Abstract
In this article, an attempt is made to propose a novel method of lifetime distributions with maximum flexibility using a popular T–X approach together with an exponential distribution, which is known as the New Generalized Logarithmic-X Family (NGLog–X for short) of distributions. Additionally, the generalized form of the Weibull distribution was derived by using the NGLog–X family, known as the New Generalized Logarithmic Weibull (NGLog–Weib) distribution. For the proposed method, some statistical properties, including the moments, moment generating function (MGF), residual and reverse residual life, identifiability, order statistics, and quantile functions, were derived. The estimation of the model parameters was derived by using the well-known method of maximum likelihood estimation (MLE). A comprehensive Monte Carlo simulation study (MCSS) was carried out to evaluate the performance of these estimators by computing the biases and mean square errors. Finally, the NGLog–Weib distribution was implemented on four real biomedical datasets and compared with some other distributions, such as the Alpha Power Transformed Weibull distribution, Marshal Olkin Weibull distribution, New Exponent Power Weibull distribution, Flexible Reduced Logarithmic Weibull distribution, and Kumaraswamy Weibull distribution. The analysis results demonstrate that the new proposed model performs as a better fit than the other competitive distributions.
1. Introduction
To model and analyse lifetime data, probability distributions are essential tools, particularly in the area of biomedical science; see Liu et al. [1]. Various probability distributions have been suggested for modelling lifetime phenomena; for example, the Exponential (Expo), Rayleigh (Ray), and Weibull (Weib) distributions. However, the performance of these aforementioned classical distributions is affected when the phenomena are complex. For illustration, the commonly used Expo distribution performs well for modelling lifetime phenomena based on a constant hazard rate function (HRF), whereas the Ray distribution has the ability to model lifetime phenomena having only an increasing HRF. The Weib distribution is known for its performance, as it has the characteristics of both the Expo and Ray distributions. The Weib distribution can model the phenomena having a monotone (increasing, decreasing, and constant) HRF (see Almalki and Yuan [2], and Liao et al. [3]). However, when the phenomena follow non-monotonic (unimodal, modified unimodal, and bathtub-shaped) HRFs, the Weib distribution may not be a good option. In medical cases, e.g., breast cancer, neck cancer, and bladder cancer, the HRF of the phenomena is shown to have a uni-modal or modified uni-modal shape. The HRF for breast cancer, bladder cancer, and neck cancer has been identified as a uni-modal shape after surgical removal. The cancer recurrence HRF begins to increase in the early stage and gradually decreases after a definite period of time when removed by surgery (Demicheli et al. [4]). Another example of a uni-modal failure rate is infection with some new viruses, where the initial phase increases and then decreases; see, for example, (Liu et al. [1]).
In the recent past, researchers have contributed toward developing new families of continuous probability distributions that are flexible in nature. These flexible distributions are derived by incorporating some additional parameters into the baseline distributions. Here, we refer to some of the newly proposed families of lifetime distributions, including: the Marshall–Olkin Weibull–Generated (MO–Weib–G) family of probability distributions proposed by Klakattawi et al. [5], the Shifted Exponential–G (SExpo–G) family of distributions proposed by Eghwerido et al. [6], the Generalization of Gull Alpha Power (GGAP) family of probability distributions proposed by Kilai et al. [7], the New Flexible Logarithmic–X (NFLog–X) family of probability distributions proposed by Alkhairy et al. [8], the Arcsine–X family of probability distributions proposed by Tung et al. [9], the Truncated family of distributions proposed by Alzaatreh et al. [10], the Transmuted Alpha Power–G (TAP–G) family of Eghwerido et al. [11], the Fréchet Topp Leone–G (FTL–G) family of Reyad et al. [12], the New Extended-Family (NEx-F) of distributions proposed by Zichuan et al. [13], a New Lifetime Exponential–X (NLE–X) family proposed by Huo et al. [14], a New Modified Exponent Power Alpha (NMEPA) family of distributions proposed by Shah et al. [15], and a generalized Alpha Exponent Power (GAEP) Family of distributions proposed by Hussain et al. [16]. For more reading about probability distributions, see Chen et al. [17], Xu et al. [18], Zhang et al. [19], Luo et al. [20], and Zhuang et al. [21].
Zhao et al. [22] have introduced a new method of lifetime distributions by incorporating an additional parameter using the T–X family method (Alzaatreh et al. [23]). The CDF (cumulative distribution function) is given by
where is the shape parameter, and is the CDF of any baseline distribution.
Wang et al. [24] have suggested a new logarithmic family of lifetime distributions, and its CDF is
where and are the additional parameters, and is the CDF of any baseline or classical distribution.
Likewise, another approach has been recommended for the lifetime phenomena modelling named the Log–U (Logarithmic–U) of distributions by Zhao et al. [25]. The CDF of the Log–U family is
where and are the additional parameters, and is the CDF of any baseline or classical distribution.
In this paper, we carry this approach of distribution theory and propose a new family of probability distributions by implementing the T–X family approach (Alzaatreh et al. [23]). The proposed family of distributions gives an appropriate fit for biomedical datasets. Additionally, this study empirically shows that the new extension of the Weib distribution offers an efficient fit to the considered datasets in comparison with well-known distributions (see Section 6).
The work carried out in this paper is outlined and organized in the following sections: In Section 2, the new method of lifetime distributions is derived. In Section 3, a three-parameter special subcase of the proposed class named a New Generalized Logarithmic Weibull (NGLog–Weib) distribution is derived, and the shape of the CDF, PDF (probability density function), and HF (hazard function) are also discussed in the same section. In Section 4, some mathematical and statistical properties of the proposed approach are derived. In Section 5, the estimation methods for estimating the modal parameters are used, as well as in the same section, a brief MCSS is also conducted to assess the behaviour of these estimates. The implementations of the novel-introduced methods on four biomedical datasets are discussed in Section 6.
2. The NGLog–X Family
Let be the PDF of a RV (random variable), say , where for , and let suppose that be a function of CDF of a RV, say , satisfying the conditions given bellow:
- i.
- ;
- ii.
- is monotonically increasing and differentiable; and
- iii.
- as and as .
