others remain inconsistent or dependent on factors like production pressure | Most criteria are well-defined and generally followed | Criteria are fully defined, specific, and consistently applied across all OHS scenarios |
| R5 | Response list | How was the list of specific OHS responses developed (e.g., use of safety standards like ISO 45001)? Is it based on empirical evidence from accidents in the manufacturing sector, or on model simulations? | The response list is inadequate for almost all events | The response list is inadequate for many events | The response list is somewhat adequate, but significant gaps remain | The response list is adequate for most events, but a few gaps exist | The response list is comprehensive and fully adequate for all expected events |
| R6 | Speed | How quickly can the safety team respond to different types of incidents (e.g., how fast can machinery be shut down in an emergency)? What measures ensure quick response (e.g., location of first-aid kits, accessibility of fire extinguishers, on-site medical staff)? | Responses are slow and usually delayed | Responses are often slow but occasionally timely | Responses are reasonably quick but may face occasional delays | Responses are quick and timely in most cases | Responses are implemented rapidly and effectively in all cases |
| R7 | Duration | For how long can an emergency response (e.g., handling a chemical spill) be maintained before additional resources are required? What is the minimum acceptable response level (e.g., having a trained first responder on-site) and how long can that level be sustained? | Full response cannot be sustained for any meaningful time | Full response can be sustained only for a short period | Full response can be sustained for a moderate amount of time | Full response can be sustained for an extended period | Full response can be sustained indefinitely, or as long as needed |
| R8 | Stop rule | What criteria are used to determine when it is safe to resume normal operations after an incident (e.g., after machinery has been inspected post-accident or air quality has been verified post-gas leak)? | There are no defined criteria for stopping a response | Stop criteria are vague or inconsistently applied | Stop criteria exist but are not always followed or well understood | Stop criteria are clearly defined and generally followed | Stop criteria are well-defined, consistently applied, and understood by all employees |
| R9 | Response capability | What resources (e.g., personal protective equipment (PPE), fire suppression systems, spill control materials) are allocated to ensure readiness? How many workers are trained for OHS emergency responses, and who is responsible for maintaining this readiness (e.g., Safety Officers, OHS department)? | Resources are wholly inadequate | Resources are often insufficient to maintain readiness | Resources are adequate but stretched thin at times | Resources are mostly sufficient, with minor occasional limitations | Resources are fully adequate and consistently available for all OHS needs |
| R10 | Verification | How is OHS response readiness maintained (e.g., regular drills, inspections)? How often is readiness verified and by whom (e.g., through third-party safety audits, internal audits)? | Readiness is never or rarely verified | Readiness is verified occasionally but without consistency | Readiness is verified, but the process is incomplete or irregular | Readiness is regularly verified and mostly thorough | Readiness is systematically and consistently verified with comprehensive testing |
| Possible Answers | |||||||
|---|---|---|---|---|---|---|---|
| ID | Item | Question | 1 | 2 | 3 | 4 | 5 |
| M1 | Indicator list | How are safety performance indicators defined in the manufacturing context? Are they based on historical incident data, regulatory requirements (e.g., incident rates, near-miss reports), or industry best practices? | No indicators are defined | Indicators are poorly defined and lack relevance to OHS risks | Some indicators are well-defined, but important areas are missing | Most indicators are clearly defined and relevant to OHS risks | Indicators are comprehensively defined and fully relevant to all OHS risks |
| M2 | Relevance | When was the OHS indicator list created? Is it regularly updated based on audits, risk assessments, or changing legal requirements? Who is responsible for maintaining the list (e.g., the Safety Officer or Compliance Manager)? | The list is outdated and irrelevant | The list is mostly outdated with minimal relevance to current risks | The list is somewhat relevant but needs regular updates | The list is relevant and updated fairly regularly | The list is fully up-to-date and relevant, with a clear process for regular revisions |
