Simple Summary
As agriculture and human settlements expand, conflicts between humans and animals become more frequent, resulting in resource loss and safety risks. Therefore, accurately identifying and locating offending animals is essential. This study presents a novel method for automatically detecting offending animals, especially in situations where they are obscured or the images are unclear. This research focused on six types of offending animals commonly found in northeastern China. By employing improved image processing techniques, this study enhanced detection accuracy in complex environments. Experimental results demonstrate that the proposed method outperforms existing techniques on the dataset used. This new approach helps improve the accuracy of intelligent monitoring systems, providing better technical support to minimize conflicts between humans and animals, thus protecting agriculture and ensuring the safety of both humans and animals.
Abstract
Conflicts between humans and animals in agricultural and settlement areas have recently increased, resulting in significant resource loss and risks to human and animal lives. This growing issue presents a global challenge. This paper addresses the detection and identification of offending animals, particularly in obscured or blurry nighttime images. This article introduces Multi-Channel Coordinated Attention and Multi-Dimension Feature Aggregation (MDA-DETR). It integrates multi-scale features for enhanced detection accuracy, employing a Multi-Channel Coordinated Attention (MCCA) mechanism to incorporate location, semantic, and long-range dependency information and a Multi-Dimension Feature Aggregation Module (DFAM) for cross-scale feature aggregation. Additionally, the VariFocal Loss function is utilized to assign pixel weights, enhancing detail focus and maintaining accuracy. In the dataset section, this article uses a dataset from the Northeast China Tiger and Leopard National Park, which includes images of six common offending animal species. In the comprehensive experiments on the dataset, the index of MDA-DETR was 1.3%, 0.6%, 0.3%, 3%, 1.1%, and 0.5% higher than RT-DETR-r18, yolov8n, yolov9-C, DETR, Deformable-detr, and DCA-yolov8, respectively, indicating that MDA-DETR is superior to other advanced methods.
1. Introduction
With the rapid advancement of urbanization, human activities are increasingly encroaching on wildlife habitats. This has led to a rise in harmful wildlife incidents, despite efforts to establish national parks and protected areas. Such incidents not only pose a threat to human health and livelihoods but also highlight the urgent need to address wildlife–human conflicts [1]. As a result, mitigating these conflicts has become a global priority for governments and a focus of academic research.
Traditional methods for managing wildlife–human conflicts, such as erecting physical barriers like barbed wire or electric fences around settlements and agricultural areas, have notable limitations. These measures can induce stress responses or even fatalities in animals and pose potential risks to humans [2]. To overcome these challenges, there is a growing demand for intelligent surveillance systems capable of automatically detecting and identifying offending animals in real time.
Object detection, a fundamental yet challenging task in computer vision, involves assigning precise bounding boxes and classification labels to objects in images. Recent advances in deep learning, coupled with reduced hardware costs, have spurred the development of robust object detection algorithms. Two-stage detection frameworks such as Faster R-CNN [3,4] and R-CNN [5], as well as single-stage detectors like YOLO [6,7,8,9], have gained prominence. Moreover, the dominance of Convolutional Neural Networks (CNNs) in this field has recently been challenged by the rise of Transformers, which leverage attention mechanisms to boost model performance. DETR, the first Transformer-based object detection model [10], eliminates the need for manually designed anchor frames and non-maximal suppression (NMS). However, it faces limitations in processing speed. In 2023, Baidu’s Flying Paddle team introduced RT-DETR, a breakthrough in object detection. This model transitions from “dense detection” to “sparse detection”, eliminating threshold filtering and NMS. It delivers an end-to-end, real-time object detection solution [11], making it a promising tool for applications like offending animal detection.
Offending animals frequently appear near planting and breeding areas, causing damage to vegetation and livestock. These activities often obscure the animals within the damaged vegetation. Furthermore, many offending animals are nocturnal, leading to blurry images captured by trap cameras. This study emphasizes the crucial need for accurate detection and recognition of obscured or blurry images of offending animals. While the RT-DETR model exhibits strong robustness and generalization, it has limitations. The AIFI module, relying solely on a self-attention mechanism, provides rich semantic information but lacks precise positional information. Additionally, the CCFF module, despite integrating cross-scale information, struggles with detecting targets in blurry images.
To address these limitations, this paper proposes MDA-DETR, a novel method based on Multi-Channel Coordinated Attention and multi-scale feature aggregation, to enhance the detection of obscured and blurry images of offending animals. Inspired by channel attention mechanisms [12], we introduce a Multi-Channel Coordinated Attention (MCCA) mechanism. This mechanism extracts image features along three spatial directions, capturing long-range dependencies and providing precise positional information while preserving the rich semantic information from deep networks. This significantly improves the accuracy of detecting occluded targets.
