

Replication-Based Dynamic Energy-Aware Resource Provisioning for Scientific Workflows

 ,
,  ,
,  and
and
Abstract
1. Introduction
- This research work presents a dynamic energy-aware resource-provisioning (DEAR) strategy for SWs in an IaaS cloud service model.
- This work also implements a replication-based fault-tolerant mechanism in the proposed DEAR strategy to make it R-DEAR, a failure-free resource-provisioning technique for the IaaS cloud service model.
- In the proposed R-DEAR strategy, one or more users will submit SWs to the workflow manager.
- The workflow/resource information provider (WRIP) will obtain the details of resources and scientific workflow requirements. It is presumed that the energy consumption for each resource is predefined for the submitted workflow on the basis of tasks contained within it.
- The workflow scheduler obtains information regarding the workflow tasks from the workflow manager. The tasks are sorted per their energy consumption in ascending order T1 < T2 < T3 … Tn.
- The WRIP provides information about resources and workflows to the workflow scheduler. The accessible resources are arranged in descending order by energy consumption: R1 > R2 > R3 … Rn.
- The workflow scheduler sends the information about tasks and resources to the workflow engine.
- The workflow engine assigns tasks to resources in each process based on sorted lists, and then starts the workflow. The workflow engine distributes the workload across available resources and reports task and resource status to the workflow replica manager.
- During task execution, the workflow replica manager keeps a copy of each task and checks the resource status. If a task fails, a duplicate of the task will be sent to the resource to finish the execution.
- The workflow engine will compile the result after successful execution and return it to the end user.
2. Related Work
3. System Design and Model
3.1. Parts of R-DEAR Strategy
- User
- Workflow manager
- Workflow/resource information provider
- Workflow scheduler
- Workflow engine
- Workflow replica manager
3.1.1. User
3.1.2. Workflow Manager
3.1.3. Workflow/Resource Information Provider (WRIP)
3.1.4. Workflow Scheduler
3.1.5. Workflow Engine
3.1.6. Resource Power Manager
3.1.7. Workflow Replica Manager
3.2. Algorithm for the R-DEAR Strategy
| Algorithm 1 R-DEAR strategy |
| Input: δ (Scientific workflow) Output: γ (Generated results) Procedure: R-DEAR (δ) |
