
Event Monitoring and Intelligence Gathering Using Twitter Based Real-Time Event Summarization and Pre-Trained Model Techniques


Abstract
:1. Introduction
- In a high-impact event, people may want to learn the latest information as the event develops. It is necessary to develop an effective real-time event summary system to obtain sufficient real-time intelligence information for effective decision-making.
- In order to acquire extensive coverage of event details, using pre-trained language models can help us expand more knowledge and trending topics about how event stories develop. The benefit of this potential for event awareness deserves in-depth study.
2. Related Work
3. Models and Methods
3.1. System Framework
3.2. Proposed Approach for Collectively Summurizing Text Streams
| Algorithm 1 1st Pass real-time event detection |
| INPUT: TS{1, 2, …, m} // Twitter Streams OUTPUT: RTED{1, 2, …, ε}; //Real-Time Event Detection 1: Begin 2: for each TS{i} 3: BursT ← Dynamic Term Weighting(i) 4: RTED ← Self-Adaptive Stream Clustering(BursT, i) 5: end for 6: End |
| Algorithm 2 Self-adaptive stream clustering |
| INPUT: MS{1, 2, …, m} // Message Streams OUTPUT: RTEC{1, 2, …, ε}; HEC{1, 2, …, n} //Real-Time Event Cluster 1: Begin 2: for each MS{i} 3: for each RTEC{j} 4: if(d(‧) – Θ < 0) then 5: add RTEC{j} into HEC and revom RTEC{j}; 6: else 7: simOfMS&RTEC ← sim(MS{i}, RTEC{j})*d(·); 8: if(simOfMS&RTEC > maxSimOfMS&RTEC) then 9: maxSimOfMS&RTEC ← simOfMS&RTEC; 10: idOfMaxC ← j; 11: else continue; 12: end for 13: if(maxSimOfMS&RTEC < Θ) then 14: create a new RTEC for MS{i}; 15: else 16: merge MS{i} to RTEC{idOfMaxC}; 17: end for 18: until no messages is posted |
| Algorithm 3 2nd Pass event-message accumulation & summarization |
| INPUT: TM{1, 2, …, n} // Text Message OUTPUT: HT{1, 2, …, ε}; HTS{1, 2, …, m}; EHT{1, 2, …, k} // Hot Topic 1: Begin 2: for each TM{i} 3: Text ← BERT Classifier Model(TM{i}) 4: Sentence Embedding ← Sentence-BERT Model(Text) 5: HT ← DBSCAN(Sentence Embedding) 6: for each HT{j} 7: HTS ← T5 Text Summarization Model(j) 8: end for 9: end for 10: End |
4. Proposed Pre-Trained Language Models for Text Summarization
4.1. Bert Model and Sentence-BERT Model
4.2. T5 (Text-to-Text Transfer Transformer) Model
4.3. Developed Text Summarization Method Using a Hybrid Pre-Trained Model System
4.4. Evaluation Method for Text Summarization