Furthermore, inspired by the RepBiPAN module [13], we propose a Multi-Dimension Feature Aggregation Module (DFAM). This module effectively fuses positional information from shallow networks with semantic information from deeper networks, and aggregates features from multiple scales. This enhances the detection accuracy of blurry images. To reduce the overall parameter count, we incorporate the RepNCSPELAN4 module [14] into the backbone network.
MDA-DETR was rigorously evaluated on a subset of the Northeast China Tiger and Leopard National Park dataset [15]. Ablation experiments were conducted to assess the performance of each component, demonstrating the superior performance of MDA-DETR in detecting offending animals. The main contributions of this study are as follows:
- (i)
- Multi-Channel Coordinate Attention (MCCA) mechanism This mechanism extracts image features along three spatial directions, integrating precise positional and long-range dependency information while preserving the rich semantic information from deep networks.
- (ii)
- Multi-Dimension Feature Aggregation Module (DFAM) This module effectively fuses multi-scale feature maps, enabling the extraction of complementary and global information.
- (iii)
- Comparative experiments demonstrate the superiority of MDA-DETR over state-of-the-art methods. Ablation experiments confirm the effectiveness of each key component.
2. Related Works
2.1. Transformer-Based Object Detection
Transformer is an encoder–decoder architecture based on a self-attention mechanism, first proposed by Google and applied to Natural Language Processing (NLP), achieving state-of-the-art (SOTA) results in various NLP tasks [16]. In 2020, Nicolas Carion et al. introduced Transformer to object detection with the DETR (DEtection TRansformer) model, simplifying the detection process by treating it as an ensemble prediction problem and eliminating the need for manually designing components. In addition, DETR converts the feature image output from the backbone network into a one-dimensional sequence, enabling the model to compute correlations between each pixel and others, thus achieving a wider receptive field than that of CNNs [17].
However, as a pioneering work, DETR has some limitations. Zhu et al. proposed Deformable-detr [18] to address the slow training speed of Transformer in computer vision. Its attentional module focuses only on the key sampling points, resulting in better performance on small targets and reduced training time. In 2022, Wang et al. introduced Anchor DETR [19], a new Transformer-based query mechanism for object detection. This model employs a new attentional variant to predict multiple objects in a region, thus effectively solving the problem of ‘one region, multiple objects’.
Although the Transformer-based DETR series has challenged the monopoly of CNN in just two years, it is still no substitute for the CNN-based series of algorithms in terms of real-time performance in industrial applications. To address this, Baidu’s team, composed of Lv et al., proposed RT-DETR (Real-Time DEtection Transformer) in 2023 [11]. It is a real-time end-to-end detector based on the DETR model and outperforms YOLO in real-time object detection. Compared with yolov8, RT-DETR requires a shorter training duration, fewer data enhancement strategies, and demonstrates stronger performance under the same test conditions.
Most state-of-the-art Transformer methods divide images into regular grids and represent each grid region with visual tokens. However, the fixed token distribution ignores the semantic information of different areas of the image, which leads to performance degradation. To address this issue, in 2024, Wang Zeng et al. proposed the Token Clustering Transformer (TCFormer) [20]. This method dynamically generates visual tokens based on semantic information, allowing regions with similar semantics to be represented by the same token, even if these regions are not adjacent. For areas containing important details, TCFormer uses fine-grained tokens to enhance the accuracy of image understanding. In the same year, Yansong Peng et al. redefined the bounding box regression task in the DETR model and proposed the D-FINE model [21]. This model introduces Fine-grained Distribution Refinement (FDR) and Global Optimal Localization Self-Distillation (GO-LSD) strategies, transforming the regression process from predicting fixed coordinates to iteratively refining probability distributions, thus achieving higher accuracy in object localization.
2.2. Wildlife Object Detection
Wildlife surveys are key to nature conservation. In 2021, Delplanque et al. evaluated the performance of three CNN algorithms: Faster-RCNN, Libra-RCNN [22], and RetinaNet [23]. They trained the models using an independent dataset, enabling them to detect and identify African mammal species based on high-resolution aerial imagery. The Libra-RCNN model [24] with the best detection results accurately detected animals in open and sparse grasslands, reducing detection time. In 2022, Cai Qianzhou et al. proposed a solution [25] for long-tailed data based on YOLOv4-Tiny. Their approach combined two-stage learning and reweighting. In the first stage, the model was trained without weighting. In the second stage, weights from the first stage were used in combination with the reweighting method, ultimately improving the model’s accuracy for long-tailed data acquired by trap cameras. In 2023, Roy et al. proposed the WilDect-YOLO model [26] for the automatic detection of endangered wildlife. This model introduces residual blocks in the backbone network and integrates DenseNet blocks to extract and retain critical feature information. Additionally, Spatial Pyramid Pooling (SPP) and an improved Path Aggregation Network (PANet) are added to the feature fusion part, enhancing the model’s perceptual field and preserving fine-grained local information. In 2024, Yang Wenhan et al. combined the Swin Transformer module with a CNN to propose a method [27] for detecting wildlife images captured by trap cameras based on YOLOV5s. The technique fuses the advantages of both networks in the feature extraction layer, expanding the receptive field of feature extraction and enabling the model to accurately detect animals despite severe occlusion, low contrast with the background, and other challenges.
