Abstract
In this paper, we consider the problem of estimating the time-dependent ability of workers participating in distributed matrix-vector multiplication over heterogeneous clusters. Specifically, we model the workers’ ability as a latent variable and introduce a log-normally distributed working rate as a function of the latent variable with parameters so that the working rate increases as the latent ability of workers increases, and takes positive values only. This modeling is motivated by the need to reflect the impact of time-dependent external factors on the workers’ performance. We estimate the latent variable and parameters using the expectation-maximization (EM) algorithm combined with the particle method. The proposed estimation and inference on the working rates are used to allocate tasks to the workers to reduce expected latency. From simulations, we observe that our estimation and inference on the working rates are effective in reducing expected latency.
1. Introduction
In order to meet the ever-growing demand for massive-scale computations using a large amount of data, distributed computing systems have become a central part of many machine learning algorithms [1]. However, distributed computing systems often face the problem of waiting for slow workers, called stragglers [2]. To overcome this issue and provide straggler tolerance, Lee et al. introduced redundancy to distributed matrix multiplication [3]. Specifically, the authors show that computational latency can be reduced using the maximum distance separable (MDS) code, since collecting any out of n workers’ results would complete the assigned task.
Including the idea proposed by Lee et al. [3], there has been a growing body of work using coding to mitigate the straggler problem in homogeneous clusters. This includes coding for high-dimensional matrix multiplication [4,5], matrix multiplication that considers the architecture of practical systems [6], gradient descent [7,8,9], convolution [10], and non-linear computation using a learning-based approach [11]. Mitigating the effects of stragglers is not limited to environments that consider computing clusters but can also be used in many types of distributed computing architectures that may struggle with stragglers or failures. Examples include fog computing, computation with a deadline, mobile edge computing, layered architecture of edge-assisted Internet of Things, and federated learning [10,12,13].
The system designs under homogeneous assumptions in potentially heterogeneous clusters can significantly reduce the overall performance [14]. For example, suppose that we assign the same amount of tasks to two workers with different computing capabilities. Consider a time for two workers to finish the tasks. A worker with relatively large computing capabilities takes less time to complete the given task than a worker with relatively small computing capabilities, on average. Thus, the expected time to complete the entire task is highly dependent on the time for a worker with relatively small computing capabilities to finish the task. In other words, the uniform load allocation to workers without considering the heterogeneous characteristics of the workers’ computing capabilities can lead to the performance degradation of computing systems. Reflecting on these points, research has been conducted under the assumption of heterogeneous clusters [15,16]. In [15], the authors present an asymptotically optimal load allocation to minimize the expected task completion delay for fully heterogeneous clusters. Similarly, in [16], an optimal load allocation is proposed to minimize the expected execution time under the assumption of group heterogeneity, which means that workers in different groups have different latency statistics.
In this work, we consider a scenario where the ability of each heterogeneous worker changes over time. While the work of [15,16] covers distributed computation in a heterogeneous environment, the authors assume that each worker’s ability is a fixed known constant. However, in reality, even workers designed to maintain a constant level of ability can have time-dependent abilities due to external factors such as changes in temperature and humidity over time [17]. If we do not estimate workers’ abilities, the basic load allocation method would be the uniform load allocation, which assigns the same amount of tasks to each worker. However, as we mentioned earlier, this load allocation method can potentially lead to a loss of system performance. Thus, the estimation of workers’ abilities is essential to improve system latency.
We model the aggregated impact of such factors on the worker’s ability as a normal distribution and set the worker’s ability as a latent variable. As demonstrated in several prior works [3,4,6,15,16], it is widely accepted that the runtime of a worker is often modeled by an exponential distribution. We define the working rate of a worker as the rate of the exponentially distributed runtime and assume that the working rate is log-normally distributed with two parameters: the mean and standard deviation of the logarithm of the working rate, respectively. The log-normal distribution is a good fit for the working rate since it ensures that the working rate takes only positive values and increases as the latent ability of a worker increases. We aim to estimate the latent variable and parameters associated with the ability/working rate of the worker so that one can properly allocate the workload on the workers in distributed computing. Many pieces of research have been devoted to the analysis of the time-series data with latent variables from different points of view [18,19,20,21]. In this paper, we employ particle methods to deal with both the estimation of parameters and the inference of latent variables.
