
Artificial Intelligence for Creating Low Latency and Predictive Intrusion Detection with Security Enhancement in Power Systems

 ,
, 
 ,
, 
Abstract
:1. Introduction
- Malware—malware is just code packed with malicious content. About 92% of malware is deployed via email attachments and the rest as downloadable content. The primary motivation of using malware is to infect the device and steal or destroy information. In November 2020 alone, about 113 million new malware programs were reported [8].
- Phishing—it simply is an act of posing as a legitimate organization or person and asking users for sensitive information. According to the APWG report in the Q4 of 2020, 22.5% of the phishing activities targeted financial institutions, 22% of them involved SAAS/webmail and 15.2% of them were involved in payment activities [9].
- Password attack—these include frequent dictionary attacks or keyloggers to gain access to users’ passwords. Password decryption is employed to gain the original password from the hashed password. Therefore, it is essential to have a password combination consisting of alphabets, numeric and special characters.
- DDoS—a distributed denial-of-service interrupts the proper functioning of Internet-connected devices. It continuously sends fake requests to the server, consequently increasing the load on the server. Hence, when a legitimate user sends a request to the server, the server is not able to respond to valid requests. If the same activity is performed by a large number of infected devices, from which millions of requests are sent to the server and if a valid user tries to request on the server, the server is unable to respond due to high traffic or malicious requests. In a report by Netscout, 929,000 DDoS attacks were recorded within 31 days, in April-May 2020 [10].
2. Related and Background Work
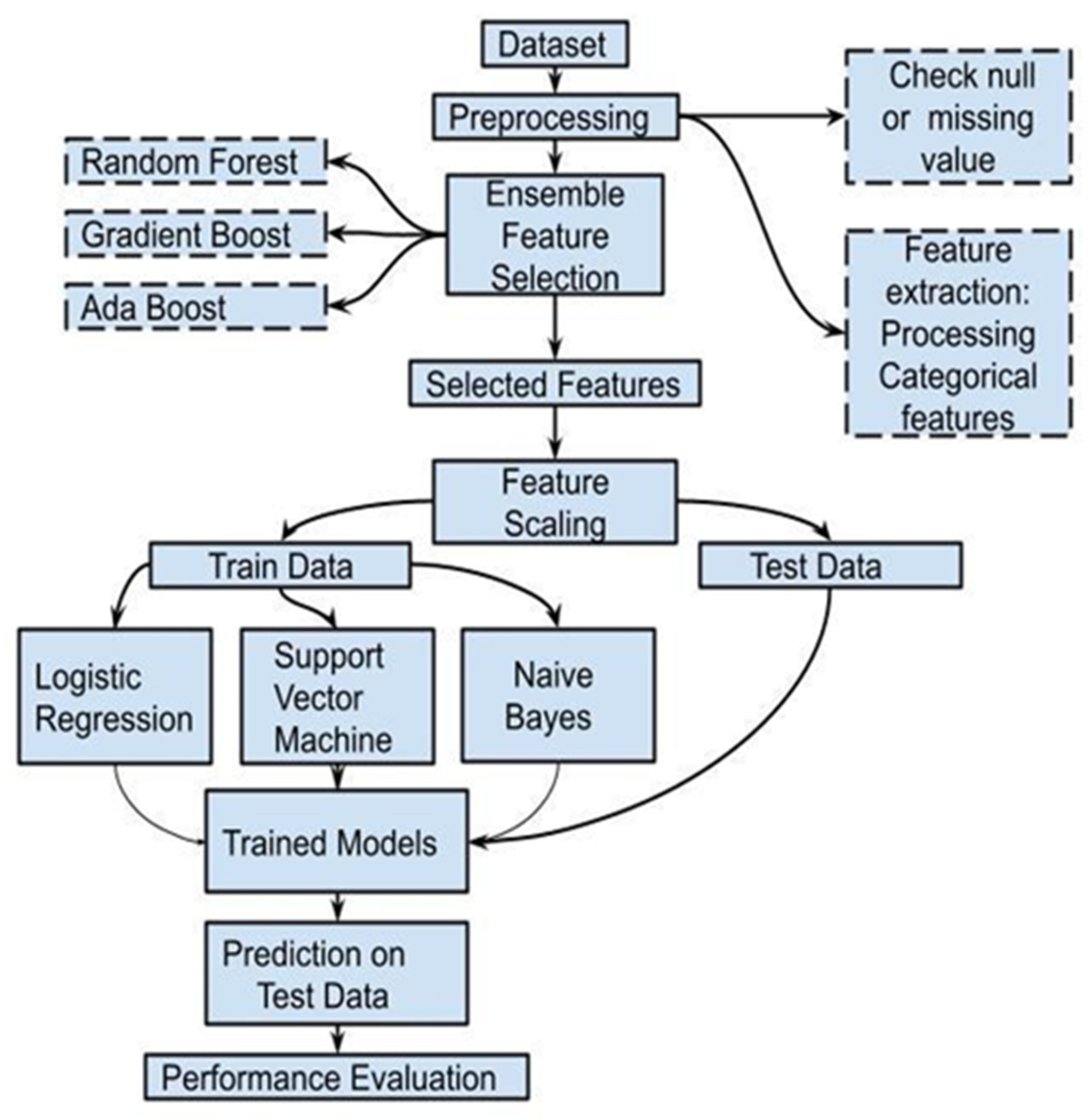
- Experiment with various ensemble feature selection techniques to identify the best set of features.