5. Experiment and Case Study
5.1. Experiment and Performance Comparison
5.2. Xsum and Tweet Data Sets for Fine-Turning and Downstream Task
5.3. Detected Hot Topics with Twitter Data
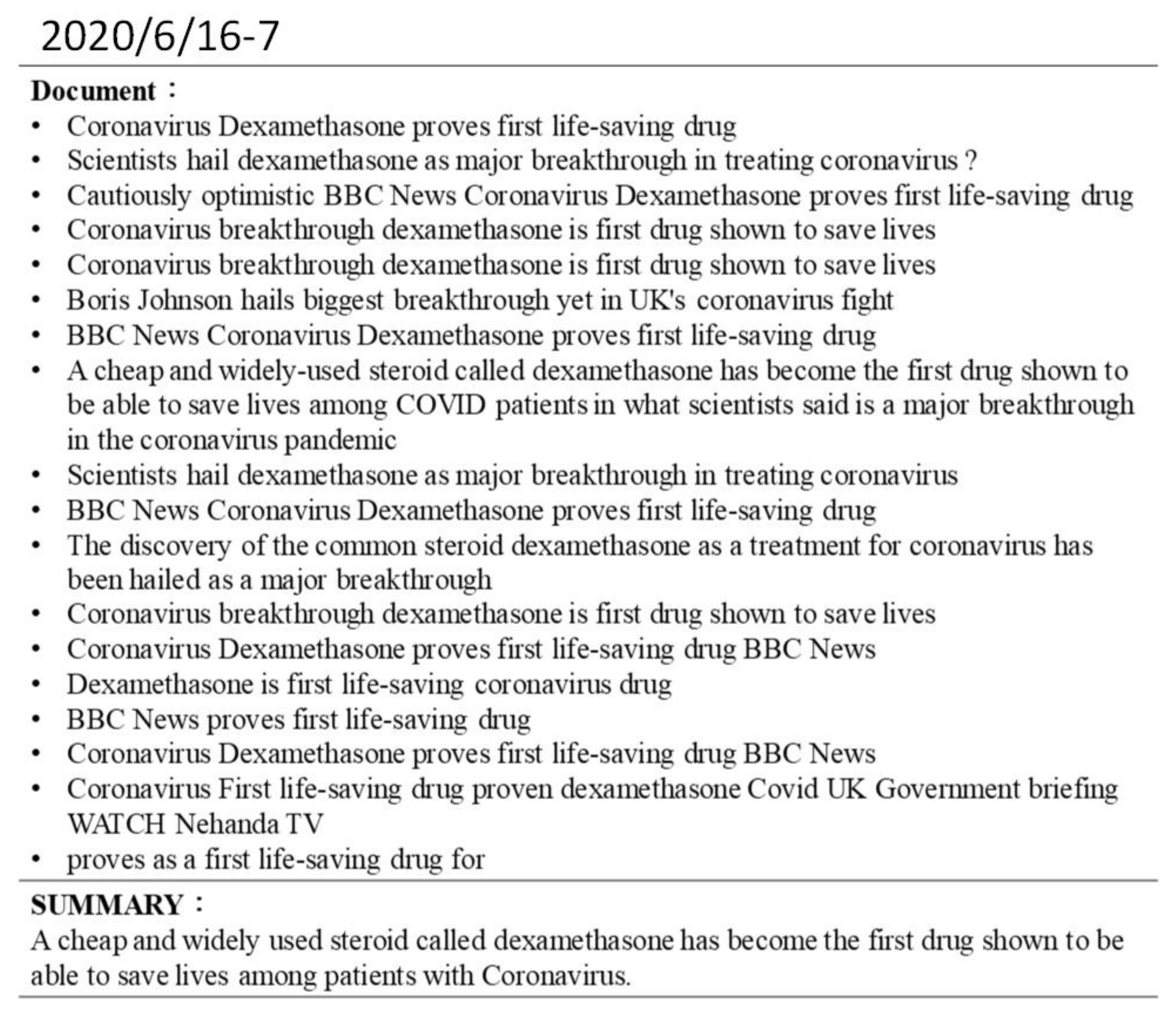
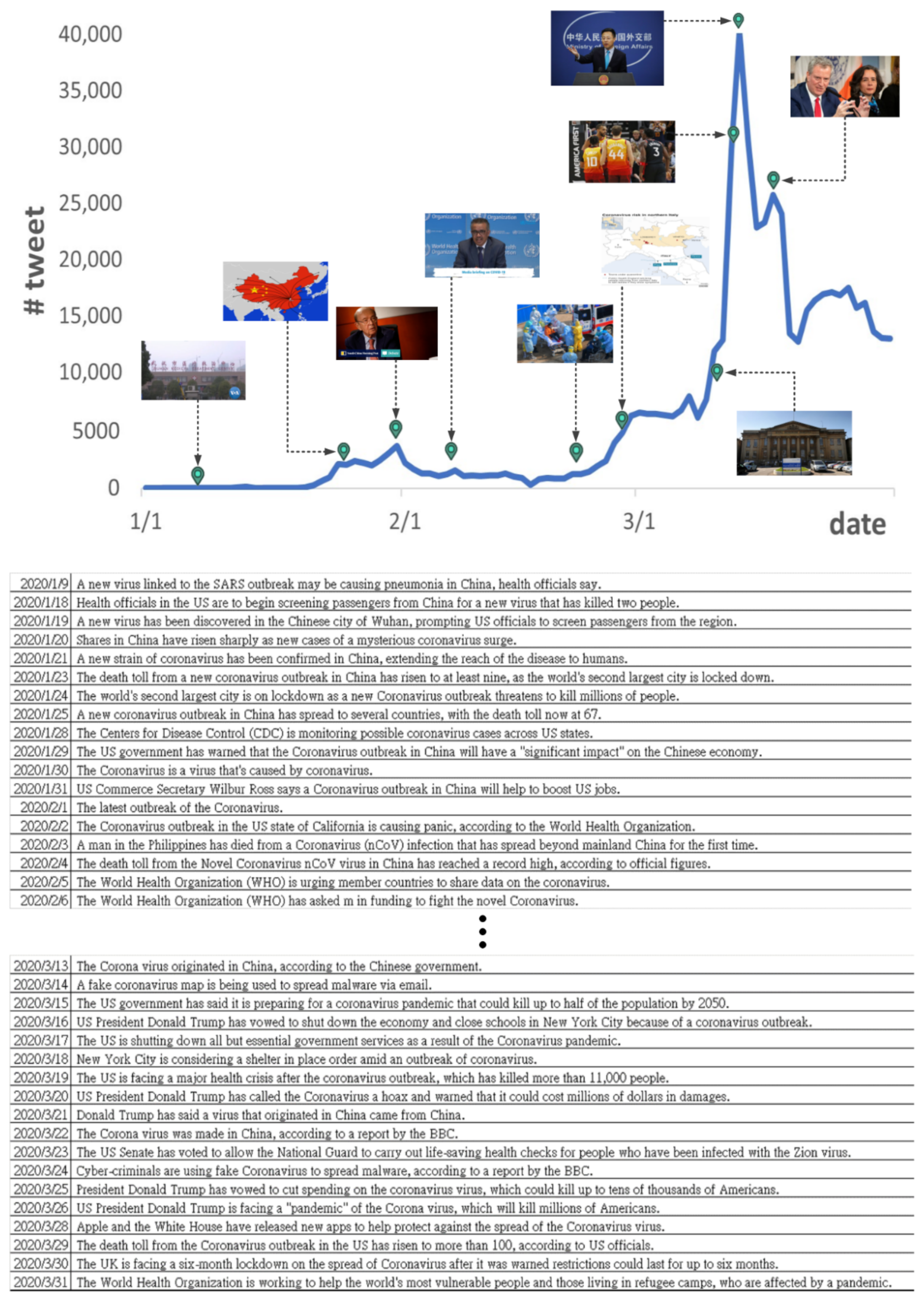
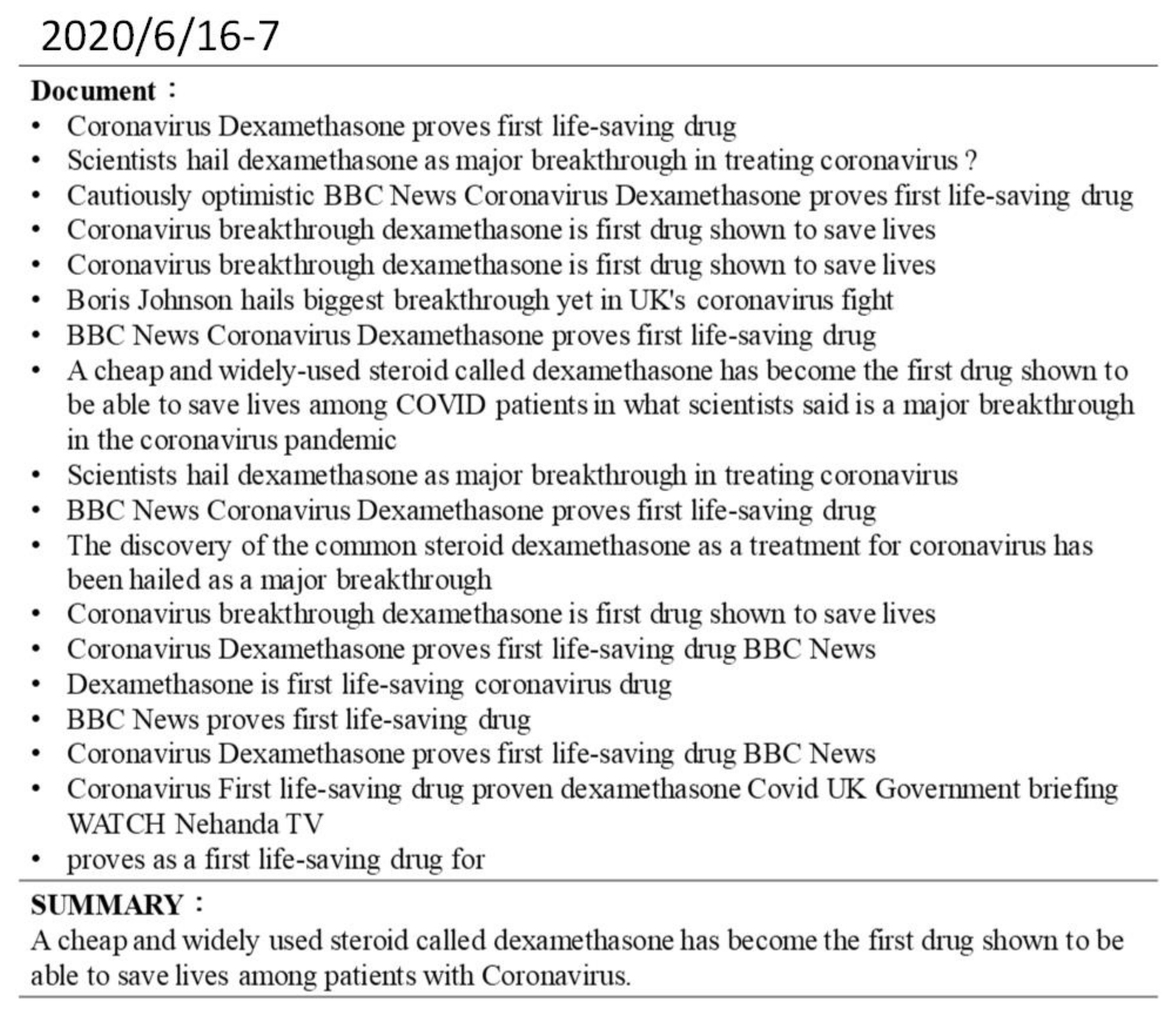
5.4. Case Study:Tweet Summary of the “COVID-19 Pandemic” Event
5.5. Human Evaluation for Quality Assessment of Generated Summaries
6. Discussion
- (1)
- The T5 model is trained in an end-to-end and text-to-text manner, with text as input and summary text as output. In this work, we demonstrated that T5 has achieved state-of-the-art results in many NLP benchmarks and can be fine-tuned to perform automatic summarization tasks well.
- (2)
- As mentioned earlier, due to the real-time nature of social media, an automatic event summary system using Twitter data was developed in this work to provide people with an updated summary of the event while the situation is still evolving. However, it is worth mentioning that the “real-time” here means that the summary system can expand or update the summary at any point in time, rather than real-time computing.
