1. Introduction
Low-illumination environments are commonplace and have significant relevance to our daily lives. In recent years, computer vision has shown impressive performance in visual and speech recognition areas. Object detection, one of the fundamental tasks in computer vision, has found widespread applications in fields like autonomous driving and video surveillance. However, due to poor illumination conditions in real-world environments, object recognition confronts substantial difficulties. Recognizing low-illumination situations is essential for locating prospective things in the surrounding area. Under low-illumination conditions, images may suffer from distortion, low signal-to-noise ratio, low brightness, and substantial noise, leading to a significant increase in both false positives and false negatives in object detection.
Early low-illumination object detection [
1] was usually achieved using cameras with infrared imaging; widespread use was prevented due to their sensitivity to temperature information and high cost. However, research on advanced tasks, such as object detection in low-illumination environments, remains limited. With the advent of deep learning, numerous successful object-detection algorithms have been proposed. These include two-stage object-detection algorithms exemplified by Fast R-CNN [
2] (which is a faster variation of regions with CNN feature) and Faster R-CNN [
3], as well as single-stage object-detection algorithms exemplified by YOLO [
4] (you only look once–which turns an object-detection problem into a regression problem) and FCOS [
5] (
Figure 1).
Most of the current studies on low-illumination treated image enhancement as a pre-processing step, and [
6] proposed a low-illumination object-detection algorithm combining deep convolutional adversarial generation network and Faster RCNN to generate normal illumination-like images by adversarial generation network. To enhance the detection performance, feature fusion and multi-scale pooling were incorporated into Faster R-CNN. The human eye, on the other hand, is insufficient for directly evaluating the mean average precision (mAP) of object detection. Moreover, when enhancing low-illumination images, algorithms may lead to noise and the loss of important image features potentially. Consequently, achieving a higher detection mAP becomes challenging. To mitigate these detrimental effects, recent research has focused on directly optimizing the entire object-detection network. These efforts aim to minimize the negative impact on object detection in low-illumination environments and enhance overall detection performance. For example, Ref. [
7] introduced the context fusion and feature pyramid module based on RFP-Net [
8] to improve the ability of feature extraction for low-light images. However, the major determinant of detection performance is light intensity, and detection performance cannot be significantly enhanced in the event of severe underexposure.
To address the above shortcomings, this paper investigates an end-to-end low-illumination object-detection algorithm with higher accuracy, a simpler structure, and the ability to output detection results on low-illumination images. In our approach, we introduce a low-level feature attention (LFA) module into the backbone architecture. This module generates feature maps with varying perceptual fields using different kernel sizes. By performing channel concatenation, we are able to learn the significance of each channel in the feature map, facilitating effective information fusion. Then, we suggest a feature fusion neck (FFN) after the backbone that can aggregate both high-level and low-level features. At this stage, we utilized a structure similar to the feature pyramid, to enable mutual learning among feature maps from different layers, improving the feature expression ability of each feature map and enabling the better fusion of rich low-level feature information at the neck part. Finally, we modified the original network’s coupled head to a context-spatial decoupling head (CSDH), which fuses semantic information from deep features in the classification branch for classification tasks, and shallow spatial information in the regression branch to improve the accuracy of regression tasks.
This paper makes three main contributions, which are as follows:
We have made improvements to the traditional object-detection pipeline to achieve higher accuracy in low-illumination environments compared to traditional object-detection algorithms. This provides a solid foundation for downstream tasks such as night-time monitoring and driving.
We propose the LFA module, the FFN neck, and the CSDH head. The LFA module improves the feature extraction ability of the backbone network by fusing channel information from different receptive fields. The FFN neck boosts the feature maps of each layer carrying out mutual learning to fuse information, avoiding the loss of information during the process of feature pyramid feature fusion and improving the feature representation capability. The CSDH head enables the branches of classification and regression to better focus on the tasks that belong to them, and extract enough contextual and spatial information.
Experimental results on the ExDark dataset show that our work has achieved significant improvements, with an increase of 0.5% to 1.7% compared to the baseline. We also compared the results of training with images enhanced using low-light techniques and found that traditional enhancement algorithms only improve the visual quality of the images and may not necessarily improve the accuracy of object detection.
2. Related Work
2.1. Low-Illumination Image Enhancement
Low-illumination images commonly suffer from inadequate contrast and brightness, making it challenging for the human eyes to discern image details. Numerous low-illumination image-enhancement algorithms have been proposed, with histogram equalization [
9] being a classic method. While histogram equalization is simple and computationally efficient, it can result in the loss of crucial image details due to excessive merging of grayscale levels. Building upon the dehazing technique, the enhancement algorithm [
10] achieves a normal illuminated image by inversely processing the low-illumination image after dehazing. However, this approach tends to sacrifice numerous details in over-bright areas. Another alternative is a weight-sharing illumination learning enhancement algorithm with a self-calibration module [
11], but it requires pre-training of an SCI network, and substantial data and computing resources. Inspired by the Retinex theory [
12], which posits that object brightness is a combination of the object’s own reflection component and the ambient light, several algorithms have been developed, including RetinexNet [
13], MSR [
14], and LIME [
15].
