Abstract
Automated text generation (ATG) technology has evolved rapidly in the last several years, enabling the spread of content produced by artificial intelligence (AI). In addition, with the release of ChatGPT, virtually everyone can now create naturally sounding text on any topic. To optimize future use and understand how humans interact with these technologies, it is essential to capture people’s attitudes and beliefs. However, research on ATG perception is lacking. Based on two representative surveys (March 2022: n1 = 1028; July 2023: n2 = 1013), we aimed to examine the German population’s concepts of and attitudes toward AI authorship. The results revealed a preference for human authorship across a wide range of topics and a lack of knowledge concerning the function, data sources, and responsibilities of ATG. Using multiple regression analysis with k-fold cross-validation, we identified people’s attitude toward using ATG, performance expectancy, general attitudes toward AI, and lay attitude toward ChatGPT and ATG as significant predictors of the intention to read AI-written texts in the future. Despite the release of ChatGPT, we observed stability across most variables and minor differences between the two survey points regarding concepts about ATG. We discuss the findings against the backdrop of the ever-increasing availability of automated content and the need for an intensive societal debate about its chances and limitations.
1. Introduction
Public awareness of the terms automated text generation (ATG), natural language generation (NLG), or large language models (LLM) has grown. The November 2022 release of ChatGPT—a language model developed by the company OpenAI with the capability of generating human-like text in a conversational manner—has fueled the attention to this subfield of artificial intelligence (AI). In detail, NLG is “the subfield of artificial intelligence and computational linguistics that is concerned with the construction of computer systems that can produce understandable texts […] from some underlying non-linguistic representation of information” [1,2]. While the output is always text, the input can vary substantially [3], including flat semantic representations, numerical data, or structured knowledge bases [4]. ATG is a particular type of NLG where natural-sounding text is generated through algorithmic processes with limited human intervention [5]. Already before ChatGPT’s release, these automatically produced texts were no longer distinguishable on a linguistic level from those written by humans [6,7]. What is new, however, is that through the wider availability of ATG technology for a broad population, written text will be more and more automatically created. Moreover, unlike previous customer service chatbots, users interact with open access LLMs such as ChatGPT without a particular purpose. Instead, it is a communicative object in itself [2], providing language translation, summarization, or question answering, all in one tool [8]. Additionally, the underlying technology makes ChatGPT’s output unique compared to automatically written text which existed before. Based on a vast amount of data, LLMs have learned how people use written language and how writing works on a statistical level. This makes applications like ChatGPT specifically different from previous ones, such as those used in automated journalism. Due to the fact that the training data are not stored and the output generation does not follow transparently predetermined rules, it is neither predictable nor fully controllable. Consequently, what defines LLMs and leads to the high quality of their output is also one of their most significant weaknesses and dangers for potential users unaware of the genesis of the resulting text.
Among the first to apply ATG technology systematically were news media organizations that used the more rule-based approaches of ATG to automate news reporting (e.g., Associated Press, Forbes, Washington Post). However, the e-commerce sector was also fast to recognize the potential for automating product descriptions, for instance. This shows that AI-generated content has already existed on the internet for over a decade, but the public perception and awareness of this AI subfield has hardly been investigated. However, the release of ChatGPT threw a spotlight on the technological possibilities of generating human-sounding language. GPT-4 (the underlying model of ChatGPT) and other language models like BERT (Google) or XLNet (Microsoft) now have the potential to revolutionize the way people write, perceive, and use text in all contexts. A prerequisite for realizing the full potential of these AI technologies is that users and readers accept and adopt them [9]. While speech-based applications like voice assistants have been known to many for several years, more creative approaches of NLG on more complex topics and data are not very common and hardly salient in public (e.g., Open Research Knowledge Graph). Currently, there is a discrepancy between small groups of people firmly dealing with the benefits of LLMs in general (ranging from individuals revising their complete working process to companies implementing NLG wherever possible) and a large population for whom this technology still is not a reality. However, unlike other AI subfields, such as in the medical context, ATG is no longer just a niche topic for researchers or developers. No more does it concern only those actively using the technology. The amount of AI-generated content on the internet is growing, with some forecasting that the quantity of synthetically generated content will be up to 90% by 2026 [10]. As AI content will become more prevalent in print media, too, consumers will increasingly encounter automatically written text, often without realizing it, especially online. Therefore, it is crucial and unavoidable that consumers deal with AI authorship and develop pertinent opinions. However, a fundamental issue is the general population’s lack of awareness of automated texts due to inadequate labeling requirements: it is mostly not labeled or only identified by a single byline. To date, this makes it questionable if and to what extent readers have perceived content to be automatically generated.
In the last decade, many (primarily qualitative) investigations have dealt with journalists’ perspectives on this technology, often through job replacement scenarios [11,12,13,14]. Investigations into readers’ perceptions, attitudes, and beliefs concerning automatically produced content are rare. Consequently, a thoughtful debate about societal, ethical, economic, and juridical implications is late in coming [15]. In short, with the release of ChatGPT, a highly developed technology is accessible to virtually everyone with internet access. At the same time, potential users have not had the time to foster a sharpened awareness of the chances and risks this technology brings.
1.1. Automated Journalism
Before the release of ChatGPT, one of the most popular ATG application areas was the automation of news reporting, also known as automated journalism or robot journalism. Several studies have investigated readers’ perceptions and acceptance of automated short news and the novel source cue “AI authorship”. However, the findings concerning the perceived credibility of the content and the author are inconsistent. Some studies found that readers perceived AI-written texts as less credible [16], readable [17], and accurate [18]. Others found AI vs. human written texts to be perceived as equal in expertise, trustworthiness [19], and credibility [20,21,22,23,24]. Moreover, some studies found that AI-written texts were perceived as more credible, objective, and balanced [6,17,25] than human-written texts. However, a meta-analysis across different topics of short news reporting shows that differences, if found, were relatively small [26].
These studies have mainly investigated very number-based topics like weather forecasts, earthquake information, or financial reports, for instance. However, the topics’ content and reporting style might be essential to the findings. The information presented in a weather forecast or a product description leaves little room for interpretation and stylistic creativity. Advantages of algorithms like accuracy or objectivity, as postulated by the machine heuristic [27], might predominate here. Moreover, even if the author is noticed, the person reporting about these number- and data-driven topics might not be of much interest to the reader, which could explain the relatively minor differences found so far. However, even when using a more complex and detailed topic, Lermann Henestrosa et al. [28] found no differences concerning perceived credibility and trustworthiness between an AI and a human author. They discovered at the same time that the AI author was perceived to be less anthropomorphic and intelligent.
1.2. Algorithm Aversion
Evidence shows that people have specific expectations toward AI and algorithms in particular contexts. The word-of-machine-effect describes the belief that AI recommenders are more competent than human recommenders in utilitarian vs. hedonistic realms [29]. In addition, the machine heuristic is a cognitive shortcut when ascribing accuracy or lack of bias to an algorithm when performing certain tasks, for instance, a job in online transactions [27,30]. In line with these findings, algorithm aversion describes the consumers’ preference for a human when a task is subjective by nature [31] or concerned with moral decisions because machines are thought to lack a mind and emotions [32]. AI has also been perceived as less competent in giving advice for addressing societal challenges [33]. Applied to AI authorship, Tandoc, Yao, and Wu [23] found a decrease in source and message credibility when the AI was perceived to write non-objectively. In another study, message credibility decreased for both the human and the AI author when the information was presented evaluatively vs. neutrally [28]. With the expanding applicational possibilities of ATGs allowing for the generation of human-sounding text to any possible topic, more research on the perception of AI authorship in different contexts is necessary.