|
4. Evaluation Methods
4.1. Simulation Tool
4.2. Application Modelling
4.3. Performance Evaluation Parameters
5. Experiment Setup
5.1. Results and Discussion
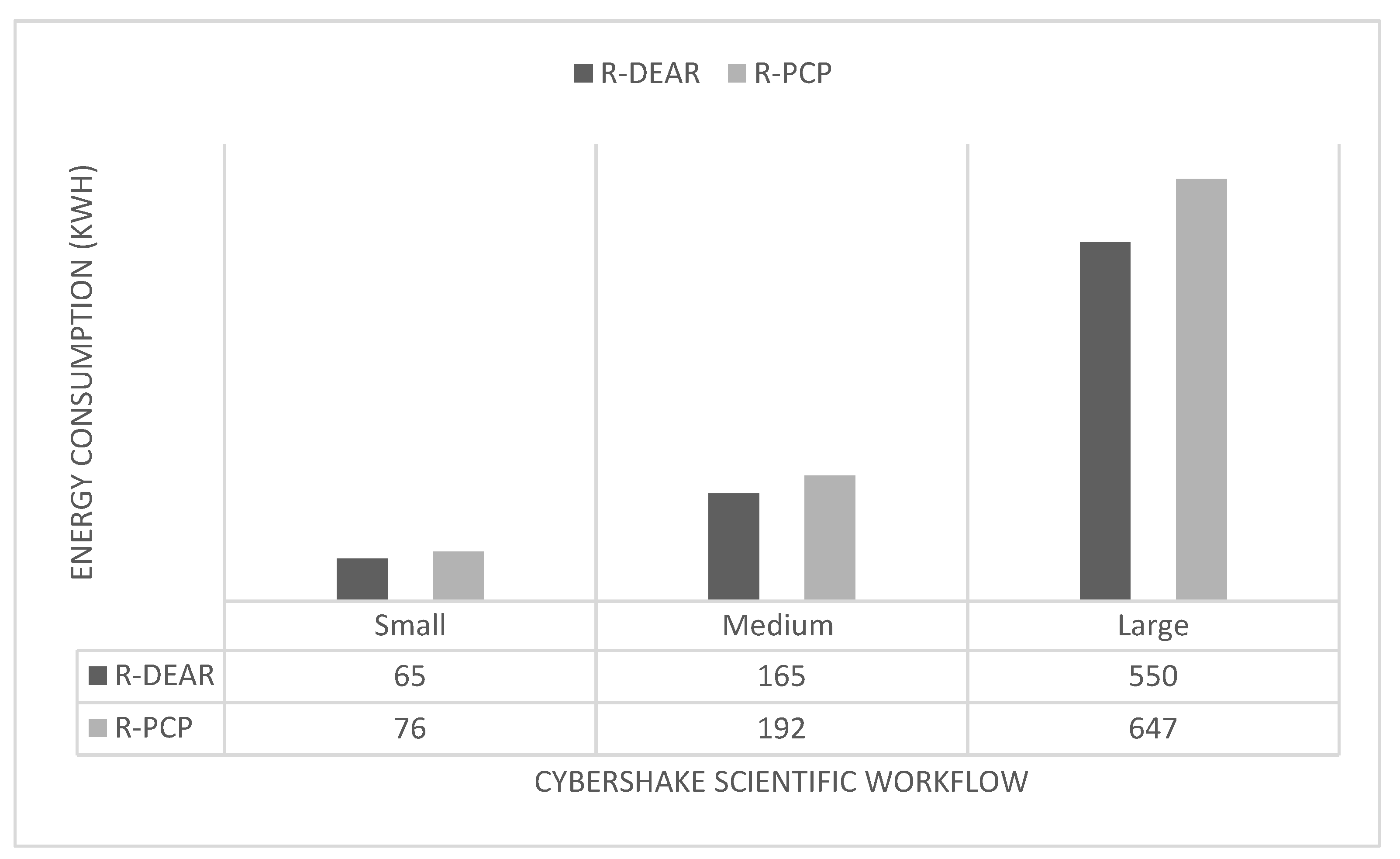
5.1.1. Energy Consumption
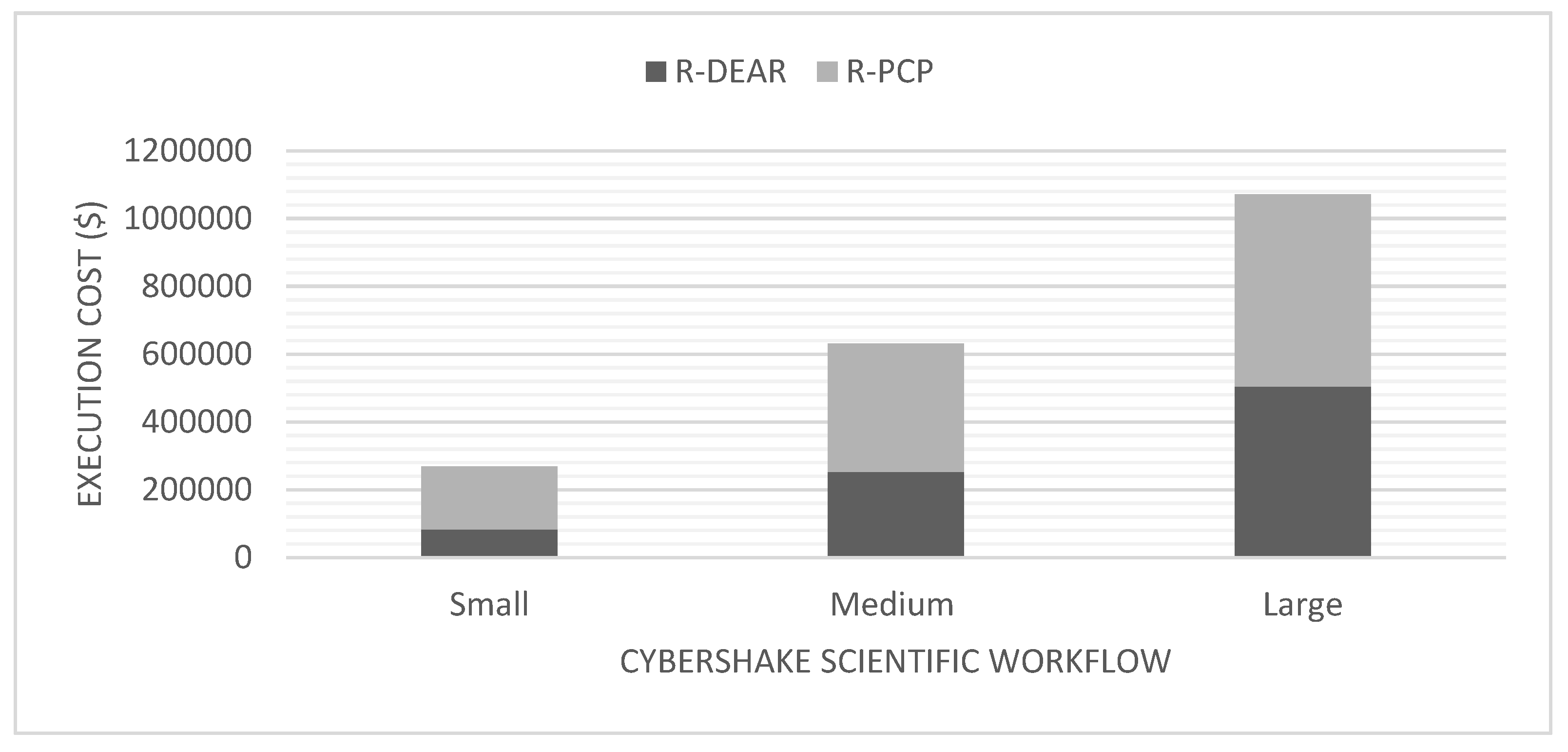
5.1.2. Execution Cost
5.1.3. Execution Time
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sookhak, M.; Yu, F.R.; Khan, M.K.; Xiang, Y.; Buyya, R. Attribute-based data access control in mobile cloud computing: Taxonomy and open issues. Futur. Gener. Comput. Syst. 2017, 72, 273–287. [Google Scholar] [CrossRef]
- Ullah, A.; Li, J.; Shen, Y.; Hussain, A. A control theoretical view of cloud elasticity: Taxonomy, survey and challenges. Clust. Comput. 2018, 21, 1735–1764. [Google Scholar] [CrossRef]
- Mustafa, S.; Nazir, B.; Hayat, A.; Khan, A.U.R.; Madani, S.A. Resource management in cloud computing: Taxonomy, prospects, and challenges. Comput. Electr. Eng. 2015, 47, 186–203. [Google Scholar] [CrossRef]
- Masdari, M.; ValiKardan, S.; Shahi, Z.; Azar, S.I. Towards workflow scheduling in cloud computing: A comprehensive analysis. J. Netw. Comput. Appl. 2016, 66, 64–82. [Google Scholar] [CrossRef]
- Serrano, D.; Bouchenak, S.; Kouki, Y.; de Oliveira, F.A., Jr.; Ledoux, T.; Lejeune, J.; Sopena, J.; Arantes, L.; Sens, P. SLA guarantees for cloud services. Futur. Gener. Comput. Syst. 2016, 54, 233–246. [Google Scholar] [CrossRef]
- Dimitri, N. Pricing cloud IaaS computing services. J. Cloud Comput. 2020, 9, 14. [Google Scholar] [CrossRef]
- Alanzy, M.; Latip, R.; Muhammed, A. Range wise busy checking 2-way imbalanced algorithm for cloudlet allocation in cloud environment. J. Physics: Conf. Ser. 2018, 1018, 012018. [Google Scholar] [CrossRef]
- Rodriguez, M.A.; Buyya, R. Budget-Driven Scheduling of Scientific Workflows in IaaS Clouds with Fine-Grained Billing Periods. ACM Trans. Auton. Adapt. Syst. 2017, 12, 1–22. [Google Scholar] [CrossRef]
- Ahmad, Z.; Nazir, B.; Umer, A. A fault-tolerant workflow management system with Quality-of-Service-aware scheduling for scientific workflows in cloud computing. Int. J. Commun. Syst. 2021, 34, e4649. [Google Scholar] [CrossRef]
- Casas, I.; Taheri, J.; Ranjan, R.; Wang, L.; Zomaya, A.Y. A balanced scheduler with data reuse and replication for scientific workflows in cloud computing systems. Futur. Gener. Comput. Syst. 2016, 74, 168–178. [Google Scholar] [CrossRef]