| M3 | Indicator type | Are the OHS indicators leading (e.g., number of near-misses, safety training completion rates) or lagging (e.g., injury frequency, lost workdays)? Are they based on individual incidents or aggregated data from across multiple workstations or facilities? | Only lagging indicators are used | Mostly lagging indicators, with very few leading ones | A balance of leading and lagging indicators is present, but needs improvement | A strong balance between leading and lagging indicators is maintained | Leading and lagging indicators are fully integrated and balanced |
| M4 | Validity | How is the validity of OHS indicators ensured? Are they tied to an articulated risk management model (e.g., hazard identification and control) or just general safety guidelines? | Indicators lack validity and are not tied to any systematic model | Indicators have limited validity, often relying on assumptions | Some indicators are valid, but others are based on informal processes | Most indicators are valid and based on articulated OHS models | Indicators are fully valid, systematically derived from risk models or empirical data |
| M5 | Delay | What is the typical lag between a safety incident (e.g., injury, equipment malfunction) and the reporting of the corresponding indicator? Is the delay acceptable for timely corrective actions? | The delay is unacceptable and causes significant problems | The delay is too long and hampers corrective actions | The delay is manageable but should be improved | The delay is acceptable in most cases | The delay is minimal and fully acceptable for all indicators |
| M6 | Measurement type | Are OHS measurements qualitative (e.g., employee feedback on safety culture) or quantitative (e.g., incident rates, exposure levels)? If quantitative, what scales are used (e.g., accident severity scales)? | Measurements are exclusively qualitative with no quantifiable data | Measurements are mostly qualitative with minimal quantitative data | A mix of qualitative and quantitative measurements is used, but it’s inconsistent | Measurements are mostly quantitative, with some qualitative inputs | Measurements are systematically quantitative, with qualitative inputs where necessary |
| M7 | Measurement frequency | How often are safety indicators measured? Is it continuous (e.g., real-time monitoring of air quality or noise levels) or periodic (e.g., monthly safety audits)? | Measurements are rarely taken and are inconsistent | Measurements are taken occasionally but not regularly | Measurements are taken periodically, but not with enough frequency | Measurements are taken regularly and with sufficient frequency | Measurements are taken continuously or at very regular intervals, ensuring constant monitoring |
| M8 | Analysis/interpretation | What is the time gap between collecting safety data (e.g., incident reports) and analyzing them? How many indicators require deeper analysis (e.g., trend analysis of near-misses), and how are the results communicated to workers and management? | There is a significant delay between measurement and analysis | Analysis is slow and often incomplete | Analysis is timely but requires improvement for deeper insights | Analysis is timely and mostly effective | Analysis is prompt, thorough, and leads to actionable insights quickly |
| M9 | Stability | Are the measured safety effects temporary (e.g., reduced accidents during a safety campaign) or long-lasting (e.g., consistently low incident rates over years)? | The measured effects are highly transient and do not last | The effects are mostly transient with occasional lasting impacts | The effects are somewhat stable, but not consistently long-lasting | The effects are mostly stable and sustained over time | The effects are highly stable and consistently permanent |
| M10 | Organizational support | Is there a structured schedule for safety inspections (e.g., weekly equipment checks, quarterly safety audits)? Is there adequate resource allocation for ongoing monitoring (e.g., dedicated Safety Officers, budget for safety improvements)? | There is little to no support for OHS monitoring | The organization provides minimal support for OHS monitoring | There is some support, but it is inconsistent or insufficient | The organization provides adequate support, with room for improvement | The organization provides full and consistent support, ensuring the monitoring process is well-resourced and effective |
| Possible Answers | |||||||
|---|---|---|---|---|---|---|---|
| ID | Item | Question | 1 | 2 | 3 | 4 | 5 |
| L1 | Selection criteria | What types of OHS incidents or near-misses are investigated (e.g., only severe accidents or also near-misses)? What criteria (e.g., injury severity, frequency) are used for selecting cases for detailed investigation? | No clear criteria for selecting events to investigate | Events are rarely selected based on clear criteria | Events are sometimes selected based on frequency or severity, but inconsistently | Most events are selected for investigation based on relevant criteria | All OHS events are consistently selected based on well-defined and appropriate criteria |
