

MONWS: Multi-Objective Normalization Workflow Scheduling for Cloud Computing


Abstract
1. Introduction
- (1)
- Identifying the best workflow is a challenging task in scheduling. In this paper, based on the study, we select “Cybershake” as the best workflow;
- (2)
- Handling dynamic traffic in cloud computing is very difficult. Static thresholds fail to schedule tasks optimally. In our proposed approach, we define a dynamic threshold value based on the task execution time, workflow model, and availability of resources;
- (3)
- In this paper, we present an extensive literature review for selecting multi-objective parameters for task scheduling;
- (4)
- We exemplify our proposed work with standard numerical values to prove the efficiency of a framework for cloud computing;
- (5)
- To make our proposed algorithm more realistic, we include the data transfer time between tasks;
- (6)
- To calculate the efficiency of proposed algorithm, simulation results are compared with the five existing algorithms.
2. Related Work
3. Scheduling Problem Formation
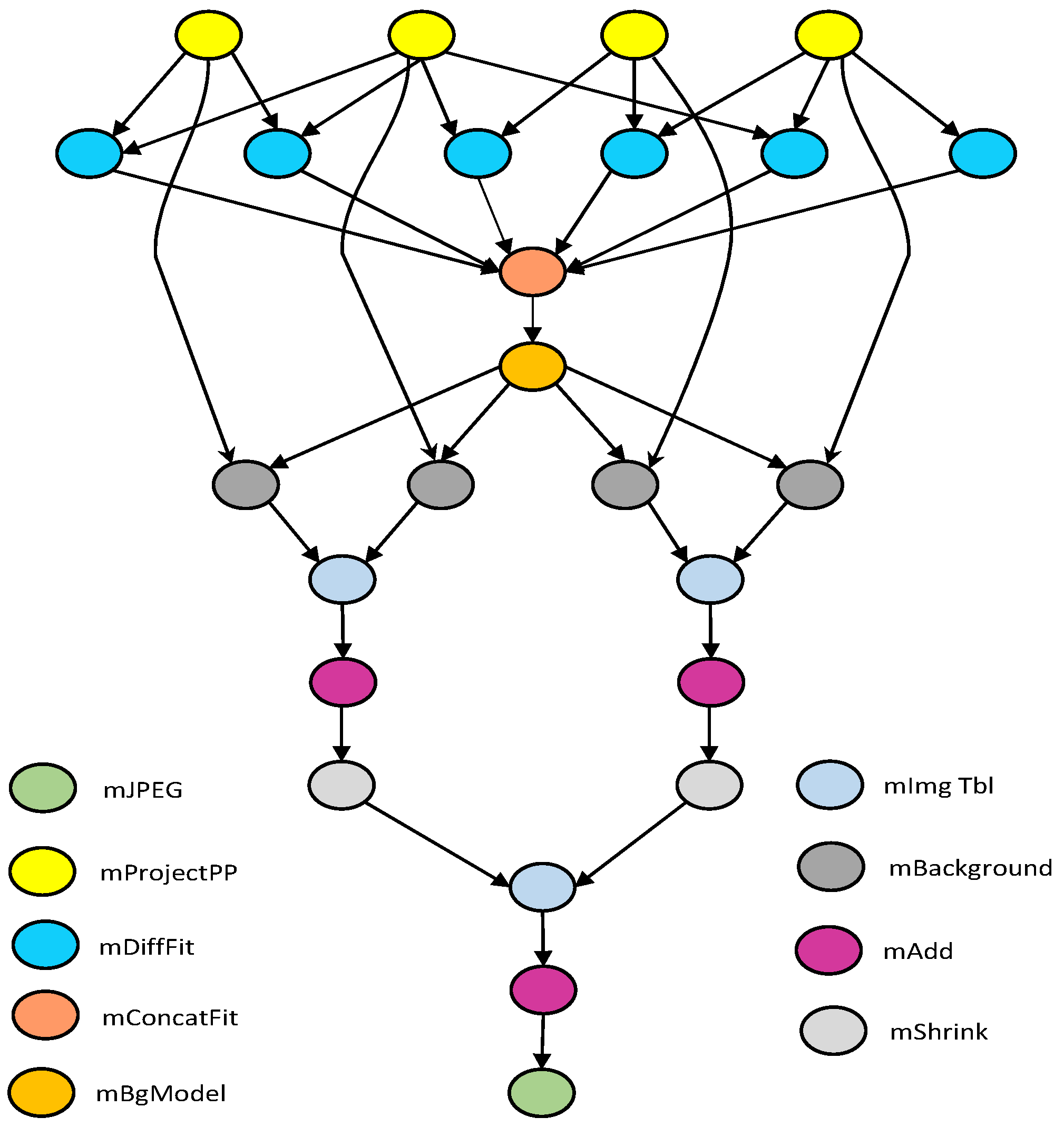
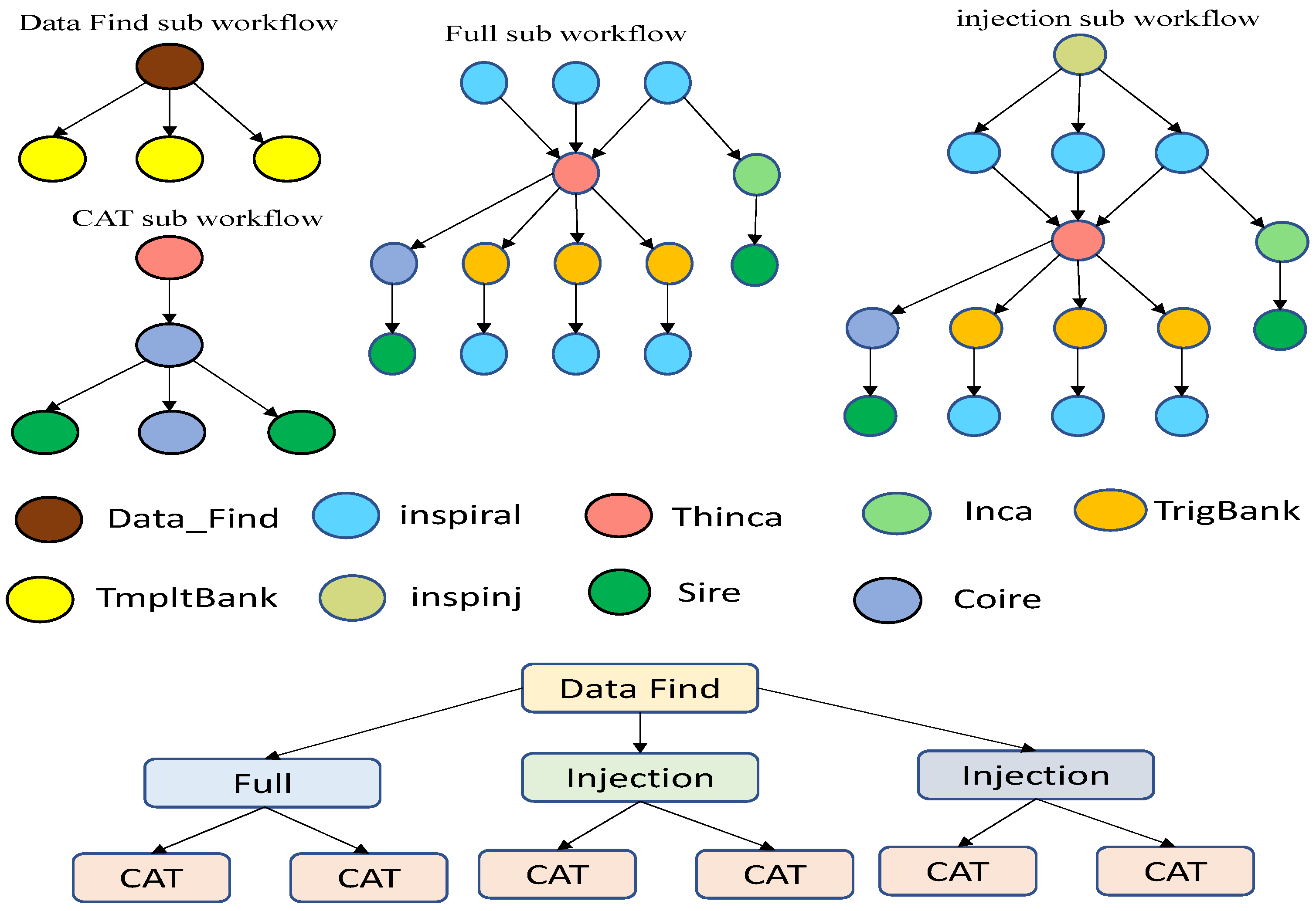
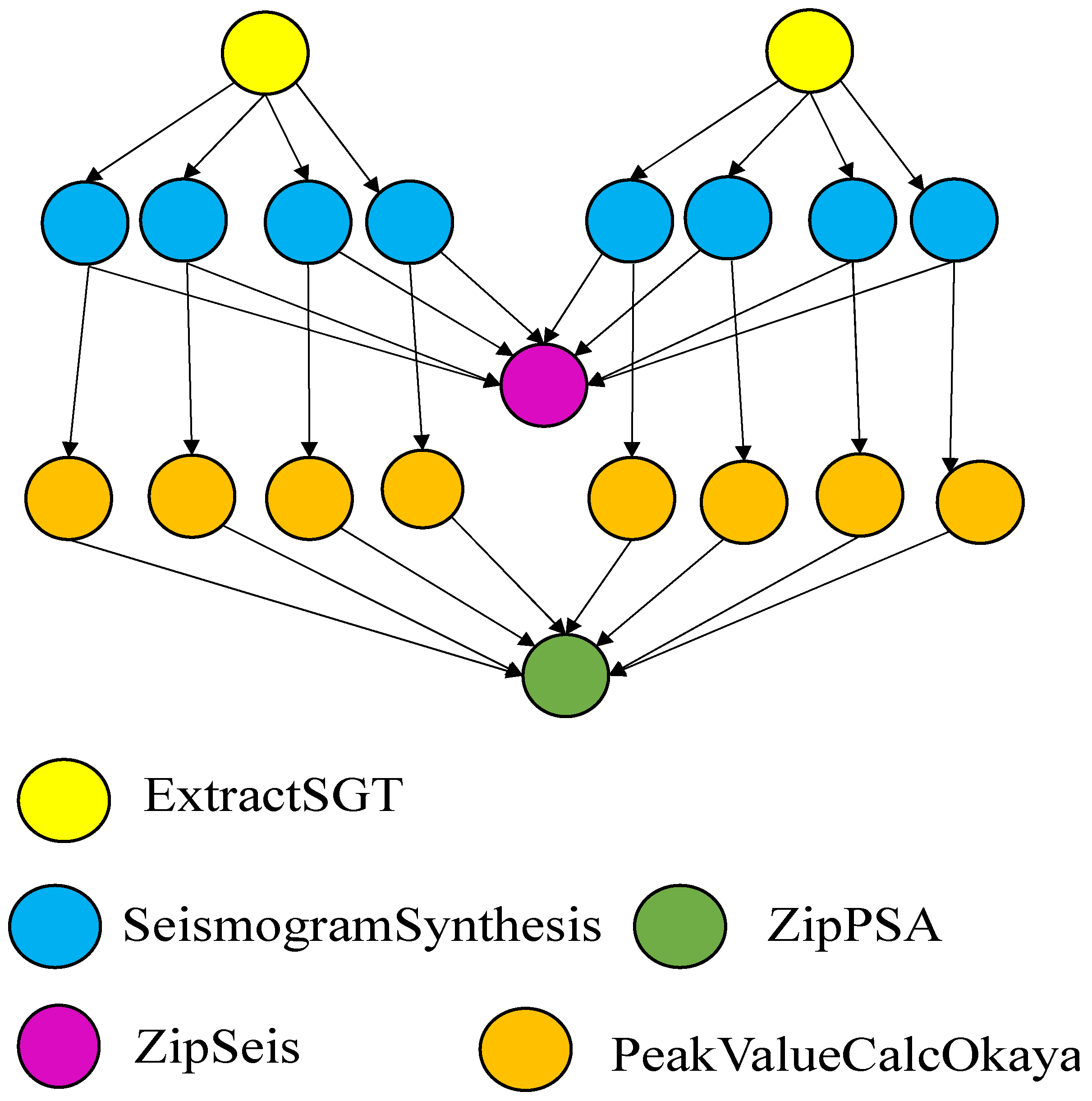
Application Model
4. Proposed Algorithm
4.1. Normalize ECT
4.2. VM Selection
| Algorithm 1: Proposed MONWS Algorithm |
| Input: workflow with n number of tasks Output: Scheduling on available VMs on m number of cloud servers |
| Read Ect and DTT of the given workflow D (T, E) while for every task Ti in each level /*Generate Ready Task List*/ while if tasks are unscheduled do b_large is empty for every task Ti in each level add Ti to Ready List RLi end for end if end while /*Compute Early finish time*/ for every task Ti Ready List RLi do if task Ti has no Tp Ect= availablevm+Ectvm else for every vm and Tp of Ti if taskvmmap(Tp) =! Vm if Ect<Est Ect=Est endif else if Ect<max(availablevm,Act) Ect=max(availablevm,Act) endif endif endfor endif endfor /*Partition of tasks*/ Find min(Ect) Find max(Ect) Find N_Ect Find threshold Th(dt) if max(N_Ect)>= th(dt) add in to b_large else add into b_small endif if b_large =! Empty find min(Eft(i,j) taskvmmap(Ti)=vm Act = Eft Est = 1 remove Ti from b_large else find min(Eft(i,j) taskvmmap(Ti) = vm Act = Eft Est = 1 endif endfor endwhile |