Contribution: The key contributions of this work are summarized as follows.
- To the best of our knowledge, we first model the workers’ ability that changes over time with latent variables.
- We present an estimation algorithm for the parameters and latent variables of the workers’ ability using the expectation maximization (EM) algorithm combined with the particle method.
- We verify the validity of the presented algorithm with Monte Carlo simulations.
- We confirm the validity of our inference by verifying that the load allocation based on the estimated workers’ ability achieves the lower bound of the expected execution time.
2. Preliminaries
In this section, we describe our system model and model assumptions. Then an optimal load allocation is introduced according to the system model and the model assumptions.
2.1. System Model
We focus on the distributed matrix-vector multiplication over a master–worker setup in time-dependent heterogeneous clusters (described in Figure 1). At time t, we assign a task to compute the multiplication of and to the N distributed workers with different runtimes for a given matrix and the input vector . We assume that N workers are divided into G groups. Each group has a different number of workers and a different working rate. The workers in each group have the same working rate. We denote the number of workers in group i as , which implies that
The tasks are successively assigned to the workers at time points . To demonstrate our computation model, we present the uncoded and coded computations for a given task computing the multiplication of and assigned at time t as follows.

Figure 1.
Illustration of the time-dependent heterogeneous cluster (task assigned at time t). The master sends the input vector to the N workers, each of which stores and in uncoded and coded computations, respectively, for and ; (a) worker j in group i computes the multiplication of and with the working rate , and sends back the computation results to the master; (b) worker j in group i computes the multiplication of and with the working rate , and sends back the results to the master.
2.1.1. Uncoded Computation
The rows of are divided into G disjoint submatrices as
where
and
Here, is a submatrix of allocated to worker j in group i for and . Worker j in group i is assigned a subtask to compute the multiplication of and after receiving the input vector from the master. Then, worker j in group i computes the multiplication of and and sends back the result to the master. After the master collects the computation results from all the workers, the desired computation result can be obtained.
2.1.2. Coded Computation
We apply an MDS code to the rows of to obtain the coded matrix . Afterward, the rows of are grouped into N submatrices as
where
is the coded data matrix allocated to the workers in group i and
Here, worker j in group i is assigned a subtask to compute the multiplication of and for and . Worker j in group i sends the computation result to the master after finishing the subtask multiplying and . The master can retrieve the desired computation result by combining the inner products of any coded rows with from the MDS property.
For efficient load allocation to the distributed workers, we need to estimate the workers’ ability, which is assumed to change over time. To do so, for the first T time points , we assign the matrix-vector multiplication tasks using the uncoded computation framework to measure the runtime of all the workers. Here, every worker is assigned the same amount of the subtask, i.e., we set for , , and . Based on the observations on the runtime, we estimate the parameters and latent variables of the working rates. Afterward (), the coded computation is applied using the load allocation based on the estimated working rates. The latent variable is obtained continuously for each time step to properly allocate to the workers. The detailed process of estimating the working rates will be shown in Section 3.
2.2. Model Assumptions
For the task assigned at time t, we assume the time taken for calculating an inner product of a row of ; the input vector follows the shifted exponential distribution with rate , which is defined as the working rate of workers in group i. It is assumed that workers having the same working rate form a group. In other words, workers in a group have the same computing capabilities.
We model the working rate as
using a latent variable Here, denotes the ability of workers in group i for a subtask assigned at time t.
For workers in group i, it is assumed that the zero state follows the normal distribution , where m and are model parameters. Let us denote . We write as the probability density function of given parameters,
The ability of workers may vary over time, which is formulated by
where is a white noise that is independent across group i and time t and follows the normal distribution with zero mean and variance . Here, represents the change in the worker ability as the time elapses from to t. In this work, we assume is given. For a precise formulation, we denote the distribution of given by
which is the probability density function of the normal distribution with mean and variance .