The significant advancements in deep learning techniques have greatly contributed to the progress of low-level image restoration algorithms, such as image deblurring and dehazing. These algorithms utilize the potential of deep learning models to efficiently restore images by reducing the effects of blur and haze. Given the difficulty of obtaining ground truth data for enhancing low-illumination images, most existing methods rely on training with synthetic data. Since the Retinex theory is more suitable for human visual characteristics, it has become popular to combine it with deep learning, such as LightenNet [
16]. Zero-DCE [
17] uses a zero-reference loss function to guide the low-illumination image to transform into a normal image without the need for paired data, which has a strong generalization ability. EnlightenGAN [
18] is the first to successfully introduce non-paired training into low-illumination image enhancement and introduces an attention mechanism to adaptively adjust the brightness and contrast of the image.
2.2. Object Detection
Object detection is an important research direction in the field of computer vision, which aims to locate and identify the objects in an image. Traditional object-detection algorithms primarily depend on manually designed feature extractors and classifiers, including Haar features, HOG features, SIFT features, SVM classifiers, and AdaBoost classifiers, among others. Although these algorithms have certain effects in some simple scenarios, they perform poorly in complex scenarios and face difficulty with handling problems such as multi-scale, multi-pose, and occlusion. Since the introduction of R-CNN [
19], which employed convolutional neural networks for object detection, object-detection methods have been categorized into two main groups: one-stage methods and two-stage methods.
One-stage methods, also known as single-shot detectors, are object-detection algorithms that predict bounding box coordinates and classification scores directly in a single forward pass of the neural network. These methods offer faster inference times and simpler implementation compared to two-stage methods. The one-stage object-detection algorithm is designed to detect objects in images. In contrast to the two-stage object-detection algorithm, it eliminates the need for separate stages of generating candidate frames and predicting object categories. Instead, the one-stage algorithm performs a single forward pass, generating predictions for candidate frames by simultaneously outputting object categories, labels, and their corresponding scores. This approach enables fast and accurate object detection. The one-stage object-detection algorithm offers several advantages, including high computational efficiency, fast inference speed, and excellent performance when handling large-scale image datasets. Currently, one of the most well-known and widely used one-stage object-detection algorithms is You Only Look Once(YOLO) [
4], which is faster and suitable for real-time object-detection scenarios because it directly predicts bounding boxes and categories instead of using sliding windows or candidate regions. In addition, the Single Shot MultiBox Detector (SSD) [
20] and RetinaNet [
21] algorithm is also a commonly used one-stage object-detection algorithm, which has a slight advantage over YOLO in terms of accuracy. The speed and accuracy of one-stage object-detection algorithms have been greatly enhanced with the integration of deep learning techniques in computer vision.
Two-stage object-detection algorithms typically follow a two-step process: candidate frame proposal and object classification. In these algorithms, the initial stage involves generating candidate frames from the input image, while the subsequent step focuses on classifying and localizing the targets within those frames. One of the most popular two-stage object-detection methods is Faster R-CNN [
3], which introduced region proposal networks (RPN) that identify object proposals and classify them using a shared convolutional network. However, Faster R-CNN still suffers from slow region proposal steps, leading to the emergence of Mask R-CNN [
22]. This method incorporates a masked convolutional layer to efficiently generate bounding boxes, enabling effective object detection and segmentation. As a result, the overall performance of the algorithm is enhanced.
Another variant of two-stage object detection is the Cascade R-CNN [
23] algorithm, which improves the performance of the Faster R-CNN by introducing multiple stages of classification and refinement, leading to better accuracy and precision in object detection. The algorithm’s object-detection strategy involves using a series of RPNs that select high-quality proposal regions, and a cascade of classifiers that refine the detection results.
In addition to the approaches mentioned above, significant research efforts have been devoted to advancing anchor-free techniques in object-detection algorithms. Among these, CenterNet [
24] stands out as one of the most effective methods. CenterNet directly predicts the object centers, offering faster processing and improved accuracy compared to traditional anchor-based methods.
In conclusion, two-stage object-detection methods have received significant attention in the field of computer vision, with numerous advancements proposed to enhance accuracy, speed, and robustness. Future research endeavors can continue exploring diverse approaches to further enhance the efficiency and precision of two-stage detection methods.
2.3. Attention Mechanism
The attention mechanism has gained widespread use in deep learning for assigning varying weights to input information, allowing models to focus on crucial features. This mechanism has proven effective in improving both the performance and efficiency of deep learning models. In particular, the attention mechanism has gained significant traction in the field of computer vision, demonstrating its effectiveness in achieving favorable outcomes.
One of the pioneering works in this field is the Recurrent Models of Visual Attention [
25], which first introduced the utilization of attention mechanisms in computer vision. Their model, based on recurrent neural networks, dynamically selects regions of interest in images to enhance image classification performance. Since then, attention mechanisms have been further developed and applied in various ways to improve a wide range of computer vision tasks.
