
A Situational Analysis of Current Speech-Synthesis Systems for Child Voices: A Scoping Review of Qualitative and Quantitative Evidence


Abstract
1. Introduction
2. Methods
2.1. Eligibility Criteria
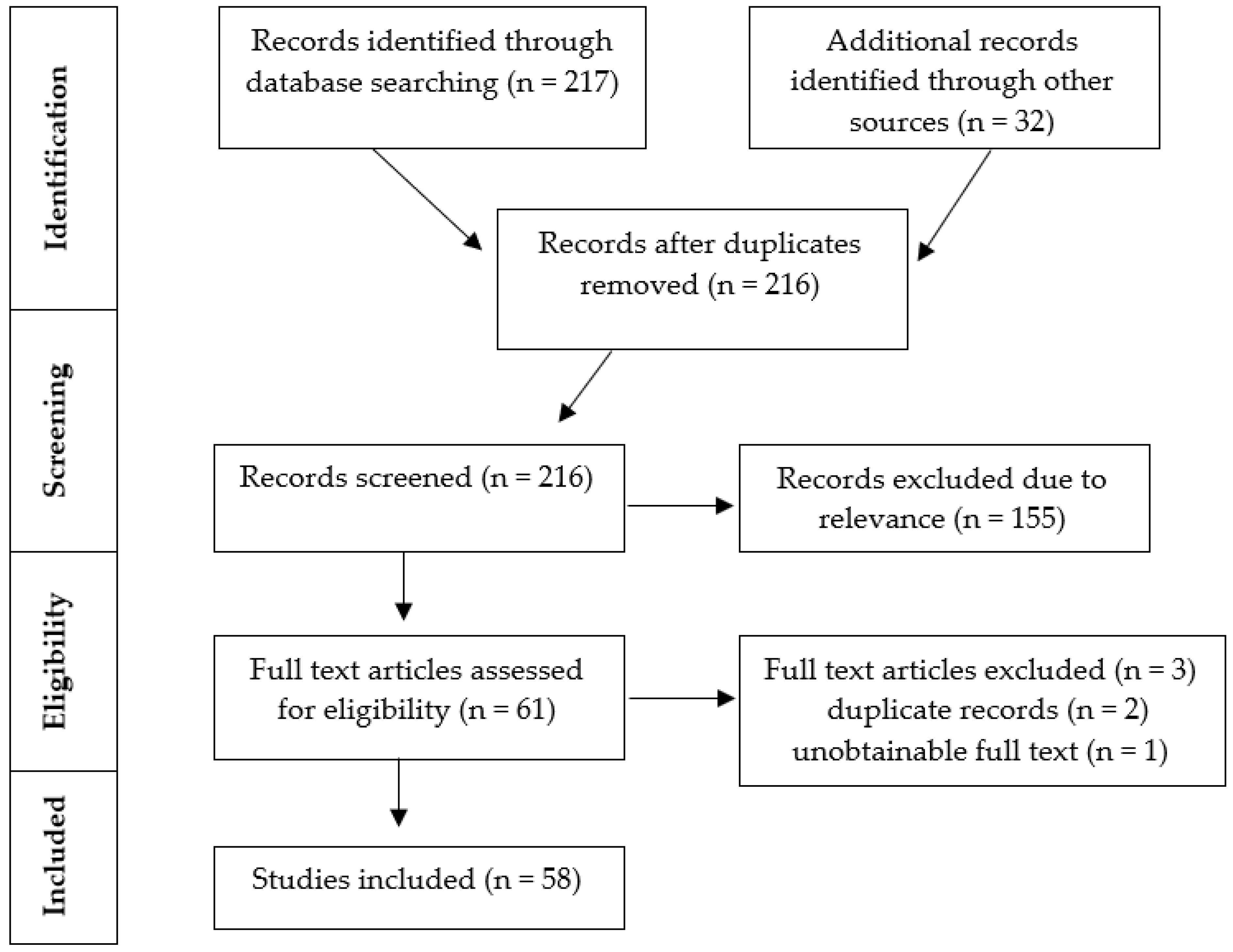
2.2. Search Procedures
2.3. Coding Procedures
3. Results
3.1. Language
3.2. Speech-Synthesis Systems
3.3. Child-Speech Data
3.4. Intelligibility
3.5. Age
4. Discussion
4.1. Language
4.2. Speech-Synthesis Systems
4.3. Child-Speech Data
4.4. Intelligibility
4.5. Age
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Drager, K.; Light, J.; McNaughton, D. Effects of AAC interventions on communication and language for young children with complex communication needs. J. Pediatr. Rehabil. Med. Interdiscip. Approach 2010, 3, 303–310. [Google Scholar] [CrossRef] [PubMed]
- Creer, S.; Cunningham, S.; Green, P.; Yamagishi, J. Building personalised synthetic voices for individuals with severe speech impairment. Comput. Speech Lang. 2013, 27, 1178–1193. [Google Scholar] [CrossRef]
- Yamagishi, J.; Veaux, C.; King, S.; Renals, S. Speech synthesis technologies for individuals with vocal disabilities: Voice banking and reconstruction. Acoust. Sci. Technol. 2012, 33, 1–5. [Google Scholar] [CrossRef][Green Version]
- Mills, T.; Bunnell, H.T.; Patel, R. Towards personalized speech synthesis for augmentative and alternative communication. Augment. Altern. Commun. 2014, 30, 226–236. [Google Scholar] [CrossRef] [PubMed]
- Begnum, M.; Hoelseth, S.F.; Johnsen, B.; Hansen, F. A Child’s Voice. In Proceedings of the 2012 Norsk Informatikkonferanse (NIK), Bodø, Norway, 9–12 November 2012; pp. 165–176. [Google Scholar]
- Dada, S.; Horn, T.; Samuels, A.; Schlosser, R. Children’s attitudes toward interaction with an unfamiliar peer with complex communication needs: Comparing high- and low-technology devices. Augment. Altern. Commun. 2016, 32, 305–311. [Google Scholar] [CrossRef]
- Tönsing, K.M.; Dada, S. ‘Teachers’ perceptions of implementation of aided AAC to support expressive communication in South African special schools: A pilot investigation. Augment. Altern. Commun. 2016, 32, 282–304. [Google Scholar] [CrossRef]
- Jette, A.M.; Spicer, C.M.; Flaubert, J.L. (Eds.) Augmentative and alternative communication and voice products and technologies. In The Promise of Assistive Technology to Enhance Activity and Work Participation; The National Academies Press: Washington, DC, USA, 2017; pp. 209–310. [Google Scholar] [CrossRef]
- Creer, S. Personalising Synthetic Voices for Individuals with Severe Speech Impairment. Ph.D. Thesis, University of Sheffield, Sheffield, UK, 2009. [Google Scholar]
- Sefara, T.J.; Mokgonyane, T.B.; Manamela, M.J.; Modipa, T.I. HMM-based speech synthesis system incorporated with language identification for low-resourced languages. In Proceedings of the 2019 International Conference on Advances in Big Data, Computing and Data Communication Systems (icABCD), Winterton, South Africa, 5–6 August 2019. [Google Scholar] [CrossRef]
- Koul, R.; Hester, K. Effects of Repeated Listening Experiences on the Recognition of Synthetic Speech by Individuals With Severe Intellectual Disabilities. J. Speech Lang. Hear. Res. 2006, 49, 47–57. [Google Scholar] [CrossRef]
