Abstract
There are many pre-trained deep learning-based face recognition models developed in the literature, such as FaceNet, ArcFace, VGG-Face, and DeepFace. However, performing transfer learning of these models for handling face sketch recognition is not applicable due to the challenge of limited sketch datasets (single sketch per subject). One promising solution to mitigate this issue is by using optimization algorithms, which will perform a fine-tuning and fitting of these models for the face sketch problem. Specifically, this research introduces an enhanced optimizer that will evolve these models by performing automatic weightage/fine-tuning of the generated feature vector guided by the recognition accuracy of the training data. The following are the key contributions to this work: (i) this paper introduces a novel Smart Switching Slime Mold Algorithm (S2SMA), which has been improved by embedding several search operations and control rules; (ii) the proposed S2SMA aims to fine-tune the pre-trained deep learning models in order to improve the accuracy of the face sketch recognition problem; and (iii) the proposed S2SMA makes simultaneous fine-tuning of multiple pre-trained deep learning models toward further improving the recognition accuracy of the face sketch problem. The performance of the S2SMA has been evaluated on two face sketch databases, which are XM2VTS and CUFSF, and on CEC’s 2010 large-scale benchmark. In addition, the outcomes were compared to several variations of the SMA and related optimization techniques. The numerical results demonstrated that the improved optimizer obtained a higher level of fitness value as well as better face sketch recognition accuracy. The statistical data demonstrate that S2SMA significantly outperforms other optimization techniques with a rapid convergence curve.
1. Introduction
Face sketch recognition involves matching two face images from different modalities; one is a face drawing created by a professional artist based on a witness statement, and the other is the corresponding image from the agency’s department database. Some facial sketches are depicted for illustrative purposes, as given in Figure 1. Due to the partial and approximate nature of the eyewitness’s description, face sketches are less detailed than their corresponding photos. Due to the modality disparities between face photos and sketch images, classic homogeneous face recognition algorithms perform badly in face sketch recognition [1]. To overcome this challenge, soft computing models have been utilized. Existing methods for face sketch recognition are resolved in three ways, which are synthesis-based, projection-based, and optimization-based. In the first category, synthesis-based methods, also known as generative methods, are used to transform one of the modalities into the other (photo to sketch or vice versa) prior to matching [2,3,4,5,6,7,8,9,10,11]. Projection-based techniques utilize soft computing approaches [12,13,14,15,16,17] to reduce the differences between sketch and photo features projected in a different space. The final category, which is optimization-based, focuses on fine-tuning the parameters using optimization methods. In other words, the objective is to maximize the similarity between the sketch and its photo, maximizing the weights of their extracted features [1,18,19,20].
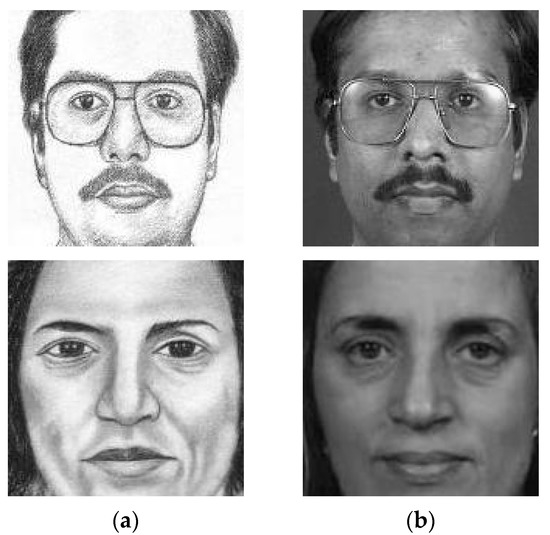
Figure 1.
Sample of sketches (a) and corresponding photos (b).
Apart from that, deep learning approaches such as FaceNet [21], ArcFace [22], VGG-Face [23], and DeepFace [24] have recently achieved major advances in face recognition by learning latent embeddings from large amounts of face data. However, it is more difficult to use deep learning for face sketch recognition due to the lack of face sketch–photo data. This is due to the challenge of obtaining face sketch pictures where existing public datasets contain only a handful of face sketch–photo combinations, with one sketch per individual in most cases. Over-fitting and local minima arise from these limitations, making it hard for deep networks to learn adequate feature representations for face sketch recognition during training [25]. This study suggests adopting a recent optimization approach to solve this problem by performing fine-tuning of those pre-trained deep-face recognition models such as FaceNet, ArcFace, VGG-Face, and DeepFace.
Recently, several optimizers have been presented in the literature, such as Fitness Dependent Optimizer (FDO) [26], Donkey and Smuggler Optimizer (DSO) [27], Slime Mold Algorithm (SMA) [28], Black Widow Optimization Algorithm (BWO) [29], The Red Fox Optimization Algorithm (RFO) [30], Q-Learning Embedded Sine Cosine Algorithm (QLESCA) [31], and Reptile Search Algorithm (RSA) [32]. Among them, SMA received a lot of attention due to its smooth structure, few parameters, robustness, and implementation flexibility. However, when dealing with complicated and high-dimensional situations, SMA still has some limitations, such as its slow convergence and potential to slip into the local optima trap [33,34,35]. Additionally, the optimization algorithm for slime molds utilizes the best leader and two randomly pooled slime molds from the population, resulting in poor exploitation and exploration [36,37]. Thus, in order to fully optimize the performance of SMA and make it perfect for the face sketch recognition problem, we propose an enhanced variant named S2SMA. Accordingly, S2SMA will be applied to tackle the face sketch recognition problem.
In summary, this work presents S2SMA with embedded rules and search operations, namely the Arithmetic Optimization Algorithm (AOA) and the Levy Flight (LF). Moreover, S2SMA has been applied to tune the weights of deep-face models to make it work for the problem of face sketch recognition. Specifically, a total of four deep-face models were combined, and the proposed algorithm gives weights to each model to obtain the highest accuracy for face sketch recognition. The principal contributions to this paper are as follows:
- To propose an improved method for solving large-scale problems, which is called S2SMA. This work presents S2SMA with embedded rules and operations, namely AOA and LF. The AOA operation aims to solve the problem of SMA’s limited exploitation. Moreover, the LF mechanism has been integrated to improve SMA’s exploratory capability and aid in maintaining an appropriate balance between exploration and exploitation [38]. Furthermore, the proposed embedded smart switching rules allow for adaptive switching between search operations during execution.
- To formulate an optimized deep-face sketch recognition problem by fine-tuning the weights of deep features using S2SMA. As such, S2SMA tunes the weights of the outputs of the deep-face models to maximize the similarity between sketch–photo pairs. Here, S2SMA adjusts the weights of these models’ outputs to fit the face sketch recognition problem.
- To further enhance the deep-face sketch recognition by fine-tuning multiple deep models, four deep-face models specialized in facial recognition are used in this study: FaceNet [21], ArcFace [22], VGG-Face [23], and DeepFace [24]. These models are combined, and the proposed S2SMA gives weight to each model to obtain the highest accuracy for the face sketch recognition problem.
The remainder of this article is structured as follows. The following section presents a quick overview of the relevant research on face sketch recognition and SMA. Section 3 describes the SMA’s’ specifications and the details of the proposed work. The numerical experiment and statistical analysis are presented in Section 4. Finally, this paper is concluded in Section 5.