4.3. MONWS Framework
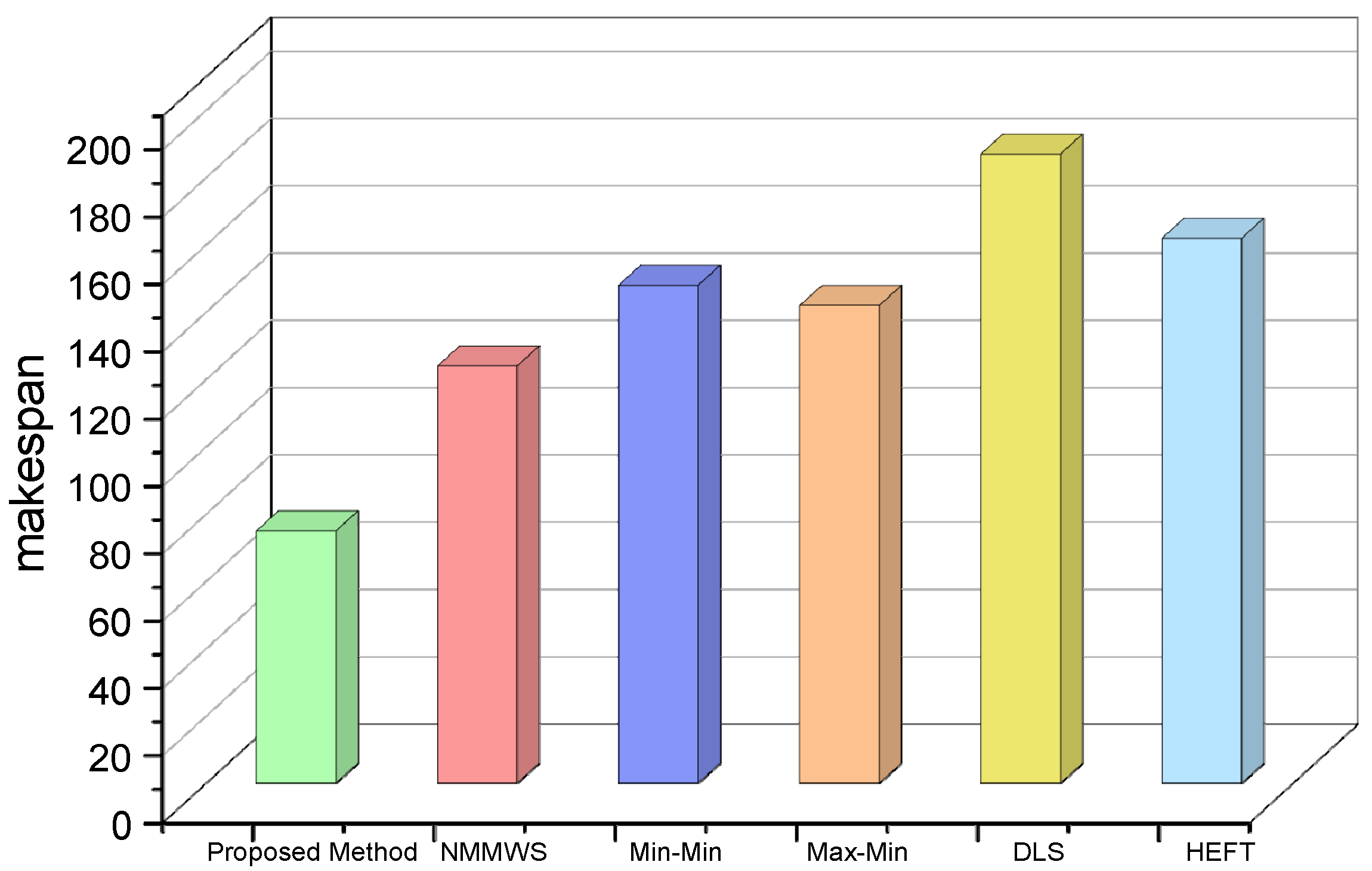
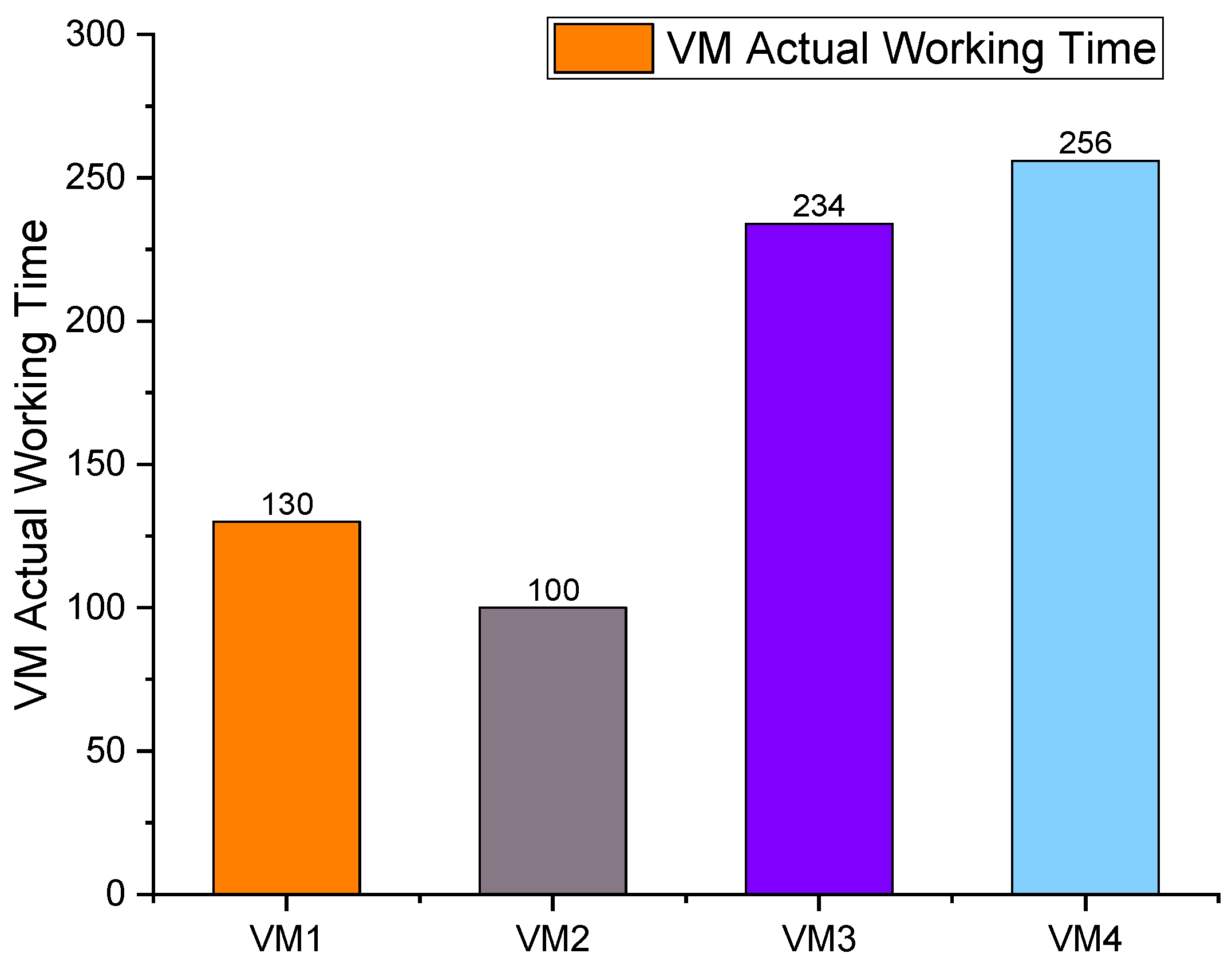
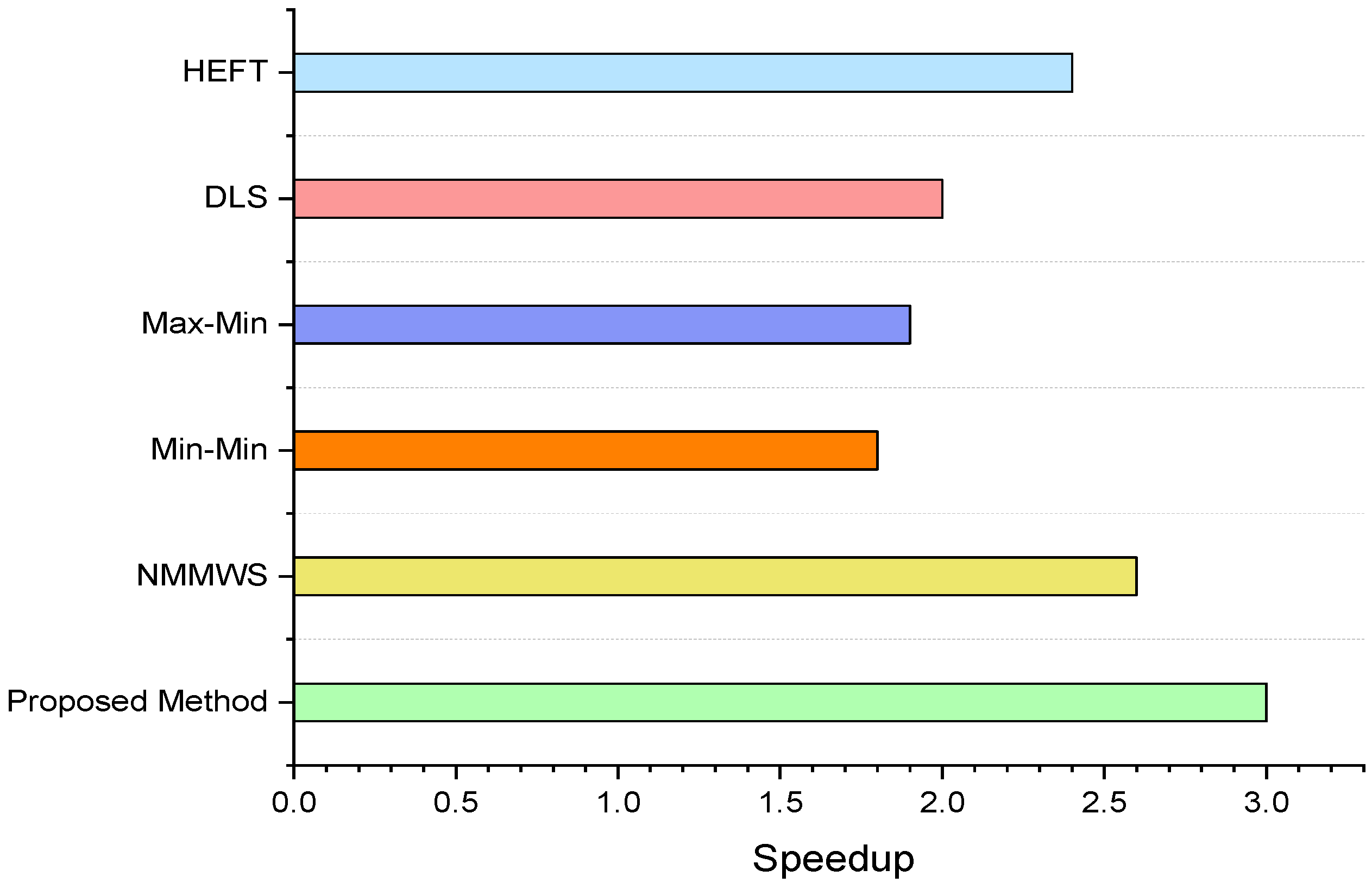
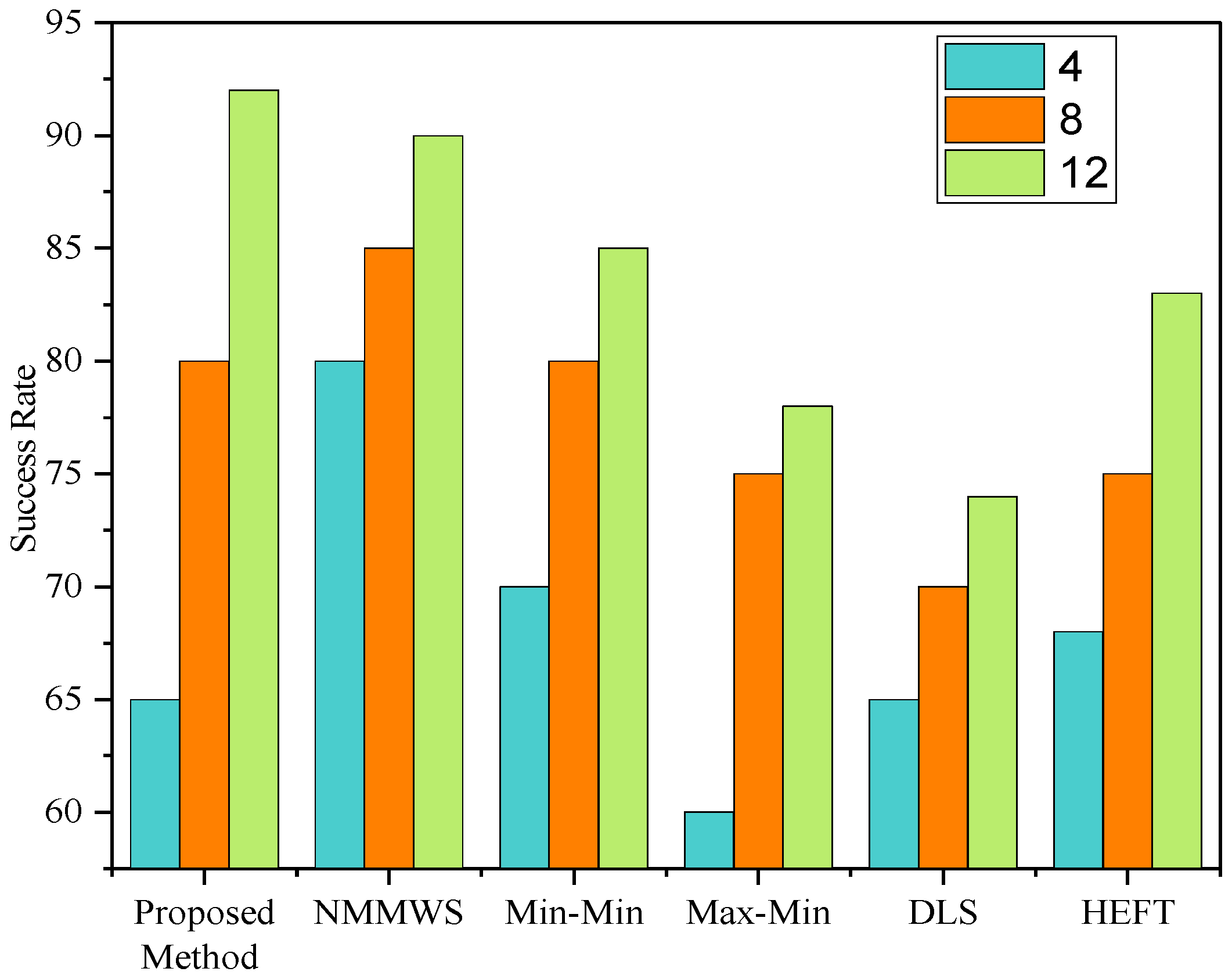
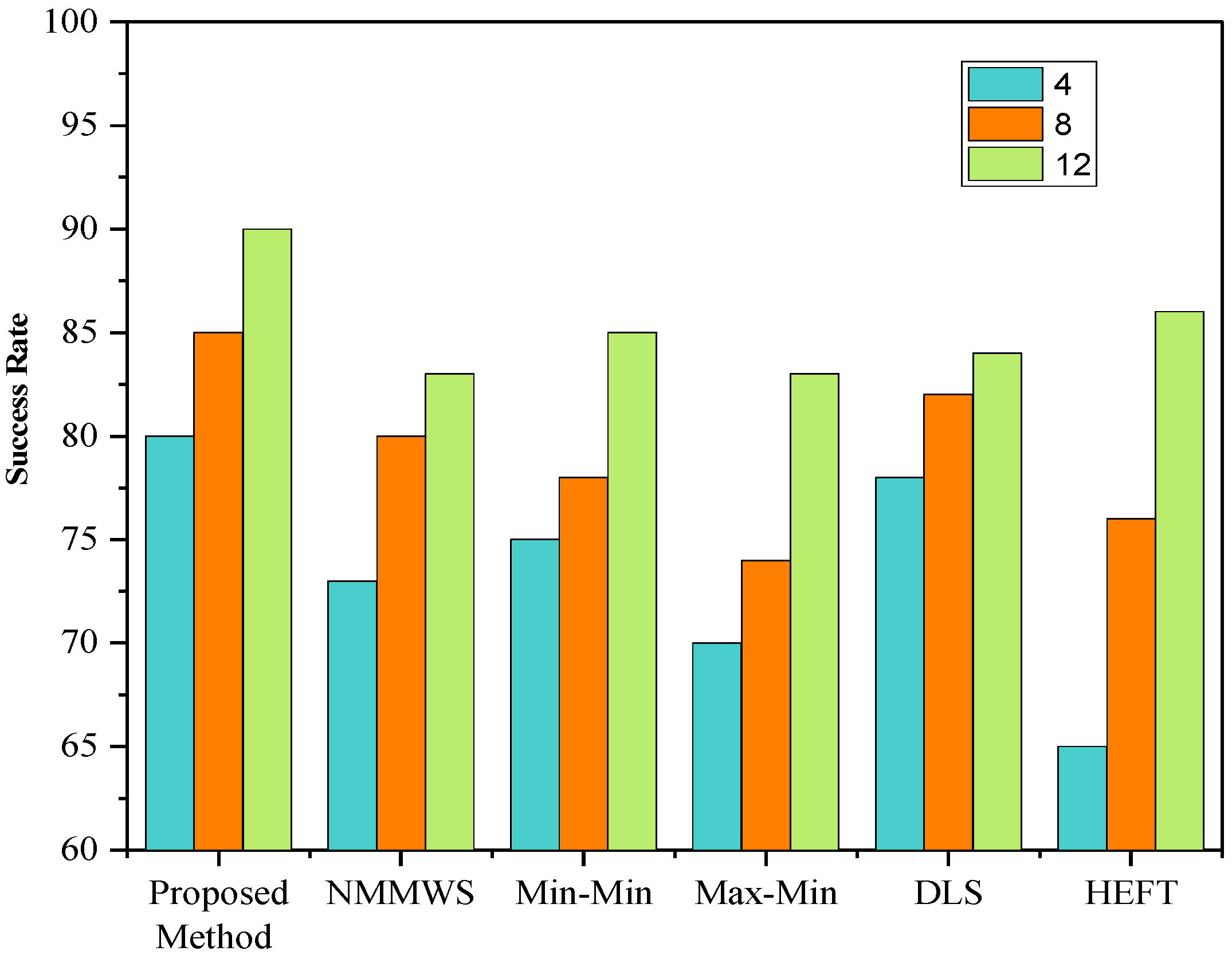
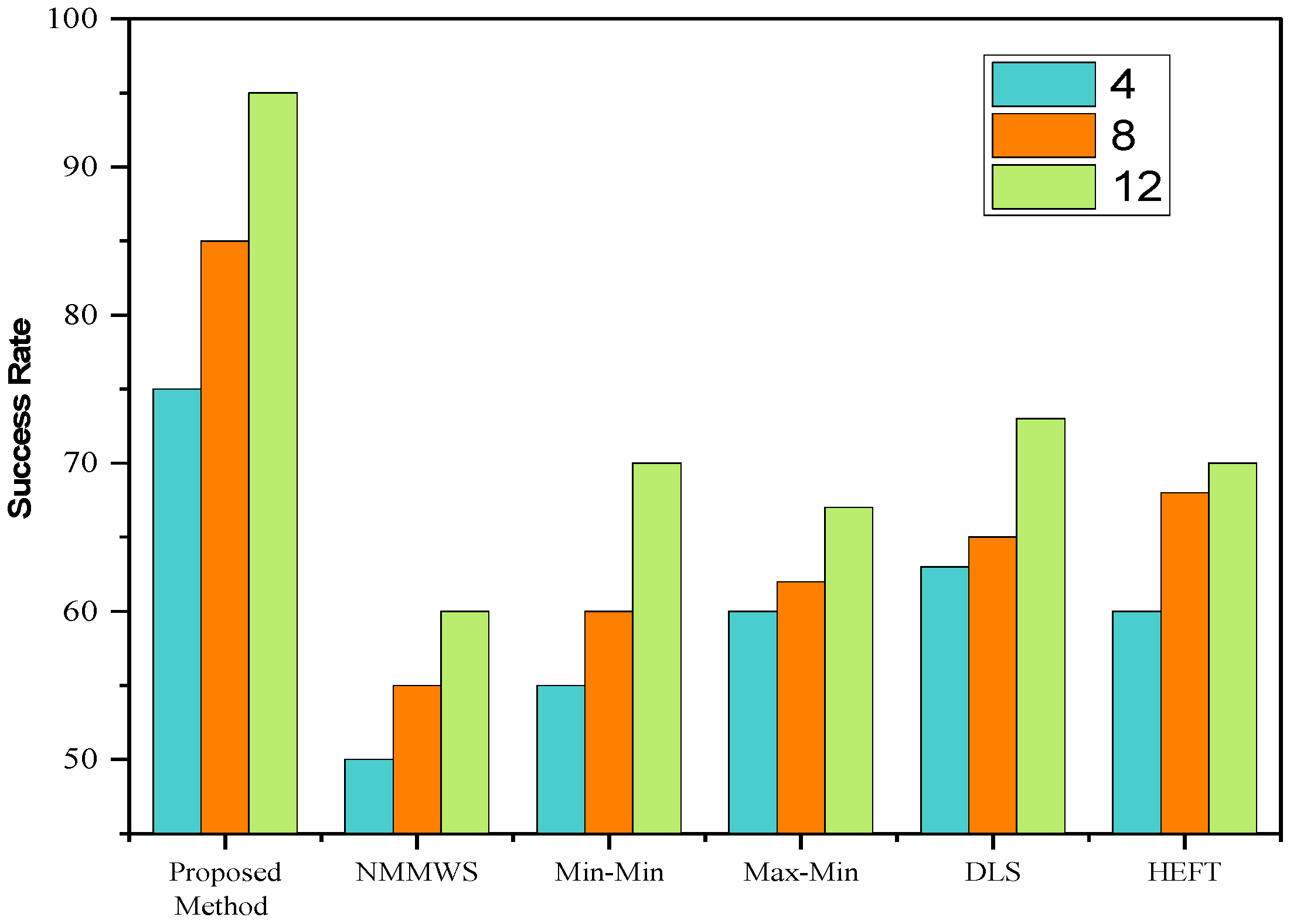
5. Simulation and Performance Evaluations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bardsiri, A.; Hashemi, S. A review of workflow scheduling in cloud computing environment. Int. J. Comput. Sci. Manag. Res. 2012, 1, 348–351. [Google Scholar]
- Zhu, Z.; Zhang, G.; Li, M.; Liu, X. Evolutionary multi-objective workflow scheduling in cloud. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1344–1357. [Google Scholar] [CrossRef]
- Juve, G.; Chervenak, A.; Deelman, E.; Bharathi, S.; Mehta, G.; Vahi, K. Characterizing and profiling scientific workflows. Futur. Gener. Comput. Syst. 2013, 29, 682–692. [Google Scholar] [CrossRef]
- Rakrouki, M.A.; Alharbe, N. QoS-aware algorithm based on task flow scheduling in cloud computing environment. Sensors 2022, 22, 2632. [Google Scholar] [CrossRef]
- Mangalampalli, S.; Keshari, S.; Vamsi, S.; Mangalampalli, K. Multi objective task scheduling in cloud computing using cat swarm optimization algorithm. Arab. J. Sci. Eng. 2021. [Google Scholar] [CrossRef]
- Nabi, S.; Ahmad, M.; Ibrahim, M.; Hamam, H. AdPSO: Adaptive PSO-Based task scheduling approach for cloud computing. Sensors 2022, 22, 920. [Google Scholar] [CrossRef]
- Wu, Q.; Ishikawa, F.; Zhu, Q.; Xia, Y.; Wen, J. Deadline-Constrained cost optimization approaches for workflow scheduling in clouds. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 3401–3412. [Google Scholar] [CrossRef]
- Yu, J.; Buyya, R.; Ramamohanarao, K. Workflow Scheduling Algorithms for Grid Computing; Springer: Berlin/Heidelberg, Germany, 2008; Volume 146. [Google Scholar] [CrossRef]
- Zhang, H.; Shi, J.; Deng, B.; Jia, G.; Han, G.; Shu, L. MCTE: Minimizes task completion time and execution cost to optimize scheduling performance for smart grid cloud. IEEE Access 2019, 7, 134793–134803. [Google Scholar] [CrossRef]
