Analysis of Cross-Referencing Artificial Intelligence Topics Based on Sentence Modeling


Abstract
1. Introduction
2. Related Research
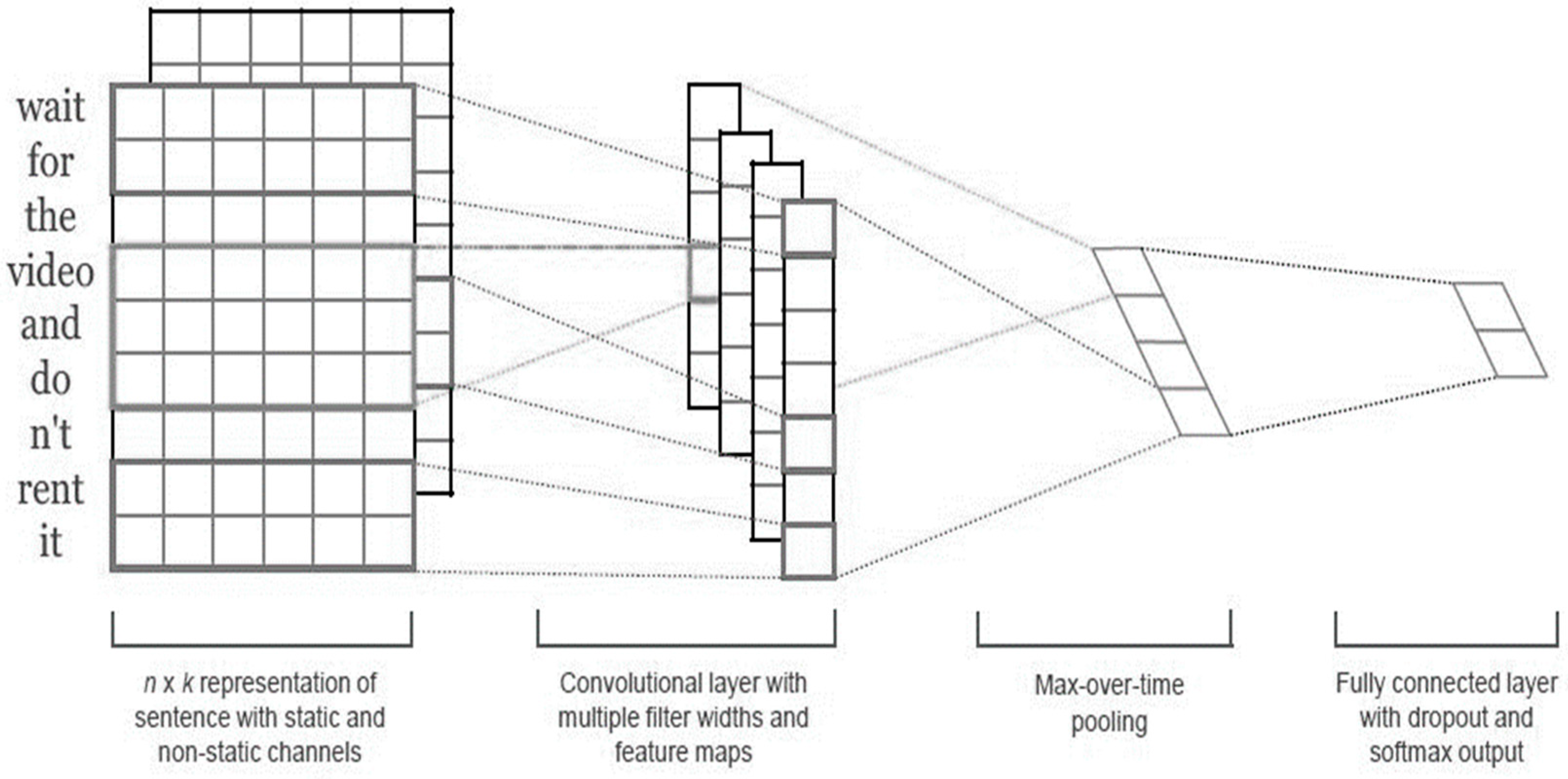
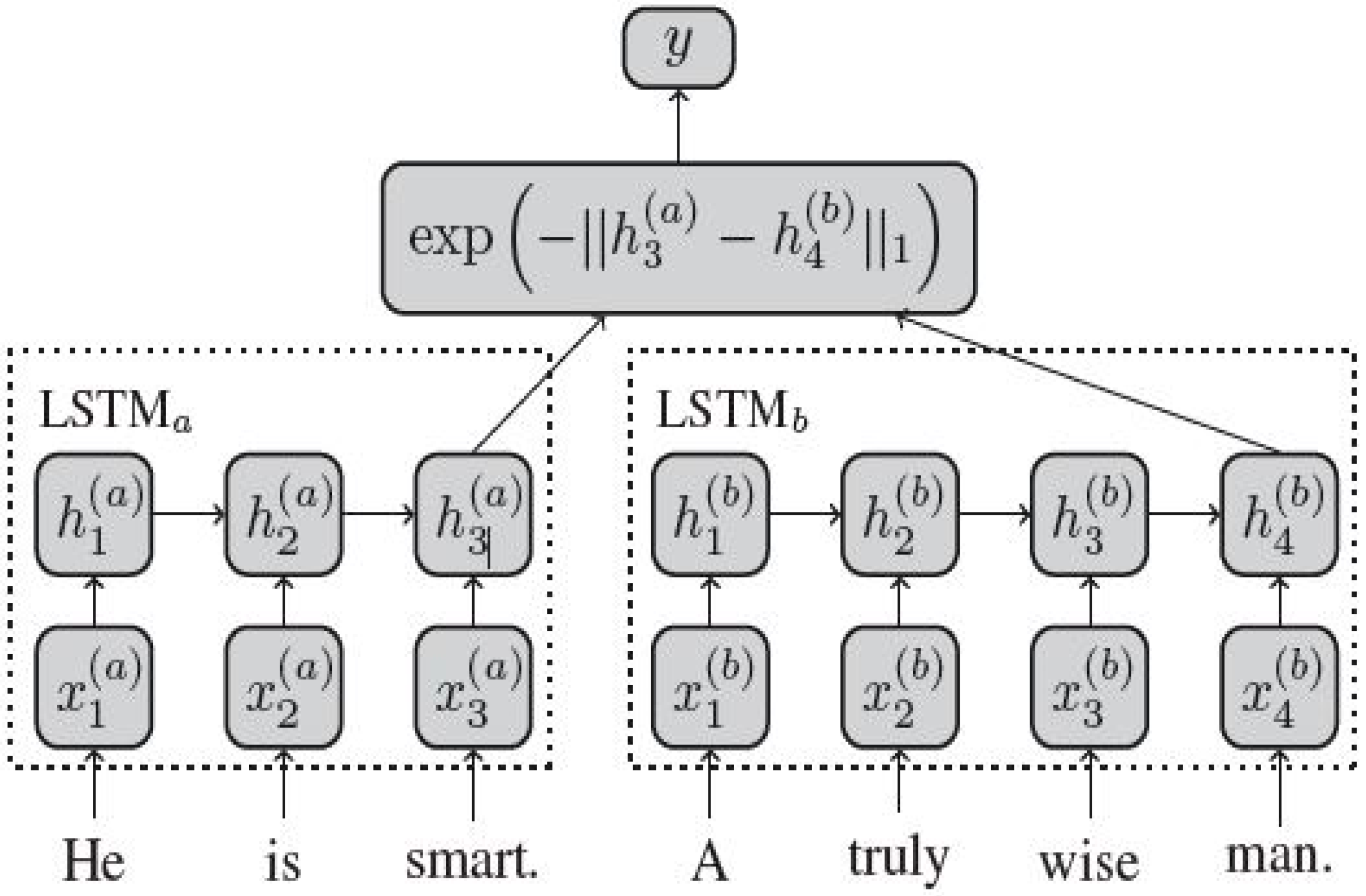
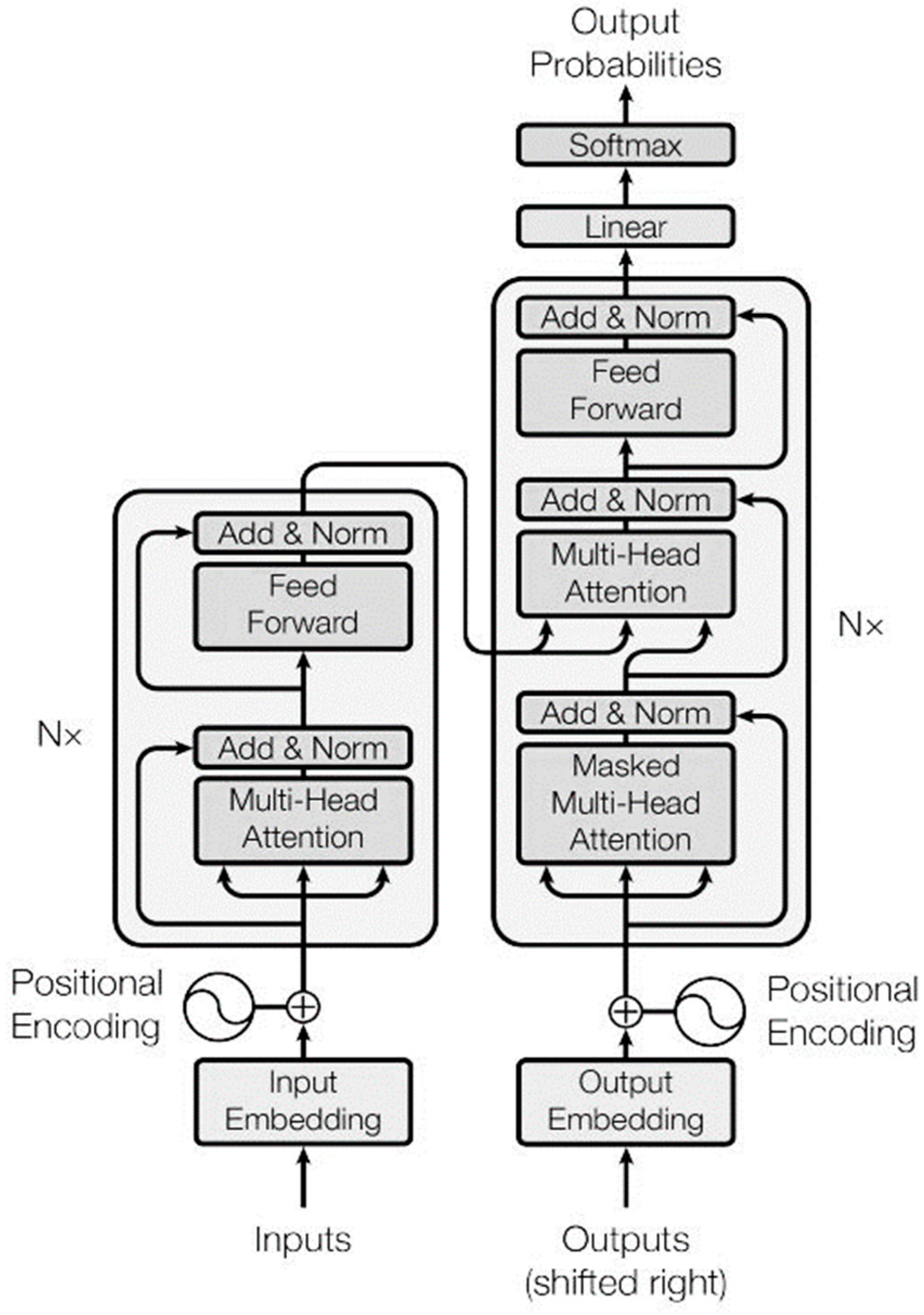
2.1. Sentence Modeling
