
A Time-Series Model for Varying Worker Ability in Heterogeneous Distributed Computing Systems

Abstract
1. Introduction
- To the best of our knowledge, we first model the workers’ ability that changes over time with latent variables.
- We present an estimation algorithm for the parameters and latent variables of the workers’ ability using the expectation maximization (EM) algorithm combined with the particle method.
- We verify the validity of the presented algorithm with Monte Carlo simulations.
- We confirm the validity of our inference by verifying that the load allocation based on the estimated workers’ ability achieves the lower bound of the expected execution time.
2. Preliminaries
2.1. System Model

2.1.1. Uncoded Computation
2.1.2. Coded Computation
2.2. Model Assumptions
2.3. Optimal Load Allocation
3. Estimation of Latent Variable and Parameters
3.1. EM Algorithm
| Algorithm 1 EM Algorithm. |
|
3.2. Filtering and Smoothing
| Algorithm 2 The SMC for filtering on workers in group i. |
Input: , , . |
|
|
Output: |
| Algorithm 3 FFBSa on workers in group i. |
Input: , , . |
|
Output: |
3.3. Inference of
3.3.1. Offline Inference
3.3.2. Online Inference
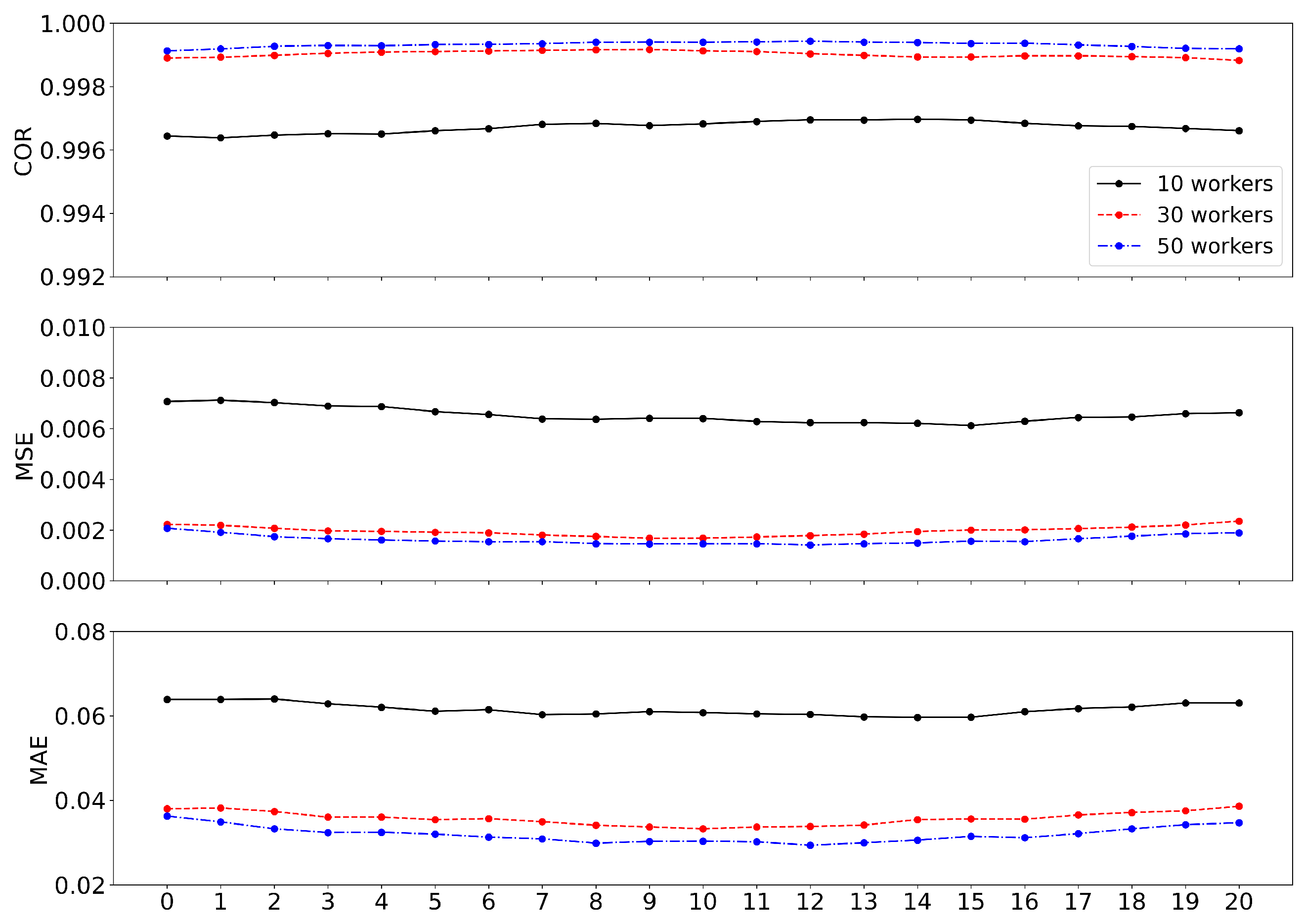
4. Performance Evaluation
5. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Notations
| Symbol | Description |
| N | The number of workers participating in the matrix multiplication task |
| The number of workers in group i | |
| G | The number of groups |
| () | (coded) Data matrix in at time t |
| () | (Coded) data matrix in at time t allocated to worker j in group i |
| () | (Coded) data matrix in at time t allocated to the workers in group i, |
| i.e., () | |
| Input vector in at time t | |
| The number of rows of the matrix allocated to workers in group i at time t | |
| The ability of workers in group i for a subtask assigned at time t | |
| Working rate of workers in group i at time t | |
| Observed variable that indicates the runtime of worker j in group i at time t | |
| Normal distribution with the mean m and variance | |
| Model parameters, i.e., | |
| Probability density function (pdf) of the initial worker’s ability in group i, | |
| where follows a normal distribution | |
| pdf of worker’s ability in group i at time t provided the worker’s ability | |
| at the previous time | |
| pdf of the runtime of worker j in group i at time t, given the workers’ | |
| ability and load allocation |
| White noise that is independent across group i and time t and follows normal | |
| distribution | |
| Task runtime taken to calculate the multiplication of and at a worker | |
| in group i at time t | |
| Task runtime for the master to finish the given task |
References
- Dean, J.; Corrado, G.; Monga, R.; Chen, K.; Devin, M.; Mao, M.; Senior, A.; Tucker, P.; Yang, K.; Le, Q.V. Large scale distributed deep networks. Proc. Adv. Neural Inform. Process. Syst. (NIPS) 2012, 1, 1223–1231. [Google Scholar]
- Dean, J.; Barroso, L.A. The tail at scale. Commun. ACM 2013, 56, 74–80. [Google Scholar] [CrossRef]