- da Silva, R.F.; Casanova, H.; Orgerie, A.-C.; Tanaka, R.; Deelman, E.; Suter, F. Characterizing, Modeling, and Accurately Simulating Power and Energy Consumption of I/O-intensive Scientific Workflows. J. Comput. Sci. 2020, 44, 101157. [Google Scholar] [CrossRef]
- Choi, J.; Adufu, T.; Kim, Y. Data-Locality Aware Scientific Workflow Scheduling Methods in HPC Cloud Environments. Int. J. Parallel Program. 2016, 45, 1128–1141. [Google Scholar] [CrossRef]
- Ala’Anzy, M.A.; Othman, M.; Hasan, S.; Ghaleb, S.M.; Latip, R. Optimising Cloud Servers Utilisation Based on Locust-Inspired Algorithm. In Proceedings of the 7th International Conference on Soft Computing & Machine Intelligence, Stockholm, Sweden, 14–15 November 2020; pp. 23–27. [Google Scholar] [CrossRef]
- Ahmad, Z.; Jehangiri, A.I.; Ala’Anzy, M.A.; Othman, M.; Umar, A.I. Fault-Tolerant and Data-Intensive Resource Scheduling and Management for Scientific Applications in Cloud Computing. Sensors 2021, 21, 7238. [Google Scholar] [CrossRef] [PubMed]
- Acevedo, C.; Hernández, P.; Espinosa, A.; Mendez, V. A Data-aware MultiWorkflow Scheduler for Clusters on WorkflowSim. In Proceedings of the COMPLEXIS 2017: 2nd International Conference on Complexity, Future Information Systems and Risk, Online Streaming, 23–24 April 2022; pp. 79–86. [Google Scholar] [CrossRef]
- Gottin, V.M.; Pacheco, E.; Dias, J.; Ciarlini, A.E.M.; Costa, B.; Vieira, W.; Souto, Y.M.; Pires, P.; Porto, F.; Rittmeyer, J.G. Automatic Caching Decision for Scientific Dataflow Execution in Apache Spark. In Proceedings of the 5th ACM SIGMOD Workshop on Algorithms and Systems for MapReduce and Beyond, Houston, TX, USA, 15 June 2018. [Google Scholar] [CrossRef]
- Anwar, N.; Deng, H. Elastic Scheduling of Scientific Workflows under Deadline Constraints in Cloud Computing Environments. Futur. Internet 2018, 10, 5. [Google Scholar] [CrossRef]
- Rehman, A.U.; Ahmad, Z.; Jehangiri, A.I.; Ala’Anzy, M.A.; Othman, M.; Umar, A.I.; Ahmad, J. Dynamic Energy Efficient Resource Allocation Strategy for Load Balancing in Fog Environment. IEEE Access 2020, 8, 199829–199839. [Google Scholar] [CrossRef]
- Stavrinides, G.L.; Karatza, H.D. An energy-efficient, QoS-aware and cost-effective scheduling approach for real-time workflow applications in cloud computing systems utilizing DVFS and approximate computations. Futur. Gener. Comput. Syst. 2019, 96, 216–226. [Google Scholar] [CrossRef]
