Noise-Robust Voice Conversion Using High-Quefrency Boosting via Sub-Band Cepstrum Conversion and Fusion


Abstract
Featured Application
Abstract
1. Introduction
2. Related Work
2.1. GMM-Based VC
2.2. BLSTM-Based VC
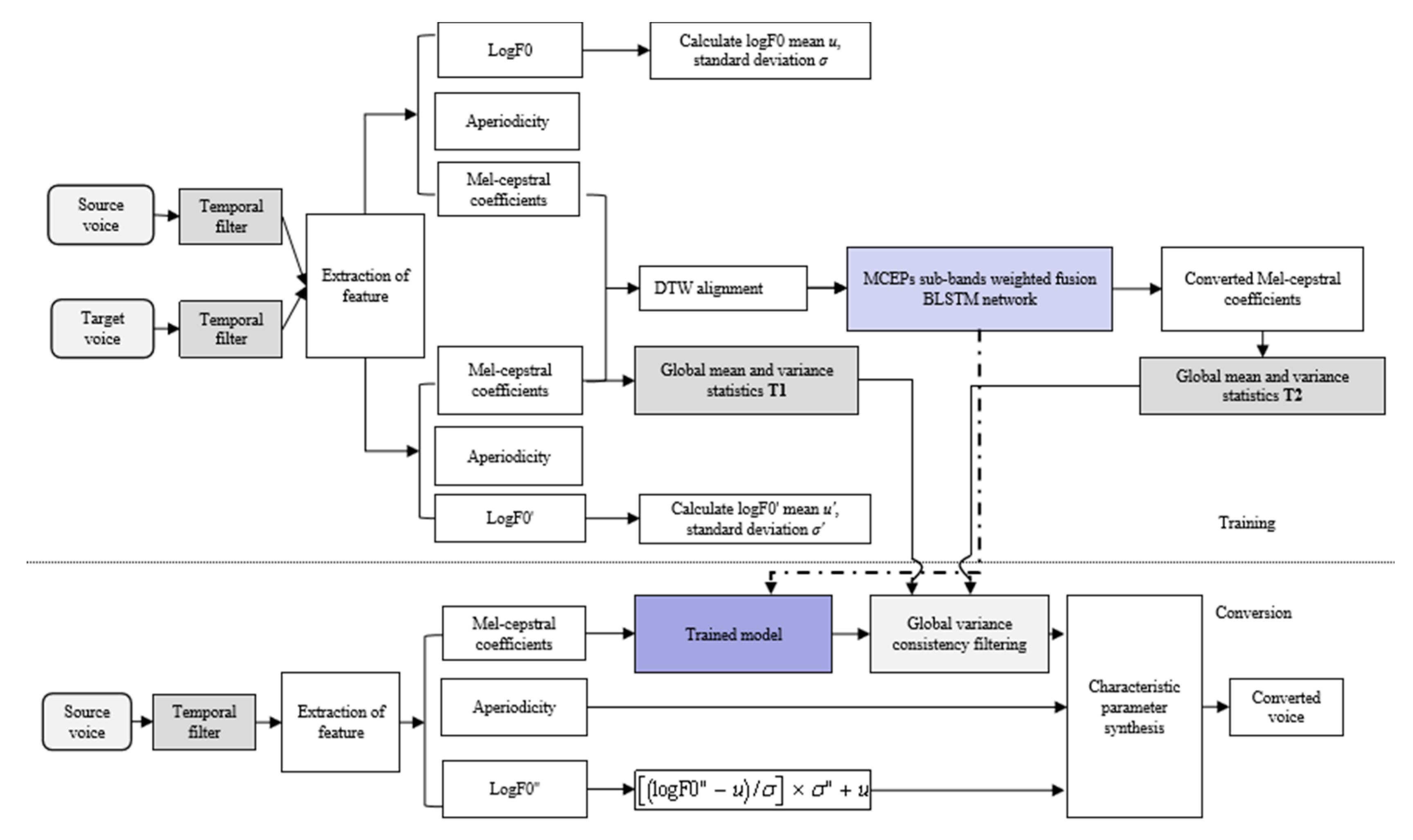
3. Proposed Method
3.1. Overall Architecture
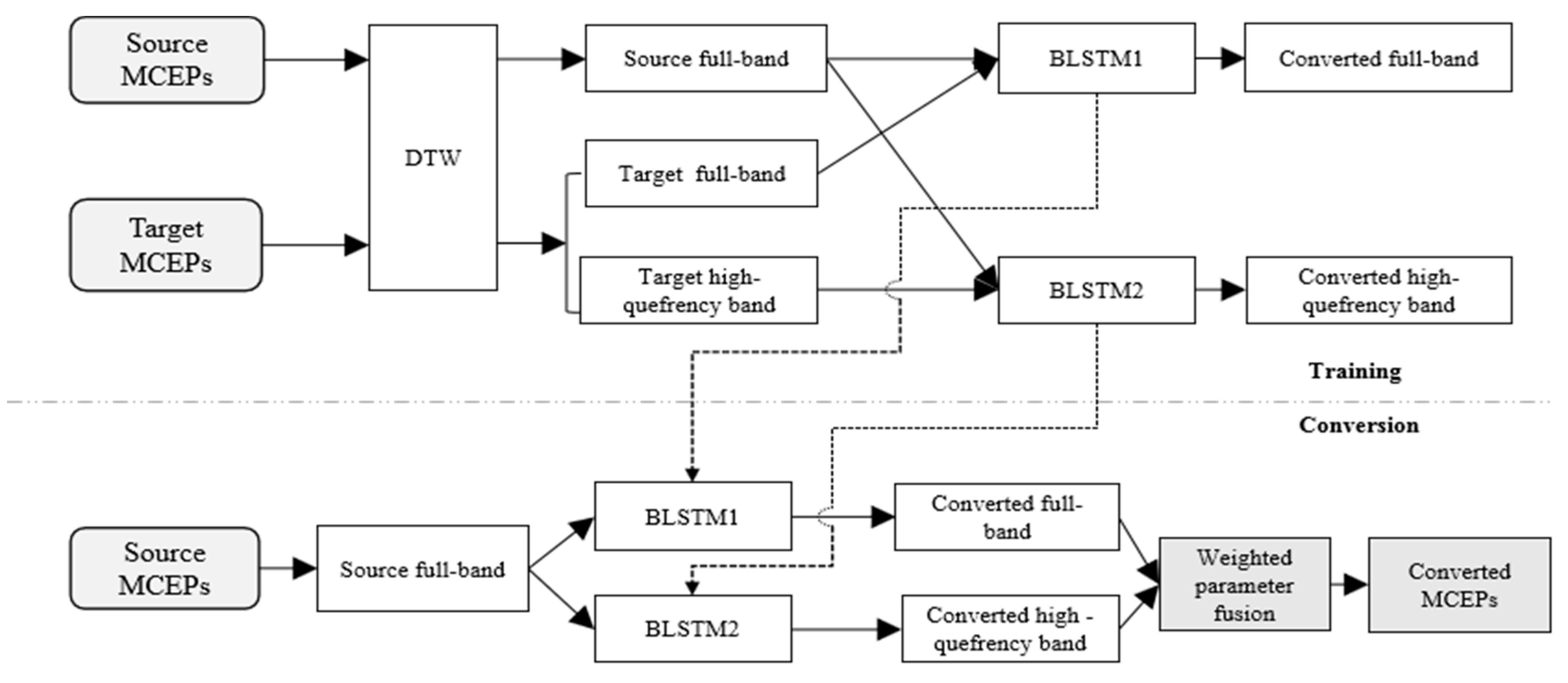
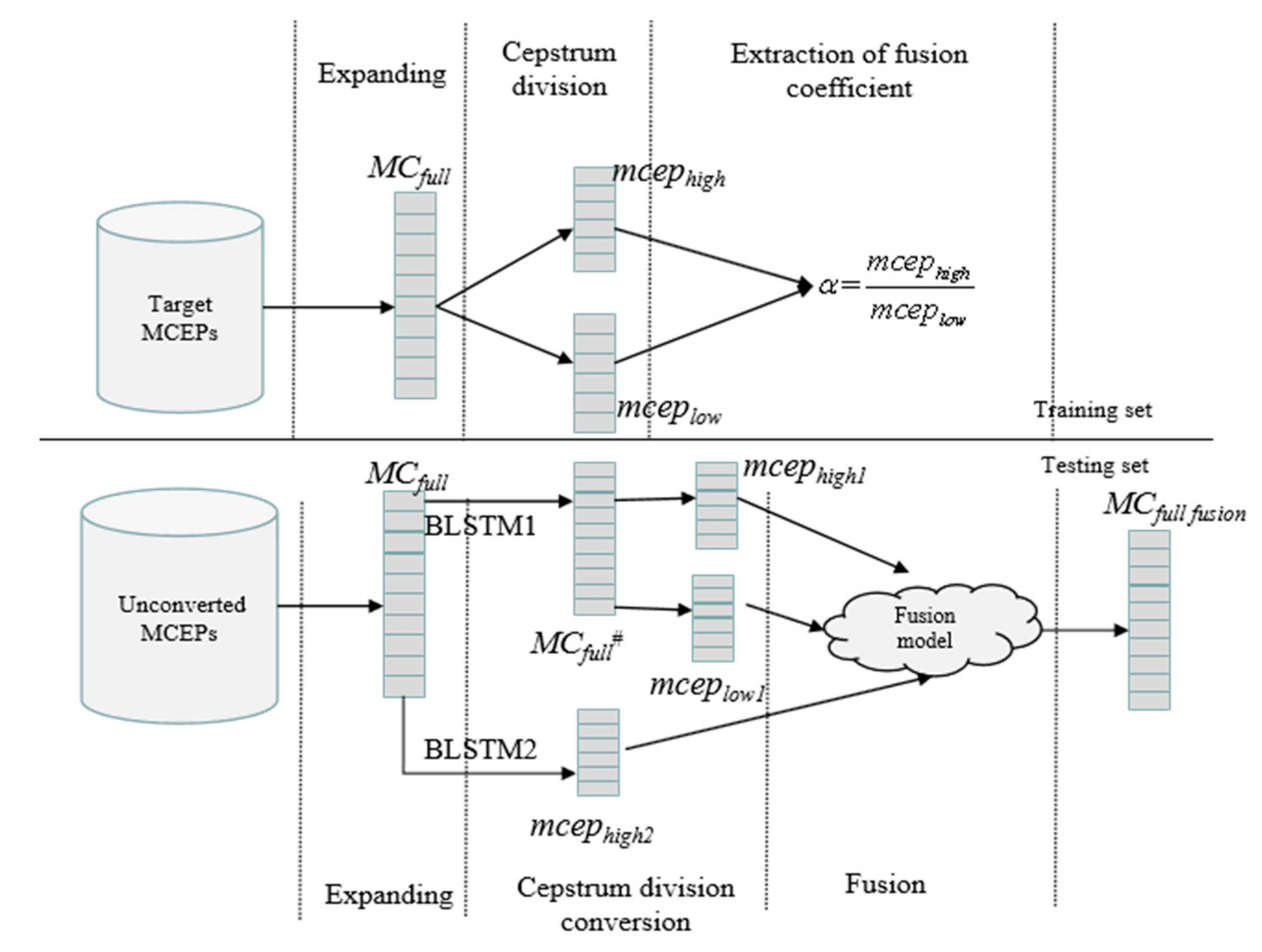
3.2. High-Quefrency Boosting via Sub-Band Cepstrum Conversion and Fusion
3.3. Time–Frequency Domain Filtering
- (1)
- The mean and variance of each one-dimensional MCEPs of the target sentences was calculated using Equation (10):where N, M, and T represent the number of target sentences in the training phase, the number of frames per sentence, and the dimension of MCEPs, respectively. denotes the ith dimensional MCEPs, and represent the mean and variance of MCEPs in the ith dimension of all the training sentences, respectively. tar represents the information from the target speaker.
- (2)
- Equation (10) was also used to calculate the mean and variance of all the converted MCEPs during the training phase and the MCEPs to be converted during the conversion phase. and represent the mean and variance in ith dimension of the converted MCEPs, respectively. con represents the information of the converted voice. The vector was constituted of each dimensional MCEP of sentences to be converted. The vector was constituted of the variance of each dimensional MCEP of sentences to be converted.
- (3)
- A global variance consistency filter was constructed to obtain the primary filtered data, as shown in Equation (11):where denotes the vector consisting of means of each dimension of the MCEPs of target sentences. denotes the vector consisting of the means of each dimension of MCEPs of the converted sentences. y denotes the MCEP vector of the sentences to be converted. is the output after the initial filtering.