According to (Alzaatreh et al. [23]), the CDF of the T–X family is defined by
The PDF corresponding to (4) is given by
Using the T–X idea, several novel classes of distributions have been proposed in the literature. Table 1 lists different functions for special members of the T–X family.

Table 1.
Different functions for some members of the T–X family.
Table 1.
Different functions for some members of the T–X family.
| Support of X | Member of T–X Family | |
|---|---|---|
| Beta–G (Eugen et al. [26]) | ||
| Gamma–G type 1 (Zografos and Balakrishnan [27]) | ||
| Gamma–G type 2 (Ristic and Balakrishnan [28]) | ||
| Gamma–G type 3 (Torabi and Montazeri [29]) | ||
| Logistic–X family (Tahir et al. [30]) | ||
| Weighted T–X family (Ahmad et al. [31]) | ||
| New Expo–X family (Shah et al. [32]) | ||
| NGLog–X family (proposed) |
Now, taking inspiration from Equation (4), we propose the novel-introduced family of distributions. Let , and then its CDF is given by
The PDF corresponding to Equation (5) is
Setting and as Equation (6) in Equation (4), we obtain the CDF of the New Generalized Logarithmic–X (NGLog–X) family of lifetime distributions, which is given by
where is an extra shape parameter, and is the CDF of any baseline (or existing) probability distribution which may depend on a parameter vector .
The PDF corresponding to Equation (7) is given by
where,
Furthermore, for and , the SF (survival function) , HF (hazard function) , RHF (reverse hazard function) , and CHF (cumulative hazard function) of the NGLog–X family are shown in Equations (9)–(12):
and
3. NGLog–Weib Distribution
For a three-parameter special case of the NGLog–X family, let us consider the CDF,, and PDF, , of the traditional Weib distribution are and , respectively ( and ), where .
Using in Equation (7), we define the CDF of the NGLog–Weib model. For , the scale parameter, , and shape parameters, and , the CDF of the NGLog–Weib model is as follows,
Plots of the CDF, i.e., and SF (survival function), i.e., of the NGLog–Wei probability model, are given in Figure 1 for (i) 2.0, 6.0, 1.5 (in red), (ii) 3.0, 5.0, 2.3 (in green), (iii) 4.0, 3.0, 2.9 (in black), and (iv) 4.0, 1.5, 3.5 (in blue).
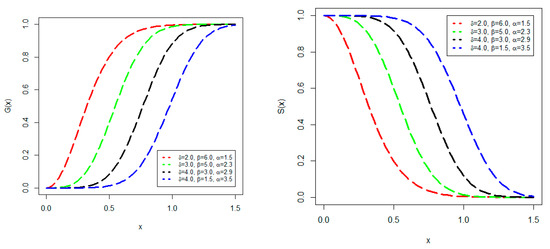
Figure 1.
Plots of the CDF (left) and the SF (right) of the NGLog–Weib model.
Corresponding to in Equation (13), the PDF,, is
For a graphical illustration, some possible behaviours of the PDF of the NGLog–Weib distribution at different parameter values are sketched in Figure 2. The plots are sketched for (i) 3.0, 3.5, 0.3 (in red), (ii) 3.0, 5.0, 1.9 (in green), (iii) 4.5, 3.0, 2.9 (in black), and (iv) 6.5, 1.5, 3.3 (in blue). Figure 2 shows four different shapes of the PDF , including (i) decreasing or a reverse-J pattern (in red), (ii) right-skewed (in green), (iii) symmetrical (in black), and (iv) left-skewed (in blue).
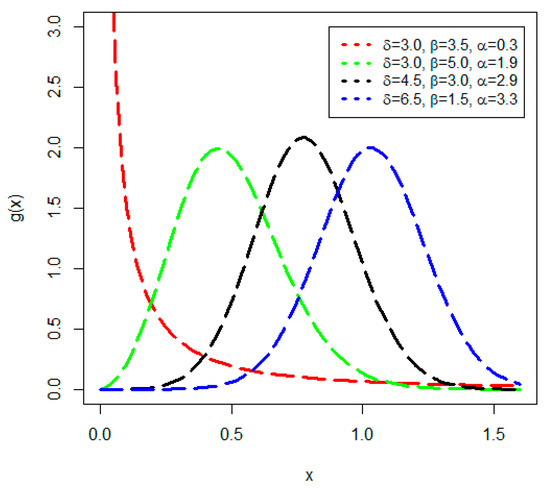
Figure 2.
Plots of the PDF of the NGLog–Weib model.
Furthermore, the hazard function , RHF (reverse hazard function) , and CHF (cumulative hazard function) of the NGLog–Weib are given in Equations (16) to (18), respectively, by
Furthermore, for the various values of the parameters, some possible behaviours of the HF of the NGLog–Weib model are shown in Figure 3 for (i) 10.7, 2.6, 0.5 (in red), (ii) 10.4, 3.5, 0.5 (in green), (iii) 0.5, 0.2, 2.9 (in black), (iv) 6.0, 2.4, 0.3 (in blue), and (iv) 0.5, 0.8, 0.5 (in violet). From Figure 3, we can observe (or examine) that the NGLog–Wieb offers data modelling with increasing, decreasing, uni-model, and bathtub-shaped HFs, .
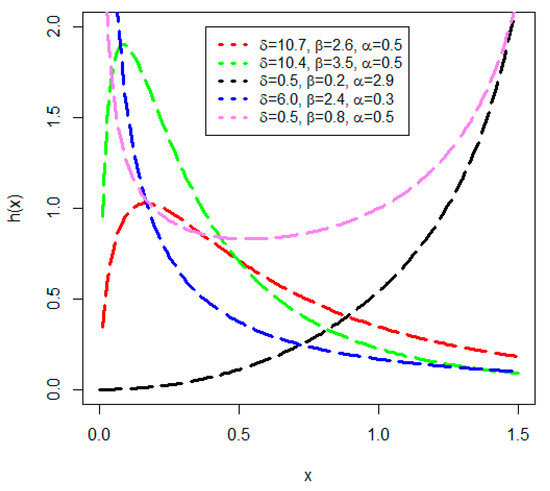
Figure 3.
Plots of the HF of the NGLog–Weib model.
4. Statistical Properties
This section presents some mathematical and statistical properties of the NGLog–X family of probability distributions.
