
Horizon Targeted Loss-Based Diverse Realistic Marine Image Generation Method Using a Multimodal Style Transfer Network for Training Autonomous Vessels


Abstract
:1. Introduction
- A specialized style transfer method for marine images is proposed.
- A novel horizon-targeted loss is designed to enhance and preserve the shapes of the ocean horizon and the vessel.
- The accuracy of representing structural forms is improved through the style transfer of marine data.
- A method for the generation of diverse and realistic marine images is proposed that uses one-to-many style mapping and is based on multimodal style transfer.
2. Related Works
2.1. Simulators of Autonomous Vessels
2.2. Image-to-Image Translation for Style Transfer
2.2.1. Supervised-Learning Approach
2.2.2. Unsupervised-Learning Approach for a Single Style
2.2.3. Unsupervised-Learning Approach for Multiple Styles
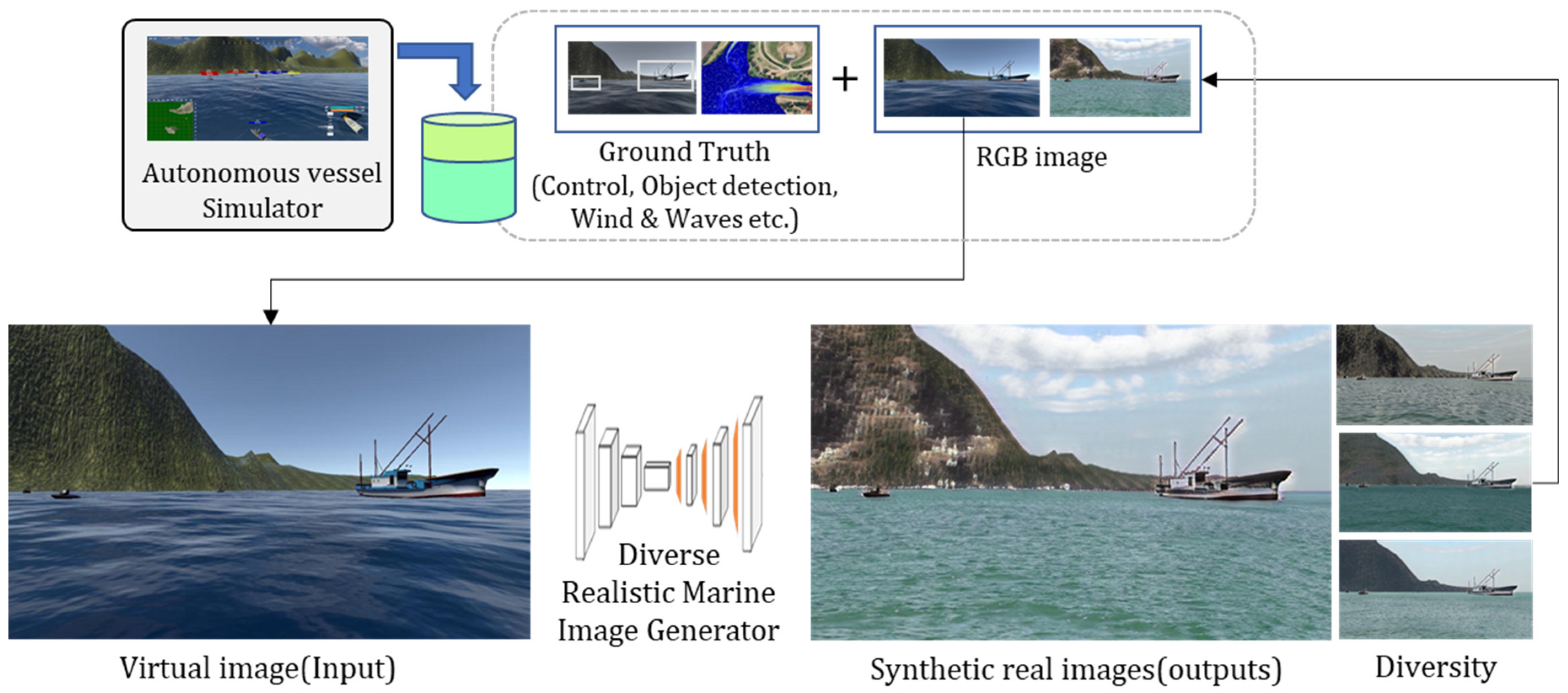
3. Proposed Diverse and Realistic Marine Image Generation Framework
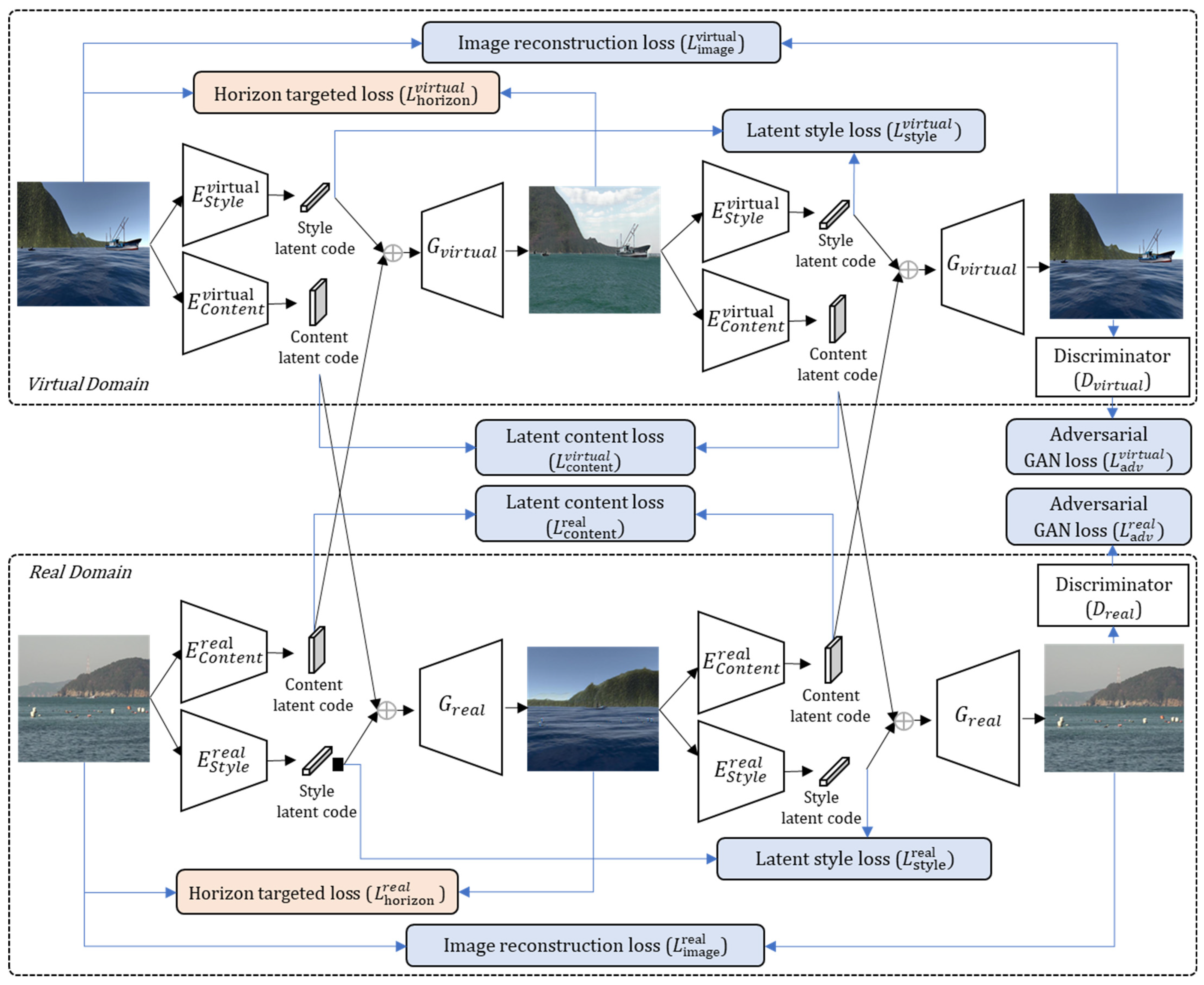
3.1. Diverse Realistic Marine Image Generator
- (1)
- Image reconstruction loss: Given an image sampled from the data distribution, we reconstruct the entire image after encoding and decoding. is defined in a similar manner.
- (2)
- Latent content loss: Given a latent content code sampled from the latent distribution, we calculate the latent content code required to reconstruct it after decoding and encoding. is defined in a similar manner.
- (3)
- Latent style loss: Given a latent style code sampled from the latent distribution, we calculate the latent style code required to reconstruct it after decoding and encoding. is defined in a similar manner.
- (4)
- Adversarial GAN loss: We employ GANs to match the distribution of virtual-domain images to that of the real-domain data. is defined in a similar manner.
- (5)
- Horizon-targeted loss: We calculate the loss by comparing the RoI in the input data to that in the output data. is defined in a similar manner.
- (6)
- Total loss: The objective function of our conditional GAN model is based on that of MUNIT [22]. We propose the introduction of horizon-targeted loss, which focuses on the horizon area to prevent losing shape coherence, via the following minimax game.