- Reddy, P.V.; Reddy, K.G. An analysis of a meta heuristic optimization algorithms for cloud computing. In Proceedings of the 2021 5th International Conference on Information Systems and Computer Networks (ISCON), Mathura, India, 22–23 October 2021. [Google Scholar] [CrossRef]
- Anwar, N.; Deng, H. A hybrid metaheuristic for multi-objective scientific workflow scheduling in a cloud environment. Appl. Sci. 2018, 8, 538. [Google Scholar] [CrossRef]
- Malik, N.; Sardaraz, M.; Tahir, M.; Shah, B.; Ali, G.; Moreira, F. Energy-efficient load balancing algorithm for workflow scheduling in cloud data centers using queuing and thresholds. Appl. Sci. 2021, 11, 5849. [Google Scholar] [CrossRef]
- Cao, H.; Jin, H.; Wu, X.; Wu, S.; Shi, X. DAGMap: Efficient and dependable scheduling of DAG workflow job in grid. J. Supercomput. 2010, 51, 201–223. [Google Scholar] [CrossRef]
- Wu, Q.; Zhou, M.; Zhu, Q.; Xia, Y.; Wen, J. MOELS: Multiobjective evolutionary list scheduling for cloud workflows. IEEE Trans. Autom. Sci. Eng. 2020, 17, 166–176. [Google Scholar] [CrossRef]
- Masdari, M.; ValiKardan, S.; Shahi, Z.; Azar, S.I. Towards workflow scheduling in cloud computing: A comprehensive analysis. J. Netw. Comput. Appl 2016, 66, 64–82. [Google Scholar] [CrossRef]
- Durillo, J.J.; Fard, H.M.; Prodan, R. MOHEFT: A multi-objective list-based method for workflow scheduling. In Proceedings of the 4th IEEE International Conference on Cloud Computing Technology and Science Proceedings, Taipei, Taiwan, 3–6 December 2012; pp. 185–192. [Google Scholar] [CrossRef]
- Habibi, M.; Jafari, N. Multi-objective task scheduling in cloud computing using an imperialist competitive algorithm. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 289–293. [Google Scholar] [CrossRef]
- El Din Hassan Ali, H.G.; Ali, H.G.E.D.H.; Saroit, I.A.; Kotb, A.M. Grouped tasks scheduling algorithm based on QoS in cloud computing network. Egypt. Inform. J. 2017, 18, 11–19. [Google Scholar] [CrossRef]
