Abstract
In this paper, we study the inference of the multicomponent stress–strength reliability (MSSR) based on the Chen distribution using progressively Type-II censored data. Both the stress and strength variables follow the Chen distribution with a common second shape parameter. The maximum likelihood estimates and the asymptotic confidence intervals of the MSSR are developed. The bootstrap confidence interval of the MSSR is also constructed. The Bayesian estimation of the MSSR is obtained under the generalized entropy loss function using the Markov Chain Monte Carlo method. To check the effectiveness of the proposed approach, simulation studies are performed. Finally, a real data set is analyzed.
1. Introduction
Reliability estimation is a popular research topic that has recently received much attention. Many studies focus on the stress–strength system with two components, which can be regarded as two random variables X and Y, representing strength and stress. Its reliability is . For this kind of system, extensive research has been carried out. Many scholars have discussed the estimation of this reliability under certain distributions, such as Weerahandi and Johnson [1], Badr et al. [2], Xu et al. [3], Hassan et al. [4], etc.
In the theory of reliability, the multicomponent stress–strength system is an extension of the classical stress–strength system, which contains one stress component and k independent strength components. The system will remain stable if at least s of the k strength values exceed the stress value. For instance, a bridge with k vertical cables that represent the strength of the structure is just a multicomponent stress–strength system. It will remain stable if the stress brought on by wind, high traffic volume, etc., does not exceed the values of at least s of its k strength components. Another example is an eight-cylinder vehicle engine, which operates as long as at least four of the eight cylinders are firing.
For k strengths that are exposed to one stress, strengths are independent random variables with the same cumulative distribution function (CDF) , and stress Y (independent of ) is a random variable with the CDF . Then, the multicomponent stress–strength reliability (MSSR) can be described as
The estimation of the MSSR has been widely studied under complete sample data, where different distributions have been used. For example, Rao [5] studied the maximum likelihood estimation and asymptotic confidence interval of the MSSR based on generalized exponential distribution. Jia et al. [6] discussed the classical estimation of the MSSR based on generalized inverted exponential distribution. Nadar and Kizilaslan [7] derived the estimation of the MSSR based on the Marshall–Olkin Bivariate Weibull distribution using frequentist and Bayesian methods. The Bayesian estimators were developed using Lindley’s approximation and Markov Chain Monte Carlo techniques. Kizilaslan and Nadar [8] discussed the estimation of the MSSR based on the Bivariate Kumaraswamy distribution in a similar way.
Censoring is an effective tool that is often used in lifetime tests. In practical experiments, censoring plays an important role when there are not enough test units or when data for all test units cannot be collected because of the lack of time and resources. Type-I and Type-II censoring attract a lot of attention due to their mathematical simplicity. In Type-I censoring, if a pre-determined time is reached, the test will be stopped, whereas in Type-II censoring, if a pre-determined number of units fail, the test will be stopped. However, both censoring schemes may be inappropriate if the experimenter needs to intermittently remove units. Thus, progressive Type-II censoring is considered a better option and has been widely used in recent years. In this censoring, the intermittent removal of units is allowed. In addition, it saves time and expenses to a certain extent.
Progressive Type-II censoring in a lifetime test is as follows. Assume that M units are tested in the experiment. When the first failure happens, units are randomly removed. When the second failure happens, units are randomly removed, and so on. Finally, when the failure happens, the remaining active units are all removed. Note that . In this way, the ordered lifetime data for m elements are obtained using the censoring scheme . This process is shown in Figure 1. In particular, progressive Type-II censoring can be seen as an extension of Type-II censoring, which is derived by assuming . Otherwise, the complete sample is derived by assuming .
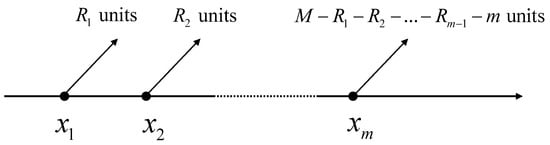
Figure 1.
A schematic diagram of progressive Type-II censoring.