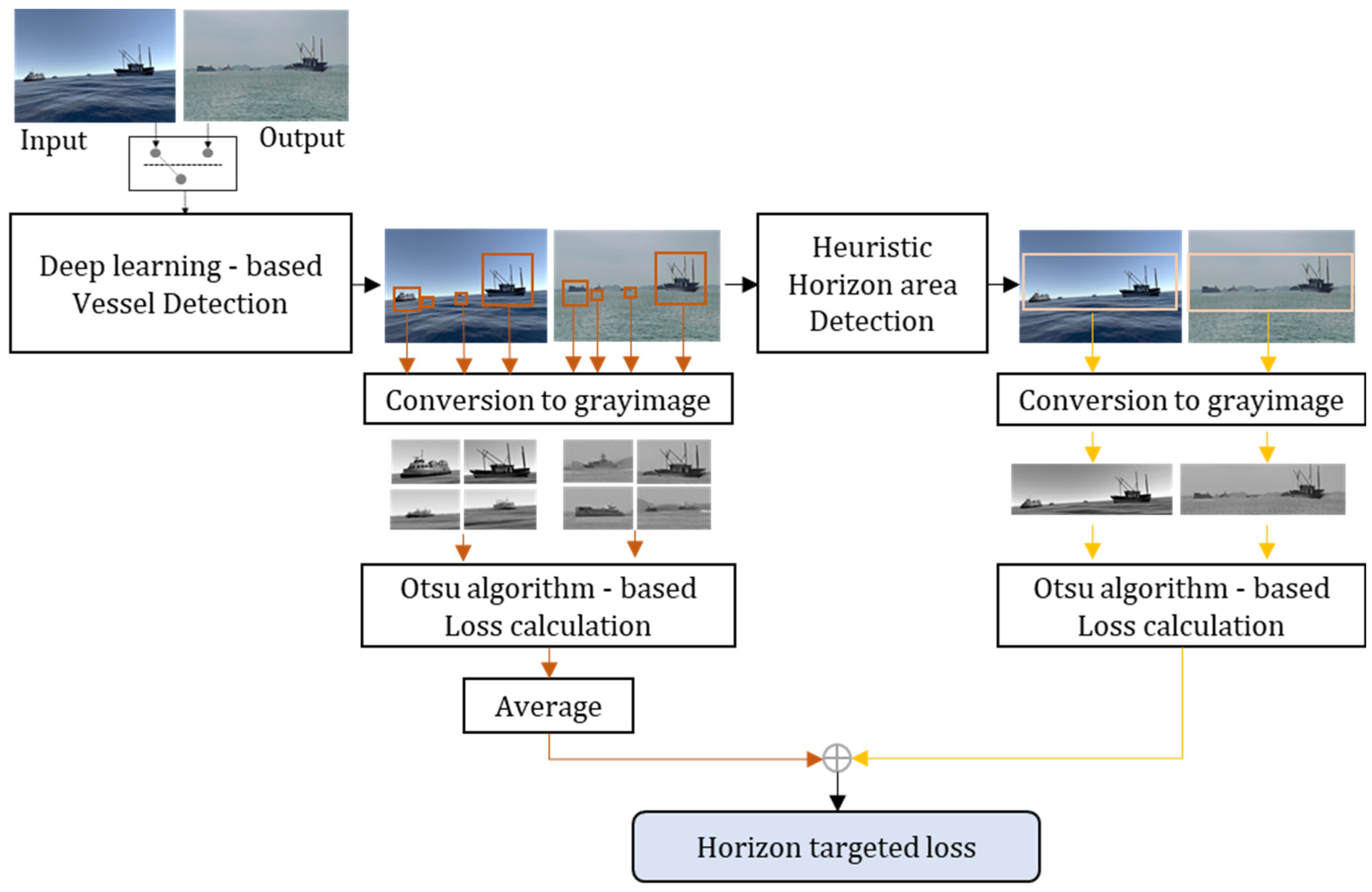
3.2. Horizon Targeted Loss Calculator
| Algorithm 1 Horizon-targeted loss calculation |
| Input: |
| Output: |
| 1: minY |
| 2: |
| 3: If then |
| 4: For |
| 5: If then |
| 6: |
| 7: |
| 8: If then |
| 9: minY |
| 10: End |
| 11: End |
| 12: End |
| 13: |
| 14: |
| 15: |
| 16: |
| 17: |
| 18: For |
| 19: vesselLoss ← |
| 20: End |
| 21: vesselLoss ← vesselLoss |
| 22: horizonLoss ← |
| 23: |
| 24: Else |
3.3. Discriminator
4. Experiments and Analysis
4.1. Experiment Settings
4.2. Evaluation Metrics
4.3. Quantitative Evaluation of Diverse Photorealistic Marine Image Generator
4.4. Horizion Targeted Loss Effects
4.5. Comparison of Object Detection Performance
4.6. Inference Time
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. In Field and Service Robotics; Springer: Cham, Switzerland, 2017; pp. 621–635. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Rong, G.; Shin, B.H.; Tabatabaee, H.; Lu, Q.; Lemke, S.; Možeiko, M.; Boise, E.; Uhm, G.; Kim, T.H.; Kim, S.; et al. Lgsvl simulator: A high fidelity simulator for autonomous driving. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Kermorgant, O. A dynamic simulator for underwater vehicle-manipulators. In International Conference on Simulation, Modeling, and Programming for Autonomous Robots; Springer: Cham, Switzerland, 2014; pp. 25–36. [Google Scholar]
- Rohmer, E.; Singh, S.P.; Freese, M. V-REP: A versatile and scalable robot simulation framework. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 1321–1326. [Google Scholar]
- RobotX Simulator. Available online: https://bitbucket.org/osrf/vmrc/overview (accessed on 30 December 2018).