We assume that is a sufficient time interval for the workers to carry out their subtasks allocated at time . We further assume that a task is assigned at successive time points spaced at uniform intervals, i.e., for all . Then, can be rewritten as for notational convenience.
Let be the observed variable that indicates the runtime of worker in group for a given data matrix
with the following probability density function:
Since ’s are independent, we obtain the probability density function g of the observation given by
for , , and . It follows from (5) that we have the probability density function of (observations for workers in group i through the time points ) as follows:
where and denote the number of rows of the data matrix assigned to workers in group i and the ability of workers in group i at time , respectively. Then, for all of the workers,
where , , and represent the overall observations, the workers’ ability, and the number of rows of the assigned matrices for workers in group at time , respectively.
2.3. Optimal Load Allocation
In this subsection, we provide an analysis of load allocation given , for at time t. The previous work [16] presents the optimal load allocation to minimize the expected task runtime. We reproduce the results in [16] with some definitions according to our system model.
Let denote the task runtime taken to calculate the inner product of rows of with at a worker in group i at time t. We assume that s are independent random variables, with the shifted exponential distribution as follows
for and . Here, it is assumed that the cumulative distribution function of the task runtime for a worker in group i to calculate one inner product is
for
Let denote the -th order statistics of random variables following the distribution in (6). We define
as the task runtime for the master to finish the given task.
Theorem 1
(Theorem 2 in [16]). The optimal load allocation to achieve the minimum of
denoted by , is determined as follows:
for , where
and
Here, is the lower branch of the Lambert W function. ( denotes the branch satisfying and ). Then the minimum expected execution time, , is represented as
Then, we have
The first inequality follows from the definition of in (7) and the last inequality comes from Theorem 1.
Next, we introduce the asymptotic behavior of the expected task runtime for the master to finish the given task as follows.
Theorem 2
(Theorem 3 in [16]). For the given optimal load allocation , is asymptotically equivalent to for a sufficiently large N.
As we mentioned in Theorem 1, the optimal load allocation achieves the minimum of
denoted by . For the given and , the constant is a theoretical limit of . From Theorem 2, we can conclude that the load allocation given by (8) is also optimal for from an asymptotical perspective for sufficiently large N.
Remark 1.
For a fixed time t, the working rate of workers in group i is the rate parameter of the shifted exponential distribution. This implies that the expected execution time for a worker in group i to finish the given task is a linear function with respect to the reciprocal of the working rate. A large indicates that workers in group i have a relatively good ability, and the expected execution time for workers in group i tends to be relatively small. As given by Equation (1), a worker’s ability in group i can be represented by , where the log-normal distribution is widely used to describe the distribution of positive random variables.
3. Estimation of Latent Variable and Parameters
For the tasks allocated at time , the master collects the computation result , as well as the observed data which means the runtime of the worker in group for the task assigned at t. After obtaining at , we estimate the parameter and the latent variable using the EM algorithm combined with filtering and smoothing. For , we obtain the estimated based on the particle filtering algorithm and the estimated parameter .
3.1. EM Algorithm
We define the complete-data likelihood functions as follows:
Let
be the complete-data log-likelihood function where log represents the natural logarithm.
The EM algorithm is used to estimate the latent variable and parameter simultaneously, which consists of the following two steps: The first step is called the E-step, which starts by calculating the expected value of the complete data log-likelihood function , defined as
where the expectation is over , more precisely, . Here, is the v-th parameter estimate in the procedure of the EM algorithm. Then we have
Hence, (10) implies that the distribution function for given , , and are required to evaluate the Q function value at each iteration. The methodology for obtaining this distribution will be given in the next subsection. M-step finds the parameter of the next iteration using
The aforementioned EM algorithm is summarized in Algorithm 1.
| Algorithm 1 EM Algorithm. |
|
3.2. Filtering and Smoothing
We resort to the sampling method to approximate the function since the integral (10) is analytically intractable. Our goal is to find an approximation of
Since the distribution is independent across groups, we only need to infer
for each group i, which is the so-called a smoothed estimate. To obtain the smoothed estimate, we use the particle method [22] since it is efficient in high-dimensional sampling and more suitable for filtering [23,24,25] compared to the other competing schemes. Specifically, we choose sequential Monte Carlo (SMC) for the filtering algorithm [26]. The algorithm is based on sequential importance sampling with resampling, which has advantages in controlling the variance of estimates [27]. Note that the SMC algorithm is based on importance sampling, and the sampled object is called the particle (hence, its name).