- Lee, K.; Lam, M.; Pedarsani, R.; Papailiopoulos, D.; Ramchandran, K. Speeding up distributed machine learning using codes. IEEE Trans. Inf. Theory 2018, 64, 1514–1529. [Google Scholar] [CrossRef]
- Lee, K.; Suh, C.; Ramchandran, K. High-dimensional coded matrix multiplication. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2418–2422. [Google Scholar]
- Yu, Q.; Maddah-Ali, M.; Avestimehr, S. Polynomial codes: An optimal design for high-dimensional coded matrix multiplication. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Los Angeles, CA, USA, 4–9 December 2017; pp. 4403–4413. [Google Scholar]
- Park, H.; Lee, K.; Sohn, J.-Y.; Suh, C.; Moon, J. Hierarchical coding for distributed computing. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 1630–1634. [Google Scholar]
- Tandon, R.; Lei, Q.; Dimakis, A.G.; Karampatziakis, N. Gradient coding: Avoiding stragglers in distributed learning. In Proceedings of the International Conference Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3368–3376. [Google Scholar]
- Raviv, N.; Tandon, R.; Dimakis, A.; Tamo, I. Gradient coding from cyclic MDS codes and expander graphs. In Proceedings of the International Conference Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4305–4313. [Google Scholar]
- Ozfaturay, E.; Gündüz, D.; Ulukus, S. Speeding up distributed gradient descent by utilizing non-persistent stragglers. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019. [Google Scholar]
- Dutta, S.; Cadambe, V.; Grover, P. Coded convolution for parallel and distributed computing within a deadline. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2403–2407. [Google Scholar]
- Kosaian, J.; Rashmi, K.V.; Venkataraman, S. Learning-Based Coded Computation. IEEE J. Sel. Areas Commun. 2020, 1, 227–236. [Google Scholar] [CrossRef]
- Li, S.; Maddah-Ali, M.A.; Avestimehr, A.S. Coding for distributed fog computing. IEEE Commun. Mag. 2017, 55, 34–40. [Google Scholar] [CrossRef]
- Fu, X.; Wang, Y.; Yang, Y.; Postolache, O. Analysis on cascading reliability of edge-assisted Internet of Things. Reliab. Eng. Syst. Saf. 2022, 223, 108463. [Google Scholar] [CrossRef]
- Zaharia, M.; Konwinski, A.; Joseph, A.D.; Katz, R.H.; Stoica, I. Improving mapreduce performance in heterogeneous environments. In Proceedings of the USENIX Symposium on Operating Systems Design Implement (OSDI), San Diego, CA, USA, 8–10 December 2008; pp. 29–42. [Google Scholar]
- Reisizadeh, A.; Prakash, S.; Pedarsani, R.; Avestimehr, S. Coded computation over heterogeneous clusters. IEEE Trans. Inf. Theory. 2019, 65, 4227–4242. [Google Scholar] [CrossRef]
- Kim, D.; Park, H.; Choi, J.K. Optimal load allocation for coded distributed computation in heterogeneous clusters. IEEE Trans. Commun. 2021, 69, 44–58. [Google Scholar] [CrossRef]
- Gao, J. Machine Learning Applications for Data Center Optimization. Google White Pap. Available online: https://research.google/pubs/pub42542/ (accessed on 6 April 2023).