2.3. Offending Animal Detection
Timely detection and identification of offending animals are crucial to reducing human–animal conflicts. In 2018, Ram et al. proposed an automatic unsupervised elephant image detection system [28] for human–elephant conflicts. This system acquires animal images and presence signals from cameras and sensors, respectively. Placed near conflict-prone areas in forest villages, the device generates a warning signal when an elephant is detected, and then sent to a specific location via a GSM module. In 2020, Ravoor et al. designed a cross-camera tracking system [29] for detecting jaguars, elephants, and other offending animals. The method uses the MobileNetv2-SSD [30] model to localize the animals and the Triplet Loss trained ResNet-50 [31] model for re-identification. The integrated model runs at 2–3 frames per second, enabling near real-time functionality. In 2022, Lee et al. proposed an extract–append data enhancement method [32] that extracts specific objects from a limited number of images through semantic segmentation and appends them to numerous images with arbitrary backgrounds. The technique generates images of offending animals with varied backgrounds, improving the model’s detection performance by enriching the dataset. In 2023, Charles et al. developed a system [33] consisting of an Arduino, a PIR motion sensor, an LED flash, a speaker, and an acoustic cannon to monitor a field h a day. When the PIR motion sensor detects an animal, the Arduino activates, the speaker emits a threatening animal sound, the LED light flashes, and the system sends a text message and a photo to the farmer within seconds of detection.
3. Materials and Methods
3.1. Dataset
This study uses the publicly available Northeast China Tiger and Leopard National Park dataset [15]. From this dataset, six common species of offending animals in northeastern China—badger, black bear, leopard cat, red fox, weasel, and wild boar—were selected. The total dataset comprises 9641 images, including 5823 daytime images and 3818 nighttime images. The dataset was divided into training, validation, and test sets in a 7:2:1 ratio. Mosaic data augmentation was applied to the training set to enhance the dataset (see Table 1).

Table 1.
Brief information about the dataset used in this article.
3.2. Overall Architecture
The overall structure of MDA-DETR proposed in this paper is shown in Figure 1, which is a Transformer-based encoding–decoding structure. First, the improved ResNet-18 backbone network is used for encoding and extracting image features. This paper acquires three different scales of features with the resolutions: , , . Then, the deep feature images are inputted into MCCA to obtain accurate position information. In addition, the AIFI self-attention mechanism in the RT-DETR model is retained to extract rich semantic information. Next, the feature maps of three different scales—shallow, intermediate, and deep—are further fused by DFAM to obtain a new feature image with global information. Finally, the Variable Focal Loss function (VariFocal Loss) [34], GIoU loss function [35], and L1-loss [36] are used to measure the error between the model’s prediction results and the actual labels and to adjust the weight parameters accordingly to optimize the overall model further.
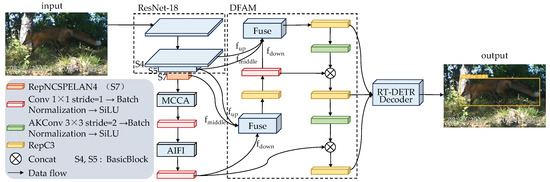
Figure 1.
The overall structure of MDA-DETR.
3.3. Multi-Channel Coordinate Attention (MCCA)
Generally, channel attention mechanisms play a crucial role in improving model performance. However, traditional channel attention mechanisms focus primarily on extracting semantic information from feature maps, often neglecting the importance of target position [37]. In the field of detecting offending animals, obstructions often occur, making accurate positional information critical for enhancing model predictive performance. Inspired by channel attention mechanisms, this paper proposes the Multi-Channel Coordinated Attention Mechanism (MCCA). It effectively extracts semantic and positional information from feature maps through three spatial directions and captures long-range dependencies (as shown in Figure 2), ultimately improving the accuracy of detecting obscured offending animals.