- (4)
- As in Equation (12), α was set to adjust for the final filtering data:where is the final MCEPs after filtering.
4. Experiments and Results
4.1. Experimental Setup and Implementation Details
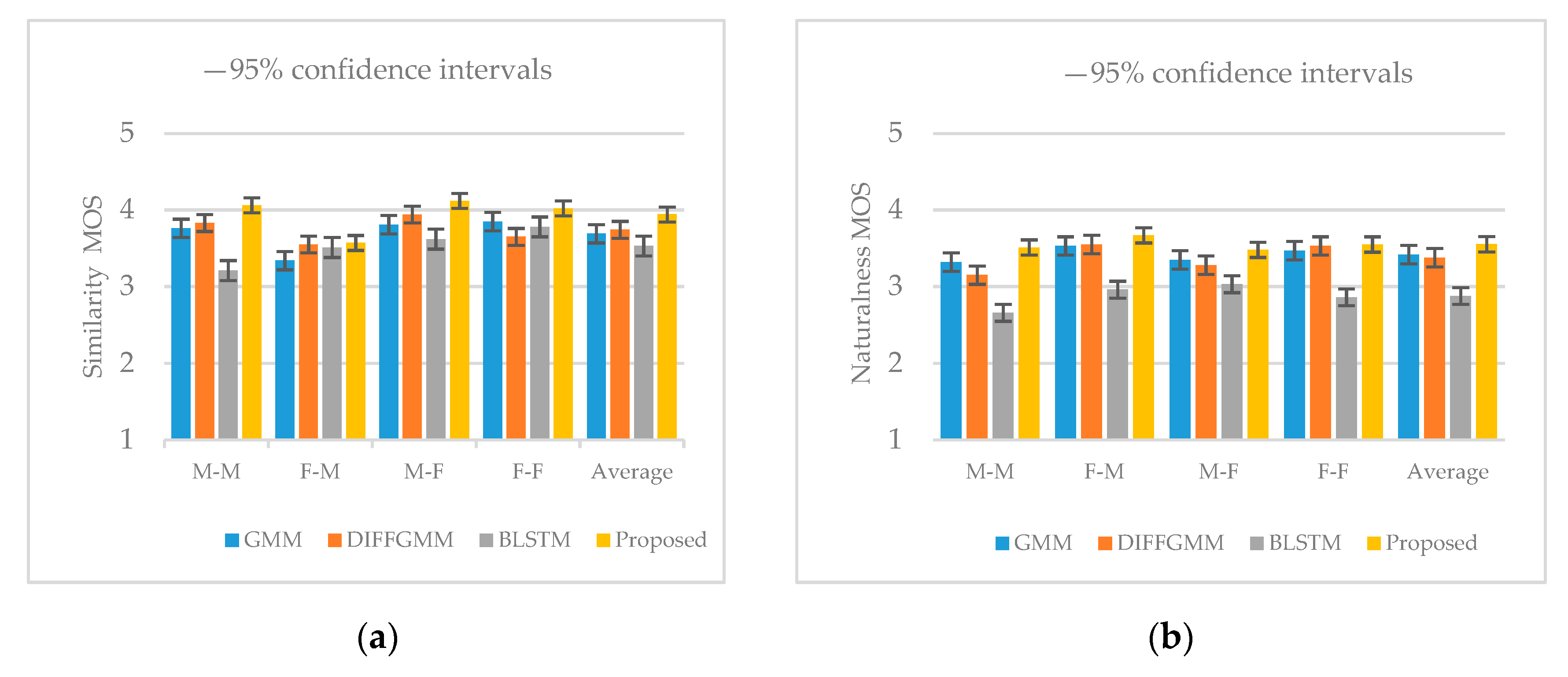
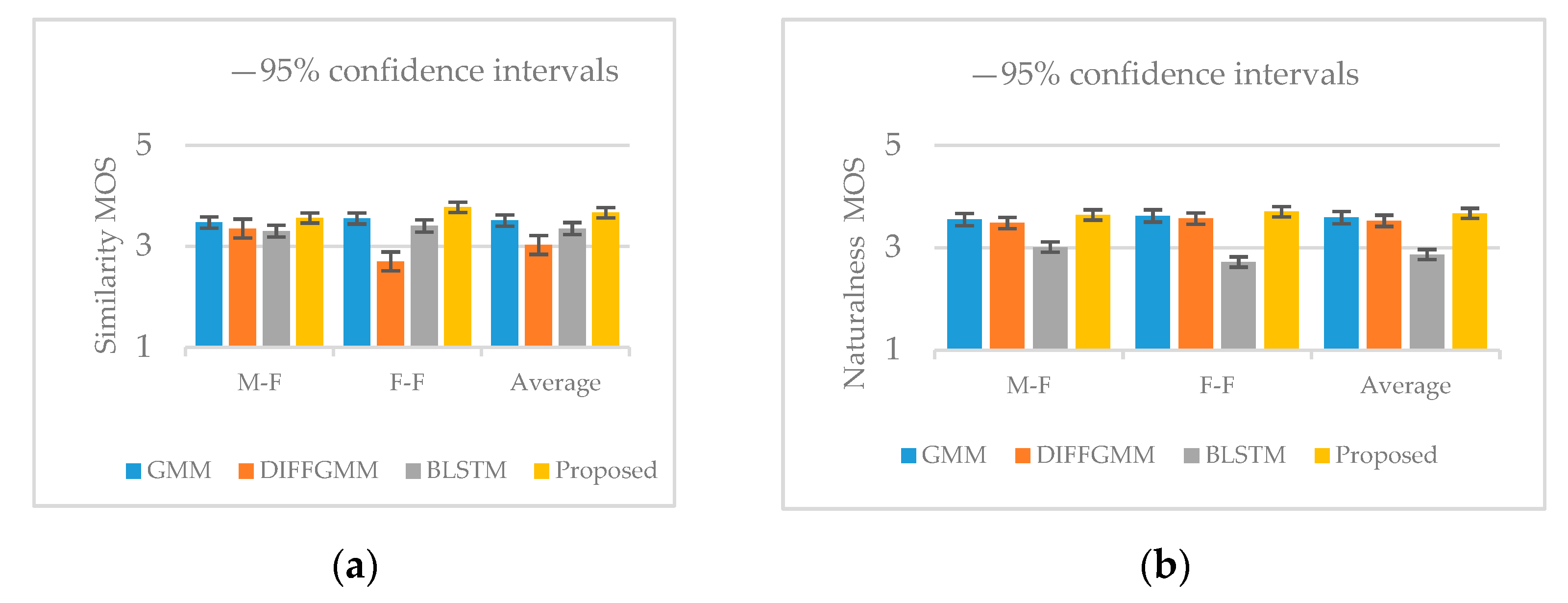
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Stylianou, A.Y.; Cappe, O.; Moulines, E. Continuous probabilistic transform for voice conversion. IEEE Trans. SAP 1998, 6, 131–142. [Google Scholar] [CrossRef]
- Toda, T.; Black, A.W.; Tokuda, K. Voice conversion based on maximum-likelihood estimation of spectral parameter trajectory. IEEE Trans. ASLP 2007, 15, 2222–2235. [Google Scholar] [CrossRef]
- Kurita, Y.; Kobayashi, K.; Takeda, K.; Toda, T. Robustness of Statistical Voice Conversion based on Direct Waveform Modification against Background Sounds. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 684–688. [Google Scholar]
- Kobayashi, K.; Toda, T.; Neubig, G.; Sakti, S.; Nakamura, S. Statistical Singing Voice Conversion with Direct Waveform Modification based on the Spectrum Differential. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 2514–2518. [Google Scholar]
- Kain, A.; Macon, M.W. Spectral voice conversion for text-to-speech synthesis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seattle, WA, USA, 12–15 May 1998; pp. 285–288. [Google Scholar]
- Wu, Z.; Li, H. Voice conversion and spoofing attack on speaker verification systems. In Proceedings of the APSIPA, Kaohsiung, Taiwan, 29 October–1 November 2013; pp. 1–9. [Google Scholar]
- Nakamura, K.; Toda, T.; Saruwatari, H.; Shikano, K. Speaking-aid systems using GMM-based voice conversion for electrolaryngeal speech. Speech Commun. 2012, 54, 134–146. [Google Scholar] [CrossRef]
- Deng, L.; Acero, A.; Jiang, L.; Droppo, J.; Huang, X. High-performance robust speech recognition using stereo training data. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Salt Lake City, UT, USA, 7–11 May 2001; pp. 301–304. [Google Scholar]
- Niwa, J.; Yoshimura, T.; Hashimoto, K.; Oura, K.; Nankaku, Y.; Tokuda, K. Statistical voice conversion based on wavenet. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5289–5293. [Google Scholar]