2. Related Work
As previously mentioned, face sketch recognition methods can be categorized into synthesis-based, projection-based, and optimization-based. This section highlights the studies that have followed the optimization methods. Many optimization approaches are used in the literature for face recognition, e.g., PSO-based [39,40,41,42,43], Firefly Optimization Algorithm-based [44], Harris Hawks Optimization-based [45], and Bald Eagle Search Optimization-based [46], which have been effectively applied to the problem of face recognition. However, only these studies focused on optimization-based methods for handling the problem of face sketch recognition. For example, the earliest study mentioned in this literature review is by Bhatt et al. [18], who proposed a weight optimization technique based on the Genetic Algorithm (GA) to determine the optimal weights for every facial patch. Their model was evaluated on sketch–digital picture pairs from the CUHK and IIIT-D databases. The results indicated that their approach could offer superior identification performance compared to existing algorithms. Later, Bhatt et al. (2012) combined the Genetic Algorithm (GA) and Simulated Annealing (SA) to address the issue of face sketch recognition [19]. GA-SA adjusted the weights of extracted features via a Local Binary Pattern (LBP). The experiments showed that the GA-SA method was better than other face recognition algorithms and two commercial systems. Moving to recent studies, Samma et al. (2019) introduced a hybrid optimization model that combined PSO and a local search strategy to perform localization and weighting of the facial sketch region [1]. They employed three distinct extraction strategies for texture features: Histogram of Gradient (HOG), Local Binary Pattern (LBP), and Gabor wavelet. Several datasets were used to assess their proposed hybrid model, such as LFW, AR, and CUHK. The results demonstrated that the hybrid model achieved 96% on AR, 87.68% on CUHK, and 50% on LFW. Statistically, the suggested approach outperforms PSO-based models and state-of-the-art optimization methods. In the most recent study, Samma et al. (2022) introduced a hybrid deep learning model for face sketch recognition that combined Particle Swarm Optimization (PSO) with the VGG-face deep learning network [20]. Their work incorporated PSO to determine the necessary VGG-facial filters and fine-tuned the weights of these selected filters for face sketch recognition. The outcomes showed PSO’s ability to improve model accuracy and reduce complexity.
Recent studies explored non-optimization-based methods for handling face sketch recognition. Ren et al. [47] presented an unsupervised CycleGAN-based model that converted face sketches into high-quality photos by incorporating a multi-scale feature extraction module and a CBAM module to improve feature extraction and reduce background interference. Rizkinia et al. [48] proposed a GAN-based method for generating color face photos from hand-drawn sketches with improved accuracy and reduced artifacts. The proposed method by Zhong et al. [49], called Unsupervised Self-Attention Lightweight photo-to-sketch synthesis with Feature Maps (USAL), added a self-attention module to a generative adversarial network and reduced the layers of the discriminator to improve efficiency and performance. Furthermore, C. Peng et al. [50] proposed an Intra-Domain Enhancement (IDE) method for face photo–sketch synthesis. The MLA-GAN model was designed to refine and extract features and enhance the resolution of the synthesized image, which outperformed the state-of-the-art face sketch synthesis methods on multiple public face sketch databases. In addition, Y. Peng et al. [51] introduced a Sketch-Guided Latent Diffusion Model (SGLDM) that used a Multi-Auto-Encoder (AE) to encode input sketches for denoising. The paper also proposed Stochastic Region Abstraction (SRA) as a data augmentation strategy to improve the model’s robustness in managing sketches with varying levels of abstraction. The SGLDM outperformed state-of-the-art methods and could synthesize high-quality face images with different expressions, facial accessories, and hairstyles. Earlier, Singh et al. [52] provided more information about digital image denoising based on a comprehensive overview of the backpropagation algorithm. However, these recent studies well demonstrated significant progress in the development of effective and efficient methods for handling face sketch recognition.
In the literature, the SMA has been applied to solve a wide variety of real-world problems, such as economic emission dispatch [53], image segmentation [54], and the estimation of solar photovoltaic cell parameters [55]. Researchers proposed several variations of the SMA to further enhance its performance in specific domains. Naik et al. [36] proposed a unique NSD-based multilevel thresholding strategy that employed the Leader Slime Mold Algorithm (LSMA). The LSMA outperformed the traditional SMA by using the three best candidates as a leader to guide the search. The study also applied the NSD-LSMA method for multilevel thresholding of Landsat images and showed that it outperformed state-of-the-art methods. In another study, Naik et al. [37] introduced an Adaptive Opposition Slime Mold Algorithm (AOSMA) for function optimization that adaptively decided whether to use opposition-based learning to enhance exploration and replaced one random search agent with the best one to maximize exploitation. The AOSMA outperformed other state-of-the-art optimization algorithms in qualitative and quantitative analyses. The algorithm was suggested to be useful for function optimization to solve real-world engineering problems. Concurrently, another study by Naik et al. [56] showed the development of a new Equilibrium Slime Mold Algorithm (ESMA) for multilevel thresholding of breast thermogram images based on minimizing the entropic dependencies among different classes in the image. The ESMA was evaluated and compared to other optimization algorithms and found to perform better. The study claimed that the proposed method might be useful for assisting medical practitioners in breast thermogram analysis. Chauhan et al. [57] proposed HAOASMA, a hybrid algorithm that combined AOA and SMA to address the limitations of SMA’s exploration and exploitation capabilities. They integrated lens opposition-based learning to increase population diversity and accelerate convergence. HAOASMA outperformed traditional SMA algorithms and is better for finding optimal global solutions. Recently, Altay [58] proposed the Chaotic SMA (CSMA) to improve the SMA method by applying ten different chaotic maps to generate chaotic values instead of random values. It was intended to speed up SMA’s global convergence and keep it from becoming trapped in its local solutions using chaotic maps. CSMA performed better in 62 benchmark functions and real-world engineering design challenges than other methods and standard SMA. Although very few studies have attempted to use different optimization techniques to solve the face sketch recognition problem, none have used SMA and its variants. Therefore, the current study aims to conduct further investigation on the effectiveness of the optimization algorithms to solve the face sketch recognition problem and to develop a new algorithm to deal with large-scale problems, including the face sketch recognition problem. In addition, the use of multiple pre-trained deep learning models and their simultaneous fine-tuning using S2SMA can be considered a novel approach to improve the accuracy of face sketch recognition.
3. Proposed SMA-Based Method
3.1. The Original Slime Mold Algorithm (SMA)
The SMA is a novel swarm intelligence optimization algorithm recently proposed by Li et al. [28], which simulates the foraging behavior of slime molds. The SMA consists of three phases: approaching, wrapping, and grabbing food.
3.1.1. Approaching Food
For a slime mold to approach food, the concentration of odor in the air is crucial. This contraction pattern while approaching food is defined by Equation (1):
where is a parameter with the interval [−a, a] and decreases from one to zero linearly. indicates the individual position with the highest odor concentration currently discovered, represents the current location of a slime mold, and represent two chosen randomly individuals from the population, and represent the current number of iterations and a random value within [0, 1], respectively, and denotes the weight of the slime mold. The parameter p is calculated as in Equation (2):
where , indicates the fitness of and represents the best fitness obtained throughout all iterations. The formula of is shown in Equation (2), where is given in Equation (4):
Here, is the maximum number of iterations, the formula of is listed in Equation (5), and it’s is defined in Equation (6):
where indicates that ranks in the top fifty percent of the overall population, represents a random value within [0, 1], the best fitness value obtained in the current iterative process is denoted by , the worst fitness value is denoted by , and represents the series of fitness values arranged in ascending order of fitness (ascends in the minimum value problem).
3.1.2. Wrapping Food
The mathematical formula for updating the location of the slime mold is given in Equation (7):
, and are random values in the interval [0, 1], where and represent the lower and upper search range bounds, respectively. The value represents the probability of a slime mold and is a parameter with a fixed value of 0.03.
Equation (7) has two switching parameters. is the first parameter that increases local exploration when individuals find less information near a targeted meal. This value may be an SMA characteristic; if slimes receive less knowledge for the global optimal, the algorithm chooses some slimes to abandon the current exploration and start over. On the other hand, is the second parameter that guides slimes to explore or exploit in each iteration. This value balances exploration and exploitation during iterations. The proper value could decrease the rate of slimes trapped in local optima.
3.1.3. Grabbling Food
, , and are applied to represent the changes in slime mold venous width. replicates the oscillating frequency of slime molds by analyzing the food’s quality to update the food’s speed, thus assisting slime molds in selecting the ideal food source. The values of and are oscillated randomly within a certain range. is within , while within [−1, 1]; additionally, as a result of the iterative process, they all converge on zero. In addition, the variation process of replicates whether the slime mold approaches or seeks out alternative food sources when a new food source is identified. The slime mold will always separate some organic matter to search for higher-quality food sources in other places, even if a superior food source has been discovered. This conduct increases the slime mold’s chances of locating higher-quality food and improves the optimal local problem. Additional information on the SMA can be found in the study of Li et al. [28].
3.2. Smart Switching Slime Mold Algorithm (S2SMA)
As explained in Equation (7), the SMA relies on this equation to update slime positions during the exploration and exploitation phases. Moreover, the SMA depends on z and p parameters to switch from exploration to exploitation and vice versa. However, the SMA still suffers from poor exploitative behavior, thus from slow convergence, and lacks potentially better solutions, which eventually require improvement. To overcome these shortcomings of the SMA, three modifications have been made to the original algorithm, which are summarized as follows:
- The first improvement, the SMA exploration phase, has been improved by incorporating LF into the original equation that updates the slime’s position in the wrap food phase in Equation (7).