- Build a baseline model to set a benchmark for future studies.
- Analyse the performance of feature selection techniques based upon the time taken to select a particular set of features. This is particularly essential for building a low latency real-time system.
3. Materials and Methods
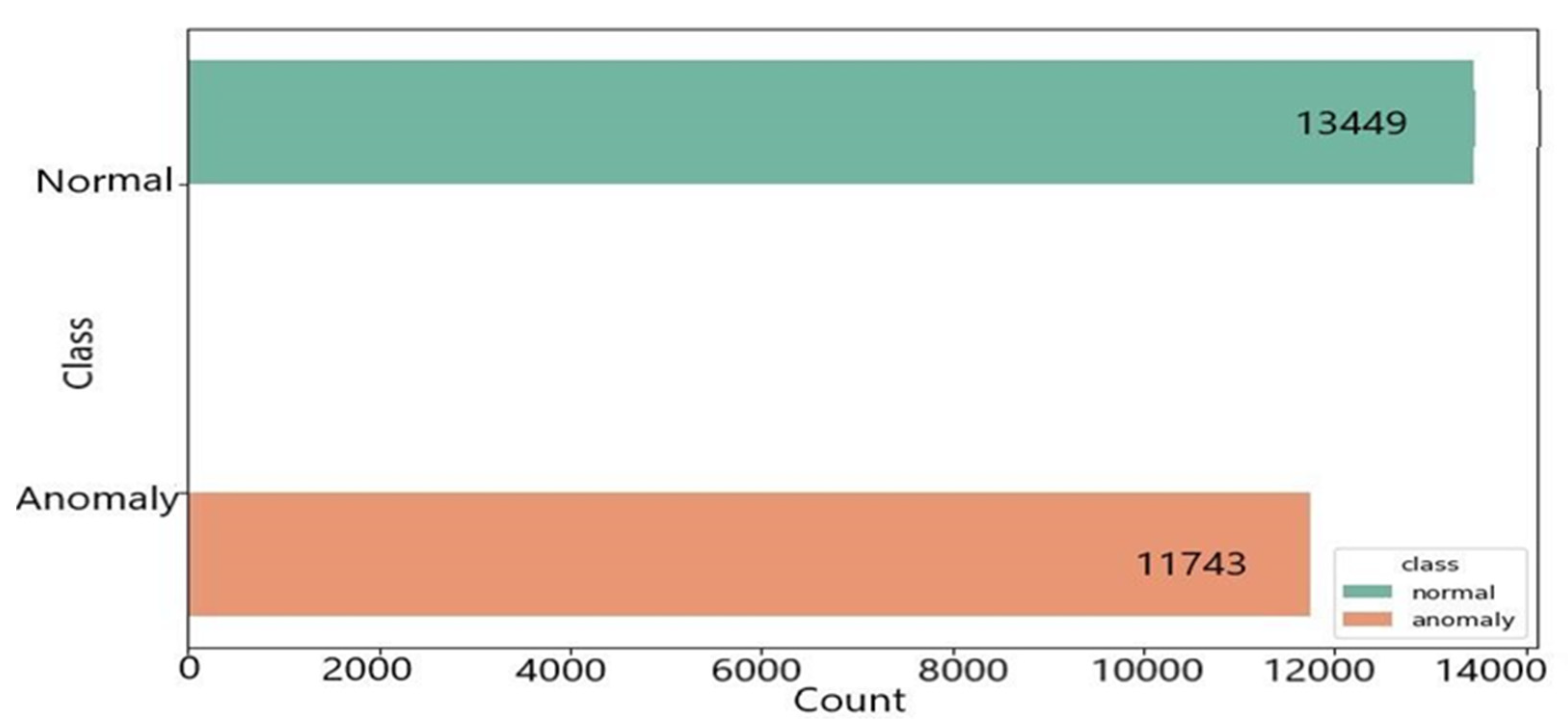
3.1. Used Dataset
3.2. Algorithms
3.2.1. Random Forest (RF)
3.2.2. Logistic Regression (LR)
3.2.3. Support Vector Machine (SVM)
3.3. Analysis Model
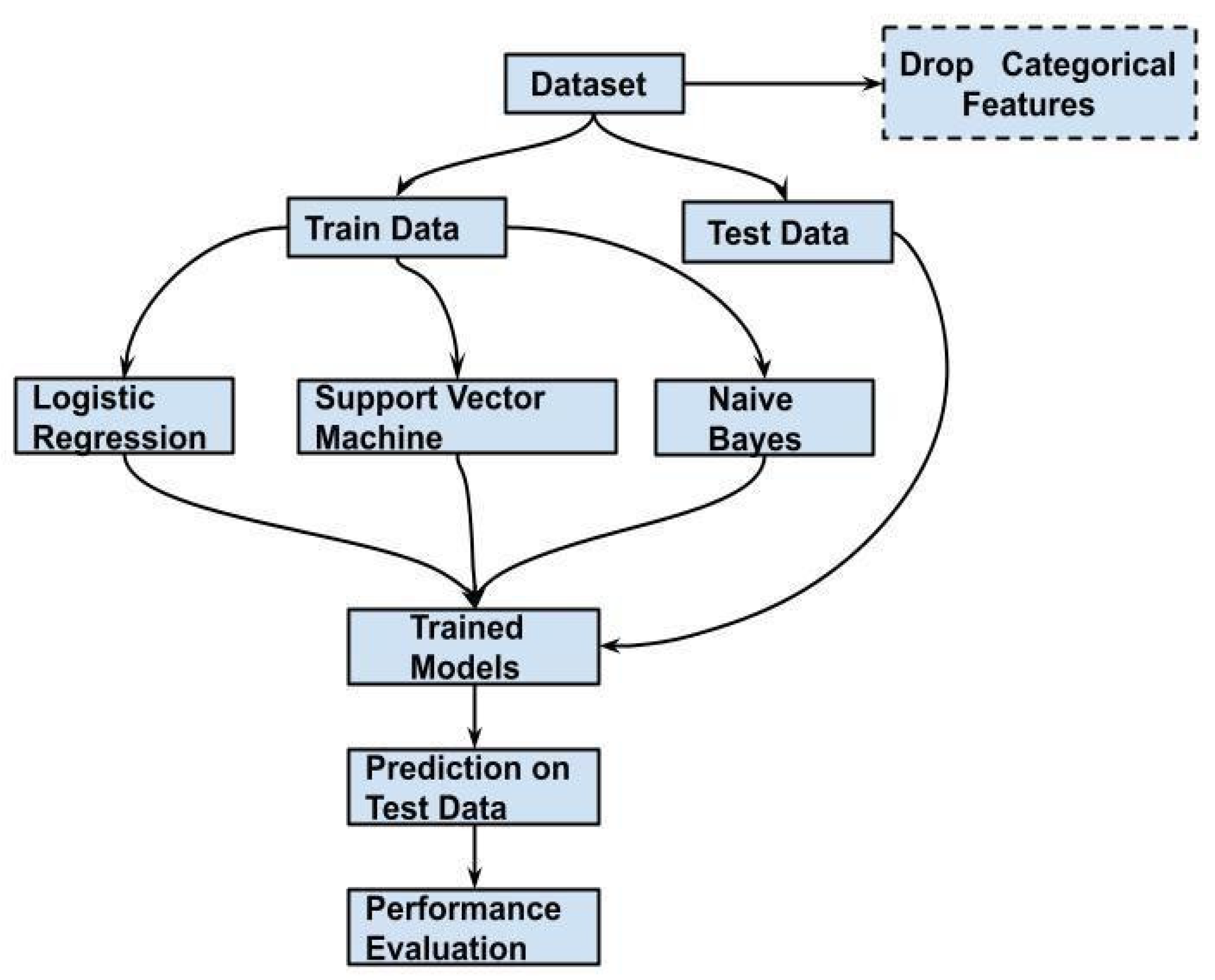
3.3.1. Baseline Model
3.3.2. Proposed Model
4. Results
- Elimination time: this describes the time taken by the ensemble algorithm to perform recursive feature elimination to get the set of most valuable features out of a total of 121 features available. This is largely important as a lower elimination time indicates a faster approach to identify the set of valuable features, but this metric alone does not provide conclusive evidence of the best technique to be used to build a robust intrusion detection system. Therefore, two other evaluation metrics, namely, accuracy and F1-score, were also used to identify the best model and comment on the accuracy and time trade-off of the models.
- Accuracy: for a binary classification problem, accuracy can be defined as the ratio of the sum of all true positives and true negatives to the sum of true positives, true negatives, false positive and false negative.
- F1-score: it is defined as the harmonic mean of precision and recall and is used to measure a test accuracy.