- Miao, X.K.; Zhang, X.W.; Sun, M.; Zheng, C.Y.; Cao, T.Y. A BLSTM and WaveNet based Voice Conversion Method with Waveform Collapse Suppression by Post-processing. IEEE Access 2019, 7, 54321–54329. [Google Scholar] [CrossRef]
- Helander, E.; Virtanen, T.; Nurminen, J.; Gabbouj, M. Voice conversion using partial least squares regression. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 912–921. [Google Scholar] [CrossRef]
- Erro, D.; Alonso, A.; Serrano, L.; Navas, E.; Hernáez, I. Towards physically interpretable parametric voice conversion functions. In Proceedings of the 6th Advances in Nonlinear Speech Processing International Conference, Mons, Belgium, 19–21 June 2013; pp. 75–82. [Google Scholar]
- Tian, X.; Wu, Z.; Lee, S.W.; Hy, N.Q.; Chng, E.S.; Dong, M. Sparse representation for frequency warping based voice conversion. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4235–4239. [Google Scholar]
- Kawahara, H.; Masuda-Katsuse, I.; Cheveigne, A. Restructuring speech representations using a pitch-adaptive time frequency smoothing and an instantaneous-frequency-based f0 extraction: Possible role of a repetitive structure in sounds. Speech Commun. 1999, 27, 187–207. [Google Scholar] [CrossRef]
- Sun, L.; Kang, S.; Li, K.; Meng, H. Voice conversion using deep Bidirectional Long Short-Term Memory based Recurrent Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4869–4873. [Google Scholar]
- Nguyen, H.Q.; Lee, S.W.; Tian, X.; Dong, M.; Chng, E.S. High quality voice conversion using prosodic and high-resolution spectral features. Multimed. Tools Appl. 2016, 75, 5265–5285. [Google Scholar] [CrossRef]
- Desai, S.; Black, A.W.; Yegnanarayana, B.; Prahallad, K. Spectral mapping using artificial neural networks for voice conversion. IEEE/ACM Trans. Audio Speech Lang. Process. 2010, 18, 954–964. [Google Scholar] [CrossRef]
- Takashima, R.; Takiguchi, T.; Ariki, Y. Exemplar-based voice conversion using sparse representation in noisy environments. IEICE Trans. Inf. Syst. 2013, 96, 1946–1953. [Google Scholar] [CrossRef]
- Wu, Z.; Virtanen, T.; Chng, E.S.; Li, H. Exemplar-based sparse representation with residual compensation for voice conversion. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1506–1521. [Google Scholar]