4.1. Moments
We derived a computational representation of the general order moments corresponding to the proposed NGLog–X of distributions. If x is an RV from the NGLog–X family, then about the origin, the moments are given by
Putting the density of the proposed family in Equation (19), we obtain
Using the expansion , where , , and in Equation (20), respectively, then we obtain
where
and
Similarly, using the PDF , a general explicit expression for the MGF (moments generating function) of the NGLog–X is derived as
By simplifying, we obtain the MGF
4.2. Residual and Reverse Residual Life of NGLog–X
In life distributions, the residual lifetime RV is referred to as the “time since failure” and has wide applications in survival analysis. The notation used for the residual lifetime of the NGLog–X RV x is denoted by and is given as
For the NGLog–X RVs, the reverse residual life is :
4.3. The Identifiability Property
The IP is a very worthwhile statistical property that ensures precise inference. In this subsection, we calculated the IP of the NGLog–X family of the distributions. Let and be the two additional parameters having the CDFs and . The parameter is identifiable if . Mathematically, the IP is derived as:
Inserting Equation (7) in Equation (25), we obtain
After simplifying Equation (26), we obtain
By taking logarithm of Equation (27), we obtain
From Equation (28), we observed that . Hence, the parameter, , is identifiable.
4.4. Order Statistics
Let be the set of the i.i.d RVs of the ‘n’ size taken from the NGLog–X family of distributions with the parameters and . Let suppose that the associated OS (order statistics) is . Then, from David [33], the density function (DF) of , say , where , is defined by
Using Equations (7) and (8) in Equation (29), we obtain the order statistics for the proposed family of probability distributions.
4.5. Quantile Function
A QF (quartile function) is used to calculate any of the positional descriptive statistics of the distributions. The QF of the proposed NGLog–X method is the function that satisfies the following nonlinear equations:
By using Equation (7) in Equation (30), we obtain
where u is the solution of .
5. Estimation and Simulations
To obtain the MLEs of the proposed method, we used the method of the maximum likelihood function. In addition, an MCSS was also conducted to assess the performance of the corresponding and .
5.1. Estimation
Various methods of estimation have been developed for estimating the model parameters; however, a well-known method, MLE, is used commonly. Here, from a complete sample only, we define the MLE method for the estimation of the unknown parameters of the NGLog–X family distributions. Suppose that are the observed values of the size “n” selected from the proposed NGLog–X family of distributions with the parameters randomly. Then, the expression of the LF (likelihood function) is acquired as
The corresponding log-LF, , is given by
Using , the partial derivatives are the following equations:
where .
Setting and and solving these equations simultaneously yielded the MLEs of , . Clearly, the resulting equations cannot be solved analytically. Therefore, statistical software can be applied to solve these equations numerically through iterative Newton–Raphson-type algorithms.
5.2. Simulation
Here, in this sub-section, a comprehensive MCSS is conducted to assess the performance of the estimators of the NGLog–Weib distribution by using the R package. The simulation results are calculated for six sets of parameter values: (i) Set I , (ii) Set II , (iii) Set III , (iv) Set IV , (v) Set V , and (vi) Set VI . For each set of the above parameters values, the MCSS replicates are made 1000 times under different sample sizes, . We obtained the average MLEs, MSEs (mean square errors), and biases for each sample size. The numerical values of the biases and the MSEs of the model are calculated as:
and
For the numerical values, the same process is repeated for . The SRs (simulation results) corresponding to Set I and Set II are shown in Table 2. Similarly, the results of Set III and Set IV are provided in Table 3, beside the results of Set V and Set VI, which are provided in Table 4. It is observed from Table 2, Table 3 and Table 4 that the estimated values of are stable, and the MSE of decreases as the sample size increases. Similarly, the values of the biases, , are also decay to zero as the sample size increases.
Table 2.
SRs of the NGLog–Weib distribution for Set I and Set II.
Table 3.
SRs of the NGLog–Weib distribution for Set III and Set IV.
Table 4.
SRs of the NGLog–Weib distribution for Set V and Set VI.
6. Real Data Applications
In this section, we show the practical performance of the suggested method by analysing four real datasets from the biomedical field. The first biomedical dataset is guinea pigs infected, consisting of 72 observations and presenting the survival time of the guinea pigs infected with different amounts of virulent tubercle bacilli. The second dataset is head and neck cancer, having 44 observations and presenting the length of time the head and neck cancer patients stay alive. The third dataset, COVID−19 patients, contains 36 observations and denotes the death rate of COVID−19 pandemic patients belong to Canada of 36 days, from 10 April to 15 May 2020, see the link [https://covid19.who.int/]. Similarly, the fourth dataset represents the lifetimes of 20 patients receiving analgesics. A detailed description of all the datasets is presented in Table 5.
Table 5.
Medical datasets.
Table 5.
Medical datasets.