For instance, in a notable work by [
26], the spatial attention mechanism was introduced. This mechanism assigns distinct weights to feature maps corresponding to different spatial locations within a convolutional neural network. By doing so, the network can better focus on spatial locations that are more useful for the current task. Likewise, the channel attention mechanism, as presented by [
27], assigns varying weights to feature maps across different channels. This facilitates the enhancement of task-relevant information and mitigates the influence of irrelevant information, leading to improved performance in target tasks.
To combine both spatial and channel information, ref. [
28] proposed the CBAM module, which infers attention weights sequentially along both channel and spatial dimensions. This lightweight and general-purpose module has been shown to effectively improve the performance and generalization of the network. Additionally, Fcanet [
29], BAM [
30] and SKnet [
31] borrowed ideas from CBAM as well.
Attention mechanisms are a potent tool that empowers deep learning models to process input data more effectively, thereby enhancing their performance and efficiency. With ongoing development and continual improvements, attention mechanisms will continue to hold a crucial role in a wide range of deep learning tasks across diverse domains. Their versatility and effectiveness make them a valuable asset in advancing the capabilities of deep learning models.
3. Low-Illumination Object Detection
In this section, we first outline the motivation of the entire task to solve the difficult situation of object detection in low-illumination object environments. Secondly, we divided 3 sub-sections to introduce the modules we have proposed, LFA, FFN and CSDH, respectively.
3.1. Motivation
In this section, we introduce our customized low-illumination object-detection model, which is based on the YOLOv5s architecture. Given the backbone network’s frequent merging of objects with dark backgrounds during feature extraction, we propose the use of LFA. The traditional FPN+PAN structure may not adequately extract low-level features, impacting the accuracy of localization and classification. Hence, we design a feature fusion neck to merge high-level and low-level features effectively. Moreover, because the coupled detection head severely affects the performance of object detection in terms of both classification and localization, we replace it with a decoupled head and propose a context-spatial decoupling head, enabling the regression and classification branches to focus more on their respective tasks.
The overall module can be divided into three parts. The LFA mechanism is first added to the backbone network. After feature extraction, the features are passed to the FFN. Finally, the output is generated through the CSDH (
Figure 2).
3.2. Low-Level Feature Attention
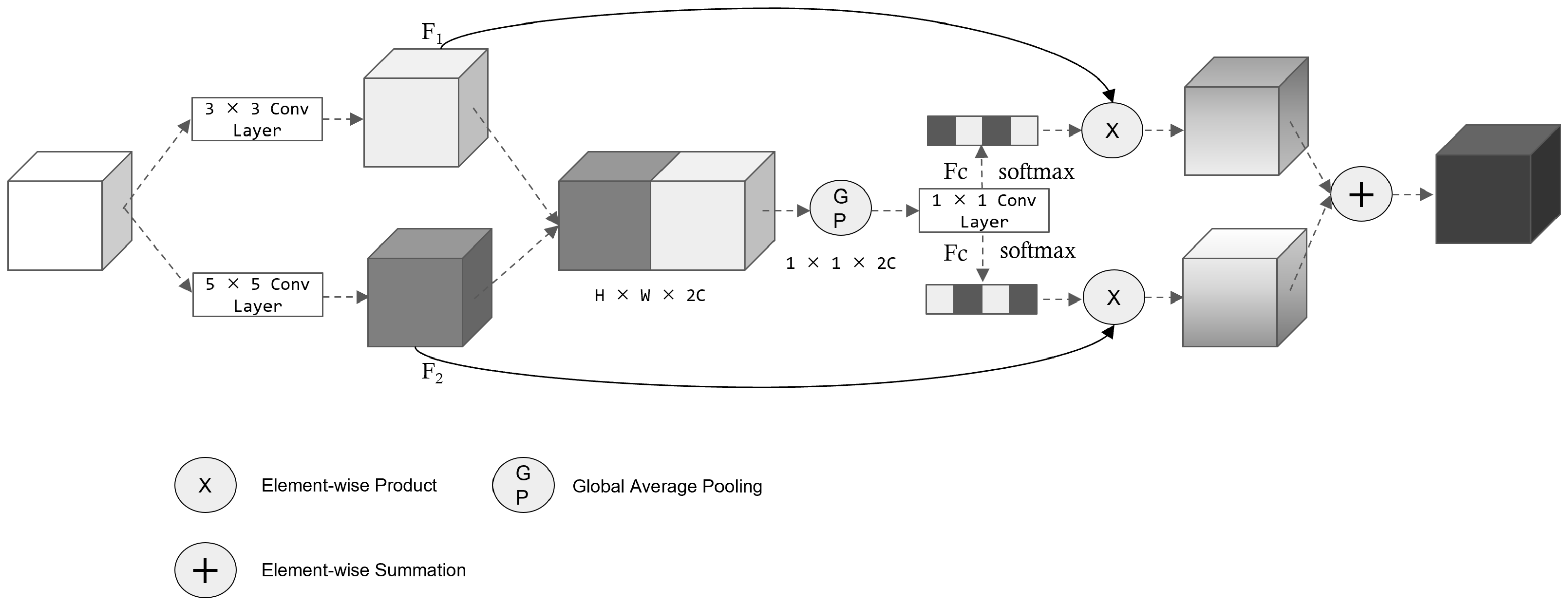
In low-illumination images, most objects are typically obscured within dark backgrounds, posing challenges for the detection network to accurately identify target regions and categories. Additionally, the extracted feature information from these images is typically sparse. Although image-enhancement techniques can enhance the visibility of features, they may also introduce unnecessary and misleading background features, which can negatively impact the overall detection performance. To address this issue and prioritize relevant feature information of the target region, this paper proposes an LFA.
