
Image Deraining Algorithm Based on Multi-Scale Features




Abstract
1. Introduction
- (1)
- Diversity of rain. Influenced by a variety of factors such as shape, size, and wind speed, rainwater has a variety of forms and characteristics. If the actual rain features are not consistent with the model presets, the effectiveness of this model will be affected.
- (2)
- Pairs of images with and without rain are difficult to obtain. Existing models are effective on synthetic datasets, but it is difficult to take paired no-rain and rain images in the real world, and the synthetic rain images are still different compared to the real rain images.
- (3)
- The generalization ability of the model needs to be improved. Currently, synthetic rain images are mainly used to train and evaluate the model, however, there are differences between synthetic rain images and real rain images. This may not be effective when dealing with irregular or dense rain in natural environments.
2. Related Work
2.1. Model-Based Rain Removal Method
2.2. Rain Removal Method Based on Supervised Learning
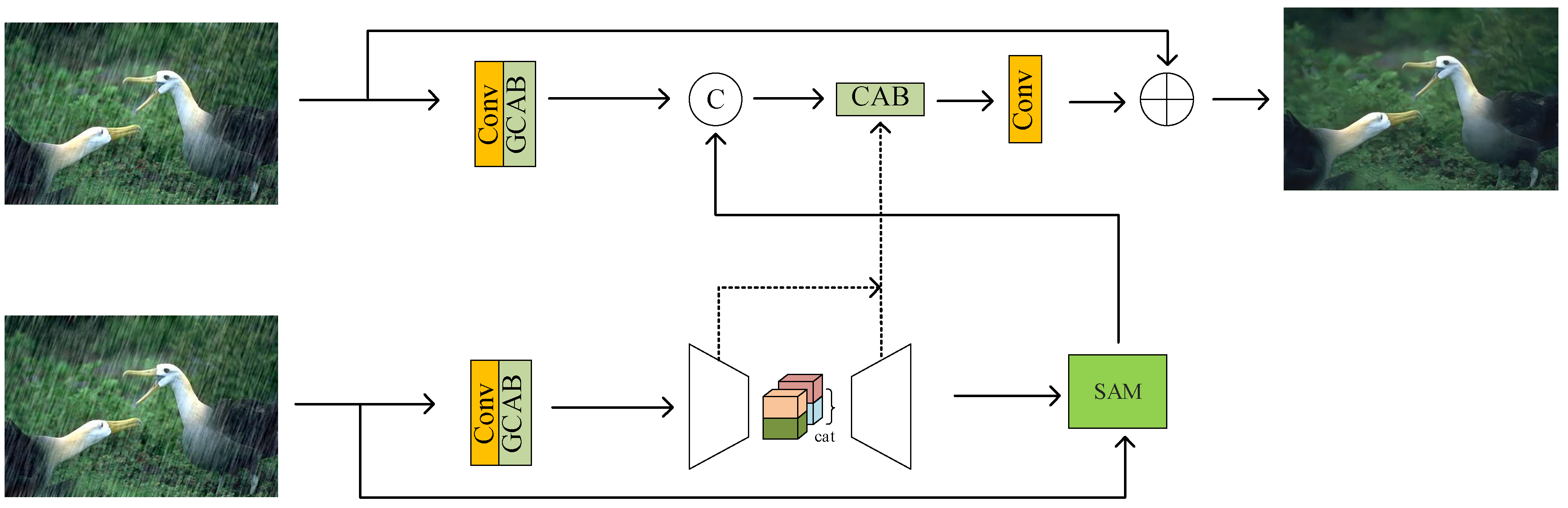
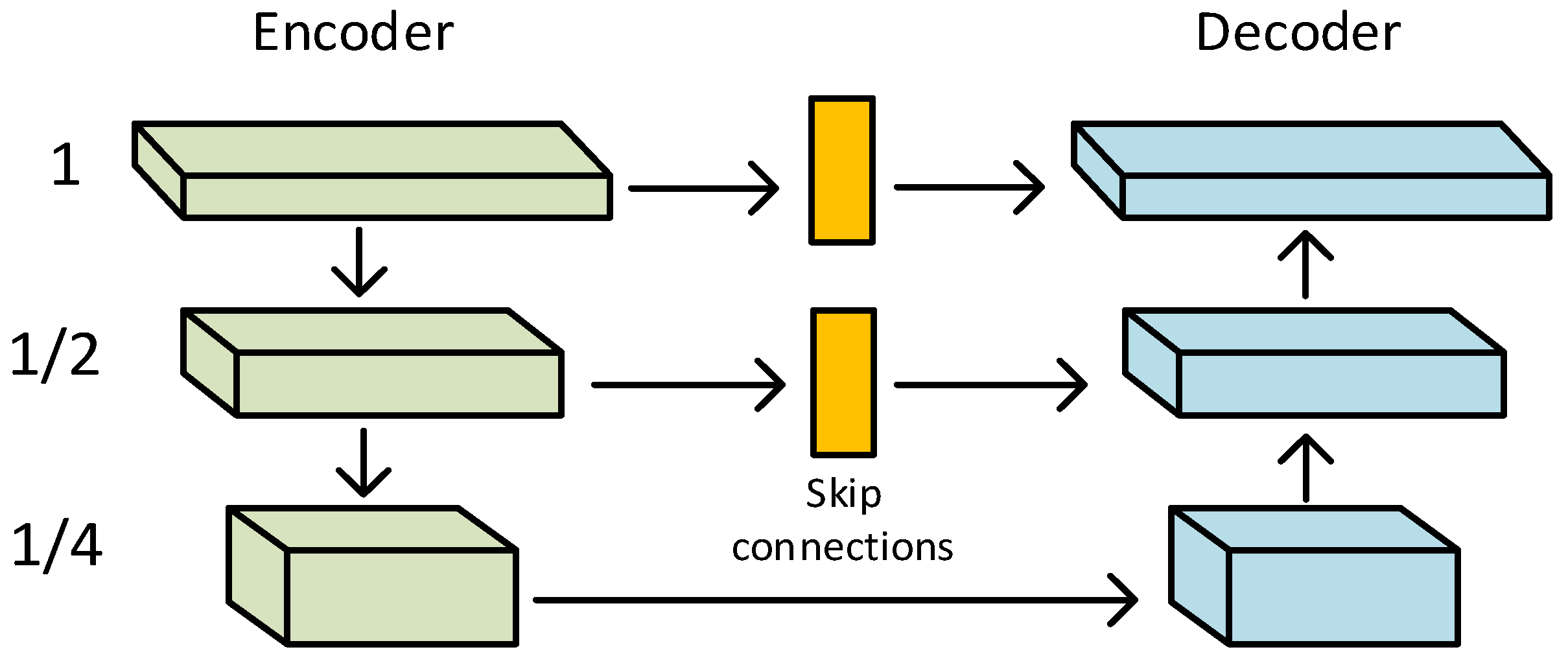
3. Multi-Scale Features to Remove Rain
3.1. Multi-Scale Feature Processing
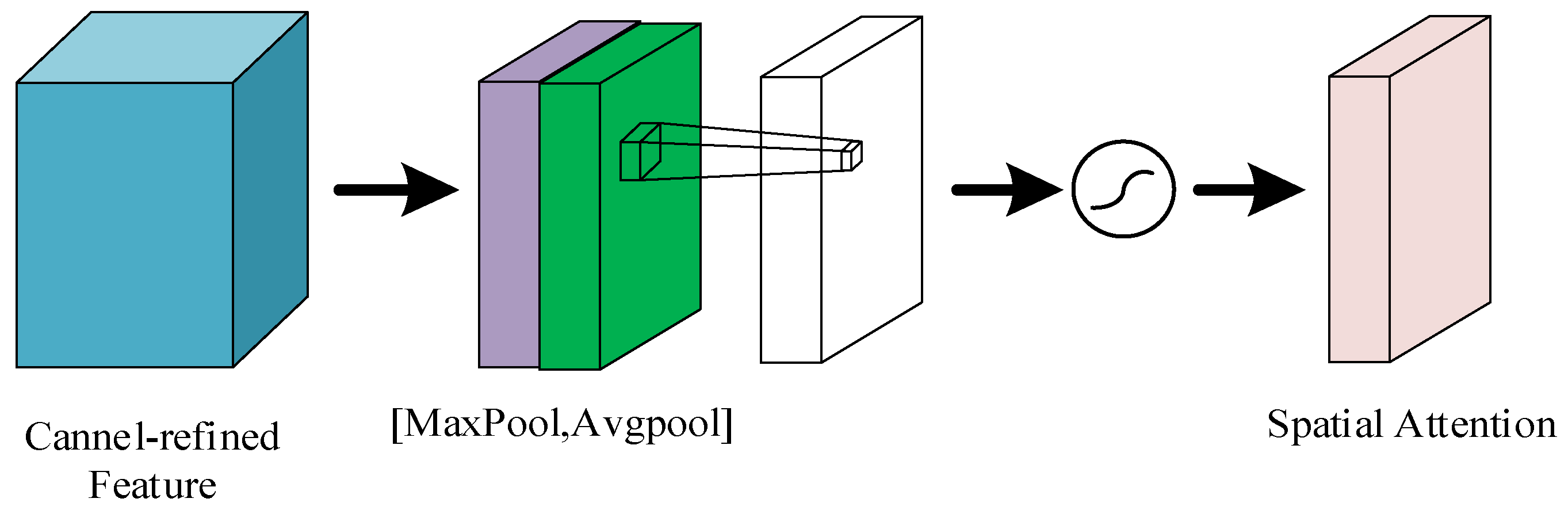
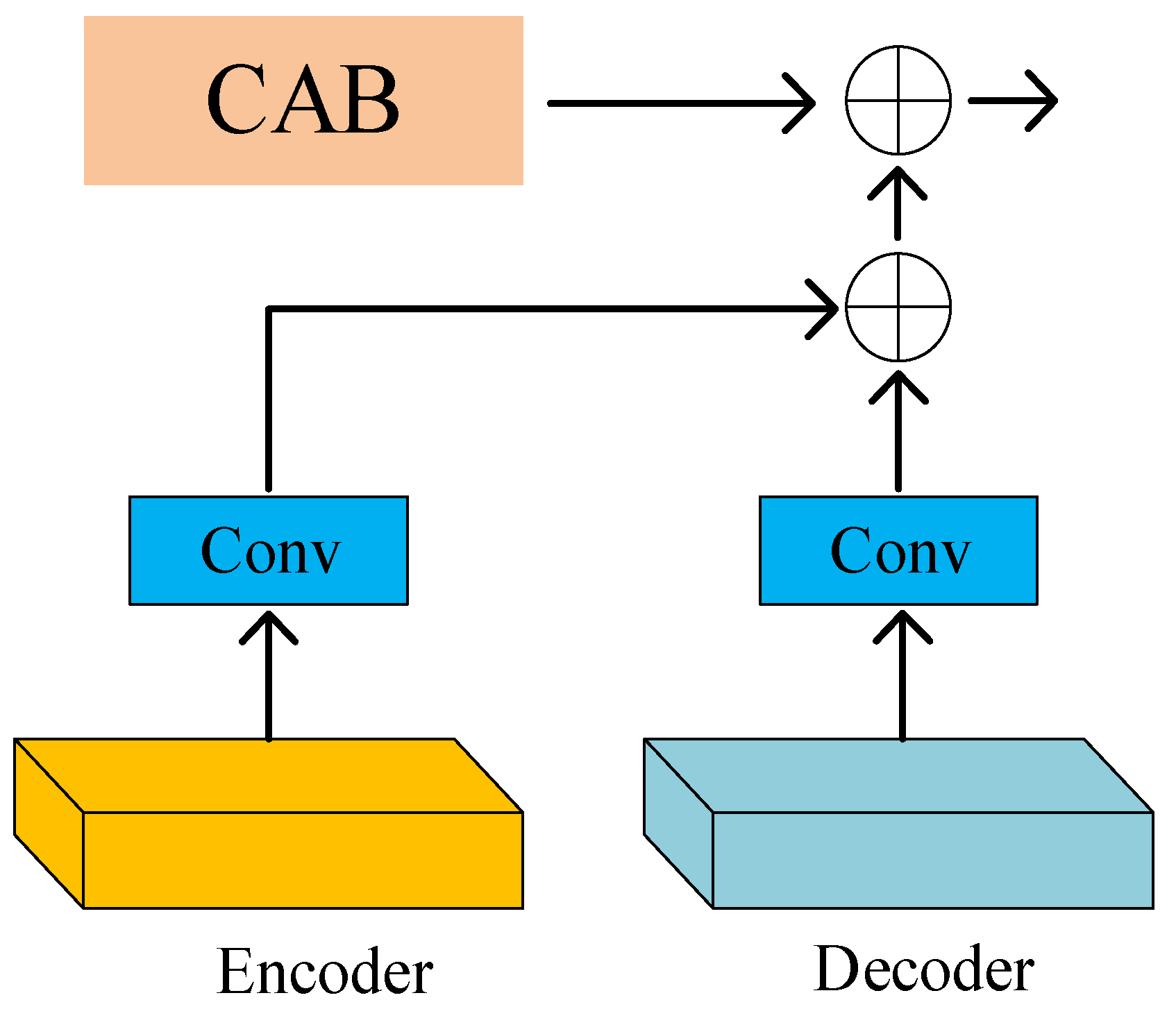
3.2. Feature Fusion
4. Experiments and Results Analysis
4.1. Datasets and Evaluation Metrics
4.2. Experiment Details
4.3. Derain Results
4.4. Rain Removal Experiment on a Real Rain Map
4.5. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xiao, J.; Zhou, M.; Fu, X.; Liu, A.; Zha, Z.-J. Improving De-Raining Generalization via Neural Reorganization. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: New York, NY, USA, 2021; pp. 4967–4976. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Receptive Field Block Net for Accurate and Fast Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; IEEE: New York, NY, USA, 2018; pp. 404–419. [Google Scholar]