| L2 | Learning basis | Does the organization learn from positive events (e.g., instances where employees avoided accidents through proper safety behavior) as well as negative ones (e.g., actual accidents)? | The system learns only from failures, never from successes | The system rarely learns from successes, primarily focusing on failures | The system sometimes learns from successes, but mostly from failures | The system often learns from both successes and failures | The system fully integrates learning from both successes and failures in a balanced manner |
| L3 | Classification | How are OHS incidents described, classified, and categorized (e.g., based on type of injury, location, equipment involved)? | There is no system for classifying or categorizing incidents | Incidents are rarely classified or categorized in a meaningful way | Incidents are classified inconsistently or with limited structure | Most incidents are systematically classified and categorized | All incidents are comprehensively described, classified, and categorized in a standardized manner |
| L4 | Formalization | Are there formal procedures for collecting, analyzing, and learning from OHS incidents (e.g., root cause analysis, safety debriefs)? | There are no formal procedures in place | Procedures are informal and inconsistently applied | Some formal procedures exist, but they are not always followed | Procedures are mostly formalized and followed | Fully formalized procedures are in place and consistently applied for all aspects of data collection and learning |
| L5 | Training | Is there formal training on how to collect and analyze safety data? Are employees and supervisors trained on how to apply lessons learned from past incidents? | There is no training provided | Training is minimal and insufficient | Some training is provided, but it needs improvement | Adequate training is provided, but with occasional gaps | Comprehensive and regular training is provided to all relevant staff, ensuring effective learning from incidents |
| L6 | Learning style | Is learning from safety incidents continuous (e.g., integrated into regular safety meetings) or only triggered by specific events (e.g., after a major accident)? | Learning only occurs after major incidents or accidents | Learning is mostly event-driven, with little focus on continuous improvement | Learning is a mix of event-driven and continuous, but mostly reactive | Learning is often continuous, with some event-driven elements | Learning is fully continuous and integrated into everyday practices |
| L7 | Resources | Are there adequate resources (e.g., dedicated investigation teams, software tools for incident tracking) allocated for investigating safety incidents and facilitating learning? | There are no dedicated resources for investigation and learning | Resources are very limited and inadequate | Resources are available but are often stretched too thin | Adequate resources are available, but occasional limitations occur | Resources are fully sufficient and consistently available for thorough investigation and learning |
| L8 | Delay | What is the delay between an incident and learning from it (e.g., how quickly are root causes identified, and corrective actions implemented)? How are the outcomes communicated internally (e.g., through safety bulletins) and externally (e.g., regulatory bodies)? | There is a significant delay that prevents timely learning | Delays are often too long to ensure effective learning | There are occasional delays, but learning is generally timely | The delay is minimal, and learning occurs in a timely manner | Learning happens promptly after every incident, with immediate analysis and corrective actions |
| L9 | Learning target | At what level does learning take place? Does it focus on individual workers, specific teams, or at the organizational level? | Learning rarely takes effect at any level | Learning mostly affects individuals, with little collective or organizational impact | Learning has some impact on teams or individuals, but limited organizational changes | Learning impacts both individuals and teams, with some organizational changes | Learning is systematically applied at the individual, team, and organizational levels |
| L10 | Implementation | How are lessons learned from OHS incidents implemented? Are they translated into revised safety procedures, updated training programs, or new workplace designs? | Lessons learned are rarely, if ever, implemented | Implementation of lessons learned is sporadic and ineffective | Lessons are sometimes implemented, but often inconsistently | Lessons learned are implemented effectively most of the time | Lessons learned are always implemented thoroughly and consistently across the organization, with clear impact on procedures and practices |
| Possible Answers | |||||||
|---|---|---|---|---|---|---|---|
| ID | Item | Question | 1 | 2 | 3 | 4 | 5 |