- (3)
- Going further, “real-time event summarization” is different from “real-time event detection” methods. The summarization system we developed can summarize the continuously accumulated hot topic tweets into a short sentence, instead of just performing real-time event detection. Compared to real-time event detection methods, detected events on Twitter are often short-term. The summary generated by our system can represent a simplified version of the event tweet message of interest, starting at any point in time of the ongoing event.
- (4)
- Generally speaking, abstractive summarization models are prone to produce grammatically correct incoherent sentences. In the work of summarizing text, it is easy for human researchers to make language errors. The advantages of using abstractive summarization models enable us to alleviate some of the grammatical problems of real people. Despite the results of the system evaluation show that the summaries we got are not perfect in terms of grammatical fluency, the results are acceptable and close to the performance of human researchers in the real world.
- (5)
- Although this developed model can quickly summarize the text, it still has certain limitations in generality. The social media data used in this study only uses English data on Twitter to generate summaries. Although English is the common language of most people in the world, it must be only through English to understand the various events in the world, there are still some prejudices. In the future, we consider using multilingual models and multilingual data sets (made by different native speakers) to train the model so that we can more accurately grasp various world events from different perspectives.
- (6)
- In this work, we implemented a method of generating storylines using the automatic summarization technique we developed. The generated storyline is composed of sub-events or key events related to a given major event. The sub-events show the status of the main event in progress. Automated storyline generation has been a research issue since nearly the inception of artificial intelligence. In particular, the storylines of events relate to identify entities and summarize events that leads to the event of interest. However, the proposed system model has not yet performed the full function of the “automated storyline generation” paradigm for understanding event development. This is because in this work, we have not provided methods for analyzing the evolution of specific event entities and exploring the entities and their relationships in event stories. We will leave the work of constructing event storyline for future work to complete.
7. Conclusions
- We implemented an end-to-end and text-to-text summarization system model, in which text streams as input and summary text as output.
- Our system model combined a real-time event summarization system and a self-adaptive Twitter-based event detection method. The developed summarization system can summarize the continuously accumulated hot topic tweets into a short sentence, instead of just performing real-time event detection.
- The developed system used pre-trained language models to help users obtain more knowledge and trending topics about how event stories develop.
- The system can support users to obtain sufficient real-time intelligence information in specific events to make effective decisions.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Examples of Generated Storyline Related to COVID-19 Pandemic