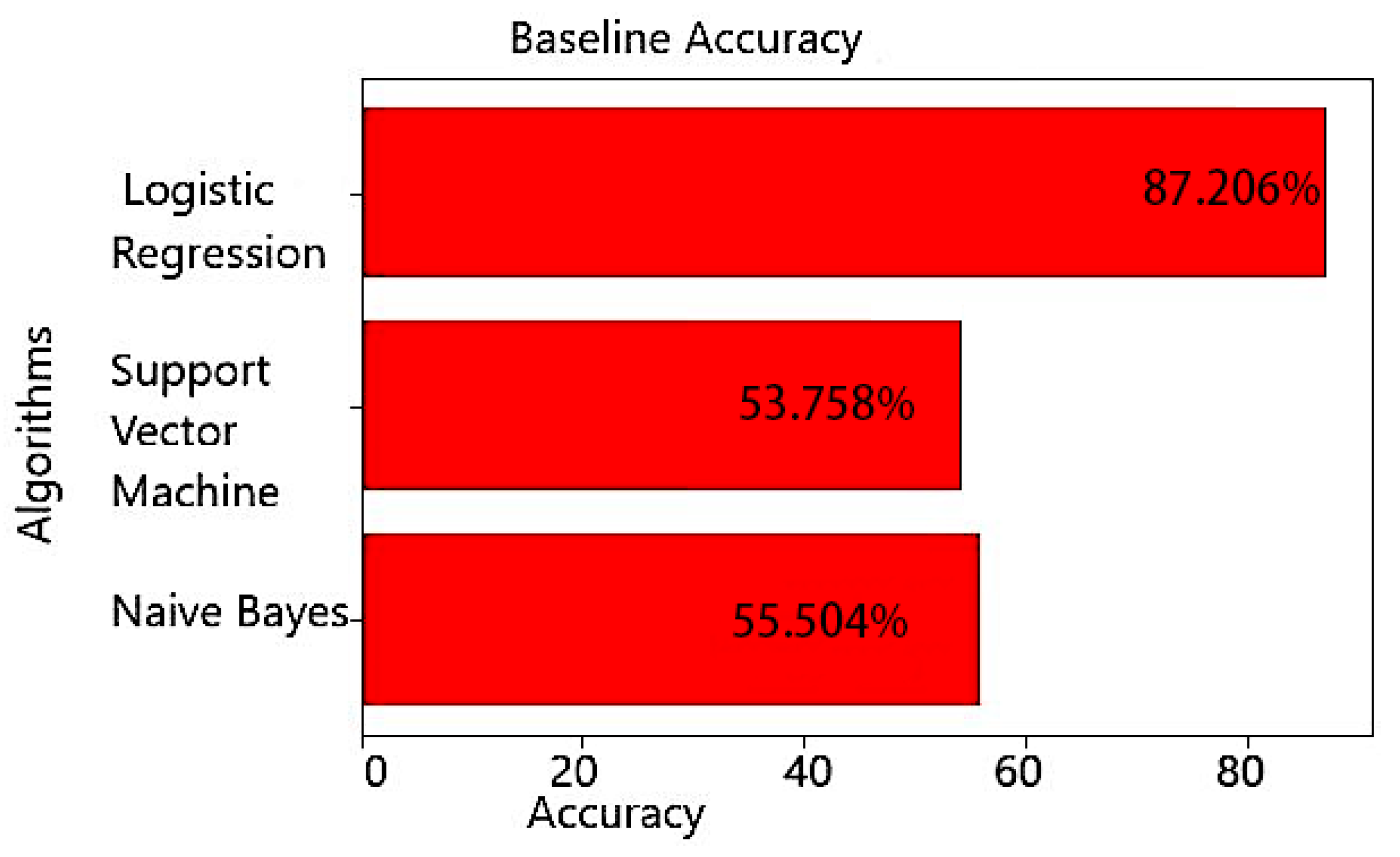
4.1. Evaluation of Baseline Model
4.2. Evaluation of 27 Feature Selected Model (Proposed)
4.3. Comparison of Optimal Feature Model with Baseline Model
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Internet Growth Statistics 1995 to 2021—The Global Village Online. Available online: https://www.internetworldstats.com/emarketing.htm (accessed on 13 September 2021).
- Nobakht, M.; Sivaraman, V.; Boreli, R. A host-based intrusion detection and mitigation framework for smart home iot using openflow. In Proceedings of the 2016 11th International Conference on Availability, Reliability and Security (ARES), Salzburg, Austria, 31 August–2 September 2016; IEEE: New York, NY, USA, 2016; pp. 147–156. [Google Scholar]
- Vailshery, L.S. Number of Connected Devices Worldwide 2030 (January 2021). Available online: https://www.statista.com/ (accessed on 16 September 2021).
- Perwej, Y.; Haq, K.; Parwej, F.; Mumdouh, M.; Hassan, M. The internet of things (iot) and its application domains. Int. J. Comput. Appl. 2019, 975, 182. [Google Scholar] [CrossRef]
- Theodoridis, E.; Mylonas, G.; Chatzigiannakis, I. Developing an iot smart city framework. In Proceedings of the IISA 2013, Piraeus, Greece, 10–12 July 2013; IEEE: New York, NY, USA, 2013; pp. 1–6. [Google Scholar]
- Liao, H.J.; Lin, C.H.R.; Lin, Y.C.; Tung, K.Y. Intrusion detection system: A comprehensive review. J. Netw. Comput. Appl. 2013, 36, 16–24. [Google Scholar] [CrossRef]
- Lastdrager, E.E. Achieving a consensual definition of phishing based on a systematic review of the literature. Crime Sci. 2014, 3, 9. [Google Scholar] [CrossRef]
- Zaharia, A. 300+ Terrifying Cybercrime & Cybersecurity Statistics [2021 Edition] (March 2021). Available online: https://www.comparitech.com (accessed on 16 September 2021).