1.3. Surveys on AI and ATG Perception
An online survey by a local initiative for the media and digital scene in Hamburg, Germany, revealed that in 2018, 49% of the respondents were skeptical toward automated news and robot journalism, and 28% considered it “bad”, while 20% considered it to depend on the topic [34]. Moreover, in a follow-up survey in 2019, 77% of the respondents demanded that automatically produced content be recognizable as such, while only 39% could distinguish between an actual AI-written text and a human-written one [35]. Interestingly, the wording of the questions in this survey suggested that the prevalence of AI-written texts would be realized only in the future.
A survey among American adults in 2022 revealed a general awareness of the public toward AI in daily life, but only three in ten identified all uses of AI provided in the survey correctly [36]. Another representative survey among the German population investigating the general beliefs and attitudes toward algorithms revealed in 2018 that 45% of the respondents could not indicate what an algorithm is. This knowledge gap was accompanied by skepticism toward algorithms, with 79% of the respondents indicating that they preferred human decisions [37]. Also, different applicational fields of algorithms were not known to a majority but became better known in 2022 [15]. In a recent replication, the authors found evidence for a connection between familiarity and acceptance of automized decisions, with decisions being considered more acceptable and the respondents being more familiar with the potential field of application [15]. The term algorithm can stand for a simple mathematical function or a highly complex algorithm for data encryption. However, specific knowledge about certain applications and their underlying technology is often irrelevant to users. But, as ATG is now dominating public debate, it is necessary to investigate what people currently think about this specific AI.
1.4. The Current Research
According to the most prominent theory for predicting the acceptance of technology, the technology acceptance model (TAM) [9,38], the adoption of a specific technology is primarily determined by users’ performance expectancy and effort expectancy, which influence the attitude toward using it and finally the intention and actual usage of technology. In addition, the evaluation of automatically produced content might depend on participants’ attitudes toward AI in general. Darda et al. [39] found that a positive attitude toward AI leads to higher ratings for both automated and human-generated content. Furthermore, discussions around AI fields like automated driving or AI in healthcare were not based on tools suddenly accessible to everyone. In these areas, the focus lies more on the decisions made by AI rather than on the underlying technology that leads to them. This is problematic with tools like ChatGPT, where the information provided will probably be judged based on the user’s beliefs about the perceived sources, for instance. However, systematic surveys about people’s beliefs, experience, or knowledge concerning specific AI fields are rare, with the majority dealing with perceptions of AI in general or in the medical context [40,41,42,43] and surveys even leaving out the specific field of ATG entirely [44]. To the best of our knowledge, there is no current investigation specifically on people’s beliefs about ATG or their concepts about its function, responsibilities, or data sources.
In view of these considerations and research gaps, we posed the following research questions: What attitudes, perceptions, and knowledge does the German population have toward ATG? Have these attitudes, perceptions, and knowledge changed over time, specifically since the release of ChatGPT as a critical event? Additionally, we exploratively investigated people’s behavioral intentions to consume ATG by using several predictors as suggested by the TAM.
This design made observing a potential change in the data over time possible. Both surveys asked questions about attitude toward ATG, while the second survey included additional questions about ChatGPT to take this event into account as a potential influencing factor. Finally, with its representation of different ages, genders, and educational levels, this study aimed to shed light on differences in the population concerning these subgroups.
2. Methods
2.1. Sample
The study was conducted in accordance with the guidelines of the Local Ethics Committee of the Leibniz-Institut für Wissensmedien, which approved the study design and methods (Approval number: LEK 2023/022). Written informed consent was obtained from all participants involved in the study. Participants were invited to complete the online survey via the online market research platform Mingle in March 2022 (Study 1) and in June 2023 (Study 2). To assure representativeness in terms of age, gender, and education among the German population over 18 years old, quotas were defined in advance. Responses to all questions were voluntary, but participants were only included in the analyses when they had finished the entire survey. Therefore, exclusion criteria were only premature dropout and missing consent to the use of the data. The survey took 10–15 min in the first and 15–20 min in the second census. Each participation was compensated within Mingle’s internal reward system.
The Pearson’s correlation coefficient with the final sample size of n1 = 1028 and n2 = 1013 participants was sufficient to detect correlational effects of r = 0.088 with 80% power (alpha = 0.05, two-tailed), according to sensitivity power analysis (G*Power). In other words, correlations greater than r = 0.088 could be reliably detected.
The participants in Study 1 were on average M1 = 46.90 (SD1 = 15.28) years old (range = 18–73 years). The participants in Study 2 had a mean age of M2 = 45.58 (SD2 = 14.27) years (range = 18–69). Table 1 shows the absolute and relative distributions by survey for gender, education, and age.

Table 1.
Absolute and relative (in percent) numbers of participants in Studies 1 and 2 by gender, education level, and age group. The German education system differentiates between qualifications after the 9th (low), 10th (middle), and 12th or 13th grade (high). Respondents indicating having no degree (n1 = 13, n2 = 4) are included in the low level.
2.2. Measures and Procedure
In the following paragraphs, we describe the measures and procedure of both surveys, as Study 2 was conducted in the same way as Study 1 apart from several additional questions concerning ChatGPT. After giving informed consent and their initial screening with respect to age, gender, and education, respondents were redirected to the survey platform Qualtrics (Provo, UT, USA).
First, self-assessed knowledge about AI in general was captured with a single item from 1 = no knowledge about AI to 5 = comprehensive knowledge about AI.
Afterwards, participants were briefly introduced to the topic and were presented with a general definition of AI, followed by a section about AI in general.
General attitudes toward AI were assessed by using a 20-item instrument [45]. The measure comprised 12 positively (e.g., “There are many useful applications of AI”) and eight negatively phrased sentences (e.g., “I think AI systems make many mistakes”). These were worded to express a general attitude toward AI systems mainly in society and in the work context. The items were measured on 5-point Likert-scales from 1 = absolutely disagree to 5 = absolutely agree.
The belief in the machine heuristic [27] was used to further measure participants’ assessment of AI. Participants were asked for their degree of agreement, from 1 = absolutely disagree to 5 = absolutely agree, with four adjectives for an AI when performing a task (“unbiased”, “error-free”, “objective”, and “accurate”).
Then, participants were asked if and how often they used different speech-based applications (e.g., voice-based assistants, chatbots, translation systems) in order to examine experience with AI-based writing- and voice-software among the population (5-point scale from 1 = never to 5 = constantly). Moreover, we asked if and how often they used different media types (e.g., TV, radio, magazines) to obtain information about scientific topics. To both questions “ChatGPT” was added as an option in Study 2, which served to analyze further the subgroups with and without ChatGPT experience. Only participants who indicated having used ChatGPT were presented with the attitude toward ChatGPT scale.
Subsequently, we assessed participants’ experience with ATG. Participants were asked if they had ever heard about the fact that AI is able to write texts (Heard about ATG) and if they had ever consciously read an AI-written text (Read an AI generated text), both on 5-point single items from 1 = never to 5 = constantly. If participants indicated with at least item 2 = seldom to have read a text written by AI, they were redirected to an open response field and were asked to state the type of text(s) they had read so far.
