Real-Time, Content-Based Communication Load Reduction in the Internet of Multimedia Things

 , ,
, , 
Abstract
1. Introduction
- Enabling sensors to transmit only changing motion information, established through inter- frame differing.
- Consequently, reducing communication overhead by limiting the data to be sent.
- Accommodation of limited resources in the IoMT by managing excessive data.
- Efficient data compression based on the contents of individual frames.
- Bitrate reduction through compression, while preserving the video content and its quality of representation.
- Configuration of IoT testbed with two Intel NUC Core i5-6260U mini computers for experiments and performance evaluation of proposed load reduction scheme.
- Analysis of the proposed method in comparison with five other related methods for load reduction. The relative merits and demerits of these methods are indicated.
2. Related Research and Background
2.1. Challenges in IoT
2.1.1. Overloaded Multimedia Networks
2.1.2. Management of Limited Resources
2.1.3. Video Streaming in the IoT
2.1.4. IoT Security
2.2. Video Processing
2.2.1. Video Compression
2.2.2. Motion Detection
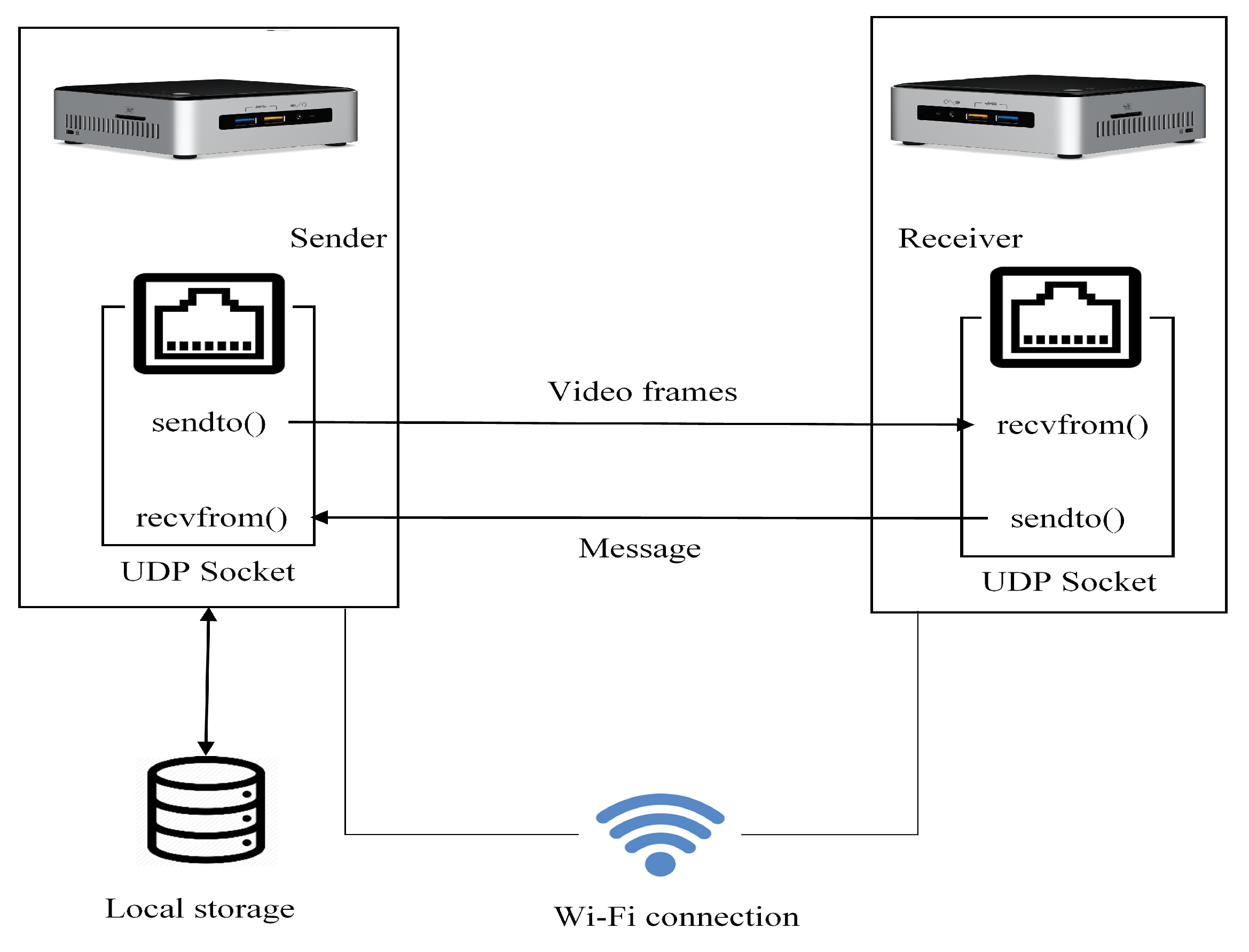
3. METHODOLOGY
3.1. Outline of the Approach
3.2. System Composition
3.2.1. Data Acquisition
3.2.2. ROM Identification
3.2.3. Load Reduction
3.2.4. Secure Transmission
3.2.5. Video Compression Algorithm
Algorithm at Sender
| Algorithm 1 Sender |
|
Algorithm at Receiver
| Algorithm 2 Receiver |
|
4. Results
4.1. ROM Extraction
4.2. Evaluation Parameters
4.2.1. Data Sent
4.2.2. Delays in Sending Video
4.2.3. Frame Rate
4.2.4. Average Bit-Rate
4.3. Video Quality Metrics
4.3.1. Structural Similarity (SSIM) Index
4.3.2. Peak Signal-to-Noise Ratio (PSNR)
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Development, S.R. IoT: Number of Connected Devices Worldwide 2012–2025, Statista. 2016. Available online: https://www.statista.com/statistics/471264/iot-number-of-connected-devices-worldwide/ (accessed on 20 December 2019).
- Aslam, A.; Curry, E. Towards a generalized approach for deep neural network based event processing for the internet of multimedia things. IEEE Access 2018, 6, 25573–25587. [Google Scholar] [CrossRef]