The feature maps undergo separate convolution layers with kernel sizes of 3 × 3 and 5 × 5, respectively. This variation in kernel sizes allows the feature map to capture a range of perceptual fields within the same layer, promoting the extraction of deeper image features. To prevent interference between features extracted from different convolutional kernel sizes, we opt to perform a concatenation operation on the input features rather than adding them together. This approach ensures that the distinct information from each kernel size is preserved without causing unwanted blending or distortion. The fused features are
. After that, the features map is rescaled by using global average pooling in the dimension of the channel to encode the information features in the spatial dimension, and each two-dimensional feature channel is encoded as a parameter to express the global information of the feature channel. After global averaging pooling, the feature vector
has the same feature dimension as the fused features. The following formula is followed.
In the formula above,
H and
W represent the dimensions of the features, while
i and
j represent the spatial positions of the features. In order to make the feature channels correlated with each other, the feature vector
U is transformed into
after a
convolution layer, where
r is the scaling factor, in order to reduce the vector dimension and reduce the computational effort. Since it is a two-channel entry, we also need to branch through two fully connected layers to obtain two weight vectors. These weight vectors can be calculated using the following formulas:
In the formula, denotes the weight vectors obtained from two channels of 3 × 3 convolutional layers, and denotes the weight vectors obtained from two channels of 5 × 5 convolutional layers, where and are the fully connected layer’s parameters of the two corresponding branches to generate the weight vectors of the corresponding input features. denotes the operation to let the network know where to focus more in a low-illumination image.
Following the generation of two-feature weight vectors, the element-wise product operation is performed between
and
. This operation enhances the network’s focus on channels that contain relevant target feature information, thereby improving the expressive capability of low-level feature fusion. By assigning appropriate weights to the channels, the network can effectively emphasize the most informative features and enhance its ability to capture and represent the desired target features. Subsequently, the two feature maps are element-wise summed, effectively combining the corresponding elements and integrating the information from both feature matrices. This fusion process significantly contributes to improving the overall accuracy and performance of the model (
Figure 3).
3.3. Feature Fusion Neck
In low-illumination images, the low contrast levels necessitate the network to extract crucial low-level features, such as edges and shapes, from the original image to improve visibility and overall image quality. Although the FPN + PAN structure is widely utilized in various object-detection algorithms to improve detection accuracy and multi-scale localization capabilities, the conventional detection network often faces challenges in extracting adequate low-level features from the image. This limitation significantly impacts the accuracy of both classification and localization tasks.
To address the aforementioned issues, this paper proposes a neck that can fuse high- and low-level features, known as FFN. The proposed model has the ability to learn features from each layer of the feature map, enabling the neck to better comprehend the characteristics of low-level features and acquire more comprehensive low-level feature information. This capability enhances the model’s understanding and representation of the important details present in the image, unlike the PAN structure, which only has one top-down and bottom-up pathway. To ensure a more effective feature fusion process, the model removes input nodes with only one edge, such as the first node on the right side of
. This decision is made considering that nodes with only one input without feature fusion contribute less to the overall feature representation. The network often faces challenges in attending to feature information that is too distant in terms of spatial or temporal proximity. It can be challenging for the network to effectively capture and utilize such distant information. While the correlation between features of the current layer and output features that span a large region may be lower, creating a divide. Given a list of multi-scale features
where
represents the feature at level
.
is the output where
f is the function which we will introduce next. So the feature map of the last layer with backbone, after two upsampling,
, increases the feature map to four times the original one and performs the
operation (feature map summation) with
and
. Similarly, the
feature map after one downsampling,
, the feature map is reduced to two times the original one, and the
operation is performed with the upsampled
. These two operations further fuse feature information from the multi-scale perceptual field (
Figure 4).
3.4. Context-Spatial Decoupling Head
In contrast to image classification tasks, object detection involves not only classifying objects but also precisely localizing their positions within an image. For instance, the detection head of the popular YOLOv5 detector follows a similar design to YOLOv3 [
32], incorporating three separate receptive field branches at the output end. Each branch has a coupled head that directly predicts the regression and classification tasks in a single step. The shared head for localization and classification can be traced back to the two-stage object-detection network Fast R-CNN [
2], which was a standard approach in early object-detection tasks. However, as proposed in the RCL [
33] paper, the authors found through experimental analysis that the two head structures exhibit exactly opposite preferences for the two sub-tasks of classification and localization. The convolutional head is more suitable for localization, while the fully connected head is more suitable for classification tasks. The fully connected head has higher spatial sensitivity and a stronger ability to distinguish between a complete and a partial object, but it is not robust for regressing the entire object. Therefore, YOLOX [
34] proposed a decoupled head to improve the convergence speed and accuracy.