- Lorenzo-Trueba, J.; Yamagishi, J.; Toda, T.; Saito, D.; Villavicencio, F.; Kinnunen, T.; Lin, Z.H. The Voice Conversion Challenge 2018: Promoting Development of Parallel and Nonparallel Methods. In Proceedings of the Odyssey 2018 The Speaker and Language Recognition Workshop, Les Sables d’Olonne, France, 26–29 June 2018. [Google Scholar]
- Dudley, H. Remaking Speech. J. Acoust. Soc. Am. 1939, 11, 169–177. [Google Scholar] [CrossRef]
- Kobayashi, K.; Toda, T.; Nakamura, S. F0 transformation techniques for statistical voice conversion with direct waveform modification with spectral differential. In Proceedings of the SLT, San Diego, CA, USA, 13–16 December 2016; pp. 693–700. [Google Scholar]
- Toda, T.; Saruwatari, H.; Shikano, K. Voice conversion algorithm based on Gaussian mixture model with dynamic frequency warping of STRAIGHT spectrum. In Proceedings of the ICASSP, Salt Lake City, UT, USA, 7–11 May 2001; pp. 841–844. [Google Scholar]
- Toda, T.; Black, A.W.; Tokuda, K. Spectral conversion based on maximum likelihood estimation considering global variance of converted parameter. In Proceedings of the ICASSP, Philadelphia, PA, USA, 18–23 March 2005; Volume 1, pp. 9–12. [Google Scholar]
- Kobayashi, K.; Toda, T. sprocket: Open-source voice conversion software. In Proceedings of the Odyssey 2018 The Speaker and Language Recognition Workshop, Les Sables d’Olonne, France, 26–29 June 2018. [Google Scholar]
- Martin, W.; Angeliki, M.; Nassos, K.; Björn, S.; Shrikanth, N. Analyzing the memory of BLSTM Neural Networks for enhanced emotion classification in dyadic spoken interactions. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4157–4160. [Google Scholar]
- Ming, H.; Huang, D.; Xie, L.; Wu, J.; Dong, M.; Li, H. Deep Bidirectional LSTM Modeling of Timbre and Prosody for Emotional Voice Conversion. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016. [Google Scholar]
- Morise, M.; Yokomori, F.; Ozawa, K. WORLD: A vocoderbased high-quality speech synthesis system for real-time applications. IEICE Trans. Inf. Syst. 2016, 99, 1877–1884. [Google Scholar] [CrossRef]
- Ohtani, Y.; Toda, T.; Saruwatari, H.; Shikano, K. Maximum likelihood voice conversion based on GMM with STRAIGHT mixed excitation. In Proceedings of the ICSLP, Pittsburgh, PA, USA, 17–21 September 2006. [Google Scholar]
