
Automatic Identification of Landslides Based on Deep Learning


 , ,
, ,
Abstract
:1. Introduction
- (1)
- We process the landslide data in the Bijie landslide dataset, create a landslide dataset, and preprocess the dataset (data cleaning, data enhancement);
- (2)
- On the landslide dataset, we use three models (U-Net, DeepLab v3+ and PSPNet) to conduct experiments and test the performance changes in the models when different classification networks are used as the backbone network;
- (3)
- We use the above pretrained model to test the landslide test set and use mIoU, precision, and recall to evaluate the model performance to obtain the optimal model for landslide identification performance.
2. Related Work
3. Materials and Methods
3.1. Data Source
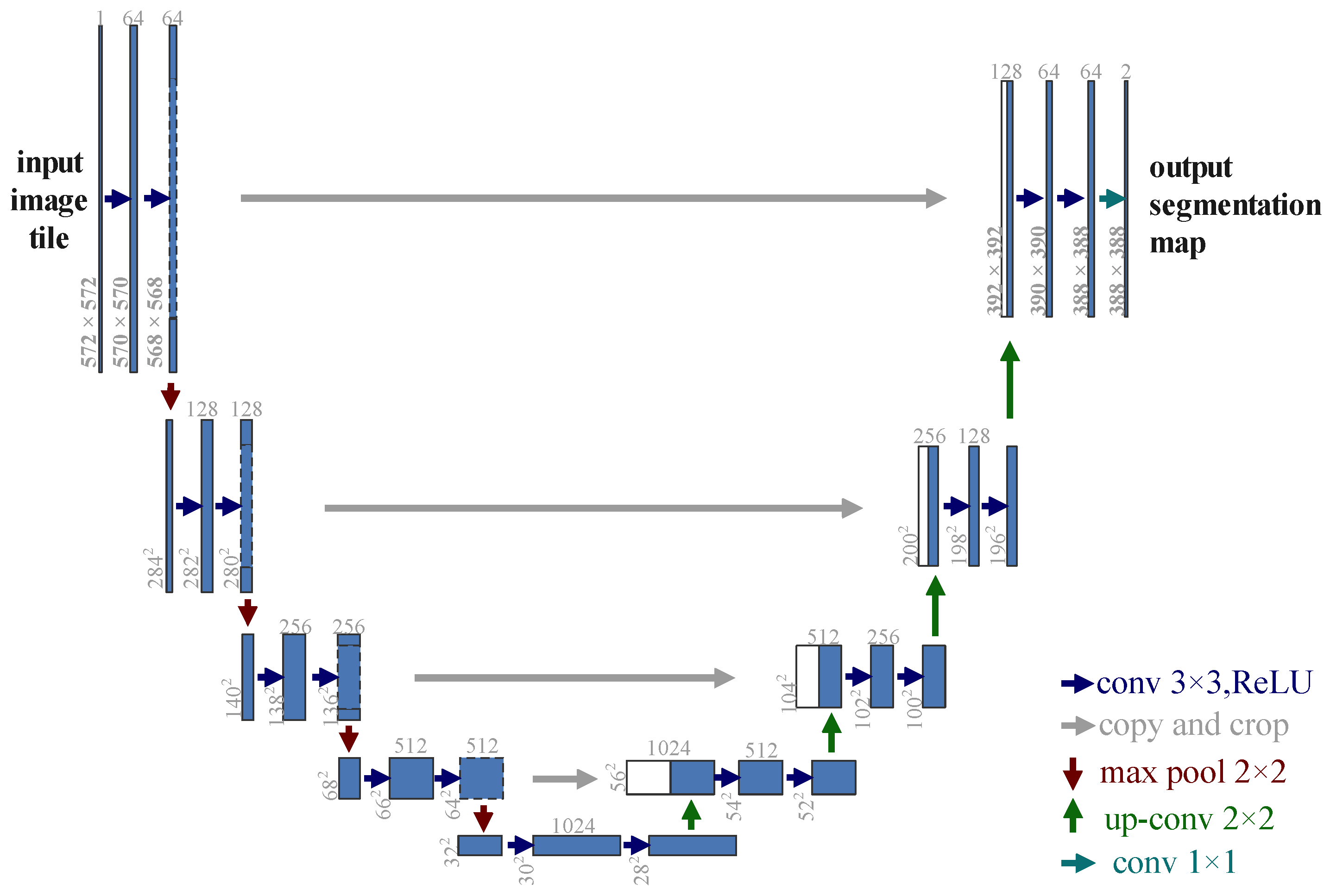
3.2. U-Net
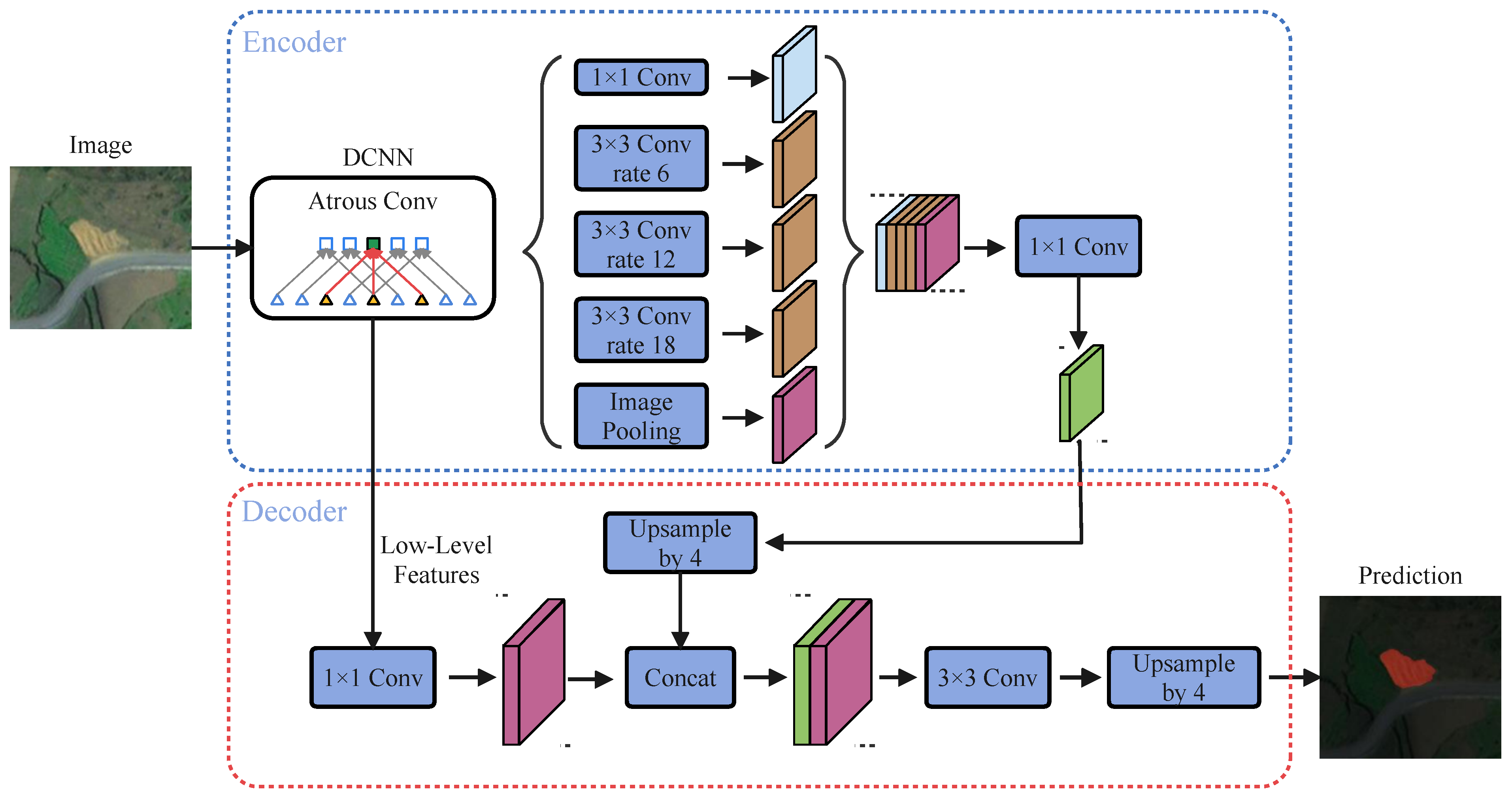
3.3. DeepLab v3+
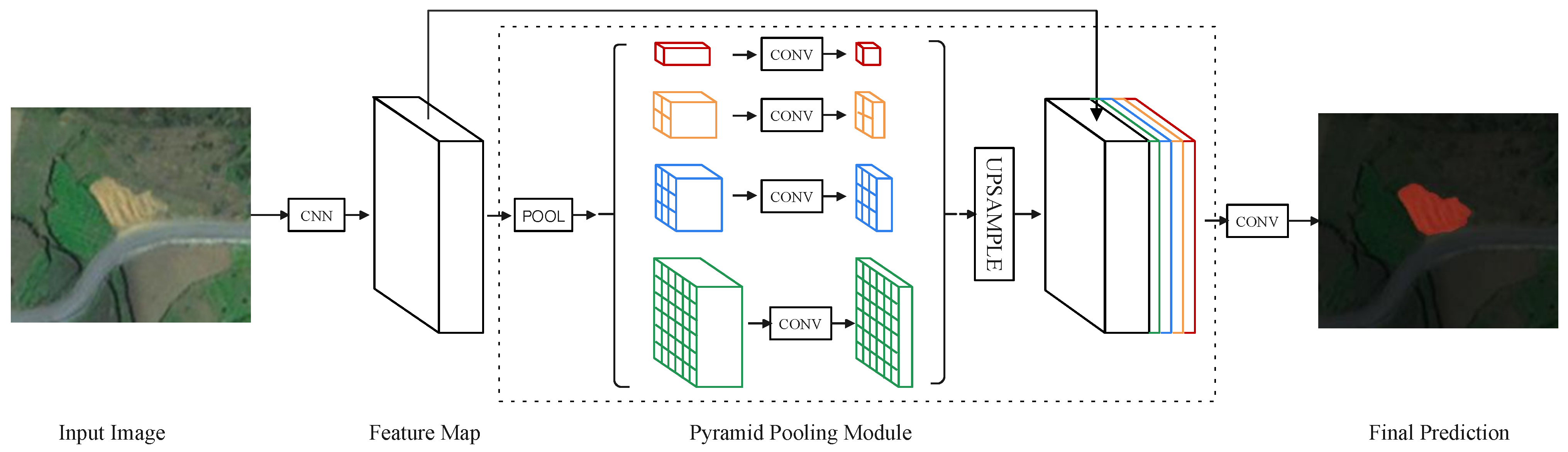
3.4. PSPNet
3.5. Evaluation Metrics
4. Results and Discussion
4.1. Data Preprocessing
4.2. Training
4.3. Experimental Results and Analysis
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hacıefendioğlu, K.; Demir, G.; Başağa, H.B. Landslide detection using visualization techniques for deep convolutional neural network models. Nat. Hazards 2021, 109, 329–350. [Google Scholar] [CrossRef]
- Voigt, S.; Kemper, T.; Riedlinger, T.; Kiefl, R.; Scholte, K.; Mehl, H. Satellite image analysis for disaster and crisis-management support. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1520–1528. [Google Scholar] [CrossRef]
- Plank, S.; Twele, A.; Martinis, S. Landslide mapping in vegetated areas using change detection based on optical and polarimetric SAR data. Remote Sens. 2016, 8, 307. [Google Scholar] [CrossRef]
- Czikhardt, R.; Papco, J.; Bakon, M.; Liscak, P.; Ondrejka, P.; Zlocha, M. Ground stability monitoring of undermined and landslide prone areas by means of sentinel-1 multi-temporal InSAR, case study from Slovakia. Geosciences 2017, 7, 87. [Google Scholar] [CrossRef]