- Garg, K.; Nayar, S.K. Detection and Removal of Rain from Videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE: New York, NY, USA, 2004; pp. 528–535. [Google Scholar]
- Garg, K.; Nayar, S.K. Vision and Rain. Int. J. Comput. Vis. 2007, 75, 3–27. [Google Scholar] [CrossRef]
- Kang, L.; Lin, C.W.; Fu, Y.H. Automatic Single-Image-Based Rain Streaks Removal via Image Decomposition. IEEE Trans. Image Process. 2011, 21, 1742–1755. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Xu, Y.; Ji, H. Removing Rain from a Single Image via Discriminative Sparse Coding. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: New York, NY, USA, 2015; pp. 3397–3405. [Google Scholar]
- Yasarla, R.; Patel, V.M. Uncertainty Guided Multi-Scale Residual Learning-Using a Cycle Spinning CNN for Single Image De-Raining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019; pp. 8405–8414. [Google Scholar]
- Zhou, M.; Xiao, J.; Chang, Y.; Fu, X.; Liu, A.; Pan, J.; Zha, Z.J. Image De-raining via Continual Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: New York, NY, USA, 2021; pp. 4905–4914. [Google Scholar]
- Nanba, Y.; Miyata, H.; Han, X. Dual Heterogeneous Complementary Networks for Single Image Deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 567–576. [Google Scholar]
- Li, X.; Wu, J.; Lin, Z.; Liu, H.; Zha, H. Recurrent Squeeze-and-Excitation Context Aggregation Net for Single Image Deraining. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; IEEE: New York, NY, USA, 2018; pp. 262–277. [Google Scholar]
- Fu, X.; Liang, B.; Huang, Y.; Ding, X.; Paisley, J. Lightweight Pyramid Networks for Image Deraining. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 1794–1807. [Google Scholar] [CrossRef] [PubMed]
- Wei, Y.; Zhang, Z.; Wang, Y.; Zhang, H.; Zhao, M.; Xu, M.; Wang, M. Semi-Deraingan: A New Semi-Supervised Single Image Deraining. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; IEEE: New York, NY, USA, 2021; pp. 1–6. [Google Scholar]