- Watt, D.; Harrison, P.S.; Cabot-King, L. Who owns your voice? Linguistic and legal perspectives on the relationship between vocal distinctiveness and the rights of the individual speaker. Int. J. Speech Lang. Law 2019, 26, 137–180. [Google Scholar] [CrossRef]
- Wester, M.; Wu, Z.; Yamagishi, J. Human vs. machine spoofing detection on wideband and narrowband data. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 2047–2051. [Google Scholar]
- Wang, X.; Yamagishi, J.; Todisco, M.; Delgado, H.; Nautsch, A.; Evans, N.; Sahidullah, M.; Vestman, V.; Kinnunen, T.; Lee, K.A. ASVspoof 2019: A large-scale public database of synthetic, converted and replayed speech. arXiv 2020, arXiv:1911.01601. [Google Scholar] [CrossRef]
- Terblanche, C.; Harrison, P.; Gully, A.J. Human Spoofing Detection Performance on Degraded Speech. In Proceedings of the Interspeech 2021, Brno, Czechia, 30 August–3 September 2021; pp. 1738–1742. [Google Scholar] [CrossRef]
- De Wet, F.; van der Walt, W.; Dlamini, N.; Govender, A. Building Synthetic Voices for Under-Resourced Languages: The Feasibility of using Audiobook Data. In Proceedings of the 2017 Pattern Recognition Association of South Africa and Robotics and Mechatronics (PRASA-RobMech), Bloemfontein, South Africa, 30 November–1 December 2017. [Google Scholar]
- Govender, A.; de Wet, F. Objective Measures to Improve the Selection of Training Speakers in HMM-Based Child Speech Synthesis. In Proceedings of the 2016 Pattern Recognition Association of South Africa and Robotics and Mechatronics International Conference (PRASA-RobMech), Stellenbosch, South Africa, 30 November–2 December 2016. [Google Scholar]
- Hagen, A.; Pellom, B.; Hacioglu, K. Generating Synthetic Children’s Acoustic Models from Adult Models. In Proceedings of the NAACL HLT 2009: Short Papers, Boulder, CO, USA, 31 May–5 June 2009; pp. 77–80. [Google Scholar]
- Kumar, J.V.; Surendra, A.K. Statistical Parametric Approach for Child Speech Synthesis using HMM-Based System. Int. J. Comput. Sci. Technol. 2011, 2, 149–152. [Google Scholar]
- Watts, O.; Yamagishi, J.; King, S.; Berkling, K. Synthesis of child speech with HMM adaptation and voice conversion. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 1005–1016. [Google Scholar] [CrossRef]
- Cosi, P.; Nicolao, M.; Paci, G.; Sommavilla, G.; Tesser, F. Comparing Open Source ASR Toolkits on Italian Children Speech. In Proceedings of the Fourth Workshop on Child Computer Interaction (WOCCI 2014), Singapore, 19 September 2014. [Google Scholar]
- Yamagishi, J.; Watts, O.; King, S.; Usabaev, B. Roles of the Average Voice in Speaker-Adaptive HMM-Based Speech Synthesis. In Proceedings of the Interspeech 2010, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Govender, A.; Nouhou, B.; de Wet, F. HMM Adaptation for child speech synthesis using ASR data. In Proceedings of the 2015 Pattern Recognition Association of South Africa and Robotics and Mechatronics International Conference (PRASA-RobMech), Port Elizabeth, South Africa, 26–27 November 2015. [Google Scholar]
