
Facial Micro-Expression Recognition Based on Deep Local-Holistic Network


Abstract
:1. Introduction
2. Related Works and Background
2.1. Micro-Expression Recognition
2.2. Deep Convolutional Neural Network
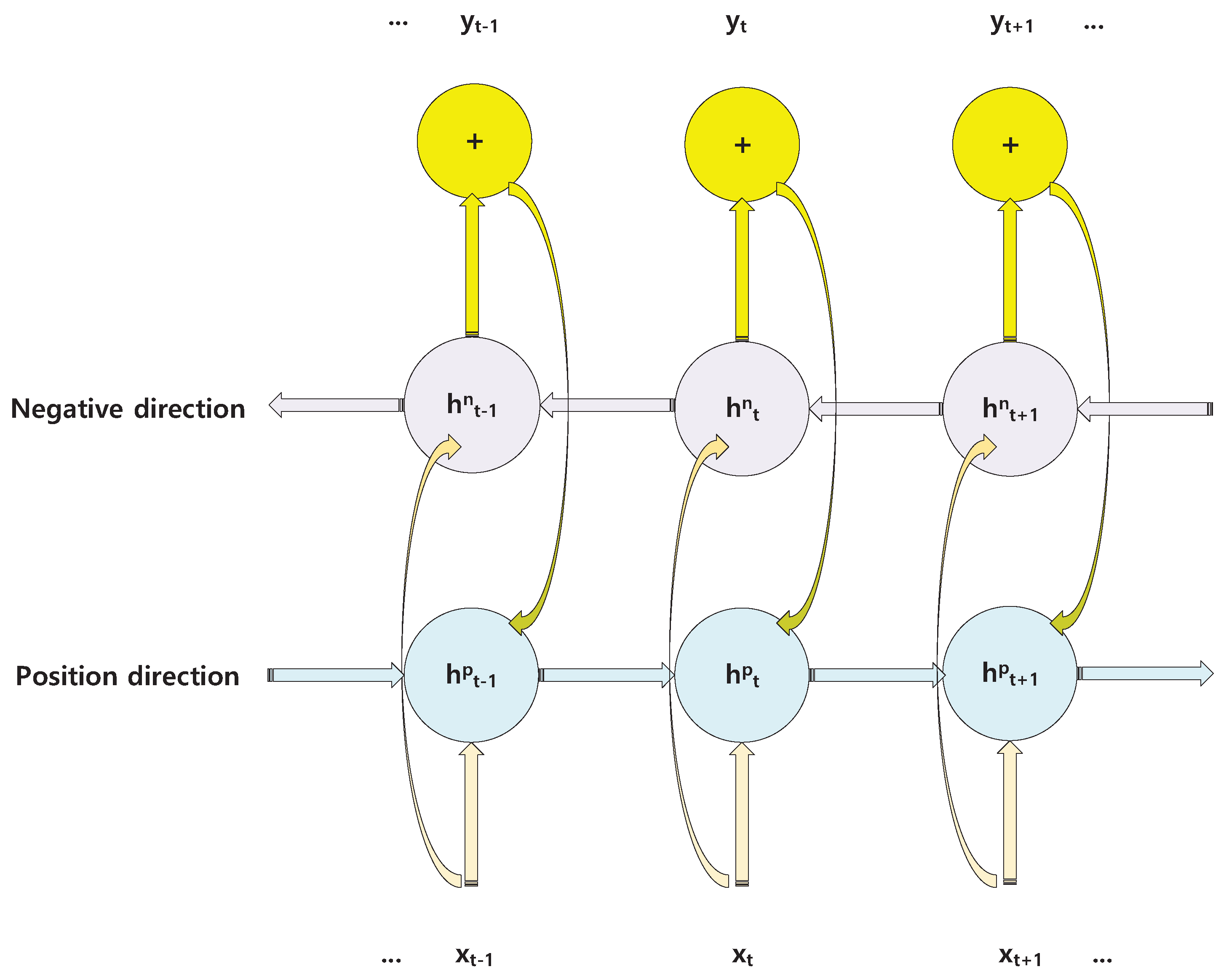
2.3. Recurrent Neural Network
2.4. Robust Principal Component Analysis
3. Our Model
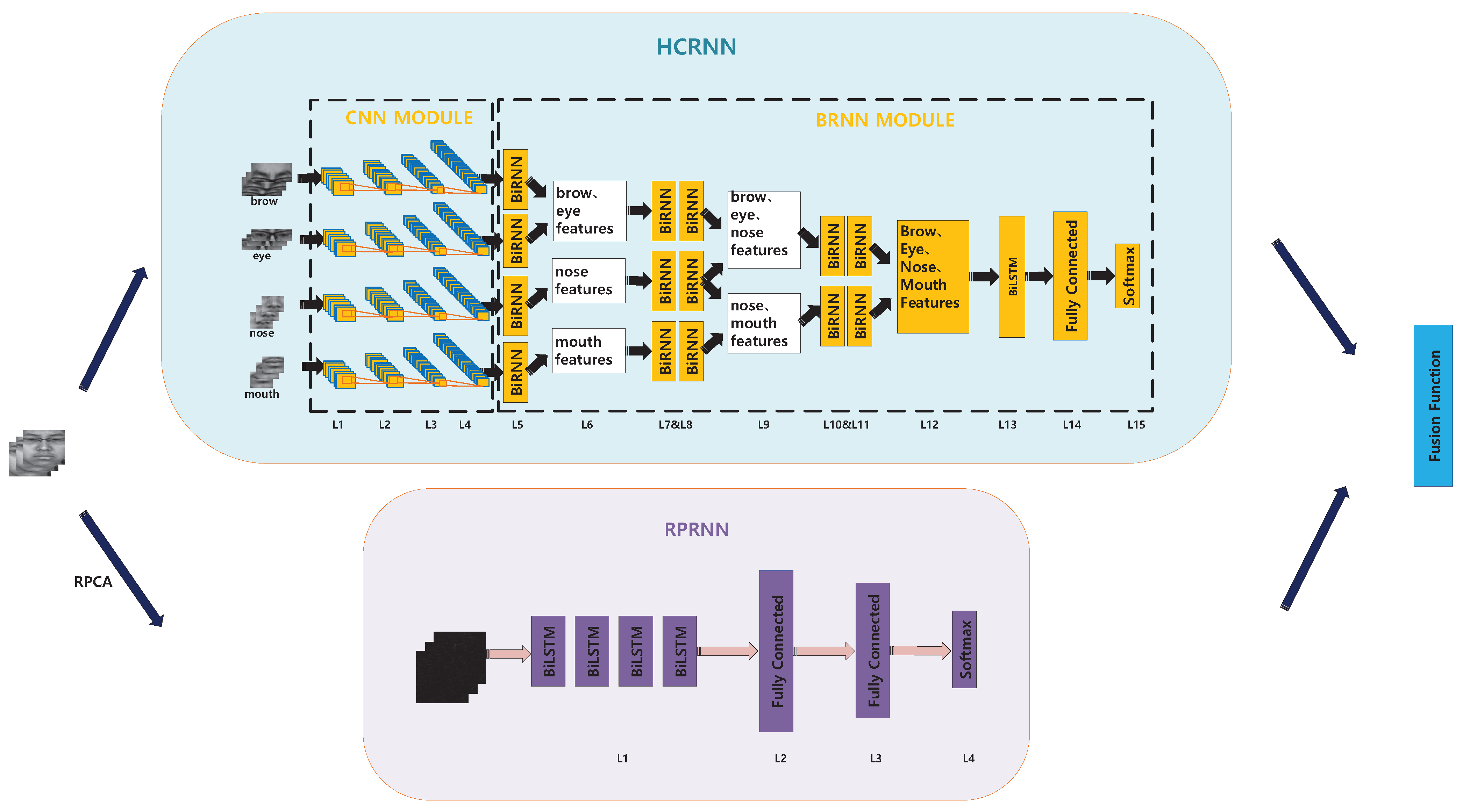
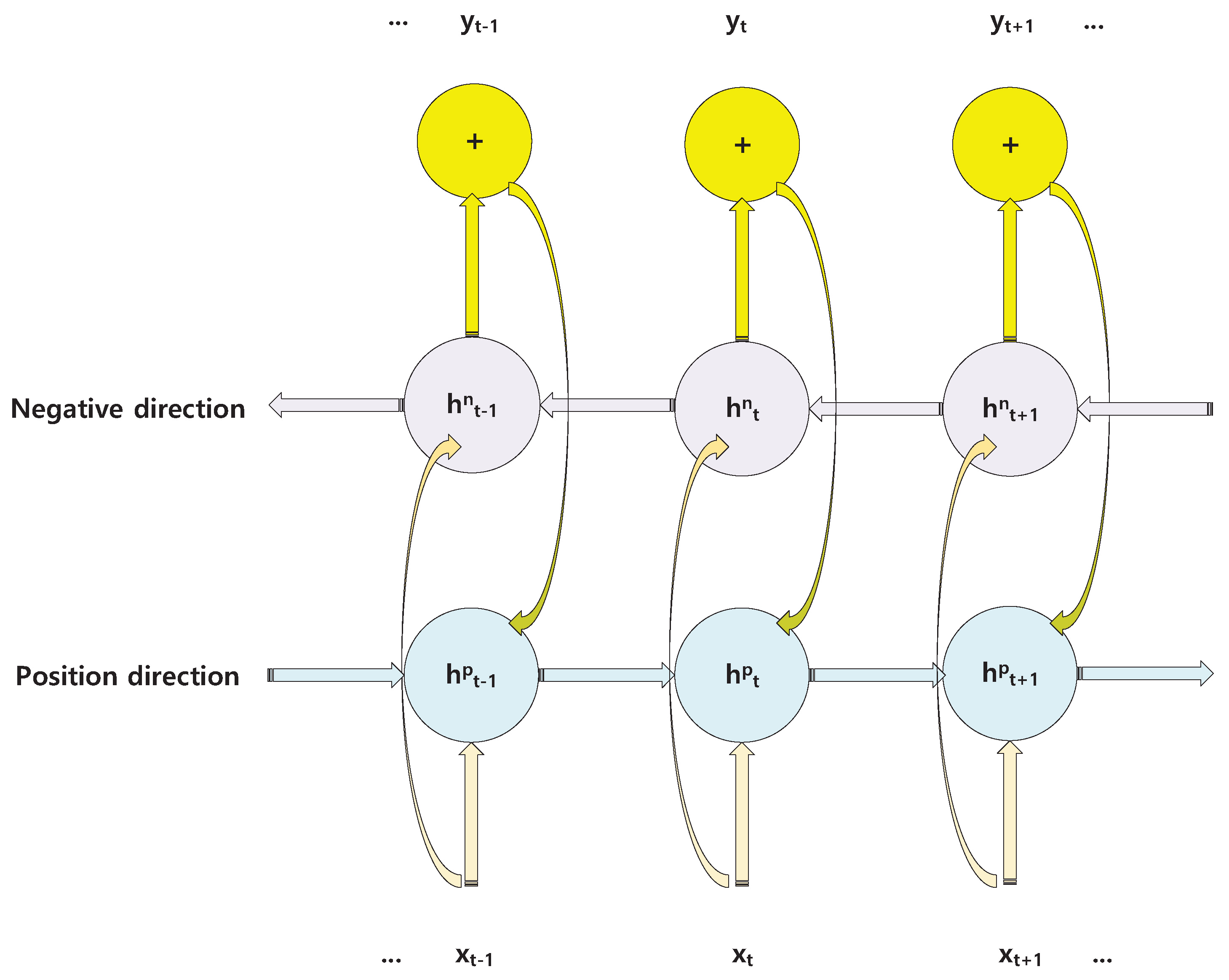
3.1. HCRNN for Local Features
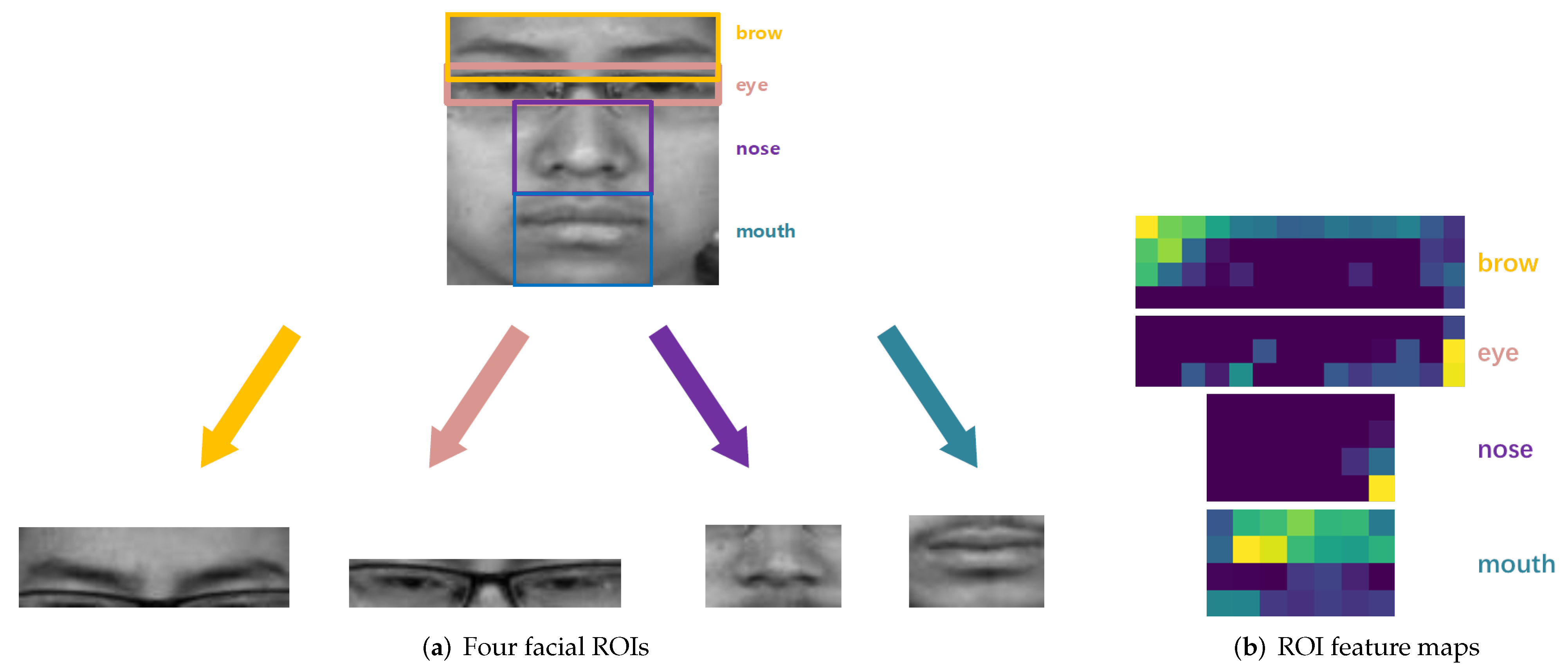
3.1.1. CNN Module
3.1.2. BRNN Module
3.2. RPRNN for Holistic Features
3.2.1. Input: Sparse Micro-Expression Obtained By RPCA
3.2.2. RPRNN Architecture
3.3. Model Fusion
4. Experiments
4.1. Databases and Validation Protocols
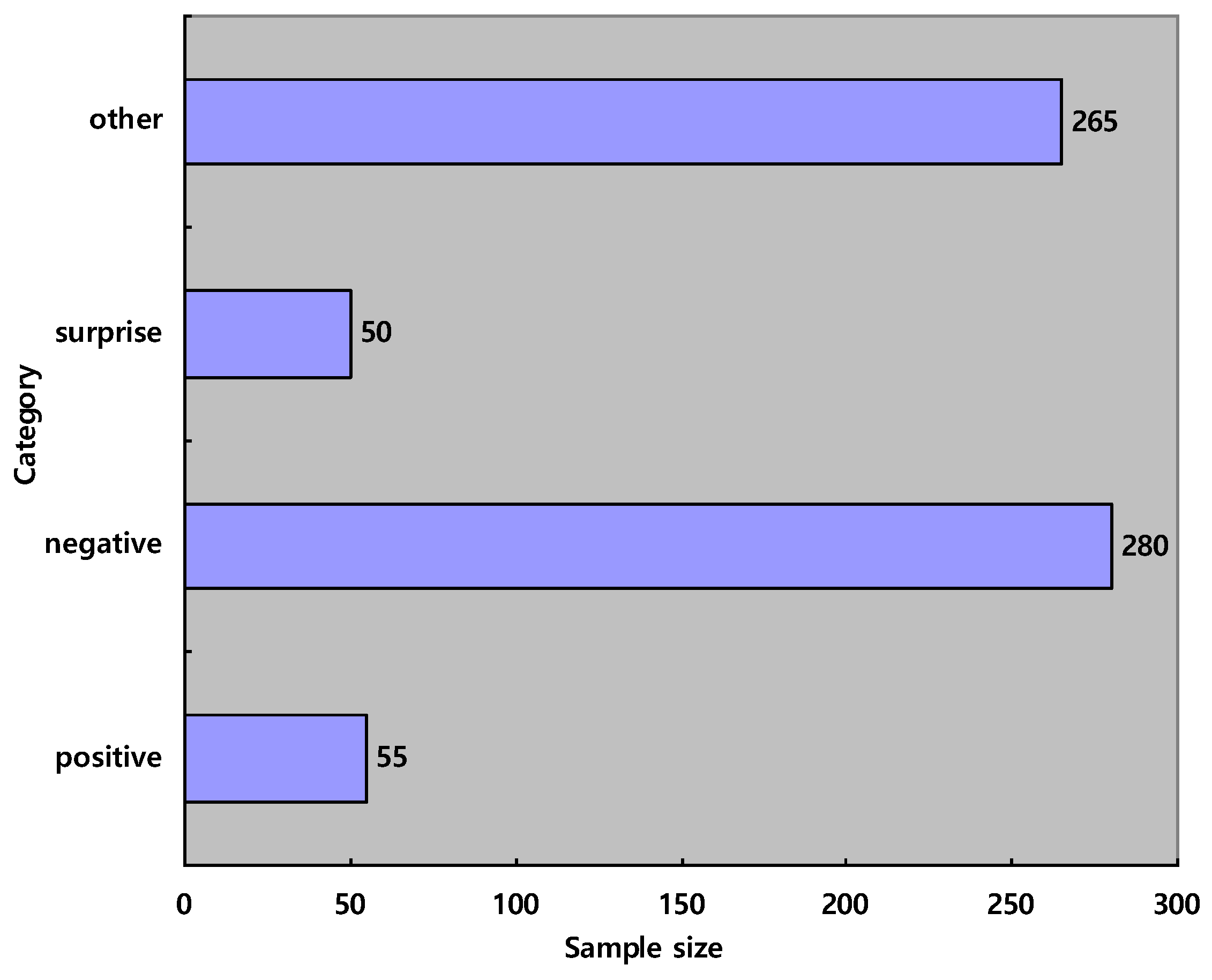