- Zhou, N.; Li, F.F.; Xu, K.; Qi, D. Concurrent workflow budget- and deadline-constrained scheduling in heterogeneous distributed environments. Soft Comput. 2018, 22, 7705–7718. [Google Scholar] [CrossRef]
- Nasr, A.A.; El-Bahnasawy, N.A.; Attiya, G.; El-Sayed, A. Cost-effective algorithm for workflow scheduling in cloud computing under deadline constraint. Arab. J. Sci. Eng. 2019, 44, 3765–3780. [Google Scholar] [CrossRef]
- Verma, A.; Kaushal, S. Cost-time efficient scheduling plan for executing workflows in the cloud. J. Grid Comput. 2015, 13, 495–506. [Google Scholar] [CrossRef]
- Chakravarthi, K.K.; Shyamala, L.; Vaidehi, V. Budget aware scheduling algorithm for workflow applications in IaaS clouds. Clust. Comput. 2020, 23, 3405–3419. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, G.; Sun, J.; Zhou, J.; Wei, T.; Hu, S. Minimizing cost and makespan for workflow scheduling in cloud using fuzzy dominance sort based HEFT. Future Gener. Comput. Syst. 2019, 93, 278–289. [Google Scholar] [CrossRef]
- Rodriguez, M.A.; Buyya, R.A. Taxonomy and survey on scheduling algorithms for scientific workflows in IaaS cloud computing environments. Concurr. Comput. Pract. Exp. 2017, 29, e4041. [Google Scholar] [CrossRef]
- Dubey, K.; Kumar, M.; Sharma, S.C. Modified HEFT algorithm for task scheduling in cloud environment. Procedia Comput. Sci. 2018, 125, 725–732. [Google Scholar] [CrossRef]
- Arabnejad, V.; Bubendorfer, K.; Ng, B. Budget and deadline aware e-science workflow scheduling in clouds. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 29–44. [Google Scholar] [CrossRef]
- Patra, S.S. Energy-Efficient task consolidation for cloud data center. Int. J. Cloud Appl. Comput. 2018, 8, 117–142. [Google Scholar] [CrossRef]
- Mohammadzadeh, A.; Masdari, M.; Gharehchopogh, F.S. Energy and Cost-Aware Workflow Scheduling in Cloud Computing Data Centers Using a Multi-Objective Optimization Algorithm. J. Netw. Syst. Manag. 2021, 29, 1–34. [Google Scholar] [CrossRef]
- Gupta, I.; Kumar, M.S.; Jana, P.K. Efficient workflow scheduling algorithm for cloud computing system: A Dynamic priority-based approach. Arab. J. Sci. Eng. 2018, 43, 7945–7960. [Google Scholar] [CrossRef]