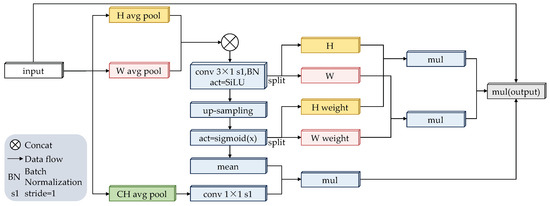
Figure 2.
The structure diagram of MCCA.
Specifically, the input image of size is first decomposed into three one-dimensional feature encoding processes. The three outputs can be expressed as follows:
The features of H and W are then combined to obtain . These combined features are then fed into a convolution kernel for convolution, followed by batch normalization and SiLU activation [38]. This process can be described as follows:
where represents a series of operations, including convolution, batch normalization, and SiLU activation functions.
Subsequently, is decomposed into two separate tensors along the H and W directions to obtain and . Upsampling and activation operations are then performed on . The activation function is used here to reduce the complexity and computational overhead of the module. This process can be described as follows:
where denotes upsampling.
Decomposing into two separate attentional weights along the H and W directions yields and for subsequent refinement of the and tensors. Next, is batch normalized. Afterward, it is multiplied with , which has been processed through a convolution, to obtain . This process can be defined as follows:
The resulting output can be written as
3.4. Multi-Dimension Feature Aggregation Module (DFAM)
When detecting offending animals, their rapid movements and nighttime appearances can result in blurry images and unclear boundaries when captured by trap cameras. Utilizing the MCCA module and the AIFI module, the model obtains feature images with precise localization and rich semantic information. However, recognition accuracy for such challenging conditions remains an issue. To leverage the complementarity and correlation between multi-scale features, this paper proposes a multi-scale feature aggregation module (DFAM), inspired by the RepBiPAN module, to fuse feature images from the backbone network with those processed through MCCA and AIFI operations. Figure 1 illustrates the overall structure of DFAM. The main contribution of DFAM is the fusion of multiple feature images at different scales, utilizing both element-wise addition and cascading operations. This approach enhances information at the same scale while benefiting from features at other scales. Additionally, this paper introduces an aggregation block (Fuse) that consolidates feature maps of varying sizes in the DFAM fusion path, followed by a convolution block (RepC3) composed of multiple convolutional layers. These operations enable the model to integrate feature maps from each layer, yielding feature images with globally essential features and improving the detection accuracy of blurry animal images. Figure 3 shows the structure of Fuse and RepC3 in DFAM.
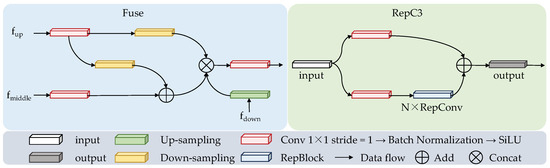
Figure 3.
Structure of Fuse and RepC3 in DFAM.
Specifically, the Fuse module handles three inputs to the aggregation block: , , and . For the shallow feature map, is first processed by a convolution, followed by batch normalization and the SiLU activation function, and then undergoes downsampling to facilitate subsequent fusion operations. This process can be expressed as follows:
where is a series of sequential operations, including convolution, batch normalization, and SiLU activation functions.
After that, the middle layer feature map is input into for a convolution operation with a kernel, and the deep layer feature map is upsampled. This process can be represented as follows:
where denotes upsampling.
Then, and are fused using element-wise addition, and the fused feature maps are cascaded with and , and finally input into for a convolution operation. This process can be defined as follows:
In the RepC3 convolutional block, the input features first undergo sequential operations to adjust the number of channels. After this, feature extraction is performed on one of the branches using a RepBlock consisting of N RepConvs [39]. Finally, the outputs of the dual paths are fused using element-wise addition. By employing DFAM, the model can fuse features at three different scales and utilize cross-level features to acquire more global and complementary information. This results in a more expressive fused feature image that accurately detects the presence of offending animals in blurred images.
3.5. Backbone Network Improvement Strategy
Although the images processed by MCCA and DFAM retain accurate positional information and rich semantic information, the overall number of model parameters is high. To address this, we use the RepNCSPELAN4 structure to replace the last layer of the ResNet-18 backbone network. The RepNCSPELAN4 structure combines CSPNet with gradient path planning and ELAN, extending ELAN to support GELAN for any computational block. This design is focused on achieving lightweight inference speed and accuracy. This optimization strategy enables the model to reduce the number of parameters while maintaining the original accuracy.
3.6. Loss Function
The Variable Focal Loss function (VariFocal Loss) uses the IoU-aware Classification Score (IACS) to represent the probability of target object ranking of candidate detection frames. The loss function employs an asymmetric weighting approach to improve the model’s classification performance by reducing the weight of negative samples and increasing the weight of positive samples. This allows the model to better focus on training with high-quality positive samples. The functional representation of VariFocal Loss is as follows:
where denotes the label of the sample i with positive class 1 and negative class 0. denotes the predicted IACS for the sample i. and represent the scalability coefficients of the moderating loss.