- Emotion category: The number of emotion classes is different in these four databases, and micro-expression samples are labeled by taking different AU criteria. For example, the combination of AU1 and AU2 defines a micro-expression sample as disgust in CAS(ME) and as surprise in CASME II. In order to alleviate the impact of the different encoding, we adopt a uniformly AU encoding criterion proposed by Davison et al. [48]. Finally, we select 650 samples from the combined dataset and divide them into four emotion labels:Specifically, Negative consists of anger, disgust, sadness, and fear. Figure 6 shows the sample size of each emotion category.
- Validation Protocol: Since there are only 650 video samples in the combined database, the sample size for training, validation, and testing would be small with a straightforward division. In order to verify the model performance more fairly and eliminate the effect of individual differences on the results, we adopt a 10-fold cross-validation method. In particular, the samples are equally randomly distributed into 10 folds, of which 9 folds are used for training and the remaining one for testing, and the average of 10 validations represents the accuracy of the model.
- Evaluation metric: For the evaluation fo the micro-expression recognition results, a common evaluation criterion is the accuracy of recognition [49], i.e., the proportion of correct predictions among the total number of micro-expression video samples:where k is the index of the test fold in the 10-fold cross-validation; [1, 2, 3, 4], i.e., the emotion label index; denotes the number of emotion categories, i.e., 4 in our article; and represents the total number of micro-expression videos in the kth test fold.