- The second improvement, an embedded operation, was added from the AOA algorithm [59] to improve the exploitation phase further.
- The final improvement, a total of four embedded switching rules have been added to control switching between AOA, LF, and other SMA search operations.
3.2.1. The Proposed Embedded Levy Flight
The first part of the modification was to the original SMA by adding the Levy Flight to the SMA in Equation (7). LF is used to update the positions of the search agents and increase the search space [60], as well as to ensure the effective exploration position and avoid local convergence [61]. Moreover, LF maintains an appropriate balance between exploration and exploitation [62]. The expression is added to the SMA, and the following is how the embedded Levy Flight operation is added to the SMA equations, as given in Equation (8):
where is the problem’s dimension, is a random vector of size 1 × dim, and is the Levy Flight function, which is computed in Equation (9):
where and refer to the standard normal distribution, represents the standard gamma function, and = 1.5 as suggested in [63].
3.2.2. Embedded Arithmetic Operation (EAO)
The second part of modifying the original SMA was formulated by adding EAO, adapted from AOA [59], to improve the exploitation of S2SMA. Hence, EAO is the specialist portion of exploitation in AOA. The AOA’s exploitation part is straightforward, using only the subtractive and additive operators. The small step sizes generated by these operators provide a dense population of potential solutions [59]. Consequently, EAO is considered simple in terms of computation where it performs either subtract or add operations as given in Equation (10). As a result, incorporating EAO will not require a significant amount of time when executing code. These reasons encouraged us to include EAO in our current work and to further investigate its effectiveness in solving the aforementioned problems. EAO can be expressed mathematically to update slime positions as given in Equation (10):
where indicates the solution in the next iteration, is the individual position of the best-obtained solution so far, t is the current iteration, Abualigah et al. [59] suggested that is a search process control parameter with a fixed value of 0.5, and is a random number within [0, 1]. In addition, the upper bound value and lower bound value of the th position are described by and , respectively. It should be noted that the parameter is computed in Equation (11):
where math optimizer probability is a coefficient, is the value of the function at the th iteration, is the maximum number of iterations, is the current iteration, and is a sensitive parameter and defines the exploitation accuracy over the iterations, which is fixed at five as suggested by Abualigah et al. [59].
3.2.3. The Proposed Embedded Smart Switching Rules
The last modification was formulated by adding four embedded switching rules. The main objective of these rules was to control the recall ratio switching between AOA, LF, and other SMA search operations when updating slime positions. Embedded switching rules are triggered according to the occurrence of some events. Four events are used to control the trigger of rules: the parameter, parameter, parameter, and . is a factor with a range of [0, 1]. This parameter computes the percentage of SMA search operations with LF called to update slime positions from the total update rate. The second parameter is , a value with a range of [0, 1]. This parameter computes the percentage of EAO called to update slime positions from the total update rate. The third parameter is the . It will take on a value of either zero or one. If the best population location has not changed, it will be zero; otherwise, it will be one. The fourth parameter is , which will take a value of 0.1 or 0.9. Its value depends on the rule that will be applied.
S2SMA prioritizes LF and other SMA search operations (LS) for initially updating positions. If it has succeeded in finding a new leader, RULE1 will be applied. RULE1 is given in Figure 2. In other words, if LS is called most of the time during the update of slime positions and finds a new leader, LS will be given a high opportunity to update the slime’s positions in the next iteration.
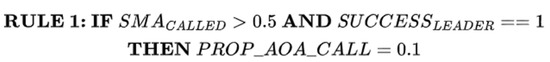
Figure 2.
RULE 1 for switching between EAO and LS.
The second rule is formulated to verify whether LS has failed to find a new leader. Consequently, the second rule will be implemented, as shown in Figure 3. In other words, if LS is called most of the time during the update of slime positions and fails to find a new leader, then EAO will be given a high opportunity to update the slime positions in the next iteration.
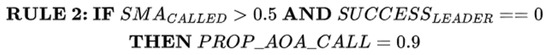
Figure 3.
RULE 2 for switching between EAO and LS.
The third rule is designed to verify whether EAO is often called during the update of slime positions and succeeds in finding a new leader. Then, EAO will be given a high chance to continue updating the slime positions in the next iteration. In that case, the third rule will be applied as given in Figure 4.
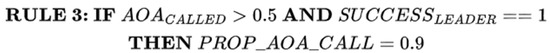
Figure 4.
RULE 3 for switching between EAO and LS.
The fourth rule is developed to verify whether EAO is often called during the update of slime positions and fails to find a new leader. Consequently, LS will have a high probability of updating the slime positions in the next iteration. In this instance, the fourth rule shown in Figure 5 will be applied.
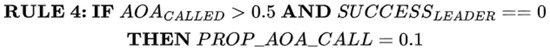
Figure 5.
RULE 4 for switching between EAO and LS.
The complete steps of the proposed S2SMA algorithm are given in Algorithm 1 and Figure 6.
| Algorithm 1: Pseudo-code of proposed method |
| Input and . ; ; While Calculate the fitness of all slime molds; ; Calculate the by Equation (5); For do If) then ; Else ; ; For each dimension do If () then ; Else) then ; Else ; End If End End If End ; End While Output: ; |
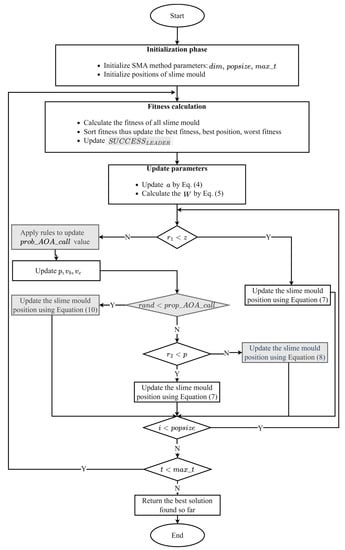
Figure 6.
Flow chart of the proposed method.
3.3. Fine-Tuning of Pre-Trained Deep-Face Sketch Using S2SMA
The proposed S2SMA optimization algorithm was integrated with several deep-face models to perform the task of face sketch recognition. This work is divided into two sections: the first section uses a single deep-face model to address face sketch recognition problems and the second combines four deep models to further enhance the recognition performance.
3.3.1. Fine-Tuning of Single Pre-Trained Deep Models
Figure 7 shows the main procedures of fine-tuning a single deep-face model. As indicated, there are three stages, which are feature extraction, feature tuning, and fitness evaluation. In the first stage, all training sketches and the corresponding photos have their features extracted and converted into output vectors. The size of the output vector depends on the model used. In this study, four models were used: FaceNet [21], ArcFace [22], VGG-Face [23], and DeepFace [24]. It is important to note that the output vector size for each deep-face model is different: 128, 512, 2622, and 4096, respectively, as can be seen in Figure 7; note that the feature array has two dimensions, and , where represents the number of training images and represents the number of features in each image (e.g., if we have 10 training images, then the feature array will contain 20 vectors: 10 pairs of sketches and their corresponding photos).
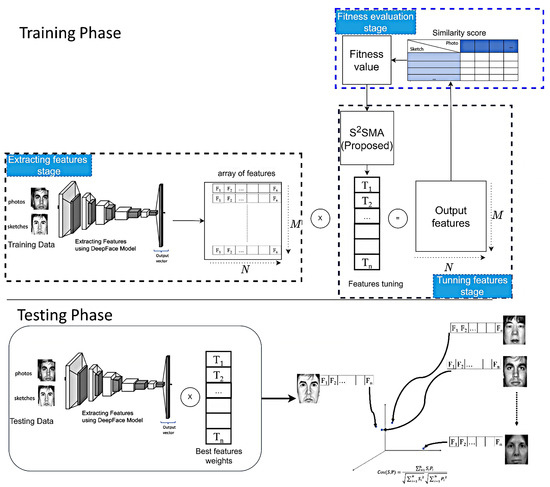
Figure 7.
The illustration shows the suggested technique for face sketch recognition using a single deep-face model. The upper portion represents the training phase, while the lower portion represents the testing phase.
