
Optimization and Application of Improved YOLOv9s-UI for Underwater Object Detection


Abstract
1. Introduction
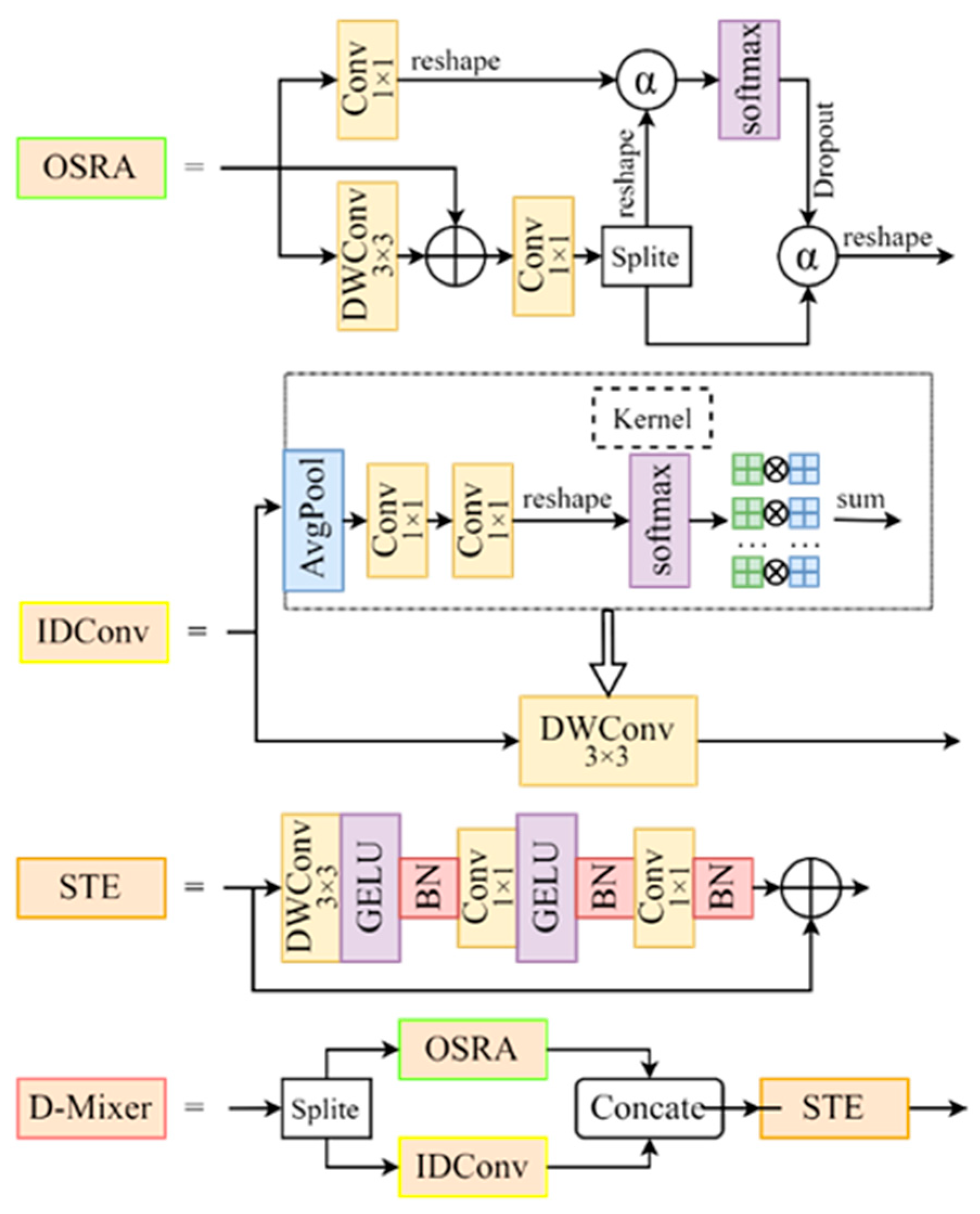
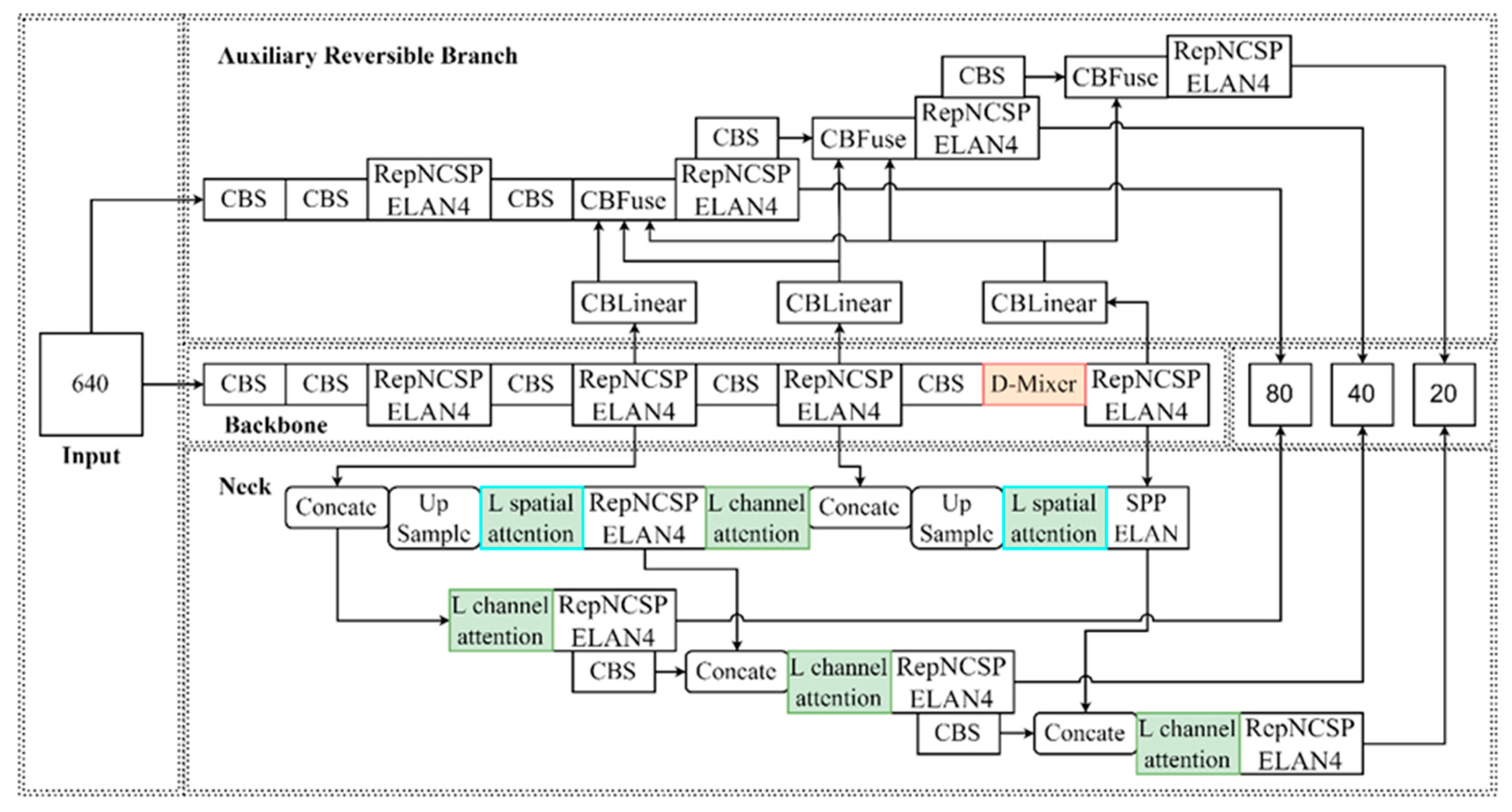
- Integration of the D-Mixer module from TransXNet: This improvement dynamically adjusts token distribution during feature extraction, significantly improving target recognition capabilities in complex underwater environments.