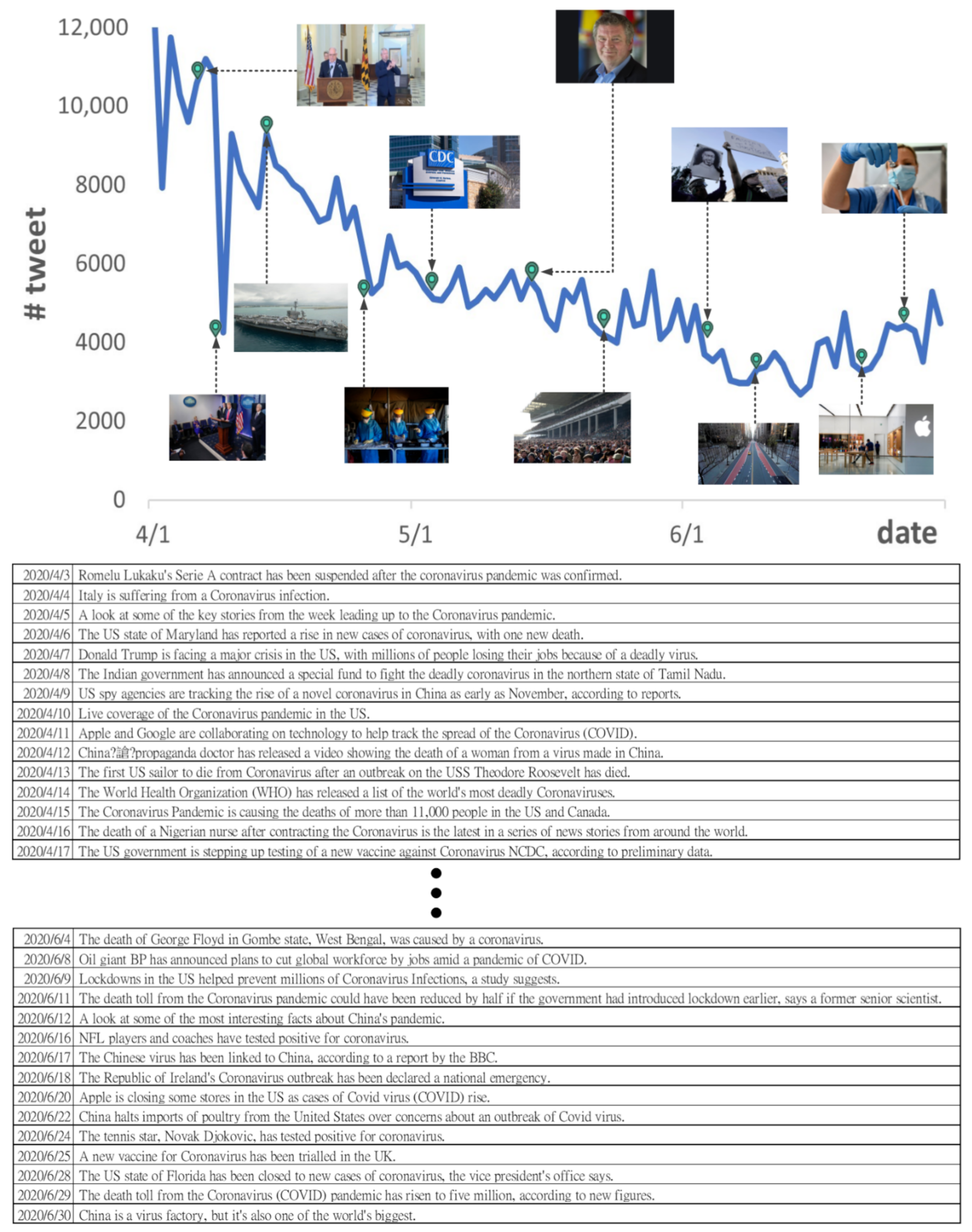
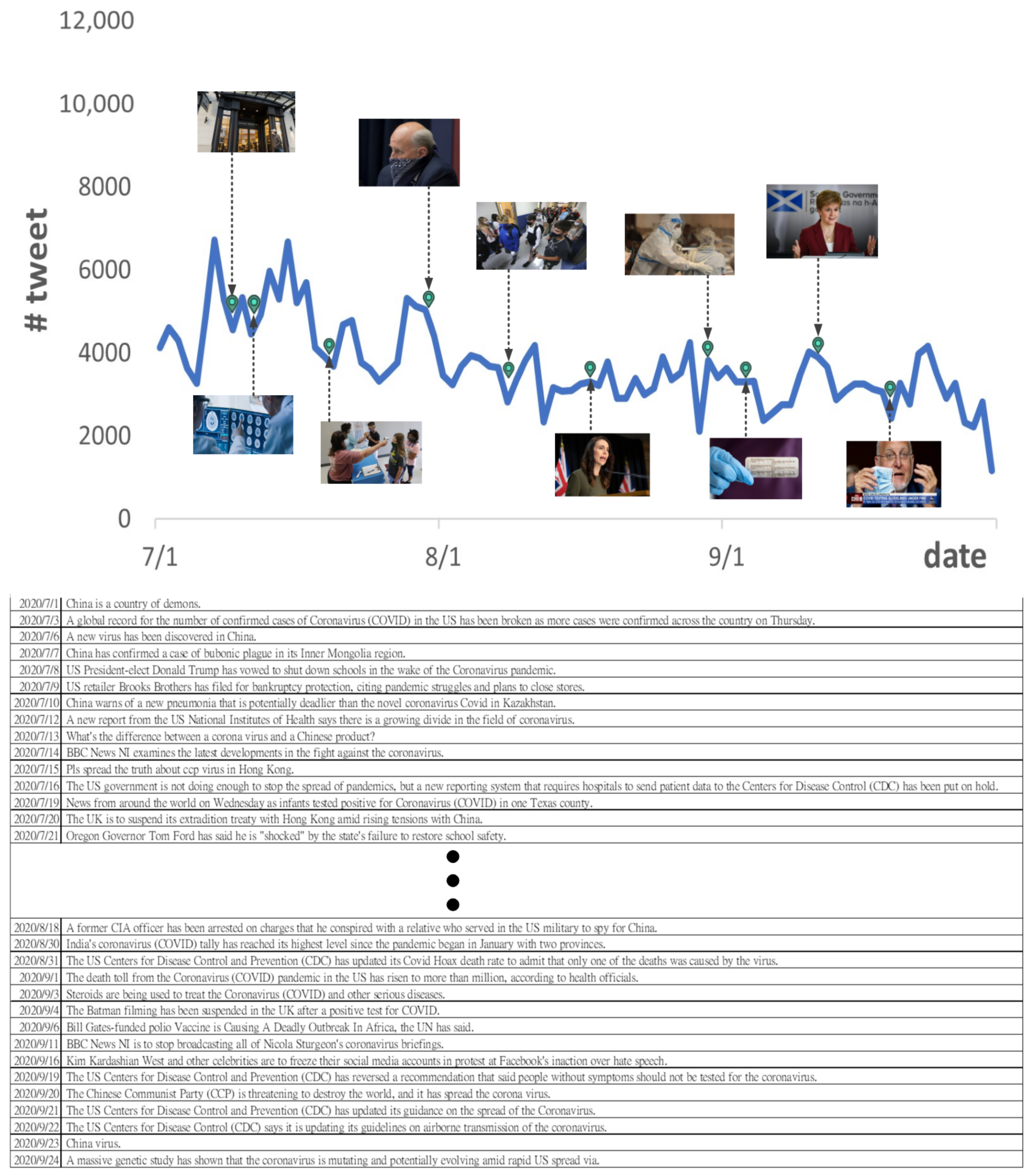

Appendix B. Example Model Outputs: Tweet Summaries of the “COVID-19 Pandemic” Sub-Events







References
- Rudrapal, D.; Das, A.; Bhattacharya, B. A survey on automatic Twitter event summarization. J. Inf. Process. Syst. 2018, 14, 79–100. [Google Scholar]
- Chakrabarti, D.; Punera, K. Event summarization using tweets. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011; Volume 5. [Google Scholar]
- Chua, F.C.T.; Asur, S. Automatic summarization of events from social media. In Proceedings of the Seventh International AAAI Conference on Weblogs and Social Media, Cambridge, MA, USA, 8–11 July 2013. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar]
- Lee, C.-H. Mining spatio-temporal information on microblogging streams using a density-based online clustering method. Expert Syst. Appl. 2012, 39, 9623–9641. [Google Scholar] [CrossRef]
- Lee, C.-H.; Chien, T.-F. Leveraging microblogging big data with a modified density-based clustering approach for event awareness and topic ranking. J. Inf. Sci. 2013, 39, 523–543. [Google Scholar] [CrossRef]
- Sharifi, B.; Hutton, M.A.; Kalita, J. Summarizing microblogs automatically. In Proceedings of the 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; pp. 685–688. [Google Scholar]
- Inouye, D.; Kalita, J.K. Comparing Twitter Summarization Algorithms for Multiple Post Summaries. In Proceedings of the 2011 IEEE Third Int’l Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing, Boston, MA, USA, 9–11 October 2011; pp. 298–306. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Rachabathuni, P.K. A survey on abstractive summarization techniques. In Proceedings of the 2017 International Conference on Inventive Computing and Informatics (ICICI), Coimbatore, India, 23–24 November 2017; pp. 762–765. [Google Scholar]
- Gambhir, M.; Gupta, V. Recent automatic text summarization techniques: A survey. Artif. Intell. Rev. 2017, 47, 1–66. [Google Scholar] [CrossRef]
- Neto, J.L.; Freitas, A.A.; Kaestner, C.A.A. Automatic Text Summarization Using a Machine Learning Approach. In Proceedings of the 16th Brazilian Symposium on Artificial Intelligence, Porto de Galinhas/Recife, Brazil, 11–14 November 2002; pp. 205–215. [Google Scholar]
- Tas, O.; Kiyani, F. A survey automatic text summarization. J. PressAcademia Procedia 2017, 5, 205–213. [Google Scholar] [CrossRef]
- Radev, D.R.; Allison, T.; Blair-Goldensohn, S.; Blitzer, J.; Celebi, A.; Dimitrov, S.; Drabeck, E.; Hakim, A.; Lam, W.; Liu, D.; et al. MEAD-a platform for multidocument multilingual text summarization. In Proceedings of the Fourth International Conference on Language Resources and Evaluation (LREC’04), Lisbon, Portugal, 26–28 May 2004; pp. 699–702. [Google Scholar]
- Nenkova, A.; Vanderwende, L.; McKeown, K. A compositional context sensitive multi-document summarizer: Exploring the factors that influence summarization. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 6–11 August 2006; pp. 573–580. [Google Scholar]
- Filatova, E.; Hatzivassiloglou, V. Event-based extractive summarization. In Proceedings of the ACL-04 Workshop, Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; pp. 104–111. [Google Scholar]