- Unmanned Surface Vehicle Simulator. Available online: https://github.com/disaster-robotics-proalertas/usv_sim_lsa (accessed on 30 December 2018).
- Yoo, J.; Uh, Y.; Chun, S.; Kang, B.; Ha, J.W. Photorealistic style transfer via wavelet transforms. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9036–9045. [Google Scholar]
- Li, Y.; Tang, S.; Zhang, R.; Zhang, Y.; Li, J.; Yan, S. Asymmetric GAN for Unpaired Image-to-Image Translation. IEEE Trans. Image Process. 2019, 28, 5881–5896. [Google Scholar] [CrossRef]
- Manzo, M.; Pellino, S. Voting in Transfer Learning System for Ground-Based Cloud Classification. Mach. Learn. Knowl. Extr. 2021, 3, 542–553. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Processing Syst. 2014, 27, 1–9. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2337–2346. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the 16th IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1857–1865. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2180–2188. [Google Scholar]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. Beta-Vae: Learning Basic Visual Concepts with a Constrained Variational Framework. 2016. Available online: https://openreview.net/forum?id=Sy2fzU9gl (accessed on 1 December 2021).
- Kim, H.; Mnih, A. Disentangling by factorising. In Proceedings of the International Conference on Machine Learning, Hanoi, Vietnam, 28–30 September 2018; pp. 2649–2658. [Google Scholar]
- Lee, H.Y.; Tseng, H.Y.; Huang, J.B.; Singh, M.; Yang, M.H. Diverse image-to-image translation via disentangled representations. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 35–51. [Google Scholar]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–189. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Processing Syst. 2017, 30, 1–12. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simulator | Waves | Buoyancy | Water Currents | Wind Currents | Camera (RGB) |
|---|---|---|---|---|---|
| Freefloating Gazebo [4] | O | O | O | X | O |
| VREP [5] | O | O | X | X | O |
| RobotX Simulator [6] | O | O | X | O | O |
| USVSim [7] | O | O | O | O | O |
| Ocean Dataset | Real Ocean Data | Virtual Ocean Data |
|---|---|---|
| Training | 1800 | 1800 |
| Testing | 200 | 200 |
| Total Number of Images | 2000 | 2000 |
| Method | FID (↓) |
|---|---|
| Virtual images vs. Real images | 109.422 |
| Realistic images (ours) vs. Real images | 102.210 |
| Data Type | Object Detection Accuracy |
|---|---|
| Real data | 85% |
| Virtual data | 79% |
| Realistic data | 81% |
| Method | Average Inference Time |
|---|---|
| MUNIT [22] | 0.034 s (29.41 fps) |
| Ours | 0.032 s (31.25 fps) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Choi, T.H.; Cho, K. Horizon Targeted Loss-Based Diverse Realistic Marine Image Generation Method Using a Multimodal Style Transfer Network for Training Autonomous Vessels. Appl. Sci. 2022, 12, 1253. https://doi.org/10.3390/app12031253
Park J, Choi TH, Cho K. Horizon Targeted Loss-Based Diverse Realistic Marine Image Generation Method Using a Multimodal Style Transfer Network for Training Autonomous Vessels. Applied Sciences. 2022; 12(3):1253. https://doi.org/10.3390/app12031253
Chicago/Turabian StylePark, Jisun, Tae Hyeok Choi, and Kyungeun Cho. 2022. "Horizon Targeted Loss-Based Diverse Realistic Marine Image Generation Method Using a Multimodal Style Transfer Network for Training Autonomous Vessels" Applied Sciences 12, no. 3: 1253. https://doi.org/10.3390/app12031253
APA StylePark, J., Choi, T. H., & Cho, K. (2022). Horizon Targeted Loss-Based Diverse Realistic Marine Image Generation Method Using a Multimodal Style Transfer Network for Training Autonomous Vessels. Applied Sciences, 12(3), 1253. https://doi.org/10.3390/app12031253