- Wei, Y.; Zhang, Z.; Wang, Y.; Xu, M.; Yang, Y.; Yan, S.; Wang, M. DerainCycleGAN: Rain Attentive CycleGAN for Single Image Deraining and Rainmaking. IEEE Trans. Image Process. 2021, 30, 4788–4801. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Pan, J.; Jiang, K.; Li, Y.; Huang, Y.; Kong, C.; Dai, L.; Fan, Z. Unpaired Deep Image Deraining Using Dual Contrastive Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 2007–2016. [Google Scholar]
- Su, Z.; Zhang, Y.; Zhang, X.P.; Qi, F. Non-local Channel Aggregation Network for Single Image Rain Removal. Neurocomputing 2022, 469, 261–272. [Google Scholar] [CrossRef]
- Ye, Y.; Yu, C.; Chang, Y.; Zhu, L.; Zhao, X.L.; Yan, L.; Tian, Y. Unsupervised Deraining: Where Contrastive Learning Meets Self-Similarity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 5811–5820. [Google Scholar]
- Yu, C.; Chang, Y.; Li, Y.; Zhao, X.; Yan, L. Unsupervised Image Deraining: Optimization Model Driven Deep CNN. In Proceedings of the 29th ACM International Conference on Multimedia (ACMM), Virtual, 20–24 October 2021; ACM: New York, NY, USA, 2021; pp. 2634–2642. [Google Scholar]
- Li, Y. Rain Streak Removal Using Layer Priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 2736–2744. [Google Scholar]
- Zhu, L.; Fu, C.W.; Lischinski, D.; Heng, P.A. Joint Bi-layer Optimization for Single-Image Rain Streak Removal. In Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 2545–2553. [Google Scholar]
- Zhu, H.; Wang, C.; Zhang, Y.; Su, Z.; Zhao, G. Physical Model Guided Deep Image Deraining. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Eigen, D.; Krishnan, D.; Fergus, R. Restoring an Image Taken through a Window Covered with Dirt or Rain. In Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE: New York, NY, USA, 2014; pp. 633–640. [Google Scholar]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Deep Joint Rain Detection and Removal from a Single Image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 1685–1694. [Google Scholar]
- Fu, X.; Huang, J.; Zeng, D.; Huang, Y.; Ding, X.; Paisley, J. Removing Rain from Single Images via a Deep Detail Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 1715–1723. [Google Scholar]