Traditional object detection algorithms typically use the IoU loss function to measure the degree of overlap between the prediction frame and the ground truth. However, when the overlap is high, the IoU loss function suffers from the vanishing gradient problem, making further model optimization difficult [40]. To better localize the target and reduce the absolute error between the prediction and ground truth, the GIoU loss function and L1-loss are introduced. Specifically, the GIoU loss function introduces a penalty term on top of the IoU loss function to measure the non-overlap between the prediction and ground truth frames, addressing the vanishing gradient problem and enabling faster convergence. The L1-loss, or mean absolute error (MAE), is the average of the absolute errors between the model’s predicted and true values. Using both the GIoU loss function and L1-loss provides better supervision during model training and ensures the accuracy of its results.
The expressions for the loss functions are as follows:
where denotes the intersection ratio between the predicted and ground truth boxes, represents the minimum bounding box containing both the predicted and ground truth boxes, and U represents the union of predicted and real bounding boxes. N is the number of samples, is the true value of sample i, and is the predicted value of sample i.
Finally, the overall loss function for the proposed model is as follows:
4. Results
4.1. Evaluation Metrics
To evaluate the model proposed in this study, six widely used evaluation metrics in object detection tasks were adopted: Precision, Recall, (mean Average Precision), mAP50–95, parameters, and FPS (Frames Per Second). In object detection tasks, the Intersection over Union ( between the predicted bounding box and the ground truth box is generally used to assess their overlap, thereby evaluating the model’s detection accuracy on a specific dataset. A higher value indicates greater similarity between the two boxes. If the exceeds a certain threshold (commonly set at 0.5, also used in this paper), the model is considered to have successfully detected the object, and the result is classified as a positive example (P); otherwise, it is treated as a negative example (N). For a positive example, if the model’s classification result is correct, it is considered a true positive (); otherwise, it is regarded as a false positive (). If a ground truth box is not detected, it is labeled as a false negative (). Based on these, Precision and Recall can be calculated using the following formulas:
However, Precision and Recall do not fully reflect the performance of an object detection model across different thresholds. When Precision increases, Recall often decreases; conversely, when Recall increases, Precision tends to decrease. This is because the stricter the criteria for predicting a sample as a positive example, the more likely the model is to miss some true positive examples. On the other hand, the more lenient the criteria, the more likely the model is to increase the number of false positives. Therefore, this study includes two additional evaluation metrics: and mAP50–95. represents the average precision () across multiple categories at an IoU threshold of 0.5. mAP50–95 represents the average of results at 10 thresholds ranging from 0.5 to 0.95, with a step size of 0.05. The higher the value, the better the model’s detection performance. The formulas for calculating AP and mAP are as follows:
where P represents Precision, R represents Recall, s represents the classification confidence of the detection box, N represents the number of discrete points, and c represents the number of categories.
For model complexity and detection speed, this study uses two metrics: Frames Per Second () and parameters. indicates the number of frames the object detection model can process per second. The higher the value, the faster the detection speed and the better the real-time performance of the model. Parameters reflect the spatial complexity of the model. The expression for is as follows:
where 1000 ms refers to 1000 milliseconds, refers to the time required for the preprocessing stage, refers to the time required for the model’s inference, and refers to the post-processing time required when the model applies Non-Maximum Suppression.
4.2. Parameter Settings
The overall model is implemented using the Pytorch framework and trained on a Titan RTX3090 GPU. During training, the pre-trained weights of the ResNet-18 [31] on ImageNet-1k [41] were used and trained on the public dataset used in this paper. The model used the AdamW optimizer with a weight decay of 0.0001, an initial learning rate set to 0.0001, and a mosaic data enhancement probability of 0.5.
4.3. Comparative Experiments on Backbone Network Improvement Strategies
This paper compares the model with only the backbone network part to the one with the RT-DETR decoder part. The results show that the improved model reduces the number of parameters by 46.75% compared with the original model using the ResNet-18 backbone network. Additionally, it achieves some improvement in accuracy, as shown in Table 2.
Table 2.
Comparison of the improved backbone network model with the ResNet-18 backbone network model on the dataset.
4.4. Ablation Study
To evaluate the effectiveness of each key component in MDA-DETR, this paper conducted comprehensive ablation experiments focusing on (1) the effectiveness of backbone network improvement strategies, (2) the effectiveness of MCCA, and (3) the importance of DFAM. During these experiments, two challenging scenarios—occlusion and blurring—were selected to observe and record the performance of these key components under different conditions, demonstrating their effectiveness in various situations.