- Moratanch, N.; Chitrakala, S. A survey on extractive text summarization. In Proceedings of the 2017 International Conference on Computer, Communication and Signal Processing (ICCCSP), Chennai, India, 10–11 January 2017; pp. 1–6. [Google Scholar]
- Mutlu, B.; Sezer, E.A.; Akcayol, M.A. Multi-document extractive text summarization: A comparative assessment on features. J. Knowl.-Based Syst. 2019, 183, 104848. [Google Scholar] [CrossRef]
- Kupiec, J.; Pedersen, J.; Chen, F. A trainable document summarizer. In Proceedings of the 18th Annual International ACM SIGIR conference on Research and Development in Information Retrieval–SIGIR ’95, Seattle, WA, USA, 9–13 July 1995; pp. 68–73. [Google Scholar]
- Conroy, J.M.; O’Leary, D.P. Text summarization via hidden Markov models. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval—SIGIR ’01, New Orleans, LA, USA, 9–13 September 2001; pp. 406–407. [Google Scholar]
- Woodsend, K.; Lapata, M. Automatic generation of story highlights. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 565–574. [Google Scholar]
- Isonuma, M.; Fujino, T.; Mori, J.; Matsuo, Y.; Sakata, I. Extractive Summarization Using Multi-Task Learning with Document Classification. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2101–2110. [Google Scholar]
- Nallapati, R.; Zhai, F.; Zhou, B. Summarunner: A recurrent neural network based sequence model for extractive summarization of documents. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Gunawan, D.; Pasaribu, A.; Rahmat, R.F.; Budiarto, R. Automatic Text Summarization for Indonesian Language Using TextTeaser. In IOP Conference Series: Materials Science and Engineering; IOP Publishing Ltd.: Semarang, Indonesia, 2016; Volume 190, p. 012048. [Google Scholar]
- Narayan, S.; Cohen, S.B.; Lapata, M. Ranking Sentences for Extractive Summarization with Reinforcement Learning. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 1747–1759. [Google Scholar]
- Dong, Y.; Shen, Y.; Crawford, E.; Van Hoof, H.; Cheung, J.C.K. BanditSum: Extractive Summarization as a Contextual Bandit. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3739–3748. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A Neural Attention Model for Abstractive Sentence Summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 379–389. [Google Scholar]
- Chopra, S.; Auli, M.; Rush, A.M. Abstractive Sentence Summarization with Attentive Recurrent Neural Networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 93–98. [Google Scholar]
- Song, S.; Huang, H.; Ruan, T. Abstractive text summarization using LSTM-CNN based deep learning. J. Multimed. Tools Appl. 2018, 78, 857–875. [Google Scholar] [CrossRef]
- Paulus, R.; Xiong, C.; Socher, R. A deep reinforced model for abstractive summarization. arXiv 2017, arXiv:1705.04304. [Google Scholar]
- Chen, Y.-C.; Bansal, M. Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 675–686. [Google Scholar]
- Masum, A.K.M.; Abujar, S.; Talukder, A.I.; Rabby, A.S.A.; Hossain, S.A. Abstractive method of text summarization with sequence to sequence RNNs. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–5. [Google Scholar]
- Cai, T.; Shen, M.; Peng, H.; Jiang, L.; Dai, Q. Improving Transformer with Sequential Context Representations for Abstractive Text Summarization. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Dunhuang, China, 9–14 October 2019; pp. 512–524. [Google Scholar]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. J. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Liu, Y.; Lapata, M. Text Summarization with Pretrained Encoders. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3721–3731. [Google Scholar]