For samples that have been censored or are incomplete, there are few studies on the inference of the MSSR in the literature. Saini et al. [9] studied the estimation of the MSSR for Burr XII distribution using progressive first-failure censoring data. Tsai et al. [10] discussed the estimation of the MSSR for generalized exponential distribution using Type-I censoring data. Saini et al. [11] obtained the estimation of the MSSR for Topp–Leone distribution using progressive censoring data.
Many probability distributions have been proposed to fit the lifetime data. Here, we select the Chen distribution proposed by Chen [12]. Its probability density function (PDF), CDF, and hazard rate function (HRF) are, respectively, given by
where and the shape parameters . Hereafter, the Chen distribution can be represented by Chen. Images of the PDFs and HRFs of the Chen distribution for certain cases are presented in Figure 2. It can be seen that the Chen distribution has a flexible PDF and HRF when the shape parameters are taken at different values. When , the PDFs have a significant peak; when , the PDFs have a roughly decreasing trend; and when , the PDFs are monotonically decreasing. Additionally, when , the HRFs are monotonically increasing, and when , the HRFs present as a bathtub-shaped curve. In the literature, the Chen distribution has received considerable attention and has been studied by several scholars, including Chen and Gui [13], Rastogi et al. [14], Sarhan et al. [15], Mendez-Gonzalez et al. [16], and the references therein.
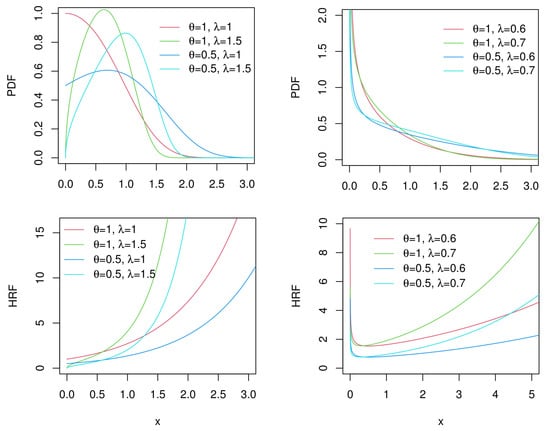
Figure 2.
Images of PDFs and HRFs of Chen distribution under different sets of parameters.
Let follow independently, and let Y (independent of ) follow . They have a common second shape parameter and different first shape parameters. Now, based on Equations (1)–(3), can be derived as
where .
As far as we know, no research has been conducted on the inference of the MSSR for the Chen distribution using progressively censored data. Wang et al. [17] discussed its classical estimation using Type-II censored data. So, our goal is to expand their research by carrying out its estimation from the Chen distribution using progressively censored data. In addition, the Bayesian estimation is also considered.
This article is organized as follows. In Section 2, the maximum likelihood estimate (MLE) is studied. Then, the interval estimation is discussed in Section 3. The asymptotic confidence interval (ACI) is derived based on the MLE. Additionally, the Bootstrap confidence interval (BootCI) is constructed. In Section 4, the Bayes estimates based on gamma priors are derived using the Markov Chain Monte Carlo (MCMC) method. The Bayesian credible interval (BCI) and the highest posterior density credible interval (HPDCI) are also discussed. In Section 5, Monte Carlo simulation studies are performed and a real data set is analyzed. Finally, the conclusions are reported in Section 6.
2. Maximum Likelihood Estimation
In this section, we derive the MLE of by adapting the approach of Wang et al. [17] and extending its application to progressively Type-II censored data. Assume that N systems with K strength components are subjected to a lifetime test. We observe the lifetime data for n systems with k components using progressive Type-II censoring. The observed and are described as follows:
Observed strength values Observed stress values
where each row of values in is the censored sample from with the progressive Type-II censoring scheme , and is the censored sample from with the progressive Type-II censoring scheme . For simplicity, we denote the censoring scheme as and . Then, the likelihood function is
where
Now, using Equations (2), (3), and (5), the likelihood function is
From Equation (6), the log-likelihood function is
By taking the derivative of with respect to and and setting them to 0, we obtain the following equations:
Theorem 1.
For a given , the MLEs of and exist and are, respectively, given by and in Equation (10).
Proof.
Let , . Using inequality , we obtain
From Equation (10), one obtains
One further obtains
The equality holds if , where and . □
From Theorem 1, by substituting and into Equation (7), the log-likelihood function of is
By taking the derivative of and setting it to 0, we obtain the following equation and its solution is the MLE .