- (1)
- Effectiveness of Backbone Network Improvement Strategies: The backbone network employs the RepNCSPELAN4 structure, initially enhancing the backbone’s performance and shows improvement across four indicators compared with the model with only the ResNet-18 backbone network (as shown in the second row of Table 3). However, when animals are occluded, the detection accuracy is low (as shown in the second row and fourth column of Figure 4).
Table 3. Ablation experiments of the three key components on the dataset constructed in this paper.
 Figure 4. Comparison of ablation experiments. (The orange animal in the upper right corner of the third column is the dataset icon.)
Figure 4. Comparison of ablation experiments. (The orange animal in the upper right corner of the third column is the dataset icon.) - (2)
- Effectiveness of MCCA: This study retained only the improved backbone network and MCCA for training and testing to demonstrate its effectiveness. The results indicate that MCCA significantly improves all four evaluation metrics and further enhances the accuracy of detecting occluded offending animals (as shown in the third row and fourth column of Figure 4).
- (3)
- The effectiveness of DFAM. DFAM adjusts the number of channels in the feature map generated by the AIFI module and further fuses it with the feature map generated by the improved backbone network. To demonstrate DFAM’s effectiveness, this study retained only DFAM and the improved backbone network for testing. Table 3 shows that adding DFAM leads to a slight decrease in recall. However, the 0.3% decrease in recall is accompanied by a 1.2% increase in precision, making the slight drop in recall acceptable. Furthermore, Figure 4 shows that using this module has enhanced the accuracy of generating the minimum bounding rectangle. Particularly when the offending animal in the image is blurry, it can more accurately locate and identify the offending animal. Finally, by combining the three proposed improvement methods, the model achieved a 2.9% increase in accuracy, a 3.3% increase in recall, a 2.9% improvement in , and a 4.7% improvement in mAP50–95 compared with the original baseline. The detection performance was exceptional, proving the effectiveness of the improvement strategy proposed in this article.
4.5. Comparison with Other Models
To comprehensively evaluate the performance of MDA-DETR, this paper compares it with six state-of-the-art object detection models: RT-DETR-r18 [11], yolov8n [42], yolov9-C [14], DETR [10], Deformable-detr [18], and DCA-yolov8 [43]. The results for all models were generated using the official code or based on published papers.
Table 4 shows the results of comparing MDA-DETR with six state-of-the-art methods, where the red font and blue font indicate the best and second best performance. From the results in Table 4, it can be seen that the proposed model achieves 97.8% metrics on the dataset, outperforming the original RT-DETR-r18 model by 1.3%, and it is 0.6% better than yolov8n, 0.3% better than yolov9-C, 3% better than DETR, 1.1% better than Deformable-detr, and 0.5% better than DCA-yolov8. Overall, the model proposed in this article outperforms other advanced methods in the detection of offending animals on the part of the publicly available Northeast China Tiger and Leopard National Park dataset and can better detect images of accident-prone animals.
Table 4.
Comparison of MDA-DETR with 6 state-of-the-art methods.
Figure 5 and Figure 6 show the detection results of MDA-DETR and advanced methods in different scenarios. The images selected in this article include three scenarios: animals being occluded, only having partial animal features, and animals being blurry at night. Among them, DETR and Deformable-detr have better performance in detecting images with only partial animal features, but there are false detections when detecting occluded animal images (leopard cats), and DETR also has false detections when detecting occluded wild boars. Yolov8n and yolov9-C can effectively handle scenes with only partial animal features and animal occlusion, but when detecting blurry animal images at night, yolov8n has lower detection accuracy, while yolov9-C lacks comprehensive detection (badgers). This article selects the DCA-yolov8 model, which can also detect occluded scenes, as the comparison model. From the results, it can be seen that the MDA-DETR proposed in this article has higher detection accuracy than DCA-ylov8 in several complex tasks. Overall, the method proposed in this article outperforms other methods on the publicly available dataset used. MDA-DETR not only accurately classifies the offending animal but also accurately locates and detects the offending animal in scenes where the animal is occluded and blurred at night.

Figure 5.
Comparison between ours and advanced methods (badger, black bear, leopard cat).

Figure 6.
Comparison between ours and advanced methods (red fox, yellow weasel, wild boar).
5. Discussion
This study proposed MDA-DETR, a novel object detection model, to address the challenges of detecting offending animals, particularly in obscured and blurry nighttime images. Comprehensive evaluations on the Northeast China Tiger and Leopard National Park dataset demonstrated that MDA-DETR significantly outperforms six state-of-the-art models, achieving superior results in mAP50 (+1.3% to +3%) and mAP50-95 (+0.5% to +4.7%). These results validate the effectiveness of the Multi-Channel Coordinated Attention (MCCA) mechanism and the Multi-Dimension Feature Aggregation Module (DFAM) in improving detection accuracy under challenging conditions.