| No. | Observations | Sources |
|---|---|---|
| Dataset 1. | 10, 33, 44, 56, 59, 72, 74, 77, 92, 93, 96, 100, 100, 102, 105, 107, 107, 108, 108, 108, 109, 112, 113, 115, 116, 120, 121, 122, 122, 124, 130, 134, 136, 139, 144, 146, 153, 159, 160, 163, 163, 168, 171, 172, 176, 183, 195, 196, 197, 202, 213, 215, 216, 222, 230, 231, 240, 245, 251, 253, 254, 255, 278, 293, 327, 342, 347, 361, 402, 432, 458, 555 | Bjerkedal [34] |
| Dataset 2. | 12.20, 23.56, 23.74, 25.87, 31.98, 37, 41.35, 47.38, 55.46, 58.36, 63.47, 68.46, 78.26, 74.47, 81.43, 84, 92, 94, 110, 112, 119, 127, 130, 133, 140, 146, 155, 159, 173, 179, 194, 195, 209, 249, 281, 319, 339, 432, 469, 519, 633, 725, 817, 1776 | Ceren et al. [35] |
| Dataset 3. | 3.1091, 3.3825, 3.1444, 3.2135, 2.4946, 3.5146, 4.9274, 3.3769, 6.8686, 3.0914, 4.9378, 3.1091, 3.2823, 3.8594, 4.0480, 4.1685, 3.6426, 3.2110, 2.8636, 3.2218, 2.9078, 3.6346, 2.7957, 4.2781, 4.2202, 1.5157, 2.6029, 3.3592, 2.8349, 3.1348, 2.5261, 1.5806, 2.7704, 2.1901, 2.4141, 1.9048 | Almetwally et al. [36] |
| Dataset 4. | 1.1, 1.4, 1.3, 1.7, 1.9, 1.8, 1.6, 2.2, 1.7, 2.7, 4.1, 1.8, 1.5, 1.2, 1.4, 3.0, 1.7, 2.3, 1.6, 2.0. | Jamal et al. [37] |
The NGLog–Weib distribution was applied to all four datasets. The goodness of the fit of the newly introduced method was compared with the APTra–Weib (Alpha Power Transformed Weibull) model (Dey et al. [38]), the NExpo–Weib (New Exponential Weibull) model (Shah et al. [32]), the MO–Weib (Marshall–Olkin Weibull) model (Marshall and Olkin [39]), the FRLog–Weib (Flexible Reduced Logarithmic Weibull) model (Liu et al. [1]), and the Kumar–Weib (Kumaraswamy Weibull) distribution (Cordeiro et al. [40]). The CDF of the competitive probability models (or distributions) are given below:
- The APTra–Weib distribution:
- The MO–Weib distribution:
- The NExpo–Weib distribution:
- The Kumar–Weib distribution:
- The FRlog–Weib distribution:
Additionally, we considered various AMs (analytical measures) to verify which distribution outperformed and provided the closest fit to the considered datasets among the fitted distributions. These AMs included GFMs (goodness of fit measures) and DMs (discrimination measures) with corresponding p-values. The GFMs were computed as
- The CM (Cramer-von Misses) test statistic:
- The AD (Anderson Darling) test statistics:
- The KS (Kolmogorov Smirnov) test statistic:
The DMs were computed as
- The Akaike IC (information criterion):
- The Bayesian IC:
- The Consistent Akaike IC:
- The Hannan–Quinn IC:
In general, a statistical model that has lower values of these AMs and a higher p-value will be considered a good probability (or competitor) model for the underlined (or considered) datasets. By implementing these AMs, it is observed that the NGLog–Weib model gives a superior fit to the considered datasets as compared to the other distributions.
6.1. Injected Guinea Pigs, Dataset 1
The NGLog–Weib distribution was applied to the injected guinea pigs dataset, and its goodness of fit was compared with the other distributions. The summary measures were: min = 10.00, 1st quartile = 108.00, mean = 176.80, median = 149.50, 3rd quartile = 224.00, max = 555.00, skewness = 1.341, kurtosis = 4.989, variance = 10,705.10, and range = 545.0. Corresponding to Data 1, the histogram plot, kernel density, TTT plot, violin plot, and box plot are plotted in Figure 4. Similarly, the corresponding model’s parameter values, i.e., , , , , , and of the NGLog–Weib distribution and another extension of the Weib distributions, are recorded in Table 6, whereas the GFMs with p-values and DMs of the competing probability distributions are shown in Table 7 and Table 8. Furthermore, in favour of the AM results presented in Table 7 and Table 8, the estimated PDF, CDF, SF, PP (probability–probability), and QQ (quintile–quintile) plots of the NGLog–Weib distribution are plotted in Figure 5.
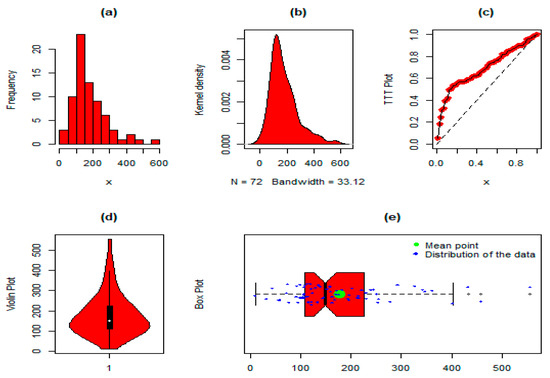
Figure 4.
For dataset 1, the (a) histogram, (b) kernel density plot, (c) TTT plot, (d) violin plot, and (e) box plot.
Table 6.
The , , , , and values for infected guinea pigs data (dataset 1).
Table 7.
The GFMs and p-values of the competing models for infected guinea pigs data (dataset 1).
Table 8.
The DMs of the competing models for infected guinea pigs data (dataset 1).
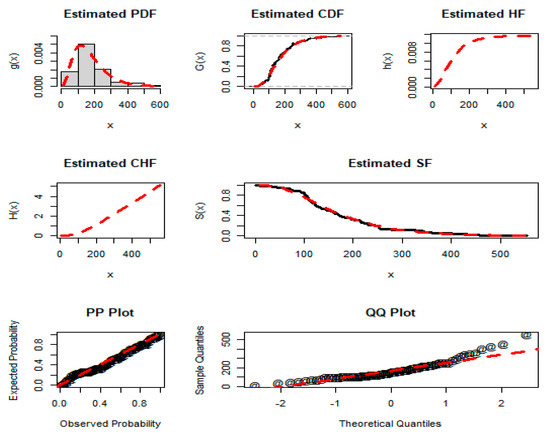
Figure 5.
Estimated PDF, CDF, HF, CHF, SF, PP plot, and QQ plot of the NGLog–Weib distribution for dataset 1.
Given the results presented in Table 7 and Table 8, we can conclude that the NGLog–Weib distribution has the lowest GFM and DM values and the highest p-value, as compared to the other distributions. For the proposed NGLog–Weib distribution, the AMs are: CM = 0.079, AD = 0.492, KS = 0.086, AIC = 856.654, BIC = 863.484, CAIC = 857.007, HQIC = 859.373, and p-value = 0.665. In terms of the AD, KS, AIC, BIC, CAIC, HQIC, and p-value, the second cohesive distribution is the four-parameter Kumar–Weib model. For the Kumar–Weib model, the AM values of the KS, AIC, BIC, CAIC, HQIC, and p-value are given by 0.092, 859.492, 868.599, 860.089, 863.117, and 0.580, respectively, while in comparison to the AD, the second-best distribution is the three-parameter APTra–Weib model because for the APTra–Waib model, the value of the statistics, AD, is 0.138.