2.2. Knowledge Areas Analysis Research
3. Methods
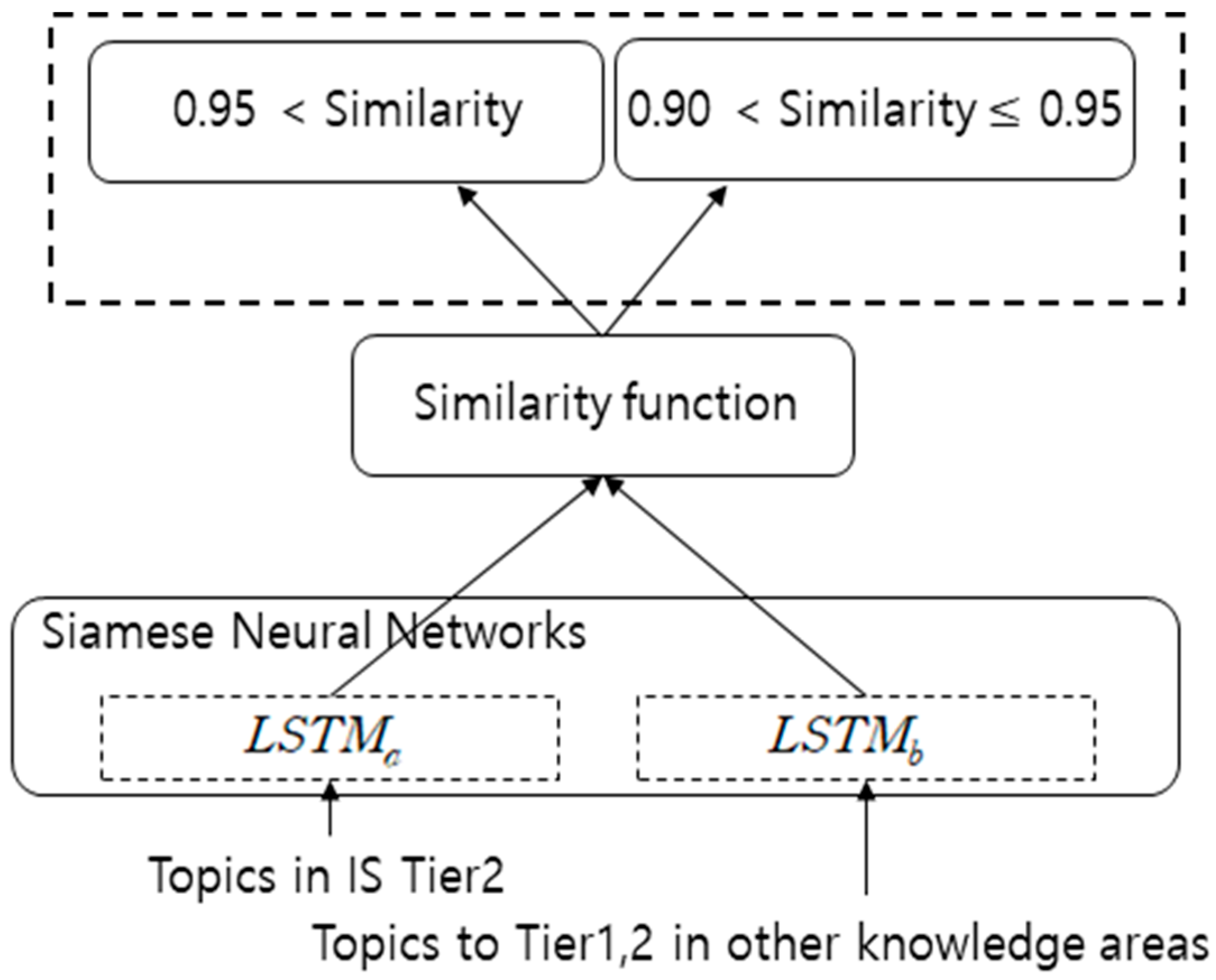
3.1. Experimental Procedure
- Step 1.