From Equation (14), we can derive a nonlinear equation , where
The above equation has a fixed-point solution for . The MLE can be derived using the fixed-point iterative approach as , where is the iterative value of . When is very close to 0, the iteration process can be stopped. Then, according to Equation (11), the MLEs and can be obtained using the MLE .
Based on the invariance property of the MLEs, once we obtain the MLEs , , and , the MLE is
3. Interval Estimation
3.1. Asymptotic Confidence Interval
Similar to the work of Wang et al. [17], we construct an ACI using the asymptotic normality of the MLE. Let be the MLEs of . The observed Fisher information matrix is given by , where
Using the delta method (see Xu and Long [18]), the variance of is derived as follows:
where
Here, the parameters are computed as the MLEs . Therefore, the ACI for is
where is percentile of .
A negative lower bound might be generated by the ACI proposed above but . To avoid this problem, the logit transformation can be used to provide a more accurate confidence interval, as proposed by Krishnamoorthy and Lin [19]. Let be the MLE of . Then, the ACI of is , where
and
Then, the ACI of based on the logit scale is
3.2. Bootstrap Confidence Interval
The MLEs may not follow the asymptotic normality when the observed sample size is insufficient, which can be a limitation of the ACI. Therefore, the BootCI is considered. Using the method discussed by Stine [20], the percentile BootCI is constructed. The procedures are provided in Algorithm 1.
| Algorithm 1 The algorithm of the Bootstrap CI method. |
|
4. Bayesian Estimation
In this section, Bayesian estimation is discussed, together with the generalized entropy loss function (GELF). When overestimation and underestimation are considered different consequences of errors, the GELF is useful. The GELF is a suitable loss function used for reliability estimation since overestimating is typically considerably more harmful than underestimating. As first discussed by Calabria and Pulcini [21], the GELF is given by
where is the decision rule to estimate . The Bayes estimate with the GELF is derived as
Note that the Bayes estimate in Equation (20) corresponds to the Bayes estimate with a precautionary loss function when , a squared error loss function when , and an entropy loss function when .
In Bayesian estimation, , , and can be considered random variables. Assume that they have independent gamma priors and their PDFs are expressed as follows:
where . Then, the joint posterior density function is
By substituting Equation (6) into Equation (21), the posterior distribution is
4.1. MCMC Method
The MCMC method is considered to obtain the Bayesian estimation. According to Equation (22), the conditional posterior density of , , and are derived as
and
Now, using the gamma distributions, the values of and can be directly generated. Nonetheless, the Metropolis–Hastings (M–H) algorithm is utilized to obtain the values of . The procedure of the Gibbs sampling is provided in Algorithm 2. Then, according to the sampling results, the Bayes estimate with the GELF is
where is the burn-in period.
| Algorithm 2 The algorithm of the MCMC method. |
|
4.2. Bayesian Credible Intervals and Highest Posterior Density Credible Intervals
In this subsection, the BCI and HPDCI are constructed in the following way:
To begin with, the generated posterior samples are sorted to derive the values . Then, the BCI with a confidence level for is obtained as
Among all the possible intervals with a confidence level, the HPDCI has the shortest width. Thus, the HPDCI for is given by
where n is the integer that makes
where is the least integer function.
5. Numerical Explorations
5.1. Simulation Studies
To analyze the effects of various estimates, Monte Carlo simulations are performed. First, the samples with the censoring scheme are generated according to Algorithm 3, as discussed by Balakrishnan and Sandhu [22].
| Algorithm 3 The algorithm for generating progressively censored samples. |
|
For the different point estimates, including MLEs and Bayes estimates, we compute their corresponding mean absolute deviations and mean squared errors. For different interval estimates, including 95% ACIs, BootCIs, BCIs, and HPDCIs, we compute their corresponding average lengths and coverage probabilities.