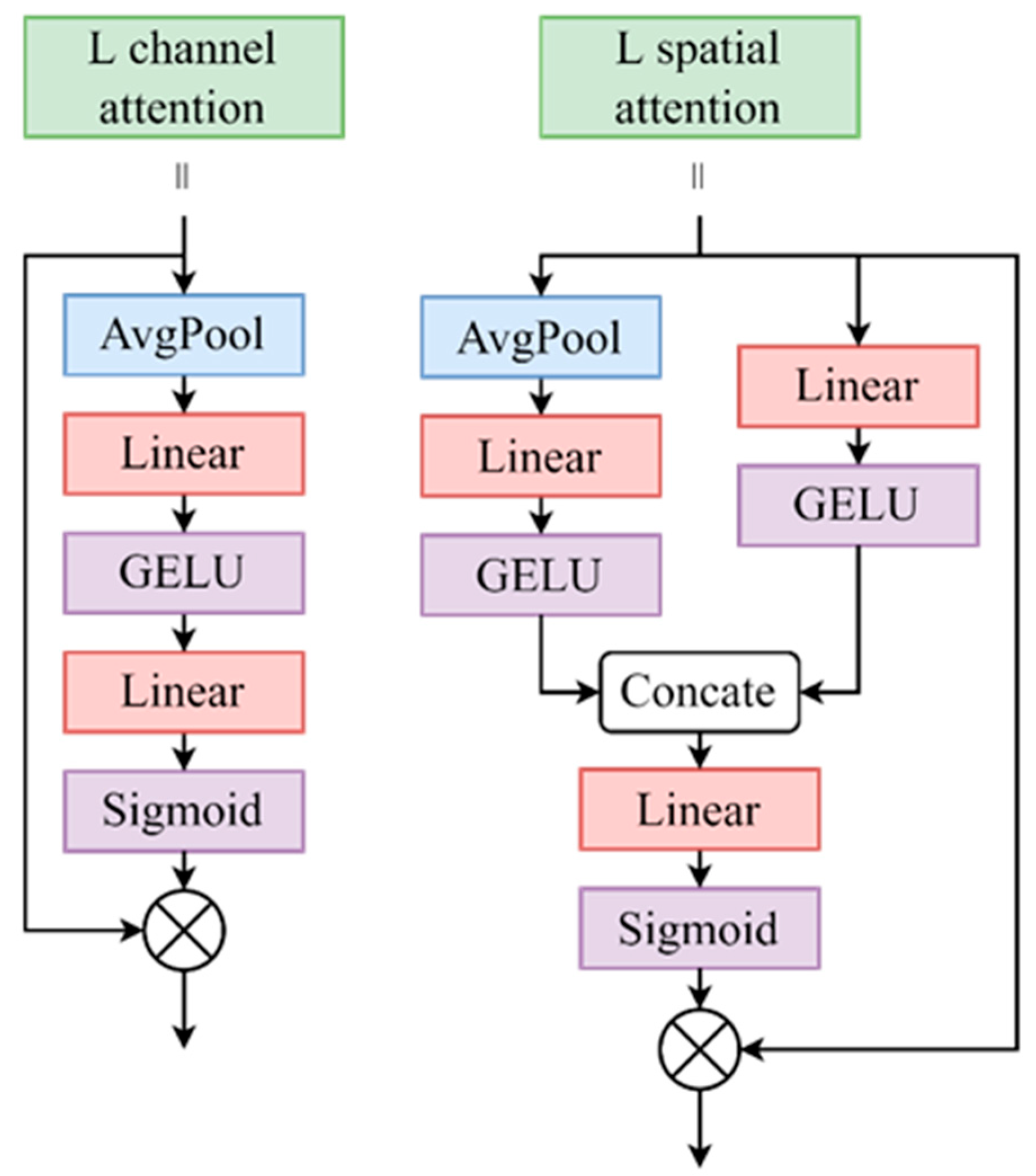
- Design of a network featuring channel and spatial attention: The channel attention module and spatial attention module independently improve the significance of different feature channels and spatial positions within the feature maps. This guided feature fusion process significantly improves detection accuracy.
- Model lightweighting: Despite the incorporation of multiple improvement modules, the model maintains a compact total weight of only 9.3 M, ensuring both efficiency and portability.
2. Related Works
2.1. Underwater Object Detection Methods
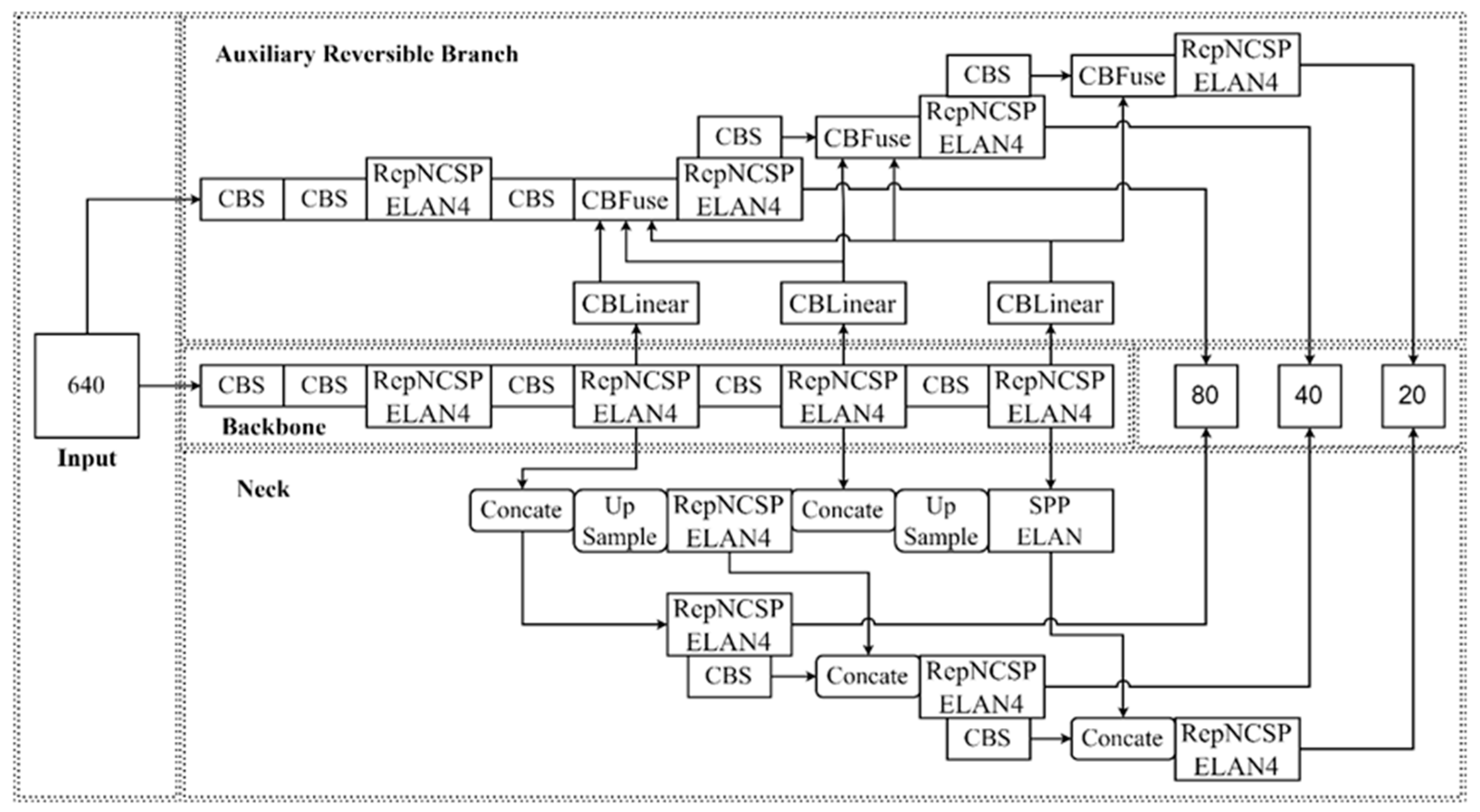
2.2. YOLOv9 Object Detection Network
2.3. D-Mixer
3. Methods
3.1. Local Channel Attention and Local Spatial Attention
3.2. YOLOv9s-UI Network Model
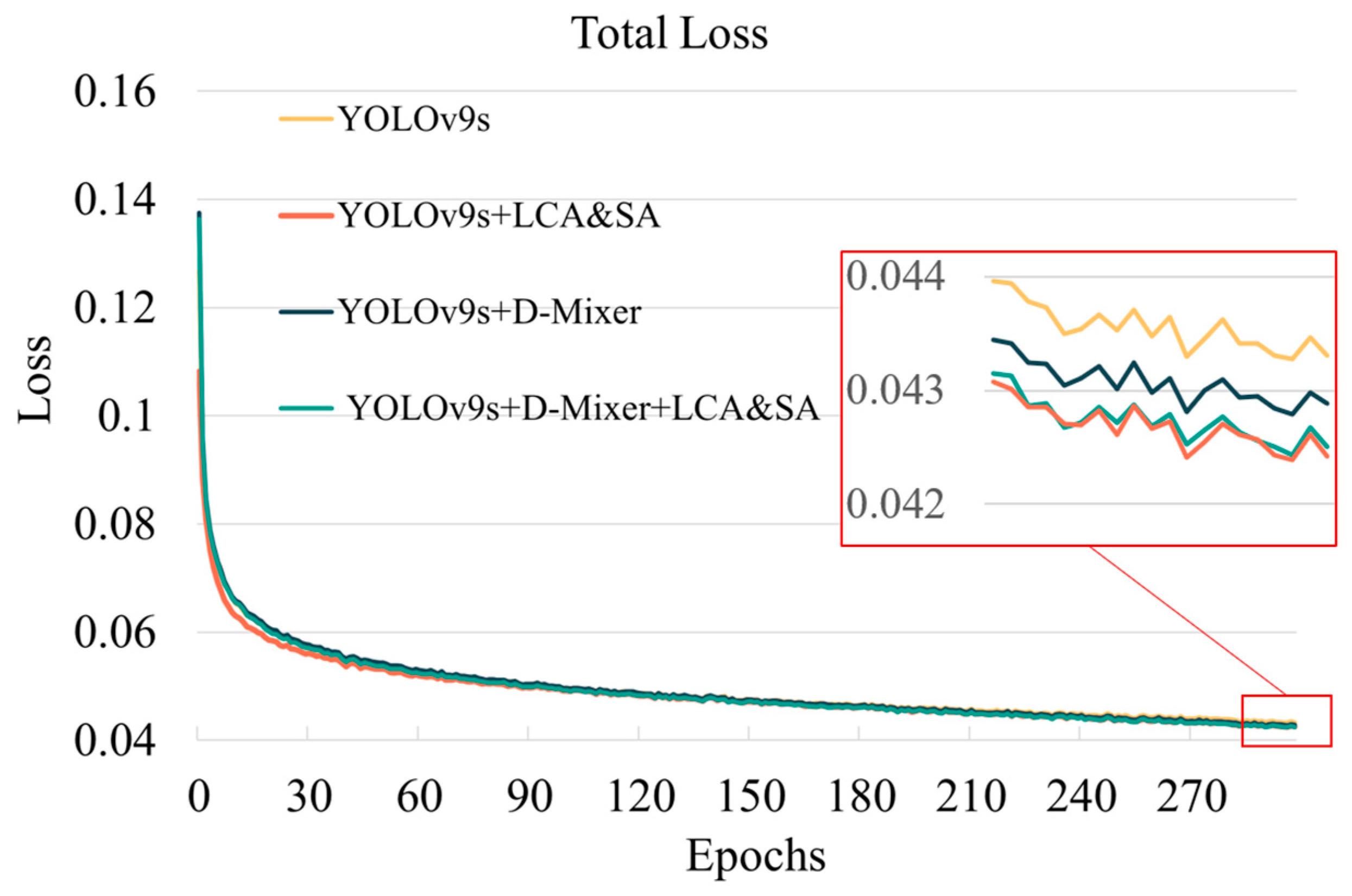
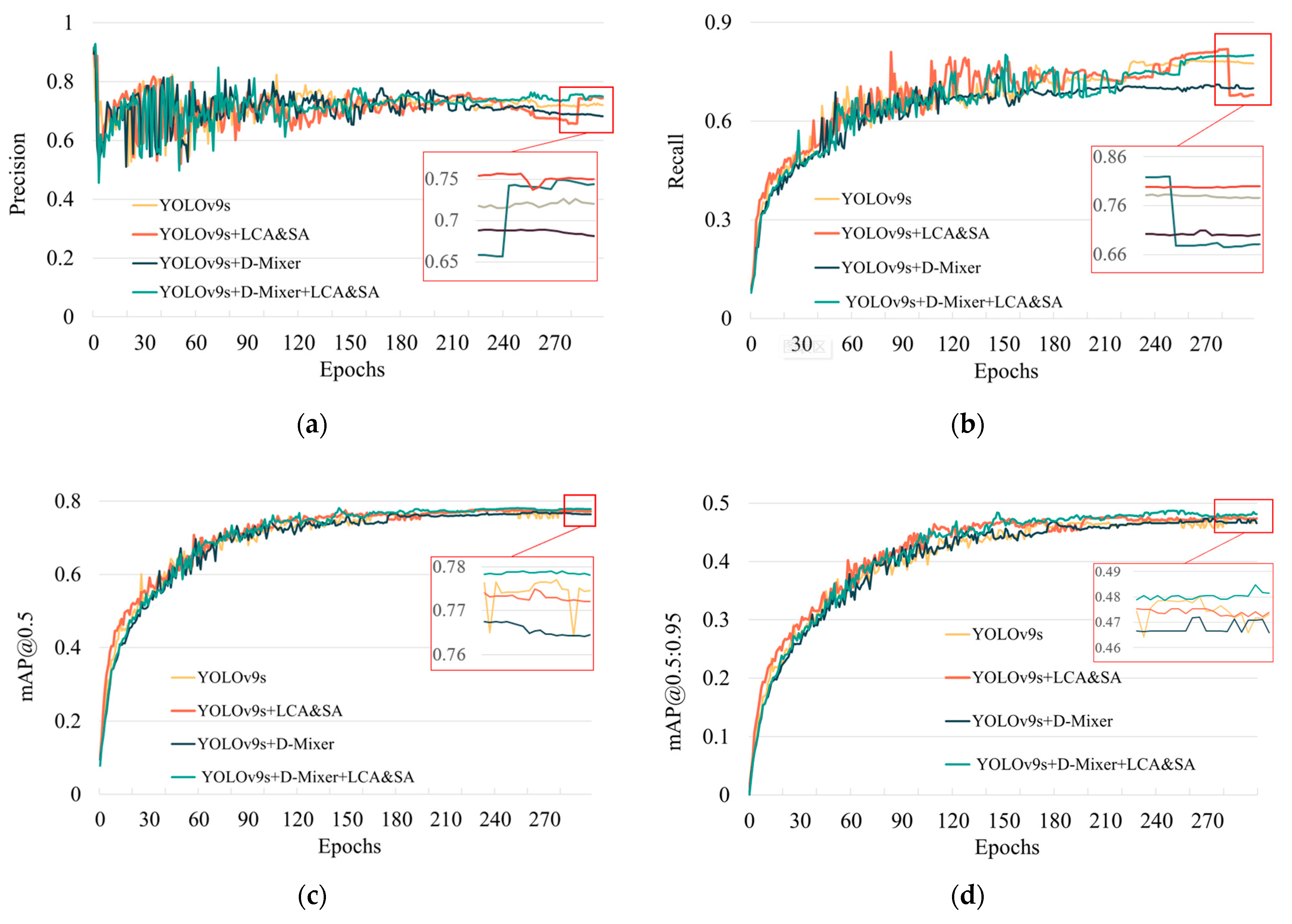
4. Experimental Results
4.1. Experimental Setup and Data
4.2. Evaluation Metrics
4.3. Experimental Setup
4.4. Comparison of Model
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Redmon, J.; Farhadi, A. YOlOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOlOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Fu, C.; Liu, R.; Fan, X.; Chen, P.; Fu, H.; Yuan, W.; Zhu, M.; Luo, Z. Rethinking general underwater object detection: Datasets, challenges, and solutions. Neurocomputing 2023, 517, 243–256. [Google Scholar] [CrossRef]
- Fayaz, S.; Parah, S.A.; Qureshi, G.J. Underwater object detection: Architectures and algorithms–a comprehensive review. Multimed. Tools Appl. 2022, 81, 20871–20916. [Google Scholar] [CrossRef]
- Awalludin, E.A.; Arsad, T.N.T.; Yussof, W.N.J.H.W.; Bachok, Z.; Hitam, M.S. A comparative study of various edge detection techniques for underwater images. J. Telecommun. Inf. Technol. 2022. [Google Scholar] [CrossRef]