4.2. Preprocessing and Parameter Configuration
4.2.1. Possessing
- HCRNN: Since the length of each video sample varies, we performed linear interpolation and extracted 16 frames from it for the subsequent recognition task. The size of the face image is . For HCRNN, the face region is divided into four ROIs as the input of the CNN module. To guarantee the integrity of each part, ROIs have overlapping areas, and the size of brow, eye, nose, and mouth regions are , , , and , respectively.
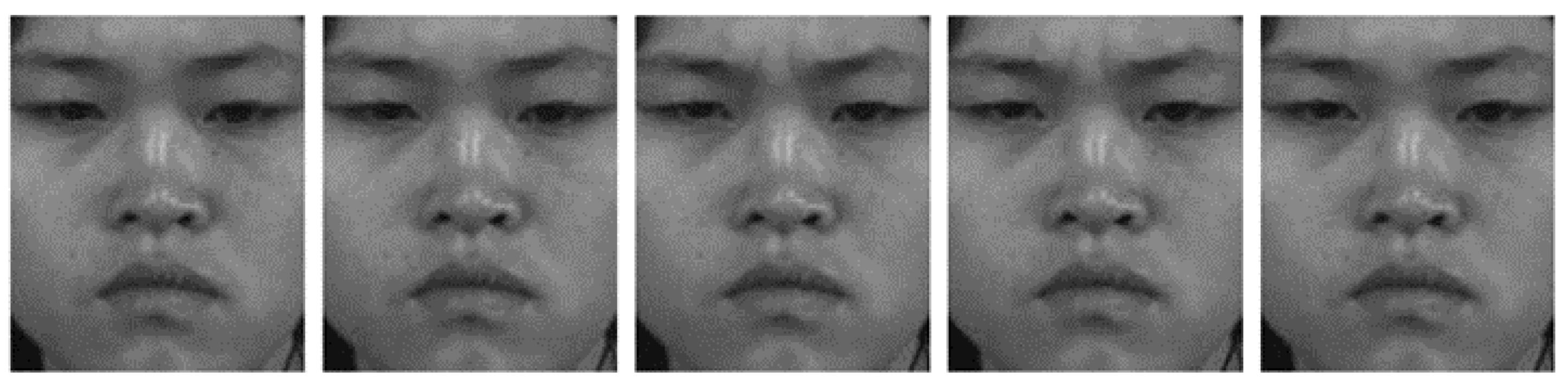
- RPRNN: The original micro-expression frames are processed by RPCA to obtain the sparse micro-expression images. Figure 7 illustrates an example of micro-expression images processed by RPCA. Then, the sparse images are fed to RPRNN to obtain holistic features.
4.2.2. Parameter Configuration for DLHN
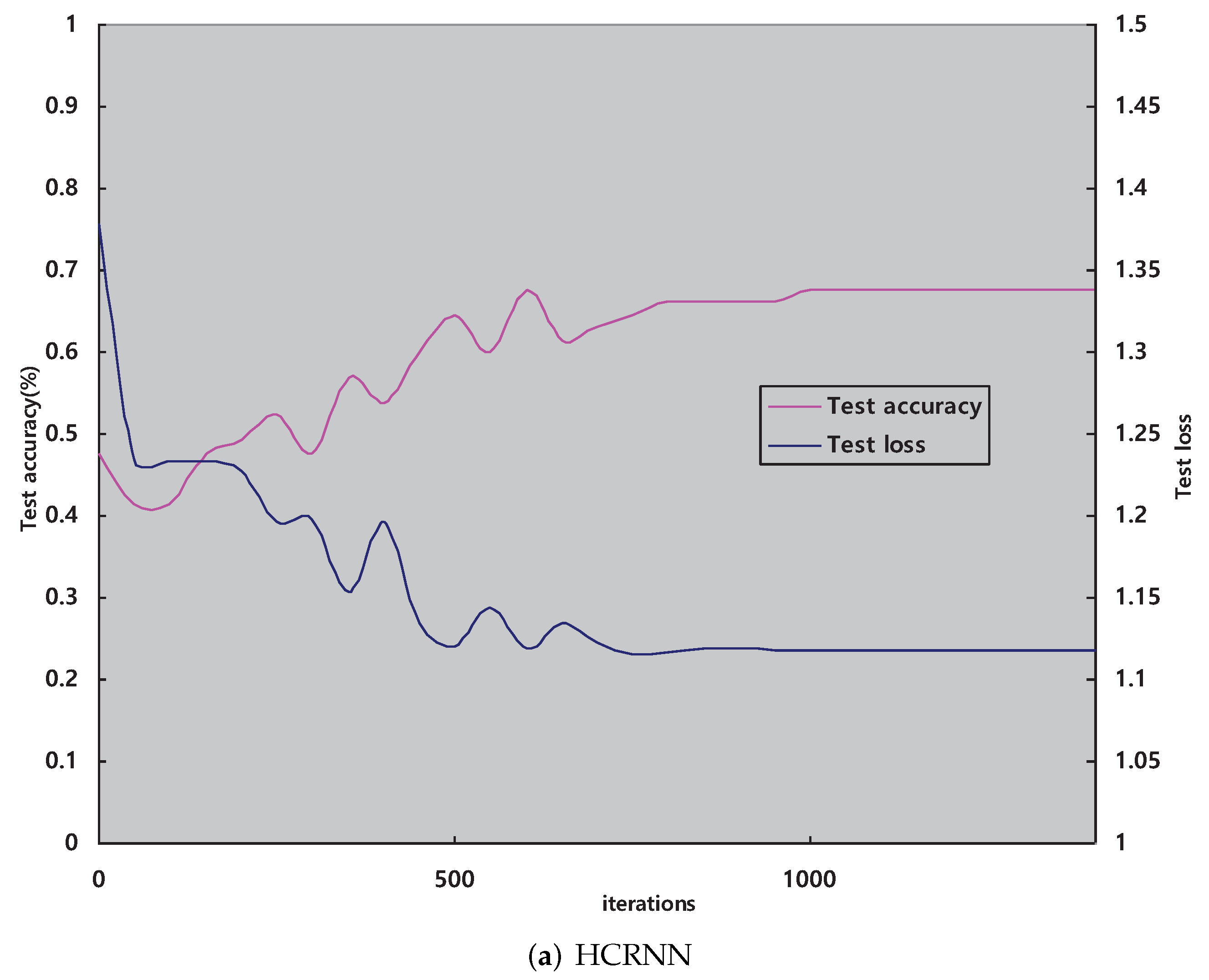
- HCRNN: The convolution kernel size of the HCNN is set to , and the size of the pooling kernel is . The strides of the convolution and pooling layers are set as 1 and 2. In the training stage, the learning rate adopts exponential decay with the initial value equal to 0.85. We update all weights in each iteration with mini-batch samples whose size is 45. The number of epochs is 1500. The iteration curves in Figure 8a represent the trend of the loss and accuracy values in the testing set.