- Kieuvongngam, V.; Tan, B.; Niu, Y. Automatic text summarization of Covid-19 medical research articles using bert and gpt-2. arXiv 2020, arXiv:2006.01997. [Google Scholar]
- Khandelwal, U.; Clark, K.; Jurafsky, D.; Kaiser, L. Sample efficient text summarization using a single pre-trained transformer. arXiv 2019, arXiv:1905.08836. [Google Scholar]
- Zhang, X.; Wei, F.; Zhou, M. HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5059–5069. [Google Scholar]
- Farahani, M.; Gharachorloo, M.; Manthouri, M. Leveraging ParsBERT and Pretrained mT5 for Persian Abstractive Text Summarization. In Proceedings of the 2021 26th International Computer Conference, Computer Society of Iran (CSICC), Tehran, Iran, 3–4 March 2021; pp. 1–6. [Google Scholar]
- Ma, T.; Pan, Q.; Rong, H.; Qian, Y.; Tian, Y.; Al-Nabhan, N. T-BERTSum: Topic-Aware Text Summarization Based on BERT. J. IEEE Trans. Comput. Social Syst. 2021, 1–12. [Google Scholar] [CrossRef]
- Kerui, Z.; Haichao, H.; Yuxia, L.; Zhang Kerui Lazada Group, China; Hu Haichao SF Technology, Shenzhen China; Liu Yuxia SF Technology, Shenzhen China. Automatic Text Summarization on Social Media. In Proceedings of the 2020 4th International Symposium on Computer Science and Intelligent Control, Newcastle upon Tyne, UK, 17–19 November 2020; pp. 1–5. [Google Scholar]
- Garg, A.; Adusumilli, S.; Yenneti, S.; Badal, T.; Garg, D.; Pandey, V.; Nigam, A.; Gupta, Y.K.; Mittal, G.; Agarwal, R. NEWS Article Summarization with Pretrained Transformer. In Communications in Computer and Information Science, Proceedings of the Advanced Computing, IACC 2020, Panaji, Goa, India, 5–6 December 2020; Springer: Singapore, 2020; pp. 203–211. [Google Scholar] [CrossRef]
- Daiya, D. Combining Temporal Event Relations and Pre-Trained Language Models for Text Summarization. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 14–17 December 2020; pp. 641–646. [Google Scholar]
- Fecht, P.; Blank, S.; Zorn, H.P. Sequential Transfer Learning in NLP for German Text Summarization. In Proceedings of the 4th edition of the Swiss Text Analytics Conference, Winterthur, Switzerland, 18–19 June 2019. [Google Scholar]
- Narayan, S.; Cohen, S.B.; Lapata, M. Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1797–1807. [Google Scholar]
- Lee, C.-H.; Wu, C.-H.; Chien, T.-F. BursT: A Dynamic Term Weighting Scheme for Mining Microblogging Messages. J. Int. Symp. Neural Netw. 2011, 6677, 548–557. [Google Scholar] [CrossRef]
- Lee, C.-H.; Wu, C.-H. A Self-adaptive Clustering Scheme with a Time-Decay Function for Microblogging Text Mining. J. Inf. Technol. 2011, 185, 62–71. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the 27th Interna-tional Conference on Neural Information Processing Systems, Montréal, QC, Canada, 6–12 December 2014; pp. 3104–3112. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 2227–2237. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Workshop on Text Summarization Branches Out (WAS 2004), Barcelona, Spain, 21–26 July 2004; pp. 74–81. [Google Scholar]
- Shigemura, J.; Ursano, R.J.; Morganstein, J.C.; Kurosawa, M.; Benedek, D.M. Public responses to the novel 2019 coronavirus (2019-nCoV) in Japan: Mental health consequences and target populations. J. Psychiatry Clin. Neurosci. 2020, 74, 281–282. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Citing the Author | Model | Using Pre-Trained Model | Method of Text Summarization | Data Set |