- Rosi, A.; Tofani, V.; Tanteri, L.; Tacconi Stefanelli, C.; Agostini, A.; Catani, F.; Casagli, N. The new landslide inventory of Tuscany (Italy) updated with PS-InSAR: Geomorphological features and landslide distribution. Landslides 2018, 15, 5–19. [Google Scholar] [CrossRef]
- Li, Z.; Shi, W.; Lu, P.; Yan, L.; Wang, Q.; Miao, Z. Landslide mapping from aerial photographs using change detection-based Markov random field. Remote Sens. Environ. 2016, 187, 76–90. [Google Scholar] [CrossRef]
- Li, Z.; Shi, W.; Myint, S.W.; Lu, P.; Wang, Q. Semi-automated landslide inventory mapping from bitemporal aerial photographs using change detection and level set method. Remote Sens. Environ. 2016, 175, 215–230. [Google Scholar] [CrossRef]
- Han, Y.; Wang, P.; Zheng, Y.; Yasir, M.; Xu, C.; Nazir, S.; Hossain, M.S.; Ullah, S.; Khan, S. Extraction of Landslide Information Based on Object-Oriented Approach and Cause Analysis in Shuicheng, China. Remote Sens. 2022, 14, 502. [Google Scholar] [CrossRef]
- Chen, T.; Trinder, J.C.; Niu, R. Object-oriented landslide mapping using ZY-3 satellite imagery, random forest and mathematical morphology, for the Three-Gorges Reservoir, China. Remote Sens. 2017, 9, 333. [Google Scholar] [CrossRef]
- Vaduva, C.; Gavat, I.; Datcu, M. Deep learning in very high resolution remote sensing image information mining communication concept. In Proceedings of the 20th European Signal Processing Conference (EUSIPCO), Bucharest, Romania, 27–31 August 2012; pp. 2506–2510. [Google Scholar]
- Peña, J.M.; Gutiérrez, P.A.; Hervás-Martínez, C.; Six, J.; Plant, R.E.; López-Granados, F. Object-based image classification of summer crops with machine learning methods. Remote Sens. 2014, 6, 5019–5041. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Tiede, D.; Dabiri, Z.; Sudmanns, M.; Lang, S. Dwelling extraction in refugee camps using cnn—First experiences and lessons learnt. In Proceedings of the ISPRS TC I Mid-term Symposium “Innovative Sensing—From Sensors to Methods and Applications” Conference, Karlsruhe, Germany, 10–12 October 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Natarajan, A.; Bharat, K.; Kaustubh, G.R.; Moharir, M.; Srinath, N.; Subramanya, K. An Approach to Real Time Parking Management using Computer Vision. In Proceedings of the 2nd International Conference on Control and Computer Vision, Jeju Island, Korea, 15–18 June 2019; pp. 18–22. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Landslide Detection of Hyperspectral Remote Sensing Data Based on Deep Learning with Constrains. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5047–5060. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of different machine learning methods and deep-learning convolutional neural networks for landslide detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef]
- Prakash, N.; Manconi, A.; Loew, S. Mapping landslides on EO data: Performance of deep learning models vs. traditional machine learning models. Remote Sens. 2020, 12, 346. [Google Scholar] [CrossRef]
- Zhu, Q.; Chen, L.; Hu, H.; Xu, B.; Zhang, Y.; Li, H. Deep Fusion of Local and Non-Local Features for Precision Landslide Recognition. arXiv 2020, arXiv:2002.08547. [Google Scholar]
- Ji, S.; Yu, D.; Shen, C.; Li, W.; Xu, Q. Landslide detection from an open satellite imagery and digital elevation model dataset using attention boosted convolutional neural networks. Landslides 2020, 17, 1337–1352. [Google Scholar] [CrossRef]
- Liu, P.; Wei, Y.; Wang, Q.; Chen, Y.; Xie, J. Research on post-earthquake landslide extraction algorithm based on improved U-Net model. Remote Sens. 2020, 12, 894. [Google Scholar] [CrossRef]
- Ju, Y.; Xu, Q.; Jin, S.; Li, W.; Su, Y.; Dong, X.; Guo, Q. Loess Landslide Detection Using Object Detection Algorithms in Northwest China. Remote Sens. 2022, 14, 1182. [Google Scholar] [CrossRef]
- Dai, B.; Wang, Y.; Ye, C.; Li, Q.; Yuan, C.; Lu, S.; Li, Y. A Novel Method for Extracting Time Series Information of Deformation Area of A single Landslide Based on Improved U-Net Neural Network. Front. Earth Sci. 2021, 9, 1139. [Google Scholar] [CrossRef]