At this point in Study 2, a knowledge test about ATG followed. The test covered 15 partly adapted [46] statements, for which participants had to decide whether they were true, false, or if they didn’t know (e.g., “Humans can still easily recognize AI-generated speech as artificial speech”).
In both surveys, a short description and definition of ATG and automated journalism followed to assure that every participant had at least a basic understanding of the subject matter. To keep it as simple as possible, we consistently used the phrases “AI-written text” or “AI-generated text”.
The definition was followed by a set of self-generated statements to examine people’s conceptions about ATG. The scales referred to the mode of ATG’s function (ATG functionality), the source of the automatically written texts’ content (data sources), the extent of control participants believed a human has over an AI-written text (human control), and who they believed was responsible for the content (content responsibility). Participants rated their perceived likelihood of each item (5-point scales from 1 = not at all to 5 = for certain).
People’s understanding about ATG functionality was assessed by four statements in Study 1 (e.g., “The AI uses existing words and texts and reassembles them”). In Study 2, the item “The AI calculates the word that is most likely to follow next” was added, as this applies to the LLM underlying ChatGPT. Respondents’ belief about the data sources was assessed by five items in Study 1 (e.g., “The AI produces the content itself, without human intervention”). In Study 2, the item “The AI has been trained with certain content, which it then draws on” was added, as this is a more precise description of ChatGPT’s functionality. To assess people’s belief about human control, we presented three items in Study 1 (e.g., “The human sees the final product and edits it if necessary”). Again, in Study 2, the item “The end product is only indirectly controlled by humans (via built-in rules)” was added. Then, participants were presented with eight entities (e.g., “programmer” or “AI itself”) for which they had to indicate the likelihood that one or the other was responsible for the produced content.
The concepts section was followed by five adapted subscales from the UTAUT-instrument (Unified Theory of Acceptance and Use of Technology) [9] to measure specific attitudes toward AI-written texts. All items were measured on 5-point Likert scales from 1 = absolutely disagree to 5 = absolutely agree.
Three items were presented concerning performance expectancy (e.g., “I would find AI-written texts useful”), three items concerning effort expectancy (e.g., “I think AI-written texts are clear and understandable”), four items concerning participants’ attitude toward using ATG (AT; e.g., “AI-written texts would make information retrieval more interesting”), three items concerning anxiety (e.g., “AI-written texts are somewhat intimidating to me”), and three items concerning behavioral intentions to consume ATG (e.g., “I intend to read AI-written texts in the future”). To assess participants’ attitude toward what an AI should be permitted to write (permission to write like a human), we added four self-created items (e.g., “AI should be allowed to write about the same topics humans do”).
At the end of the specific attitudes block, participants were asked how likely (5-point scales from 1 = not at all to 5 = for certain) they would be to read an AI-written text on 18 different news media topics (e.g., politics, society, or weather forecasts). Afterwards, the identical list of topics was presented again, asking participants to indicate if they could choose freely by whom they would prefer to read about each topic (“preferably by a human being”, “no preference”, “preferably by an AI”).
In Study 2, participants who had experience with ChatGPT were asked to indicate their agreement to 16 statements addressing their attitude toward ChatGPT (e.g., “I am satisfied with ChatGPT’s answers”; 5-point Likert scale from 1 = absolutely disagree to 5 = absolutely agree).
Finally, independently of their prior experience, all participants in Study 2 were presented with a definition of ChatGPT and were afterwards asked about their lay attitude toward ChatGPT and ATG by indicating their agreement with nine statements (e.g., “I’m optimistic about the impact of automated text generation (e.g., ChatGPT) on society”; 5-point Likert scale from 1 = absolutely disagree to 5 = absolutely agree).
3. Results
3.1. General Attitudes toward AI
Participants’ answers on the item concerning their self-assessed knowledge about AI are displayed separated by gender and study (Figure 1) and by education and study (Figure 2). Table 2 shows the means, standard deviations, and Cronbach alpha values for all single items and scales by study. In addition, exploratory t-tests for independent samples were conducted to compare the two time points. Furthermore, the relationships between the variables in Study 2 are depicted by Figure 3 showing the correlations between all Likert-type variables and the knowledge test (for means and standard deviations of all variables separated by age groups, see Supplementary Table S1).
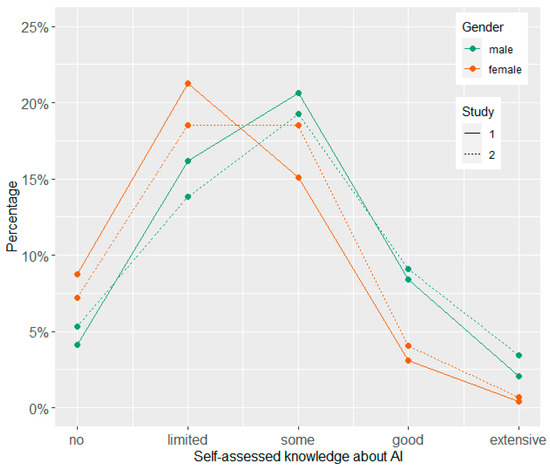
Figure 1.
Self-assessed knowledge about AI by gender and study survey.
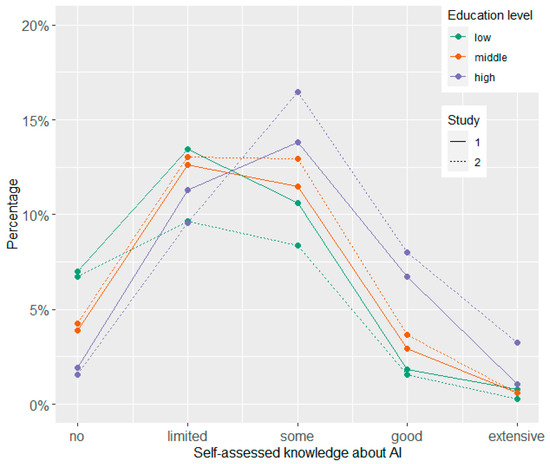
Figure 2.
Self-assessed knowledge about AI by education level and study survey.
Table 2.
Mean, standard deviation, and Cronbach alpha for all variables (number of items in brackets) by study and differences in means (ΔM) with Cohen’s d, tested using exploratory unpaired t-tests; * p < 0.05, ** p < 0.01, *** p < 0.001. All variables except for knowledge were measured on 5-point scales.
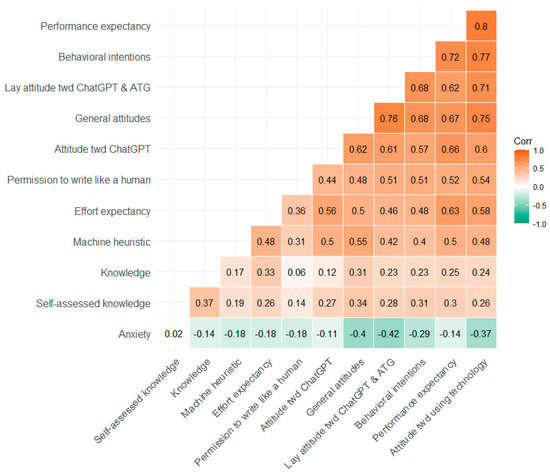
Figure 3.