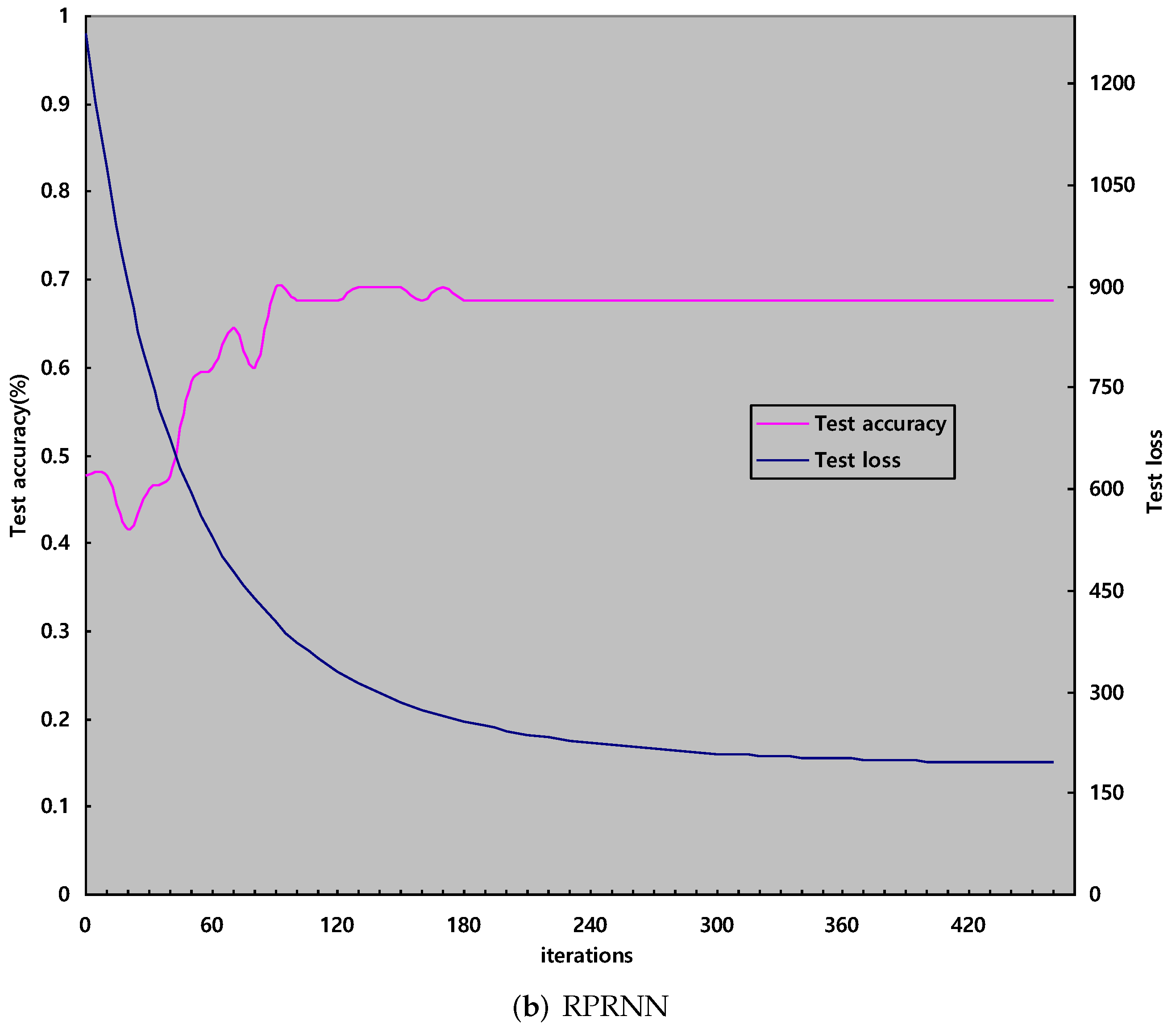
- RPRNN: In the model, the attenuation method of the learning rate and the update mode of the weights are the same as the HCRNN, and the value of the learning rate is initialized to 0.01. Same as in the HCRNN, the number of epochs is 1500. In the training stage, we update all weights in each iteration. Figure 8b plots the iteration curves representing the trend of loss and accuracy value in the testing set. In the whole experiment, we employ a truncated normal distribution with zero mean and a standard deviation of 0.1 to initialize weights and initialize biases as 0.1.
4.3. Parameter Analysis and Ablation Study
4.3.1. Parameter Analysis
4.3.2. Ablation Study
4.4. DLHN Performance Analysis
4.4.1. Comparison with SOTA Methods
- First, micro-expressions are involuntary and rapidly flowing facial expressions of individuals, which are subtle, brief, and localized. The recognition rate of micro-expressions in videos by the naked eye is less than 50%, even for professionally trained experts [8]. Similarly, it is very challenging for traditional feature extraction methods and deep learning methods to extract micro-expression features with representational properties. Deep learning networks targeting fine-grained feature learning may be able to improve performance, e.g., by drawing on fine-grained object recognition network designs.
- Second, the small sample size of micro-expressions limits the ability of deep learning to further mine micro-expression features. The maximum sample size of a single database containing micro-expression videos is only 256. In this paper, we combine three common micro-expression databases for analysis, and there are only 650 samples in total. However, the amount of data of this size is still very small compared to face recognition and expression recognition. The performance of micro-expression recognition should be improved in the future when the amount of micro-expression data increases.