- Ullo, S.L.; Mohan, A.; Sebastianelli, A.; Ahamed, S.E.; Kumar, B.; Dwivedi, R.; Sinha, G.R. A new mask R-CNN-based method for improved landslide detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3799–3810. [Google Scholar] [CrossRef]
- Liu, P.; Wei, Y.; Wang, Q.; Xie, J.; Chen, Y.; Li, Z.; Zhou, H. A research on landslides automatic extraction model based on the improved mask R-CNN. ISPRS Int. J. Geo-Inf. 2021, 10, 168. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Gholamnia, K.; Ghamisi, P. The application of ResU-net and OBIA for landslide detection from multi-temporal sentinel-2 images. In Big Earth Data; Taylor & Francis: Abingdon, UK, 2022; pp. 1–26. [Google Scholar] [CrossRef]
- Dahmane, M.; Foucher, S.; Beaulieu, M.; Riendeau, F.; Bouroubi, Y.; Benoit, M. Object detection in pleiades images using deep features. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1552–1555. [Google Scholar] [CrossRef]
- Längkvist, M.; Alirezaie, M.; Kiselev, A.; Loutfi, A. Interactive learning with convolutional neural networks for image labeling. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–16 July 2017; pp. 2881–2890. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actual Values | Predicted Values | |
|---|---|---|
| Positive | Negative | |
| Positive | TP | FN |
| Negative | FP | TN |
| Method | Probability of Execution | Specific Operations |
|---|---|---|
| random rotation | 50% | rotate 20°, +90°, −90° |
| left-right flipping | 100% | flip the image left and right |
| image cropping | 100% | original image 0.7× dimension |
| Model | Backbone |
|---|---|
| U-Net | VGG |
| U-Net | ResNet50 |
| DeepLab v3+ | MobileNet |
| DeepLab v3+ | Xception |
| PSPNet | MobileNet |
| PSPNet | ResNet50 |
| Hyper-Parameter | Parameter Values |
|---|---|
| input_shape | [473, 473] |
| classes | landslide, background |
| freeze_Train | True |