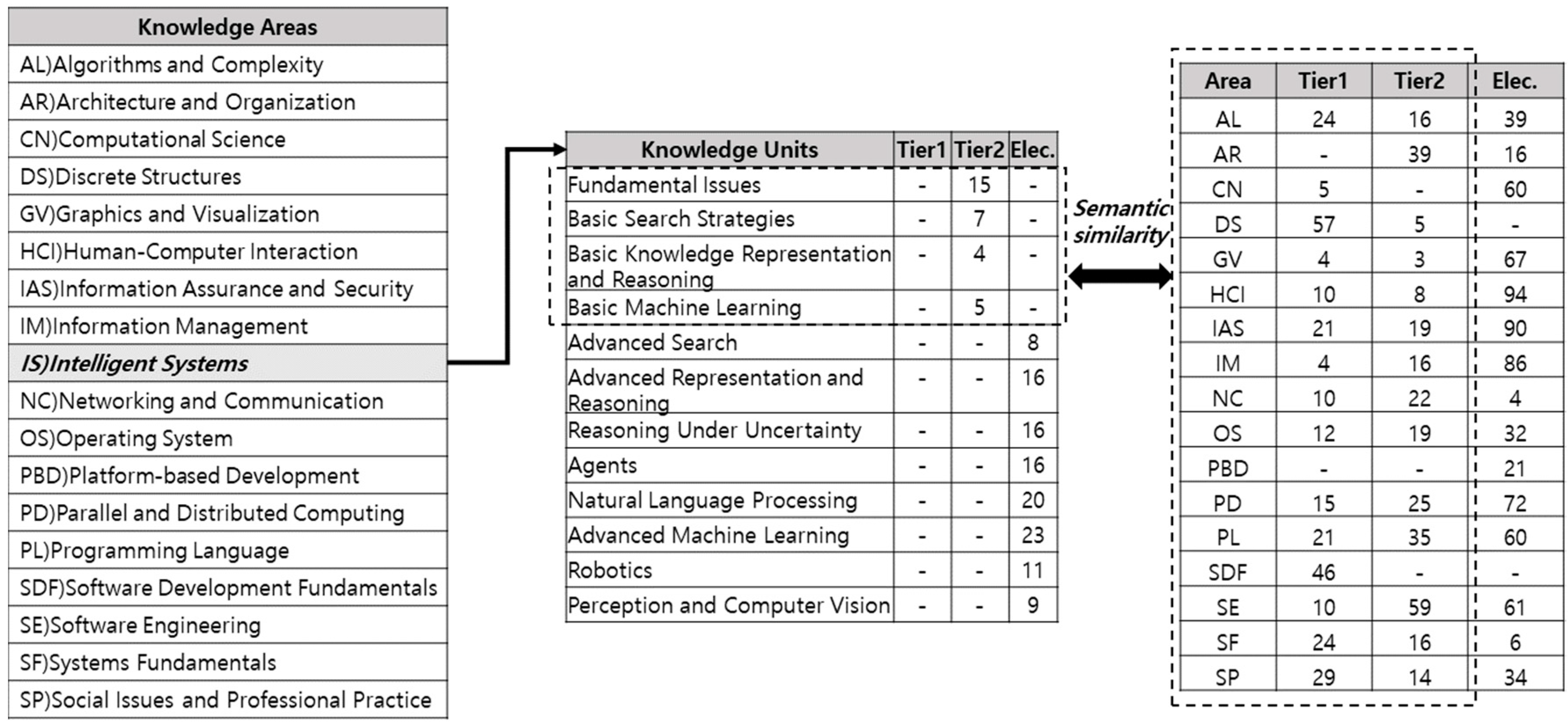
- From the CS2013 body of knowledge, the topics of IS and other areas were classified.
- Step 2.
- To calculate the similarity among topics, three different sentence models (CNN, MaLSTM, and transformer) based on machine learning were implemented. This system was developed using Python 3.6 and executed on Linux 16.04.
- Step 3.
- The models were trained using data from Stanford Natural Language Inference (SNLI) corpus and Quora Question Pairs (QQP).
- Step 4.
- The accuracy was calculated after training, and the sentence model with the highest accuracy was selected.
- Step 5.
- Semantic similarities between classified IS topics and topics from other areas were calculated.
- Step 6.
- Through various similarity simulations between the two topics, the similarity levels were divided into “0.95 < similarity” and “0.90 < similarity ≤ 0.95.”
- Step 7.
- A search engine was used to examine the semantic validity of the topics with a similarity of “0.95 < similarity.”
3.2. Subject of Analysis
3.3. Sentence Model Performance
- Training set: SNLI number: 330,635, QQP number: 363,861
- Testing set: SNLI number: 36,738, QQP number: 40,430
3.4. Setting the Similarity of the Sentence Model
4. Application Results
4.1. Sentence Model Performance
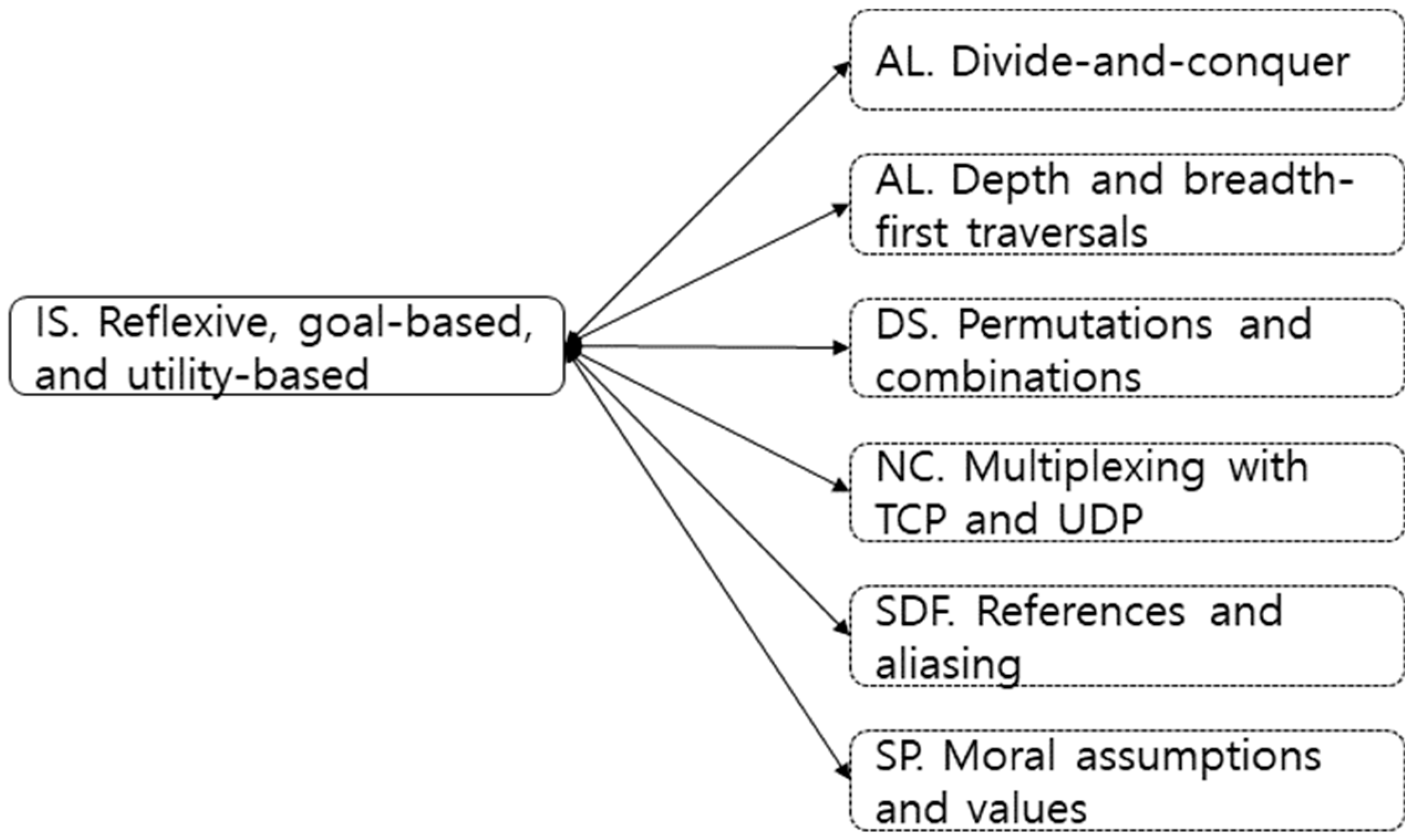
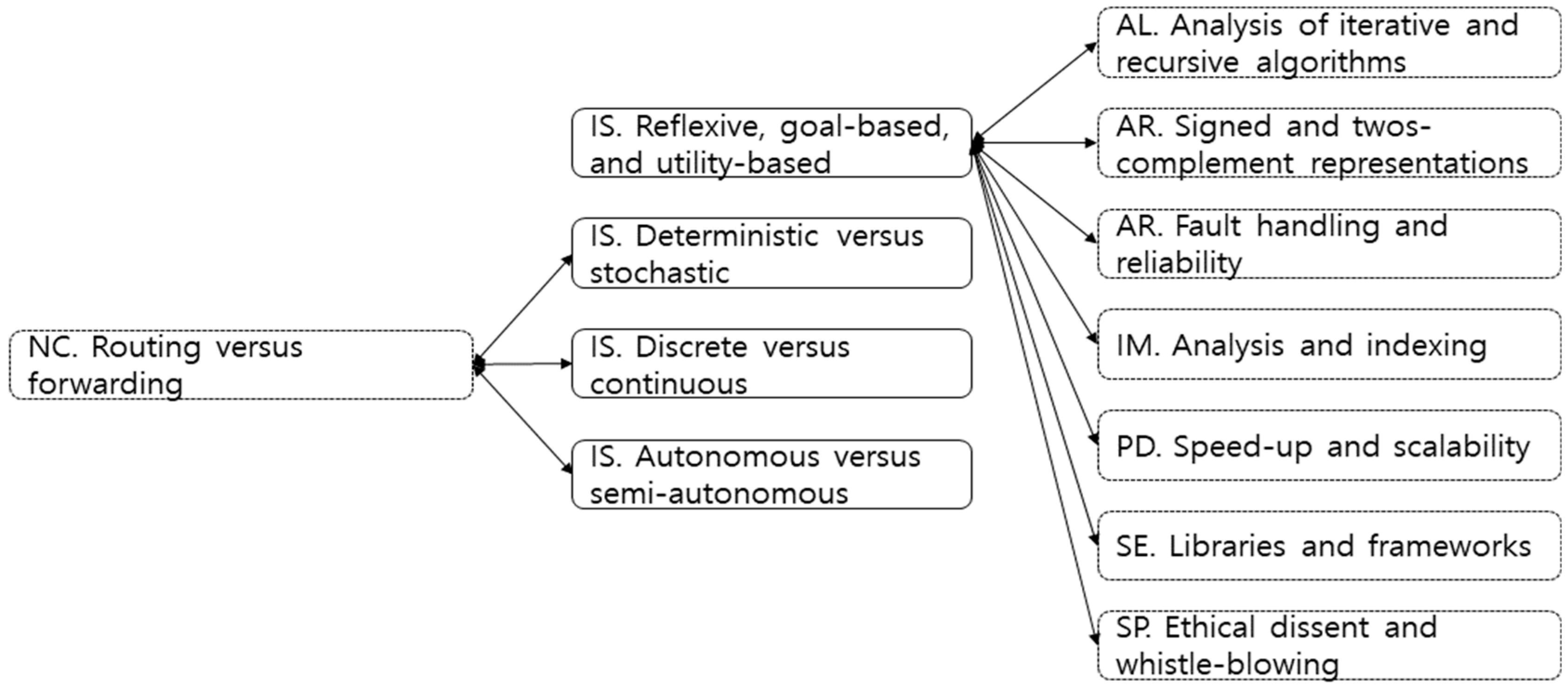