- Yakubu, I.Z.; Aliyu, M.; Musa, Z.A.; Matinja, Z.I.; Adamu, I.M. Enhancing cloud performance using task scheduling strategy based on resource ranking and resource partitioning. Int. J. Inf. Technol. 2021, 13, 759–766. [Google Scholar] [CrossRef]
- Rawat, P.S.; Dimri, P.; Saroha, G.P. Virtual machine allocation to the task using an optimization method in cloud computing environment. Int. J. Inf. Technol. 2020, 12, 485–493. [Google Scholar] [CrossRef]
- Kaur, A.; Kaur, B.; Singh, D. Meta-heuristic based framework for workflow load balancing in cloud environment. Int. J. Inf. Technol. 2019, 11, 119–125. [Google Scholar] [CrossRef]
- Kamanga, C.T.; Bugingo, E.; Badibanga, S.N.; Mukendi, E.M. A multi-criteria decision making heuristic for workflow scheduling in cloud computing environment. J. Supercomput. 2022, 1–22. [Google Scholar] [CrossRef]
- Qin, S.; Pi, D.; Shao, Z. AILS: A budget-constrained adaptive iterated local search for workflow scheduling in cloud environment. Expert. Syst. Appl. 2022, 198, 116824. [Google Scholar] [CrossRef]
- Belgacem, A.; Beghdad-Bey, K. Multi-objective workflow scheduling in cloud computing: Trade-off between makespan and cost. Clust. Comput. 2022, 25, 579–595. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, L.; Xiao, M.; Wen, Z.; Peng, C. EM_WOA: A budget-constrained energy consumption optimization approach for workflow scheduling in clouds. Peer-Peer Netw. Appl. 2022, 15, 973–987. [Google Scholar] [CrossRef]
- Chakravarthi, K.K.; Neelakantan, P.; Shyamala, L.; Vaidehi, V. Reliable budget aware workflow scheduling strategy on multi-cloud environment. Clust. Comput. 2022, 25, 1189–1205. [Google Scholar] [CrossRef]
- Gupta, I.; Kumar, M.S.; Jana, P.K. Compute-intensive workflow scheduling in multi-cloud environment. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 315–321. [Google Scholar] [CrossRef]
- Panda, S.K.; Jana, P.K. Normalization-based task scheduling algorithms for heterogeneous multi-cloud environment. Inf. Syst. Front. 2018, 20, 373–399. [Google Scholar] [CrossRef]
- Panda, S.K.; Jana, P.K. Efficient task scheduling algorithms for heterogeneous multi-cloud environment. J. Supercomput. 2015, 71, 1505–1533. [Google Scholar] [CrossRef]