- Rodriguez, M.A.; Buyya, R. A taxonomy and survey on scheduling algorithms for scientific workflows in IaaS cloud computing environments. Concurr. Comput. Pract. Exp. 2016, 29, e4041. [Google Scholar] [CrossRef]
- Marozzo, F.; Talia, D.; Trunfio, P. A Workflow Management System for Scalable Data Mining on Clouds. IEEE Trans. Serv. Comput. 2016, 11, 480–492. [Google Scholar] [CrossRef]
- Ahmad, Z.; Jehangiri, A.I.; Iftikhar, M.; Umer, A.I.; Afzal, I. Data-Oriented Scheduling with Dynamic-Clustering Fault-Tolerant Technique for Scientific Workflows in Clouds. Program. Comput. Softw. 2019, 45, 506–516. [Google Scholar] [CrossRef]
- Verma, R.K.; Pattanaik, K.; Bharti, S.; Saxena, D. In-network context inference in IoT sensory environment for efficient network resource utilization. J. Netw. Comput. Appl. 2019, 130, 89–103. [Google Scholar] [CrossRef]
- Chen, W.; da Silva, R.F.; Deelman, E.; Fahringer, T. Dynamic and Fault-Tolerant Clustering for Scientific Workflows. IEEE Trans. Cloud Comput. 2015, 4, 49–62. [Google Scholar] [CrossRef]
- Zhu, X.; Wang, J.; Guo, H.; Zhu, D.; Yang, L.T.; Liu, L. Fault-Tolerant Scheduling for Real-Time Scientific Workflows with Elastic Resource Provisioning in Virtualized Clouds. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 3501–3517. [Google Scholar] [CrossRef]
- da Silva, R.F.; Filgueira, R.; Deelman, E.; Pairo-Castineira, E.; Overton, I.M.; Atkinson, M.P. Using simple PID-inspired controllers for online resilient resource management of distributed scientific workflows. Futur. Gener. Comput. Syst. 2019, 95, 615–628. [Google Scholar] [CrossRef]
- Sardaraz, M.; Tahir, M. A parallel multi-objective genetic algorithm for scheduling scientific workflows in cloud computing. Int. J. Distrib. Sens. Networks 2020, 16, 1550147720949142. [Google Scholar] [CrossRef]
- Sardaraz, M.; Tahir, M. A Hybrid Algorithm for Scheduling Scientific Workflows in Cloud Computing. IEEE Access 2019, 7, 186137–186146. [Google Scholar] [CrossRef]
- Shirvani, M.H.; Talouki, R.N. Bi-objective scheduling algorithm for scientific workflows on cloud computing platform with makespan and monetary cost minimization approach. Complex Intell. Syst. 2021, 8, 1085–1114. [Google Scholar] [CrossRef]
- Sujana, J.A.J.; Revathi, T.; Priya, T.S.S.; Muneeswaran, K. Smart PSO-based secured scheduling approaches for scientific workflows in cloud computing. Soft Comput. 2017, 23, 1745–1765. [Google Scholar] [CrossRef]