| A1 | Expertise | What kind of expertise is used to anticipate future OHS risks (e.g., in-house safety experts, external consultants)? Is expertise drawn from cross-industry practices, ergonomics, or specific manufacturing knowledge? | No expertise is used to anticipate future risks | Minimal expertise is available, and it is often insufficient | Expertise is available but is inconsistently applied or limited in scope | Expertise is mostly sufficient and appropriately applied | Expertise is fully sufficient, comprehensive, and consistently applied |
| A2 | Frequency | How often are future OHS threats (e.g., potential risks from new machinery, changes in production lines) assessed? | Future threats and opportunities are never assessed | Assessments are very rare and typically ad-hoc | Assessments are conducted occasionally, but not regularly | Assessments are conducted regularly, with some gaps | Future threats and opportunities are assessed frequently and systematically |
| A3 | Communication | How are forecasts of future OHS risks or opportunities (e.g., new safety technologies) communicated within the organization? | Expectations are never communicated | Communication of future risks is very poor and rarely reaches relevant parties | Communication occurs but is often unclear or inconsistent | Communication is mostly clear and reaches relevant stakeholders | Communication is always clear, consistent, and reaches all relevant stakeholders in a timely manner |
| A4 | Strategy | Does the organization have a clear safety vision or strategy for addressing future OHS risks (e.g., zero-accident policies, advanced automation for hazardous tasks)? | There is no strategy for future OHS risks | There is a very vague or informal strategy with minimal planning | There is a strategy, but it is incomplete or not well formulated | The strategy is well-formulated and mostly clear, with minor gaps | The organization has a clearly formulated and comprehensive strategy for addressing future OHS risks |
| A5 | Model | Is the safety strategy or model of future OHS risks explicitly defined (e.g., through formal risk assessments), and is it qualitative (e.g., expert judgment) or quantitative (e.g., risk probability models)? | There is no explicit model or assumptions about future risks | Models are mostly implicit and qualitative, with little structure | Models are somewhat explicit but lack thoroughness, primarily qualitative | Models are explicit and reasonably detailed, often blending qualitative and quantitative elements | Models are fully explicit, highly detailed, and include both qualitative and quantitative aspects |
| A6 | Time horizon | How far ahead does the system look in terms of OHS risk anticipation? Does this vary between business goals (e.g., production targets) and safety priorities? | No forward-looking assessments are made | The time horizon is very short (e.g., only a few months) | The time horizon is moderate (e.g., 1–2 years), but may not account for long-term risks | The time horizon is substantial (e.g., 3–5 years), with good planning for future risks | The organization looks far ahead (5+ years), with comprehensive risk assessments for the long-term future |
| A7 | Acceptability of risks | What criteria are used to determine which OHS risks are acceptable (e.g., minor injuries) and which are not (e.g., fatalities, permanent disabilities)? | No distinction is made between acceptable and unacceptable risks | The definition of acceptable risks is vague or inconsistently applied | Some criteria exist for defining acceptable risks, but they are incomplete | Acceptable and unacceptable risks are mostly well defined and understood | There are clear, well-documented criteria for distinguishing acceptable and unacceptable risks, consistently applied across the organization |
| A8 | Aetiology | How does the organization define the nature of future OHS threats? Are they seen as inherent to the manufacturing process (e.g., machinery risks) or as preventable through better safety controls? | The nature of future threats is not anticipated at all | Future threats and opportunities are anticipated in a very limited and reactive way | Some effort is made to anticipate future threats, but the approach is incomplete | The organization mostly anticipates the nature of future threats and opportunities in a proactive way | The organization systematically anticipates and plans for future OHS threats and opportunities with a proactive approach |
| A9 | Culture | Is there a strong culture of risk awareness in the organization? Do employees actively contribute to risk assessments and proactive safety measures? | Risk awareness is not part of the culture at all | Risk awareness is minimal and rarely encouraged within the organization | Risk awareness is present but not consistently reinforced across the organization | Risk awareness is a part of the culture and generally reinforced in most areas | Risk awareness is fully embedded in the organizational culture and actively promoted at all levels |
Appendix B
OHS RAG Questionnaire Original Socratic Dialogue
- Understanding the Task—Analyze and contextualize the initial framework.