- Phishing Activity Trends Reports. Available online: https://apwg.org/trendsreports/ (accessed on 18 September 2021).
- Netscout Threat Intelligence Report (April 2021). Available online: https://www.netscout.com/threatreport365 (accessed on 21 September 2021).
- Finkelhor, D.; Walsh, K.; Jones, L.; Mitchell, K.; Collier, A. Youth internet safety education: Aligning programs with the evidence base. Trauma Violence Abuse 2020, 22, 1233–1247. [Google Scholar] [CrossRef] [PubMed]
- Anand, A.; Patel, B. An overview on intrusion detection system and types of attacks it can detect considering different protocols. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2012, 2, 94–98. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Alkasassbeh, M.; Almseidin, M. Machine learning methods for network intrusion detection. arXiv 2018, arXiv:1809.02610. [Google Scholar]
- Choudhury, S.; Bhowal, A. Comparative analysis of machine learning algorithms along with classifiers for network intrusion detection. In Proceedings of the 2015 International Conference on Smart Technologies and Management for Computing, Communication, Controls, Energy and Materials (ICSTM), Chennai, India, 6–8 May 2015; IEEE: New York, NY, USA, 2015; pp. 89–95. [Google Scholar]
- Belouch, M.; El Hadaj, S.; Idhammad, M. Performance evaluation of in trusion detection based on machine learning using Apache Spark. Proc. Comput. Sci. 2018, 127, 1–6. [Google Scholar] [CrossRef]
- Koc, L.; Mazzuchi, T.A.; Sarkani, S. A network intrusion detection system based on a hidden naïve bayes multiclass classifier. Exp. Syst. Appl. 2012, 39, 13492–13500. [Google Scholar] [CrossRef]
- Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi, S.A.R.; Ghogho, M. Deep learning approach for network intrusion detection in software defined networking. In Proceedings of the 2016 International Conference on Wireless Networks and Mobile Communications (WINCOM), Reims, France, 27–29 October 2020; IEEE: New York, NY, USA, 2016; pp. 258–263. [Google Scholar]
- Prabakar, D.; Sasikala, S.; Saravanan, T.; Gomathi, S.; Ramesh, S. Enhanced simulating an nealing and svm for intrusion detection system in wireless sensor networks. Res. Sq. 2021. [Google Scholar] [CrossRef]
- Rajagopal, S.; Kundapur, P.P.; Hareesha, K.S. A stacking ensemble for network intrusion detection using heterogeneous datasets. Secur. Commun. Netw. 2020, 2020, 4586875. [Google Scholar] [CrossRef] [Green Version]
- Ambwani, T. Multi class support vector machine implementation to intru395 sion detection. In Proceedings of the IEEE International Joint Conference on Neural Networks, Portland, OR, USA, 20–24 July 2003; Volume 3, pp. 2300–2305. [Google Scholar]
- Bhosale, S. Network Intrusion Detection (October 2018). Available online: https://www.kaggle.com/sampadab17 (accessed on 19 July 2021).