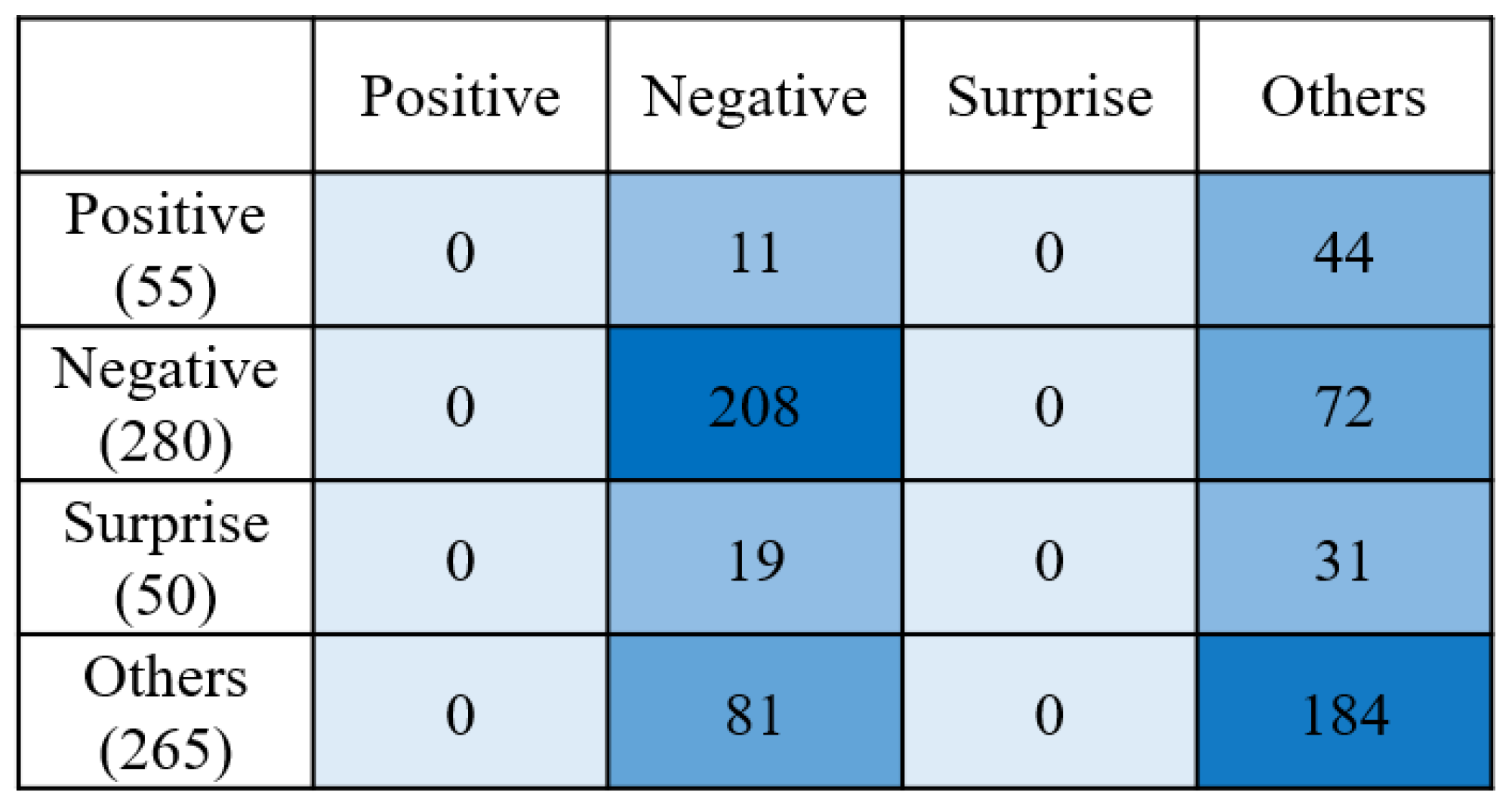
4.4.2. Micro-Expression Recognition Per Emotion Class
5. Conclusions and Perspective
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, present, and future of face recognition: A review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Jacques, S. Multi-block color-binarized statistical images for single-sample face recognition. Sensors 2021, 21, 728. [Google Scholar] [CrossRef]
- Khaldi, Y.; Benzaoui, A.; Ouahabi, A.; Jacques, S.; Taleb-Ahmed, A. Ear recognition based on deep unsupervised active learning. IEEE Sens. J. 2021, 21, 20704–20713. [Google Scholar] [CrossRef]
- El Morabit, S.; Rivenq, A.; Zighem, M.E.n.; Hadid, A.; Ouahabi, A.; Taleb-Ahmed, A. Automatic pain estimation from facial expressions: A comparative analysis using off-the-shelf CNN architectures. Electronics 2021, 10, 1926. [Google Scholar] [CrossRef]
- Perusquia-Hernandez, M.; Hirokawa, M.; Suzuki, K. A wearable device for fast and subtle spontaneous smile recognition. IEEE Trans. Affect. Comput. 2017, 8, 522–533. [Google Scholar] [CrossRef]
- Perusquía-Hernández, M.; Ayabe-Kanamura, S.; Suzuki, K.; Kumano, S. The invisible potential of facial electromyography: A comparison of EMG and computer vision when distinguishing posed from spontaneous smiles. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–9. [Google Scholar]
- Ekman, P.; Friesen, W.V. Nonverbal leakage and clues to deception. Psychiatry 1969, 32, 88–106. [Google Scholar] [CrossRef]
- Frank, M.; Herbasz, M.; Sinuk, K.; Keller, A.; Nolan, C. I see how you feel: Training laypeople and professionals to recognize fleeting emotions. In Proceedings of the Annual Meeting of the International Communication Association, Sheraton New York, New York City, NY, USA, 7–11 April 2009. [Google Scholar]
- O’Sullivan, M.; Frank, M.G.; Hurley, C.M.; Tiwana, J. Police lie detection accuracy: The effect of lie scenario. Law Hum. Behav. 2009, 33, 530. [Google Scholar] [CrossRef]
- Yan, W.J.; Li, X.; Wang, S.J.; Zhao, G.; Liu, Y.J.; Chen, Y.H.; Fu, X. CASME II: An improved spontaneous micro-expression database and the baseline evaluation. PLoS ONE 2014, 9, e86041. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Facial action coding system. Environ. Psychol. Nonverbal Behav. 1978. [Google Scholar] [CrossRef]
- Paul Ekman Group. MicroExpression Training Tool (METT); University of California: San Francisco, CA, USA, 2002. [Google Scholar]
- Yan, W.J.; Wu, Q.; Liu, Y.J.; Wang, S.J.; Fu, X. CASME database: A dataset of spontaneous micro-expressions collected from neutralized faces. In Proceedings of the 2013 10th IEEE international conference and workshops on automatic face and gesture recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–7. [Google Scholar]
- Qu, F.; Wang, S.J.; Yan, W.J.; Li, H.; Wu, S.; Fu, X. CAS(ME)2: A Database for Spontaneous Macro-Expression and Micro-Expression Spotting and Recognition. IEEE Trans. Affect. Comput. 2017, 9, 424–436. [Google Scholar] [CrossRef]
- Li, J.; Dong, Z.; Lu, S.; Wang, S.J.; Yan, W.J.; Ma, Y.; Liu, Y.; Huang, C.; Fu, X. CAS(ME)3: A Third Generation Facial Spontaneous Micro-Expression Database with Depth Information and High Ecological Validity. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar]
- Davison, A.K.; Lansley, C.; Costen, N.; Tan, K.; Yap, M.H. SAMM: A Spontaneous Micro-Facial Movement Dataset. IEEE Trans. Affect. Comput. 2018, 9, 116–129. [Google Scholar] [CrossRef] [Green Version]
- Cheng, Z.; Chuk, T.; Hayward, W.; Chan, A.; Hsiao, J. Global and Local Priming Evoke Different Face Processing Strategies: Evidence From An Eye Movement Study. J. Vis. 2015, 15, 154. [Google Scholar] [CrossRef]
- Polikovsky, S.; Kameda, Y.; Ohta, Y. Facial micro-expressions recognition using high speed camera and 3D-gradient descriptor. In Proceedings of the 3rd International Conference on Imaging for Crime Detection and Prevention (ICDP 2009), London, UK, 3 December 2009. [Google Scholar]
- Pfister, T.; Li, X.; Zhao, G.; Pietikäinen, M. Recognising spontaneous facial micro-expressions. In Proceedings of the 2011 International Conference on Computer Vision, Washington, DC, USA, 6–13 November 2011; pp. 1449–1456. [Google Scholar]
- Zhao, G.; Pietikainen, M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.J.; Yan, W.J.; Zhao, G.; Fu, X.; Zhou, C.G. Micro-expression recognition using robust principal component analysis and local spatiotemporal directional features. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 325–338. [Google Scholar]
- Wright, J.; Ganesh, A.; Rao, S.; Peng, Y.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low-rank matrices via convex optimization. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2009; pp. 2080–2088. [Google Scholar]