The main findings of this research align with the initial hypothesis that incorporating multi-scale feature aggregation and enhanced attention mechanisms would address limitations in existing models. The observed improvements can be attributed to the following factors: The MCCA mechanism effectively integrates spatial and long-range dependencies, enhancing the accuracy of detecting occluded animals. The DFAM module fuses features across multiple scales, providing global and complementary information to improve the detection of blurry images. The use of VariFocal Loss further enhances classification accuracy by emphasizing high-quality positive samples.
Compared with the YOLO series, DETR, and its variants, MDA-DETR demonstrates significant advantages in handling occlusion and nighttime detection on the dataset used in this study. While the existing YOLO and DETR series methods perform well in most conventional object detection tasks, YOLO models tend to lose crucial information when processing blurred images of animals at night, leading to inaccurate target localization. Although DETR and its variants have improved target detection localization, they often fail to correctly classify objects in complex backgrounds, especially in occlusion or cluttered backgrounds. In contrast, MDA-DETR effectively overcomes these challenges by combining MCCA and DFAM. By incorporating multi-scale feature fusion and integrating the image’s positional information, semantic information, and long-range dependencies, MDA-DETR avoids detection failures caused by the loss of local features. Additionally, this multi-level information integration enhances the model’s ability to detect occluded animals and blurred nighttime animal images, reducing false negatives and false positives, and providing stronger robustness.
Despite the significant advantages demonstrated by MDA-DETR, this study still has certain limitations. First, the dataset used in this study contains only six specific species of offending animals, which limits the model’s applicability to other species and broader scenarios. Second, the dataset does not cover more complex environmental factors, such as changing lighting conditions or motion blur caused by rapid movement, which can often affect the model’s performance in detection tasks. Furthermore, although MDA-DETR has achieved significant accuracy improvements, its computational complexity may pose challenges for real-time deployment on edge devices.
To address these limitations, future research will focus on the following areas: Expanding the dataset: Plans are in place to create a dataset that includes more animal species and more complex environmental factors. Additionally, the use of generative models or trap cameras will be considered to acquire the relevant images for further evaluating the model’s performance in various scenarios, thereby enhancing its generalization ability and applicability to a broader range of species. Optimizing the model architecture: considering the computational complexity involved in real-time deployment, future work will explore lighter model architectures, such as integrating more efficient attention mechanisms or designing low-computation overhead feature extraction modules, to better suit resource-constrained edge devices. Expanding the application scope: Future studies will further explore the potential of MDA-DETR in a wider range of application scenarios, including general wildlife detection and endangered species protection. By expanding its application scope, this study wishes MDA-DETR to play a greater role in protecting ecological environments and biodiversity.
6. Conclusions
We propose a novel model, MDA-DETR, for detecting offending animals. To better handle scenes where animals are occluded, the MCCA module is designed to extract semantic information from feature maps, target location information, and long-distance dependencies. Subsequently, the DFAM module aggregates features at three different scales to obtain global features, enhancing the accuracy of detecting offending animals in blurry images. The data used in this study come from the Northeast Tiger and Leopard National Park dataset. Ablation experiments on this dataset demonstrate the effectiveness of the key components in MDA-DETR. Additionally, comprehensive comparative experimental results on this dataset confirm the robustness and effectiveness of the MDA-DETR model.
Author Contributions
All authors have made significant contributions to this research. Conceptualization, H.L. and H.Z.; methodology, H.L. and H.Z.; validation, H.L.; writing, H.L., H.Z., G.S., and F.Y.; supervision, H.Z., G.S., and F.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Key R&D Program of China (Grant number 2022YFF1302700), The Emergency Open Competition Project of National Forestry and Grassland Administration (Grant number 202303), and Outstanding Youth Team Project of Central Universities (Grant number QNTD202308).
Institutional Review Board Statement
Ethical review and approval were waived for this study because the research involves the development and evaluation of a computer vision model for detecting offending animals. The model was trained and tested on existing datasets of images and videos, such as the NTLNP dataset (https://github.com/myyyyw/NTLNP, (accessed on 9 March 2023)), which does not involve any direct interaction with or harm to animals.
Informed Consent Statement
Not applicable.
Data Availability Statement
This study uses the publicly available Northeast China Tiger and Leopard National Park dataset, which can be downloaded at https://github.com/myyyyw/NTLNP (accessed on 9 March 2023).