- Sperandei, S. Understanding logistic regression analysis. Biochem. Med. 2014, 24, 12–18. [Google Scholar] [CrossRef] [PubMed]
- Cox, D.R. The regression analysis of binary sequences. J. R. Stat. Soc. Ser. B 1958, 20, 215–232. [Google Scholar] [CrossRef]
- Vapnik, V. Pattern recognition using generalized portrait method. Automat. Remote Control 1963, 24, 774–780. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Sharma, U.; Tomar, P.; Ali, S.S.; Saxena, N.; Bhadoria, R.S. Optimized authentication system with high security and privacy. Electronics 2021, 10, 458. [Google Scholar] [CrossRef]
- Swarnkar, M.; Bhadoria, R.S.; Sharma, N. Security, privacy, trust management and performance optimization of blockchain technology. In Applications of Blockchain in Healthcare; Springer: Singapore, 2021; pp. 69–92. [Google Scholar]
- Sharma, P.; Borah, M.D.; Namasudra, S. Improving security of medical big data by using Blockchain technology. Comput. Electr. Eng. 2021, 96, 107529. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Accuracy | F1-Score |
|---|---|---|
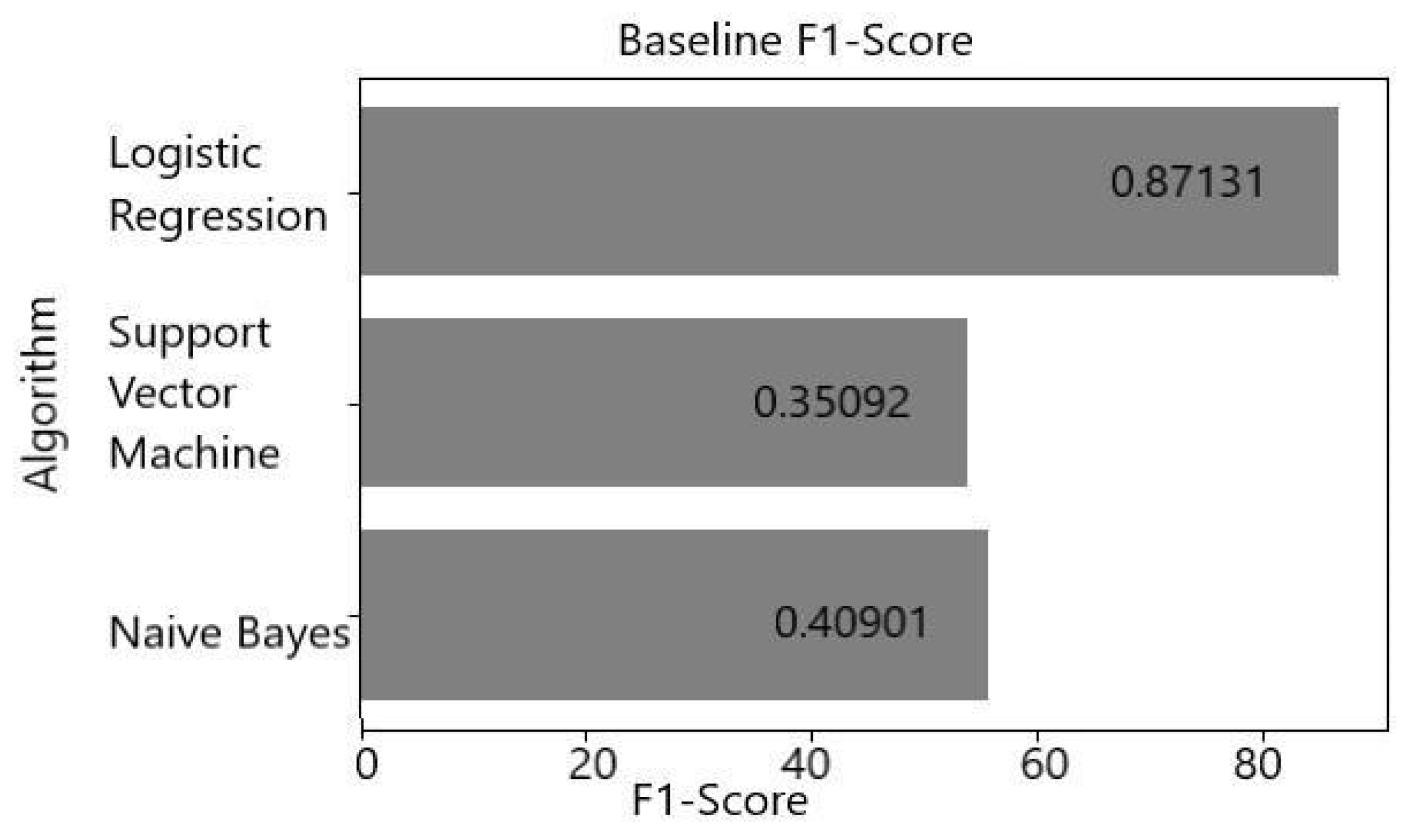
| Logistic regression | 87.206% | 0.87131 |
| Support vector machine | 53.758% | 0.35092 |
| Naive Bayes | 55.504% | 0.40901 |
| No. of Features Selected | Random Forest | Gradient Boost | Ada Boost |
|---|---|---|---|
| 60 | 21.009 s | 133.8944 s | 158.044 s |