- Wang, S.J.; Chen, H.L.; Yan, W.J.; Chen, Y.H.; Fu, X. Face recognition and micro-expression recognition based on discriminant tensor subspace analysis plus extreme learning machine. Neural Process. Lett. 2014, 39, 25–43. [Google Scholar] [CrossRef]
- Wang, S.J.; Yan, W.J.; Li, X.; Zhao, G.; Fu, X. Micro-expression recognition using dynamic textures on tensor independent color space. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 4678–4683. [Google Scholar]
- Huang, X.; Wang, S.J.; Zhao, G.; Piteikainen, M. Facial micro-expression recognition using spatiotemporal local binary pattern with integral projection. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 1–9. [Google Scholar]
- Liu, Y.J.; Zhang, J.K.; Yan, W.J.; Wang, S.J.; Zhao, G.; Fu, X. A main directional mean optical flow feature for spontaneous micro-expression recognition. IEEE Trans. Affect. Comput. 2015, 7, 299–310. [Google Scholar] [CrossRef]
- Huang, X.; Zhao, G.; Hong, X.; Zheng, W.; Pietikäinen, M. Spontaneous facial micro-expression analysis using spatiotemporal completed local quantized patterns. Neurocomputing 2016, 175, 564–578. [Google Scholar] [CrossRef]
- Xu, F.; Zhang, J.; Wang, J.Z. Microexpression identification and categorization using a facial dynamics map. IEEE Trans. Affect. Comput. 2017, 8, 254–267. [Google Scholar] [CrossRef]
- Wang, S.J.; Wu, S.; Qian, X.; Li, J.; Fu, X. A main directional maximal difference analysis for spotting facial movements from long-term videos. Neurocomputing 2017, 230, 382–389. [Google Scholar] [CrossRef]
- Li, J.; Soladie, C.; Seguier, R. Local Temporal Pattern and Data Augmentation for Micro-Expression Spotting. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef]
- Patel, D.; Hong, X.; Zhao, G. Selective deep features for micro-expression recognition. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancún, Mexico, 4–8 December 2016; pp. 2258–2263. [Google Scholar]
- Wang, S.J.; Li, B.J.; Liu, Y.J.; Yan, W.J.; Ou, X.; Huang, X.; Xu, F.; Fu, X. Micro-expression recognition with small sample size by transferring long-term convolutional neural network. Neurocomputing 2018, 312, 251–262. [Google Scholar] [CrossRef]
- Xia, Z.; Peng, W.; Khor, H.Q.; Feng, X.; Zhao, G. Revealing the invisible with model and data shrinking for composite-database micro-expression recognition. IEEE Trans. Image Process. 2020, 29, 8590–8605. [Google Scholar] [CrossRef]
- Li, Y.; Huang, X.; Zhao, G. Joint Local and Global Information Learning With Single Apex Frame Detection for Micro-Expression Recognition. IEEE Trans. Image Process. 2020, 30, 249–263. [Google Scholar] [CrossRef]
- Zhou, L.; Mao, Q.; Huang, X.; Zhang, F.; Zhang, Z. Feature refinement: An expression-specific feature learning and fusion method for micro-expression recognition. Pattern Recognit. 2022, 122, 108275. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Ouahabi, A. Signal and Image Multiresolution Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Haneche, H.; Ouahabi, A.; Boudraa, B. New mobile communication system design for Rayleigh environments based on compressed sensing-source coding. IET Commun. 2019, 13, 2375–2385. [Google Scholar] [CrossRef]
- Haneche, H.; Boudraa, B.; Ouahabi, A. A new way to enhance speech signal based on compressed sensing. Measurement 2020, 151, 107117. [Google Scholar] [CrossRef]
- Mahdaoui, A.E.; Ouahabi, A.; Moulay, M.S. Image Denoising Using a Compressive Sensing Approach Based on Regularization Constraints. Sensors 2022, 22, 2199. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.J.; Yan, W.J.; Sun, T.; Zhao, G.; Fu, X. Sparse tensor canonical correlation analysis for micro-expression recognition. Neurocomputing 2016, 214, 218–232. [Google Scholar] [CrossRef]
- Donoho, D.L. High-dimensional data analysis: The curses and blessings of dimensionality. AMS Math Challenges Lect. 2000, 1, 32. [Google Scholar]
- Zhang, K.; Huang, Y.; Du, Y.; Wang, L. Facial Expression Recognition Based on Deep Evolutional Spatial-Temporal Networks. IEEE Trans. Image Process. 2017, 26, 4193–4203. [Google Scholar] [CrossRef] [PubMed]
- Lin, Z.; Chen, M.; Ma, Y. The augmented lagrange multiplier method for exact recovery of corrupted low-rank matrices. arXiv 2010, arXiv:1009.5055. [Google Scholar]
- Davison, A.K.; Merghani, W.; Yap, M.H. Objective classes for micro-facial expression recognition. J. Imaging 2018, 4, 119. [Google Scholar] [CrossRef] [Green Version]
- Ben, X.; Ren, Y.; Zhang, J.; Wang, S.J.; Kpalma, K.; Meng, W.; Liu, Y.J. Video-based facial micro-expression analysis: A survey of datasets, features and algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Li, X.; Hong, X.; Moilanen, A.; Huang, X.; Pfister, T.; Zhao, G.; Pietikäinen, M. Towards reading hidden emotions: A comparative study of spontaneous micro-expression spotting and recognition methods. IEEE Trans. Affect. Comput. 2017, 9, 563–577. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; See, J.; Phan, R.C.W.; Oh, Y.H. LBP with six intersection points: Reducing redundant information in lbp-top for micro-expression recognition. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 525–537. [Google Scholar]