- Song, S.; Zhu, J.; Li, X.; Huang, Q. Integrate MSRCR and mask R-CNN to recognize underwater creatures on small sample datasets. IEEE Access 2020, 8, 172848–172858. [Google Scholar] [CrossRef]
- Zeng, L.; Sun, B.; Zhu, D. Underwater target detection based on Faster R-CNN and adversarial occlusion network. Eng. Appl. Artif. Intell. 2021, 100, 104190. [Google Scholar] [CrossRef]
- Saini, A.; Biswas, M. Object detection in underwater image by detecting edges using adaptive thresholding. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Yuan, X.; Guo, L.; Luo, C.; Zhou, X.; Yu, C. A survey of target detection and recognition methods in underwater turbid areas. Appl. Sci. 2022, 12, 4898. [Google Scholar] [CrossRef]
- Fatan, M.; Daliri, M.R.; Shahri, A.M. Underwater cable detection in the images using edge classification based on texture information. Measurement 2016, 91, 309–317. [Google Scholar] [CrossRef]
- Lin, Y.-H.; Chen, S.-Y.; Tsou, C.-H. Development of an image processing module for autonomous underwater vehicles through integration of visual recognition with stereoscopic image reconstruction. J. Mar. Sci. Eng. 2019, 7, 107. [Google Scholar] [CrossRef]
- Mandal, R.; Connolly, R.M.; Schlacher, T.A.; Stantic, B. Assessing fish abundance from underwater video using deep neural networks. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Sung, M.; Yu, S.-C.; Girdhar, Y. Vision based real-time fish detection using convolutional neural network. In Proceedings of the OCEANS 2017-Aberdeen, Aberdeen, UK, 19–22 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Hu, X.; Liu, Y.; Zhao, Z.; Liu, J.; Yang, X.; Sun, C.; Chen, S.; Li, B.; Zhou, C. Real-time detection of uneaten feed pellets in underwater images for aquaculture using an improved yolo-v4 network. Comput. Electron. Agric. 2021, 185, 106135. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Y.; Sun, X.; Liu, J.; Yang, X.; Zhou, C. Composited fishnet: Fish detection and species recognition from low-quality under-water videos. IEEE Trans. Image Process. 2021, 30, 4719–4734. [Google Scholar] [CrossRef] [PubMed]