| pretrained weights | True |
| datasets used for pre-training | VOC data set |
| Init_Epoch | 0 |
| downsample_factor | 8 |
| freeze_epoch | 50 |
| unfreeze_epoch | 100 |
| freeze_learning_rate | 10 |
| freeze_batch_size | 8 |
| unfreeze_batch_size | 4 |
| unfreeze_learning_rate | 10 |
| focal_loss | True |
| dice_loss | True |
| eager pattern | False |
| aux_branch | False |
| early_stopping | True |
| num_workers | 1 |
| cls_weights | np.array([1, 2], np.float32) |
| Model | Backbone | mIoU | Recall | Precision |
|---|---|---|---|---|
| U-Net | VGG | 81.64% | 89.34% | 89.22% |
| DeepLab v3+ | Xception | 86.15% | 92.26% | 92.20% |
| DeepLab v3+ | MobileNet | 87.06% | 94.06% | 91.64% |
| U-Net | ResNet50 | 88.75% | 96.15% | 91.82% |
| PSPNet | MobileNet | 89.11% | 97.39% | 92.61% |
| Backbone | Evaluate | Landslide | Background |
|---|---|---|---|
| MobileNet | P | 82.79% | 97.08% |
| R | 97.37% | 97.41% | |
| IoU | 81.15% | 82.97% | |
| ResNet50 | P | 88.14% | 99.41% |
| R | 95.47% | 98.34% | |
| IoU | 84.6% | 97.76% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Wang, Y.; Wang, P.; Mu, J.; Jiao, S.; Zhao, X.; Wang, Z.; Wang, K.; Zhu, Y. Automatic Identification of Landslides Based on Deep Learning. Appl. Sci. 2022, 12, 8153. https://doi.org/10.3390/app12168153
Yang S, Wang Y, Wang P, Mu J, Jiao S, Zhao X, Wang Z, Wang K, Zhu Y. Automatic Identification of Landslides Based on Deep Learning. Applied Sciences. 2022; 12(16):8153. https://doi.org/10.3390/app12168153
Chicago/Turabian StyleYang, Shuang, Yuzhu Wang, Panzhe Wang, Jingqin Mu, Shoutao Jiao, Xupeng Zhao, Zhenhua Wang, Kaijian Wang, and Yueqin Zhu. 2022. "Automatic Identification of Landslides Based on Deep Learning" Applied Sciences 12, no. 16: 8153. https://doi.org/10.3390/app12168153
APA StyleYang, S., Wang, Y., Wang, P., Mu, J., Jiao, S., Zhao, X., Wang, Z., Wang, K., & Zhu, Y. (2022). Automatic Identification of Landslides Based on Deep Learning. Applied Sciences, 12(16), 8153. https://doi.org/10.3390/app12168153