- Mohan, A.; Gauen, K.; Lu, Y.H.; Li, W.W.; Chen, X. Internet of video things in 2030: A world with many cameras. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar]
- Alvi, S.A.; Afzal, B.; Shah, G.A.; Atzori, L.; Mahmood, W. Internet of multimedia things: Vision and challenges. Ad Hoc Netw. 2015, 33, 87–111. [Google Scholar] [CrossRef]
- Kumari, A.; Tanwar, S.; Tyagi, S.; Kumar, N.; Maasberg, M.; Choo, K.K.R. Multimedia big data computing and Internet of Things applications: A taxonomy and process model. J. Netw. Comput. Appl. 2018, 124, 169–195. [Google Scholar] [CrossRef]
- Zhu, W.; Cui, P.; Wang, Z.; Hua, G. Multimedia big data computing. IEEE Multimed. 2015, 22, 96-c3. [Google Scholar] [CrossRef]
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of things: A survey on enabling technologies, protocols, and applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Kaashki, N.; Safabakhsh, R. RGB-D face recognition under various conditions via 3D constrained local model. J. Vis. Commun. Image Represent. 2018, 52, 66–85. [Google Scholar] [CrossRef]
- Karmann, K. Moving object recognition using an adaptive background memory. In Time-Varying Image Processing and Moving Object Recognition; Cappellini, V., Ed.; Elsevier: Amsterdam, The Netherlands, 1990; Volume 2, pp. 297–307. [Google Scholar]
- Chen, S.; Xu, H.; Liu, D.; Hu, B.; Wang, H. A vision of IoT: Applications, challenges, and opportunities with china perspective. IEEE Int. Things J. 2014, 1, 349–359. [Google Scholar] [CrossRef]
- Whitmore, A.; Agarwal, A.; Da Xu, L. The Internet of Things—A survey of topics and trends. Inf. Syst. Front. 2015, 17, 261–274. [Google Scholar] [CrossRef]
- Wang, K.; Mi, J.; Xu, C.; Zhu, Q.; Shu, L.; Deng, D.J. Real-time load reduction in multimedia big data for mobile Internet. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2016, 12, 76. [Google Scholar] [CrossRef]
- Knight, M. Data Management and the Internet of Things. Available online: https://www.dataversity.net/data-management-internet-things/ (accessed on 20 December 2019).