Hence, from the numerical depiction in Table 7 and Table 8, the visual graphical illustration (the close-fitting of the NGLog–Weib model), and the above comprehensive discussion, we can say that the newly derived NGLog–Weib model is a good competitor among the other compared probability models for the injected guinea pigs dataset.
6.2. Head and Neck Cancer, Dataset 2
The NGLog–Weib distribution was analysed on the head and neck cancer data and compared with the other distributions to evaluate its optimum fitting power. The summary measures were: min = 12.2, 1st quartile = 67.210, mean = 223.50, median = 128.50, 3rd quartile = 219.0, max = 1776.0, skewness = 3.384, kurtosis = 16.559, var = 93,286.41, and range = 1763.80. Some basic plots, such as the histogram, kernel density, TTT plot, violin plot, and box plot, for dataset 2 are presented in Figure 6. Similarly, the corresponding parameter values, i.e., , , , , , and of the NGLog–Weib distribution in comparison with the other competing probability distributions are given in Table 9, whereas the GFMs with p-values and DMs for selecting the best distribution of the competing probability distributions are presented in Table 10 and Table 11. Furthermore, the graphical representation, the estimated PDF, CDF, SF, PP, and QQ plots of the NGLog–Weib distribution, are shown in Figure 7.
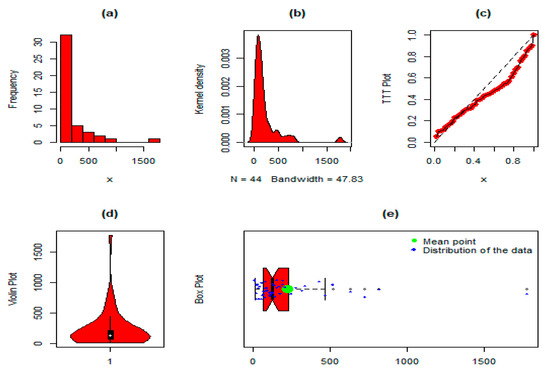
Figure 6.
For dataset 2, the (a) histogram, (b) kernel density plot, (c) TTT plot, (d) violin plot, and (e) box plot.
Table 9.
The , , , , and for head and neck cancer data (dataset 2).
Table 10.
The GFMs and p-values of the competing models for head and neck cancer data (dataset 2).
Table 11.
The DMs of the competing models for head and neck cancer, dataset 2.
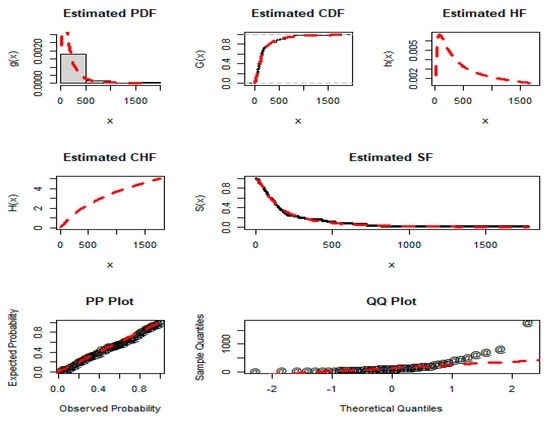
Figure 7.
Estimated PDF, CDF, HF, CHF, SF, PP plot and QQ plot of the NGLog–Weib distribution for dataset 2.
The results presented in Table 10 and Table 11 show that the NGLog–Weib distribution has the lowest GFM and DM values and the highest p-value, as compared to the GFM and DM values and p-values of the other distributions. For the proposed NGLog–Weib distribution, the AMs and p-value are: CM = 0.018, AD = 0.119, KS = 0.057, AIC = 560.732, BIC = 566.085, CAIC = 561.332, HQIC = 562.717, and p-value = 0.9973, respectively. In terms of the CM, AD, KS, AIC, CAIC, HQIC, and p-value, the second optimum distribution is the Kumar–Weib model. For the Kumar–Weib model, the values of the CM, AD, KS, AIC, CAIC, HQIC, and p-value are given by 0.022, 0.136, 0.065, 562.711, 563.737, 565.358 and 0.985, respectively. Similarly, in terms of the BIC, the second optimum distribution is the NExpo–Weib distribution because its value is 568.725.
In light of the numerical justification in Table 10 and Table 11, the visual graphical illustration (the close-fitting of the proposed NGLog–Weib distribution) in Figure 7, and the above discussion, we can observe that the proposed NGLog–Weib distribution is a moral competitor among the other compared probability distributions for the head and neck cancer data (Data 2).
6.3. COVID−19 Patients, Dataset 3
The NGLog–Weib distribution was evaluated on the COVID-19 patients’ dataset. The key measures were: minimum = 1.516, 1st quartile = 2.788, mean = 3.282, median = 3.178, 3rd quartile = 3.637, maximum = 6.868, skewness = 3.384, kurtosis = 16.559, var = 93,286.41, and range = 1763.8. Figure 8 depicts the histogram, kernel density, TTT plot, violin plot, and box plot for the COVID-19 patients’ dataset 3. Similarly, the values of the parameters, i.e., , , , , , and of the NGLog–Weib model with the other competing probability distributions are displayed in Table 12, whereas the GFMs with p-values and DMs for selecting the best distribution of the competing distributions are recorded in Table 13 and Table 14. Furthermore, the graphical representation of the estimated PDF, CDF, SF, PP, and QQ plots of the NGLog–Weib distribution is shown in Figure 9.
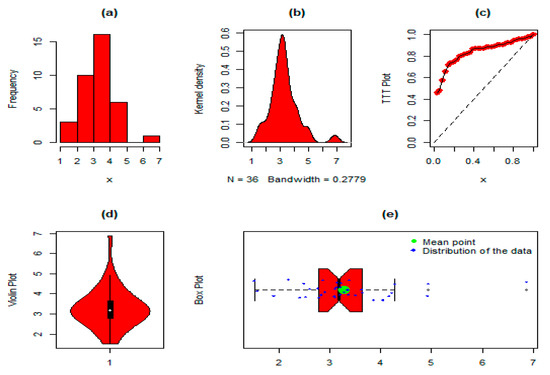
Figure 8.