- Li, Z.; Yu, J.; Hu, H.; Chen, J.; Hu, H.; Ge, J.; Chang, V. Fault-Tolerant Scheduling for Scientific Workflow with Task Replication Method in Cloud. In Proceedings of the 3rd International Conference on Internet of Things, Big Data and Security, IoTBDS 2018, Funchal, Portugal, 19–21 March 2018; pp. 95–104. [Google Scholar] [CrossRef]
- Wu, N.; Zuo, D.; Zhang, Z. Dynamic Fault-Tolerant Workflow Scheduling with Hybrid Spatial-Temporal Re-Execution in Clouds. Information 2019, 10, 169. [Google Scholar] [CrossRef]
- Chen, W.; Deelman, E. WorkflowSim: A toolkit for simulating scientific workflows in distributed environments. In Proceedings of the 2012 IEEE 8th International Conference on E-Science, Chicago, IL, USA, 8–12 October 2012. [Google Scholar] [CrossRef]
- Padmakumari, P.; Umamakeswari, A. Development of cognitive fault tolerant model for scientific workflows by integrating overlapped migration and check-pointing approach. J. Ambient. Intell. Humaniz. Comput. 2019, 1–11. [Google Scholar] [CrossRef]
- Ulabedin, Z.; Nazir, B. Replication and data management-based workflow scheduling algorithm for multi-cloud data centre platform. J. Supercomput. 2021, 77, 10743–10772. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, L.; Xiao, M.; Wen, Z.; Peng, C. EM_WOA: A budget-constrained energy consumption optimization approach for workflow scheduling in clouds. Peer-to-Peer Netw. Appl. 2022, 15, 973–987. [Google Scholar] [CrossRef]
- Choudhary, R.; Perinpanayagam, S. Applications of Virtual Machine Using Multi-Objective Optimization Scheduling Algorithm for Improving CPU Utilization and Energy Efficiency in Cloud Computing. Energies 2022, 15, 9164. [Google Scholar] [CrossRef]
- Bharany, S.; Sharma, S.; Khalaf, O.I.; Abdulsahib, G.M.; Al Humaimeedy, A.S.; Aldhyani, T.H.H.; Maashi, M.; Alkahtani, H. A Systematic Survey on Energy-Efficient Techniques in Sustainable Cloud Computing. Sustainability 2022, 14, 6256. [Google Scholar] [CrossRef]
- Deelman, E.; Singh, G.; Livny, M.; Berriman, B.; Good, J. The cost of doing science on the cloud: The Montage example. In Proceedings of the SC ‘08: Proceedings of the 2008 ACM/IEEE Conference on Supercomputing, Austin, TX, USA, 15–21 November 2008. [Google Scholar] [CrossRef]