- Park, T.; Abuzainab, N.; Saad, W. Learning how to communicate in the Internet of Things: Finite resources and heterogeneity. IEEE Access 2016, 4, 7063–7073. [Google Scholar] [CrossRef]
- Albreem, M.A.; El-Saleh, A.A.; Isa, M.; Salah, W.; Jusoh, M.; Azizan, M.; Ali, A. Green internet of things (IoT): An overview. In Proceedings of the 2017 IEEE 4th International Conference on Smart Instrumentation, Measurement and Application (ICSIMA), Putrajaya, Malaysia, 28–30 November 2017; pp. 1–6. [Google Scholar]
- Abbasi, M.A.; Memon, Z.A.; Memon, J.; Syed, T.Q.; Alshboul, R. Addressing the future data management challenges in iot: A proposed framework. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 197–207. [Google Scholar]
- Perala, S.S.N.; Galanis, I.; Anagnostopoulos, I. Fog computing and efficient resource management in the era of Internet-of-video things (IoVT). In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar]
- Devasena, C.L. IPv6 Low Power Wireless Personal Area Network (6LoWPAN) for Networking Internet of Things (IoT)–Analyzing its Suitability for IoT. Indian J. Sci. Technol. 2016, 9, 30. [Google Scholar]
- Pereira, R.; Pereira, E.G. Video streaming considerations for internet of things. In Proceedings of the 2014 International Conference on Future Internet of Things and Cloud, Barcelona, Spain, 27–29 Auguest 2014; pp. 48–52. [Google Scholar]
- Sammoud, A.; Kumar, A.; Bayoumi, M.; Elarabi, T. Real-time streaming challenges in Internet of Video Things (IoVT). In Proceedings of the 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar]
- Jennehag, U.; Forsstrom, S.; Fiordigigli, F. Low delay video streaming on the internet of things using Raspberry Pi. Electronics 2016, 5, 60. [Google Scholar] [CrossRef]
- Mande, V.; Lakhe, M. Automatic Video Processing Based on IoT Using Raspberry Pi. In Proceedings of the 2018 3rd International Conference for Convergence in Technology (I2CT), Pune, India, 6–8 April 2018; pp. 1–6. [Google Scholar]
- Patil, N.; Ambatkar, S.; Kakde, S. IoT based smart surveillance security system using raspberry Pi. In Proceedings of the 2017 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 6–8 April 2017; pp. 344–348. [Google Scholar]
- Quadri, S.A.I.; Sathish, P. IoT based home automation and surveillance system. In Proceedings of the 2017 International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 15–16 June 2017; pp. 861–866. [Google Scholar]
- Mahmoud, R.; Yousuf, T.; Aloul, F.; Zualkernan, I. Internet of things (IoT) security: Current status, challenges and prospective measures. In Proceedings of the 2015 10th International Conference for Internet Technology and Secured Transactions (ICITST), London, UK, 14–16 December 2015; pp. 336–341. [Google Scholar]
- Zhang, Z.K.; Cho, M.C.Y.; Wang, C.W.; Hsu, C.W.; Chen, C.K.; Shieh, S. IoT security: Ongoing challenges and research opportunities. In Proceedings of the 2014 IEEE 7th international conference on service-oriented computing and applications, Matsue, Japan, 17–19 November 2014; pp. 230–234. [Google Scholar]
- Shifa, A.; Asghar, M.N.; Noor, S.; Gohar, N.; Fleury, M. Lightweight Cipher for H. 264 Videos in the Internet of Multimedia Things with Encryption Space Ratio Diagnostics. Sensors 2019, 19, 1228. [Google Scholar] [CrossRef]
- Daemen, J.; Rijmen, V. The Design of Rijndael: AES-the Advanced Encryption Standard; Springer: New York, NY, USA, 2013. [Google Scholar]
- Wang, Y.; Ostermann, J.; Zhang, Y.Q. Video processing and communications. Progressive 2002, 1, 12. [Google Scholar]