- Er, M.J.; Chen, J.; Zhang, Y.; Gao, W. Research challenges, recent advances, and popular datasets in deep learning-based underwater marine object detection: A review. Sensors 2023, 23, 1990. [Google Scholar] [CrossRef] [PubMed]
- Xu, S.; Zhang, M.; Song, W.; Mei, H.; He, Q.; Liotta, A. A systematic review and analysis of deep learning-based underwater object detection. Neurocomputing 2023, 527, 204–232. [Google Scholar] [CrossRef]
- Yeh, C.H.; Lin, C.H.; Kang, L.W.; Huang, C.H.; Lin, M.H.; Chang, C.Y.; Wang, C.C. Lightweight deep neural network for joint learning of underwater object detection and color conversion. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6129–6143. [Google Scholar] [CrossRef]
- Han, F.; Yao, J.; Zhu, H.; Wang, C. Underwater image processing and object detection based on deep CNN method. J. Sens. 2020, 2020, 6707328. [Google Scholar] [CrossRef]
- Zhang, J.; Peng, X.; Zhang, G. Using Improved YOLOX for Underwater Object Recognition. In Proceedings of the 2022 5th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Chengdu, China, 19–21 August 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Hou, J.; Zhang, C. Shallow mud detection algorithm for submarine channels based on improved YOLOv5s. Heliyon 2024, 10, e31029. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Jiao, P. YOLO series target detection algorithms for underwater environments. arXiv, 2023; arXiv:2309.03539. [Google Scholar]
- Yang, Y.; Chen, L.; Zhang, J.; Long, L.; Wang, Z. UGC-YOLO: Underwater environment object detection based on YOLO with a global context block. J. Ocean. Univ. China 2023, 22, 665–674. [Google Scholar] [CrossRef]
- Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight underwater object detection based on yolo v4 and multi-scale attentional feature fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Jia, J.; Fu, M.; Liu, X.; Zheng, B. Underwater object detection based on improved efficientDet. Remote Sens. 2022, 14, 4487. [Google Scholar] [CrossRef]
- Yuan, S.; Luo, X.; Xu, R. Underwater Robot Target Detection Based On Improved YOLOv5 Network. In Proceedings of the 2024 12th International Conference on Intelligent Control and Information Processing (ICICIP), Nanjing, China, 8–10 March 2024; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Lou, M.; Zhou, H.Y.; Yang, S.; Yu, Y. TransXNet: Learning both global and local dynamics with a dual dynamic token mixer for visual recognition. arXiv 2023, arXiv:2310.19380. [Google Scholar]
- Xu, R.; Yang, S.; Wang, Y.; Du, B.; Chen, H. A survey on vision mamba: Models, applications and challenges. arXiv 2024, arXiv:2404.18861. [Google Scholar]
- Zhu, J.; Yu, S.; Han, Z.; Tang, Y.; Wu, C. Underwater object recognition using transformable template matching based on prior knowledge. Math. Probl. Eng. 2019, 2019, 2892975. [Google Scholar] [CrossRef]
- Chen, R.; Zhan, S.; Chen, Y. Underwater target detection algorithm based on YOLO and Swin transformer for sonar images. In Proceedings of the OCEANS 2022, Hampton Roads, VA, USA, 17–20 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–7. [Google Scholar]
- Qiang, W.; He, Y.; Guo, Y.; Li, B.; He, L. Exploring underwater target detection algorithm based on improved SSD. Xibei Gongye Daxue Xuebao/J. Northwestern Polytech. Univ. 2020, 38, 747–754. [Google Scholar] [CrossRef]