As mentioned earlier, classification tasks demand a higher level of semantic information derived from the context, which is naturally associated with deep feature maps. Therefore, it is reasonable to fuse the deep feature maps and integrate them into the current feature maps for classification tasks. Conversely, regression tasks necessitate more precise spatial information, which can be effectively provided by shallow feature maps. Consequently, the information from shallow feature maps is propagated to the subsequent layer of feature maps, allowing the model to capture finer spatial details and improve the accuracy of regression tasks.
In the classification head, the output feature map of the nth layer undergoes downsampling to align with the size of the (
n + 1)th layer’s feature map. Subsequently, the downsampled feature map is added to the feature map of the (
n + 1)th layer. The resulting feature map is then concatenated with the feature map of the (
n + 1)th layer to achieve the fusion of context semantic information, thereby enriching the overall context information available to the model (
Figure 5).
where Concat denotes concatenation, Add denotes feature map summation, and “
Ds” denotes downsampling. The feature map “
Cls” has half the size of
and twice the number of channels as
. This feature map is then fed into the classification head to obtain the classification prediction score. By using the proposed method, richer contextual semantic information can be obtained from a higher layer of the pyramid, particularly for images that are significantly impacted by illumination or those without texture.
In the localization head, shallow features are employed due to their ability to provide richer spatial detail information. These details are crucial in accurately performing the regression task, where precise localization of objects is required. Leveraging the spatial information present in shallow features improves the accuracy and effectiveness of regression in object localization. Therefore, the shallow feature map is then propagated to the next layer of feature maps to incorporate higher spatial detail correlation between adjacent feature maps and avoid generating gaps in the information. The localization head consists of several steps. Firstly, the feature map size is upsampled, followed by an ADD operation with the feature map from the previous layer. Subsequently, the fused feature map is downsampled and then concatenated with the original feature map. This process enables the integration of both high-level and low-level information, enhancing the localization capabilities of the model (
Figure 6).
In the following text, ”Us” denotes upsampling. The feature map “Loc” shares the same size as “Pn”, but has twice the number of channels. This feature map is then fed into the localization head to predict the bounding box for the Nth pyramid level.
Thus, the complete head is formed, and subsequent operations are consistent with YOLOX. To accomplish this, a 1 × 1 convolutional layer is utilized to adjust the number of channels to 256. Subsequently, two 3 × 3 convolutional layers are employed for both the classification and regression branches. The feature map size is then modified using a 1 × 1 convolutional layer. Additionally, an Intersection-over-Union (IoU) branch is incorporated into the regression branch to further refine the accuracy of regression tasks (
Figure 7).
4. Experiment
This section is dedicated to experiments conducted on the ExDark [
35] dataset of low-illumination images. Given the lack of a specific method for low-illumination object detection, the experiments in this paper compare the proposed algorithm with more widely used object detectors using mAP at 0.5 as the evaluation metric to measure its performance in low-illumination object detection. Furthermore, the study investigates the contribution of each proposed component to the model. We use CSPDarknet53 as the backbone, and it was pe-trained on ImageNet [
36] dataset. We use Adam [
37] as the optimizer. The training is divided into the first 50 epochs and the next 150 rounds. For the first 50 epochs we freeze the weight of the backbone feature extraction network, and only train the partial weight outside the backbone network, and we set the learning rate as 1 × 10
. For the next 150 epochs, we release the weight gradient of the backbone feature extraction network, allowing the network to automatically adjust all of the training parameters.
4.1. Detection Performance
The ExDark dataset is annotated for object detection, and this paper conducts both training and evaluation on this dataset. The dataset comprises 12 categories, namely Bicycle, Boat, Bottle, Bus, Car, Cat, Chair, Cup, Dog, Motorbike, People, and Table. It is partitioned into the training, validation, and test sets with an 8:1:1 ratio, following the official partitioning criteria. Using the same input size of 640 × 640, our proposed algorithm achieves a 1.7% improvement over the baseline, resulting in a detection accuracy of 64.6% and a significant improvement in mAP at 0.5.
Table 1 presents a comparison of the proposed algorithm with other popular object-detection algorithms, in terms of accuracy.
Table 1 displays a comparison of the proposed algorithm with other currently popular object-detection algorithms. And displayed in
Figure 8.
Additionally, this paper compares the performance of the proposed low-illumination object-detection algorithm with the combination of image-enhancement algorithms and the YOLO series algorithms on the ExDark dataset. The objective is to assess the effectiveness and superiority of the proposed algorithm in addressing the challenges posed by low-illumination conditions for object-detection tasks.