- Ghanbari, M. Standard Codecs: Image Compression to Advanced Video Coding; Iet: London, UK, 2003. [Google Scholar]
- Joshi, M.A.; Raval, M.S.; Dandawate, Y.H.; Joshi, K.R.; Metkar, S.P. Image and Video Compression: Fundamentals, Techniques, and Applications; Chapman and Hall/CRC: New York, NY, USA, 2014. [Google Scholar]
- Rao, K.R.; Yip, P. Discrete Cosine Transform: Algorithms, Advantages, Applications; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Pennebaker, W.B.; Mitchell, J.L. JPEG: Still Image Data Compression Standard; Springer: New York, NY, USA, 1992. [Google Scholar]
- Haskell, B.G.; Netravali, A.N. Digital Pictures: Representation, Compression, and Standards; Perseus Publishing: New York, NY, USA, 1997. [Google Scholar]
- Lee, J.H.; Jang, K.S.; Kim, B.G.; Jeong, S.; Choi, J.S. Fast video encoding algorithm for the internet of things environment based on high efficiency video coding. Int. J. Distrib. Sensor Netw. 2015, 11, 146067. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Hsu, C.C.; Fang, Y.T.; Yu, F. Content-sensitive data compression for IoT streaming services. In Proceedings of the 2017 IEEE International Congress on Internet of Things (ICIOT), Honolulu, HI, USA, 25–30 June 2017; pp. 147–150. [Google Scholar]
- Ukil, A.; Bandyopadhyay, S.; Pal, A. Iot data compression: Sensor-agnostic approach. In Proceedings of the 2015 Data Compression Conference, Snowbird, UT, USA, 7–9 April 2015; pp. 303–312. [Google Scholar]
- Jackson, E.S.; Peplow, R. Video compression system for mobile devices. RN 2003, 2. [Google Scholar]
- Al-Ani, M.S.; Awad, F.H. The JPEG image compression algorithm. Int. J. Adv. Eng. Technol. 2013, 6, 1055. [Google Scholar]
- Rawat, S.; Verma, A.K. Survey paper on image compression techniques. Int. Res. J. Eng. Technol. 2017, 4, 1–6. [Google Scholar]
- Bovik, A.C. Video Communication Networks, in Handbook of Image and Video Processing; Academic press: Cambridge, MA, USA, 2010; pp. 1031–1064. [Google Scholar]
- Jansi, P. A review on motion detection and tracking techniques. Int. J. Modern Trends Sci. Technol. Rev. Motion Detect. Track. Tech. 2017, 3, 219–224. [Google Scholar]
- Daniyal, F.; Cavallaro, A. Abnormal motion detection in crowded scenes using local spatio-temporal analysis. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 1944–1947. [Google Scholar]
- Zeng, W.; Du, J.; Gao, W.; Huang, Q. Robust moving object segmentation on H. 264/AVC compressed video using the block-based MRF model. Real-Time Imaging 2005, 11, 290–299. [Google Scholar] [CrossRef]
- Widyawan, M.I.Z.; Nugroho, L.E. Adaptive motion detection algorithm using frame differences and dynamic template matching method. In Proceedings of the 2012 9th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Daejeon, Korea, 26–28 November 2012; pp. 236–239. [Google Scholar]
- Yu, Z.; Chen, Y. A real-time motion detection algorithm for traffic monitoring systems based on consecutive temporal difference. In Proceedings of the 2009 7th Asian Control Conference, Hong Kong, China, 27–29 Auguest 2009; pp. 1594–1599. [Google Scholar]
- Singla, N. Motion detection based on frame difference method. Int. J. Inf. Comput. Technol. 2014, 4, 1559–1565. [Google Scholar]
- Alavi, S. Comparison of Some Motion Detection Methods in cases of Single and Multiple Moving Objects. Int. J. Image Process. 2012, 6, 389–396. [Google Scholar]
- Yong, C.Y.; Sudirman, R.; Chew, K.M. Motion detection and analysis with four different detectors. In Proceedings of the 2011 Third International Conference on Computational Intelligence, Modelling & Simulation, Langkawi, Malaysia, 20–22 September 2011; pp. 46–50. [Google Scholar]