|---|---|---|---|---|
| Isonuma et al. [23] | CNN-LSTM | No | Extractive | NIKKEI Financial Report |
| Nallapati et al. [24] | SummaRuNNer | No | Extractive | CNN/Daily Mail and DUC 2002 |
| Masum et al. [33] | Bidirectional LSTM | No | Abstractive | Amazon Fine Food Reviews |
| Fecht et al. [45] | BERT | Yes | Abstractive | German Wikipedia articles |
| Kerui et al. [42] | BERT | Yes | Abstractive | LCSTS |
| Garg et al. [43] | T5 | Yes | Abstractive and Extractive | 80 K News Articles |
| Farahani et al. [40] | mT5 | Yes | Abstractive | Pn-summary |
| Cai et al. [34] | RC-Transformer | Yes | Abstractive | Gigaword and DUC 2004 |
| Chopra et al. [29] | Conditional Generation by RNN | No | Abstractive | |
| Song et al. [30] | CNN-LSTM | No | Abstractive | CNN/Daily Mail |
| Paulus et al. [31] | Attention-RNN | No | Abstractive | |
| Ma et al. [41] | T-BERTSum | Yes | Abstractive | |
| Zhang et al. [39] | HIBERT | Yes | Abstractive | |
| Liu et al. [36] | BERT | Yes | Abstractive and Extractive | |
| Daiya [44] | ENEMABst | Yes | Abstractive and Extractive |
| Model/Score | Rouge-1 | Rouge-2 | Rouge-L |
|---|---|---|---|
| T5-small | 28.17 | 8.08 | 21.76 |
| T5-base | 33.01 | 11.46 | 25.76 |
| BERT | 23.50 | 6.51 | 17.62 |
| Model/Score | Rouge-1 | Rouge-2 | Rouge-L |
|---|---|---|---|
| T5-small | 28.21 | 8.37 | 21.66 |
| T5-base | 33.64 | 11.80 | 26.34 |
| BERT | 23.42 | 6.56 | 17.43 |
| Model/Score | Rouge-1 | Rouge-2 | Rouge-L |
|---|---|---|---|
| T5-small | 28.97 | 8.26 | 22.07 |
| T5-base | 33.70 | 12.06 | 26.47 |
| BERT | 23.66 | 6.82 | 17.75 |
| Model/Score | Rouge-1 | Rouge-2 | Rouge-L |
|---|---|---|---|
| T5-small | 32.64 | 11.37 | 25.66 |
| T5-base | 38.13 | 16.39 | 30.88 |
| BERT | 29.58 | 11.14 | 22.22 |
| Model | Dataset | Rouge Score |
|---|---|---|
| T5-base | Xsum | 38.13 |
| UniLm | CNN/DailyMail | 43.08 |
| BERT | CNN/DailyMail | 44.16 |
| Consistency of the Topic | Closeness to the Facts | Grammatical Correctness | |
|---|---|---|---|
| No. of Participant | 39 | 39 | 39 |
| Minimum | 2 | 2 | 1 |
| Maximum | 5 | 5 | 5 |
| Mean | 3.92 | 3.89 | 3.92 |
| Median | 4 | 4 | 4 |
| Std. Deviation | 0.824 | 0.819 | 0.928 |
| Std. Error | 0.132 | 0.131 | 0.148 |
| Cronbach’s alpha | 0.725 | 0.812 | 0.846 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, C.-H.; Yang, H.-C.; Chen, Y.J.; Chuang, Y.-L. Event Monitoring and Intelligence Gathering Using Twitter Based Real-Time Event Summarization and Pre-Trained Model Techniques. Appl. Sci. 2021, 11, 10596. https://doi.org/10.3390/app112210596
Lee C-H, Yang H-C, Chen YJ, Chuang Y-L. Event Monitoring and Intelligence Gathering Using Twitter Based Real-Time Event Summarization and Pre-Trained Model Techniques. Applied Sciences. 2021; 11(22):10596. https://doi.org/10.3390/app112210596
Chicago/Turabian StyleLee, Chung-Hong, Hsin-Chang Yang, Yenming J. Chen, and Yung-Lin Chuang. 2021. "Event Monitoring and Intelligence Gathering Using Twitter Based Real-Time Event Summarization and Pre-Trained Model Techniques" Applied Sciences 11, no. 22: 10596. https://doi.org/10.3390/app112210596
APA StyleLee, C.-H., Yang, H.-C., Chen, Y. J., & Chuang, Y.-L. (2021). Event Monitoring and Intelligence Gathering Using Twitter Based Real-Time Event Summarization and Pre-Trained Model Techniques. Applied Sciences, 11(22), 10596. https://doi.org/10.3390/app112210596