4.2. Results for Tier 2
4.3. KU of IS vs. KU of Other Knowledge Areas
4.4. Evaluation
4.4.1. Content Validation by Experts
4.4.2. Validation through Index Terms
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Whitehouse Executive Order on AI. Available online: https://www.whitehouse.gov/ai/executive-order-ai/ (accessed on 2 March 2020).
- Cabinet Office, Government of Japan Summit on Artificial Intelligence in Government. Artificial intelligence technology strategy meeting. Available online: https://www8.cao.go.jp/cstp/tyousakai/jinkochino/index.html (accessed on 2 March 2020).
- Ministry of Science and ICT I-Korea 4.0 Artificial Intelligence (AI) R&D Strategy for Realization; Ministry of Science and ICT I: Korea, 2018.
- Carnegie Mellon University (CMU) B.S. in Artificial Intelligence; Carnegie Mellon University (CMU): Pittsburgh, PA, USA, 2020.
- MIT Artificial Intelligence: Implications for Business Strategy (self-paced online). Available online: https://executive.mit.edu/openenrollment/program/artificial-intelligence-implications-for-business-strategy-self-paced-online/ (accessed on 2 March 2020).
- Ministry of Education, PRC Ministry of Education of People’s Republic of China official Website. Available online: http://www.moe.gov.cn/srcsite/A16/s7062/201804/t20180410_332722.html (accessed on 2 March 2020).