- Fu, X.; Huang, J.; Ding, X.; Liao, Y.; Paisley, J. Clearing the Skies: A Deep Network Architecture for SingleImage Rain Removal. IEEE Trans. Image Process. 2017, 26, 2944–2956. [Google Scholar] [CrossRef]
- Li, G.; He, X.; Zhang, W.; Chang, H.; Dong, L.; Lin, L. Non-locally Enhanced Encoder-Decoder Network for Single Image De-raining. In Proceedings of the 26th ACM International Conference on Multimedia (ACMM), Seoul, Republic of Korea, 22–26 October 2018; ACM: New York, NY, USA, 2018; pp. 1056–1064. [Google Scholar]
- Fan, Z.; Wu, H.; Fu, X.; Huang, Y.; Ding, X. Residual-Guide Network for Single Image Deraining. In Proceedings of the 26th ACM International Conference on Multimedia (ACMM), Seoul, Republic of Korea, 22–26 October 2018; ACM: New York, NY, USA, 2018; pp. 1751–1759. [Google Scholar]
- Hu, X.; Fu, C.W.; Zhu, L.; Heng, P.A. Depth-Attentional Features for Single-Image Rain Removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019; pp. 8022–8031. [Google Scholar]
- Wang, T.; Yang, X.; Xu, K.; Chen, S.; Zhang, Q.; Lau, R.W. Spatial Attentive Single-Image Deraining with a High Quality Real Rain Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019; pp. 12270–12279. [Google Scholar]
- Wang, C.; Xing, X.; Wu, Y.; Su, Z.; Chen, J. DCSFN: Deep Cross-Scale Fusion Network for Single Image Rain Removal. In Proceedings of the 28th ACM International Conference on Multimedia (ACMM), Seattle, WA, USA, 12–16 October 2020; ACM: New York, NY, USA, 2020; pp. 1643–1651. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Chen, C.; Huang, B.; Luo, Y.; Ma, J.; Jiang, J. Multi-Scale Progressive Fusion Network for Single Image Deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: New York, NY, USA, 2020; pp. 8343–8352. [Google Scholar]
- Deng, S.; Wei, M.; Wang, J.; Feng, Y.; Liang, L.; Xie, H.; Wang, F.L.; Wang, M. Detail-recovery Image Deraining via Context Aggregation Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: New York, NY, USA, 2020; pp. 14548–14557. [Google Scholar]