- Jiang, X.; Zhuang, X.; Chen, J.; Zhang, J.; Zhang, Y. YOLOv8-MU: An Improved YOLOv8 Underwater Detector Based on a Large Kernel Block and a Multi-Branch Reparameterization Module. Sensors 2024, 24, 2905. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. ISBN 978-3-319-46448-0. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Zhang, X.; Wan, F.; Liu, C.; Ji, X.; Ye, Q. Learning to Match Anchors for Visual Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3096–3109. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Ahmed, I.; Ahmad, M.; Rodrigues, J.J.P.C.; Jeon, G. Edge Computing-Based Person Detection System for Top View Surveillance: Using CenterNet with Transfer Learning. Appl. Soft Comput. 2021, 107, 107489. [Google Scholar] [CrossRef]
- Zhang, J.; Yan, X.; Zhou, K.; Zhao, B.; Zhang, Y.; Jiang, H.; Chen, H.; Zhang, J. Marine Organism Detection Based on Double Domains Augmentation and an Improved YOLOv7. IEEE Access 2023, 11, 68836–68852. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Num | Train | Valid | Test | mAP@0.5 (%) |
|---|---|---|---|---|---|
| Faster R-CNN (VGG16) | 4757 | 3805 | 0 | 952 | 66.5 |
| SSD (VGG16) | 4757 | 3805 | 0 | 952 | 70.2 |
| FCOS (ResNet50) | 4757 | 3805 | 0 | 952 | 72.3 |
| Faster R-CNN (ResNet50) | 4757 | 3805 | 0 | 952 | 73.2 |
| FreeAnchor (ResNet50) | 4757 | 3805 | 0 | 952 | 74.8 |
| EfficientDet | 4757 | 3805 | 0 | 952 | 74.8 |
| CenterNet (ResNet50) | 4757 | 3805 | 0 | 952 | 76.1 |
| YOLOv8n | 4707 | 3765 | 0 | 942 | 86.1 |
| DDA + YOLOv7-ACmix | 4707 | 3765 | 0 | 942 | 87.2 |
| YOLOv8-MU | 4707 | 3765 | 0 | 942 | 88.1 |
| Baseline | D-Mixer | Local CA&SA | Precision (%) | Recall (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) |
|---|---|---|---|---|---|---|
| YOLOv9 | × | × | - | - | - | - |
| YOLOv9s | × | × | 72.62 | 78.51 | 77.79 | 48.01 |
| √ | × | 74.92 | 81.91 | 77.65 | 47.66 | |
| × | √ | 69.47 | 75.11 | 77.10 | 47.37 | |