In the second stage, S2SMA will generate a “features tuning” vector with random values between 1 and 2. The size of the features tuning vector and the output vector are similar. The output vector and the features tuning vector will be multiplied (element by element), and the result will be saved in the output features array. In other words, there are a lot of features in each image, but there are some features that have a greater impact during the face sketch recognition process for each model. S2SMA attempts to discover the effectiveness of all features and their impact on performance during face sketch recognition. Thus, the optimizer has tuned the features based on how much they are affected. It is worth noting that all deep-face models mentioned above are dedicated only to face recognition [25]. As a result, the suggested algorithm tuned the deep-face models to make them suitable for face sketch recognition.
Finally, based on the features tuned in the previous step, the final step calculates the similarities between each sketch and all photos. This study computes the similarity task using the cosine distance measure, which is defined in Equation (12):
where is the cosine similarity measure. Variables and represent the input feature vector from the input sketched image and the photo, respectively. Subsequently, the is calculated based on separation using Equation (13):
where denotes the distance between the input sketch and the nearest incorrect photo, as depicted in Figure 8, where S2SMA aims to maximize this distance. Moreover, every agent will repeat the second and third steps.
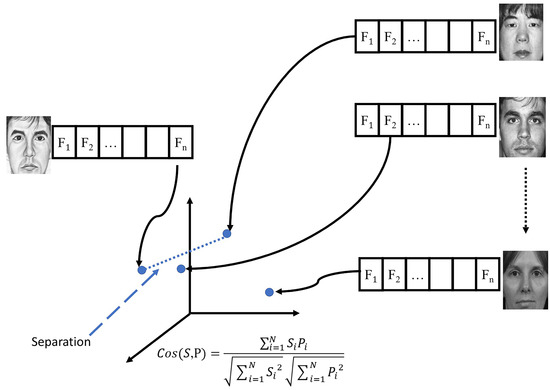
Figure 8.
Description of separation measures.
3.3.2. Fine-Tuning of Multiple Pre-Trained Deep Models
As can be seen from Figure 9, which shows the main procedures of the second section, there are four stages in this section: feature extraction, feature tuning, similarity tuning, and fitness evaluation. Overall, this section has four main differences that distinguish it from the previous section. The first difference is that all features are extracted from four different deep-face models simultaneously, each working separately. The models are FaceNet [21], ArcFace [22], VGG-Face [23], and DeepFace [24], and their respective abbreviations are M1, M2, M3, and M4. The second difference, as shown in Figure 9, is that S2SMA will generate a “features tuning” vector divided into four parts; each model has its part (e.g., if M1 has a vector length of 128, then its part is the same length). Next, S2SMA tunes each model’s output vectors, as explained in the previous section. This process is done for each model separately. Then, the results of each model will be saved to the output feature array for that model. The third difference shows that S2SMA also generates a ‘similarity weight’ vector for tuning the model similarities. The vector of similarity weight has four values, W1, W2, W3, and W4, and the values range between [0.1, 1]. These weights are dynamically adjusted using S2SMA, which finds the optimal weights. In other words, S2SMA attempts to find the effectiveness of each model in terms of its accuracy in face sketch recognition. As a result, S2SMA tunes the similarities for each model. The last difference demonstrates how to calculate the average similarity for all four models after tuning similarity, which is calculated based on Equation (14):
where is the cosine similarity measure. Variables and represent the FaceNet input feature vectors from the input sketched image and the photo, respectively. and are ArcFace features, and are VGG-Face features, and and are DeepFace features.
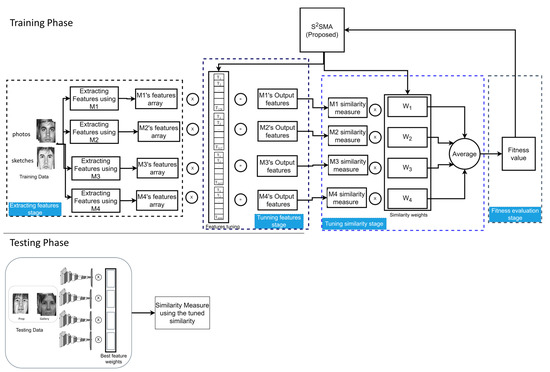
Figure 9.
The illustration shows the suggested technique for face sketch recognition using multiple models. The upper portion represents the training phase, while the lower portion represents the testing phase.
4. Experimental Results and Analysis
In this section of the analysis, a series of experiments were performed to verify the efficiency of S2SMA. A total of three case studies were investigated, including large-scale benchmark problems, CEC’2010 benchmark [64], and two public sketch databases, XM2VTS [65] and CUFSF [66].
4.1. Evaluation on Large-Scale Benchmark Problems (CEC’2010)
The usefulness of embedding rules and operations to strengthen the SMA (i.e., the proposed method) on large-scale benchmark issues is investigated in this experimental part. Twenty large-scale functions from the CEC’2010 benchmark functions [64] have specifically been utilized. Table 1 presents details about these functions, namely, separable functions, single-group –non-separable functions, group –non-separable functions, group –non-separable functions, and fully separable functions are the five sets of functions that make up the CEC’2010 benchmark.

Table 1.
Description of 1000-D CEC’2010 large-scale benchmark functions.
4.1.1. The Influence of Population Size
This section examines the impact of population size on S2SMA’s performance. In total, 2 experiments with populations of 10 and 30 were conducted for comparison and analysis. As shown in Table 2, the search accuracy of S2SMA tends to decrease when a small population is used, i.e., ten agents. This result is because a greater number gives the potential to discover more regions than a smaller number, thus finding the best solution. Based on this finding, 30 agents have been utilized in the remaining experiments.
Table 2.
Comparison of S2SMA (proposed) with 10 and 30 search agents.
4.1.2. Performance Analysis
This section aims to compare the performance of S2SMA against SMA [28], AOA [59], and recently developed SMA variants. Specifically, LSMA [36], AOSMA [37], and ESMA [56] are executed based on the settings indicated in Table 3. Table 4 presents the results of comparisons between all algorithms for the best, median, worst, mean, and standard deviation. An average of 30 runs were used to determine the ranking. The outcomes show that S2SMA surpassed all other algorithms in most functions. This is because S2SMA can converge quickly and switch to exploitation mode faster. However, the results in single-group m–non-separable functions were not satisfactory. Nevertheless, F8 in this group demonstrates S2SMA ‘s superiority over other algorithms, and F4’s algorithm results in the same group were comparable to those of the other algorithms.
Table 3.
Parameter settings for the studied algorithms.
Table 4.
Results of 1000-D CEC’2010 large-scale functions.
4.1.3. Convergence Evaluation
In this section, Figure 10 depicts the convergence graphs between S2SMA and the original SMA [28], AOA [59], and SMA variants (LSMA [36], AOSMA [37], and ESMA [56]), which are compared in Table 4. The convergence curves in Figure 10 are based on the mean value of the best objective function obtained after 30 runs. The horizontal axis represents the number of iterations, , while the vertical axis represents the highest score obtained. As seen in all functions, the convergence is far better in S2SMA than in other algorithms in most functions. It can be seen in Figure 10 that S2SMA has a much faster convergence speed than the original SMA and others. This is due to the ability of S2SMA to switch to exploitation mode early in the search process and LF’s ability to avoid falling into the local optima.