The various progressive Type-II censoring schemes (C.S) selected for the simulations are shown in Table 1, where , , ..., are the censoring schemes used for the strength variables, and , , ..., are the censoring schemes used for the stress variables. We perform lifetime tests on N systems with K components and observe the data obtained for n systems with k components using a certain censoring scheme. For simplicity, a short notation such as () represents (1, 1, 1) and () represents (0, 1, 0, 1, 0, 1). Take in schemes , , and and in schemes , , and . When at least two or three components survive, we derive the estimations of the system reliability. The simulation results are based on 3000 replications and all simulation calculations are performed using R-4.3.0 software.

Table 1.
Different censoring schemes.
Here, two different sets of distribution parameters are used:
For , is 0.5 and is 0.6, whereas for , is 0.5901 and is 0.6885.
To compute the Bayesian estimates, three priors are considered. The non-informative prior is denoted as prior 1 and the gamma priors are denoted as prior 2 for and prior 3 for . The relevant parameters for the priors are as follows:
For the GELF, three loss functions are considered:
For two different sets of parameters and multiple combinations of censoring schemes, we obtain the MLEs and Bayes estimates. Then, we compute their mean absolute deviations (MAD) and mean squared errors (MSE), as shown in Table 2 for and Table 3 for . The ACIs, BootCIs, BCIs, and HPDCIs for at a 95% confidence level are also derived under the same combinations of censoring schemes for two different sets of parameters. When computing the BootCIs, we take re-samples. The average lengths (AL) and the coverage probabilities (CP) for different types of intervals are shown in Table 4 for , and Table 5 for .
Table 2.
MADs and MSEs of the point estimations for when is 0.5 and is 0.6.
Table 3.
MADs and MSEs of the point estimations for when is 0.5901 and is 0.6885.
Table 4.
ALs and CPs of the intervals for when is 0.5 and is 0.6.
Table 5.
ALs and CPs of the intervals for when is 0.5901 and is 0.6885.
To ensure the feasibility of the MCMC method, the posterior density plots for are provided, as shown in Figure 3 and Figure 4. It can be observed that these posterior density plots are very close to the density plots of the Gaussian distributions. Therefore, when implementing the M–H algorithm to obtain the MCMC samples, it is possible to use the Gaussian distribution as the proposed density. We perform 10,000 iterations for the MCMC method. To ensure convergence, trace plots for the three parameters are provided, as illustrated in Figure 5 and Figure 6. As can be seen in these two figures, the MCMC chains rapidly converge to their stationary distributions. Thus, we can consider as a burn-in period.
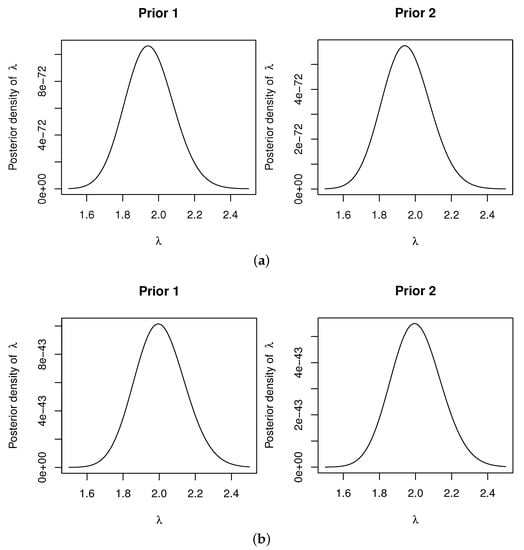
Figure 3.
Posterior density plots of for (a) with C.S (, ), (b) with C.S (, ).
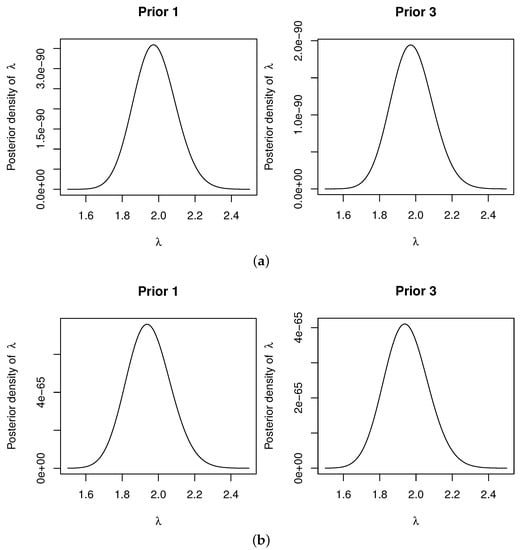
Figure 4.