- Qian, Y.; Wang, X.; Evanini, K.; Suendermann-Oeft, D. Improving DNN-Based Automatic Recognition of Non-Native Children’s Speech with Adult Speech. In Proceedings of the Workshop on Child Computer Interaction, San Fransisco, CA, USA, 6–7 September 2016; pp. 40–44. [Google Scholar]
- Qian, M.; McLoughlin, I.; Quo, W.; Dai, L. Mismatched Training Data Enhancement for Automatic Recognition of Children’s Speech using DNN-HMM. In Proceedings of the 2016 10th International Symposium on Chinese Spoken Language Processing (ISCSLP), Tianjin, China, 17–20 October 2016. [Google Scholar]
- Fainberg, J.; Bell, P.; Lincoln, M.; Renals, S. Improving Children’s Speech Recognition through Out-of-Domain Data Augmentation. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 1598–1602. [Google Scholar]
- Tong, R.; Wang, L.; Ma, B. Transfer Learning for Children’s Speech Recognition. In Proceedings of the 2017 International Conference on Asian Language Processing (IALP), Stockholm, Sweden, 5–7 December 2017; pp. 2193–2197. [Google Scholar]
- Serizel, R.; Giuliani, D. Vocal tract length normalisation approaches to DNN-based children’s and adults’ speech recognition. In Proceedings of the 2014 IEEE Spoken Language Technology Workshop (SLT), South Lake Tahoe, CA, USA, 7–10 December 2014; pp. 135–140. [Google Scholar] [CrossRef]
- Giuliani, D.; Baba Ali, B. Large Vocabulary Children’s Speech Recognition with DNN-HMM and SGMM Acoustic Modeling. In Proceedings of the Interspeech 2015, Dresden, Germany, 6–10 September 2015; pp. 1635–1639. [Google Scholar]
- Cosi, P. A KALDI-DNN-Based ASR System for Italian: Experiments on Children Speech. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–5. [Google Scholar]
- Tong, R.; Chen, N.F.; Ma, B. Multi-Task Learning for Mispronunciation Detection on Singapore Children’s Mandarin Speech. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 2193–2197. [Google Scholar]
- Serizel, R.; Giuliani, D. Deep-neural network approaches for speech recognition with heterogeneous groups of speakers including children. Nat. Lang. Eng. 2016, 23, 325–350. [Google Scholar] [CrossRef]
- Colquhoun, H.L.; Levac, D.; O’Brien, K.K.; Straus, S.; Tricco, A.C.; Perrier, L.; Kastner, M.; Moher, D. Scoping reviews: Time for clarity in definition, methods, and reporting. J. Clin. Epidemiol. 2014, 64, 1291–1294. [Google Scholar] [CrossRef] [PubMed]
- Hoover, J.; Reichle, J.; Van Tasell, D.; Cole, D. The intelligibility of synthesized speech: Echo II versus Votrax. J. Speech Hear. Res. 1987, 30, 425–431. [Google Scholar] [CrossRef] [PubMed]
- Ouzzani, M.; Hammady, H.; Fedorowicz, Z.; Elmagarmid, A. Rayyan—A web and mobile app for systematic reviews. Syst. Rev. 2016, 5, 210. [Google Scholar] [CrossRef]
- Von Berg, S.; Panorska, A.; Uken, D.; Qeadan, F. DECtalkTM and VeriVoxTM: Intelligibility, Likeability, and Rate Preference Differences for Four Listener Groups. Augment. Altern. Commun. 2009, 25, 7–18. [Google Scholar] [CrossRef]
- Shivakumar, P.G.; Georgiou, P. Transfer Learning from Adult to Children for Speech Recognition: Evaluation, Analysis and Recommendations. Comput. Speech Lang. 2020, 63, 101077. [Google Scholar] [CrossRef]