| √ | √ | 75.68 | 80.20 | 78.12 | 48.74 |
| Class | YOLOv9s | YOLOv9s-UI |
|---|---|---|
| Sea cucumber |  |  |
| Echinus (Sea urchin) | 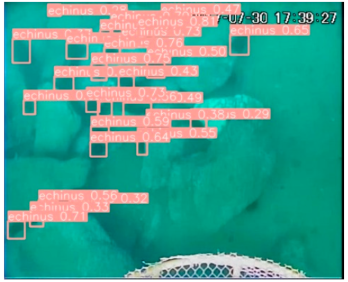 | 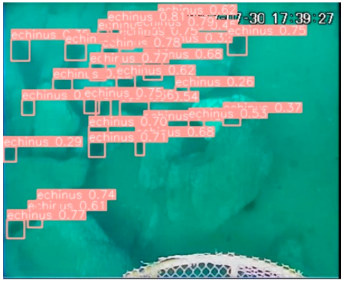 |
| Scallop |  |  |
| Starfish |  |  |
| Aquatic plants |  |  |
| Baseline | D-Mixer | Local CA&SA | Misidentification | Accuracy (%) | FPS | Inference Time (ms) |
|---|---|---|---|---|---|---|
| YOLOv9 | × | × | - | - | - | - |
| YOLOv9s | × | × | 126 | 73.19 | 32.97 | 14,254 |
| √ | × | 123 | 73.83 | 32.56 | 14,437 | |
| × | √ | 140 | 70.21 | 32.33 | 14,537 | |
| √ | √ | 112 | 76.17 | 32.25 | 14,573 |
| Baseline | D-Mixer | Local CA&SA | Layers | Parameter Quantity | Mode Size/MB | FLOPs/G |
|---|---|---|---|---|---|---|
| YOLOv9 | × | × | 727 | 60,512,080 | 122.4 | 264.0 |
| YOLOv9s | × | × | 727 | 4,223,998 | 9.1 | 18.4 |
| √ | × | 751 | 4,247,566 | 9.2 | 18.5 | |
| × | √ | 771 | 4,298,552 | 9.3 | 18.5 | |
| √ | √ | 779 | 4,308,934 | 9.3 | 18.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, W.; Chen, J.; Lv, B.; Peng, L. Optimization and Application of Improved YOLOv9s-UI for Underwater Object Detection. Appl. Sci. 2024, 14, 7162. https://doi.org/10.3390/app14167162
Pan W, Chen J, Lv B, Peng L. Optimization and Application of Improved YOLOv9s-UI for Underwater Object Detection. Applied Sciences. 2024; 14(16):7162. https://doi.org/10.3390/app14167162
Chicago/Turabian StylePan, Wei, Jiabao Chen, Bangjun Lv, and Likun Peng. 2024. "Optimization and Application of Improved YOLOv9s-UI for Underwater Object Detection" Applied Sciences 14, no. 16: 7162. https://doi.org/10.3390/app14167162
APA StylePan, W., Chen, J., Lv, B., & Peng, L. (2024). Optimization and Application of Improved YOLOv9s-UI for Underwater Object Detection. Applied Sciences, 14(16), 7162. https://doi.org/10.3390/app14167162