Correlation matrix for all Likert-type variables and the knowledge test in Study 2. The responses of the knowledge test were re-coded for the purpose of the analyses, i.e., the answer option “don’t know” was coded as 0 = false response.
Due to the poor internal consistency of the scale, which indicates that the items covered different aspects, participants’ answers to each of the four self-created items capturing the permission to write like a human are presented separately. The means and standard deviations by study were as follows: M1 = 2.98 (SD1 = 1.06) and M2 = 3.05 (SD2 = 1.09) for “AI should be allowed to write about the same topics as humans”, M1 = 3.70 (SD1 = 0.96) and M2 = 3.71 (SD2 = 1.00) for “AI should present pure facts” (reversely scored in the scale), M1 = 2.59 (SD1 = 1.08) and M2 = 2.67 (SD2 = 1.12) for “AI may express an opinion in its texts”, and M1 = 2.82 (SD1 = 1.07) and M2 = 2.99 (SD2 = 1.14) for “The AI may write emotional texts”.
3.2. Experience with ATG
The responses to the questions of whether participants had ever heard of ATG and whether participants had ever read a text written by AI can be seen in Table 3. In addition, the answers specifically regarding ChatGPT use are displayed in this table. A total number of n = 408 participants in Study 2 (40.28% of respondents) indicated having used ChatGPT before and were thus later forwarded to the attitudes toward ChatGPT questionnaire (see below). For distributions of the scales separated for participants who indicated having or not having used ChatGPT, see Figure 4.
Table 3.
Relative frequencies (in percent) of answers on the items regarding ATG experience and ChatGPT use by study. * Answer options seldom, occasionally, often, and constantly were merged.
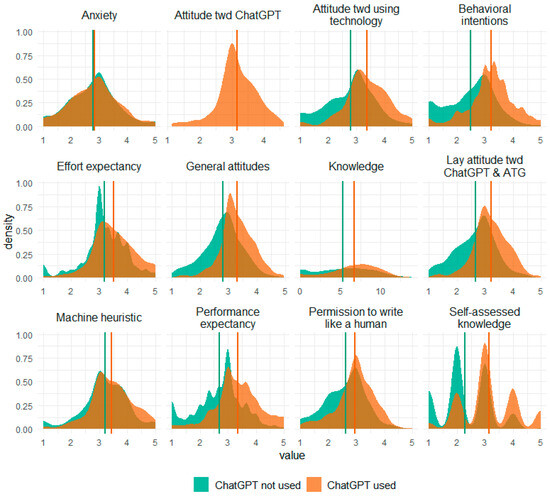
Figure 4.
Density distributions of all variables for the subgroups of ChatGPT use in Study 2. Vertical lines represent the means within the subgroups; n = 605 for “ChatGPT not used” and n = 408 for “ChatGPT used”.
3.3. Knowledge Test
Concerning the knowledge test in Study 2, 120 (11.85%) respondents did not answer any question correctly while only two (0.002%) reached to answer 14 statements correctly (see Table 2 for mean and standard deviation). For the 15 statements of the knowledge test and the distribution of participants’ responses on each statement, see Table 4.
Table 4.
Relative frequencies (in percent) of the correctness of the answers on the knowledge test and correctness of each statement (True/False) in Study 2 (n = 1013).
3.4. Concepts
Figure 5, Figure 6, Figure 7 and Figure 8 show participants’ perceived probabilities toward each item concerning the concepts. Relative answers to each belief about how ATG could potentially work (Figure 5), where the content could come from (Figure 6), how much control the human could have in the process (Figure 7), and who could be responsible for the content (Figure 8) are depicted by study.
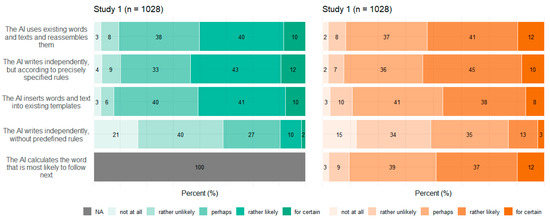
Figure 5.
Relative frequencies of participants’ perceived probability for each item regarding ATG functionality by study.
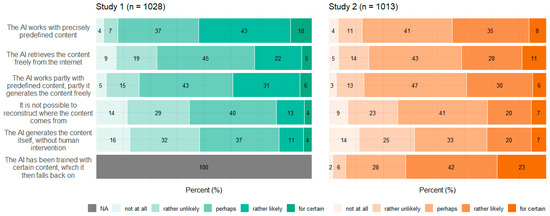
Figure 6.
Relative frequencies of participants’ perceived probability for each item regarding data sources by study.
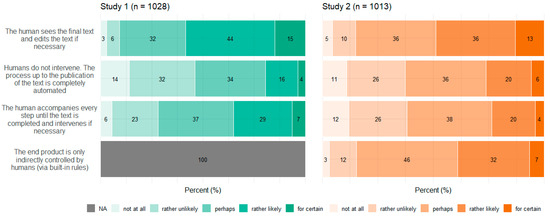
Figure 7.
Relative frequencies (percentage) of participants’ perceived probability for each item regarding human control by study.
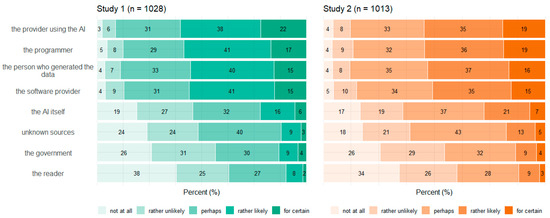
Figure 8.
Relative frequencies (percentage) of participants’ perceived probability for each item regarding content responsibility by study.
3.5. Intention to Read AI-Written Texts concerning Journalistic Topics
For participants’ detailed answers on the question “How likely would you be to read AI-written texts on the following topics?” separated by study, see Supplementary Figure S1. Regarding all 18 topics, the proportion of participants answering “perhaps” was between 30–40% for both studies. The option to read an AI written text “for certain” was chosen in equally small proportions in both studies, with the highest values for product descriptions and weather forecasts. The proportion of participants indicating to be “not at all” willing to read an AI-generated text to the presented topics reached between 8–30% in Study 1 and 12–26% in Study 2, with the highest proportion of rejection for the topic “opinion” in both time points.
Concerning the question “If you had a choice, who would you rather be informed by about the following topics?”, detailed response distribution across the 18 topics is depicted in Supplementary Figure S2. At both time points and regarding all topics, the percentage of people who chose “preferably by an AI” did not reach a majority. The proportion of participants preferring an AI author was between 3–21% in Study 1 and 5–20% in Study 2, depending on the topic. On some topics, respondents expressed a clear tendency to prefer a human author (e.g., opinion, health, politics), whereas on some topics the option “no preference” was selected more frequently (e.g., sports reports, advertisements, stock reports).
3.6. Specific Attitudes toward ATG
In Study 2, participants who indicated having used ChatGPT were asked about their attitudes and their experience with this tool. The answer distributions regarding each item are depicted in Table 5. Furthermore, all participants indicated their attitudes toward ATG and ChatGPT on a more general level (Table 6).
Table 5.
Relative frequencies (in percent) of participants’ agreement to each item regarding attitude toward ChatGPT in Study 2 (n = 408).
Table 6.