- Callaghan, S.; Maechling, P.J.; Small, P.; Milner, K.; Juve, G.; Jordan, T.H.; Deelman, E.; Mehta, G.; Vahi, K.; Gunter, D.; et al. Metrics for heterogeneous scientific workflows: A case study of an earthquake science application. Int. J. High Perform. Comput. Appl. 2011, 25, 274–285. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Strategy | Contribution | Evaluation Platform | Limitations |
|---|---|---|---|---|
| [9] | QFWMS | Provides scheduling solution based on data awareness | WorkflowSim | Not an energy efficient approach |
| [17] | DSB | Bag-of-tasks-based solution to reduce financial cost | WorkflowSim | Not an energy efficient and fault tolerant approach |
| [26] | PID controller | Prevents and mitigates data storage overload and memory overflow | Activity-based simulator | Not an energy efficient approach |
| [27] | GA-PSO | Provides a solution based on genetic algorithm to minimize time and cost | CloudSim | No consideration of fault tolerance |
| [35] | R-PCP | Provides a replication-based scheduling solution in multi-cloud environment | WorkflowSim | Not an energy efficient approach |
| No. VMs | Memory | BW | VM | Arch |
|---|---|---|---|---|
| 1000 VMs | 10,240 MB | 10,000 Mbps | Xen | X86 |
| OS | Cost per VM $/Hr | Memory cost $/s | Storage cost $/S | Data transfer cost $/s |
| Linux | 3.00 $/Hr | 0.05 $/s | 0.10 $/S | 0.10 $/s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ala’anzy, M.A.; Othman, M.; Ibbini, E.M.; Enaizan, O.; Farid, M.; Alsaaidah, Y.A.; Ahmad, Z.; Ghoniem, R.M. Replication-Based Dynamic Energy-Aware Resource Provisioning for Scientific Workflows. Appl. Sci. 2023, 13, 2644. https://doi.org/10.3390/app13042644
Ala’anzy MA, Othman M, Ibbini EM, Enaizan O, Farid M, Alsaaidah YA, Ahmad Z, Ghoniem RM. Replication-Based Dynamic Energy-Aware Resource Provisioning for Scientific Workflows. Applied Sciences. 2023; 13(4):2644. https://doi.org/10.3390/app13042644
Chicago/Turabian StyleAla’anzy, Mohammed Alaa, Mohamed Othman, Emad Mohammed Ibbini, Odai Enaizan, Mazen Farid, Yousef A. Alsaaidah, Zulfiqar Ahmad, and Rania M. Ghoniem. 2023. "Replication-Based Dynamic Energy-Aware Resource Provisioning for Scientific Workflows" Applied Sciences 13, no. 4: 2644. https://doi.org/10.3390/app13042644
APA StyleAla’anzy, M. A., Othman, M., Ibbini, E. M., Enaizan, O., Farid, M., Alsaaidah, Y. A., Ahmad, Z., & Ghoniem, R. M. (2023). Replication-Based Dynamic Energy-Aware Resource Provisioning for Scientific Workflows. Applied Sciences, 13(4), 2644. https://doi.org/10.3390/app13042644