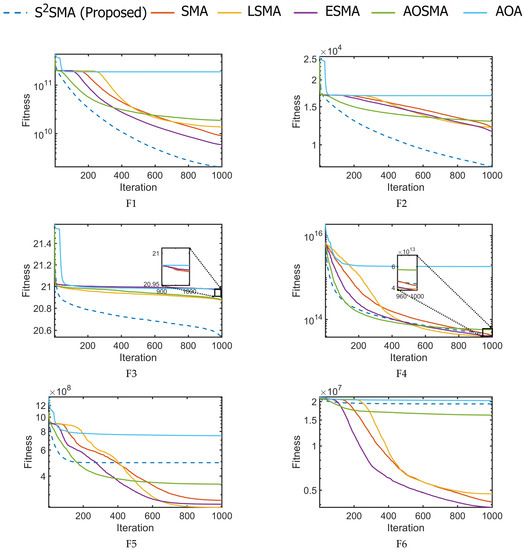
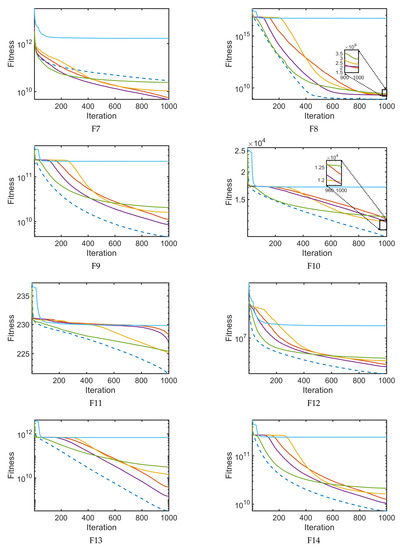
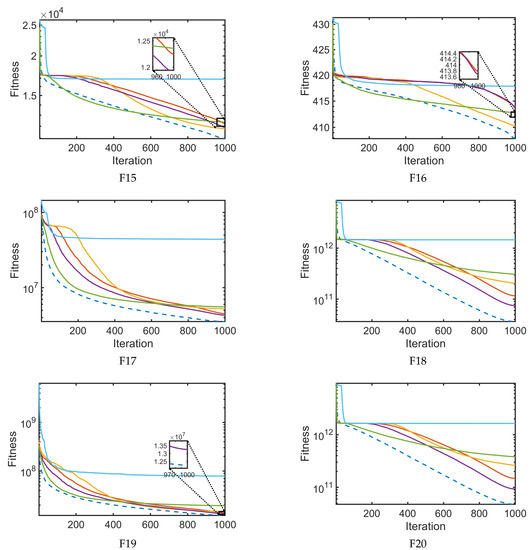
Figure 10.
The convergence curves for large-scale functions F1–F20.
4.1.4. Statistical Analysis
To statistically evaluate the performance of S2SMA compared to the original SMA, AOA, and SMA variants (LSMA, AOSMA, and ESMA), the p-value of the Wilcoxon signed-rank test [67] is computed. Each value above 0.05 is displayed in bold to indicate that the difference is not statistically significant. As shown in Table 5, S2SMA is significantly better than other algorithms on the majority of test problems. This shows that the original SMA’s capability for exploration and exploitation has been significantly enhanced by the addition of embedded rules and operations. However, F4, F5, F6, and F7 yielded no satisfactory results, showing that the difference compared to the proposed approach is not statistically significant. In contrast, S2SMA outperformed every other algorithm in the remaining functions.
Table 5.
p-values for S2SMA versus other competitors on a large scale.
4.1.5. Execution Time Analysis
The software and hardware specifications of the computer used for conducting the experiments in this study are listed in Table 6. This section compares the computational time of S2SMA with that of SMA for large-scale problems. This investigation was performed to determine the overhead related to the embedded rules and operations, shown in Table 7. The average computation time for 30 iterations of the F1 function is provided in Table 7. Clearly, S2SMA required more time due to the calculations of population status and agent location required to execute the embedded rules and operations. However, the computational time required by these rules and operations is reasonable, at less than one second. This value accounts for approximately 7% of the overall time required by SMA. It should be noted that the CPU time consumed by each method is affected by several factors, such as programming language, programming skill, and hardware configuration.
Table 6.
The details of hardware and software settings.
Table 7.
Computational time analysis.
4.2. Evaluation on Face Sketch Recognition
This section evaluates the effectiveness of S2SMA for fine-tuning several pre-trained deep models in handling the face sketch recognition problem. A total of two public datasets were used to evaluate the performances, including XM2VTS [65] and CUFSF [66]. It should be noted that these datasets have been utilized frequently in the literature [25], [68,69]. Partition settings of images contained in each database are shown in Table 8. As in earlier research [1,25], each database was separated into training and testing, as indicated in Table 8. Some example images from XM2VTS and CUFSF are displayed in Figure 11. It is worth mentioning that the datasets were taken without any image enhancements or pre-processing. S2SMA was run 10 times for each dataset with a population size set to 30, and the maximum number of iterations is .
Table 8.
The studied database sketches.
Figure 11.
Sample images from (a) XM2VTS database, and (b) CUFSF database.
4.2.1. Case Study I: XM2VTS Dataset
XM2VTS [65] database was used to evaluate the efficiency of S2SMA in fine-tuning pre-trained deep models. The features were extracted in two ways: using single deep-face models and a multiple deep-face model, as shown previously in the methodology section. In this study, a total of four deep models were used, which are FaceNet [21], ArcFace [22], VGG-Face [23], and DeepFace [24].
The Mean Recognition Rates
This experiment evaluates the performance of S2SMA compared to the original SMA [28], AOA [59], and SMA variants (LSMA [36], AOSMA [37], and ESMA [56]) on face sketch recognition. Table 9 summarizes the mean recognition rate from rank 1 to 10 for XM2VTS. The results were compared using single-model and multiple-model approaches. The proposed model achieved the highest recognition rate at rank 1 among other algorithms and was non-optimized in all experiments. For example, it outperforms rank 1 with 98.81% in multiple-model tests, while the single-model tests closest to it, FaceNet and ArcFace, scored 85.28%. Table 9 also shows that S2SMA reported a 100% accurate recognition rate at rank 2 in multiple-model tests, exceeding other results obtained. The results can be attributed to the efficiency of S2SMA in tuning multiple-model features based on their importance and giving weight to each model based on its efficiency.
Table 9.
A comparison of the effectiveness of several optimization algorithms and a non-optimized model on XMTVTS.
The Cumulative Matching Characteristic
Further study was performed by calculating the cumulative matching characteristic (CMC) generated by S2SMA vs. the non-optimized model for FaceNet, ArcFace, VGG-Face, DeepFace, and multiple-model, as given in Figure 12. CMC evaluates face sketch recognition performance along an x-axis ranging from 1 to . The y-axis displays the recognition rate for each rank value. As demonstrated in Figure 12, S2SMA had a better recognition curve for most ranks between 1 and 10 in all models. Furthermore, as shown in Figure 12, S2SMA achieved 100% precision in multiple-model at rank 2. Moreover, at the level of single-model, S2SMA at rank 1 outperformed the non-optimized in all models.

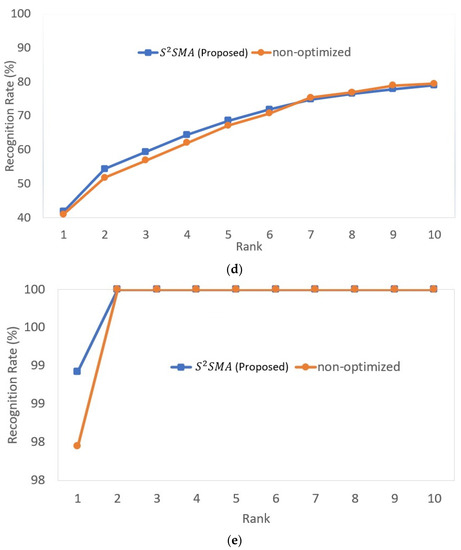
Figure 12.
The CMC results of S2SMA as compared with non-optimized for (a) FaceNet, (b) ArcFace, (c) VGG-Face, (d) DeepFace, and (e) multiple-model.
Fitness Value Analysis
This section aims to compare the performance of S2SMA compared to the original SMA [28], AOA [59], and SMA variants (LSMA [36], AOSMA [37], and ESMA [56]). Table 10 includes the results of the single-model and multiple-model approaches. Table 10 shows the best, worst, average, and mean of all algorithms, as well as the standard deviation. S2SMA received the highest mean value for both single-model and multiple-model approaches out of all the other algorithms. For example, the best mean value for a multiple-model is S2SMA, with a value of −2.34 × 10−1. On the other hand, the worst mean value for the multiple-model approach is ESMA, with a value of −1.77 × 10−1, the lowest among all algorithms.
Table 10.
The fitness outcomes of several single-model and multiple-model approaches on XMTVTS.
Convergence Evaluation
Further investigation was done by analysing the convergence graphs between S2SMA and other algorithms used in Table 10 and plotted in Figure 13. As shown in Figure 13, S2SMA has the fastest and most effective convergence speed, outperforming all other optimizers for single-model and multiple-model face sketch recognition. This demonstrates that S2SMA is capable of addressing large-scale problems. In other words, the ability of all single-model and multiple-model approaches to converge has been greatly improved by tuning features and similarity and by combining all deep-face models.