- Fringi, E.; Lehman, J.F.; Russell, M. Evidence of phonological processes in automatic recognition of children’s speech. In Proceedings of the Interspeech 2015, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Gray, S.; Willett, D.; Lu, J.; Pinto, J.; Maergner, P.; Bodenstab, N. Child automatic speech recognition for US English: Child interaction with living-room-electronic-devices. In Proceedings of the Fourth Workshop on Child Computer Interaction (WOCCI), Singapore, 19 September 2014; pp. 21–26. [Google Scholar]
- Liao, H.; Pundak, G.; Siohan, O.; Carroll, M.K.; Coccaro, N.; Jiang, Q.-M.; Sainath, T.N.; Senior, A.; Beaufays, F.; Bacchiani, M. Large vocabulary automatic speech recognition for children. In Proceedings of the Interspeech 2015, Dresden, Germany, 6–10 September 2015; pp. 1611–1615. [Google Scholar]
- Murphy, A.; Yanushevskaya, I.; Chasaide, A.N.; Gobl, C. Testing the GlórCáíl system in a speaker and affect voice transformation task. In Proceedings of the 10th International Conference on Speech Prosody 2020, Tokyo, Japan, 25–28 May 2020; pp. 950–954. [Google Scholar]
- Tulsiani, H.; Swarup, P.; Rao, P. Acoustic and language modeling for children’s read speech assessment. In Proceedings of the 2017 Twenty-Third National Conference on Communications (NCC), Chennai, India, 2–4 March 2017; pp. 1–6. [Google Scholar]
- Hasija, T.; Kadyan, V.; Guleria, K. Out Domain Data Augmentation on Punjabi Children Speech Recognition using Tacotron. In Proceedings of the International Conference on Mathematics and Artificial Intelligence (ICMAI 2021), Chengdu, China, 19–21 March 2021. [Google Scholar] [CrossRef]
- Karhila, R.; Sanand, D.R.; Kurimo, M.; Smit, P. Creating synthetic voices for children by adapting adult average voice using stacked transformations and VTLN. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012. [Google Scholar]
- Pucher, M.; Toman, M.; Schabus, D.; Valentini-Botinhao, C.; Yamagishi, J.; Zillinger, B.; Schmid, E. Influence of speaker familiarity on blind and visually impaired children’s perception of synthetic voices in audio games. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Vaz Brandl, M.H.; Joublin, F.; Goerick, C. Speech imitation with a child’s voice: Addressing the correspondence problem. In Proceedings of the 13th International Conference on Speech and Computer (SPECOM), St. Petersburg, Russia, 21–25 June 2009. [Google Scholar]
- Pribilova, A.; Přibil, J. Non-linear frequency scale mapping for voice conversion in text-to-speech system with cepstral description. Speech Commun. 2006, 48, 1691–1703. [Google Scholar] [CrossRef]
- Cosi, P. On the development of matched and mismatched Italian children’s speech recognition systems. In Proceedings of the Interspeech 2009, Brighton, UK, 6–10 September 2009; pp. 540–543. [Google Scholar]
- Gerosa, M.; Giuliani, D.; Brugnara, F. Acoustic variability and automatic recognition of children’s speech. Speech Commun. 2007, 49, 847–860. [Google Scholar] [CrossRef]
- Gerosa, M.; Giuliani, D.; Brugnara, F. Towards age-independent acoustic modeling. Speech Commun. 2009, 51, 499–509. [Google Scholar] [CrossRef]