- Topcuoglu, H.; Hariri, S. Society IC. In Performance-Effective and Low-Complexity; IEEE: New York, NY, USA, 2002; Volume 13, pp. 260–274. [Google Scholar]
- Available online: https://confluence.pegasus.isi.edu/display/pegasus (accessed on 10 October 2022).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
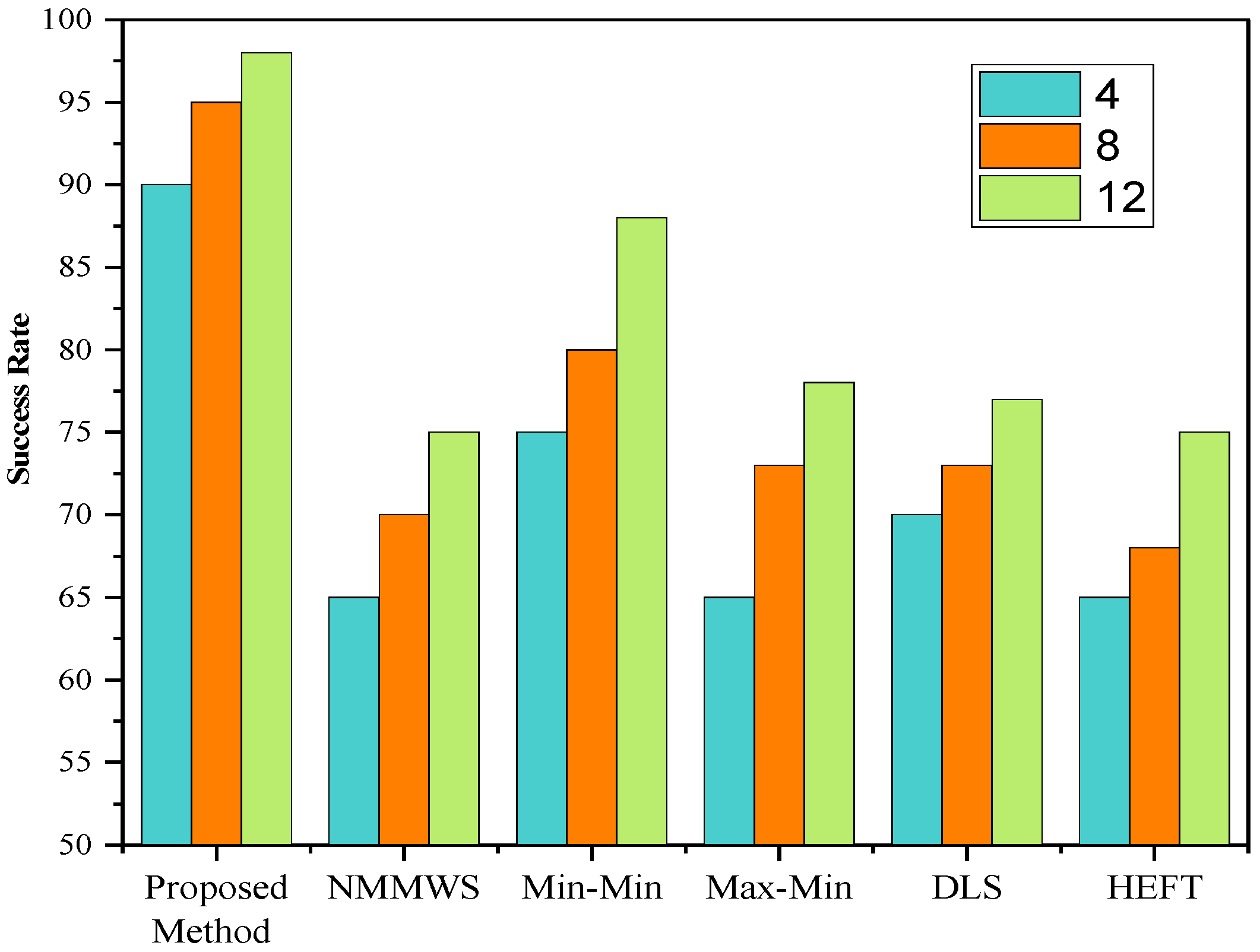{kind=link}
{kind=link}
| Ref. | Technique | Objectives | Tools | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Makespan | Energy Consumption | Cost | Budget | Cloud Utilization | Deadline | Execution Time | Response Time | Resource Utilization | Load Balancing | |||
| [25] | Modified HEFT | ✓ | - | - | - | - | - | - | - | - | - | Cloudsim |
| [26] | BDAS | - | - | - | ✓ | - | - | ✓ | - | - | - | Cloudsim |
| [27] | MinIncreaseInEnergy, NoIdleMachineECTC, MaxUtilECTCandNoIdleMachineMaxUtil | - | ✓ | - | - | - | - | - | - | ✓ | - | Cloudsim |
| [22] | NBWS | - | - | - | ✓ | - | - | - | - | - | - | Cloudsim |
| [28] | BHGALO-GOA | ✓ | - | ✓ | - | - | - | - | - | - | - | Workflowsim |
| [13] | DAGMap | - | - | - | - | - | - | ✓ | - | ✓ | - | Grid |
| [29] | NMMWS | ✓ | - | - | - | ✓ | - | - | - | - | - | MATLAB |
| [19] | MW-HBDCS | - | - | - | ✓ | - | ✓ | - | - | - | - | SimGrid |
| [23] | FDHEFT | - | - | ✓ | ✓ | - | - | - | - | - | - | Realtime |
| [21] | BDHEFT | - | - | ✓ | - | - | - | - | - | - | - | Cloudsim |
| [30] | Resource ranking and partitioning | - | - | - | - | - | - | - | ✓ | - | - | Cloudsim |
| [31] | BB-BC | - | - | ✓ | - | - | - | ✓ | - | - | - | Cloudsim |
| [32] | PEFT | - | - | - | - | - | - | - | - | - | ✓ | Workflowsim |
| [33] | MCDM | ✓ | - | ✓ | - | - | - | - | - | - | - | Realtime |
| [34] | HBCWSP | ✓ | - | - | ✓ | - | - | - | - | - | - | Realtime |
| [35] | HEFT-ACO | ✓ | - | ✓ | - | - | - | - | - | - | - | Workflowsim |
| [36] | EM-WOA | - | ✓ | - | ✓ | - | - | - | - | - | - | cloudsim |
| [37] | NRBWS | ✓ | - | - | ✓ | - | - | - | - | - | - | Cloudsim |
| Abbreviations | Definitions |
|---|---|
| DTT | Data transfer time |
| DTTp,q | Data transfer time from Tp to Tq |