Posterior density plots of for (a) with C.S (, ), (b) with C.S (, ).
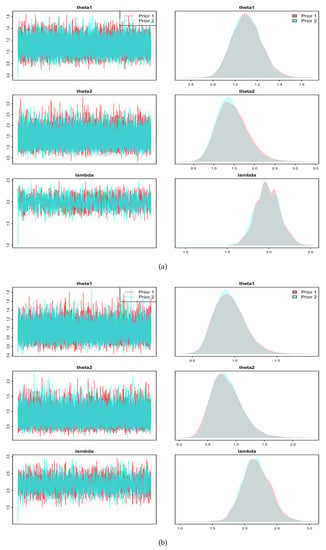
Figure 5.
Trace plots for (a) with C.S (, ), (b) with C.S (, ).
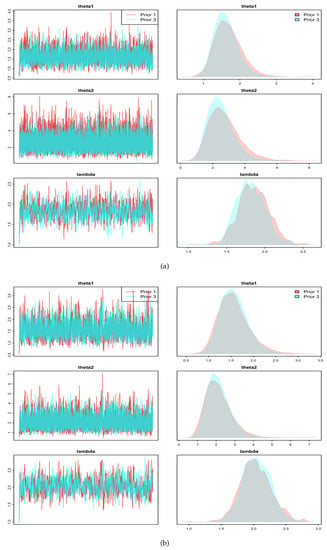
Figure 6.
Trace plots for (a) with C.S (, ), (b) with C.S (, ).
To better compare the effects of the different estimates, in Table 2, Table 3, Table 4 and Table 5, we present the simulation results shown in Figure 7 for the point estimates and Figure 8 for the interval estimates. Note that the x-axis sequentially represents 12 different combinations of censoring schemes.
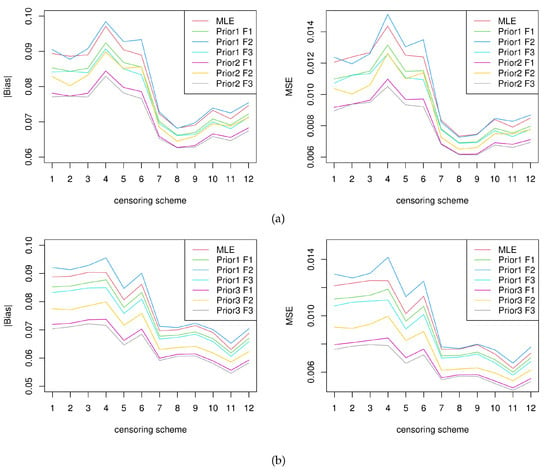
Figure 7.
Visualization results of MADs and MSEs (a) for , (b) for .
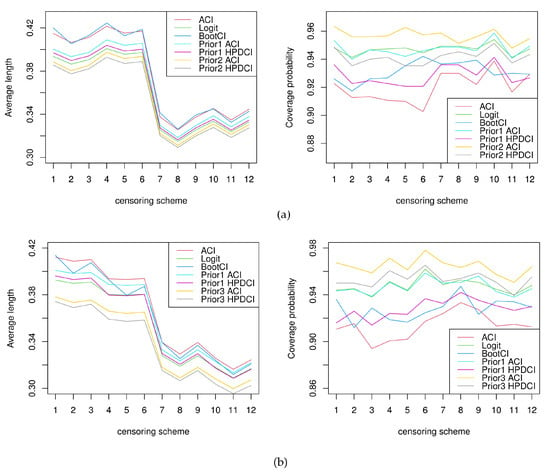
Figure 8.
Visualization results of average lengths and coverage probabilities (a) for , (b) for .
In Figure 7, it can be seen that the Bayes estimates performed better in the majority of cases because they had lower MADs and MSEs. However, the Bayes estimate with non-informative priors, where F2 was chosen as the loss function, performed slightly worse. In the Bayes estimate, the informative priors had lower MADs and MSEs than the non-informative priors. In all cases, among the three loss functions, F3 performed the best, followed by F1, and F2 performed the worst. In addition, the performances of the different censoring schemes varied. For , the censoring scheme (, ) exhibited the smallest MADs and MSEs, and the censoring scheme (, ) was the second-best performer. For , the censoring scheme (, ) exhibited the smallest MADs and MSEs, and the censoring scheme (, ) was the second-best performer.