- Gerosa, M.; Giuliani, D.; Narayanan, S.; Potamianos, A. A review of ASR technologies for children’s speech. In Proceedings of the 2nd Workshop on Child, Computer and Interaction, Grenoble, France, 5 November 2009; pp. 1–8. [Google Scholar]
- Matassoni, M.; Falavigna, D.; Giuliani, D. DNN adaptation for recognition of children speech through automatic utterance selection. In Proceedings of the 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, USA, 13–16 December 2016; pp. 644–651. [Google Scholar]
- Jia, N.; Zheng, C.; Sun, W. Speech synthesis of children’s reading based on cycleGAN model. In Proceedings of the International Symposium on Electronic Information Technology and Communication Engineering (ISEITCE), Jinan, China, 19–21 June 2020. [Google Scholar]
- Metallinou, A.; Cheng, J. Using deep neural networks to improve proficiency assessment for children english language learners. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 1468–1472. [Google Scholar]
- Saheer, L.B.; Yamagishi, J.; Garner, P.N.; Dines, J. Combining vocal tract length normalization with hierarchical linear transformations. IEEE J. Sel. Top. Signal Process. 2013, 8, 262–272. [Google Scholar] [CrossRef]
- Mousa, A. Speech segmentation in synthesized speech morphing using pitch shifting. Int. Arab. J. Inf. Technol. 2011, 8, 221–226. [Google Scholar]
- Ghai, S.; Sinha, R. Exploring the effect of differences in the acoustic correlates of adults’ and children’s speech in the context of automatic speech recognition. EURASIP J. Audio Speech Music. Process. 2010, 2010, 318785. [Google Scholar] [CrossRef][Green Version]
- Ghai, S.; Sinha, R. Enhancing children’s speech recognition under mismatched condition by explicit acoustic normalization. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Ghai, S.; Sinha, R. Pitch adaptive MFCC features for improving children’s mismatched ASR. Int. J. Speech Technol. 2015, 18, 489–503. [Google Scholar] [CrossRef]
- Sinha, R.; Ghai, S. On the use of pitch normalization for improving children’s speech recognition. In Proceedings of the Interspeech 2009, Brighton, UK, 6–10 September 2009; pp. 568–571. [Google Scholar]
- Shahnawazuddin, S.; Dey, A.; Sinha, R. Pitch-adaptive front-end features for robust children’s ASR. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 3459–3463. [Google Scholar]
- Ghai, S.; Sinha, R. Analyzing pitch robustness of PMVDR and MFCC features for children’s speech recognition. In Proceedings of the 2010 International Conference on Signal Processing and Communications (SPCOM), Bangalore, India, 18–21 July 2010; pp. 1–5. [Google Scholar]
- Umesh, S.; Sinha, R.; Rama Sanand, D. Using vocal-tract length normalisation in recognition of children speech. In Proceedings of the Interspeech 2007, Stockholm, Sweden, 20–24 August 2007. [Google Scholar]
- Jreige, C.; Patel, R.; Bunnell, H.T.; Vocali, D. VocaliD: Personalizing Text-to-Speech Synthesis for Individuals with Severe Speech Impairment. In Proceedings of the 11th International ACM SIGACCESS Conference on Computers and Accessibility, Pittsburgh, PA, USA, 25–28 October 2009; pp. 259–260. [Google Scholar] [CrossRef]