Relative frequencies (in percent) of participants’ agreement to each item regarding lay attitude toward ATG and ChatGPT in Study 2 (n = 1013).
3.7. Exploratory Analyses
In both studies, we measured participants’ intentions to read AI-written texts and to use ATG technology. Due to the release of ChatGPT in November 2022, we were able to ask more specifically for attitudes toward ChatGPT and ATG in Study 2. Therefore, we conducted two explorative multiple regression analyses to predict people’s behavioral intentions to consume ATG. Figure 9 depicts Q-Q plots for evaluating residual normality in the models for both studies. The plot shows that the residuals follow the theoretical quantiles of the normal distribution well around the mean, with some deviation at the tails of the distribution. This deviation is expected (and commonly seen) since the theoretical normal distribution ranges from minus infinity to infinity, which is, of course, not true for our measure.
Figure 9.
Q-Q plots of residuals to assess normality in the regression models predicting behavioral intention to consume ATG for both studies.
We adopted the common supervised machine learning principle k-fold cross-validation, which helps to estimate the predictive accuracy of a regression model. Using cross-validation, the data set is divided into a training (used for model training) and a test set (also hold-out set, used to evaluate the model performance). The purpose of this approach is not to fit the model to the entire sample but only to a part of it (training set) and thus to test whether the model can be generalized to the unseen hold-out set. Furthermore, the training set is divided into k equal-sized folds on which the statistical model is iteratively developed and fitted, leaving each fold out in turn. This process is repeated k times, with each fold being used as the validation set once. Therefore, cross-validation is a robust and reliable method to reduce the risk of model overfitting and serves the generalizability of the regression results to unseen data [47,48,49].
According to the TAM [9], the intention to use a technology is determined by people’s attitude toward using it, which is in turn influenced by the performance expectancy and effort expectancy. Therefore, we added these variables to the models. We also aimed to investigate the predictive contribution of several other variables, such as the general attitude toward AI or participants’ prior experience with ChatGPT, as relationships between these variables were found before [39,50].
Each survey data set was split into a training (75%) and a hold-out set (25%). A regression model using k = 5-fold cross-validation was used in each training set. This process involved training the model in four subsets and evaluating it in the remaining subset in a rotating fashion. Finally, the performance on the fitted model was assessed in the hold-out sample. The predictors of the respective models as well as their corresponding coefficients can be seen in Table 4 and are illustrated in Figure 10. Results indicated that both models explained a substantial proportion of variance, with R21 = 0.66 and R22 = 0.66. Together with the small average magnitudes of errors, RMSE1 = 0.48 and RMSE2 = 0.53, and mean absolute errors, MAE1 = 0.37 and MAE2 = 0.43, the fitted models were highly accurate in their predictions. In both models, as expected, performance expectancy and attitude toward using ATG significantly contributed to predicting behavioral intentions, but effort expectancy did not. Moreover, in Study 2, the added predictor lay attitude toward ChatGPT and ATG was a significant predictor (see Table 7).
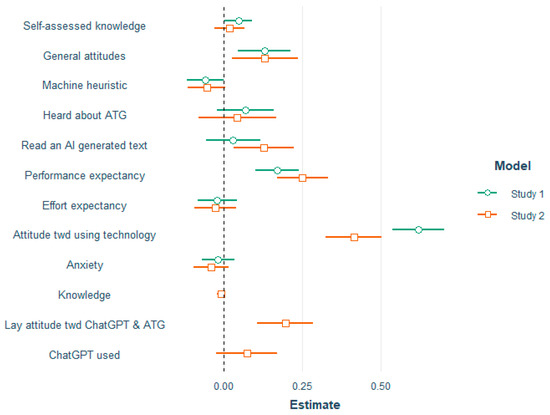
Figure 10.
Coefficients of the predictors of behavioral intention to consume ATG for both models (Study 1 & Study 2). Whiskers represent the 95% CI.
Table 7.
Coefficients of the multiple regression analyses with cross-validation for predicting behavioral intentions to consume ATG in Studies 1 and 2. Heard about ATG, read an AI-generated text, and ChatGPT use were included in the models as dummy variables with 0 (not heard, not read, and no usage) serving as the reference group.
4. Discussion
What society expects from technological development, which information people may need to understand and adopt innovations, or whether the attitudes tend to be positive or negative should be investigated parallel to the developmental process. Awareness of people’s perceptions and ideas regarding technologies that are ever more present is essential for a meaningful debate about developments and adequate information for laypeople. However, discussions such as those that have been held publicly about deep fakes or facial recognition technology are missing regarding ATG, as public perception is currently largely shaped by one new tool. Even if many people are currently not aware of where ATG is already being used or cannot distinguish between human and AI-written texts, research into attitudes and possible concerns is essential, as these influence trust in and the handling of texts authored by AI. Moreover, knowledge gaps need to be revealed to target misconceptions. We addressed this research gap by investigating the German population’s current beliefs, concepts, and attitudes toward ATG. Data from two representative surveys conducted in 2022, before the release of ChatGPT, and 2023, after the sudden media focus on NLG developments, were collected to gain insights into the current state and potential changes over time.
4.1. Public Awareness of ATG
Without a doubt, the hype surrounding ChatGPT has drawn attention to this field of AI. However, a survey among the U.S. population finding that 42% of Americans had in March 2023 heard nothing at all about ChatGPT revealed that this did not reach all sections of the population equally quickly [36]. While a third of respondents in Study 1 presented here indicated never having heard that AI can write texts, this proportion decreased substantially to 16% in Study 2. In contrast, the proportion of people indicating never having read an AI-written text barely dropped from 56% to 49% between the two polls. Apparently, the coverage of ChatGPT has led people to become more concerned with this technology. Though we cannot retrospectively measure participants’ actual experience with ATG, the evidence still reflects a remarkable lack of awareness of the presence of ATG. Automatically produced content has been present in automated journalism for over a decade (unknown to a majority, as the knowledge test indicated), and automatic product descriptions in online shops are also not new phenomena. Similarly, a German survey by DIW Berlin revealed that many people are unaware of AI in their work contexts: when indirectly asked about AI at work, nearly twice as many respondents indicated working with AI compared to when they were directly asked [51]. It is important to consider that the criteria for what constituted AI are also shifting. The futuristic, distant, and complex image many associated with AI certainly differs from their image of a simpler translation algorithm. Furthermore, an in-depth understanding of technology is not decisive for people to apply it. Nevertheless, future research should constantly adapt to the given circumstances and accompany technological developments.
4.2. Self-Assessed Knowledge about AI
Concerning self-assessed knowledge about AI, we observed only small shifts from Study 1 to Study 2. However, there were differences on gender and education levels. Men rated their knowledge higher slightly more often than women, while women indicated more frequently than men having limited or no knowledge. In addition, the higher the educational level, the higher the proportion was of participants who indicated some or good knowledge about AI in general. Similar to a survey from Bertelsmann Stiftung [37], we found that people who indicated knowing more about AI in general had a more positive attitude toward it. Moreover, we also found a positive but rather moderate correlation with the performance in the knowledge test. An educational advantage could enable people to more effectively determine how to use technology to their advantage.