In Figure 8, it can be seen that BCIs and HPDCIs for the gamma informative priors performed the best, as they had the shortest average lengths and highest coverage probabilities. The logit-scale-based ACIs performed the second best. The ACIs and BootCIs performed the worst, as they had the longest average lengths and the lowest coverage probabilities. In all of these cases, in terms of the BCIs and HPDCIs, the HPDCIs had shorter average lengths, whereas the BCIs had higher coverage probabilities so they each have their own advantages. In addition, the informative priors outperformed the non-informative priors, as they exhibited both shorter average lengths and higher coverage probabilities. Furthermore, different censoring schemes also performed differently. For , in terms of average lengths, the censoring scheme that performed the best was (, ), whereas in terms of coverage probabilities, the censoring scheme that performed the best was (, ). For , in terms of average lengths, the censoring scheme that performed the best was (, ), whereas in terms of coverage probabilities, the censoring scheme that performed the best was (, ).
5.2. Real Data Example
To illustrate the suitability of the proposed method, a real data set was used. The data set we selected was obtained from http://cdec.water.ca.gov/cgi-progs/queryMonthly?SHA (accessed on 10 March 2023) and represents the water capacity of the Shasta reservoir in California, USA. We assumed that the water levels do not lead to excessive dryness if the reservoir capacities in August for at least 2 out of the next 5 years are not lower than the capacity observed in December of that year. Our purpose was to infer whether the area was excessively dry. Therefore, we can build a model to estimate the MSSR, where the capacities in August can be regarded as the strength variables and the capacity in December can be regarded as the stress variable. From 1975 to 2016, the water capacities in August and December were as follows:
Before proceeding with the estimation, we first performed Kolmogorov–Smirnov (K-S) tests to ensure that X and Y did follow the Chen distribution. In addition, three distributions were used to compare with the Chen distribution in the K–S tests. Their PDFs are as follows:
The results of the K–S tests are shown in Table 6. It can be seen that both X and Y followed the Chen distribution at the 0.05 significance level. In particular, the Chen distribution demonstrated better performance in the K–S tests for data set X.
Table 6.
Comparison of different distributions in K–S tests.
In the previous sections, the estimations of were discussed under the assumption that the stress and strength variables followed the Chen distribution with the same second shape parameter. Therefore, before estimating using the real data, we needed to check whether their second shape parameters were the same. Let follow independently, and let Y (independent of ) follow . Then, the following hypothesis testing question is posed as
In the complete sample, the corresponding likelihood function is given by
Then, the likelihood ratio statistic is constructed as follows:
For large n, when holds, one has asymptotically. Thus, the rejection region is at a given significance level , where is percentile of . For given data sets X and Y, we calculate that with a p-value of 0.6115. Therefore, we can accept at the 0.05 significance level, whereupon the MSSR can be estimated using our proposed method.
Then, we obtain different estimates of using the complete sample, as well as three different censored samples. The samples can be, respectively, generated by the censoring schemes as follows:
Based on C.S 1, the censored samples are derived as
Based on C.S 2, the censored samples are derived as
Based on C.S 3, the censored samples are derived as
For the complete, as well as three progressively censored, samples, we derive various point estimates and 95% interval estimates of , as shown in Table 7 and Table 8, respectively. For the Bayesian estimates, non-informative priors are used. For three parameters in the MCMC method, we provide the CUSUM plots in Figure 9 and the trace plots in Figure 10. As can be seen in these figures, the MCMC chains converged quickly to stationary distributions, indicating that the MCMC method performed well.
Table 7.
The point estimates for real data.
Table 8.
The interval estimates for real data.
Figure 9.
CUSUM plots for , , and (a) with the complete sample, (b) with censoring scheme 1, (c) with censoring scheme 2, (d) with censoring scheme 3.
Figure 10.
Trace plots for real data.