For workers in group i and the task assigned at t, the number of particle sequences is denoted by L and the -th particle is denoted by . We need to obtain the proposal (importance) distributions and . The optimal choices of the proposal distribution and proposal function are just the distributions of themselves, i.e.,
and
However, evaluating these distributions is intractable in our model. Although there are several possible methods to obtain a proposal distribution, we choose the following, which are known to work well in practice:
and
for . Here, is an initial guess of . These choices ease the computation of importance weights, which are given as follows for the l-th particle sequence:
and
Note that we can skip the resampling step for since the importance weights for are independent of the particles , which means all particles have the same weights. Therefore, has no effects on the algorithm practically.
The algorithm for SMC filtering on workers in group i is summarized in Algorithm 2. One additional shorthand notation
is used in describing Algorithm 2.
| Algorithm 2 The SMC for filtering on workers in group i. |
Input: , , . |
|
|
Output: |
We can effectively sample from the proposal distribution by the adaptive rejection sampling (ARS) [28] since the proposal distribution is log-concave as shown in Proposition 1.
Proposition 1.
The proposal distributions and are log-concave functions with respect to and , respectively.
Proof.
By (11), we have
The second-order partial derivative of the above function with respect to evaluates to
which is negative for all real values . Since the logarithm of the function is concave, the proposal distribution is log-concave in .
Similarly, (12) implies
The second-order partial derivative with respect to gives the following negative value for all real :
Therefore, the proposal distribution is log-concave in . □
We resample at every time step so that the particle sequences have equally weighted samples. In this paper, we use the multinomial resampling [22], which involves sampling from the multinomial distribution. The sampling probabilities are given by the weights of the corresponding original weighted samples.
Then, we can calculate
the approximation of the desired distribution by employing Algorithm 2. However, note that we cannot directly use the output
to the EM algorithm because the particle filtering method often suffers from the sample impoverishment, called the degeneracy problem. When the number of distinct particles
is too small for , it can lead to
is not reliable for . Therefore, from Algorithm 2, we can take the filtered marginal distribution
of the distribution
at time , when we are interested in the online estimation of state variables. We have
for , where is the Dirac delta mass located at . Note that the weights are the same as due to resampling at the last step.
To obtain the smoothed estimate
for the EM algorithm, we rely on the forward-filtering backward-sampling (FFBSa) algorithm using the filtered particles , , in (13). The detailed process is given in Algorithm 3.
| Algorithm 3 FFBSa on workers in group i. |
Input: , , . |
|
Output: |
By Algorithm 3, an estimate of the smoothed marginal distribution of is represented as
for . Now we have the particles from the distribution
Since all particle sequences have the same weights due to resampling, we can approximate the function as follows:
We can run the EM algorithm given in Algorithm 1 by using the particles obtained from Algorithm 3. We begin with the initial guess . In the first iteration, we compute and find
We then run iterations until converges and obtain the converged parameter estimate .
3.3. Inference of
We have the estimated parameter from the EM algorithm. Then the parameter and the given values are omitted for brevity. Once a point estimate of the ability is given, we can directly infer the working rates via (1). We will look at several point estimates in the following subsections based on particle filtering and smoothing algorithms.
3.3.1. Offline Inference
We consider estimating when , where we have observations until time . Then the smoothed estimates can be exploited for this purpose. For example, offline estimation is used in the estimation of the model parameters in Algorithm 1 to avoid the particle degeneracy problem [23]. Given the observations up to time s, we denote the mean of as
For a point estimate on , we take the smoother mean . To calculate the smoothed estimate
is obtained from Algorithm 3 considering the observed data . Then, is represented as
where are the smoothed samples from Algorithm 3.