4.3. Attitudes toward ATG
We explored significant differences between the two time points on most scales that were surveyed twice. The general attitudes toward AI and the belief in the machine heuristic decreased in Study 2, reflecting a less positive attitude and a slightly diminished belief in the accuracy and objectivity of AI. However, the effect sizes do not allow any conclusion of substantial practical relevance. Rather, this study observed stability across the concepts over time.
Furthermore, high positive correlations occurred among the attitude scales (see Figure 3): The more positive the attitude toward AI, the more favorable was the attitude toward ChatGPT and ATG as well, a relationship also found among a student sample in Arabic countries [52]. However, more intriguing is the positive relationship between the machine heuristic (i.e., the belief that an AI is objective, accurate, neutral, and unbiased) and the attitude scales, as they suggest that predispositions can predict reactions to specific technologies. Furthermore, anxiety was negatively correlated, especially with lay attitude toward ChatGPT and ATG and the general attitudes toward AI, a pattern already found before [53] and in other cultural contexts [52]. More research is needed to address concerns and worries to specifically enable people to deal with ATG appropriately. Tool-specific strengths and weaknesses can get lost in public debates about “generative AI”. Educational gaps can either be bridged or widened by ATG technology, particularly when they are primarily used by groups that already benefit from new developments more than others. This underscores the necessity of widespread and transparent information about the potentials and limits of ATG.
4.4. Knowledge Regarding ATG
The knowledge test conducted in Study 2 revealed some detailed insights into potential misconceptions and knowledge gaps. Almost half of the participants incorrectly believed that the quality of AI-created texts depends only on the training data set. That many also believed that language models have learned to understand language like a human. Of course, these two items require a high level of technological understanding. However, the distribution of answers could reflect a misconception about the fundamental function of AI and ATG: It is a popular misunderstanding that artificial and human intelligence work in the same way. Whereas AI developers aim to imitate human intelligence orienting on the mere results, the technological process of reaching these (seemingly) intelligent results can differ significantly from human cognitive or physical processes. The statements correctly answered by a considerable proportion of participants covered more general aspects with no need for intense technical understanding (e.g., “The statements of language-generating AIs are always correct”). Overall, a high proportion of participants responded “don’t know” to each statement, reflecting the heterogeneous level of knowledge in the population but also emphasizing the need for more information and explanation about ATG.
4.5. ATG-Related Concepts
Regarding the four concepts relating to ATG, respondents had to assess the likelihood that each statement applied, as the concepts covered different possibilities rather than hard facts. However, within each item of the concepts function of ATG and data source, a high proportion of participants chose the option “perhaps”. No clear tendency toward single statements was observed within any of the four concepts. Still, a substantial portion of participants perceived most ideas as “rather likely” or “rather unlikely”. Only a small fraction committed to the answer options “for certain” or “not at all”. In Study 2, an item was added to three of the concepts, to cover ChatGPT’s mechanisms. Concerning function of ATG, the added item “The AI calculates the word that is most likely to follow next” (which describes the function very simply) was perceived to be nearly equally likely as the other options. Only the statement that the AI writes independently was perceived as the least probable option. Concerning data source, participants perceived it to be most likely that the AI would have been trained with certain content, which it then falls back on. Moreover, the items “The AI retrieves the content freely from the internet” as well as “It is not possible to reconstruct where the content comes from” and “The AI generates the content itself” were perceived to be likely more often than in Study 1.
Overall, the high frequency of the answer option “perhaps” along with the result that no statements sticked out with a clear tendency of being favored speak for a great uncertainty concerning the underlying mechanisms of ATG. Similarly, a current survey on ChatGPT found high proportions of indecision, too [54]. Some items also reflected different existing technological approaches of ATG, which do not necessarily contradict each other. It is also unrealistic that users would be comprehensively informed about all the specific underlying technologies. Nevertheless, a basic understanding of the potentials and limitations of ATG is crucial for a realistic assessment of its application and use. Furthermore, with the release of tools available for people with every conceivable level of knowledge, benchmark studies such as the present one can provide information about misconceptions and possible weaknesses of technologies that must be addressed.
4.6. Preferences for Human Authorship
The current study shows that the broad field of topics that falls under “news” has to be examined in a more sophisticated way, since people seem to have topic-specific preferences. Similar to what “algorithm aversion” [31] predicts, respondents are more likely to read AI-written content about objective and impersonal topics (e.g., traffic news, weather forecasts, or product descriptions). In contrast, participants particularly refuse to read AI texts about genuinely human-centered topics [55] (e.g., society, culture, or politics). When directly asked for author preferences, participants prefer human authorship across all 18 topics, even with slight shifts toward human preference in Study 2. In both surveys, the notable number of participants selecting “perhaps” or “no preference”, along with many indicating they have never read AI-written texts, suggests uncertainty or a lack of imagination about what AI-created content entails. The results are remarkable against the background of a tool that aims to completely imitate written human language in all areas. At the same time, in the context of science communication, two studies suggest that readers perceive a human and an AI author as equally credible [28] or only slightly less credible [56]. However, the current technical possibilities seem to differ from what people want and expect from ATG. Future studies on the actual usage of ChatGPT will hopefully shed light on what people use it for indeed.
4.7. Limitations
Since this survey approach concentrated on depicting people’s attitudes at two separate points in time, the two distinct samples do not allow for concluding inter-individual changes, thus rendering them as merely two snapshots. Furthermore, the second survey took place relatively shortly after the publication of ChatGPT. The German population might not have had enough time to get in touch with this tool, and different population groups did not have access to it equally quickly. As we are one of the first to systematically investigate people’s attitudes and concepts regarding this specific subfield of AI, our survey captures rather general aspects. This also means that the aspects asked for, such as previous use of ChatGPT, were only recorded very superficially, meaning that large variance can be assumed at the individual level. Of course, the variety of technological implementations and possible applications could not be covered here by any means. Therefore, the cautious approach only allows for preliminary conclusions and should be specified in future studies.
4.8. Implications and Future Directions
The present study revealed that much of the German population has not yet had conscious contact with ATG technology, though the release of ChatGPT seemed to have an impact, at least on people’s general awareness. On average, extreme attitudes were not observed. Whether this expresses a balanced attitude toward this specific AI application remains doubtful. The large proportion of answer selections expressing uncertainty in numerous scales and concepts instead shows that we confronted the samples with a relatively unknown field. It suggests a situation in which this type of AI flows into the most diverse areas at breakneck speed while facing a public widely naïve to it. Nevertheless, a certain amount of basic knowledge about ATG is present in some respondents, but the need for education also became apparent. Since our second survey took place only seven months after the release of ChatGPT and our results indicate that a significant part of the population still did not have the chance to get used to this technology, it remains to be observed how people’s attitudes will change in the long run. Other analyses have made it clear that people with experience with this technology tend to have more positive attitudes and are more open to the use and consumption of ATG. Therefore, skepticism and unease should be encountered with broad knowledge and competence building.