- Wang, C.; Wu, Y.; Su, Z.; Chen, J. Joint Self-Attention and Scale-Aggregation for Self-Calibrated Deraining Network. In Proceedings of the 28th ACM International Conference on Multimedia (ACMM), Seattle, WA, USA, 12–16 October 2020; ACM: New York, NY, USA, 2020; pp. 2517–2525. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Chen, C.; Wang, X.; Jiang, J.; Xiong, Z. Multi-level Memory Compensation Network for Rain Removal via Divide-and-Conquer Strategy. IEEE J. Sel. Top. Signal Process. 2021, 15, 216–228. [Google Scholar] [CrossRef]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and Checkerboard Artifacts. Distill 2016, 1, e3. [Google Scholar] [CrossRef]
- Pereira, L.M.; Salazar, A.; Vergara, L. A comparative analysis of early and late fusion for the multimodal two-class problem. IEEE Access 2023, 11, 84283–84300. [Google Scholar] [CrossRef]
- Salazar, A.; Safont, G.; Vergara, L.; Vidal, E. Graph Regularization Methods in Soft Detector Fusion. IEEE Access 2023, 11, 144747–144759. [Google Scholar] [CrossRef]
- Pereira, L.M.; Salazar, A.; Vergara, L. A Comparative Study on Recent Automatic Data Fusion Methods. Computers 2023, 13, 13. [Google Scholar] [CrossRef]
- Salazar, A.; Vergara, L.; Vidal, E. A proxy learning curve for the Bayes classifier. Pattern Recognit. 2023, 136, 109240. [Google Scholar] [CrossRef]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image de-raining using a conditional generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3943–3956. [Google Scholar] [CrossRef]
- Zhang, H.; Patel, V.M. Density-aware single image de-raining using a multi-stream dense network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Simoncelli. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. arXiv 2017, arXiv:1608.03983. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Rain14000 | Rain800 | Rain100H | Rain100L | Rain1200 |
|---|---|---|---|---|---|
| Train Samples | 13,500 | 700 | 0 | 0 | 0 |
| Test Samples | 500 | 100 | 100 | 100 | 400 |
| Testset Rename | Test500 | Test100 | Rain100H | Rain100L | Test400 |