3.3.2. Online Inference
This subsection considers the case of ; we need a point estimate on for the load allocation at time . The filtered mean can be obtained from Algorithm 2 as soon as we have observations at time . Using the observed data , is expressed as the filtered mean
where are the filtered samples from Algorithm 2. Unlike offline inference, online inference is free from the particle degeneracy problem. We can employ the online inference procedure to obtain the ability estimates simultaneously with the entry of observations.
4. Performance Evaluation
We perform a simulation study in order to validate the suggested inference methods. We fix the true parameters and so that the initial ability of groups has an average of 1 and a standard deviation of 1. We allow a minor degree of ability changes over time by setting . We consider timepoints after the initial time and groups of workers. The number of particles is set to . For simplicity, we assume that all workers are assigned unit loads over time so that for , , and , and each group has the same number of workers so that . We vary the number of workers, , to check that the algorithm works for various situations and to see how the number of workers affects the performance of the proposed algorithms.
We generate the ability of workers using (2) and (3) and use them to generate the observation data that follows the distribution given in (4). This process is repeated 30 times for each case . Then we apply the inference algorithm to estimate the model parameters and the ability of workers.
Table 1 presents the parameter estimates of 30 repeated datasets for the cases . The algorithm estimates the parameters close to the true parameters and in all of the cases of , suggesting that the algorithm works well in estimating the true parameter. Moreover, we can see that the standard deviations of all the estimates over 30 repetitions tend to decrease as increases, implying the larger number of workers in each group tends to yield more accurate estimates.

Table 1.
Parameter estimates for the datasets with the cases . The true parameter is set as , . We present the mean and standard deviation of 30 repetitions for each case.
We now study the accuracy of the ability estimate using the smoothed estimates given in (14). We use three criteria, the Pearson correlation coefficient (COR), the mean squared error (MSE), and the mean absolute error (MAE) to evaluate the performance. The measure COR is the correlation coefficient between the estimated and the true worker abilities over all the groups and timepoints , given by
where and are the means of the estimated and true abilities, respectively. On the other hand, the other measures of MSE and MAE are based on the differences between the true and estimated item qualities over all the groups and timepoints , given by
Table 2 shows the COR, MSE, and MAE results across 30 datasets. The average COR values are almost equal to 1, which suggests that the proposed algorithm properly estimates the true ability of worker groups. The average MSE and MAE values turn out to be close to 0, which suggests that the difference between the true and estimated abilities is almost the same. It is reasonable to have fewer discrepancies between the true and estimated values in the case of large since we have more observations.
Table 2.
COR, MSE, and MAE results for the datasets with the cases . We present the mean and standard deviations of 30 repetitions for each case.
We also depict the three measures in Figure 2, where the three measures are computed at each time . The at each time is given by
where and are the means of the estimated and true abilities at each time, respectively. The other two measures are represented by
at each time . We can see the errors of estimates tend to be uniform over time, implying that the ability estimates can be reliable at any time point.
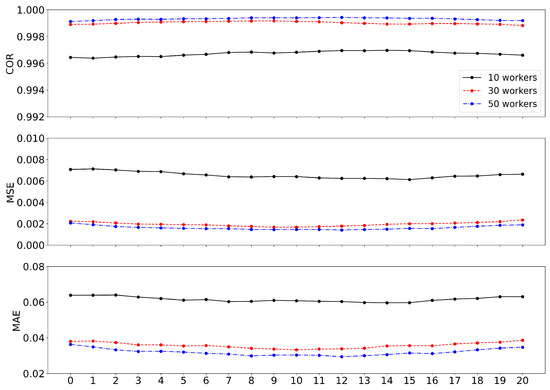
Figure 2.
, , and results for the datasets with the cases for each time .