- Contextualization of Framework—Adapt questions for OHS in manufacturing.
- Creation of Measurement Tools—Develop Likert scales for assessment.
- Synthetic Data Generation—Generate data using RAG scoring.
- Feedback Iteration and Refinement—Incorporate user feedback to improve the process.
References
- Koc, K.; Gurgun, A.P. Scenario-Based Automated Data Preprocessing to Predict Severity of Construction Accidents. Autom. Constr. 2022, 140, 104351. [Google Scholar] [CrossRef]
- Tsalidis, G.A. Introducing the Occupational Health and Safety Potential Midpoint Impact Indicator in Social Life Cycle Assessment. Sustainability 2024, 16, 3844. [Google Scholar] [CrossRef]
- Stepanovic, S.; Naous, D.; Mettler, T. A Privacy Impact Assessment Method for Organizations Implementing IoT for Occupational Health and Safety. 2023. Available online: https://aisel.aisnet.org/icis2023/ishealthcare/ishealthcare/14/ (accessed on 11 November 2024).
- Bond, T.G.; Fox, C.M. Applying the Rasch Model; Psychology Press: London, UK, 2013; ISBN 978-1-135-60265-9. [Google Scholar]
- Adriaensen, A.; Costantino, F.; Di Gravio, G.; Patriarca, R. Teaming with Industrial Cobots: A Socio-Technical Perspective on Safety Analysis. Hum. Factors Ergon. Manuf. Serv. Ind. 2022, 32, 173–198. [Google Scholar] [CrossRef]
- Rodríguez, M.; Lawson, E.; Butler, D. A Study of the Resilience Analysis Grid Method and Its Applicability to the Water Sector in England and Wales. Water Environ. J. 2020, 34, 623–633. [Google Scholar] [CrossRef]
- Duros, S.E. Supporting Resilience in Distributed Work Systems through Modeling Adaptive Capacity. 2022. Available online: https://rave.ohiolink.edu (accessed on 11 November 2024).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Hellwig, N.C.; Fehle, J.; Wolff, C. Exploring Large Language Models for the Generation of Synthetic Training Samples for Aspect-Based Sentiment Analysis in Low Resource Settings. Expert Syst. Appl. 2025, 261, 125514. [Google Scholar] [CrossRef]
- Zhao, F.; Yu, F.; Trull, T.; Shang, Y. A New Method Using LLMs for Keypoints Generation in Qualitative Data Analysis. In Proceedings of the 2023 IEEE Conference on Artificial Intelligence (CAI), Santa Clara, CA, USA, 5–6 June 2023; pp. 333–334. [Google Scholar]
- Kalyniukova, A.; Várfalvyová, A.; Andruch, V. Applicability of ChatGPT 3.5 in the Development of New Analytical Procedures. Microchem. J. 2024, 203, 110787. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Shah, I.A.; Mishra, S. Artificial Intelligence in Advancing Occupational Health and Safety: An Encapsulation of Developments. J. Occup. Health 2024, 66, uiad017. [Google Scholar] [CrossRef]
- Tang, K.H.D. Artificial Intelligence in Occupational Health and Safety Risk Management of Construction, Mining, and Oil and Gas Sectors: Advances and Prospects. J. Eng. Res. Rep. 2024, 26, 241–253. [Google Scholar] [CrossRef]
- Linkon, A.A.; Shaima, M.; Sarker, M.S.U.; Nabi, N.; Rana, M.N.U.; Ghosh, S.K.; Rahman, M.A.; Esa, H.; Chowdhury, F.R. Advancements and Applications of Generative Artificial Intelligence and Large Language Models on Business Management: A Comprehensive Review. J. Comput. Sci. Technol. Stud. 2024, 6, 225–232. [Google Scholar] [CrossRef]