In this study, some deep learning-based low-illumination image-enhancement algorithms, including ZeroShot-RUAS [
38], Zero-DCE [
17], MBLLEN [
39], EnlightenGAN [
18], were combined with the basic object-detection models. The model weights of the image-enhancement network were retrained and integrated with the YOLOv5s object detector to conduct experiments on low-illumination object detection using the ExDark dataset. Specifically, the test images underwent an initial enhancement process using image-enhancement algorithms before being input into the object detector, thereby obtaining the mean Average Precision (mAP) associated with the respective algorithm (
Figure 9). We validate the benefits of the suggested low-illumination object-detection method in terms of detection accuracy through these studies, as shown in
Table 2.
Upon comparing the results in
Table 2, it can be observed that the proposed end-to-end low-illumination object-detection algorithm exhibits superior detection accuracy. On the other hand, a considerable drop in detection accuracy may result from preprocessing low-illumination pictures with deep-learning-based image-enhancement algorithms before feeding them into the object detector for detection. This suggests that, whereas improved images may somewhat enhance human visual perception, they may also cause the loss of important feature information that is necessary for object-detection tasks. Additionally, we compared the processing speed and training time of each method. It is evident that the approach without using enhancement algorithms, both in terms of processing speed and training time, outperforms the methods that involve pre-processing with enhancement algorithms.
4.2. Ablation Experiment
To further examine the impact of different modules on the experimental results, this section conducts ablation experiments on LEA, FFN, and CSDH. The aim is to analyze the influence of each module on the overall performance and effectiveness of the proposed algorithm.
In order to combine low-level features with original features and force the network to pay more attention to low-level features, the LEA module was added to the backbone in this part. The mAP increased by 0.5% when compared to the baseline. The FFN module was added in place of the original neck portion to improve feature expression capability and enable mutual learning of feature maps at each layer to prevent information loss during class pyramid feature fusion. The original baseline network head was switched out for the CSDH head, enabling the classification and regression branches to extract contextual and spatial data and improve the final detection accuracy. The mAP increased by 0.5% when compared to the baseline. Based on this, the effectiveness of the proposed modules was further demonstrated through the combination of different modules. The specific data are shown in
Table 3. And, we also provide all objects’ mAP 0.5/% in
Table 4. In each ablation experiment, the Bicycle category consistently achieves the highest accuracy, while the Table category exhibits the lowest accuracy. In conclusion, the overall differences in accuracy among the various object categories are relatively small across each experiment.
5. Application
To investigate the real-world performance of our improvement, we captured two sets of authentic low-illumination scene images using Xiaomi 12 and iPhone 11, respectively. We conducted object detection using both the baseline model and our improved model. As depicted in
Figure 10, we can clearly observe that our improved model demonstrates superior performance in real-world scenarios, outperforming the baseline model significantly.
6. Discussion and Limitation
Low-illumination images not only exhibit an unsatisfactory visual appearance, but also deliver compromised information for high-level computer vision applications such as object detection. In this paper, we propose three modules; namely, LFA, FFN, and CSDH, to address the issue of low detection accuracy in low-illumination environments. These modules enable end-to-end detection of low-illumination images. Ablation experiments are conducted to demonstrate the effectiveness of each module in
Table 3 and
Table 4.
We find that simply applying low-illumination enhancement algorithms prior to detection does not necessarily yield superior results. The enhanced images may appear visually better to human observers, aligning with [
7] and
Figure 9.
In our future work, it is crucial to incorporate more low-illumination object-detection datasets to further enhance the performance. Currently, our research is constrained by the limited availability of such datasets. Expanding the datasets for low-illumination object detection is necessary. Moreover, we have not taken into account the lightweight aspect of the algorithm, which may limit its effectiveness in downstream applications such as surveillance or onboard cameras. Lightweight optimization is one of our future objectives.
7. Conclusions
In order to solve the issue of object-detection accuracy reduction owing to a low-illumination environment, a low-illumination environment-based object detector is developed. To make the network focus on lower-level information, the LEA module is designed to be added to the backbone network, enhancing its ability to focus more attention in low-illumination conditions, the neck is modified to fuse low-level and high-level semantic information, avoiding the difficulty of extracting sufficient low-level feature information in the traditional FPN+PAN structure. Finally, the detection head part is altered so that its classification branch focuses more on semantic information from the context and the location branch will pay more attention to extracting more abundant spatial details from shallow features. According to experiments, the proposed module in the ExDark dataset increases results by 0.5% to 1.7% percentage points above the baseline. The algorithm suggested in this paper has a higher detection accuracy, and in the following work, lightweight research will be conducted to help with the low-illumination-detecting landing application.
Author Contributions
Conceptualization, Z.L. and S.W.; methodology, Z.L., S.W. and H.L.; software, S.W.; validation, Z.L., H.L. and Y.H.; formal analysis, Z.L., S.W., H.L. and Y.H.; resources, Z.L.; writing—original draft preparation, S.W., H.L. and Y.H.; writing—review and editing, S.W., H.L. and Y.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under grants (82272075), the Guangxi Science and Technology Project (AB21220037), the Innovation Project of Guangxi Graduate Education: YCBZ2022112.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors thank everyone that provided suggestions and assistance for this paper.