The possible applications outside of journalism are as diverse as they are unexploited, ranging from creative writing tasks to highly formalized and standardized content generation and from informal interpersonal communication to academic writing. As ATG can be used in virtually any setting where text is required, future studies will have to cover a broad range of topics but also delve deep into specific subject matters. The diversity of technical approaches will lead to an improvement not only in ATG but also in general AI (cf. [57]). Given that the underlying data will be irrelevant for readers and that providers rarely label AI-generated text, public discussion should approach ATG with a different focus. Similarly, for AI and algorithms in general, knowledge and competence building that reaches the general population [15] are necessary for ATG. Only with a sharpened understanding of chances and risks can users learn to handle ATG in an informed way and participate in a debate about potential regulations and the shaping of the technologies. The present study contributes to a basic understanding of current concepts and attitudes, which could serve as a benchmark for further studies. The results can also serve as a first indication for various types of stakeholders, who, for example, should orient on the desire for clear labeling and address misconceptions when letting people interact with AI-generated texts. Also, future research needs to understand what people expect from ATG and which misconceptions should be addressed. Speaking for the German population, with the current state of knowledge and awareness, the ground is paved for misattribution, disinformation, and credibility issues in journalism, while at the same time, building competence in informal and formal learning contexts cannot be fully exploited.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/bs14050353/s1, Figure S1: Relative frequencies (percentage) of participants’ perceived probability on how likely they would be to read 18 topics written by AI, by study; Figure S2: Relative frequencies (percentage) of participants’ author preference regarding 18 topics, by study; Table S1: Means and standard deviations of all variables separated by age group and study.
Author Contributions
Both A.L.H. and J.K. conceptualized the study, edited, and revised the manuscript. A.L.H. drafted the manuscript, conducted the studies, and monitored the recruitment of participants. A.L.H. analyzed and interpreted the data and is responsible for data curation. J.K. supervised the studies and was responsible for funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Leibniz-Institut für Wissensmedien (STB Data Science).
Institutional Review Board Statement
The study was conducted in accordance with the guidelines of the Local Ethics Committee of the Leibniz-Institut für Wissensmedien, which approved the study design and methods (Approval number: LEK 2023/022, approved on 17 May 2023).
Informed Consent Statement
Written informed consent was obtained from all participants involved in the study. Participants were invited to complete the online survey via the online market research platform Mingle in March 2022 (Study 1) and in June 2023 (Study 2).
Data Availability Statement
The data used in the study can be made available on requests addressed to the corresponding author.
Conflicts of Interest
The authors declare no competing interests.
References
- Reiter, E.; Dale, R. Building applied natural language generation systems. Nat. Lang. Eng. 1997, 3, 57–87. [Google Scholar] [CrossRef]
- Guzman, A.L. What is human-machine communication, anyway? In Human-Machine Communication: Rethinking Communication, Technology, and Ourselves; Guzman, A.L., Ed.; Peter Lang: New York, NY, USA, 2018; pp. 1–28. [Google Scholar]
- McDonald, D.D. Issues in the choice of a source for natural language generation. Comput. Linguist. 1993, 19, 191–197. [Google Scholar]
- Gatt, A.; Krahmer, E. Survey of the state of the art in natural language generation: Core tasks, applications and evaluation. J. Artif. Intell. Res. 2018, 61, 65–170. [Google Scholar] [CrossRef]
- Carlson, M. The robotic reporter: Automated journalism and the redefinition of labor, compositional forms, and journalistic authority. Digit. J. 2015, 3, 416–431. [Google Scholar] [CrossRef]
- Clerwall, C. Enter the robot journalist: Users’ perceptions of automated content. J. Pract. 2014, 8, 519–531. [Google Scholar] [CrossRef]
- Köbis, N.; Mossink, L.D. Artificial intelligence versus Maya Angelou: Experimental evidence that people cannot differentiate AI-generated from human-written poetry. Comput. Hum. Behav. 2021, 114, 13. [Google Scholar] [CrossRef]
- Lund, B.D.; Wang, T. Chatting about ChatGPT: How may AI and GPT impact academia and libraries? Libr. Hi Tech News 2023, 40, 26–29. [Google Scholar] [CrossRef]
- Venkatesh, V.; Morris, M.G.; Davis, G.B.; Davis, F.D. User acceptance of information technology: Toward a unified view. MIS Q. 2003, 27, 425–478. [Google Scholar] [CrossRef]
- Schick, N. Deep Fakes and The Infocalypse: What You Urgently Need to Know; Hachette UK: London, UK, 2020. [Google Scholar]
- de Haan, Y.; van den Berg, E.; Goutier, N.; Kruikemeier, S.; Lecheler, S. Invisible friend or foe? How journalists use and perceive algorithmic-driven tools in their research process. Digit. J. 2022, 10, 1775–1793. [Google Scholar] [CrossRef]
- Dörr, K.N. Mapping the Field of Algorithmic Journalism. Digit. J. 2016, 4, 700–722. [Google Scholar] [CrossRef]
- Graefe, A. Guide to Automated Journalism; Tow Center for Digital Journalism: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Montal, T.; Reich, Z. I, Robot. You, Journalist. Who is the Author? Authorship, bylines and full disclosure in automated journalism. Digit. J. 2017, 5, 829–849. [Google Scholar] [CrossRef]
- Overdiek, M.; Petersen, T. Was Deutschland über Algorithmen und Künstliche Intelligenz weiß und denkt. In Ergebnisse Einer Repräsentativen Bevölverungsumfrage; Bertelsmann Stiftung: Gütersloh, Germany, 2022. [Google Scholar]
- Waddell, T.F. A robot wrote this? how perceived machine authorship affects news credibility. Digit. J. 2018, 6, 236–255. [Google Scholar] [CrossRef]
- Graefe, A.; Haim, M.; Haarmann, B.; Brosius, H.-B. Readers’ perception of computer-generated news: Credibility, expertise, and readability. Journalism 2018, 19, 595–610. [Google Scholar] [CrossRef]
- Longoni, C.; Fradkin, A.; Cian, L.; Pennycook, G. News from artificial intelligence is believed less. SSRN Electron. J. 2021. [Google Scholar] [CrossRef]
- Van der Kaa, H.; Krahmer, E. Journalist versus news consumer: The perceived credibility of machine written wews. Proc. Comput. J. Conf. 2014, 24, 25. [Google Scholar]
- Jia, C.; Johnson, T.J. Source credibility matters: Does automated journalism inspire selective exposure? Int. J. Commun. 2021, 15, 22. [Google Scholar]
- Wölker, A.; Powell, T.E. Algorithms in the newsroom? News readers’ perceived credibility and selection of automated journalism. Journalism 2021, 22, 86–103. [Google Scholar] [CrossRef]
- Jang, W.; Chun, J.W.; Kim, S.; Kang, Y.W. The effects of anthropomorphism on how people evaluate algorithm-written news. Digit. J. 2021. [Google Scholar] [CrossRef]
- Tandoc, E.C.; Yao, L.J.; Wu, S. Man vs. machine? The impact of algorithm authorship on news credibility. Digit. J. 2020, 8, 548–562. [Google Scholar] [CrossRef]
- Haim, M.; Graefe, A. Automated news: Better than expected? Digit. J. 2017, 5, 1044–1059. [Google Scholar] [CrossRef]
- Wu, Y. Is automated journalistic writing less biased? An experimental test of auto-written and human-written news stories. J. Pract. 2020, 14, 1008–1028. [Google Scholar] [CrossRef]
- Graefe, A.; Bohlken, N. Automated journalism: A meta-analysis of readers’ perceptions of human-written in comparison to automated news. Media Commun. 2020, 8, 50–59. [Google Scholar] [CrossRef]
- Sundar, S.S.; Kim, J. Machine heuristic: When we trust computers more than humans with our personal information. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–9. [Google Scholar] [CrossRef]
- Lermann Henestrosa, A.; Greving, H.; Kimmerle, J. Automated journalism: The effects of AI authorship and evaluative information on the perception of a science journalism article. Comput. Hum. Behav. 2023, 138, 107445. [Google Scholar] [CrossRef]
- Longoni, C.; Cian, L. Artificial intelligence in utilitarian vs. hedonic contexts: The “word-of-machine” effect. J. Mark. 2022, 86, 91–108. [Google Scholar] [CrossRef]
- Sundar, S.S. The MAIN model: A heuristic approach to understanding technology effects on credibility. In Digital Media, Youth, and Credibility; Metzger, J.M., Flanagin, J.A., Eds.; The MIT Press: Cambridge, MA, USA, 2008; pp. 73–100. [Google Scholar] [CrossRef]
- Castelo, N.; Bos, M.W.; Lehmann, D.R. Task-dependent algorithm aversion. J. Mark. Res. 2019, 56, 809–825. [Google Scholar] [CrossRef]
- Bigman, Y.E.; Gray, K. People are averse to machines making moral decisions. Cognition 2018, 181, 21–34. [Google Scholar] [CrossRef] [PubMed]
- Böhm, R.; Jörling, M.; Reiter, L.; Fuchs, C. Content beats competence: People devalue ChatGPT’s perceived competence but not its recommendations. PsyArXiv 2023. [Google Scholar] [CrossRef]
- nextMedia.Hamburg. 2018. Available online: https://www.nextmedia-hamburg.de/wp-content/uploads/2019/02/20180809_journalismusderzukunft.pdf (accessed on 1 February 2024).