| Method | Test100 | Rain100H | Rain100L | Test400 | Test500 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| DerainNets | 22.77 | 0.810 | 14.92 | 0.592 | 27.03 | 0.884 | 20.35 | 0.757 | 22.35 | 0.831 |
| SEMI | 22.35 | 0.788 | 16.56 | 0.486 | 25.03 | 0.842 | 20.52 | 0.735 | 25.13 | 0.816 |
| DIDMDN | 22.56 | 0.818 | 17.35 | 0.524 | 25.23 | 0.741 | 24.21 | 0.765 | 28.73 | 0.895 |
| UMRL | 24.41 | 0.829 | 26.01 | 0.832 | 29.18 | 0.923 | 25.78 | 0.807 | 29.62 | 0.904 |
| RESCAN | 25.00 | 0.835 | 26.36 | 0.786 | 29.80 | 0.881 | 27.44 | 0.810 | 29.51 | 0.877 |
| PreNet | 24.81 | 0.851 | 26.77 | 0.858 | 32.44 | 0.950 | 27.67 | 0.822 | 30.46 | 0.906 |
| MSPFN | 27.50 | 0.876 | 28.66 | 0.860 | 32,40 | 0.933 | 28.26 | 0.827 | 31.17 | 0.915 |
| MFD (Ours) | 29.45 | 0.874 | 28.67 | 0.870 | 35.01 | 0.959 | 28.12 | 0.839 | 31.67 | 0.919 |
| Method | NIQE | BRISQUE | CEIQ | SSEQ |
|---|---|---|---|---|
| SEMI | 19.969 | 28.748 | 4.864 | 2.053 |
| PreNet | 17.326 | 25.777 | 5.423 | 2.234 |
| MFD (Ours) | 15.422 | 25.094 | 5.463 | 2.549 |
| Network | PSNR | SSIM |
|---|---|---|
| Baseline | 31.63 | 0.863 |
| Baseline+SAM | 33.82 | 0.924 |
| Baseline+CSFF | 32.26 | 0.916 |
| Baseline+SAM+CSFF | 35.01 | 0.959 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Wang, J.; Li, Y.; Yao, B.; Xu, T.; Lu, T.; Gao, X.; Chen, J.; Liu, W. Image Deraining Algorithm Based on Multi-Scale Features. Appl. Sci. 2024, 14, 5548. https://doi.org/10.3390/app14135548
Yang J, Wang J, Li Y, Yao B, Xu T, Lu T, Gao X, Chen J, Liu W. Image Deraining Algorithm Based on Multi-Scale Features. Applied Sciences. 2024; 14(13):5548. https://doi.org/10.3390/app14135548
Chicago/Turabian StyleYang, Jingkai, Jingyuan Wang, Yanbo Li, Bobin Yao, Tangwen Xu, Ting Lu, Xiaoxuan Gao, Junshuo Chen, and Weiyu Liu. 2024. "Image Deraining Algorithm Based on Multi-Scale Features" Applied Sciences 14, no. 13: 5548. https://doi.org/10.3390/app14135548
APA StyleYang, J., Wang, J., Li, Y., Yao, B., Xu, T., Lu, T., Gao, X., Chen, J., & Liu, W. (2024). Image Deraining Algorithm Based on Multi-Scale Features. Applied Sciences, 14(13), 5548. https://doi.org/10.3390/app14135548