- State Council, PRC Notice of the State Council on Printing and Distributing a New Generation of AI Plan. Available online: http://www.gov.cn/zhengce/content/2017-07/20/content_5211996.html (accessed on 2 March 2020).
- CBSE Central Board of Secondary Education. Available online: http://cbseacademic.nic.in/ai.html (accessed on 2 March 2020).
- Cheng, J.; Huang, R.; Jin, Q.; Ma, J.; Pan, Y. An Undergraduate Curriculum Model for Intelligence Science and Technology. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Guangzhou, China, 8–12 October 2018; pp. 234–239. [Google Scholar] [CrossRef]
- Hearst, M. Improving Instruction of Introductory AI; Tech. Report FS-94-05; AAAI: Menlo Park, CA, USA, 1995. [Google Scholar]
- Tungare, M.; Yu, X.; Cameron, W.; Teng, G.; Perez-Quinones, M.A.; Cassel, L.; Fan, W.; Fox, E.A. Towards a syllabus repository for computer science courses. In Proceedings of the 38th SIGCSE Technical Symposium on Computer Science Education, Covington, KY, USA, 7–11 March 2007; pp. 55–59. [Google Scholar]
- Dai, Y.; Asano, Y.; Yoshikawa, M. Course Content Analysis: An initiative step toward learning object recommendation systems for MOOC learners. In Proceedings of the 9th International Conference on Educational Data Mining, Raleigh, NC, USA, 29 June–2 July 2016; pp. 347–352. [Google Scholar]
- Ida, M. Textual information and correspondence analysis in curriculum analysis. In Proceedings of the 2009 IEEE International Conference on Fuzzy Systems, Jeju Island, Korea, 20–24 August 2009; pp. 20–24. [Google Scholar]
- Sekiya, T. Mapping analysis of CS2013 by supervised LDA and isomap. In Proceedings of the Teaching Assessment and Learning (TALE) 2014 International Conference, Wellington, New Zealand, 8–10 December 2014; pp. 33–40. [Google Scholar]
- Matsuda, Y.; Sekiya, T.; Yamaguchi, K. Curriculum analysis of computer science departments by simplified, supervised LDA. J. Inf. Process. 2018, 26, 497–508. [Google Scholar] [CrossRef]
- Jang, Y.; Kim, H. Reliable classification of FAQs with spelling errors using an encoder-decoder neural network in Korean. Appl. Sci. 2019, 9, 4758. [Google Scholar] [CrossRef]
- Yin, X.; Zhang, W.; Zhu, W.; Liu, S.; Yao, T. Improving sentence representations via component focusing. Appl. Sci. 2020, 10, 958. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Yoon, K. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Shen, Y.; He, X.; Gao, J.; Deng, L.; Mesnil, G. Learning semantic representations using convolutional neural networks for web search. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Mueller, J.; Thyagarajan, A. Siamese recurrent architectures for learning sentence similarity. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16), Phoenix, AZ, USA, 12–17 February 2016; pp. 2789–2792. [Google Scholar]
- Graves, A. Supervised Sequence Labelling. In Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Cho, K.; Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Schwenk, F.B.H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Socher, R. Recursive Deep Learning for Natural Language Processing and Computer Vision. Ph.D. Thesis, Stanford University: Stanford, CA, USA, 2014. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1–15. [Google Scholar]
- Langley, P.; Laird, J.E. Artificial Intelligence and Intelligent Systems; American Association for Artificial Intelligence: Menlo Park, CA, USA, 2013. [Google Scholar]
- Aggarwal, C.C.; Hinneburg, A.; Keim, D.A. On the surprising behavior of distance metrics in high dimensional space. In Database Theory—ICDT 2001. ICDT 2001. Lecture Notes in Computer Science; Bussche, J.V., Ed.; Springer: Berlin, Heidelberg, 2001; Volume 1973. [Google Scholar]
- Pendlebury, J.; Humphrys, M.; Walshe, R. An experimental system for real-time interaction between humans and hybrid AI agents. In Proceedings of the 6th IEEE International Conference Intelligent Systems, Sofia, Bulgaria, 6–8 September 2012; pp. 121–129. [Google Scholar]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson Education: London, UK, 2016. [Google Scholar]
- Zaheer, K. Artificial Intelligence Search Algorithms in Travel Planning; Malardalen University: Västerås, Sweden, 2006. [Google Scholar]
- Srinivasan, S.; Kumar, D.; Jaglan, V. Agents and their knowledge representations. Ubiquitous Comput. Commun. J. 2010, 5, 14–23. [Google Scholar]
- Niederberger, C.; Gross, M.H. Towards a Game Agent; Institute of Visual Computing, ETH Zurich: Zurich, Sweden, 2002. [Google Scholar]
- Ilsoon, S.; Buyeon, J.; JangHyung, J. Changes in E-Commerce and Economic Impact due to the Development of Agent Technology. Inf. Commun. Policy Res. Rep. 2001. Available online: https://www.nkis.re.kr:4445/subject_view1.do?otpId=KISDI00017852&otpSeq=0 (accessed on 2 March 2020).