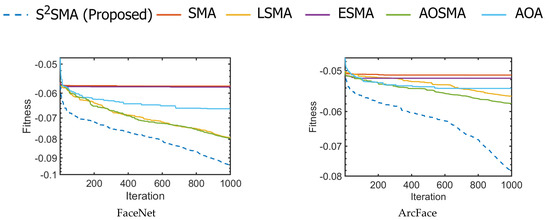
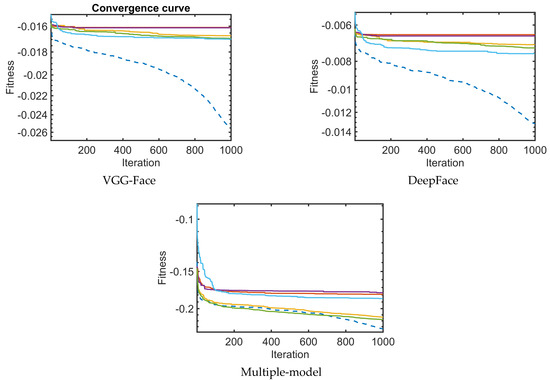
Figure 13.
The convergence curves for several single-model and multiple-model approaches.
Statistical Analysis
To statistically evaluate the performance of S2SMA compared to other algorithms, the p-value of the Wilcoxon signed-rank test [67] is computed. As shown in Table 11, S2SMA is significantly better than other algorithms on all test problems. This shows that the original SMA’s capability for exploration and exploitation has been significantly enhanced by the addition of embedded rules and operations.
Table 11.
p-values for S2SMA versus other competitors on XM2VTS.
4.2.2. Case Study II: CUFSF Dataset
In this section, the CUFSF database was used to evaluate the efficiency of S2SMA. The features were extracted from multiple deep-face models, as explained previously in the methodology section.
The Mean Recognition Rates
This experiment compares the face sketch recognition performance of S2SMA with that of the original SMA [28], AOA [59], and SMA variants (LSMA [36], AOSMA [37], and ESMA [56]). Table 12 summarizes the average recognition rate from rank 1 to 10 for CUFSF. The findings were compared using multiple model approaches, as demonstrated in Table 12. Moreover, the fine-tuned model was compared with the non-optimized model (non-fine-tuned). The results clearly showed that S2SMA achieved the highest recognition rate at rank 1 with 75.82%. This is owing to the benefits of the embedded rules and operations explained in Section 4.1. On the other hand, ESMA [56] had the lowest rank 1 performance in this experiment, with a percentage of 74.35%.
Table 12.
Comparison of the effectiveness of several optimization model algorithms and the non-optimized model on CUFSF.
The Cumulative Matching Characteristic
Further research was conducted by calculating the cumulative matching characteristic (CMC) obtained by the suggested model in comparison to the non-optimized model for the multiple-model approach. As indicated in Figure 14, along an x-axis ranging from 1 to , CMC measures face sketch recognition performance. The y-axis represents the recognition rate for every rank value. Figure 14 demonstrates that the proposed model has a better recognition curve for the majority of rankings between 1 and 10 in the multiple-model approach.
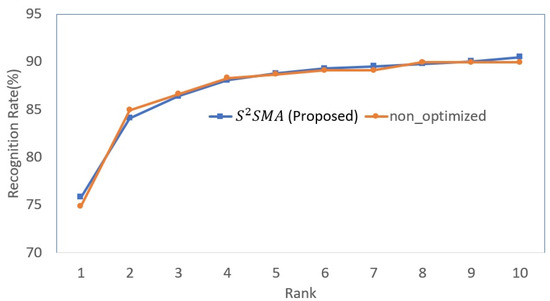
Figure 14.
The CMC results of the proposed method as compared with the non-optimized multiple-model approach.
Fitness Value Analysis
This section compares the fitness of S2SMA with the original SMA, AOA, and SMA variations (LSMA, AOSMA, and ESMA) when it is applied for fine-tuning of multiple deep-face models. Table 13 contains the multiple-model results, showing each algorithm’s best, worst, average, mean, and standard deviation. Table 13 summarizes the obtained mean value from 30 independent runs. As can be seen, S2SMA obtained the greatest mean value among all other algorithms. For instance, the optimal mean value for S2SMA is −1.94 × 10−1. Conversely, the worst mean value for the multiple-model technique is −1.55 × 10−1 for ESMA, which is the lowest among all algorithms.
Table 13.
Multiple-model fitness results on CUFSF.
Comparison with the Reported Results
The proposed face sketch recognition model is compared with previously reported results by other related methods on the CUFUS dataset. Table 14 compares the recognition results’ rank 1 accuracies. As can be seen, the suggested method achieves a rank 1 recognition accuracy value of 75.82, exceeding all competing methods. This is due the advantage of combining the features of several deep models and tuning them using S2SMA.
Table 14.
Accuracy (%) comparisons by different methods on CUFUS.
5. Future Perspective of the Research
In this research, S2SMA has been introduced as an enhanced optimization algorithm for deep-face sketch recognition models. The experimental findings show that S2SMA outperforms related algorithms regarding convergence rate and recognition accuracy. Beyond face sketch recognition, there are several potential future applications for S2SMA, including decision-making, finance, feature selection, and image processing. In addition, S2SMA can be expanded to solve additional face recognition problems, and its scalability and efficacy can be studied further by testing it on larger datasets and more complex models. In terms of applications and utility, the proposed S2SMA algorithm has the potential to significantly improve the accuracy of face sketch recognition, which has important implementations in law enforcement, security, and surveillance systems. The ability to recognize faces from sketches can aid in solving crimes and identifying suspects, especially in cases where photographic evidence is unavailable or unreliable. In addition, a hybrid method can be investigated by combining S2SMA with other optimization algorithms to improve its performance.
6. Conclusions
This work introduces an enhanced optimization algorithm named S2SMA, which has been applied for fine-tuning deep-face sketch recognition models. Many techniques were used to enhance the conducted optimizer, including incorporating embedded control and adding new search operations, namely AOA and LF operations. The experimental analysis performed on CEC’s 2010 large-scale benchmark showed that S2SMA significantly outperformed other related algorithms and had a faster convergence rate. Moreover, for the assessment of S2SMA‘s efficiency in face sketch recognition, two databases were used: XM2VTS and CUFSF. In addition, S2SMA has been applied to fine-tune the features of four deep-face models, namely FaceNet, ArcFace, VGG-Face, and DeepFace. The results of the finely tuned deep models were compared with several other models, such as the non-fine-tuned model, as well as with reported results in the literature. The results showed the superiority of S2SMA in all experiments in rank 1. XM2VTS had a 98.81% recognition rate in the multiple-model, while the single-model results closest to it, FaceNet and ArcFace, scored an 85.28% recognition rate. CUFSF achieves a recognition rate of 75.82% in the multiple-model approach. This considerable result is attributable to the better image quality of XM2VTS compared to CUFSF, which is susceptible to various distortions, shape exaggerations, and illumination problems. Finally, the statistical data analysis for all experiments, including the t-test, demonstrated that S2SMA significantly outperformed other algorithms with a confidence level of 95%.