Acknowledgments
We appreciate the hard work of every author, the valuable suggestions of every reviewer, and the patience and meticulousness of academic editors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Huang, Y.; Yang, J.; Zhang, H.; Su, K.W.; Wen, Y.L. A Comparative Study of Human-wildlife Conflicts Management in Nature Reserves at Home and Abroad. World For. Res. 2021, 34, 27–32. [Google Scholar]
- Mamat, N.; Othman, M.F.; Yakub, F. Animal intrusion detection in farming area using YOLOv5 approach. In Proceedings of the 2022 22nd International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 27 November–1 December 2022; pp. 1–5. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23 August 2020; pp. 213–229. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Geng, Y.; Jiang, H.; Cheng, M.; Zhang, B.; Ke, Z.; Xu, X.; Chu, X. Yolov6 v3.0: A full-scale reloading. arXiv 2023, arXiv:2301.05586. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- GitHub Repository. 2023. Available online: https://github.com/myyyyw/NTLNP (accessed on 2 January 2025).
- Ashish, V. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Wang, Y.; Zhang, X.; Yang, T.; Sun, J. Anchor detr: Query design for transformer-based detector. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; pp. 2567–2575. [Google Scholar]
- Zeng, W.; Jin, S.; Xu, L.; Liu, W.; Qian, C.; Ouyang, W.; Luo, P.; Wang, X. TCFormer: Visual Recognition via Token Clustering Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 9521–9535. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.; Li, H.; Wu, P.; Zhang, Y.; Sun, X.; Wu, F. D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement. arXiv 2024, arXiv:2410.13842. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Delplanque, A.; Foucher, S.; Lejeune, P.; Linchant, J.; Théau, J. Multispecies detection and identification of African mammals in aerial imagery using convolutional neural networks. Remote Sens. Ecol. Conserv. 2022, 8, 166–179. [Google Scholar] [CrossRef]
- Cai, Q.; Zheng, B.; Zeng, X.; Hou, J. Wildlife object detection combined with solving method of long-tail data. J. Comput. Appl. 2022, 42, 1284–1291. [Google Scholar]
- Roy, A.M.; Bhaduri, J.; Kumar, T.; Raj, K. WilDect-YOLO: An efficient and robust computer vision-based accurate object localization model for automated endangered wildlife detection. Ecol. Inform. 2023, 75, 101919. [Google Scholar] [CrossRef]
- Yang, W.; Liu, T.; Zhou, J.; Hu, W.; Jiang, P. CNN-Swin Transformer Detection Algorithm of Forest Wildlife Images Based on Improved YOLOv5s. Sci. Silvae Sin. 2024, 60, 121–130. [Google Scholar]
- Ram, A.V.; Prakash, A.S.; Ahamed, A.I.; Anirudh, K.; Arvindh, M.M.; Nithyavathy, N. A self induced warning system for wild animal trespassing using machine vision system. In Proceedings of the 2018 International Conference on Intelligent Computing and Communication for Smart World (I2C2SW), Erode, India, 14–15 December 2018; pp. 349–353. [Google Scholar]
- Ravoor, P.C.; Sudarshan, T.S.B.; Rangarajan, K. Digital Borders: Design of an Animal Intrusion Detection System Based on Deep Learning. In Proceedings of the International Conference on Computer Vision and Image Processing, Prayagraj, India, 4–6 December 2020; pp. 186–200. [Google Scholar]
- Chiu, Y.-C.; Tsai, C.-Y.; Ruan, M.-D.; Shen, G.-Y.; Lee, T.-T. Mobilenet-SSDv2: An improved object detection model for embedded systems. In Proceedings of the 2020 International Conference on System Science and Engineering (ICSSE), Kagawa, Japan, 31 August–3 September 2020; pp. 1–5. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lee, J.; Lim, K.; Cho, J. Improved Monitoring of Wildlife Invasion through Data Augmentation by Extract—Append of a Segmented Entity. Sensors 2022, 22, 7383. [Google Scholar] [CrossRef] [PubMed]
- Charles, P.S.; Dharmalingam, S.; Baskaran, M.; Manoharan, P.S.; Hemanth, G.R. Intelligence Harmless Animal Avoider in Agriculture Farm. In Proceedings of the 2023 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 23–25 January 2023; pp. 1–4. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. Varifocalnet: An iou-aware dense object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8514–8523. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Barron, J.T. A general and adaptive robust loss function. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4331–4339. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 1405–1573. [Google Scholar] [CrossRef]
- Jocher, G.; Qiu, J.; Chaurasia, A. Ultralytics YOLO. GitHub Repository. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 2 January 2025).
- Yang, W.; Wu, J.; Zhang, J.; Gao, K.; Du, R.; Wu, Z.; Firkat, E.; Li, D. Deformable convolution and coordinate attention for fast cattle detection. Comput. Electron. Agric. 2023, 211, 108006. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).