- Chowdhury, M. Emphasizing morals, values, ethics, and character education in science education and science teaching. Malays. Online J. Educ. Sci. 2016, 4, 1–16. [Google Scholar]
- Poole, D.L.; Mackworth, A.K. Artificial Intelligence Foundations of Computational Agents, 2nd ed.; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Cowan, C.; Wagle, P.; Pu, C.; Beattie, S.; Walpole, J. Buffer overflows: Attacks and defenses for the vulnerability of the decade. In Proceedings of the DARPA Information Survivability Conference and Exposition, Hilton Head, SC, USA, 25–27 January 2000; pp. 119–129. [Google Scholar]
- Banisar, D. Whistleblowing: International Standards and Developments, Corruption and Transparency: Debating the Frontiers between State, Market. and Society; World Bank-Institute for Social Research: Washington, DC, USA, 2011. [Google Scholar]
- Cai, Z.; Wang, C.; Cheng, S.; Wang, H.; Gao, H. Wireless algorithms, systems, and applications. In Proceedings of the 9th International Conference, WASA 2014, Harbin, China, 23–25 June 2014. [Google Scholar]
- Goralski, W. The Illustrated Network How TCP/IP Works in a Modern Network, 2nd ed.; Morgan Kaufmann: Burlington, MA, USA, 2017. [Google Scholar]
- Bose, P.; Carufel, J.L.; Durocher, S.; Langerman, S.; Munro, I. Searching and routing in discrete and continuous domains. In The Casa Matemática Oaxaca-BIRS Workshop; Banff International Research Station: Banff, AB, Canada, 2015. [Google Scholar]
- Lowry, M.R.; McCartney, R.D. Automating Software Design; MIT Press: Cambridge, MA, USA, 1991. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentence Model | Configuration | Accuracy | Mean | |
|---|---|---|---|---|
| SNLI | QQP | |||
| Convolutional Neural Networks | Number of filters: 50, 50, 50 | 0.783 | 0.838 | 0.81 |
| Filter size: 2, 3, 4 | ||||
| Manhattan LSTM | Hidden size: 128 | 0.806 | 0.828 | 0.817 |
| Cell type: GUR | ||||
| Multi-head Attention Networks | Number of blocks: 2 | 0.802 | 0.809 | 0.805 |
| Number of heads: 8 | ||||
| Layers normalization: False | ||||
| KA | Topic Number of KA | 0.95 < Similarity | |
|---|---|---|---|
| AL | 24 | 2 | 17 |
| AR | 0 | 0 | 0 |
| CN | 5 | 0 | 0 |
| DS | 57 | 1 | 74 |
| GV | 4 | 0 | 0 |
| HCI | 10 | 0 | 0 |
| IAS | 21 | 0 | 7 |
| IM | 4 | 0 | 0 |
| NC | 10 | 1 | 4 |
| OS | 12 | 0 | 1 |
| PBD | 0 | 0 | 0 |
| PD | 15 | 0 | 6 |
| PL | 21 | 0 | 4 |
| SDF | 46 | 1 | 31 |
| SE | 10 | 0 | 1 |
| SF | 24 | 0 | 9 |
| SP | 29 | 1 | 8 |
| KA | ||
|---|---|---|
| AL | Brute-force algorithms Greedy algorithms Recursive backtracking | Dynamic programming Sequential and binary search algorithms |
| DS | Sets Relations Functions Surjections, injections, bijections Inverses Composition Logical connectives Predicate logic Direct proofs Disproving by counterexample Proof by contradiction Structural induction Counting arguments Inclusion-exclusion principle Basic definitions Properties | Traversal strategies Undirected graphs Directed graphs Weighted graphs Conditional probability, Bayes’ theorem Expectation, including linearity of expectation Cardinality of finite sets Propositional inference rules (concepts of modus ponens and modus tollens) Universal and existential quantification Weak and strong induction (i.e., first and second principle of induction) The pigeonhole principle The binomial theorem |
| IAS | CIA (Confidentiality, Integrity, Availability) XSS vulnerability | Input validation and data sanitization |
| NC | Layering principles (encapsulation, multiplexing) | |
| OS | Design issues (efficiency, robustness, flexibility, portability, security, compatibility) | |
| PD | Shared Memory | Multicore processors |
| PL | A type as a set of values together with a set of operations | Effect-free programming |
| SDF | Problem-solving strategies Divide-and-conquer strategies Abstraction Arrays Queues Sets Maps | Simple refactoring Debugging strategies Documentation and program style Iterative and recursive traversal of data structures Abstract data types and their implementation |
| SE | Programming in the large vs. individual programming | |
| SF | Reliability Combinational logic, sequential logic, registers, memories | Parallel programming vs. concurrent programming Request parallelism vs. task parallelism Application-virtual machine interaction |
| SP | Ethical argumentation | Plagiarism |
| KA | Topic Number of KA | 0.95 < Similarity | 0.90 < Similarity ≤ 0.95 |
|---|---|---|---|
| AL | 16 | 1 | 17 |
| AR | 39 | 2 | 9 |
| CN | 0 | 0 | 0 |
| DS | 5 | 0 | 6 |
| GV | 3 | 0 | 0 |
| HCI | 8 | 0 | 1 |
| IAS | 19 | 0 | 1 |
| IM | 16 | 1 | 5 |
| NC | 22 | 3 | 15 |
| OS | 19 | 0 | 11 |
| PBD | 0 | 0 | 0 |
| PD | 25 | 1 | 26 |
| PL | 35 | 0 | 0 |
| SDF | 0 | 0 | 0 |
| SE | 59 | 1 | 31 |
| SF | 16 | 0 | 1 |
| SP | 14 | 1 | 8 |
| KA | ||
|---|---|---|
| AL | Heuristics Heaps | Context-free grammar |
| AR | Instruction formats RAID architectures | Multimedia support |
| DS | Graph isomorphism | Variance |
| HCI | Low-fidelity (paper) prototyping | |
| IAS | Use of vetted security components | |
| IM | Declarative and navigational queries, use of links | |