Figure 3 presents the true and estimated abilities for each group for the first dataset of the case . The true abilities tend to lie within the standard deviation of the particle sequences, implying that the presented algorithm estimates the true abilities very well. The results for groups 1 and 6 indicate that the estimates can capture increasing or decreasing patterns as well. Figure 3 on the right-hand side shows the analogous plot for the working rate given in (1), suggesting that the ability estimates are useful for estimating the working rates. Note that the estimated working rates are quite accurate for a broad range of working rates. In conclusion, the simulation result demonstrates that the estimation/inference works well for both model parameters and workers’ abilities.
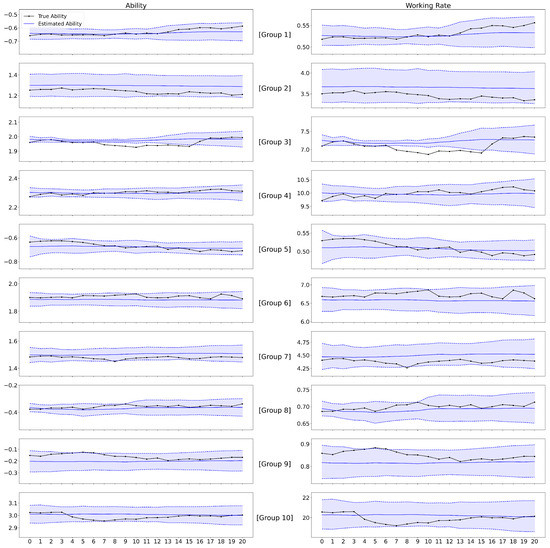
Figure 3.
The ability (left) and working rate (right) estimates for all of the groups of the first dataset in the case of . The x-axis represents time. The true ability and working rate for each group are represented as black solid lines with markers. The estimated ability and working rate values are represented as blue solid lines. The dashed line represents the standard deviation of particle sequences for each group.
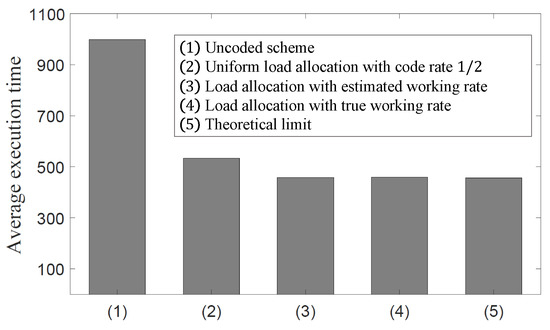
In Figure 4, we compare the expected execution time of the uncoded scheme, the uniform load allocation with code rate , the load allocation in (8) with the true working rates, and the load allocation in (8) with estimated working rates. For performance comparisons, the following simulations are conducted with the fixed parameters and , . Moreover, we set , , , and the true working rate at time . At time T, the true working rate varies to . We obtain the estimated working rates of the groups using the proposed algorithms. This simulation shows that the load allocation in (8) with the estimated working rates can achieve the same performance as the optimal load allocation in (8) with the true working rates. It is also observed that the load allocation in (8) with the estimated working rates shows 54% and 14% reductions in the expected execution times compared to the uncoded scheme and the uniform load allocation with code rate , respectively. This result demonstrates that our estimation and the inference of the latent variable are valid in terms of the expected execution time.
5. Concluding Remarks
In this paper, we model the time-varying ability of workers in heterogeneous distributed computing as latent variables. Since we allow for the ability to change over time, we employ a particle method to infer the latent variables. We present a method for estimating the parameters of the working rate with the latent variable using the EM algorithm combined with sequential Monte Carlo (SMC) for filtering and FFBSa. Monte Carlo simulations verify that the proposed algorithm works reasonably well in estimating the workers’ ability as well as the model parameters. Particularly, the estimation of workers’ ability shows great performance in terms of two measures: COR and MSE between the true and estimated ability.
Exploiting the proposed estimation of the workers’ ability, one can devise the optimal load allocation for minimizing the latency in the heterogeneous distributed computation with workers having time-varying abilities. Numerical simulations show that the load allocation with the estimated working rates achieves the theoretical limit of the expected execution time and reduces the expected execution time by up to 54% compared to existing schemes.