| CS | Cloud server |
| Ect | Estimated computation time |
| Ms | Makespan |
| Acu | Average cloud utilization |
| tp | Predecessor task |
| ts | Successor task |
| Est | Early start time |
| Eft | Early finish time |
| N_Ect | Normalized estimated computation time |
| Ptvm | Processing time on VM |
| Rsame | Same resource |
| Th(dTi) | A threshold value of each task, Ti |
| RLi | Ready List of tasks at level 1 of DAG |
| T_N_Ect | Temporary normalized estimated computation time |
| T_Ect | Temporary estimated computation time |
| Act | Actual completion time |
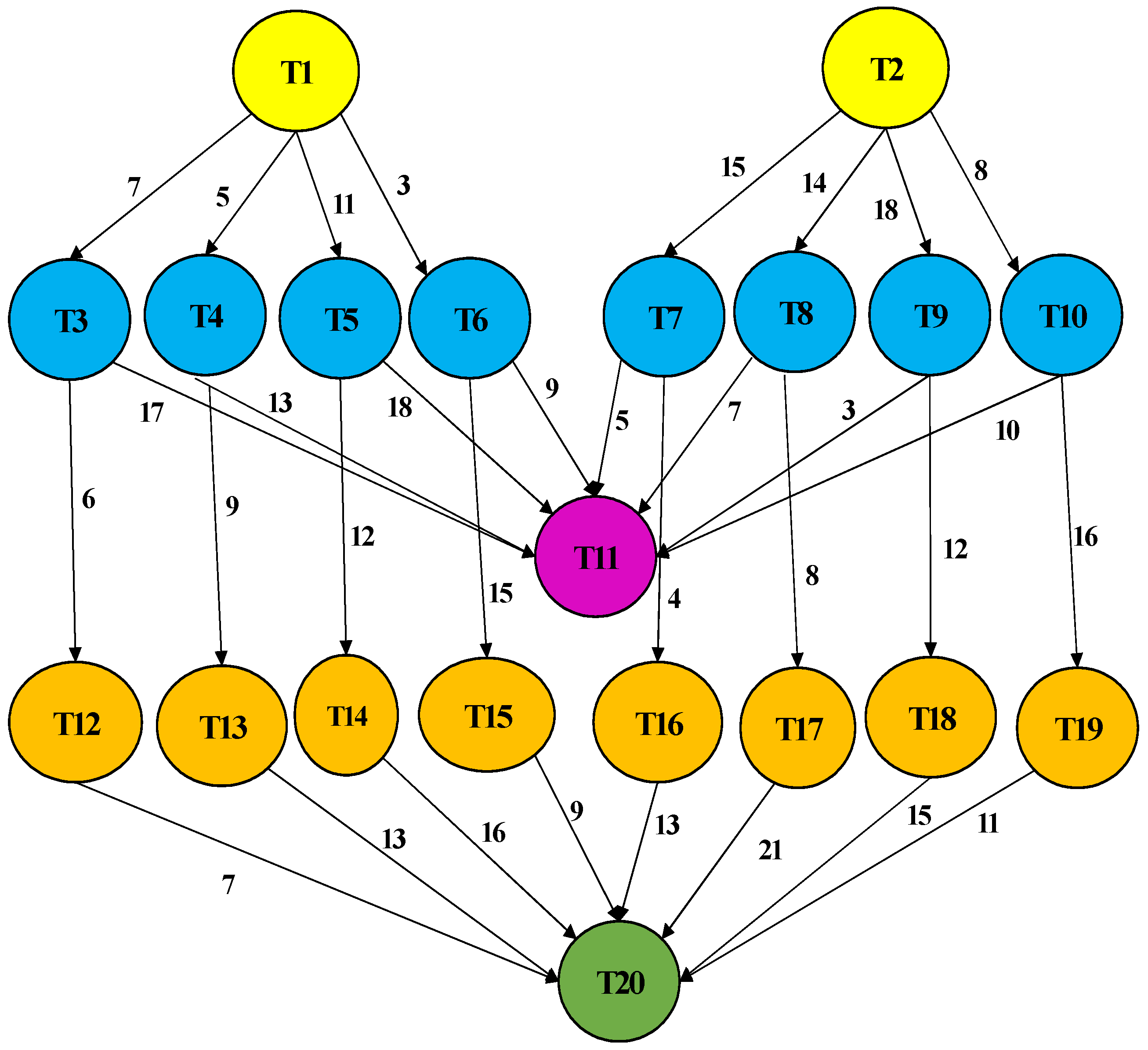
| Tasks | T1 | T2 | T3 | T4 | T5 | T6 | T7 | T8 | T9 | T10 | T11 | T12 | T13 | T14 | T15 | T16 | T17 | T18 | T19 | T20 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T1 | - | - | 7 | 5 | 11 | 3 | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| T2 | - | - | - | - | - | - | 15 | 14 | 18 | 8 | - | - | - | - | - | - | - | - | - | - |
| T3 | - | - | - | - | - | - | - | - | - | - | 17 | 6 | - | - | - | - | - | - | - | - |
| T4 | - | - | - | - | - | - | - | - | - | - | 13 | - | 9 | - | - | - | - | - | - | - |
| T5 | - | - | - | - | - | - | - | - | - | - | 18 | - | - | 12 | - | - | - | - | - | - |
| T6 | - | - | - | - | - | - | - | - | - | - | 9 | - | - | - | 15 | - | - | - | - | - |
| T7 | - | - | - | - | - | - | - | - | - | - | 5 | - | - | - | - | 4 | - | - | - | - |
| T8 | - | - | - | - | - | - | - | - | - | - | 7 | - | - | - | - | - | 8 | - | - | - |
| T9 | - | - | - | - | - | - | - | - | - | - | 3 | - | - | - | - | - | - | 12 | - | - |
| T10 | - | - | - | - | - | - | - | - | - | - | 10 | - | - | - | - | - | - | - | 16 | - |
| T11 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| T12 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 7 |
| T13 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 13 |
| T14 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 16 |
| T15 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 9 |
| T16 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 13 |
| T17 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 21 |
| T18 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 15 |