- Koul, R.; Clapsaddle, K.C. Effects of repeated listening experiences on the perception of synthetic speech by individuals with mild-to-moderate intellectual disabilities. AAC Augment. Altern. Commun. 2006, 22, 112–122. [Google Scholar] [CrossRef] [PubMed]
- Drager, K.D.R.; Clark-Serpentine, E.A.; Johnson, K.E.; Roeser, J.L. Accuracy of Repetition of Digitized and Synthesized Speech for Young Children in Background Noise. Am. J. Speech Lang. Pathol. 2006, 15, 155–164. [Google Scholar] [CrossRef]
- Jacob, A.; Mythili, P. Developing a Child Friendly Text-to-Speech System. Adv. Hum. Comput. Interact. 2008, 2008, 597971. [Google Scholar] [CrossRef]
- Shivakumar, P.G.; Potamianos, A.; Lee, S.; Narayanan, S. Improving speech recognition for children using acoustic adaptation and pronunciation modeling. In Proceedings of the Fourth Workshop on Child Computer Interaction (WOCCI), Singapore, 19 September 2014; pp. 15–19. [Google Scholar]
- Drager, K.; Finke, E. Intelligibility of Children’s Speech in Digitized Speech. AAC Augment. Altern. Commun. 2012, 28, 181–189. [Google Scholar] [CrossRef]
- Anumanchipalli, G.K.; Black, A.B. Adaptation tecniques for speech synthesis in under-resourced languages. In Proceedings of the SLTU-2010, Penang, Malaysia, 3–5 May 2010. [Google Scholar]
- Gutkin, A.; Ha, L.; Jansche, M.; Pipatsrisawat, K.; Sproat, R. TTS for Low Resource Languages: A Bangla Synthesizer. In Proceedings of the 10th edition of the Language Resources and Evaluation Conference (LREC), Portoroz, Slovenia, 23–28 May 2016; pp. 2005–2010. [Google Scholar]
- Yang, H.; Oura, K.; Wang, H.; Gan, Z.; Tokuda, K. Using speaker adaptive training to realize Mandarin-Tibetan cross-lingual speech synthesis. Multimed. Tools Appl. Int. J. 2015, 74, 9927–9942. [Google Scholar] [CrossRef]
- Matassoni, M.; Gretter, R.; Falavigna, D.; Giuliani, D. Non-native children speech recognition through transfer learning. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6229–6233. [Google Scholar]
- Sutton, S.J.; Foulkes, P.; Kirk, D.; Lawson, S. Voice as a design material: Sociophonetic inspired design strategies in Human-Computer Interaction. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019. [Google Scholar] [CrossRef]
- Ghai, S.; Sinha, R. Exploring the role of spectral smoothing in context of children’s speech recognition. In Proceedings of the Tenth Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009; pp. 1607–1610. [Google Scholar]
- Drager, K.D.R.; Reichle, J.; Pinkoski, C. Synthesized Speech Output and Children: A Scoping Review. Am. J. Speech Lang. Pathol. 2010, 19, 259–273. [Google Scholar] [CrossRef]
- Drager, K.D.; Hustad, K.C.; Gable, K.L. Telephone communication: Synthetic and dysarthric speech intelligibility and listener preferences. Augment. Altern. Commun. 2004, 20, 103–112. [Google Scholar] [CrossRef]
- Gorernflo, C.W.; Gorernflo, D.W.; Santer, S.A.; Gorenflo, C.W.; Gorenflo, D.W. Effects of synthetic voice output on attitudes toward the augmented communicator. J. Speech Hear. Res. 1994, 37, 64–68. [Google Scholar] [CrossRef]