| 30 | 30.4625 s | 183.720 s | 222.788 s |
| 20 | 36.819 s | 190.019 s | 234.9901 s |
| Algorithm | % Accuracy Using 60 Features | % Accuracy Using 30 Features | % Accuracy Using 20 Features | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RF | GB | AB | RF | GB | AB | RF | GB | AB | |
| LR | 97.04 | 97.02 | 97.01 | 96.77 | 96.69 | 96.77 | 94.09 | 95.58 | 96.53 |
| SVM | 98.86 | 98.86 | 98.87 | 99.08 | 99.06 | 98.94 | 98.43 | 98.77 | 98.58 |
| NB | 86.96 | 87.90 | 88.09 | 93.39 | 94.58 | 91.73 | 93.06 | 94.39 | 91.90 |
| Algorithm | F1-Score Using 60 Features | F1-Score Using 30 Features | F1-Score Using 20 Features | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RF | GB | AB | RF | GB | AB | RF | GB | AB | |
| LR | 0.9703 | 0.9700 | 0.9699 | 0.9675 | 0.9667 | 0.9675 | 0.9406 | 0.9552 | 0.9651 |
| SVM | 0.9885 | 0.9885 | 0.9886 | 0.9908 | 0.9905 | 0.9893 | 0.9843 | 0.9876 | 0.9857 |
| NB | 0.8645 | 0.8747 | 0.8767 | 0.9338 | 0.9454 | 0.9172 | 0.9304 | 0.9434 | 0.9189 |
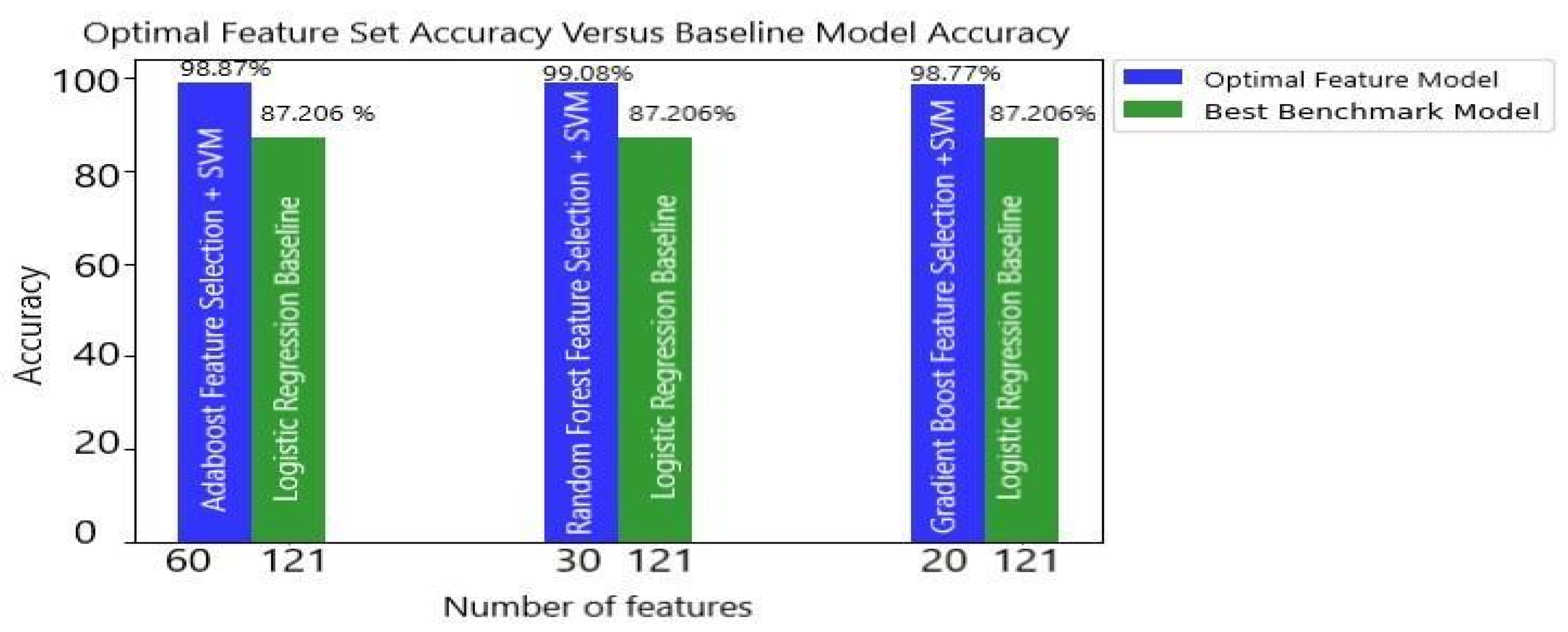
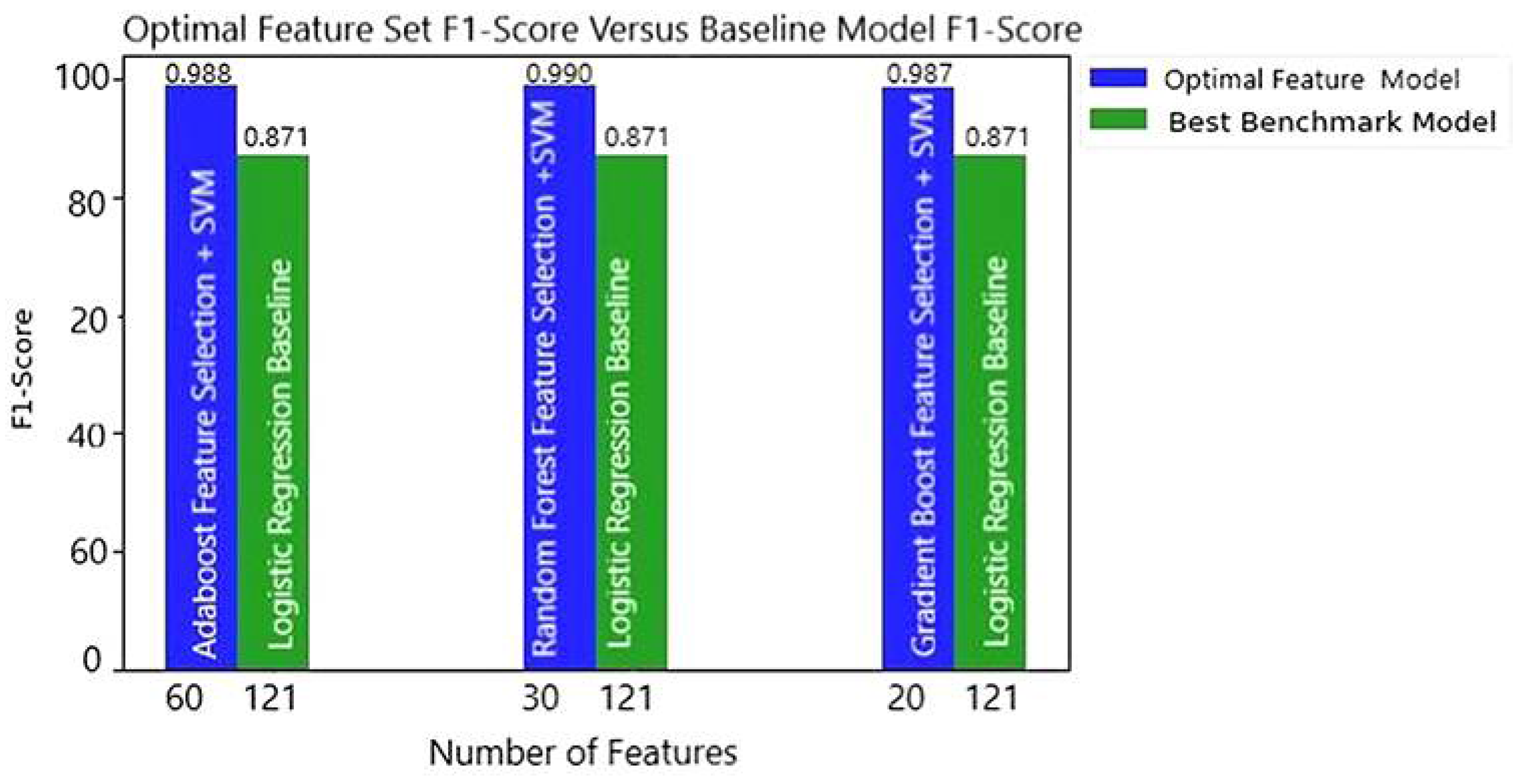
| Model | (%) Accuracy | F1-Score | Accuracy Increment | F1-Score Increment | Features Used (%) |
|---|---|---|---|---|---|
| LR Baseline (121 Features) | 87.20 | 0.871 | - | - | - |
| AB + SVM (60 Features) | 98.87 | 0.988 | 11.664 | 0.117 | 49.58 |
| RF + SVM (30 Features) | 99.08 | 0.990 | 11.874 | 0.119 | 24.79 |