- nextMedia.Hamburg. 2019. Available online: https://www.nextmedia-hamburg.de/wp-content/uploads/2019/08/nextMedia-Umfrage_KI_2019_PM-1.pdf (accessed on 1 February 2024).
- Kennedy, B.; Tyson, A.; Saks, E. Public Awareness of Artificial Intelligence in Everyday Activities. 2023. Available online: https://policycommons.net/artifacts/3450412/public-awareness-of-artificial-intelligence-in-everyday-activities/4250673/ (accessed on 1 February 2024).
- Fischer, S.; Petersen, T. Was Deutschland über Algorithmen weiß und Denkt: Ergebnisse einer Repräsentativen Bevölkerungsumfrage. 2018. Available online: https://www.bertelsmann-stiftung.de/de/publikationen/publikation/did/was-deutschland-ueber-algorithmen-weiss-und-denkt (accessed on 1 February 2024).
- Venkatesh, V.; Davis, F.D. A theoretical extension of the technology acceptance model: Four longitudinal field studies. Manag. Sci. 2000, 46, 186–204. [Google Scholar] [CrossRef]
- Darda, K.; Carre, M.; Cross, E. Value attributed to text-based archives generated by artificial intelligence. R. Soc. Open Sci. 2023, 10, 220915. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Dafoe, A. Artificial Intelligence: American Attitudes and Trends. 2019. Available online: https://isps.yale.edu/sites/default/files/files/Zhang_us_public_opinion_report_jan_2019.pdf (accessed on 1 February 2024).
- Mays, K.K.; Lei, Y.; Giovanetti, R.; Katz, J.E. AI as a boss? A national US survey of predispositions governing comfort with expanded AI roles in society. AI Soc. 2021. [Google Scholar] [CrossRef]
- Cave, S.; Coughlan, K.; Dihal, K. “Scary Robots” Examining Public Responses to AI. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 331–337. [Google Scholar] [CrossRef]
- Kimmerle, J.; Timm, J.; Festl-Wietek, T.; Cress, U.; Herrmann-Werner, A. Medical Students’ Attitudes toward AI in Medicine and their Expectations for Medical Education. J. Med. Educ. Curric. Dev. 2023, 10, 23821205231219346. [Google Scholar] [CrossRef] [PubMed]
- Ada Lovelance Institute & Alan Turing Institute. How Do People Feel about AI? A Nationally Representative Survey of Public Attitudes to Artificial Intelligence in Britain. 2023. Available online: https://adalovelaceinstitute.org/report/public-attitudes-ai (accessed on 1 February 2024).
- Schepman, A.; Rodway, P. Initial validation of the general attitudes towards Artificial Intelligence Scale. Comput. Hum. Behav. Rep. 2020, 1, 100014. [Google Scholar] [CrossRef] [PubMed]
- Said, N.; Potinteu, A.E.; Brich, I.R.; Buder, J.; Schumm, H.; Huff, M. An artificial intelligence perspective: How knowledge and confidence shape risk and opportunity perception. Comput. Hum. Behav. 2022. [Google Scholar] [CrossRef]
- Géron, A. Hands-On Machine Learning Aith Scikit-Learn, Keras, and TensorFlow; O‘Reilly Media: Sebastopol, CA, USA, 2022. [Google Scholar]
- Arlot, S.; Celisse, A. A survey of cross-validation procedures for model selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; Volume 112. [Google Scholar]
- Wu, J.; Du, H. Toward a better understanding of behavioral intention and system usage constructs. Eur. J. Inf. Syst. 2012, 21, 680–698. [Google Scholar] [CrossRef]
- Giering, O.; Fedorets, A.; Adriaans, J.; Kirchner, S. Künstliche Intelligenz in Deutschland: Erwerbstätige Wissen oft Nicht, dass sie mit KI-Basierten Systemen Arbeiten; Deutsches Institut für Wirtschaftsforschung e.V.: Berlin, Germany, 2021; Volume 88, pp. 783–789. [Google Scholar]
- Abdaljaleel, M.; Barakat, M.; Alsanafi, M.; Salim, N.A.; Abazid, H.; Malaeb, D.; Mohammed, A.H.; Hassan, B.A.R.; Wayyes, A.M.; Farhan, S.S. A multinational study on the factors influencing university students’ attitudes and usage of ChatGPT. Sci. Rep. 2024, 14, 1983. [Google Scholar] [CrossRef] [PubMed]
- Broos, A. Gender and information and communication technologies (ICT) anxiety: Male self-assurance and female hesitation. CyberPsychology Behav. 2005, 8, 21–31. [Google Scholar] [CrossRef] [PubMed]
- Bodani, N.; Lal, A.; Maqsood, A.; Altamash, S.; Ahmed, N.; Heboyan, A. Knowledge, Attitude, and Practices of General Population Toward Utilizing ChatGPT: A Cross-sectional Study. SAGE Open 2023, 13, 21582440231211079. [Google Scholar] [CrossRef]
- Proksch, S.; Schühle, J.; Streeb, E.; Weymann, F.; Luther, T.; Kimmerle, J. The Impact of Text Topic and Assumed Human vs. AI Authorship on Competence and Quality Assessment. 2024. Available online: https://osf.io/preprints/osf/7fhwz (accessed on 1 February 2024).
- Lermann Henestrosa, A.; Kimmerle, J. The Effects of Assumed AI vs. Human Authorship on the Perception of a GPT-Generated Text. 2024. Available online: https://osf.io/preprints/psyarxiv/wrusc (accessed on 1 February 2024).
- Sun, X.; Zhang, J.; Wu, X.; Cheng, H.; Xiong, Y.; Li, J. Graph prompt learning: A comprehensive survey and beyond. arXiv 2023, arXiv:2311.16534. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).