Author Contributions
Conceptualization, S.A.S. and H.S.; Methodology, K.M.A.; Software, K.M.A.; Validation, S.A.S. and H.S.; Formal analysis, K.M.A.; Investigation, K.M.A.; Resources, K.M.A.; Data curation, K.M.A.; Writing—original draft, K.M.A.; Writing—review & editing, K.M.A. and H.S.; Visualization, S.A.S. and H.S.; Supervision, S.A.S. and H.S.; Project administration, S.A.S. and H.S.; Funding acquisition, S.A.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by the Malaysia Ministry of Higher Education (MOHE) Fundamental Research Grant Scheme (FRGS), no. FRGS/ 1/2019/ICT02/USM/03/3.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Samma, H.; Suandi, S.A.; Mohamad-Saleh, J. Face sketch recognition using a hybrid optimization model. Neural Comput. Appl. 2019, 31, 6493–6508. [Google Scholar] [CrossRef]
- Radman, A.; Suandi, S.A. A Superpixel-Wise Approach for Face Sketch Synthesis. IEEE Access 2019, 7, 108838–108849. [Google Scholar] [CrossRef]
- Radman, A.; Suandi, S.A. BiLSTM regression model for face sketch synthesis using sequential patterns. Neural Comput. Appl. 2021, 33, 12689–12702. [Google Scholar] [CrossRef]
- Radman, A.; Suandi, S.A. Robust face pseudo-sketch synthesis and recognition using morphological-arithmetic operations and HOG-PCA. Multimed. Tools Appl. 2018, 77, 25311–25332. [Google Scholar] [CrossRef]
- Radman, A.; Sallam, A.; Suandi, S.A. Deep residual network for face sketch synthesis. Expert Syst. Appl. 2022, 190, 115980. [Google Scholar] [CrossRef]
- Galea, C.; Farrugia, R.A. Matching Software-Generated Sketches to Face Photographs with a Very Deep CNN, Morphed Faces, and Transfer Learning. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1421–1431. [Google Scholar] [CrossRef]
- Liu, D.; Gao, X.; Wang, N.; Peng, C.; Li, J. Iterative local re-ranking with attribute guided synthesis for face sketch recognition. Pattern Recognit. 2021, 109, 107579. [Google Scholar] [CrossRef]
- Qi, X.; Sun, M.; Wang, W.; Dong, X.; Li, Q.; Shan, C. Face Sketch Synthesis via Semantic-Driven Generative Adversarial Network. In Proceedings of the International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; pp. 1–8. [Google Scholar]
- Bae, S.; Din, N.U.; Park, H.; Yi, J. Face Photo-Sketch Recognition Using Bidirectional Collaborative Synthesis Network. In Proceedings of the 16th International Conference on Ubiquitous Information Management and Communication (IMCOM), Seoul, Republic of Korea, 3–5 January 2022; pp. 1–8. [Google Scholar]
- Wan, W.; Lee, H.J. Generative adversarial multi-task learning for face sketch synthesis and recognition. In Proceedings of the International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 4065–4069. [Google Scholar]
- Tu, C.-T.; Chan, Y.-H.; Chen, Y.-C. Facial Sketch Synthesis Using 2D Direct Combined Model-Based Face-Specific Markov Network. IEEE Trans. Image Process. 2016, 25, 3546–3561. [Google Scholar] [CrossRef]
- Kan, M.; Shan, S.; Zhang, H.; Lao, S.; Chen, X. Multi-view discriminant analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 188–194. [Google Scholar] [CrossRef] [PubMed]
- Huo, J.; Gao, Y.; Shi, Y.; Yin, H. Cross-Modal Metric Learning for AUC Optimization. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 4844–4856. [Google Scholar] [CrossRef]
- Han, H.; Klare, B.F.; Bonnen, K.; Jain, A.K. Matching Composite Sketches to Face Photos: A Component-Based Approach. IEEE Trans. Inf. Forensics Secur. 2012, 8, 191–204. [Google Scholar] [CrossRef]
- Klare, B.; Li, Z.; Jain, A.K. Matching Forensic Sketches to Mug Shot Photos. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 639–646. [Google Scholar] [CrossRef] [PubMed]
- Huo, J.; Gao, Y.; Shi, Y.; Yang, W.; Yin, H. Heterogeneous Face Recognition by Margin-Based Cross-Modality Metric Learning. IEEE Trans. Cybern. 2017, 48, 1814–1826. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Xue, X.; Wu, Y.; Mao, X. Matching a composite sketch to a photographed face using fused HOG and deep feature models. Vis. Comput. 2021, 37, 765–776. [Google Scholar] [CrossRef]
- Bhatt, H.S.; Bharadwaj, S.; Singh, R.; Vatsa, M. Memetically Optimized MCWLD for Matching Sketches with Digital Face Images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1522–1535. [Google Scholar] [CrossRef]
- Bhatt, H.S.; Bharadwaj, S.; Singh, R.; Vatsa, M. On matching sketches with digital face images. In Proceedings of the 4th IEEE International Conference on Biometrics: Theory, Applications and Systems (BTAS), Washington, DC, USA, 27–29 September 2010. [Google Scholar]
- Samma, H.; Suandi, S.A.; Mohamad-saleh, J. A Hybrid Deep Learning Model for Face Sketch Recognition. In Proceedings of the 11th International Conference on Robotics, Vision, Signal Processing and Power Applications, Penang, Malaysia, 2022; pp. 545–551. [Google Scholar]
- Champandard, A.J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition; University of Oxford: Oxford, UK, 2015. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Wan, W.; Gao, Y.; Lee, H.J. Transfer deep feature learning for face sketch recognition. Neural Comput. Appl. 2019, 31, 9175–9184. [Google Scholar] [CrossRef]
- Abdullah, J.M.; Ahmed, T. Fitness Dependent Optimizer: Inspired by the Bee Swarming Reproductive Process. IEEE Access 2019, 7, 43473–43486. [Google Scholar] [CrossRef]
- Shamsaldin, A.S.; Rashid, T.A.; Agha, R.A.A.-R.; Al-Salihi, N.K.; Mohammadi, M. Donkey and smuggler optimization algorithm: A collaborative working approach to path finding. J. Comput. Des. Eng. 2019, 6, 562–583. [Google Scholar] [CrossRef]
- Li, S.; Chen, H.; Wang, M.; Heidari, A.A.; Mirjalili, S. Slime mould algorithm: A new method for stochastic optimization. Future Gener. Comput. Syst. 2020, 111, 300–323. [Google Scholar] [CrossRef]
- Hayyolalam, V.; Kazem, A.A.P. Black Widow Optimization Algorithm: A novel meta-heuristic approach for solving engineering optimization problems. Eng. Appl. Artif. Intell. 2020, 87, 103249. [Google Scholar] [CrossRef]
- Połap, D.; Woźniak, M. Red fox optimization algorithm. Expert Syst. Appl. 2021, 166, 114107. [Google Scholar] [CrossRef]
- Hamad, Q.S.; Samma, H.; Suandi, S.A.; Mohamad-Saleh, J. Q-learning embedded sine cosine algorithm (QLESCA). Expert Syst. Appl. 2022, 193, 116417. [Google Scholar] [CrossRef]
- Abualigah, L.; Abd Elaziz, M.; Sumari, P.; Geem, Z.W.; Gandomi, A.H. Reptile Search Algorithm (RSA): A nature-inspired meta-heuristic optimizer. Expert Syst. Appl. 2022, 191, 116158. [Google Scholar] [CrossRef]
- Zhao, S.; Wang, P.; Heidari, A.A.; Chen, H.; Turabieh, H.; Mafarja, M.; Li, C. Multilevel threshold image segmentation with diffusion association slime mould algorithm and Renyi’s entropy for chronic obstructive pulmonary disease. Comput. Biol. Med. 2021, 134, 104427. [Google Scholar] [CrossRef]
- Nguyen, T.-T.; Wang, H.-J.; Dao, T.-K.; Pan, J.-S.; Liu, J.-H.; Weng, S. An Improved Slime Mold Algorithm and its Application for Optimal Operation of Cascade Hydropower Stations. IEEE Access 2020, 8, 226754–226772. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A.; Elaziz, M.A. Improved slime mould algorithm by opposition-based learning and Levy flight distribution for global optimization and advances in real-world engineering problems. J. Ambient. Intell. Humaniz. Comput. 2021, 14, 1163–1202. [Google Scholar] [CrossRef]
- Naik, M.K.; Panda, R.; Abraham, A. Normalized square difference based multilevel thresholding technique for multispectral images using leader slime mould algorithm. J. King Saud Univ. Comput. Inf. Sci. 2020, 34, 4524–4536. [Google Scholar] [CrossRef]
- Naik, M.K.; Panda, R.; Abraham, A. Adaptive opposition slime mould algorithm. Soft Comput. 2021, 25, 14297–14313. [Google Scholar] [CrossRef]