- Kominek, J.; Black, A.W. The CMU Arctic speech databases. In Proceedings of the Fifth ISCA Workshop on Speech Synthesis, Pittsburgh, PA, USA, 14–16 June 2004. [Google Scholar]
- Wang, D.; Zhang, X.W. THCHS-30: A Free Chinese Speech Corpus. arXiv 2015, arXiv:1512.01882v2. [Google Scholar]
- Tian, X.H.; Chng, E.S.; Li, H.Z. A Speaker-Dependent WaveNet for Voice Conversion with Non-Parallel Data. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 201–205. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MCD (dB) | ||||
|---|---|---|---|---|
| Methods | M-M (bdl-jmk) | F-M (clb-jmk) | M-F (bdl-slt) | F-F (clb-slt) |
| Source–target | 10.682 | 12.763 | 10.755 | 9.896 |
| GMM | 9.084 | 10.732 | 8.836 | 9.635 |
| DIFFGMM | 8.513 | 10.214 | 9.253 | 9.716 |
| BLSTM | 8.210 | 9.401 | 7.485 | 8.032 |
| Proposed | 8.013 | 8.874 | 7.180 | 7.822 |
| MCD (dB) | ||
|---|---|---|
| Methods | Cross-Gender (A8–A2) | Intra-Gender (A2–A23) |
| Source–target | 11.873 | 11.507 |
| GMM | 10.326 | 8.794 |
| DIFFGMM | 10.207 | 8.958 |
| BLSTM | 6.964 | 7.421 |
| Proposed | 6.786 | 7.155 |
| HQMCD (dB) | |
|---|---|
| Methods | Cross-Gender (bdl-slt) |
| Source–target | 1.131 |
| GMM | 0.946 |
| DIFFGMM | 1.166 |
| BLSTM | 0.912 |
| Proposed | 0.713 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miao, X.; Sun, M.; Zhang, X.; Wang, Y. Noise-Robust Voice Conversion Using High-Quefrency Boosting via Sub-Band Cepstrum Conversion and Fusion. Appl. Sci. 2020, 10, 151. https://doi.org/10.3390/app10010151
Miao X, Sun M, Zhang X, Wang Y. Noise-Robust Voice Conversion Using High-Quefrency Boosting via Sub-Band Cepstrum Conversion and Fusion. Applied Sciences. 2020; 10(1):151. https://doi.org/10.3390/app10010151
Chicago/Turabian StyleMiao, Xiaokong, Meng Sun, Xiongwei Zhang, and Yimin Wang. 2020. "Noise-Robust Voice Conversion Using High-Quefrency Boosting via Sub-Band Cepstrum Conversion and Fusion" Applied Sciences 10, no. 1: 151. https://doi.org/10.3390/app10010151
APA StyleMiao, X., Sun, M., Zhang, X., & Wang, Y. (2020). Noise-Robust Voice Conversion Using High-Quefrency Boosting via Sub-Band Cepstrum Conversion and Fusion. Applied Sciences, 10(1), 151. https://doi.org/10.3390/app10010151