For dataset 3, the (a) histogram, (b) kernel density plot, (c) TTT plot, (d) violin plot, and (e) box plot.
Table 12.
The , , , , and values for COVID-19 data (dataset 3).
Table 13.
The GFMs and p-values of the competing models for COVID-19 data (dataset 3).
Table 14.
The DMs of the competing models for COVID-19 data (dataset 3).
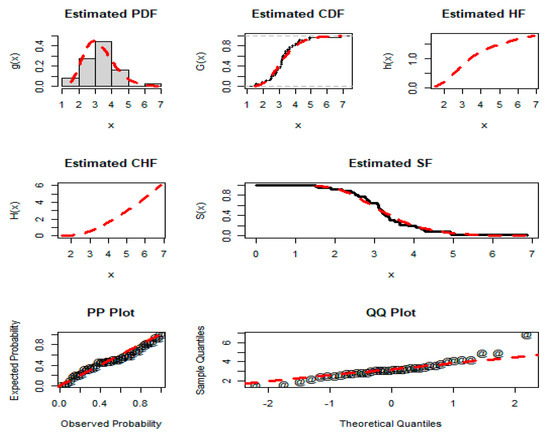
Figure 9.
Estimated PDF, CDF, HF, CHF, SF, PP plot, and QQ plot of the NGLog–Weib distribution for dataset 3.
The results presented in Table 13 and Table 14 display that the NGLog–Weib distribution has the least GFM and DM values and highest p-values, as compared to the GFM and DM values and p-values of the other distributions. For the proposed NGLog–Weib distribution, the AMs and p-values are: CM = 0.092, AD = 0.536, KS = 0.104, AIC = 102.028, BIC = 106.778, CAIC = 102.778, HQIC = 103.686, and p-value = 0.813, respectively. In terms of the CM, AD, KS, and p-value, the second most optimum distribution is the Kumar–Weib model. For the Kumar–Weib model, the values of the CM, AD, KS, and p-value are 0.093, 0.539, 0.106, and 0.795, respectively. Similarly, in terms of the AIC, BIC, CAIC, and HQIC, the second-best distribution is the APTra–Weib distribution because it’s AIC, BIC, CAIC, and HQIC values are 103.616, 108.366, 104.366, and 105.274, respectively.
Based on the justification of the numerical description in Table 13 and Table 14, the visual graphical illustration in Figure 9, and the above comprehensive discussion, we can observe that the NGLog–Weib model is a good competitor among the other compared distributions for the COVID-19 dataset (Data 3).
6.4. Patients Receiving Analgesics, Dataset 4
Finally, the NGLog–Weib distribution was evaluated on the patients receiving analgesics’ datasets. The key measures were: minimum = 1.100, 1st quartile = 1.475, mean = 1.900, median = 1.700, 3rd quartile = 2.050, maximum = 4.100, skewness= 1.720, kurtosis= 5.924, var= 0.496, and range = 3.0. Figure 10 depicts the histogram, kernel density, TTT plot, violin plot, and box plot for patients receiving the analgesics, dataset 4. Similarly, the values of the parameters, i.e., , , , , , and of the NGLog–Weib, with other well-known competing distributions, are displayed in Table 15, whereas the GFMs with p-values and DMs for selecting the best distribution of the competing distributions are provided in Table 16 and Table 17. Furthermore, the graphical representation of the estimated PDF, CDF, SF, PP, and QQ plots of the NGLog–Weib distribution is shown in Figure 11.
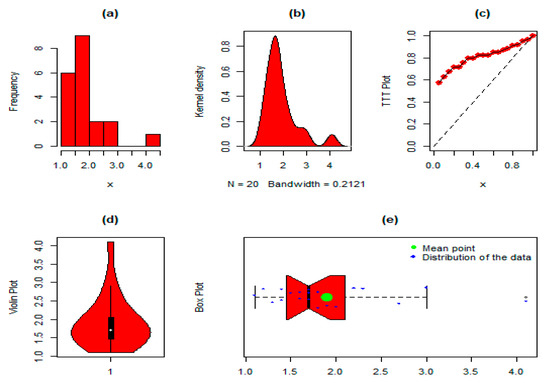
Figure 10.
For dataset 4, the (a) histogram, (b) kernel density plot, (c) TTT plot, (d) violin plot, and (e) box plot.
Table 15.
The , , , , and values for the patients receiving analgesics’ data (dataset 4).
Table 16.
The GFMs and p-values of the competing models for the patients receiving analgesics’ data (dataset 4).
Table 17.
The DMs of the competing models for the patients receiving analgesics’ data (dataset 4).
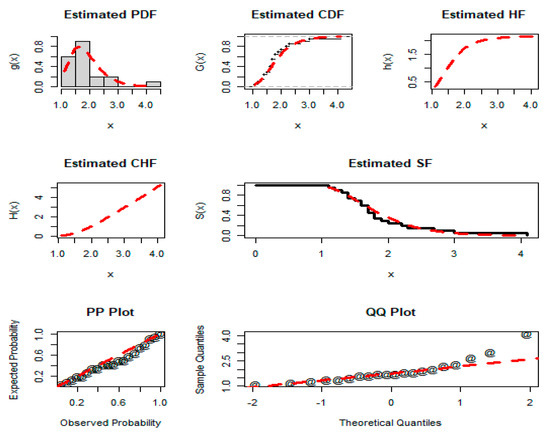
Figure 11.
Estimated PDF, CDF, HF, CHF, SF, PP plot, and QQ plot of the NGLog–Weib distribution for dataset 4.
The results presented in Table 16 and Table 17 display that the NGLog–Weib distribution has the least AM values and the highest p-value, as compared to the AMs and p-values of the other distributions. For the proposed NGLog–Weib distribution, the AMs and p-value are: CM = 0.058, AD = 0.344, KS = 0.146, AIC = 38.699, BIC = 41.687, CAIC = 40.199, HQIC = 39.282, and p-value = 0.850, respectively. In terms of the CM, AD, KS, AIC, HQIC, and p-value, the second most optimum distribution is the Kumar–Weib model. For the Kumar–Weib model, the values of the CM, AD, KS, AIC, HQIC, and p-value are 0.060, 0.359, 0.156, 39.924, 40.702, and 0.833, respectively. Similarly, in terms of the BIC, CAIC, and HQIC, the second-best distribution is the MO–Weib model because its BIC, CAIC, and HQIC values are 43.768, 42.281, and 41.364, respectively.