| GB + SVM (20 Features) | 98.77 | 0.987 | 11.564 | 0.116 | 16.52 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhadoria, R.S.; Bhoj, N.; Zaini, H.G.; Bisht, V.; Nezami, M.M.; Althobaiti, A.; Ghoneim, S.S.M. Artificial Intelligence for Creating Low Latency and Predictive Intrusion Detection with Security Enhancement in Power Systems. Appl. Sci. 2021, 11, 11988. https://doi.org/10.3390/app112411988
Bhadoria RS, Bhoj N, Zaini HG, Bisht V, Nezami MM, Althobaiti A, Ghoneim SSM. Artificial Intelligence for Creating Low Latency and Predictive Intrusion Detection with Security Enhancement in Power Systems. Applied Sciences. 2021; 11(24):11988. https://doi.org/10.3390/app112411988
Chicago/Turabian StyleBhadoria, Robin Singh, Naman Bhoj, Hatim G. Zaini, Vivek Bisht, Md. Manzar Nezami, Ahmed Althobaiti, and Sherif S. M. Ghoneim. 2021. "Artificial Intelligence for Creating Low Latency and Predictive Intrusion Detection with Security Enhancement in Power Systems" Applied Sciences 11, no. 24: 11988. https://doi.org/10.3390/app112411988
APA StyleBhadoria, R. S., Bhoj, N., Zaini, H. G., Bisht, V., Nezami, M. M., Althobaiti, A., & Ghoneim, S. S. M. (2021). Artificial Intelligence for Creating Low Latency and Predictive Intrusion Detection with Security Enhancement in Power Systems. Applied Sciences, 11(24), 11988. https://doi.org/10.3390/app112411988