- Tang, B.; Matteson, D.S. Probabilistic transformer for time series analysis. Adv. Neural Inf. Process. Syst. 2021, 34, 23592–23608. [Google Scholar]
- Lin, Y.; Koprinska, I.; Rana, M. SSDNet: State space decomposition neural network for time series forecasting. In Proceedings of the 2021 IEEE International Conference on Data Mining (ICDM), Auckland, New Zealand, 7–10 December 2021; pp. 370–378. [Google Scholar]
- Hu, Y.; Jia, X.; Tomizuka, M.; Zhan, W. Causal-based time series domain generalization for vehicle intention prediction. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 7806–7813. [Google Scholar]
- Jung, H.; Lee, J.G.; Kim, S.H. On the analysis of fitness change: Fitness-popularity dynamic network model with varying fitness. J. Stat. Mech. Theory Exp. 2020, 4, 043407. [Google Scholar] [CrossRef]
- Kitagawa, G. Monte Carlo filter and smoother for non-Gaussian nonlinear state space models. J. Comput. Graph. Stat. 1996, 5, 1–25. [Google Scholar]
- Kantas, N.; Doucet, A.; Singh, S.S.; Maciejowski, J.; Chopin, N. On particle methods for parameter estimation in state-space models. Stat. Sci. 2015, 30, 328–351. [Google Scholar] [CrossRef]
- Pitt, M.K.; Shephard, N. Filtering via simulation: Auxiliary particle filters. J. Am. Stat. Assoc. 1999, 94, 590–599. [Google Scholar] [CrossRef]
- Carpenter, J.; Clifford, P.; Fearnhead, P. Improved particle filter for nonlinear problems. IEE Proc. Radar Sonar Navig. 1999, 146, 2–7. [Google Scholar] [CrossRef]
- Doucet, A.; De Freitas, N.; Gordon, N. An introduction to sequential Monte Carlo methods. Seq. Monte Carlo Methods Pract. 2001, 3–14. [Google Scholar] [CrossRef]
- Doucet, A.; Johansen, A.M. A tutorial on particle filtering and smoothing: Fifteen years later. Handb. Nonlinear Filter 2009, 12, 656–704. [Google Scholar]
- Gilks, W.R.; Wild, P. Adaptive rejection sampling for Gibbs sampling. Appl. Statist. 1992, 41, 337–348. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| m | ||||
|---|---|---|---|---|
| Mean | St. Dev. | Mean | St. Dev. | |
| 10 | 1.0149 | 0.3102 | 0.9720 | 0.2512 |
| 30 | 1.0133 | 0.2538 | 0.9568 | 0.2086 |
| 50 | 1.0382 | 0.2607 | 1.0395 | 0.1977 |
| COR | MSE | MSE | ||||
|---|---|---|---|---|---|---|
| Mean | St. Dev. | Mean | St. Dev. | Mean | St. Dev. | |
| 10 | 0.9967 | 0.0020 | 0.0065 | 0.0034 | 0.0615 | 0.0125 |
| 30 | 0.9990 | 0.0006 | 0.0020 | 0.0007 | 0.0357 | 0.0069 |
| 50 | 0.9993 | 0.0004 | 0.0016 | 0.0005 | 0.0319 | 0.0054 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, D.; Lee, S.; Jung, H. A Time-Series Model for Varying Worker Ability in Heterogeneous Distributed Computing Systems. Appl. Sci. 2023, 13, 4993. https://doi.org/10.3390/app13084993
Kim D, Lee S, Jung H. A Time-Series Model for Varying Worker Ability in Heterogeneous Distributed Computing Systems. Applied Sciences. 2023; 13(8):4993. https://doi.org/10.3390/app13084993
Chicago/Turabian StyleKim, Daejin, Suji Lee, and Hohyun Jung. 2023. "A Time-Series Model for Varying Worker Ability in Heterogeneous Distributed Computing Systems" Applied Sciences 13, no. 8: 4993. https://doi.org/10.3390/app13084993
APA StyleKim, D., Lee, S., & Jung, H. (2023). A Time-Series Model for Varying Worker Ability in Heterogeneous Distributed Computing Systems. Applied Sciences, 13(8), 4993. https://doi.org/10.3390/app13084993