- Taiwo, R.; Bello, I.T.; Abdulai, S.F.; Yussif, A.-M.; Salami, B.A.; Saka, A.; Zayed, T. Generative AI in the Construction Industry: A State-of-the-Art Analysis. arXiv 2024, arXiv:2402.09939. [Google Scholar]
- Lu, Y.; Shen, M.; Wang, H.; Wang, X.; van Rechem, C.; Fu, T.; Wei, W. Machine Learning for Synthetic Data Generation: A Review. arXiv 2023, arXiv:2302.04062. [Google Scholar]
- Maheronnaghsh, S.; Zolfagharnasab, H.; Gorgich, M.; Duarte, J. Machine Learning in Occupational Safety and Health: Protocol for a Systematic Review: (Protocol). Int. J. Occup. Environ. Saf. 2021, 5, 32–38. [Google Scholar] [CrossRef]
- Guo, X.; Chen, Y. Generative AI for Synthetic Data Generation: Methods, Challenges and the Future. arXiv 2024, arXiv:2403.04190. [Google Scholar]
- Quadir, A.; Lewis, C.; Rau, R.-J. Generation of Pseudo-Synthetic Seismograms from Gamma-Ray Well Logs of Highly Radioactive Formations. Pure Appl. Geophys. 2019, 176, 1579–1599. [Google Scholar] [CrossRef]
- Vaccari, C.; Chadwick, A. Deepfakes and Disinformation: Exploring the Impact of Synthetic Political Video on Deception, Uncertainty, and Trust in News. Soc. Media + Soc. 2020, 6, 2056305120903408. [Google Scholar] [CrossRef]
- Loiseau, T.; Vu, T.-H.; Chen, M.; Pérez, P.; Cord, M. Reliability in Semantic Segmentation: Can We Use Synthetic Data? In Computer Vision—ECCV 2024; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Lecture Notes in Computer Science; Springer Nature: Cham, Switzerland, 2025; Volume 15081, pp. 442–459. ISBN 978-3-031-73336-9. [Google Scholar]
- Johannesson, P.; Perjons, E. An Introduction to Design Science; Springer International Publishing: Cham, Switzerland, 2021; ISBN 978-3-030-78131-6. [Google Scholar]
- Galli, C.; Cusano, C.; Meleti, M.; Donos, N.; Calciolari, E. Topic Modeling for Faster Literature Screening Using Transformer-Based Embeddings. Metrics 2024, 1, 2. [Google Scholar] [CrossRef]
- Sturm, B.; Sunyaev, A. Design Principles for Systematic Search Systems: A Holistic Synthesis of a Rigorous Multi-Cycle Design Science Research Journey. Bus. Inf. Syst. Eng. 2019, 61, 91–111. [Google Scholar] [CrossRef]
- Pishgar, M.; Issa, S.F.; Sietsema, M.; Pratap, P.; Darabi, H. REDECA: A Novel Framework to Review Artificial Intelligence and Its Applications in Occupational Safety and Health. Int. J. Environ. Res. Public Health 2021, 18, 6705. [Google Scholar] [CrossRef]
- Akoka, J.; Comyn-Wattiau, I.; Prat, N.; Storey, V.C. Knowledge Contributions in Design Science Research: Paths of Knowledge Types. Decis. Support Syst. 2023, 166, 113898. [Google Scholar] [CrossRef]
- Falegnami, A.; Romano, E.; Tomassi, A. The Emergence of the GreenSCENT Competence Framework: A Constructivist Approach: The GreenSCENT Theory. In The European Green Deal in Education; Routledge: London, UK, 2024; ISBN 978-1-00-349259-7. [Google Scholar]