Author Contributions
Conceptualization, D.K. and H.J.; methodology, D.K. and H.J.; software, D.K., S.L. and H.J.; validation, D.K. and H.J.; formal analysis, D.K. and H.J.; writing—original draft preparation, D.K., S.L. and H.J.; writing—review and editing, D.K. and H.J.; supervision, D.K. and H.J.; project administration, D.K. and H.J.; funding acquisition, H.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported in part by a National Research Foundation of Korea (NRF) grant funded by the Korean government (no. 2021R1G1A109410312).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Notations
| Symbol | Description |
| N | The number of workers participating in the matrix multiplication task |
| The number of workers in group i | |
| G | The number of groups |
| () | (coded) Data matrix in at time t |
| () | (Coded) data matrix in at time t allocated to worker j in group i |
| () | (Coded) data matrix in at time t allocated to the workers in group i, |
| i.e., () | |
| Input vector in at time t | |
| The number of rows of the matrix allocated to workers in group i at time t | |
| The ability of workers in group i for a subtask assigned at time t | |
| Working rate of workers in group i at time t | |
| Observed variable that indicates the runtime of worker j in group i at time t | |
| Normal distribution with the mean m and variance | |
| Model parameters, i.e., | |
| Probability density function (pdf) of the initial worker’s ability in group i, | |
| where follows a normal distribution | |
| pdf of worker’s ability in group i at time t provided the worker’s ability | |
| at the previous time | |
| pdf of the runtime of worker j in group i at time t, given the workers’ | |
| ability and load allocation |
| White noise that is independent across group i and time t and follows normal | |
| distribution | |
| Task runtime taken to calculate the multiplication of and at a worker | |
| in group i at time t | |
| Task runtime for the master to finish the given task |
References
- Dean, J.; Corrado, G.; Monga, R.; Chen, K.; Devin, M.; Mao, M.; Senior, A.; Tucker, P.; Yang, K.; Le, Q.V. Large scale distributed deep networks. Proc. Adv. Neural Inform. Process. Syst. (NIPS) 2012, 1, 1223–1231. [Google Scholar]
- Dean, J.; Barroso, L.A. The tail at scale. Commun. ACM 2013, 56, 74–80. [Google Scholar] [CrossRef]
- Lee, K.; Lam, M.; Pedarsani, R.; Papailiopoulos, D.; Ramchandran, K. Speeding up distributed machine learning using codes. IEEE Trans. Inf. Theory 2018, 64, 1514–1529. [Google Scholar] [CrossRef]
- Lee, K.; Suh, C.; Ramchandran, K. High-dimensional coded matrix multiplication. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2418–2422. [Google Scholar]
- Yu, Q.; Maddah-Ali, M.; Avestimehr, S. Polynomial codes: An optimal design for high-dimensional coded matrix multiplication. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Los Angeles, CA, USA, 4–9 December 2017; pp. 4403–4413. [Google Scholar]
- Park, H.; Lee, K.; Sohn, J.-Y.; Suh, C.; Moon, J. Hierarchical coding for distributed computing. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 1630–1634. [Google Scholar]
- Tandon, R.; Lei, Q.; Dimakis, A.G.; Karampatziakis, N. Gradient coding: Avoiding stragglers in distributed learning. In Proceedings of the International Conference Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3368–3376. [Google Scholar]
- Raviv, N.; Tandon, R.; Dimakis, A.; Tamo, I. Gradient coding from cyclic MDS codes and expander graphs. In Proceedings of the International Conference Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4305–4313. [Google Scholar]