- Liong, S.T.; Gan, Y.S.; See, J.; Khor, H.Q.; Huang, Y.C. Shallow triple stream three-dimensional cnn (STSTNet) for micro-expression recognition. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Activation Function | |
|---|---|---|
| HCRNN | CNN: L1-4 | ReLU |
| BRNN: L5, 8 and 11 | Tanh | |
| FC L13 | Softmax | |
| RPRNN | BiLSTM: L1 | ReLU |
| FC L2 | ReLU | |
| FC L3 | Softmax |
| Type | Kernel Size | Stride | Output Size |
|---|---|---|---|
| convolution | 1 | /// | |
| max pool | 2 | /// | |
| convolution | 1 | /// | |
| max pool | 2 | /// | |
| convolution | 1 | /// | |
| max pool | 2 | /// | |
| convolution | 1 | /// |
| Database | Sample Size | Emotions Class | FPS | Label |
|---|---|---|---|---|
| CASME I | 195 | 8 | 60 | emotion/AUs |
| CASME II | 247 | 5 | 200 | emotion/AUs |
| CAS(ME) | 57 | 4 | 30 | emotion/AUs |
| SAMM | 159 | 7 | 200 | emotion/AUs |
| a | 0.1 | 0.2 | 0.3 | 0.4 | 0.45 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 |
|---|---|---|---|---|---|---|---|---|---|---|
| Fold1 | 55.38 | 52.31 | 55.38 | 53.85 | 53.85 | 58.46 | 58.46 | 56.92 | 55.38 | 53.85 |
| Fold2 | 66.15 | 64.62 | 69.23 | 70.77 | 70.77 | 70.77 | 69.23 | 67.69 | 63.08 | 63.08 |
| Fold3 | 60 | 60 | 61.54 | 61.54 | 61.54 | 63.08 | 61.54 | 63.08 | 60 | 58.46 |
| Fold4 | 61.54 | 63.08 | 63.08 | 66.15 | 66.15 | 64.62 | 66.15 | 66.15 | 64.62 | 63.08 |
| Fold5 | 56.92 | 56.92 | 55.38 | 60 | 60 | 58.46 | 58.46 | 58.46 | 56.92 | 56.92 |
| Fold6 | 63.08 | 63.08 | 64.62 | 63.08 | 64.62 | 63.08 | 58.46 | 61.54 | 61.54 | 60 |
| Fold7 | 55.38 | 53.85 | 52.31 | 53.85 | 47.69 | 41.54 | 41.54 | 41.54 | 41.54 | 41.54 |
| Fold8 | 60 | 58.46 | 60 | 60 | 58.46 | 58.46 | 53.85 | 52.31 | 50.77 | 52.31 |
| Fold9 | 52.31 | 52.31 | 52.31 | 53.85 | 53.85 | 56.92 | 53.85 | 53.85 | 56.92 | 56.92 |
| Fold10 | 63.08 | 63.08 | 63.08 | 61.54 | 60 | 61.54 | 52.31 | 52.31 | 52.31 | 52.31 |
| Mean | 59.385 | 58.769 | 59.692 | 60.308 | 60.309 | 60.308 | 57.385 | 57.385 | 56.308 | 55.847 |
| Method | Fold1 | Fold2 | Fold3 | Fold4 | Fold5 | Fold6 | Fold7 | Fold8 | Fold9 | Fold10 | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|
| HCRNN | 53.85 | 63.08 | 58.46 | 63.08 | 56.92 | 56.92 | 40 | 52.31 | 55.38 | 50.77 | 55.08 |
| RPRNN | 56.82 | 64.62 | 60 | 61.54 | 56.92 | 60 | 56.92 | 60 | 56.92 | 61.54 | 59.53 |
| DLHN | 53.85 | 70.77 | 61.54 | 66.15 | 60 | 64.62 | 53.85 | 58.46 | 53.85 | 60 | 60.31 |
| Method | Fold1 | Fold2 | Fold3 | Fold4 | Fold5 | Fold6 | Fold7 | Fold8 | Fold9 | Fold10 | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FDM+SVM | 36.92 | 41.54 | 52.31 | 43.08 | 33.85 | 43.08 | 43.08 | 52.31 | 33.85 | 50.77 | 43.08 |
| LBP+SVM | 55.38 | 52.31 | 50.77 | 56.92 | 58.46 | 47.69 | 53.85 | 55.38 | 56.92 | 53.85 | 53.85 |
| LBP+SVM | 66.15 | 58.46 | 64.62 | 58.46 | 63.08 | 58.46 | 49.23 | 52.31 | 61.54 | 61.54 | 58.38 |
| LBP+SVM | 55.38 | 58.46 | 58.46 | 53.85 | 46.15 | 50.77 | 43.08 | 58.46 | 58.46 | 53.85 | 43.08 |
| LBP+SVM | 60 | 55.38 | 41.54 | 49.23 | 60 | 47.69 | 46.15 | 55.38 | 55.38 | 49.23 | 46.15 |
| STSTNet | 46.15 | 60.00 | 58.46 | 55.38 | 50.77 | 53.85 | 50.77 | 49.23 | 52.31 | 55.38 | 53.23 |
| RCN_w | 47.69 | 61.54 | 53.85 | 52.31 | 49.23 | 56.92 | 46.15 | 58.46 | 55.38 | 53.85 | 53.54 |
| RCN_s | 38.46 | 63.08 | 49.23 | 56.92 | 46.15 | 53.85 | 46.15 | 55.38 | 60.00 | 36.92 | 50.61 |
| RCN_a | 35.38 | 61.54 | 47.69 | 61.54 | 46.15 | 46.15 | 49.23 | 64.62 | 47.69 | 36.92 | 49.69 |
| RCN_f | 46.15 | 72.31 | 56.92 | 53.85 | 46.15 | 50.77 | 53.85 | 50.77 | 58.46 | 47.69 | 53.69 |
| FR | 46.15 | 61.54 | 58.46 | 66.15 | 61.54 | 56.92 | 50.77 | 44.62 | 56.92 | 56.92 | 56.00 |
| DLHN | 53.85 | 70.77 | 61.54 | 66.15 | 60 | 64.62 | 53.85 | 58.46 | 53.85 | 60 | 60.31 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Wang, T.; Wang, S.-J. Facial Micro-Expression Recognition Based on Deep Local-Holistic Network. Appl. Sci. 2022, 12, 4643. https://doi.org/10.3390/app12094643
Li J, Wang T, Wang S-J. Facial Micro-Expression Recognition Based on Deep Local-Holistic Network. Applied Sciences. 2022; 12(9):4643. https://doi.org/10.3390/app12094643
Chicago/Turabian StyleLi, Jingting, Ting Wang, and Su-Jing Wang. 2022. "Facial Micro-Expression Recognition Based on Deep Local-Holistic Network" Applied Sciences 12, no. 9: 4643. https://doi.org/10.3390/app12094643
APA StyleLi, J., Wang, T., & Wang, S.-J. (2022). Facial Micro-Expression Recognition Based on Deep Local-Holistic Network. Applied Sciences, 12(9), 4643. https://doi.org/10.3390/app12094643