| NC | Multiple Access Problem TCP Ethernet Switching | Fixed allocation (TDM, FDM, WDM) versus dynamic allocation Need for resource allocation Fairness |
| OS | Backups Processes and threads Multiprocessor issues (spin-locks, reentrancy) | Caching Deadlines and real-time issues Schedulers and policies |
| PD | Task-based decomposition Data-parallel decomposition Composition Symmetric multiprocessing (SMP) | Naturally (embarrassingly) parallel algorithms Implementation strategies such as threads Message buffering Message passing |
| PL | Definition | |
| SE | Continuous integration Software requirements elicitation Integration strategies Testing fundamentals Refactoring Software evolution Software reuse Components | Software configuration management and version control Tool integration concepts and mechanisms Evaluation and use of requirements specifications Product lines Non-functional requirements and their relationship to software quality |
| SF | Redundancy through check and retry | |
| SP | Context-aware computing Forms of professional credentialing | Accessibility issues, including legal requirements |
| KA.KU (Knowledge Area. Knowledge Unit) | 0.95 < Similarity | 0.90 < Similarity ≤ 0.95 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Fundamental Issues | Fundamental Issues | Basic Search Strategies | Basic Machine Learning | ||||||
| Tier 1 | Tier 2 | Tier 1 | Tier 2 | Tier 1 | Tier 2 | Tier 1 | Tier 2 | ||
| AL.Algorithmic strategies | 4 | 1 | 10 | 6 | 5 | 3 | |||
| AL.Basic analysis | 1 | 2 | |||||||
| AL.Basic automata, computability and complexity | 2 | 1 | |||||||
| AL.Fundamental data structures and algorithms | 1 | 1 | 2 | 1 | 1 | ||||
| AR.Assembly level machine organization | 4 | 2 | 1 | ||||||
| AR.Interfacing and communication | 3 | 1 | |||||||
| AR.Machine level representation of data | 1 | 1 | |||||||
| AR.Memory system organization and architecture | 1 | 1 | |||||||
| DS.Basic logic | 6 | 7 | 2 | ||||||
| DS.Basics of counting | 1 | 9 | 3 | ||||||
| DS.Discrete probability | 4 | 2 | 1 | 1 | |||||
| DS.Graphs and trees | 10 | 2 | 5 | 1 | |||||
| DS.Proof techniques | 9 | 4 | |||||||
| DS.Sets, relations, and functions | 14 | 6 | |||||||
| HCI.Designing interaction | 1 | 1 | |||||||
| IAS.Defensive programming | 3 | 2 | 1 | 1 | |||||
| IAS.Foundational concepts in security | 2 | 1 | |||||||
| IAS.Principles of secure design | 1 | ||||||||
| IM.Information management concepts | 1 | 1 | 3 | 2 | |||||
| NC.Introduction | 6 | 2 | 1 | ||||||
| NC.Local area networks | 5 | 2 | |||||||
| NC.Networked applications | 1 | 1 | |||||||
| NC.Reliable data delivery | 2 | 1 | |||||||
| NC.Resource allocation | 3 | 2 | |||||||
| NC.Routing and forwarding | 3 | ||||||||
| OS.Concurrency | 5 | 1 | 1 | 1 | |||||
| OS.Memory management | 1 | ||||||||
| OS.Overview of operating systems | 1 | ||||||||
| OS.Scheduling and dispatch | 2 | 2 | |||||||
| OS.Security and protection | 2 | 1 | |||||||
| PD.Communication and coordination | 4 | 2 | 5 | 1 | 1 | 2 | |||
| PD.Parallel algorithms, analysis, and programming | 1 | 2 | 1 | 1 | |||||
| PD.Parallel architecture | 2 | 2 | 1 | 2 | |||||
| PD.Parallel decomposition | 6 | 1 | 3 | ||||||
| PL.Basic type systems | 2 | 1 | |||||||
| PL.Functional programming | 2 | 1 | |||||||
| SDF.Algorithms and design | 3 | 6 | 1 | 3 | |||||
| SDF.Development methods | 5 | 2 | |||||||
| SDF.Fundamental data structures | 1 | 9 | 1 | 4 | |||||
| SE.Requirements engineering | 6 | 3 | 2 | ||||||
| SE.Software construction | 2 | 1 | |||||||
| SE.Software evolution | 1 | 9 | 1 | 4 | |||||
| SE.Software processes | 1 | ||||||||
| SE.Software verification and validation | 2 | 1 | |||||||
| SE.Tools and environments | 5 | 1 | |||||||
| SF.Cross-layer communications | 4 | 2 | 1 | 1 | |||||
| SF.Parallelism | 2 | ||||||||
| SF.Reliability through redundancy | 1 | ||||||||
| SF.State and state machines | 2 | 1 | |||||||
| SP.Analytical tools | 4 | 1 | 4 | 1 | |||||
| SP.Intellectual property | 2 | 1 | |||||||
| SP.Professional ethics | 1 | 3 | 1 | ||||||
| SP.Social context | 2 | 1 | 1 | ||||||
| Total | 53 | 6 | 10 | 111 | 84 | 6 | 7 | 45 | 40 |
| Range | Relevance | Necessity |
|---|---|---|
| 0.95 < Similarity | 3.74 | 3.74 |
| 0.95 Similarity > 0.9 | 3.49 | 3.58 |
| 0.9 Similarity > 0.8 | 3.08 | 3.20 |
| 0.8 Similarity > 0.7 | 3.07 | 3.14 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Woo, H.; Kim, J.; Lee, W. Analysis of Cross-Referencing Artificial Intelligence Topics Based on Sentence Modeling. Appl. Sci. 2020, 10, 3681. https://doi.org/10.3390/app10113681
Woo H, Kim J, Lee W. Analysis of Cross-Referencing Artificial Intelligence Topics Based on Sentence Modeling. Applied Sciences. 2020; 10(11):3681. https://doi.org/10.3390/app10113681
Chicago/Turabian StyleWoo, Hosung, JaMee Kim, and WonGyu Lee. 2020. "Analysis of Cross-Referencing Artificial Intelligence Topics Based on Sentence Modeling" Applied Sciences 10, no. 11: 3681. https://doi.org/10.3390/app10113681
APA StyleWoo, H., Kim, J., & Lee, W. (2020). Analysis of Cross-Referencing Artificial Intelligence Topics Based on Sentence Modeling. Applied Sciences, 10(11), 3681. https://doi.org/10.3390/app10113681