6. Conclusions
We study the estimation of the MSSR based on the Chen distribution using progressively censored data. The reliability inference of multicomponent stress–strength systems has attracted significant interest, with numerous scholars contributing to the field. Progressive Type-II censoring has been widely used in lifetime tests for nearly two decades. The Chen distribution is commonly used to model real-life data in the fields of lifetime analysis and reliability theory.
We begin by obtaining the MLE. Then, the ACI based on the MLE is derived, where the delta method is used. The percentile BootCI is also constructed. Additionally, the Bayes estimates, BCIs, and HPDCIs are obtained using the MCMC method. The stochastic simulations are performed using the R software. According to the results, the Bayes estimates under the gamma priors using the precautionary loss function exhibit the smallest MADs and MSEs among all the point estimates. Among all the interval estimates, the BCIs have the shortest lengths and the HPDCIs have the highest coverage probabilities. Finally, the applicability of the method is illustrated using real data.
Our study focuses solely on the estimation of the MSSR based on the Chen distribution using a common second shape parameter. In the future, we will explore the case of unequal shape parameters. Additionally, the multicomponent stress–strength system we study contains only one stress component and we do not consider scenarios involving multiple stress components. In the future, we will explore a more complex system and further extend the model to cases where there is more than one stress component. Furthermore, we assume that the strength random variables are independently and identically distributed, which may not accurately reflect certain real-world situations. Therefore, the study of multicomponent stress–strength systems with non-identical strength variables will be considered in the future.
Author Contributions
Investigation, C.H.; Supervision, W.G. All authors have read and agreed to the published version of the manuscript.
Funding
Wenhao’s work was partially supported by The Development Project of China Railway (No. N2022J017) and the Fund of China Academy of Railway Sciences Corporation Limited (No. 2022YJ161).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are openly available in [9].
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| MSSR | Multicomponent stress–strength reliability |
| MLE | Maximum likelihood estimate |
| ACI | Asymptotic confidence interval |
| BootCI | Bootstrap confidence interval |
| BCI | Bayesian credible interval |
| HPDCI | Highest posterior density credible interval |
| MCMC | Markov Chain Monte Carlo |
| GELF | Generalized entropy loss function |
| C.S | Censoring scheme |
| F1 | Squared error loss function |
| F2 | Entropy loss function |
| F3 | Precautionary loss function |
| MAD | Mean absolute deviation |
| MSE | Mean squared error |
| AL | Average length |
| CP | Coverage probability |
| Probability density function | |
| CDF | Cumulative distribution function |
| HRF | Hazard rate function |
| S | Censoring scheme for the strength variables |
| T | Censoring scheme for the strength variables |
| Multicomponent stress–strength reliability | |
| X | Strength variables |
| Y | Stress variables |
| I | Observed Fisher information matrix |
| First shape parameter of the Chen distribution | |
| Second shape parameter of the Chen distribution | |
| First shape parameter of the Chen distribution for the strength variables | |
| First shape parameter of the Chen distribution for the stress variables | |
| q | Parameter of the GELF |
| a | Parameter of gamma prior |
| b | Parameter of gamma prior |
| s | Parameter of MSSR |
| k | The number of observed components in each system in the lifetime test |
| N | The number of systems in the lifetime test |
| n | The number of observed systems in the lifetime test |
| K | The number of components in each system in the lifetime test |
References
- Weerahandi, S.; Johnson, R.A. Testing reliability in a stress-strength model when X and Y are normally distributed. Technometrics 1992, 34, 83–91. [Google Scholar] [CrossRef]