Based on the justification of the numerical description in Table 16 and Table 17, the visual graphical illustration, and the above comprehensive discussion, we can observe that the proposed NGLog–Weib model is a good (or optimum) competitor among the other competing distributions for the patients receiving analgesics (dataset 4).
7. Conclusions
This study proposes a New Generalized Logarithmic-X (NGLog–X) family of distributions, which is a new family of continuous probability distributions. A three-parameter special subcase of the NGLog–X family of distributions was introduced by implementing the Weibull distribution as a baseline distribution. Various statistical and mathematical properties, such as the moments, moments generating function, residual life, reverse residual life, identifiability property, order statistics, and quantile function were investigated. To this end, the MLE method was utilized to estimate the unknown parameters of the NGLog–X family of distribution. A brief Monte Carlo simulation study was considered to check the efficiency of the , , and of the NGLog–X family of distributions. The newly proposed method was applied to biomedical datasets in comparison to some other well-known distributions, including the APTra–Weib, MO–Weib, FRLog–Weib, NExpo–Weib, and Kumar–Weib distributions. Based on the GFMs and DMs, it is shown that the NGLog–Weib distribution provides a good fit in comparison with other competitive distributions by modelling the medical datasets. The results suggest that the proposed method and its generated models in distribution theory could provide useful applications in biomedical and other related fields.
Author Contributions
Conceptualization, Z.S., D.M.K. and Z.K.; methodology, D.M.K.; software, Z.S., D.M.K. and N.F.; validation, D.M.K., S.H., T.A. and K.-I.K.; formal analysis, Z.S., D.M.K. and N.F.; investigation, D.M.K., T.A. and A.A.; resources, S.H. and K.-I.K.; data curation, D.M.K., S.H., T.A. and N.F.; writing—original draft preparation, Z.S. and N.F.; writing—review and editing, D.M.K., S.H., K.-I.K., T.A. and Z.K.; visualization, Z.S. and N.F. supervision, D.M.K.; project administration, D.M.K., T.A. and K.-I.K.; funding acquisition K.-I.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Institute for Information and Communications Technology Planning and Evaluation (IITP) grant funded by the Korean Government (MSIT) (No. 2022-0-01200, Training Key Talents in Industrial Convergence Security).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Liu, Y.; Ilyas, M.; Khosa, S.K.; Muhmoudi, E.; Ahmad, Z.; Khan, D.M.; Hamedani, G.G. A flexible reduced logarithmic-X family of distributions with biomedical analysis. Comput. Math. Methods Med. 2020, 2020, 4373595. [Google Scholar] [CrossRef] [PubMed]
- Almalki, S.J.; Yuan, J. A new modified Weibull distribution. Reliab. Eng. Syst. Saf. 2013, 111, 164–170. [Google Scholar] [CrossRef]
- Liao, Q.; Ahmad, Z.; Mahmoudi, E.; Hamedani, G.G. A new flexible bathtub-shaped modification of the Weibull model Properties and applications. Math. Probl. Eng. 2020, 2020, 3206257. [Google Scholar] [CrossRef]
- De Micheli, D.; Formigoni, M.L.O. Drug use by Brazilian students: Associations with family, psychosocial, health, demographic and behavioral characteristics. Addiction 2004, 99, 570–578. [Google Scholar] [CrossRef]
- Klakattawi, H.; Alsulami, D.; Elaal, M.A.; Dey, S.; Baharith, L. A new generalized family of distributions based on combining Marshal-Olkin transformation with TX family. PLoS ONE 2022, 17, e0263673. [Google Scholar] [CrossRef]
- Eghwerido, J.T.; Agu, F.I.; Ibidoja, O.J. The shifted exponential-G family of distributions: Properties and applications. J. Stat. Manag. Syst. 2022, 25, 43–75. [Google Scholar] [CrossRef]
- Kilai, M.; Waititu, G.A.; Kibira, W.A.; Alshanbari, H.M.; El-Morshedy, M. A new generalization of Gull Alpha Power Family of distributions with application to modeling COVID-19 mortality rates. Results Phys. 2022, 36, 105339. [Google Scholar] [CrossRef]
- Alkhairy, I.; Faqiri, H.; Shah, Z.; Alsuhabi, H.; Yusuf, M.; Aldallal, R.; Makumi, N.; Riad, F.H. A New Flexible Logarithmic-X Family of Distributions with Applications to Biological Systems. Complexity 2022, 2022, 7845765. [Google Scholar] [CrossRef]
- Tung, Y.L.; Ahmad, Z.; Mahmoudi, E. The Arcsine-X Family of Distributions with Applications to Financial Sciences. Comput. Syst. Sci. Eng. 2021, 39, 351–363. [Google Scholar] [CrossRef]
- Alzaatreh, A.; Aljarrah, M.A.; Smithson, M.; Shahbaz, S.H.; Shahbaz, M.Q.; Famoye, F.; Lee, C. Truncated family of distributions with applications to time and cost to start a business. Methodol. Comput. Appl. Probab. 2021, 23, 5–27. [Google Scholar] [CrossRef]
- Eghwerido, J.T.; Efe-Eyefia, E.; Zelibe, S.C. The transmuted alpha power-G family of distributions. J. Stat. Manag. Syst. 2021, 24, 965–1002. [Google Scholar] [CrossRef]
- Reyad, H.; Korkmaz, M.Ç.; Afify, A.Z.; Hamedani, G.G.; Othman, S. The Fréchet Topp Leone-G family of distributions: Properties, characterizations and applications. Ann. Data Sci. 2021, 8, 345–366. [Google Scholar] [CrossRef]