- Ozfaturay, E.; Gündüz, D.; Ulukus, S. Speeding up distributed gradient descent by utilizing non-persistent stragglers. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019. [Google Scholar]
- Dutta, S.; Cadambe, V.; Grover, P. Coded convolution for parallel and distributed computing within a deadline. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2403–2407. [Google Scholar]
- Kosaian, J.; Rashmi, K.V.; Venkataraman, S. Learning-Based Coded Computation. IEEE J. Sel. Areas Commun. 2020, 1, 227–236. [Google Scholar] [CrossRef]
- Li, S.; Maddah-Ali, M.A.; Avestimehr, A.S. Coding for distributed fog computing. IEEE Commun. Mag. 2017, 55, 34–40. [Google Scholar] [CrossRef]
- Fu, X.; Wang, Y.; Yang, Y.; Postolache, O. Analysis on cascading reliability of edge-assisted Internet of Things. Reliab. Eng. Syst. Saf. 2022, 223, 108463. [Google Scholar] [CrossRef]
- Zaharia, M.; Konwinski, A.; Joseph, A.D.; Katz, R.H.; Stoica, I. Improving mapreduce performance in heterogeneous environments. In Proceedings of the USENIX Symposium on Operating Systems Design Implement (OSDI), San Diego, CA, USA, 8–10 December 2008; pp. 29–42. [Google Scholar]
- Reisizadeh, A.; Prakash, S.; Pedarsani, R.; Avestimehr, S. Coded computation over heterogeneous clusters. IEEE Trans. Inf. Theory. 2019, 65, 4227–4242. [Google Scholar] [CrossRef]
- Kim, D.; Park, H.; Choi, J.K. Optimal load allocation for coded distributed computation in heterogeneous clusters. IEEE Trans. Commun. 2021, 69, 44–58. [Google Scholar] [CrossRef]
- Gao, J. Machine Learning Applications for Data Center Optimization. Google White Pap. Available online: https://research.google/pubs/pub42542/ (accessed on 6 April 2023).
- Tang, B.; Matteson, D.S. Probabilistic transformer for time series analysis. Adv. Neural Inf. Process. Syst. 2021, 34, 23592–23608. [Google Scholar]
- Lin, Y.; Koprinska, I.; Rana, M. SSDNet: State space decomposition neural network for time series forecasting. In Proceedings of the 2021 IEEE International Conference on Data Mining (ICDM), Auckland, New Zealand, 7–10 December 2021; pp. 370–378. [Google Scholar]
- Hu, Y.; Jia, X.; Tomizuka, M.; Zhan, W. Causal-based time series domain generalization for vehicle intention prediction. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 7806–7813. [Google Scholar]
- Jung, H.; Lee, J.G.; Kim, S.H. On the analysis of fitness change: Fitness-popularity dynamic network model with varying fitness. J. Stat. Mech. Theory Exp. 2020, 4, 043407. [Google Scholar] [CrossRef]
- Kitagawa, G. Monte Carlo filter and smoother for non-Gaussian nonlinear state space models. J. Comput. Graph. Stat. 1996, 5, 1–25. [Google Scholar]
- Kantas, N.; Doucet, A.; Singh, S.S.; Maciejowski, J.; Chopin, N. On particle methods for parameter estimation in state-space models. Stat. Sci. 2015, 30, 328–351. [Google Scholar] [CrossRef]
- Pitt, M.K.; Shephard, N. Filtering via simulation: Auxiliary particle filters. J. Am. Stat. Assoc. 1999, 94, 590–599. [Google Scholar] [CrossRef]
- Carpenter, J.; Clifford, P.; Fearnhead, P. Improved particle filter for nonlinear problems. IEE Proc. Radar Sonar Navig. 1999, 146, 2–7. [Google Scholar] [CrossRef]
- Doucet, A.; De Freitas, N.; Gordon, N. An introduction to sequential Monte Carlo methods. Seq. Monte Carlo Methods Pract. 2001, 3–14. [Google Scholar] [CrossRef]
- Doucet, A.; Johansen, A.M. A tutorial on particle filtering and smoothing: Fifteen years later. Handb. Nonlinear Filter 2009, 12, 656–704. [Google Scholar]
- Gilks, W.R.; Wild, P. Adaptive rejection sampling for Gibbs sampling. Appl. Statist. 1992, 41, 337–348. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).