- Metkar Shilpa, P.; Talbar Sanjay, N. Dynamic Motion Detection technique for fast and efficient video coding. In Proceedings of the TENCON 2008—2008 IEEE Region 10 Conference, Hyderabad, India, 19–21 November 2008; pp. 1–5. [Google Scholar]
- Choi, Y.; Zaijun, P.; Kim, S.; Kim, T.; Park, C. Salient Motion Information Detection Technique Using Weighted Subtraction Image and Motion Vector. In Proceedings of the 2006 International Conference on Hybrid Information Technology, Cheju Island, Korea, 9–11 November 2006; Volume 1, pp. 263–269. [Google Scholar]
- Elharrouss, O.; Moujahid, D.; Tairi, H. Motion detection based on the combining of the background subtraction and the structure–texture decomposition. Optik-Int. J. Light Electron Opt. 2015, 126, 5992–5997. [Google Scholar] [CrossRef]
- Kurylyak, Y. A real-time motion detection for video surveillance system. In Proceedings of the 2009 IEEE International Workshop on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications, Rende, Italy, 21–23 November 2009; pp. 386–389. [Google Scholar]
- Oh, T.H.; Lee, J.Y.; Kweon, I.S. Real-time motion detection based on discrete cosine transform. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 Octomber 2012; pp. 2381–2384. [Google Scholar]
- Rajpurohit, A.; Agarwal, A.; Gaikwad, M.; Garg, K.; Inamdar, V. Securing public places using intelligent motion detection. In Proceedings of the 2012 IEEE International Conference on Engineering Education: Innovative Practices and Future Trends (AICERA), Kottayam, India, 19–21 July 2012; pp. 1–4. [Google Scholar]
- Bradski, G.; Kaehler, A. Learning OpenCV: Computer Vision with the OpenCV Library; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2008. [Google Scholar]
- Chattopadhyay, P.; Sural, S.; Mukherjee, J. Frontal Gait Recognition From Incomplete Sequences Using RGB-D. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1843–1856. [Google Scholar] [CrossRef]
- Dataset, V.V. Virat Data. 2011. Available online: http://www.viratdata.org/ (accessed on 20 December 2019).
- Xiph.org. Derf’s Test Media Collection. Available online: https://media.xiph.org/video/derf/ (accessed on 20 December 2019).
- Rivest, R.L. A Description of o Single-Chip Implementortion of the RSA Cipher. LAMBDA 1980, Fourth Quarter, 14–18. [Google Scholar]
- Zadka, M. Cryptography. In DevOps in Python; Springer: New York, NY, USA, 2019; pp. 95–110. [Google Scholar]
- Fall, K.R.; Stevens, W.R. TCP/IP Illustrated, Volume 1: The Protocols; Addison-Wesley: Boston, MA, USA, 2011. [Google Scholar]
- Winkler, S.; Mohandas, P. The evolution of video quality measurement: From PSNR to hybrid metrics. IEEE Trans. Broadcasting 2008, 54, 660–668. [Google Scholar] [CrossRef]
- Chen, M.J.; Bovik, A.C. Fast structural similarity index algorithm. J. Real-Time Image Process. 2011, 6, 281–287. [Google Scholar] [CrossRef]
- Mayache, A.; Eude, T.; Cherfifi, H. A comparison of image quality models and metrics based on human vidual sensitivity. In Proceedings of the International Conference on Image Processing, Chicago, IL, USA, 7 October 1998; pp. 409–413. [Google Scholar]
- Avcibas, I.; Sankur, B.; Sayood, K. Statistical evaluation of image quality measures. J. Electron. Imaging 2002, 11, 206–223. [Google Scholar]
- Winkler, S. Digital Video Quality: Vision Models and Metrics; Wiley: Hoboken, NJ, USA, 2005. [Google Scholar]
- VQEG. Final Report from the Video Quality Experts Group on the Validation of Objective Models of Video Quality Assessment, Phase II. 2004. Available online: www.vqeg.org (accessed on 8 February 2020).