- Kundu, T.; Garg, H. LSMA-TLBO: A hybrid SMA-TLBO algorithm with lévy flight based mutation for numerical optimization and engineering design problems. Adv. Eng. Softw. 2022, 172, 103185. [Google Scholar] [CrossRef]
- Hermosilla, G.; Rojas, M.; Mendoza, J.; Farias, G.; Pizarro, F.T.; Martin, C.S.; Vera, E. Particle Swarm Optimization for the Fusion of Thermal and Visible Descriptors in Face Recognition Systems. IEEE Access 2018, 6, 42800–42811. [Google Scholar] [CrossRef]
- Khan, S.A.; Ishtiaq, M.; Nazir, M.; Shaheen, M. Face recognition under varying expressions and illumination using particle swarm optimization. J. Comput. Sci. 2018, 28, 94–100. [Google Scholar] [CrossRef]
- Subramanian, R.R.; Mohan, H.; Jenny, A.M.; Sreshta, D.; Prasanna, M.L.; Mohan, P. PSO Based Fuzzy-Genetic Optimization Technique for Face Recognition. In Proceedings of the 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 28–29 January 2021; pp. 374–379. [Google Scholar]
- Ahmed, S.; Frikha, M.; Hussein, T.D.H.; Rahebi, J. Optimum Feature Selection with Particle Swarm Optimization to Face Recognition System Using Gabor Wavelet Transform and Deep Learning. BioMed Res. Int. 2021, 2021, 6621540. [Google Scholar] [CrossRef]
- Chalabi, N.E.; Attia, A.; Bouziane, A.; Akhtar, Z. Particle swarm optimization based block feature selection in face recognition system. Multimed. Tools Appl. 2021, 80, 33257–33273. [Google Scholar] [CrossRef]
- Annamalai, P. Automatic Face Recognition Using Enhanced Firefly Optimization Algorithm and Deep Belief Network. Int. J. Intell. Eng. Syst. 2020, 13, 19–28. [Google Scholar] [CrossRef]
- Ahmed, S.; Frikha, M.; Hussein, T.D.H.; Rahebi, J. Harris Hawks Optimization Method based on Convolutional Neural Network for Face Recognition Systems. In Proceedings of the International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA), Ankara, Turkey, 9–11 June 2022; pp. 1–6. [Google Scholar]
- Alsubai, S.; Hamdi, M.; Abdel-Khalek, S.; Alqahtani, A.; Binbusayyis, A.; Mansour, R.F. Bald eagle search optimization with deep transfer learning enabled age-invariant face recognition model. Image Vis. Comput. 2022, 126, 104545. [Google Scholar] [CrossRef]
- Ren, D.; Yang, J.; Wei, Z. Multi-Level Cycle-Consistent Adversarial Networks with Attention Mechanism for Face Sketch-Photo Synthesis. Sensors 2022, 22, 6725. [Google Scholar] [CrossRef] [PubMed]
- Rizkinia, M.; Faustine, N.; Okuda, M. Conditional Generative Adversarial Networks with Total Variation and Color Correction for Generating Indonesian Face Photo from Sketch. Appl. Sci. 2022, 12, 10006. [Google Scholar] [CrossRef]
- Zhong, K.; Chen, Z.; Liu, C.; Wu, Q.M.J.; Duan, S. Unsupervised self-attention lightweight photo-to-sketch synthesis with feature maps. J. Vis. Commun. Image Represent. 2023, 90, 103747. [Google Scholar] [CrossRef]
- Peng, C.; Zhang, C.; Liu, D.; Wang, N.; Gao, X. Face photo-sketch synthesis via intra-domain enhancement. Knowl.-Based Syst. 2023, 259, 110026. [Google Scholar] [CrossRef]
- Peng, Y.; Zhao, C.; Xie, H.; Fukusato, T.; Miyata, K. DiffFaceSketch: High-Fidelity Face Image Synthesis with Sketch-Guided Latent Diffusion Model. arXiv 2023, arXiv:2302.06908. [Google Scholar]
- Singh, A.; Kushwaha, S.; Alarfaj, M.; Singh, M. Comprehensive Overview of Backpropagation Algorithm for Digital Image Denoising. Electronics 2022, 11, 1590. [Google Scholar] [CrossRef]
- Hassan, M.H.; Kamel, S.; Abualigah, L.; Eid, A. Development and application of slime mould algorithm for optimal economic emission dispatch. Expert Syst. Appl. 2021, 182, 115205. [Google Scholar] [CrossRef]
- Liu, L.; Zhao, D.; Yu, F.; Heidari, A.A.; Ru, J.; Chen, H.; Mafarja, M.; Turabieh, H.; Pan, Z. Performance optimization of differential evolution with slime mould algorithm for multilevel breast cancer image segmentation. Comput. Biol. Med. 2021, 138, 104910. [Google Scholar] [CrossRef] [PubMed]
- Lin, H.; Ahmadianfar, I.; Golilarz, N.A.; Jamei, M.; Heidari, A.A.; Kuang, F.; Zhang, S.; Chen, H. Adaptive slime mould algorithm for optimal design of photovoltaic models. Energy Sci. Eng. 2022, 10, 2035–2064. [Google Scholar] [CrossRef]
- Naik, M.K.; Panda, R.; Abraham, A. An entropy minimization based multilevel colour thresholding technique for analysis of breast thermograms using equilibrium slime mould algorithm. Appl. Soft Comput. 2021, 113, 107955. [Google Scholar] [CrossRef]
- Chauhan, S.; Vashishtha, G.; Kumar, A. A symbiosis of arithmetic optimizer with slime mould algorithm for improving global optimization and conventional design problem. J. Supercomput. 2022, 78, 6234–6274. [Google Scholar] [CrossRef]
- Altay, O. Chaotic slime mould optimization algorithm for global optimization. Artif. Intell. Rev. 2022, 55, 3979–4040. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A.; Mirjalili, S.; Abd Elaziz, M.; Gandomi, A.H. The Arithmetic Optimization Algorithm. Comput. Methods Appl. Mech. Eng. 2021, 376, 113609. [Google Scholar] [CrossRef]
- Cui, Z.; Hou, X.; Zhou, H.; Lian, W.; Wu, J. Modified Slime Mould Algorithm via Levy Flight. In Proceedings of the 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI 2020), Chengdu, China, 17–19 October 2020; pp. 1109–1113. [Google Scholar]
- Deepa, R.; Venkataraman, R. Enhancing Whale Optimization Algorithm with Levy Flight for coverage optimization in wireless sensor networks. Comput. Electr. Eng. 2021, 94, 107359. [Google Scholar] [CrossRef]
- Iacca, G.; dos Santos Junior, V.C.; Veloso de Melo, V. An improved Jaya optimization algorithm with Lévy flight. Expert Syst. Appl. 2021, 165, 113902. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Futur. Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Ke, T.; Li, X.; Omidvar, M.N.; Yang, Z.; Thomas, W. Benchmark Functions for the CEC’2013 Special Session and Competition on Large-Scale Global Optimization; University of Science and Technology of China: Hefei, China, 2010; pp. 1–21. [Google Scholar]
- Messer, K.; Matas, J.; Kittler, J.; Luettin, J.; Maitre, G. XM2VTSDB: The extended M2VTS database. In Proceedings of the 2nd International Conference on Audio and Video-Based Biometric Person Authentication, Washington, DC, USA, 22–24 March 1999; Volume 964, pp. 965–966. [Google Scholar]
- Zhang, W.; Wang, X.; Tang, X. Coupled information-theoretic encoding for face photo-sketch recognition. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 513–520. [Google Scholar]
- García, S.; Fernández, A.; Luengo, J.; Herrera, F. Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power. Inf. Sci. 2010, 180, 2044–2064. [Google Scholar] [CrossRef]
- Li, P.; Sheng, B.; Chen, C.L.P. Face Sketch Synthesis Using Regularized Broad Learning System. In IEEE Transactions on Neural Networks and Learning Systems; IEEE: New York, NY, USA, 2021; pp. 5346–5360. [Google Scholar]
- Wang, N.; Gao, X.; Sun, L.; Li, J. Bayesian Face Sketch Synthesis. IEEE Trans. Image Process. 2017, 26, 1264–1274. [Google Scholar] [CrossRef] [PubMed]
- Galoogahi, H.K.; Sim, T. Inter-modality face sketch recognition. In Proceedings of the International Conference on Multimedia and Expo, Melbourne, VIC, Australia, 9–13 July 2012; pp. 224–229. [Google Scholar]
- Lenc, L.; Král, P. Automatic face recognition system based on the SIFT features. Comput. Electr. Eng. 2015, 46, 256–272. [Google Scholar] [CrossRef]
- Ding, C.; Choi, J.; Tao, D.; Davis, L.S. Multi-Directional Multi-Level Dual-Cross Patterns for Robust Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 518–531. [Google Scholar] [CrossRef] [PubMed]


















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).