- Badr, M.M.; Shawky, A.I.; Alharby, A.H. The estimation of reliability from stress-strength for exponentiated Frechet distribution. Iran. J. Sci. Technol. Trans. A Sci. 2019, 43, 863–874. [Google Scholar] [CrossRef]
- Xu, H.; Yu, P.L.H.; Alvo, M. Detecting change points in the stress-strength reliability P(X<Y). Appl. Stoch. Model. Bus. Ind. 2019, 35, 837–857. [Google Scholar]
- Hassan, A.S.; Almanjahie, I.M.; Al-Omari, A.I.; Alzoubi, L.; Nagy, H.F. Stress-Strength Modeling Using Median-Ranked Set Sampling: Estimation, Simulation, and Application. Mathematics 2023, 11, 318. [Google Scholar] [CrossRef]
- Rao, G.S. Estimation of reliability in multicomponent stress-strength based on generalized exponential distribution. Rev. Colomb. Estad. 2012, 35, 67–76. [Google Scholar]
- Jia, J.M.; Yan, Z.Z.; Song, H.H.; Chen, Y. Reliability estimation in multicomponent stress-strength model for generalized inverted exponential distribution. Soft Comput. 2023, 27, 903–916. [Google Scholar] [CrossRef]
- Nadar, M.; Kizilaslan, F. Estimation of reliability in a multicomponent stress-strength model based on a Marshall-Olkin bivariate Weibull distribution. IEEE Trans. Reliab. 2016, 65, 370–380. [Google Scholar] [CrossRef]
- Kizilaslan, F.; Nadar, M. Estimation of reliability in a multicomponent stress-strength model based on a bivariate Kumaraswamy distribution. Stat. Pap. 2018, 59, 307–340. [Google Scholar] [CrossRef]
- Saini, S.; Tomer, S.; Garg, R. On the reliability estimation of multicomponent stress-strength model for Burr XII distribution using progressively first-failure censored samples. J. Stat. Comput. Simul. 2022, 92, 667–704. [Google Scholar] [CrossRef]
- Tsai, T.R.; Lio, Y.; Chiang, J.Y.; Chang, Y.W. Stress-Strength inference on the multicomponent model based on generalized exponential distributions under Type-I hybrid censoring. Mathematics 2023, 11, 1249. [Google Scholar] [CrossRef]
- Saini, S.; Tomer, S.; Garg, R. Inference of multicomponent stress-strength reliability following Topp-Leone distribution using progressively censored data. J. Appl. Stat. 2023, 50, 1538–1567. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.M. A new two-parameter lifetime distribution with bathtub shape or increasing failure rate function. Stat. Probab. Lett. 2000, 49, 155–161. [Google Scholar] [CrossRef]
- Chen, S.Y.; Gui, W.H. Statistical analysis of a lifetime distribution with a bathtub-shaped failure rate function under adaptive progressive Type-II censoring. Mathematics 2020, 8, 670. [Google Scholar] [CrossRef]
- Rastogi, M.K.; Tripathi, Y.M.; Wu, S.J. Estimating the parameters of a bathtub-shaped distribution under progressive type-II censoring. J. Appl. Stat. 2012, 39, 2389–2411. [Google Scholar] [CrossRef]
- Sarhan, A.M.; Hamilton, D.C.; Smith, B. Parameter estimation for a two-parameter bathtub-shaped lifetime distribution. Appl. Math. Model. 2012, 36, 5380–5392. [Google Scholar] [CrossRef]
- Mendez-Gonzalez, L.C.; Rodriguez-Picon, L.A.; Perez-Olguin, I.J.C.; Portilla, L.R.V. An Additive Chen Distribution with Applications to Lifetime Data. Axioms 2023, 12, 118. [Google Scholar] [CrossRef]
- Wang, L.; Wu, K.; Tripathi, Y.M.; Lodhi, C. Reliability analysis of multicomponent stress-strength reliability from a bathtub-shaped distribution. J. Appl. Stat. 2022, 49, 122–142. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Long, J.S. Using the delta method to construct confidence intervals for predicted probabilities, rates, and discrete changes. Stata J. 2005, 5, 537–559. [Google Scholar] [CrossRef]
- Krishnamoorthy, K.; Lin, Y. Confidence limits for stress–strength reliability involving Weibull models. J. Stat. Plan. Inference 2010, 140, 1754–1764. [Google Scholar] [CrossRef]
- Stine, R. An introduction to bootstrap methods: Examples and ideas. Sociol. Methods Res. 1989, 18, 243–291. [Google Scholar] [CrossRef]
- Calabria, R.; Pulcini, G. Point estimation under asymmetric loss functions for left-truncated exponential samples. Commun. Stat. Theory Methods 1996, 25, 585–600. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Sandhu, R.A. A simple simulational algorithm for generating progressive Type-II censored samples. Am. Stat. 1995, 49, 229–230. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).