- Zichuan, M.; Hussain, S.; Iftikhar, A.; Ilyas, M.; Ahmad, Z.; Khan, D.M.; Manzoor, S. A new extended-family of distributions: Properties and applications. Comput. Math. Methods Med. 2020, 2020, 4650520. [Google Scholar] [CrossRef] [PubMed]
- Huo, X.; Khosa, S.K.; Ahmad, Z.; Almaspoor, Z.; Ilyas, M.; Aamir, M. A new lifetime exponential-X family of distributions with applications to reliability data. Math. Probl. Eng. 2020, 2020, 1316345. [Google Scholar] [CrossRef]
- Shah, Z.; Khan, D.M.; Khan, Z.; Shafiq, M.; Choi, J.G. A New Modified Exponent Power Alpha Family of Distributions with Applications in Reliability Engineering. Processes 2022, 10, 2250. [Google Scholar] [CrossRef]
- Hussain, S.; Rashid, M.S.; Ul Hassan, M.; Ahmed, R. The Generalized Alpha Exponent Power Family of Distributions: Properties and Applications. Mathematics 2022, 10, 1421. [Google Scholar] [CrossRef]
- Chen, P.; Ye, Z.S. Estimation of field reliability based on aggregate lifetime data. Technometrics 2017, 59, 115–125. [Google Scholar] [CrossRef]
- Xu, A.; Zhou, S.; Tang, Y. A unified model for system reliability evaluation under dynamic operating conditions. IEEE Trans. Reliab. 2019, 70, 65–72. [Google Scholar] [CrossRef]
- Zhang, L.; Xu, A.; An, L.; Li, M. Bayesian inference of system reliability for multicomponent stress-strength model under Marshall-Olkin Weibull distribution. Systems 2022, 10, 196. [Google Scholar] [CrossRef]
- Luo, C.; Shen, L.; Xu, A. Modelling and estimation of system reliability under dynamic operating environments and lifetime ordering constraints. Reliab. Eng. Syst. Saf. 2022, 218, 108136. [Google Scholar] [CrossRef]
- Zhuang, L.; Xu, A.; Wang, X.L. A prognostic driven predictive maintenance framework based on Bayesian deep learning. Reliab. Eng. Syst. Saf. 2023, 234, 109181. [Google Scholar] [CrossRef]
- Zhao, W.; Khosa, S.K.; Ahmad, Z.; Aslam, M.; Afify, A.Z. Type-I heavy tailed family with applications in medicine, engineering and insurance. PLoS ONE 2020, 15, e0237462. [Google Scholar] [CrossRef] [PubMed]
- Alzaatreh, A.; Famoye, F.; Lee, C. A new method for generating families of continuous distributions. Metron 2013, 71, 63–79. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, Z.; Zahra, A. A new logarithmic family of distributions: Properties and applications. CMC-Comput. Mater. Contin. 2021, 66, 919–929. [Google Scholar]
- Zhao, Y.; Ahmad, Z.; Alrumayh, A.; Yusuf, M.; Aldallal, R.; Elshenawy, A.; Riad, F.H. A novel logarithmic approach to generate new probability distributions for data modeling in the engineering sector. Alex. Eng. J. 2023, 62, 313–325. [Google Scholar] [CrossRef]
- Eugene, N.; Lee, C.; Famoye, F. Beta-normal distribution and its applications. Commun. Stat.-Theory Methods 2002, 31, 497–512. [Google Scholar] [CrossRef]
- Zografos, K.; Balakrishnan, N. On families of beta-and generalized gamma-generated distributions and associated inference. Stat. Methodol. 2009, 6, 344–362. [Google Scholar] [CrossRef]
- Ristić, M.M.; Balakrishnan, N. The gamma-exponentiated exponential distribution. J. Stat. Comput. Simul. 2012, 82, 1191–1206. [Google Scholar] [CrossRef]
- Torabi, H.; Hedesh, N.M. The gamma-uniform distribution and its applications. Kybernetika 2012, 48, 16–30. [Google Scholar]
- Tahir, M.H.; Cordeiro, G.M.; Alzaatreh, A.; Mansoor, M.; Zubair, M. The logistic-X family of distributions and its applications. Commun. Stat.-Theory Methods 2016, 45, 7326–7349. [Google Scholar] [CrossRef]
- Ahmad, Z.; Mahmoudi, E.; Dey, S.; Khosa, S.K. Modeling vehicle insurance loss data using a new member of TX family of distributions. J. Stat. Theory Appl. 2020, 19, 133–147. [Google Scholar] [CrossRef]
- Shah, Z.; Ali, A.; Hamraz, M.; Khan, D.M.; Khan, Z.; EL-Morshedy, M.; Al-Bossly, A.; Almaspoor, Z. A New Member of TX Family with Applications in Different Sectors. J. Math. 2022, 2022, 1453451. [Google Scholar] [CrossRef]
- David, H.A. Order Statistics, 2nd ed.; Wiley: New York, NY, USA, 1981. [Google Scholar]
- Bjerkedal, T. Acquisition of Resistance in Guinea Pies infected with Different Doses of Virulent Tubercle Bacilli. Am. J. Hyg. 1960, 72, 130–148. [Google Scholar] [PubMed]
- Ceren, Ü.N.A.L.; Cakmakyapan, S.; Gamze, Ö.Z.E.L. Alpha power inverted exponential distribution: Properties and application. Gazi Univ. J. Sci. 2018, 31, 954–965. [Google Scholar]
- Almetwally, E.M.; Alharbi, R.; Alnagar, D.; Hafez, E.H. A new inverted topp-leone distribution: Applications to the COVID-19 mortality rate in two different countries. Axioms 2021, 10, 25. [Google Scholar] [CrossRef]
- Jamal, F.; Reyad, H.; Chesneau, C.; Nasir, M.A.; Othman, S. The Marshall-Olkin odd Lindley-G family of distributions: Theory and applications. Punjab Univ. J. Math. 2020, 51, 111–125. [Google Scholar]
- Dey, S.; Sharma, V.K.; Mesfioui, M. A new extension of Weibull distribution with application to lifetime data. Ann. Data Sci. 2017, 4, 31–61. [Google Scholar]
- Marshall, A.W.; Olkin, I. A new method for adding a parameter to a family of distributions with application to the exponential and Weibull families. Biometrika 1997, 84, 641–652. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Ortega, E.M.; Nadarajah, S. The Kumaraswamy Weibull distribution with application to failure data. J. Frankl. Inst. 2010, 347, 1399–1429. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).