| T19 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 11 |
| T20 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| T1 | T2 | T3 | T4 | T5 | T6 | T7 | T8 | T9 | T10 | T11 | T12 | T13 | T14 | T15 | T16 | T17 | T18 | T19 | T20 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CS1 | vm1 | 17 | 14 | 19 | 13 | 19 | 13 | 15 | 19 | 13 | 19 | 13 | 15 | 18 | 20 | 11 | 16 | 22 | 18 | 14 | 19 |
| vm2 | 14 | 17 | 17 | 20 | 20 | 18 | 15 | 20 | 17 | 15 | 22 | 21 | 17 | 18 | 18 | 15 | 18 | 16 | 12 | 17 | |
| CS2 | Vm3 | 13 | 14 | 16 | 13 | 21 | 13 | 13 | 13 | 13 | 16 | 14 | 22 | 16 | 13 | 21 | 19 | 22 | 11 | 16 | 10 |
| Vm4 | 22 | 16 | 12 | 14 | 15 | 18 | 14 | 18 | 19 | 13 | 12 | 14 | 14 | 16 | 17 | 12 | 23 | 17 | 19 | 24 |
| Tasks | EST | EFT | ACT | VMID |
|---|---|---|---|---|
| 1 | 0 | 13 | 13 | 3 |
| 2 | 0 | 14 | 14 | 1 |
| 3 | 13 | 25 | 12 | 4 |
| 4 | 13 | 26 | 13 | 1 |
| 5 | 13 | 28 | 15 | 4 |
| 6 | 13 | 26 | 13 | 1 |
| 7 | 16 | 29 | 13 | 3 |
| 8 | 20 | 33 | 13 | 3 |
| 9 | 14 | 27 | 13 | 1 |
| 10 | 16 | 29 | 13 | 4 |
| 11 | 39 | 51 | 12 | 4 |
| 12 | 25 | 39 | 14 | 1 |
| 13 | 29 | 43 | 14 | 4 |
| 14 | 28 | 51 | 13 | 3 |
| 15 | 26 | 37 | 11 | 1 |
| 16 | 29 | 41 | 12 | 4 |
| 17 | 37 | 55 | 18 | 2 |
| 18 | 32 | 43 | 11 | 3 |
| 19 | 33 | 45 | 12 | 2 |
| 20 | 65 | 75 | 10 | 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pillareddy, V.R.; Karri, G.R. MONWS: Multi-Objective Normalization Workflow Scheduling for Cloud Computing. Appl. Sci. 2023, 13, 1101. https://doi.org/10.3390/app13021101
Pillareddy VR, Karri GR. MONWS: Multi-Objective Normalization Workflow Scheduling for Cloud Computing. Applied Sciences. 2023; 13(2):1101. https://doi.org/10.3390/app13021101
Chicago/Turabian StylePillareddy, Vamsheedhar Reddy, and Ganesh Reddy Karri. 2023. "MONWS: Multi-Objective Normalization Workflow Scheduling for Cloud Computing" Applied Sciences 13, no. 2: 1101. https://doi.org/10.3390/app13021101
APA StylePillareddy, V. R., & Karri, G. R. (2023). MONWS: Multi-Objective Normalization Workflow Scheduling for Cloud Computing. Applied Sciences, 13(2), 1101. https://doi.org/10.3390/app13021101