Conflicts of Interest
All the authors declare no conflict.
References
- Elguebaly, T.; Bouguila, N. Finite asymmetric generalized Gaussian mixture models learning for infrared object detection. Comput. Vis. Image Underst. 2013, 117, 1659–1671. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Rössler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C. Fcos: Fully convolutionalal one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Wang, K.; Liu, M.Z. Object Recognition at Night Scene Based on DCGAN and Faster R-CNN. IEEE Access 2020, 8, 193168–193182. [Google Scholar] [CrossRef]
- Xiao, Y.; Jiang, A.; Ye, J.; Wang, M.-W. Making of Night Vision: Object Detection Under Low-Illumination. IEEE Access 2020, 8, 123075–123086. [Google Scholar] [CrossRef]
- Liu, S.T.; Huang, D.; Wang, Y.H. Receptive Field Block Net for Accurate and Fast Object Detection. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Dong, X.; Wang, G.; Pang, Y.; Li, W.; Wen, J.; Meng, W.; Lu, Y. Fast efficient algorithm for enhancement of low lighting video. In Proceedings of the 12th IEEE Internationa Conference on Multimedia and Exposition; IEEE: Piscataway, NJ, USA, 2011. [Google Scholar]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Toward fast, flexible, and robust low-illumination image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Land, E.H.; McCann, J.J. Lightness and Retinex Theory. J. Opt. Soc. Am. 1971, 61, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Wenjing, W.; Wenhan, Y.; Liu, J. Deep retinex decomposition for low-illumination enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Rahman, Z.-U.; Jobson, D.J.; Woodell, G.A. Multi-scale retinex for color image enhancement. In Proceedings of the 3rd IEEE International Conference on Image Processing, Lausanne, Switzerland, 16–19 September 1996. [Google Scholar]
- Guo, X. Lime: A method for low-illumination image enhancement. In Proceedings of the 24th ACM Multimedia Conference (MM), Amsterdam, The Netherlands, 15–19 October 2016; pp. 87–91. [Google Scholar]
- Li, C.; Guo, J.; Porikli, F.; Pang, Y. LightenNet: A convolutionalal neural network for weakly illuminated image enhancement. Pattern Recognit. Lett. 2018, 104, 15–22. [Google Scholar] [CrossRef]
- Chunle, G.; Chongyi, L.; Jichang, G. Zero-reference deep curve estimation for low-illumination image enhancement. In Proceedings of the 33rd IEEE/CVF Conf on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1780–1789. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement Without Paired Supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3156–3164. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 783–792. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Wang, L.; Li, H.; Fu, Y. Rethinking classification and localization for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10186–10195. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Loh, Y.P.; Chan, C.S. Getting to know low-illumination images with the exclusively dark dataset. Comput. Vis. Image Underst. 2019, 178, 30–42. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired unrolling with cooperative prior architecture search for low-illumination image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10561–10570. [Google Scholar]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-illumination Image/Video Enhancement Using CNNs. BMVC 2018, 220, 4. [Google Scholar]
Figure 1.
Common object-detection algorithms for detecting conditions in low-illumination environments, for which is easy to see that the results are not good enough. Indeed, object detection in low-illumination conditions poses a significant challenge.
Figure 1.
Common object-detection algorithms for detecting conditions in low-illumination environments, for which is easy to see that the results are not good enough. Indeed, object detection in low-illumination conditions poses a significant challenge.
Figure 2.
The whole pipeline for low-illumination object detection. The overall architecture of the framework is similar to YOLOv5s. The difference between CSP1-X and CSP2-X is that the latter does not use Short-Cut. The role of SPPF is to perform multi-scale feature fusion, integrating the representations of the same feature map at different scales. We have incorporated LFA into the backbone network and replaced the original network structure’s neck and head with FFN and CSDH.
Figure 2.
The whole pipeline for low-illumination object detection. The overall architecture of the framework is similar to YOLOv5s. The difference between CSP1-X and CSP2-X is that the latter does not use Short-Cut. The role of SPPF is to perform multi-scale feature fusion, integrating the representations of the same feature map at different scales. We have incorporated LFA into the backbone network and replaced the original network structure’s neck and head with FFN and CSDH.
Figure 3.
The structure of our proposed low-level feature attention. By using two convolutional kernels of different sizes, different scales of features can be extracted, enabling the network to pay more attention to low-light conditions’ characteristics.
Figure 3.
The structure of our proposed low-level feature attention. By using two convolutional kernels of different sizes, different scales of features can be extracted, enabling the network to pay more attention to low-light conditions’ characteristics.
Figure 4.
This is the FFN structure proposed by us, which enhances the extraction capability of low-level features by fusing features of different feature map sizes.
Figure 4.
This is the FFN structure proposed by us, which enhances the extraction capability of low-level features by fusing features of different feature map sizes.
Figure 5.
The structures of our proposed classification head which realize the intersection of contextual semantic information to obtain richer contextual information.
Figure 5.
The structures of our proposed classification head which realize the intersection of contextual semantic information to obtain richer contextual information.
Figure 6.