- Pinson, M.; Wolf, S. A new standardized method for objectively measuring video quality. IEEE Trans. Broadcasting 2004, 50, 312–322. [Google Scholar] [CrossRef]
- Moorthy, A.; Seshadrinathan, K.; Soundarajan, R.; Bovik, A. Wireless video quality assessment: A study of subjective scores and subjective algorithms. IEEE Trans. Circuits Syst. Video Technol. 2010, 20, 513–516. [Google Scholar] [CrossRef]
- Wang, Z.; Bavik, A.; Sheik, A.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Zhang, F.; Bull, D.R. A parametric framework for video compression using region-based texture models. IEEE J. Sel. Top. Signal Process. 2011, 5, 1378–1392. [Google Scholar] [CrossRef]
- Leontaris, A.; Cosman, P.C. Region-of-interest video compression with a composite and a long-term frame. In Proceedings of the Seventh IASTED International Conference Computer Graphics and Imaging, Kauai, HI, USA, 17–19 August 2004. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Sequence | Frame No. | Size of Extracted ROM | Size of Buffer (JPEG Encoded Region) |
|---|---|---|---|
| Walk_384 × 288 | 28 | 267 × 286 × 3 | 31,596 × 1 |
| Ground_1280 × 720 | 185 | 1127 × 497 × 3 | 150,475 × 1 |
| Exercise_352 × 240 | 7 | 11 × 35 × 3 | 1222 × 1 |
| Duval Street_946 × 360 | 90 | 815 × 360 × 3 | 65,689 × 1 |
| Football_352 × 288 | 233 | 309 × 257 × 3 | 35,876 × 1 |
| Proposed Method | All Frames | |
|---|---|---|
| Video Sequence | fps | |
| Walk | 11 | 12 |
| Ground | 6 | 3 |
| Exercise | 19 | 12 |
| Duval Street | 6 | 9 |
| Football | 17 | 10 |
| Video Sequence | Average PSNR (db) | ||
|---|---|---|---|
| Y | U | V | |
| Walk | 39.0173807 | 40.73244 | 40.99809 |
| Ground | 37.1191006 | 38.05364 | 37.36613 |
| Exercise | 37.1012336 | 40.90042 | 43.62024 |
| Duval Street | 43.7660886 | 48.99123 | 49.87238 |
| Football | 41.0030631 | 42.71924 | 44.67114 |
| Parameters | Proposed Method | Wang [12] | Hsu [37] | Jackson [39] | Zhang [74] | Leontaris [75] |
|---|---|---|---|---|---|---|
| Objectives | Reduction of communication load in IoMT devices by limitation of video data. | Presents a hybrid-stream scheme for separating spatial and temporal information in videos to reduce the data load and improve efficiency in the mobile Internet. | Video streaming enabling lower data storage and maintaining precision of data. | A video compression scheme for computationally challenged mobile devices. | Avoid encoding of complete videos and sending only compressed information of texture regions through texture warping and synthesis. | Region of Interest (ROI) coding for high-quality videos requiring some portions of frames with high resolution and, thus, high transfer rates |
| Merits/ Features |
|
|
|
|
|
|
| Dataset | Experimentation on static and moving camera videos having motion in a range from low to high. Mostly covering surveillance video data. | Action Recognition dataset videos taken from YouTube and Google. | Static camera videos covering surveillance and video conferencing. | Static and moving camera videos with high texture and artefacts. | Aerial videos with dynamic motion and still-camera videos such as in video conferencing. | |
| Findings |
|
|
|
|
|
|
| Limitations |
|
|
|
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tanseer, I.; Kanwal, N.; Asghar, M.N.; Iqbal, A.; Tanseer, F.; Fleury, M. Real-Time, Content-Based Communication Load Reduction in the Internet of Multimedia Things. Appl. Sci. 2020, 10, 1152. https://doi.org/10.3390/app10031152
Tanseer I, Kanwal N, Asghar MN, Iqbal A, Tanseer F, Fleury M. Real-Time, Content-Based Communication Load Reduction in the Internet of Multimedia Things. Applied Sciences. 2020; 10(3):1152. https://doi.org/10.3390/app10031152
Chicago/Turabian StyleTanseer, Iffrah, Nadia Kanwal, Mamoona Naveed Asghar, Ayesha Iqbal, Faryal Tanseer, and Martin Fleury. 2020. "Real-Time, Content-Based Communication Load Reduction in the Internet of Multimedia Things" Applied Sciences 10, no. 3: 1152. https://doi.org/10.3390/app10031152
APA StyleTanseer, I., Kanwal, N., Asghar, M. N., Iqbal, A., Tanseer, F., & Fleury, M. (2020). Real-Time, Content-Based Communication Load Reduction in the Internet of Multimedia Things. Applied Sciences, 10(3), 1152. https://doi.org/10.3390/app10031152