- Kent-Walsh, J.; Murza, K.A.; Malani, M.D.; Binger, C. Effects of communication partner instruction on the communication of individuals using AAC: A meta-analysis. Augment. Altern. Commun. 2015, 31, 271–284. [Google Scholar] [CrossRef]
- Moorcroft, A.; Scarinci, N.; Meyer, C. Speech pathologist perspectives on the acceptance versus rejection or abandonment of AAC systems for children with complex communication needs. Augment. Altern. Commun. 2019, 35, 193–204. [Google Scholar] [CrossRef] [PubMed]
- Wendt, O.; Hsu, N.; Simon, K.; Dienhart, A.; Cain, L. Effects of an iPad-based speech-generating device infused into instruction with the picture exchange communication system for adolescents and young adults with severe autism spectrum disorder. Behav. Modif. 2019, 43, 898–932. [Google Scholar] [CrossRef]
- Ganz, J.; Hong, E.; Goodwyn, F. Effectiveness of the PECS Phase III app and choice between the app and traditional PECS among preschoolers with ASD. Res. Autism Spectr. Disord. 2012, 7, 973–983. [Google Scholar] [CrossRef]
- Schlosser, R.; Sigafoos, J.; Luiselli, J.K.; Angermeier, K.; Harasymowyz, U.; Schooley, K.; Belfiore, P.J. Effects of synthetic speech output on requesting and natural speech production in children with autism: A preliminary study. Res. Autism Spectr. Disord. 2007, 1, 139–163. [Google Scholar] [CrossRef]
- Cui, X.; Alwan, A. Adaptation of children’s speech with limited data based on formant-like peak alignment. Comput. Speech Lang. 2006, 20, 400–419. [Google Scholar] [CrossRef]
- Giuliani, D.; Gerosa, M.; Brugnara, F. Improved automatic speech recognition through speaker normalization. Comput. Speech Lang. 2006, 20, 107–123. [Google Scholar] [CrossRef]


{kind=link}
| Databases |
|
| Sources of evidence |
|
| Search terms | (child* AND (“speech synthesis” OR “synthetic voice*” OR “speech synthesi?er” OR “digiti?ed speech”)) |
| (child* AND VOCA AND (“digiti?ed speech” OR “synthesi?ed speech” OR “speech synthesis”)) | |
| (child* AND “speech generating device” AND (“digiti?ed speech” OR synthesi?ed speech” OR “speech synthesis”)) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Terblanche, C.; Harty, M.; Pascoe, M.; Tucker, B.V. A Situational Analysis of Current Speech-Synthesis Systems for Child Voices: A Scoping Review of Qualitative and Quantitative Evidence. Appl. Sci. 2022, 12, 5623. https://doi.org/10.3390/app12115623
Terblanche C, Harty M, Pascoe M, Tucker BV. A Situational Analysis of Current Speech-Synthesis Systems for Child Voices: A Scoping Review of Qualitative and Quantitative Evidence. Applied Sciences. 2022; 12(11):5623. https://doi.org/10.3390/app12115623
Chicago/Turabian StyleTerblanche, Camryn, Michal Harty, Michelle Pascoe, and Benjamin V. Tucker. 2022. "A Situational Analysis of Current Speech-Synthesis Systems for Child Voices: A Scoping Review of Qualitative and Quantitative Evidence" Applied Sciences 12, no. 11: 5623. https://doi.org/10.3390/app12115623
APA StyleTerblanche, C., Harty, M., Pascoe, M., & Tucker, B. V. (2022). A Situational Analysis of Current Speech-Synthesis Systems for Child Voices: A Scoping Review of Qualitative and Quantitative Evidence. Applied Sciences, 12(11), 5623. https://doi.org/10.3390/app12115623