The structures of our proposed location head which realizes the feature map of the shallow layer and the next layer feature map for information backflow.
Figure 6.
The structures of our proposed location head which realizes the feature map of the shallow layer and the next layer feature map for information backflow.
Figure 7.
This is our brand new header, through our proposed new classification branch and new regression branch, respectively.
Figure 7.
This is our brand new header, through our proposed new classification branch and new regression branch, respectively.
Figure 8.
Comparison of results between various object detection algorithms and our improved algorithm. It is evident from the visualization that our model are both effective and substantial.
Figure 8.
Comparison of results between various object detection algorithms and our improved algorithm. It is evident from the visualization that our model are both effective and substantial.
Figure 9.
Comparison of object-detection results before and after using image enhancement. After applying enhancement algorithms for detection, it is not necessarily the case that the results will be better than without enhancement. The enhancement effect may only have a significant impact on human perception, but for the detector, it may cause the loss of important feature information.
Figure 9.
Comparison of object-detection results before and after using image enhancement. After applying enhancement algorithms for detection, it is not necessarily the case that the results will be better than without enhancement. The enhancement effect may only have a significant impact on human perception, but for the detector, it may cause the loss of important feature information.
Figure 10.
Using Xiaomi 12 and iPhone 11, we captured two sets of images in low-illumination conditions. Comparing the results between the baseline model and our improved model, we observed a significant increase in accuracy with the improved model during practical usage. Moreover, the improved model successfully detected objects that the baseline model failed to identify.
Figure 10.
Using Xiaomi 12 and iPhone 11, we captured two sets of images in low-illumination conditions. Comparing the results between the baseline model and our improved model, we observed a significant increase in accuracy with the improved model during practical usage. Moreover, the improved model successfully detected objects that the baseline model failed to identify.
Table 1.
Comparison of detection accuracy on the ExDark dataset.
Table 1.
Comparison of detection accuracy on the ExDark dataset.
| Method | Backbone | mAP 0.5/% |
|---|
| YOLOv5s | CSPDarkNet | 62.9 |
| RetinaNet | ResNet50 | 58.1 |
| YOLOv4 | CSPDarkNet | 59.8 |
| EfficientDet-D0 | EfficientNet | 63.1 |
| Faster-RCNN | ResNet50 | 54.3 |
| Ours | CSPDarkNet | 64.6 |
Table 2.
Comparison of mAP 0.5%, processing speed, and training time among different methods.
Table 2.
Comparison of mAP 0.5%, processing speed, and training time among different methods.
| Method | mAP 0.5/% | Processing Speed/Ms | Training Time/h |
|---|
| Ours | 64.6 | 54.3 | 7.0 |
| Zero-DCE + Ours | 54.8 | 237.3 | 9.3 |
| ZeroShot-RUAS + Ours | 64.3 | 983.2 | 17.2 |
| EnlightenGan + Ours | 58.6 | 446.9 | 15.2 |
| MBLLEN + Ours | 63.4 | 993.5 | 18.3 |
Table 3.
Ablation experiments of different modules.
Table 3.
Ablation experiments of different modules.
| LEA | FFN | CSDH | mAP 0.5/% |
|---|
| ✓ | | | 63.4 |
| | ✓ | | 63.3 |
| | | ✓ | 63.4 |
| ✓ | | ✓ | 63.7 |
| | ✓ | ✓ | 63.5 |
| ✓ | ✓ | ✓ | 64.6 |
Table 4.
Ablation experiments of different modules on all objects, using the same evaluation mAP0.5/%.
Table 4.
Ablation experiments of different modules on all objects, using the same evaluation mAP0.5/%.
| LEA | FFN | CSDH | Bicycle | Boat | Bottle | Bus | Car | Cat | Chair | Cup | Dog | Motorbike | People | Table |
|---|
| ✓ | | | 80.3 | 55.2 | 53.1 | 77.3 | 74.4 | 54.1 | 54.3 | 59.4 | 61.3 | 70.7 | 70.9 | 49.5 |
| | ✓ | | 80.2 | 56.0 | 52.0 | 77.6 | 73.8 | 53.2 | 54.9 | 59.9 | 60.7 | 70.7 | 71.3 | 49.9 |
| | | ✓ | 80.1 | 55.5 | 52.0 | 77.3 | 73.9 | 53.7 | 54.8 | 60.1 | 61.1 | 70.6 | 71.2 | 49.9 |
| ✓ | | ✓ | 80.4 | 52.4 | 54.2 | 77.1 | 74.3 | 55.1 | 55.3 | 59.2 | 63.2 | 72.2 | 71.9 | 50.1 |
| | ✓ | ✓ | 80.7 | 52.0 | 53.0 | 78.5 | 74.5 | 56.0 | 51.9 | 60.2 | 63.5 | 71.1 | 70.3 | 49.9 |
| ✓ | ✓ | ✓ | 79.6 | 56.2 | 53.3 | 79.7 | 75.0 | 60.7 | 55.5 | 59.6 | 61.3 | 69.4 | 70.0 | 51.7 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}