- Tomassi, A.; Falegnami, A.; Romano, E. Mapping Automatic Social Media Information Disorder. The Role of Bots and AI in Spreading Misleading Information in Society. PLoS ONE 2024, 19, e0303183. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Cai, Z.; Jiang, Z.; Sun, L.; Childs, P.; Zuo, H. A Knowledge Graph-Based Bio-Inspired Design Approach for Knowledge Retrieval and Reasoning. J. Eng. Des. 2024, 35, 1–31. [Google Scholar] [CrossRef]
- Falegnami, A.; Tomassi, A.; Corbelli, G.; Romano, E. Managing Complexity in Socio-Technical Systems by Mimicking Emergent Simplicities in Nature: A Brief Communication. Biomimetics 2024, 9, 322. [Google Scholar] [CrossRef] [PubMed]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.; Rocktäschel, T. Retrieval-Augmented Generation for Knowledge-Intensive Nlp Tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Ampazis, N. Improving RAG Quality for Large Language Models with Topic-Enhanced Reranking. In Artificial Intelligence Applications and Innovations; Maglogiannis, I., Iliadis, L., Macintyre, J., Avlonitis, M., Papaleonidas, A., Eds.; IFIP Advances in Information and Communication Technology; Springer Nature: Cham, Switzerland, 2024; Volume 712, pp. 74–87. ISBN 978-3-031-63214-3. [Google Scholar]
- Exploring TITAN’s Approach to Integrating Socratic Thinking and AI in Chatbot Dialogue. Available online: https://www.titanthinking.eu/post/exploring-titan-s-approach-to-integrating-socratic-thinking-and-ai-in-chatbot-dialogue (accessed on 13 November 2024).
- Flynn, B.B.; Sakakibara, S.; Schroeder, R.G.; Bates, K.A.; Flynn, E.J. Empirical Research Methods in Operations Management. J. Oper. Manag. 1990, 9, 250–284. [Google Scholar] [CrossRef]
- Hollnagel, E. Safety-II in Practice: Developing the Resilience Potentials; Routledge: London, UK, 2017; ISBN 978-1-351-78076-6. [Google Scholar]
- Hollnagel, E. Epilogue: RAG—The Resilience Analysis Grid. In Resilience Engineering in Practice; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Winzar, H. LikertMakeR: Synthesise and Correlate Rating-Scale Data with Predefined First & Second Moments; 2022, 0.4.0. Available online: https://github.com/WinzarH/LikertMakeR (accessed on 11 November 2024).


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Falegnami, A.; Tomassi, A.; Corbelli, G.; Nucci, F.S.; Romano, E. A Generative Artificial-Intelligence-Based Workbench to Test New Methodologies in Organisational Health and Safety. Appl. Sci. 2024, 14, 11586. https://doi.org/10.3390/app142411586
Falegnami A, Tomassi A, Corbelli G, Nucci FS, Romano E. A Generative Artificial-Intelligence-Based Workbench to Test New Methodologies in Organisational Health and Safety. Applied Sciences. 2024; 14(24):11586. https://doi.org/10.3390/app142411586
Chicago/Turabian StyleFalegnami, Andrea, Andrea Tomassi, Giuseppe Corbelli, Francesco Saverio Nucci, and Elpidio Romano. 2024. "A Generative Artificial-Intelligence-Based Workbench to Test New Methodologies in Organisational Health and Safety" Applied Sciences 14, no. 24: 11586. https://doi.org/10.3390/app142411586
APA StyleFalegnami, A., Tomassi, A., Corbelli, G., Nucci, F. S., & Romano, E. (2024). A Generative Artificial-Intelligence-Based Workbench to Test New Methodologies in Organisational Health and Safety. Applied Sciences, 14(24), 11586. https://doi.org/10.3390/app142411586